Java中的类加载器、双亲委派、SPI机制
参考:
Java双亲委派模型:为什么要双亲委派?如何打破它?破在哪里?
【Code皮皮虾】带你盘点双亲委派机制【原理、优缺点】,以及如何打破它?
JDK/Dubbo/Spring 三种 SPI 机制,谁更好?
Java中的类加载器、双亲委派、SPI机制
- 前言
- 一、类加载器
- 二、双亲委派机制
-
- 1. 双亲委派机制介绍
- 2. 双亲委派机制的作用
- 3. 双亲委派的局限性与线程上下文类加载器
- 4. 双亲委派机制如何破坏
- 5. 总结
- 三、SPI机制
-
- 1. JDK SPI
- 2. Spring SPI
- 3. Dubbo SPI
- 4. 对比
前言
平时做业务开发比较少接触类加载器,但是如果想深入学习Tomcat、Spring等开源项目,或者从事底层架构的开发,了解甚至熟悉类加载的原理是必不可少的。
Java的类加载器有哪些?什么是双亲委派?为什么要双亲委派?如何打破它?多多少少对这些概念了解一些,甚至因为应付面试背过这些知识点,但是再深入一些细节,却知之甚少。
一、类加载器
类加载器,顾名思义就是一个可以将Java字节码加载为java.lang.Class实例的工具。这个过程包括,读取字节数组、验证、解析、初始化等。另外,它也可以加载资源,包括图像文件和配置文件。
类加载器的特点:
- 动态加载,无需在程序一开始运行的时候加载,而是在程序运行的过程中,动态按需加载,字节码的来源也很多,压缩包jar、war中,网络中,本地文件等。类加载器动态加载的特点为热部署,热加载做了有力支持。
- 全盘负责,当一个类加载器加载一个类时,这个类所依赖的、引用的其他所有类都由这个类加载器加载,除非在程序中显式地指定另外一个类加载器加载。所以破坏双亲委派不能破坏扩展类加载器以上的顺序。
一个类的唯一性由加载它的类加载器和这个类的本身决定(类的全限定名+类加载器的实例ID作为唯一标识)。比较两个类是否相等(包括Class对象的equals()、isAssignableFrom()、isInstance()以及instanceof关键字等),只有在这两个类是由同一个类加载器加载的前提下才有意义,否则,即使这两个类来源于同一个Class文件,被同一个虚拟机加载,只要加载它们的类加载器不同,这两个类就必定不相等。
从实现方式上,类加载器可以分为两种:一种是启动类加载器,由C++语言实现,是虚拟机自身的一部分;另一种是继承于java.lang.ClassLoader的类加载器,包括扩展类加载器、应用程序类加载器以及自定义类加载器。
-
启动类加载器(Bootstrap ClassLoader):负责加载
目录中的,或者被\lib -Xbootclasspath参数所指定的路径,并且是虚拟机识别的(仅按照文件名识别,如rt.jar,名字不符合的类库即使放在lib目录中也不会被加载)类库加载到虚拟机内存中。启动类加载器无法被Java程序直接引用,用户在编写自定义类加载器时,如果想设置Bootstrap ClassLoader为其parent,可直接设置null。 -
扩展类加载器(Extension ClassLoader):负责加载
目录中的,或者被\lib\ext java.ext.dirs系统变量所指定路径中的所有类库。该类加载器由sun.misc.Launcher$ExtClassLoader实现。扩展类加载器由启动类加载器加载,其父类加载器为启动类加载器,即parent=null。 -
应用程序类加载器(Application ClassLoader):负责加载用户类路径(ClassPath)上所指定的类库,由
sun.misc.Launcher$App-ClassLoader实现。开发者可直接通过java.lang.ClassLoader中的getSystemClassLoader()方法获取应用程序类加载器,所以也可称它为系统类加载器。应用程序类加载器也是启动类加载器加载的,但是它的父类加载器是扩展类加载器。在一个应用程序中,系统类加载器一般是默认类加载器。
二、双亲委派机制
1. 双亲委派机制介绍
JVM 并不是在启动时就把所有的.class文件都加载一遍,而是程序在运行过程中用到了这个类才去加载。除了启动类加载器外,其他所有类加载器都需要继承抽象类ClassLoader,这个抽象类中定义了三个关键方法,理解清楚它们的作用和关系非常重要。
public abstract class ClassLoader {
//每个类加载器都有个父加载器
private final ClassLoader parent;
public Class<?> loadClass(String name) {
//查找一下这个类是不是已经加载过了
Class<?> c = findLoadedClass(name);
//如果没有加载过
if (c == null) {
//先委派给父加载器去加载,注意这是个递归调用
if (parent != null) {
c = parent.loadClass(name);
} else {
// 如果父加载器为空,查找Bootstrap加载器是不是加载过了
c = findBootstrapClassOrNull(name);
}
}
// 如果父加载器没加载成功,调用自己的findClass去加载
if (c == null) {
c = findClass(name);
}
return c;
}
protected Class<?> findClass(String name){
// 1. 根据传入的类名name,到在特定目录下去寻找类文件,把.class文件读入内存
// ...
