论文辅助笔记:t2vec.ipynb
这是一个julia的代码
1 准备部分
using JSON
#引入 JSON 模块,用于处理 JSON 数据格式。
using Serialization
#引入序列化模块,它允许Julia中的对象可以被序列化(保存到文件)和反序列化(从文件加载)
using DelimitedFiles
#通常用于处理有分隔符的文件,例如 CSV 文件
using Distances
#引入了一个用于计算距离的模块,这个模块包含了多种计算距离的方法
include("utils.jl")
datapath = "/home/ruizhichai/t2vec/data"param = JSON.parsefile("../hyper-parameters.json")
#从 hyper-parameters.json 文件中读取超参数,并保存到变量 param 中
regionps = param["region"]
cityname = regionps["cityname"]
cellsize = regionps["cellsize"]2 读取porto相关的数据
region = SpatialRegion(cityname,
regionps["minlon"], regionps["minlat"],
regionps["maxlon"], regionps["maxlat"],
cellsize, cellsize,
regionps["minfreq"], # minfreq
40_000, # maxvocab_size
10, # k
4)
#创建了一个 SpatialRegion 对象
println("Building spatial region with:
cityname=$(region.name),
minlon=$(region.minlon),
minlat=$(region.minlat),
maxlon=$(region.maxlon),
maxlat=$(region.maxlat),
xstep=$(region.xstep),
ystep=$(region.ystep),
minfreq=$(region.minfreq)")
paramfile = "$datapath/$(region.name)-param-cell$(Int(cellsize))"
if isfile(paramfile)
println("Reading parameter file from $paramfile")
region = deserialize(paramfile)
println("Loaded $paramfile into region")
else
println("Cannot find $paramfile")
end
'''
Building spatial region with:
cityname=porto,
minlon=-8.735152,
minlat=40.953673,
maxlon=-8.156309,
maxlat=41.307945,
xstep=100.0,
ystep=100.0,
minfreq=100
#波尔图城区的一些基本信息
Reading parameter file from /home/ruizhichai/t2vec/data/porto-param-cell100
Loaded /home/ruizhichai/t2vec/data/porto-param-cell100 into region
#每一个单元格的最近K个热点单元格id以及其位置
'''2 创建数据库(无噪声和distorting)
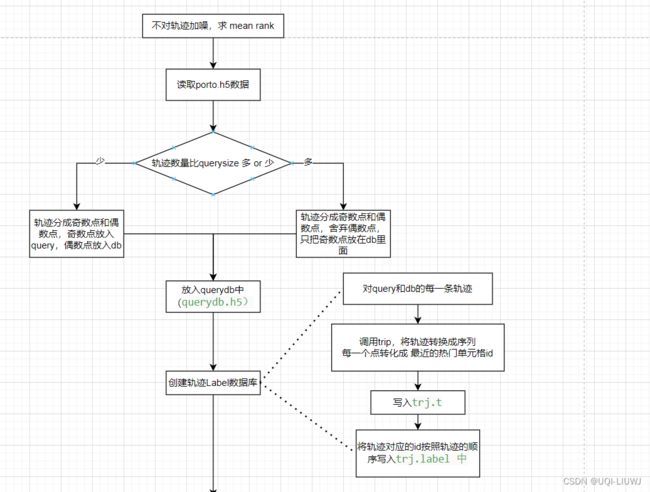
2.1 准备部分
## create querydb
prefix = "exp1"
do_split = true
start = 1_000_000+20_000
num_query = 1000
num_db = 100_000
querydbfile = joinpath(datapath, "$prefix-querydb.h5")
tfile = joinpath(datapath, "$prefix-trj.t")
labelfile = joinpath(datapath, "$prefix-trj.label")
vecfile = joinpath(datapath, "$prefix-trj.h5")2.2 创建数据库
createQueryDB(
"$datapath/$cityname.h5", # 轨迹文件路径
start, # 开始处理的轨迹的索引
num_query, # 查询数据集的大小
num_db, # 数据库的大小
(x, y)->(x, y), # 查询轨迹的噪声函数
(x, y)->(x, y), # 数据库轨迹的噪声函数
do_split=do_split, # 是否分割轨迹的标志
querydbfile=querydbfile # 输出的数据库文件名称
)
2.2.1 createQueryDB(utils.jl中定义)
"""
