第三课 ceph基础学习-CrushMap和RDB高级功能
文章目录
- 第三课 ceph基础学习-CrushMap和RDB高级功能
-
- 第一节 CrushMap调整
-
- 1.1 CrushMap简介
- 1.2 CrushMap实验拓扑图
- 1.3 CrushMap手动编辑
- 1.4 CrushMap命令行编辑
- 第二节 RDB高级功能
-
- 2.1 RBD回收机制
- 2.2 RBD镜像制作快照和恢复
- 2.3 RBD镜像克隆
- 2.4 RBD备份
- 2.5 RBD数据恢复
第一节 CrushMap调整
1.1 CrushMap简介
- CRUSH 算法通过计算数据存储位置来确定如何存储和检索。 CRUSH 授权 Ceph 客户端直接连接 OSD ,而非通过一个中央服务器或代理。数据存储、检索算法的使用,使 Ceph 避免了单点故障、性能瓶颈、和伸缩的物理限制。
- 通过CRUSH的算法把数据落在不同的OSD上。把一组OSD组合起来,CRUSH决定数据怎么分布。
- ceph提供很多种的bucket,最小的节点是osd。
osd (or device)
host
chassis
rack
row
pdu
pod
room
datacenter
zone
region
root
- 通过命令行看
ceph osd crush tree
ceph osd tree
ceph osd crush dump
{
"devices": [
{
"id": 0,
"name": "osd.0",
"class": "hdd"
},
{
"id": 1,
"name": "osd.1",
"class": "hdd"
},
{
"id": 2,
"name": "osd.2",
"class": "hdd"
}
],
"types": [
{
"type_id": 0,
"name": "osd"
},
{
"type_id": 1,
"name": "host"
},
{
"type_id": 2,
"name": "chassis"
},
{
"type_id": 3,
"name": "rack"
},
{
"type_id": 4,
"name": "row"
},
{
"type_id": 5,
"name": "pdu"
},
{
"type_id": 6,
"name": "pod"
},
{
"type_id": 7,
"name": "room"
},
{
"type_id": 8,
"name": "datacenter"
},
{
"type_id": 9,
"name": "zone"
},
{
"type_id": 10,
"name": "region"
},
{
"type_id": 11,
"name": "root"
}
],
"buckets": [
{
"id": -1,
"name": "default",
"type_id": 11,
"type_name": "root",
"weight": 1926,
"alg": "straw2",
"hash": "rjenkins1",
"items": [
{
"id": -3,
"weight": 642,
"pos": 0
},
{
"id": -5,
"weight": 642,
"pos": 1
},
{
"id": -7,
"weight": 642,
"pos": 2
}
]
},
{
"id": -2,
"name": "default~hdd",
"type_id": 11,
"type_name": "root",
"weight": 1926,
"alg": "straw2",
"hash": "rjenkins1",
"items": [
{
"id": -4,
"weight": 642,
"pos": 0
},
{
"id": -6,
"weight": 642,
"pos": 1
},
{
"id": -8,
"weight": 642,
"pos": 2
}
]
},
{
"id": -3,
"name": "ceph-01",
"type_id": 1,
"type_name": "host",
"weight": 642,
"alg": "straw2",
"hash": "rjenkins1",
"items": [
{
"id": 0,
"weight": 642,
"pos": 0
}
]
},
{
"id": -4,
"name": "ceph-01~hdd",
"type_id": 1,
"type_name": "host",
"weight": 642,
"alg": "straw2",
"hash": "rjenkins1",
"items": [
{
"id": 0,
"weight": 642,
"pos": 0
}
]
},
{
"id": -5,
"name": "ceph-02",
"type_id": 1,
"type_name": "host",
"weight": 642,
"alg": "straw2",
"hash": "rjenkins1",
"items": [
{
"id": 1,
"weight": 642,
"pos": 0
}
]
},
{
"id": -6,
"name": "ceph-02~hdd",
"type_id": 1,
"type_name": "host",