// 2. 调用defineClass将字节数组转成Class对象
return defineClass(buf, off, len);
}
// 将字节码数组解析成一个Class对象,用native方法实现
protected final Class<?> defineClass(byte[] b, int off, int len){
// ...
}
}
从上面的代码可以得到几个关键信息:
- JVM 的类加载器是分层次的,它们有父子关系,而这个关系不是继承维护,而是组合,每个类加载器都持有一个 parent字段,指向父加载器。
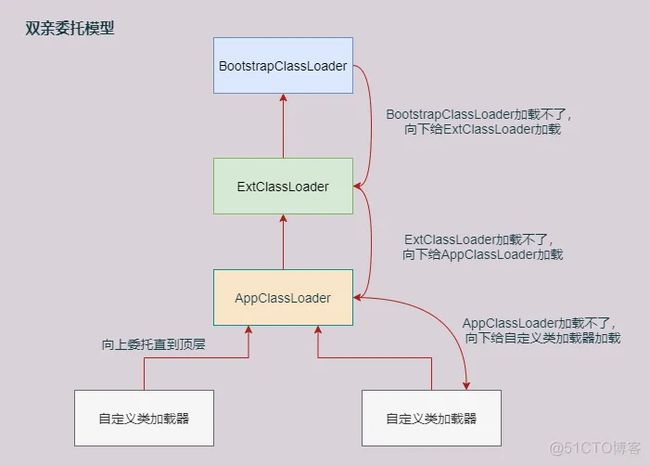
defineClass方法的职责是调用 native 方法把 Java 类的字节码解析成一个 Class 对象。findClass方法的主要职责就是找到.class文件并把.class文件读到内存得到字节码数组,然后调用 defineClass方法得到 Class 对象。子类必须实现findClass。loadClass方法的主要职责就是实现双亲委派机制:首先检查这个类是不是已经被加载过了,如果加载过了直接返回,否则委派给父加载器加载,这是一个递归调用,一层一层向上委派,最顶层的类加载器(启动类加载器)无法加载该类时,再一层一层向下委派给子类加载器加载。
2. 双亲委派机制的作用
双亲委派保证类加载器,自下而上的委派,又自上而下的加载,保证每一个类在各个类加载器中都是同一个类。
一个非常明显的目的:保证java官方的类库和扩展类库的加载安全性,不会被开发者覆盖。例如类java.lang.Object,它存放在rt.jar之中,无论哪个类加载器要加载这个类,最终都是委派给启动类加载器加载,因此Object类在程序的各种类加载器环境中都是同一个类。
如果开发者自己开发开源框架,也可以自定义类加载器,利用双亲委派模型,保护自己框架需要加载的类不被应用程序覆盖。
总结其优点如下:
- 避免类的重复加载
- 保护程序安全,防止核心API被随意篡改
缺点:在某些场景下双亲委派制过于局限,所以有时候必须打破双亲委派机制来达到目的。例如:SPI机制
3. 双亲委派的局限性与线程上下文类加载器
以JDBC创建数据库连接为例,介绍双亲委派机制的局限性:
在执行如下代码创建连接时,需要对DriverManager类进行初始化
Connection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/mysql", "root", "root");
初始化DriverManager类时,会执行下面这一行代码,加载classpath下面的所有实现了Driver接口的实现类:
ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class);
那么此处问题来了:
位于 rt.jar下的java.sql.DriverManager类是被启动类加载器加载的,那么在加载时遇到以上代码,会尝试加载所有Driver的实现类(SPI),但是这些实现类基本都是第三方提供的,第三方的类不能被启动类加载器加载。
怎么解决这个问题呢?