createQueryDB("../preprocessing/porto.h5", 1_000_000+20_000, 1000, 100_000,
(x,y)->(x,y), (x,y)->(x,y))
"""
function createQueryDB(trjfile::String, start::Int,
querysize::Int, dbsize::Int,
querynoise::Function, dbnoise::Function;
do_split=true,
querydbfile="querydb.h5",
min_length=30,
max_length=100)
nquery, ndb = 0, 0
#函数首先初始化查询 (nquery) 和数据库 (ndb) 的轨迹计数为0
h5open(trjfile, "r") do f
querydbf = h5open(querydbfile, "w")
#使用 h5open 函数打开输入轨迹文件 trjfile 进行读取
#并在其内部打开或创建一个新的HDF5文件 querydbfile 用于写入
num = read(attributes(f)["num"])
for i = start:num
trip = read(f["/trips/$i"])
timestamp = read(f["/timestamps/$i"])
if nquery < querysize
if 2min_length <= size(trip, 2) <= 2max_length
#如果查询轨迹数量还没有达到 querysize 并且轨迹长度符合限制,则处理轨迹用于查询
if do_split
nquery += 1
ndb += 1
trip1, timestamp1, trip2, timestamp2 = uniformsplit(trip, timestamp)
#如果 do_split 为 true,则使用 uniformsplit 函数将轨迹分为两部分
querydbf["/query/trips/$nquery"], querydbf["/query/timestamps/$nquery"] = querynoise(trip1, timestamp1)
querydbf["/query/names/$nquery"] = i
querydbf["/db/trips/$ndb"], querydbf["/db/timestamps/$ndb"] = dbnoise(trip2, timestamp2)
querydbf["/db/names/$ndb"] = i
else
nquery += 1
querydbf["/query/trips/$nquery"], querydbf["/query/timestamps/$nquery"] = querynoise(trip, timestamp)
querydbf["/query/names/$nquery"] = i
end
'''
每个分割或未分割的轨迹将通过 querynoise 或 dbnoise 函数添加噪声
然后被写入到新的HDF5文件 querydbf 中
如果是分割的轨迹,那么分割的两个一个放在nquery中,另一个放在ndb中
如果不分割,那么全放在nquery中
'''
end
elseif ndb < dbsize
'''
如果数据库轨迹数量还没有达到 dbsize 并且轨迹长度符合限制,则处理轨迹用于数据库
进入这个条件语句,说明ndb已经比nquery多了,也即query的轨迹数量够了
'''
if 2min_length <= size(trip, 2) <= 2max_length
if do_split
ndb += 1
trip1, timestamp1, _, _ = uniformsplit(trip, timestamp)
querydbf["/db/trips/$ndb"], querydbf["/db/timestamps/$ndb"] = dbnoise(trip1, timestamp1)
#querydbf["/db/timestamps/$ndb"] = timestamp
querydbf["/db/names/$ndb"] = i
else
ndb += 1
querydbf["/db/trips/$ndb"], querydbf["/db/timestamps/$ndb"] = dbnoise(trip, timestamp)
querydbf["/db/names/$ndb"] = i
end
end
else
break
end
end
querydbf["/query/num"], querydbf["/db/num"] = nquery, ndb
close(querydbf)
#在循环结束后,将查询和数据库的轨迹数量写入到输出文件。
end
nquery, ndb
end2.2.2 均匀分割轨迹(uniformsplit)【utils.jl中定义】
'''
原始的轨迹数据被均匀地分成两个部分,每个部分包含原始轨迹的一半点,而且这两个部分点是交错的
'''
function uniformsplit(trip::Matrix{Float64}, timestamp::Vector{Float64})