"weight": 642,
"alg": "straw2",
"hash": "rjenkins1",
"items": [
{
"id": 1,
"weight": 642,
"pos": 0
}
]
},
{
"id": -7,
"name": "ceph-03",
"type_id": 1,
"type_name": "host",
"weight": 642,
"alg": "straw2",
"hash": "rjenkins1",
"items": [
{
"id": 2,
"weight": 642,
"pos": 0
}
]
},
{
"id": -8,
"name": "ceph-03~hdd",
"type_id": 1,
"type_name": "host",
"weight": 642,
"alg": "straw2",
"hash": "rjenkins1",
"items": [
{
"id": 2,
"weight": 642,
"pos": 0
}
]
}
],
"rules": [
{
"rule_id": 0,
"rule_name": "replicated_rule",
"ruleset": 0,
"type": 1,
"min_size": 1,
"max_size": 10,
"steps": [
{
"op": "take",
"item": -1,
"item_name": "default"
},
{
"op": "chooseleaf_firstn",
"num": 0,
"type": "host"
},
{
"op": "emit"
}
]
}
],
"tunables": {
"choose_local_tries": 0,
"choose_local_fallback_tries": 0,
"choose_total_tries": 50,
"chooseleaf_descend_once": 1,
"chooseleaf_vary_r": 1,
"chooseleaf_stable": 1,
"straw_calc_version": 1,
"allowed_bucket_algs": 54,
"profile": "jewel",
"optimal_tunables": 1,
"legacy_tunables": 0,
"minimum_required_version": "jewel",
"require_feature_tunables": 1,
"require_feature_tunables2": 1,
"has_v2_rules": 0,
"require_feature_tunables3": 1,
"has_v3_rules": 0,
"has_v4_buckets": 1,
"require_feature_tunables5": 1,
"has_v5_rules": 0
},
"choose_args": {}
}
ceph osd crush rule ls
ceph osd pool get abcdocker crush_rule
1.2 CrushMap实验拓扑图

- 需求: 机器上有两种盘一种普通的盘,一种ssd的盘。按照CRUSH MAP规则把两种盘分隔开来。pool通过不同的规则落到不同的种类的盘上。
- 实验前注意事项。
- 手动编辑前,一定要做好备份。
- 初始集群时就要先规划好,若是后期改动会有大量的pg不同挪动。
- 调整crush map有些隐患,比如我重启osd服务 需要先调整配置osd crush update on start = false 这个非常重要。
systemctl restart ceph-osd
systemctl restart ceph-osd
[osd]
osd crush update on start = false
ceph-deploy config push node-1 node-2 node-3
systemctl restart ceph-osd.target
ceph osd tree
ceph osd crush move osd.3 host=node-1-ssd root=ssd
systemctl restart ceph-osd@3
systemctl reset-failed [email protected]
ceph daemon /var/run/ceph/ceph-osd.3.asok config show |grep update
1.3 CrushMap手动编辑
ceph osd getcrushmap -o crushmap.bin
crushtool -d crushmap.bin -o crushmap.txt
file crushmap.txt
cp crushmap.txt crushmap-new.txt
vi crushmap-new.txt
device 0 osd.0 class hdd
device 1 osd.1 class hdd
device 2 osd.2 class hdd
device 3 osd.3 class ssd
device 4 osd.4 class ssd
device 5 osd.5 class ssd
host node-1 {
id -3
id -4 class ssd
alg straw2
hash 0