JDBC通过引入ThreadContextClassLoader(线程上下文加载器,默认情况下是AppClassLoader)的方式来使用应用程序类加载器AppClassLoader破坏了双亲委派原则。
ServiceLoader.load()实现:
public static <S> ServiceLoader<S> load(Class<S> service) {
ClassLoader cl = Thread.currentThread().getContextClassLoader();
return ServiceLoader.load(service, cl);
}
线程上下文类加载器其实是一种类加载器传递机制。可以通过java.lang.Thread#setContextClassLoader方法给一个线程设置上下文类加载器,在该线程后续执行过程中就能把这个类加载器取(java.lang.Thread#getContextClassLoader)出来使用。
如果创建线程时未设置上下文类加载器,将会从父线程(parent = currentThread())中获取,如果在应用程序的全局范围内都没有设置过,就默认是应用程序类加载器。
线程上下文类加载器的出现就是为了方便破坏双亲委派:
一个典型的例子便是JNDI服务,JNDI现在已经是Java的标准服务,它的代码由启动类加载器去加载(在JDK 1.3时放进去的rt.jar),但JNDI的目的就是对资源进行集中管理和查找,它需要调用由独立厂商实现并部署在应用程序的ClassPath下的JNDI接口提供者(SPI,Service Provider Interface)的代码,但启动类加载器不可能去加载ClassPath下的类。
但是有了线程上下文类加载器就好办了,JNDI服务使用线程上下文类加载器去加载所需要的SPI代码,也就是父类加载器请求子类加载器去完成类加载的动作,这种行为实际上就是打通了双亲委派模型的层次结构来逆向使用类加载器,实际上已经违背了双亲委派模型的一般性原则,但这也是无可奈何的事情。
Java中所有涉及SPI的加载动作基本上都采用这种方式,例如JNDI、JDBC、JCE、JAXB和JBI等。
摘自《深入理解java虚拟机》周志明
Tomcat破坏双亲委派机制的例子:
Tomcat是web容器,那么一个web容器可能需要部署多个应用程序。不同的应用程序可能会依赖同一个第三方类库的不同版本,但是不同版本的类库中某一个类的全路径名可能是一样的。
如果采用默认的双亲委派类加载机制,那么是无法加载多个相同的类。所以,Tomcat破坏双亲委派原则,提供隔离的机制,为每个web容器单独提供一个WebAppClassLoader加载器。
Tomcat的类加载机制:为了实现隔离性,优先加载 Web 应用自己定义的类,所以没有遵照双亲委派的约定,每一个应用自己的类加载器——WebAppClassLoader负责加载本身的目录下的class文件,加载不到时再交给CommonClassLoader加载,这和双亲委派刚好相反。
4. 双亲委派机制如何破坏
双亲委派机制破坏有两种方式:
- 线程上下文类加载器。使用ThreadContextClassLoader加载上级类加载器无法加载到的类(在上面JDBC创建数据库连接提到过)
- 自定义类加载器。下面来介绍这种方式破坏双亲委派机制
如果想自定义类加载器,就需要继承ClassLoader,并重写findClass,如果想破坏双亲委派的类加载顺序,需要重写loadClass。如下是一个自定义的类加载器,并重写了loadClass破坏双亲委派:
package co.dreampointer.test.classloader;
import java.io.*;
public class MyClassLoader extends ClassLoader {
public MyClassLoader(ClassLoader parent) {
super(parent);
}
@Override
public Class<?> loadClass(String name) throws ClassNotFoundException {
// 1.找到ExtClassLoader,并首先委派给它加载
// 为什么?
// 双亲委派的破坏只能发生在"AppClassLoader"及其以下的加载委派顺序,"ExtClassLoader"上面的双亲委派是不能破坏的!