n = size(trip, 2)
# trip 矩阵中轨迹点的数量
idx1, idx2 = 1:2:n, 2:2:n
#idx1 包含从1开始到 n 结束的所有奇数索引,idx2 包含从2开始到 n 结束的所有偶数索引
copy(trip[:, idx1]), copy(timestamp[idx1]), copy(trip[:, idx2]), copy(timestamp[idx2])
end2.3 创建轨迹Label数据库
createTLabel(region, querydbfile; tfile=tfile, labelfile=labelfile)2.3.1 createTLabel
"""
Creating trj.t trj.label for t2vec()
"""
function createTLabel(region::SpatialRegion, querydbfile::String;
tfile="trj.t", labelfile="trj.label")
seq2str(seq) = join(map(string, seq), " ") * "\n"
querydbf = h5open(querydbfile, "r")
#打开轨迹数据库文件进行读取
label = Int[]
open(tfile, "w") do f
#打开 tfile 文件进行写入操作
num_query, num_db = read(querydbf["/query/num"]), read(querydbf["/db/num"])
#读取查询数据集和数据库的大小
for i = 1:num_query+num_db
location, idx = i <= num_query ? ("query", i) : ("db", i-num_query)
#遍历所有的轨迹,判断它们是查询数据集的还是数据库的,并对每个轨迹执行以下操作:
trip = read(querydbf["/$location/trips/$idx"])
name = read(querydbf["/$location/names/$idx"])
#从文件中读取轨迹 (trip) 和其名称 (name)。
seq = trip2seq(region, trip)
#调用 trip2seq 函数将轨迹转换成序列
#../preprocessing/SpatialRegionTools.jl里面设置的
#每一个点转化成最近的热门单元格的id
write(f, seq2str(seq))
#使用 seq2str 函数将序列转换为字符串,并写入 tfile 文件
push!(label, name)
#将轨迹的名称添加到 label 数组
end
end
writedlm(labelfile, label)
#将轨迹的名称添加到 label 数组
close(querydbf)
length(label)
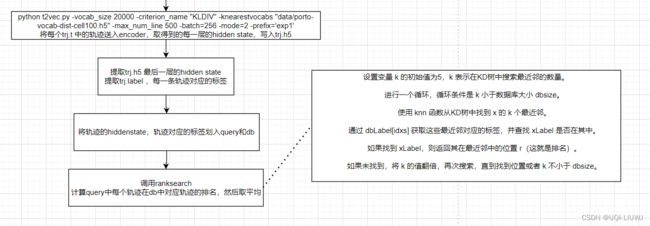
end3 在命令行敲下
python t2vec.py -vocab_size 20000 -criterion_name "KLDIV" -knearestvocabs "data/porto-vocab-dist-cell100.h5" -max_num_line 500 -batch=256 -mode=2 -prefix='exp1'
Namespace(batch=256, bidirectional=True, bucketsize=[(20, 30), (30, 30), (30, 50), (50, 50), (50, 70), (70, 70), (70, 100), (100, 100)], checkpoint='/home/ruizhichai/t2vec/data/checkpoint.pt', criterion_name='KLDIV', cuda=True, data='/home/ruizhichai/t2vec/data', discriminative_w=0.1, dist_decay_speed=0.8, dropout=0.2, embedding_size=256, epochs=15, generator_batch=32, hidden_size=256, knearestvocabs='data/porto-vocab-dist-cell100.h5', learning_rate=0.001, max_grad_norm=5.0, max_length=200, max_num_line=500, mode=2, num_layers=3, prefix='exp1', pretrained_embedding=None, print_freq=50, save_freq=100, start_iteration=0, t2vec_batch=256, use_discriminative=False, vocab_size=20000)
=> loading checkpoint '/home/ruizhichai/t2vec/data/checkpoint.pt'
0: Encoding 256 trjs...