item osd.0 weight 0.049
item osd.3 weight 0.049
}
host node-1-ssd {
alg straw2
hash 0
item osd.0 weight 0.049
item osd.3 weight 0.049
}
root default {
id -1
id -2 class hdd
alg straw2
hash 0
item node-1 weight 0.098
item node-2 weight 0.098
item node-3 weight 0.098
}
root default {
id -1
id -2 class hdd
alg straw2
hash 0
item node-1 weight 0.049
item node-2 weight 0.049
item node-3 weight 0.049
}
root ssd {
alg straw2
hash 0
item node-1-ssd weight 0.049
item node-2-ssd weight 0.049
item node-3-ssd weight 0.049
}
rule replicated_rule {
id 0
type replicatedmin_size 1
max_size 10
step take default
step chooseleaf firstn 0 type host
step emit
}
rule demo_rule {
id 10
type replicatedmin_size 1
max_size 10
step take ssd
step chooseleaf firstn 0 type host
step emit
}
crushtool -c crushmap-new.txt -o crushmap-new.bin
ceph osd tree
ceph osd setcrushmap -i crushmap-new.bin
ceph osd tree
ceph osd lspools
ceph osd pool get abcdocker crush_rule
ceph osd pool set abcdocker crush_rule demo_rule
ceph osd pool get abcdocker crush_rule
rbd create abcdocker/crush-demo.img --size 1G
ceph osd map abcdocker crush-demo.img
ceph osd setcurshmap -i crushmap.bin
ceph osd pool set abcdocker crush_rule replicated_rule
ceph osd setcurshmap -i crushmap.bin
1.4 CrushMap命令行编辑
ceph osd crush add-bucket ssd root
ceph osd crush add-bucket node-1-ssd host
ceph osd crush add-bucket node-2-ssd host
ceph osd crush add-bucket node-3-ssd host
ceph osd crush move node-1-ssd root=ssd
ceph osd crush move node-2-ssd root=ssd
ceph osd crush move node-3-ssd root=ssd
ceph osd crush move osd.3 host=node-1-ssd root=ssd
ceph osd crush move osd.4 host=node-2-ssd root=ssd
ceph osd crush move osd.5 host=node-3-ssd root=ssd
ceph osd tree
ceph osd crush rule create-replicated ssd-demo ssd host ssd
ceph osd pool set ceph-demo crush_rule ssd-demo
第二节 RDB高级功能
2.1 RBD回收机制
- ceph RBD默认提供回收站机制trash,也就是我们可以把块数据放在回收站,在回收站中保持一定的存储周期,当我们后期还需要使用的时候可以在回收站在拿回来。
- 同样,在公有云也有硬盘的回收站,作用和RBD回收站类似,当我们后不确定是否后期还会使用,回收站会为我们保留一定时间的周期
- 到期7天后仍未续费的云硬盘,会在回收站中保留7天,这期间您可以续费进行恢复。7天后,这些云硬盘会被彻底释放,不可恢复。
- 回收站有两个好处
- 可以有效的防止误删除操作 (正常情况下数据就会销毁掉了,但是有了回收站,数据是存放在回收站中)
- 还有一种情况多发生的云存储中,例如我们的服务器忘记续费,过期后默认情况下是直接被释放了,但是有了回收站,数据就会在回收站在为我们保留一段时间
ceph osd lspools
rbd -p abcdocker ls
rbd create abcdocker/ceph-trash.img --size 1G
rbd info abcdocker/ceph-trash.img
rbd -p abcdocker ls