// 因为任何类都是继承自超类"java.lang.Object",而加载一个类时,也会加载继承的类,如果该类中还引用了其他类,则按需加载,且类加载器都是加载当前类的类加载器。
ClassLoader classLoader = getSystemClassLoader();
while (classLoader.getParent() != null) {
classLoader = classLoader.getParent();
}
Class<?> clazz = null;
try {
clazz = classLoader.loadClass(name);
} catch (ClassNotFoundException ignored) {
}
if (clazz != null) {
return clazz;
}
// 2.自己加载
clazz = this.findClass(name);
if (clazz != null) {
return clazz;
}
// 3.自己加载不了,再调用父类loadClass,保持双亲委派模式
return super.loadClass(name);
}
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
// 1.获取class文件二进制字节数组
byte[] data;
try {
ByteArrayOutputStream baOS = new ByteArrayOutputStream();
// 加载class文件内容到字节数组
FileInputStream fIS = new FileInputStream("test/target/classes/co/dreampointer/test/classloader/MyTarget.class");
byte[] bytes = new byte[1024];
int len;
while ((len = fIS.read(bytes)) != -1) {
baOS.write(bytes, 0, len);
}
data = baOS.toByteArray();
} catch (IOException e) {
e.printStackTrace();
return null;
}
// 2.字节码数组加载到 JVM 的方法区,
// 并在 JVM 的堆区建立一个java.lang.Class对象的实例
// 用来封装 Java 类相关的数据和方法
return this.defineClass(name, data, 0, data.length);
}
}
测试程序:
package co.dreampointer.test.classloader;
public class Main {
public static void main(String[] args) throws ClassNotFoundException {
// 初始化MyClassLoader
// 将加载MyClassLoader类的类加载器设置为MyClassLoader的parent
MyClassLoader myClassLoader = new MyClassLoader(MyClassLoader.class.getClassLoader());
System.out.println("MyClassLoader的父类加载器:" + myClassLoader.getParent());
// 加载 MyTarget
Class<MyTarget> clazz = (Class<MyTarget>) myClassLoader.loadClass("co.dreampointer.test.classloader.MyTarget");
System.out.println("MyTarget的类加载器:" + clazz.getClassLoader());
}
}
//控制台打印
MyClassLoader的父类加载器:sun.misc.Launcher$AppClassLoader@18b4aac2
MyTarget的类加载器:co.dreampointer.test.classloader.MyClassLoader@5b1d2887
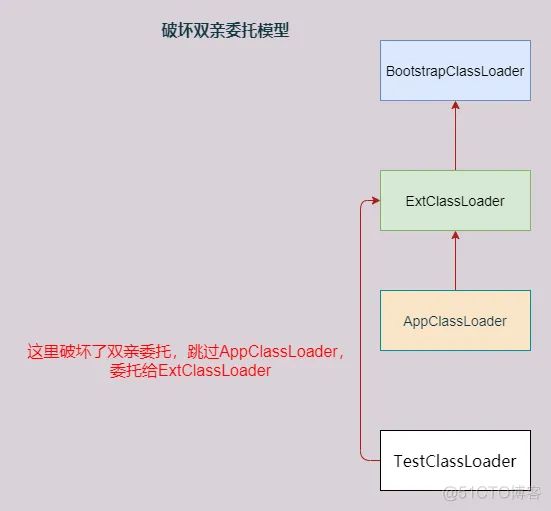
注意破坏双亲委派的位置:自定义类加载机制先委派给ExtClassLoader加载,ExtClassLoader再委派给BootstrapClassLoader,如果都加载不了,然后自定义类加载器MyClassLoader加载,MyClassLoader加载不了才交给AppClassLoader。为什么不能直接让自定义类加载器加载呢?
因为双亲委派的破坏只能发生在AppClassLoader及其以下的加载委派顺序,ExtClassLoader上面的双亲委派是不能破坏的!