/home/ruizhichai/t2vec/data_utils.py:84: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray.
src = list(np.array(src)[idx])
100: Encoding 256 trjs...
200: Encoding 256 trjs...
300: Encoding 256 trjs...
=> saving vectors into /home/ruizhichai/t2vec/data/exp1-trj.h54 查看ranking
## load vectors and labels
vecs = h5open(vecfile, "r") do f
read(f["layer3"])
end
#打开名为 vecfile 的HDF5文件
#读取最后一层hidden state的内容
label = readdlm(labelfile, Int)
#读取轨迹对应的标签
query, db = vecs[:, 1:num_query], vecs[:, num_query+1:end]
#查询向量 query 被设定为 vecs 的前 num_query 列。
#数据库向量 db 被设定为 vecs 的剩余列。
queryLabel, dbLabel = label[1:num_query], label[num_query+1:end]
#对应地,将 label 分为 queryLabel(查询标签)和 dbLabel(数据库标签)
query, db = [query[:, i] for i in 1:size(query, 2)], [db[:, i] for i in 1:size(db, 2)];
#将 query 和 db 各自转换为一个由列向量组成的列表,以便之后进行搜索
# without discriminative loss
dbsizes = [20_000, 40_000, 60_000, 80_000, 100_000]
#定义一个数组 dbsizes,包含了不同的数据库大小设置
for dbsize in dbsizes
ranks = ranksearch(query, queryLabel, db[1:dbsize], dbLabel[1:dbsize], euclidean)
#调用 ranksearch 函数(未在代码段中给出),这个函数执行搜索任务,计算每个查询向量在数据库中的排名
println("mean rank: $(mean(ranks)) with dbsize: $dbsize")
end4.1 ranksearch
"""
计算查询集(query)中每个轨迹(trajectory)在数据库集(db)中的对应轨迹的排名
For each trj in query, computing the rank of its twin trj in db.
This function is applicable to vector representations.
query[:, i] (db[:, i]) represent a trajectory.
"""
function ranksearch(query::Matrix{T},
queryLabel::Vector{Int},
db::Matrix{T},
dbLabel::Vector{Int}) where T
@assert size(query, 2) == length(queryLabel) "unmatched query and label"
@assert size(db, 2) == length(dbLabel) "unmatched db and label"
#确保提供的查询向量的数量与查询标签的数量一致,数据库向量的数量与数据库标签的数量一致
println("Building KDTree...")
kdtree = KDTree(db)
#利用数据库向量 db 建立一个KD树(kdtree),以便快速进行k最近邻搜索
dbsize = length(dbLabel)
function rank(x::Vector{T}, xLabel::Int)
#内部定义了一个 rank 函数,它接受一个向量 x 和其对应的标签 xLabel。
k = 5
@assert k < dbsize "The database size is too small"
while k < dbsize
idxs, _ = knn(kdtree, x, k, true)
r = findfirst(t->t==xLabel, dbLabel[idxs])
r == nothing ? k = 2k : return r
end
dbsize
'''
设置变量 k 的初始值为5,k 表示在KD树中搜索最近邻的数量。
进行一个循环,循环条件是 k 小于数据库大小 dbsize。
使用 knn 函数从KD树中找到 x 的 k 个最近邻。
通过 dbLabel[idxs] 获取这些最近邻对应的标签,并查找 xLabel 是否在其中。
如果找到 xLabel,则返回其在最近邻中的位置 r(这就是排名)。
如果未找到,将 k 的值翻倍,再次搜索,直到找到位置或者 k 不小于 dbsize。
'''
end
ranks = Int[]
for i = 1:length(queryLabel)
push!(ranks, rank(query[:,i], queryLabel[i]))
end
'''
初始化一个空的整数数组 ranks 来存放每个查询向量的排名。
遍历查询标签 queryLabel,对于每个查询向量,调用 rank 函数计算其排名,并将排名添加到 ranks 数组。
'''
ranks
end