自动化-测试面试题
INSERT INTO table_name (列1, 列2,...) VALUES (值1, 值2,....)
UPDATE 表名称 SET 列名称 = 新值 WHERE 列名称 = 某值
DELETE FROM 表名称 WHERE 列名称 = 值
SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo
FROM Persons
LEFT JOIN Orders
ON Persons.Id_P=Orders.Id_P
ORDER BY Persons.LastName
ORDER BY Company 降序DESC, id升序 ASC
order by 默认按照 ASC 升序排列
max(id),最小 min(id)Jmeter
提取器
边界提取器,xpath,json,正则提取器一般使用Jmeter的步骤是这样的:
- 新建一个线程组。
- 然后就是新建一个HTTP请求默认值。(输入接口服务器IP和端口)
- 再新建很多HTTP请求,一个请求一个用例。(输入接口路径,访问方式,参数等。)
- 然后创建断言和查看结果树。
Jmeter的关联方法
- 接口返回结果通常为Html和Json格式
- 主要用到正则提取、Json提取、Xpath提取和边界值提取还有beanshell
- 对于Html这种格式通常用正则或者Xpath来提取
- 对于Json这种格式通常用Json提取器
app常用的性能测试指标
GT,腾讯类似GT
1、响应
2、内存
3、CPU
4、FPS (app使用的流畅度)
5、GPU渲染
6、电量
7、流量
web端,app端,小程序端测试差异详解
前置解释:
1.单纯从功能测试的层面上来讲的话,APP 测试、web 测试和H5测试在流程和功能测试上是没有区别的
2.Web项目或pc项目都是在电脑上进行测试的。常见的PC项目架构有BS架构和CS架构的,BS架构就是通过浏览器(browser)请求后台服务(server),后台返回到响应内容显示在浏览器上
3.app测试平台分为安卓和IOS端:安卓测试需要在安卓手机上安装开发提供的apk测试包;IOS测试需要将手机UUID提供给开发安装ipa测试包进行测试。
不同点:
1.系统架构不一样
a.web端测试只要更新了服务器端,客户端就会同步会更新
b.APP测试虽然对应了一个后台,但是不同的用户可能下载了不同版本的客户端,上线测试时,需要兼容每个版本的测试。app 修改了服务端,则客户端用户所有核心版本都需要进行回归测试一遍
2.发布流程不同
a.web端每次更新发布,需要将测试通过的包替换线上包,重启服务后立刻生效,访问的就是最新的环境
b.APP端需要向应用市场发布,安卓发布的市场有很多,应用宝、豌豆荚、应用商店等,每个应用都需要单独审核;IOS端应用比较单一就是appstore,从提交、审核到发布会有一定的时间间隔,开发的应用包不会立刻发布
3.专项测试不同
a.app端需要一些专项测试--比如安装卸载测试,耗电量&流量测试等
b.兼容性方面,因为测试平台的不同,着重点不一样
展开来说:
app测试类型有如下:
1.安装卸载测试:确认系统能正常安装应用及使用,不需要时卸载及数据清除
2.安全测试:防范隐私泄露、密码加密及传输安全、权限的合理开放、数据库安全、通信安全以及安装包反编译
3.交互与异常测试:同级/上下级页面的页面交互及数据加载、网络异常、数据异常,前后端展示及状态
4.性能测试、耗电量&流量测试:内存、CPU、流量消耗、耗电量、冷热启动速度、图片资源大小
5.界面易用性测试:符合用户习惯
6.UI测试:页面颜色搭配、控件摆放位置及兼容性
7.功能测试:需求文档已有及隐含的需求功能可正常使用
8.兼容性测试:网络、机型、系统、分辨率、硬件、同类软件、新旧数据
9.此外还有,Web和移动端的同步情况,用户在Web端的操作,在移动端是否可以正常的进行同步、显示;在移动端的操作,用户登录web账号,信息是否同步等
与web测试的异同:
1.界面测试方面,移动端测试需注意手势,横竖屏切换,多点触控,事件触发区域等
2.兼容性测试方面,web是基于浏览器的,所以更倾向于浏览器和电脑硬件,电脑系统的方向的兼容,不过一般还是以浏览器的为主。而浏览器的兼容则是一般是选择不同的浏览器内核进行测试(IE、chrome、Firefox)
3.app端不仅要看分辨率,屏幕尺寸,还要看设备系统-系统总的来说也就分为Android和iOS
4.性能方面,web项目需监测响应时间、CPU、Memory,app项目除了监测响应时间、CPU、Memory外,还需监测流量、电量等
5.安全测试方面,安装包是否可反编译代码、安装包是否签名、权限设置,例如访问通讯录、相册、照相机等等,登录后长时间无操作情况
专项测试方面,相对于 Wed 项目,APP有如下专项测试项
1. 干扰测试:中断,来电,短信,关机,重启等