根本原因:任何类都是继承自超类java.lang.Object,而加载一个类时,也会加载继承的类,如果该类中还引用了其他类,则按需加载,且类加载器都是加载当前类的类加载器。
如MyTarget类只隐式继承了Object,自定义类加载器MyClassLoader加载了MyTarget,也会加载Object。如果loadClass直接调用MyClassLoader的findClass会报错java.lang.SecurityException: Prohibited package name: java.lang。
为了安全,java是不允许除BootStrapClassLOader以外的类加载器加载官方java.目录下的类库的。在defineClass源码中,最终会调用native方法defineClass1获取Class对象,在这之前会检查类的全限定名name是否是java.开头。(如果想完全绕开java的类加载,需要自己实现defineClass,但是因为个人能力有限,没有深入研究defineClass的重写,并且一般情况也不会破坏ExtClassLoader以上的双亲委派,除非不用java了)
defineClass源码如下:
protected final Class<?> defineClass(String name, byte[] b, int off, int len,
ProtectionDomain protectionDomain)
throws ClassFormatError
{
protectionDomain = preDefineClass(name, protectionDomain);
String source = defineClassSourceLocation(protectionDomain);
Class<?> c = defineClass1(name, b, off, len, protectionDomain, source);
postDefineClass(c, protectionDomain);
return c;
}
private ProtectionDomain preDefineClass(String name,
ProtectionDomain pd)
{
if (!checkName(name))
throw new NoClassDefFoundError("IllegalName: " + name);
// Note: Checking logic in java.lang.invoke.MemberName.checkForTypeAlias
// relies on the fact that spoofing is impossible if a class has a name
// of the form "java.*"
if ((name != null) && name.startsWith("java.")) {
throw new SecurityException
("Prohibited package name: " +
name.substring(0, name.lastIndexOf('.')));
}
if (pd == null) {
pd = defaultDomain;
}
if (name != null) checkCerts(name, pd.getCodeSource());
return pd;
}
通过自定义类加载器破坏双亲委派的案例在日常开发中非常常见,比如Tomcat为了实现web应用间加载隔离,自定义了类加载器,每个Context代表一个web应用,都有一个webappClassLoader。再如热部署、热加载的实现都是需要自定义类加载器的。破坏的位置都是跳过AppClassLoader。
5. 总结
-
java 的类加载,就是获取.class文件的二进制字节码数组并加载到 JVM 的方法区,并在 JVM 的堆区建立一个用来封装 java 类相关的数据和方法的java.lang.Class对象实例。
-
java默认有的类加载器有三个,启动类加载器(BootstrapClassLoader),扩展类加载器(ExtClassLoader),应用程序类加载器(也叫系统类加载器)(AppClassLoader)。类加载器之间存在父子关系,这种关系不是继承关系,是组合关系。如果parent=null,则它的父级就是启动类加载器。启动类加载器无法被java程序直接引用。
-
双亲委派就是类加载器之间的层级关系,加载类的过程是一个递归调用的过程,首先一层一层向上委托父类加载器加载,直到到达最顶层启动类加载器,启动类加载器无法加载时,再一层一层向下委托给子类加载器加载。
-
双亲委派的目的主要是为了保证java官方的类库
\lib和扩展类库 \lib\ext的加载安全性,不会被开发者覆盖。 -
破坏双亲委派有两种方式:第一种,自定义类加载器,必须重写findClass和loadClass;第二种是通过线程上下文类加载器的传递性,让父类加载器中调用子类加载器的加载动作。
三、SPI机制
SPI 全称为 Service Provider Interface,是一种服务发现机制。SPI 的本质是将接口实现类的全限定名配置在文件中,并由服务加载器读取配置文件,加载实现类。这样可以在运行时,动态为接口替换实现类。正因此特性,我们可以很容易的通过 SPI 机制为我们的程序提供拓展功能。
1. JDK SPI
JDK中提供的SPI的功能,其核心类是java.util.ServiceLoader。作用就,可以通过类名获取在"META-INF/services/"下的多个配置实现文件。
例:javax.servlet.ServletContainerInitializer文件的内容是该文件名所代表的接口的实现类的全限定类名org.springframework.web.SpringServletContainerInitializer
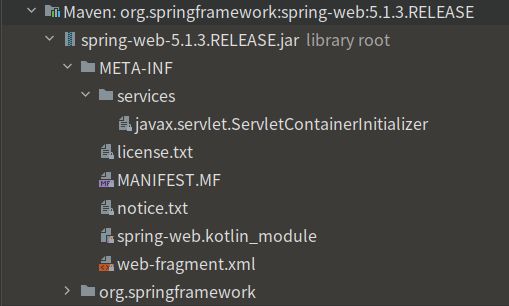
由于这个加载顺序(classpath)是由用户指定的,所以无论我们加载第一个还是最后一个,都有可能会导致加载不到用户自定义的那个配置。
所以这也是JDK SPI机制的一个劣势,无法确认具体加载哪一个实现,也无法加载某个指定的实现,仅靠ClassPath的顺序是一个非常不严谨的方式
2. Spring SPI
Spring 的 SPI 配置文件是一个固定的文件 META-INF/spring.factories,功能上和 JDK 的类似,每个接口可以有多个扩展实现,使用起来非常简单:
// 获取所有factories文件中配置的LoggingSystemFactory
List<LoggingSystemFactory>> factories = SpringFactoriesLoader.loadFactories(LoggingSystemFactory.class, classLoader);