rbd rm abcdocker/ceph-trash.img
rbd -p abcdocker ls
rbd create abcdocker/ceph-trash.img --size 1G
rbd trash move abcdocker/ceph-trash.img --expires-at 20220922
rbd -p abcdocker ls
rbd trash -p abcdocker ls
rbd trash restore -p abcdocker 197589c05957a
rbd trash -p abcdocker ls
rbd -p abcdocker ls
2.2 RBD镜像制作快照和恢复
- 和云硬盘一样,RBD也是支持快照的功能,对某个时刻的RBD文件进行保留生成快照。
- RBD是块存储基于文件系统上的,我们在生成快照时需要确保文件系统正常。否则生成的快照也出现损坏
- 云硬盘也属于块存储,和RBD一样支持快照。 (同时,公有云还可以定期为云硬盘做快照)
- 我们使用之前创建的rbd文件,将rbd挂载到本地的文件系统中,写入文件并做快照
rbd -p abcdocker ls
rbd device map abcdocker/ceph-trash.img
mkfs.ext4 /dev/rbd0
mount /dev/rbd0 /mnt/
echo "i4t.com" >/mnt/abcdocker.txt
cat /mnt/abcdocker.txt
i4t.com
df -h
rbd device ls
rbd device unmap /dev/rbd0
rbd device ls
rbd -p abcdocker ls
rbd snap create abcdocker/ceph-trash.img@snap_test_2022-09-21
rbd snap ls abcdocker/ceph-trash.img
- BD快照数据恢复,当我们做好备份后,后续有需求需要回滚。 可以通过下面的命令进行回滚操作。将rbd文件恢复到之前创建好快照的位置
rm /mnt/abcdocker.txt
ls /mnt/
rbd snap rollback abcdocker/ceph-trash.img@snap_test_2022-09-21
umount /mnt/
mount /dev/rbd0 /mnt/
ls /mnt/
cat /mnt/abcdocker.txt
i4t.com
rbd snap remove abcdocker/ceph-trash.img@snap_test_2022-09-21
2.3 RBD镜像克隆
- Ceph支持为块设备快照创建许多写时复制COW克隆。快照分层使Ceph块设备客户端能够非常快速的创建映射。例如,我们创建一个块设备镜像,其中写入一个Linux;然后对镜像进行快照、保护快照并创建写时克隆。快照是只读的,写入将写入到新的位置–进行快速克隆
- 完整克隆
- 快速克隆 (快速克隆使用的就是写时复制)
- 每个克隆镜像子级存储对父级镜像为引用作用,子级会读取父级别的数据
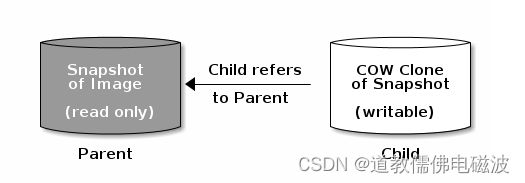
- parent代表镜像父级 Child 代表克隆的子级
- COW克隆和Ceph块设备完全相同,可以进行读取、写入和调整镜像大小。克隆镜像没用特殊限制。但是,写时复制克隆是指快照,因此必须在克隆快照之前对其保护
- Ceph目前只支持format 2镜像的克隆,内核rbd create --image-format 2还不支持。rbd因此必须使用QEMU/KVM或者librbd直接访问版本中的克隆
- RBD分层概念。Ceph块设备分层是一个简单的过程,首先我们必须创建镜像的快照,并且需要保护快照,保护完成就可以开始克隆快照
- 克隆的镜像有对父快照的引用,包括池ID、镜像ID和快照ID。
- 镜像模板: 块设备分层的一个常见用例是创建一个主镜像和一个用做克隆模板的快照。
- 扩展模板: 提供比基础镜像更多的信息,例如用户可以克隆镜像并按照其他软件,然后对扩展镜像进行快照,该扩展镜像本身可以更新就像基本镜像一样
- 模板池: 使用块设备分层的一个方法是创建一个pool,其中包含充当模板的主镜像以及这些模板的快照。然后可以将只读权限扩展到用户,以便可以直接克隆快照,但是无法在池中写入和执行
- 镜像迁移/恢复: 使用块设备分层的一个方法是将数据从一个pool迁移或者恢复到另一个pool中
- RBD快照保护, 如果用户不小心删除了父快照,所有的克隆都会终断。为了防止克隆的镜像丢失,必须保护快照才可以进行克隆
rbd create abcdocker/ceph-temp.img --size 10G
rbd -p abcdocker ls
rbd snap create abcdocker/ceph-temp.img@temp
rbd snap ls abcdocker/ceph-temp.img
rbd snap protect abcdocker/ceph-temp.img@temp
rbd snap rm abcdocker/ceph-temp.img@temp
rbd snap unprotect abcdocker/ceph-temp.img@temp
- RBD克隆快照这会我们的父镜像已经制作好了,开始克隆子镜像, 克隆可以选择pool,可以和父镜像不在一个pool中