2.弱网络测试(模拟2g、3g、4g,wifi网络状态以及丢包情况);网络切换测试(网络断开后重连、3g切换到4g/5g/wifi 等)
3.安装、更新、卸载。安装需考虑安装时的中断、弱网、安装后删除安装文件等情况;卸载需考虑 卸载后是否删除app相关的文件;更新,分强制更新、非强制更新、增量包更新、断点续传、弱网状态下更新
4.边界测试:可用存储空间少、没有SD卡/双SD卡、飞行模式、系统时间有误、第三方依赖(QQ、微信登录)等
5.不同app版本的业务功能测试
6.测试工具方面,自动化测试工具:APP 一般使用 Appium,airtest;Web端一般使用 Selenium,性能测试工具:APP 一般使用 JMeter; Web 一般使用loadrunner、JMeter
小程序测试:
小程序是一种不需要下载安装即可使用的应用
1.功能测试方面,要覆盖各功能模块,所有操作路径
2.易用性测试,包括,导航、功能入口,上下层级进入&返回、其他人机交互体验等
3.兼容性方面,主要指操作系统和屏幕分辨率方面,操作系统主要是指android系统和iOS系统
4.安全方面,小程序是内嵌到微信的,因此客户端的安全性毋庸置疑。只需关注小程序本身与后端接口传递数据的安全性即可。此外,还要注意权限方面的要求
Json和字典的区别?
python中,json和dict非常类似,都是key-value的形式,而且json、dict也可以非常方便的通过dumps、loads互转。既然都是key-value格式,为啥还需要进行格式转换?
json:是一种数据格式,是纯字符串。可以被解析成Python的dict或者其他形式。
dict:是一个完整的数据结构,是对Hash Table这一数据结构的一种实现,是一套从存储到提取都封装好了的方案。它使用内置的哈希函数来规划key对应value的存储位置,从而获得O(1)的数据读取速度。
json和dict对比
- json的key只能是字符串,python的dict可以是任何可hash对象(hashtable type);
- json的key可以是有序、重复的;dict的key不可以重复。
- json的value只能是字符串、浮点数、布尔值或者null,或者它们构成的数组或者对象。
- json任意key存在默认值undefined,dict默认没有默认值;
- json访问方式可以是[],也可以是.,遍历方式分in、of;dict的value仅可以下标访问。
- json的字符串强制双引号,dict字符串可以单引号、双引号;
- dict可以嵌套tuple,json里只有数组。
- json:true、false、null
- python:True、False、None
- json中文必须是unicode编码,如"\u6211".
- json的类型是字符串,字典的类型是字典。
hashtable
一个对象当其声明周期内的hash值不发生改变,而且可以跟其他对象进行比较时,这个对象就是hashtable的。
1、python中的基本类型都是Hashtable,如str、bytes、数字类型、tuple等;
2、用户自定义的类型默认都是hashtable,因为它们的hash值就是id()值;
3、frozenset始终都是hashtable的,因为它们所有的项目都是被定义成hashtable的;
4、只有当tuple内的所有项都是hashtable的时候,tuple才是hashtable;
接口自动化
接口自动化使用的测试框架是什么?
测试框架:python+unittest+requests+ddt+openpyxl+pymysql+logging
测试框架:python:入门简单,语法简洁
unittest :定义一个测试用例类,具体的方法来维护测试用例的生命周期,测试场景行为,测试用例 前置场景,行为,期望结果,实际结果,断言方法,Setup teardown方法
requests:接口调用 ,支持http请求的库,API 简洁,提供不同的http请求方法,支持session,cookies,
ddt :数据驱动,ddt 类装饰器,data 测试方法装饰器 unpack解包可迭代的数据类型
普通用户,数据库,配置文件---(基础数据)
openpyxl: 数据管理 excel管理 数据,使用openpyxl模块来进行excel数据的读和写(excle,csv, json, yaml, txt都可以管理测试数据)
pymysql:数据库交互,数据校验
eval,json:数据格式的转换 Eval将python支持的格式转换成对应的格式
logging:日志处理, 统一日志输出格式,渠道,级别,执行结果的记录,便于定位问题
jenkins:持续集成
不可逆的操作,如何处理,比如删除一个订单这种接口如何测试?
使用新建订单接口造数据,不建议直接使用数据库造数据
python如何连接数据库操作?