下面是一段 SpringBoot 中 spring.factories 的配置
# Logging Systems
org.springframework.boot.logging.LoggingSystemFactory=\
org.springframework.boot.logging.logback.LogbackLoggingSystem.Factory,\
org.springframework.boot.logging.log4j2.Log4J2LoggingSystem.Factory,\
org.springframework.boot.logging.java.JavaLoggingSystem.Factory
# PropertySource Loaders
org.springframework.boot.env.PropertySourceLoader=\
org.springframework.boot.env.PropertiesPropertySourceLoader,\
org.springframework.boot.env.YamlPropertySourceLoader
# ConfigData Location Resolvers
org.springframework.boot.context.config.ConfigDataLocationResolver=\
org.springframework.boot.context.config.ConfigTreeConfigDataLocationResolver,\
org.springframework.boot.context.config.StandardConfigDataLocationResolver
Spring SPI 中,将所有的配置放到一个固定的文件中,省去了配置一大堆文件的麻烦。至于多个接口的扩展配置,是用一个文件好,还是每个单独一个文件好这个,这个问题就见仁见智了(个人喜欢 Spring 这种,干净利落)。
Spring的SPI 虽然属于spring-framework(core),但是目前主要用在SpringBoot中。和前面两种 SPI 机制一样,Spring 也是支持 ClassPath 中存在多个 spring.factories 文件的,加载时会按照 classpath 的顺序依次加载这些 spring.factories 文件,添加到一个 ArrayList 中。由于没有别名,所以也没有去重的概念,有多少就添加多少。
但由于 Spring 的 SPI 主要用在 Spring Boot 中,而 Spring Boot 中的 ClassLoader 会优先加载项目中的文件,而不是依赖包中的文件。所以如果在你的项目中定义个spring.factories文件,那么你项目中的文件会被第一个加载,得到的Factories中,项目中spring.factories里配置的那个实现类也会排在第一个
如果我们要扩展某个接口的话,只需要在你的项目(SpringBoot)里新建一个META-INF/spring.factories文件,添加你要的那个配置
比如我只想添加一个新的 LoggingSystemFactory 实现,那么我只需要新建一个META-INF/spring.factories文件,而不是完整的复制+修改:
org.springframework.boot.logging.LoggingSystemFactory=\
com.example.log4j2demo.Log4J2LoggingSystem.Factory
3. Dubbo SPI
Dubbo 就是通过 SPI 机制加载所有的组件。不过,Dubbo 并未使用 Java 原生的 SPI 机制,而是对其进行了增强,使其能够更好的满足需求。在 Dubbo 中,SPI 是一个非常重要的模块。基于 SPI,我们可以很容易的对 Dubbo 进行拓展。如果大家想要学习 Dubbo 的源码,SPI 机制务必弄懂。接下来,我们先来了解一下 Java SPI 与 Dubbo SPI 的用法,然后再来分析 Dubbo SPI 的源码。
Dubbo 中实现了一套新的 SPI 机制,功能更强大,也更复杂一些。相关逻辑被封装在了 ExtensionLoader 类中,通过 ExtensionLoader,我们可以加载指定的实现类。Dubbo SPI 所需的配置文件需放置在 META-INF/dubbo 路径下,配置内容如下(以下demo来自dubbo官方文档)。
optimusPrime = org.apache.spi.OptimusPrime
bumblebee = org.apache.spi.Bumblebee
与 Java SPI 实现类配置不同,Dubbo SPI 是通过键值对的方式进行配置,这样我们可以按需加载指定的实现类。另外在使用时还需要在接口上标注 @SPI 注解。下面来演示 Dubbo SPI 的用法:
@SPI
public interface Robot {
void sayHello();
}
public class OptimusPrime implements Robot {
@Override
public void sayHello() {
System.out.println("Hello, I am Optimus Prime.");
}
}
public class Bumblebee implements Robot {
@Override
public void sayHello() {
System.out.println("Hello, I am Bumblebee.");
}
}
public class DubboSPITest {
@Test
public void sayHello() throws Exception {
ExtensionLoader<Robot> extensionLoader = ExtensionLoader.getExtensionLoader(Robot.class);
Robot optimusPrime = extensionLoader.getExtension("optimusPrime");
optimusPrime.sayHello();
Robot bumblebee = extensionLoader.getExtension("bumblebee");
bumblebee.sayHello();
}
}
Dubbo SPI 和 JDK SPI 最大的区别就在于支持“别名”,可以通过某个扩展点的别名来获取固定的扩展点。就像上面的例子中,我可以获取 Robot 多个 SPI 实现中别名为“optimusPrime”的实现,也可以获取别名为“bumblebee”的实现,这个功能非常有用!