rbd clone abcdocker/ceph-temp.img@temp abcdocker/ceph-test-01.img
rbd clone abcdocker/ceph-temp.img@temp abcdocker/ceph-test-02.img
rbd clone abcdocker/ceph-temp.img@temp abcdocker/ceph-test-03.img
rbd -p abcdocker ls
rbd -p abcdocker ls
rbd device map abcdocker/ceph-test-01.img
mkdir /mnnt
mkfs.ext4 /dev/rbd1
mount /dev/rbd1 /mnnt
ls /mnnt/
- RBD取消父级, 使用flatten取消依赖关系,此时我们在删除temp模板镜像,下面的ceph-test-03就不受影响
rbd children abcdocker/ceph-temp.img@temp
rbd flatten abcdocker/ceph-test-03.img
rbd children abcdocker/ceph-temp.img@temp
rdb info abcdocker/ceph-test-03.img
2.4 RBD备份
- 对于增量备份,常用于ceph异地备份,或者kvm、OpenStack相关备份。可以减少空间占用大小
- 可以写成定时脚本,定时基于全备添加增量的备份,
- 增量备份使用的参数为
export-diff
rbd device map abcdocker/ceph-bak.img
mount /dev/rbd1 /mnnt
cd /mnnt/
ls
- 接下来为rbd文件添加全量备份
rbd snap create abcdocker/ceph-bak.img@all_bak_2022-09-22
rbd snap ls abcdocker/ceph-bak.img
rbd export abcdocker/ceph-bak.img@all_bak_2022-09-22 /root/ceph-bak_all_bak_2022-09-22.img
ll /root/ceph-bak_all_bak_2022-09-22.img -h
- 全量备份添加完毕后,我们在创建新数据,充当增量备份
for i in `seq 200`;do touch $i.log;done
rbd snap ls abcdocker/ceph-bak.img
rbd snap create abcdocker/ceph-bak.img@new_v1
rbd snap ls abcdocker/ceph-bak.img
rbd export-diff abcdocker/ceph-bak.img@new_v1 /root/ceph_new_v1.img
ls -lh /root/ceph_new_v1.img
2.5 RBD数据恢复
- 前面已经说了RBD的增量备份,增量备份完成我们就需要考虑如何进行增量恢复数据
- 首先RBD增量数据恢复需要安装顺序进行恢复,即v1,v2,v3,v4 按照顺序进行恢复
- 即如果全量数据有影响,首先恢复全量数据
- 在恢复增量v1、增量v2、增量v3 以此类推
- 数据恢复可以恢复新的镜像中,也可以在原有的镜像恢复
- RBD增量备份 生成的.log文件删除,然后使用import-diff命令实现增量恢复, 在全量数据没有受影响的情况下,只删除增量备份前的数据进行恢复
rm -rf *.log
- 执行增量恢复
rbd -p abcdocker ls
rbd snap ls abcdocker/ceph-bak.img
rbd snap rm abcdocker/ceph-bak.img@new_v1
rbd snap ls abcdocker/ceph-bak.img
rbd import-diff /root/ceph_new_v1.img abcdocker/ceph-bak.img
rbd snap ls abcdocker/ceph-bak.img
umount -lf /mnnt/
mount /dev/rbd1 /mnnt
cd /mnnt/
- 下面说一下如何恢复到新的镜像名称中,目前我们将ceph-bak.img镜像做了全备和增量备份,我们现在需要将这块镜像恢复到一个名为ceph-bak-new.img中
rbd snap ls abcdocker/ceph-bak.img
ll -h /root/ceph-bak_all_bak_2022-09-22.img
ll -h /root/ceph_new_v1.img
rbd import /root/ceph-bak_all_bak_2022-09-22.img abcdocker/ceph-bak-new.img
rbd import-diff /root/ceph_new_v1.img abcdocker/ceph-bak-new.img
rbd snap ls abcdocker/ceph-bak-new.img
rbd device map abcdocker/ceph-bak-new.img
mkdir /new
mount /dev/rbd2 /new
df -h
rbd device ls