首先导入模块(提前pip安装) import pymysql
打开数据库连接 db = pymysql.connect("localhost", "username", "psw", "db_name")
创建一个游标对象 cursor = db.cursor()
sql查询语句 sql = "select * from emp"
执行sql语句 cursor.execute(sql)
获取所有记录列表 cursor.fetchall()
然后for循环遍历
关闭数据库连接 db.close()
依赖第三方的接口如何处理
这个需要自己去搭建一个mock服务,模拟接口返回数据,参考【python笔记25-mock-server之moco】(python笔记25-mock-server之moco - 上海-悠悠 - 博客园)
moco是一个开源的框架,在github上可以下载到https://github.com/dreamhead/moco
moco服务搭建需要自己能够熟练掌握,面试会问你具体如何搭建 ,如何模拟返回的数据,是用的什么格式,如何请求的
测试数据存放?
1.对于账号密码,这种管全局的参数,可以用命令行参数,单独抽出来,写的配置文件里(如ini)
2.对于一些一次性消耗的数据,比如注册,每次注册不一样的数,可以用随机函数生成
3.对于一个接口有多组测试的参数,可以参数化,数据放yaml,text,json,excel都可以
4.对于可以反复使用的数据,比如订单的各种状态需要造数据的情况,可以放到数据库,每次数据初始化,用完后再清理
5.对于邮箱配置的一些参数,可以用ini配置文件
6.对于全部是独立的接口项目,可以用数据驱动方式,用excel/csv管理测试的接口数据
7.对于少量的静态数据,比如一个接口的测试数据,也就2-3组,可以写到py脚本的开头,十年八年都不会变更的
什么是数据驱动,如何参数化?
参数化和数据驱动的概念这个肯定要知道的,参数化的思想是代码用例写好了后,不需要改代码,只需维护测试数据就可以了,并且根据不同的测试数据生成多个用例
openpyxl模块操作excel及结合ddt实现数据驱动
Python基础
Python3 中有六个标准的数据类型:
- Number(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Set(集合)
- Dictionary(字典)
可变类型和不可变类型:
- 不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
- 可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)。
不可变数据类型,不允许变量的值发生变化
如果改变了变量的值,相当于是新建了一个对象,
而对于相同的值的对象,在内存中则只有一个对象,
内部会有一个引用计数来记录有多少个变量引用这个对象;
可变数据类型,允许变量的值发生变化,
即如果对变量进行append、+=等这种操作后,
只是改变了变量的值,而不会新建一个对象,
变量引用的对象的地址也不会变化,不过对于相同的值的不同对象,
在内存中则会存在不同的对象,即每个对象都有自己的地址,
相当于内存中对于同值的对象保存了多份,这里不存在引用计数,是实实在在的对象。
说一说你所知道的 Python 数据结构有哪些。
列表,字典,元祖,
说一下深拷贝和浅拷贝
浅拷贝,相当于只考虑父辈,不考虑其内部存在的子辈。
最外层a的地址发生改变,但内部的x和y引用的还是老的地址。
深拷贝,相当于复制了一个新的,跟以前的没关系。
最外层a和内部可变对象的地址发生改变,但内部不可变对象地址还是老的。Python 中列表和元组的区别是什么?元组是不是真的不可变?
列表和元组之间的区别是数组内容是可以被修改的而元组内容是只读的
元组与列表相互转换,使用函数list()将元组转化为列表,使用函数tuple()将列表转化为元组什么是生成器和迭代器?它们之间有什么区别?
什么是生成器?生成器只有在调用时才会生成相应的数据只记录当前位置,只有一个__next__()方法 ---->(i*i for i in range(10)) ==生成器
可以作用于for 循环的对象统称为可迭代对象(Iterable)
可以被__next__()函数调用并不断返回下一个值的对象称为迭代器:Iterator。
使用isinstance()判断一个对象是否为迭代器:Iterator。python 生成器和迭代器_python迭代器和生成器_m0_51736952的博客-CSDN博客
什么是闭包?装饰器又是什么?
闭包,又称闭包函数或者闭合函数,其实和前面讲的嵌套函数类似,
不同之处在于,闭包中外部函数返回的不是一个具体的值,
而是一个函数。一般情况下,返回的函数会赋值给一个变量,
这个变量可以在后面被继续执行调用。什么是闭包,Python闭包(初学者必读)
装饰器有什么作用?你用过装饰器吗?请写一个装饰器的例子。
装饰器本质上是一个Python函数(其实就是闭包)
它可以让其他函数在不需要做任何代码变动的前提下增加额外功能
装饰器的返回值也是一个函数对象。
装饰器用于有以下场景,比如:插入日志、性能测试、事务处理、缓存、权限校验等场景。python装饰器详解_谦虚且进步的博客-CSDN博客
说一下什么是匿名函数,用匿名函数有什么好处?