通过 @SPI 注解的 value 属性,还可以默认一个“别名”的实现。比如在Dubbo 中,默认的是Dubbo 私有协议:dubbo protocol - dubbo://
**
来看看Dubbo中协议的接口:
@SPI("dubbo")
public interface Protocol {
// ...
}
在 Protocol 接口上,增加了一个 @SPI 注解,而注解的 value 值为 dubbo ,通过 SPI 获取实现时就会获取 Protocol SPI 配置中别名为dubbo的那个实现,com.alibaba.dubbo.rpc.Protocol文件如下:
filter=com.alibaba.dubbo.rpc.protocol.ProtocolFilterWrapper
listener=com.alibaba.dubbo.rpc.protocol.ProtocolListenerWrapper
mock=com.alibaba.dubbo.rpc.support.MockProtocol
dubbo=com.alibaba.dubbo.rpc.protocol.dubbo.DubboProtocol
injvm=com.alibaba.dubbo.rpc.protocol.injvm.InjvmProtocol
rmi=com.alibaba.dubbo.rpc.protocol.rmi.RmiProtocol
hessian=com.alibaba.dubbo.rpc.protocol.hessian.HessianProtocol
com.alibaba.dubbo.rpc.protocol.http.HttpProtocol
com.alibaba.dubbo.rpc.protocol.webservice.WebServiceProtocol
thrift=com.alibaba.dubbo.rpc.protocol.thrift.ThriftProtocol
memcached=com.alibaba.dubbo.rpc.protocol.memcached.MemcachedProtocol
redis=com.alibaba.dubbo.rpc.protocol.redis.RedisProtocol
rest=com.alibaba.dubbo.rpc.protocol.rest.RestProtocol
registry=com.alibaba.dubbo.registry.integration.RegistryProtocol
qos=com.alibaba.dubbo.qos.protocol.QosProtocolWrapper
然后只需要通过getDefaultExtension,就可以获取到 @SPI 注解上value对应的那个扩展实现了
Protocol protocol = ExtensionLoader.getExtensionLoader(Protocol.class).getDefaultExtension();
//protocol: DubboProtocol
还有一个 Adaptive 的机制,虽然非常灵活,但……用法并不是很“优雅”,这里就不介绍了
Dubbo 的 SPI 中还有一个“加载优先级”,优先加载内置(internal)的,然后加载外部的(external),按优先级顺序加载,如果遇到重复就跳过不会加载了。
所以如果想靠classpath加载顺序去覆盖内置的扩展,也是个不太理智的做法,原因同上 - 加载顺序不严谨
4. 对比
三种 SPI 机制对比之下,JDK 内置的机制是最弱鸡的,但是由于是 JDK 内置,所以还是有一定应用场景,毕竟不用额外的依赖;Dubbo 的功能最丰富,但机制有点复杂,而且只能配合 Dubbo 使用,不能完全算是一个独立的模块;Spring 的功能和JDK的相差无几,最大的区别是所有扩展点写在一个 spring.factories 文件中,也算是一个改进,并且 IDEA 完美支持语法提示。
| JDK SPI | DUBBO SPI | Spring SPI | |
|---|---|---|---|
| 文件方式 | 每个扩展点单独一个文件 | 每个扩展点单独一个文件 | 所有的扩展点在一个文件 |
| 获取某个固定的实现 | 不支持,只能按顺序获取所有实现 | 有“别名”的概念,可以通过名称获取扩展点的某个固定实现,配合Dubbo SPI的注解很方便 | 不支持,只能按顺序获取所有实现。但由于Spring Boot ClassLoader会优先加载用户代码中的文件,所以可以保证用户自定义的spring.factoires文件在第一个,通过获取第一个factory的方式就可以固定获取自定义的扩展 |
| 其他 | 无 | 支持Dubbo内部的依赖注入,通过目录来区分Dubbo 内置SPI和外部SPI,优先加载内部,保证内部的优先级最高 | 无 |