lambda 表达式,又称匿名函数
常用来表示内部仅包含 1 行表达式的函数。
如果一个函数的函数体仅有 1 行表达式,则该函数就可以用 lambda 表达式来代替。Python lambda表达式(匿名函数)及用法
回调函数
回调函数就是一个被作为参数传递的函数。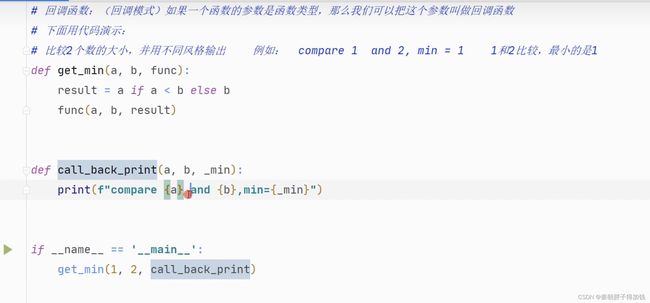
如何提高 Python 的运行效率吗?
1、多进程并行编程
对于CPU密集型的程序,可以使用multiProcessing的Process,Pool等封装好的类,通过多进程的方式实现并行计算。但是因为进程中的通信成本比较大,对于进程之间需要大量数据交互的程序效率未必有大的提高。
2、多线程并行编程
对于IO密集型的程序,multiprocessing.dummy模块使用multiprocessing的接口封装threading,使得多线程编程也变得非常轻松。
3、优化算法时间
算法的时间复杂度对程序的执行效率影响最大,在Python中可以通过选择合适的数据结构来优化时间复杂度,如list和set查找某一个元素的时间复杂度分别是O(n)和O(1)。不同的场景有不同的优化方式,总得来说,一般有分治,分支界限,贪心,动态规划等思想。
4、针对循环的优化
每种编程语言都会强调需要优化循环。当使用Python的时候,你可以依靠大量的技巧使得循环运行得更快。然而,开发者经常漏掉的一个方法是:避免在一个循环中使用点操作。优化循环的关键,是要减少Python在循环内部执行的工作量,因为Python原生的解释器在那种情况下,真的会减缓执行的速度。
5、函数选择
在循环的时候使用xrange而不是range;使用xrange可以节省大量的系统内存,因为xrange()在序列中每次调用只产生一个整数元素。而range()将直接返回完整的元素列表,用于循环时会有不必要的开销。递归调用

GUI自动化
设计模式
- PO模式
- 公用元素使用方法封装,等待,点击,切换iframe,下滑列表,截图,日志
- 页面元素定位语句
- 页面操作步骤
- 用例层,校验assert
- 日志,报告,截图
定位失败原因
| 原因 | 解决方法 |
| 没有打开正确的网址 | 填写正确的网址 |
| 定位器选择错误 | 选择合适的定位器 |
| 定位表达式错误 | 简单粗暴:F12 copy或手写定位调试 |
| 元素嵌套在iframe中 | 1,切换到iframe中:driver.switch_to.frame(’ iframe的id或name值 ');2,再进行元素定位 元素在新窗口中 1,获取打开的多个窗口句柄:handles = driver.window_handles;2,切换到新窗口中: driver.switch_to.window(handles[-1]) |
| 页面元素没有及时加载 | 1,加等待,不要加的太少,加10s,如果10秒还找不到说明不是因为页面加载导致的元素找不到;2,确定是页面元素没有及时加载原因后,可以使用以下三种等待方式,详见1.2 页面元素不可见或不可点击 1,使用JavaScript实现元素定位和动作执行;2,使用鼠标事件ActionChains来操作;3,如果是被伪元素遮挡了原本的元素,可以直接定位到伪元素上进行点击操作 。详见1.3 |
| 页面元素是动态的 | 1.根据其他静态属性定位;2.根据元素属性值模糊匹配定位。 详见1.4 |
| 脚本流程与实际不符 | 调整脚本以符合实际业务流程 |
如何处理重定向
当我们遇到这种重定向,我们应该怎么处理?
# request源码中
param allow_redirects: (optional) Boolean. Enable/disable GET/OPTIONS/POST/PUT/PATCH/DELETE/HEAD redirection. Defaults to ``True``.
:type allow_redirects: bool
发现requests中默认是True,是允许重定向的。
# coding:utf-8
import requests
url = 'http://github.com'
# 重定向为False
r = requests.get(url,allow_redirects=False)
print(r.status_code)
print(r.url)
代码结果:
301
http://github.com/
在默认开启的状态下,我们如何知道请求过程中有没有发现重定向呢?
requests返回中history可以帮我们解决
# coding:utf-8
import requests
url = 'http://github.com'
# 重定向为True
r = requests.get(url,allow_redirects=True)
print(r.status_code)
print(r.history)
代码结果:
200
[]
发现如果我们允许重定向返回的状态码为200,通过查看历史请求状态码,发现中间请求过301