ceph学习(2)——crush map 故障域划分
crush map是ceph集群最重要的组成部分之一,crush算法实现了ceph集群的去中心化,这也是它实现分布式的关键,简单来说,crush算法决定了客户端的数据写到哪,从哪读取客户需要的数据。
接上篇ceph学习(1)——手动部署ceph分布式存储集群(使用本地源离线安装)_ceph安装_jiangxi_的博客-CSDN博客
一.环境准备
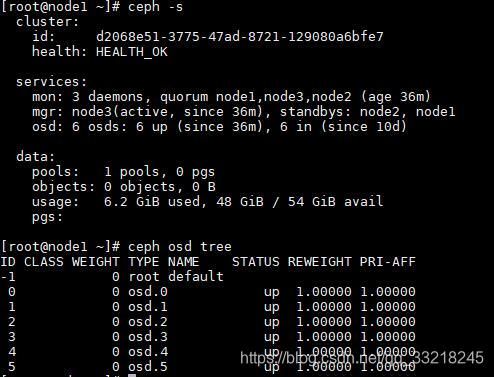
1.三台centos 7.5(1804)服务器(node1,node2,node3)
3个mon,6个osd(三个hhd盘,三个ssd盘),osd均未指定crush
osd分布:
node1:osd.0(hhd),osd.3(ssd)
node2:osd.1(hhd),osd.4(ssd)
node3:osd.2(hhd),osd.5(ssd)
二.划分故障域
1.目标
希望创建2个存储池,一个全hhd作为后端存储,一个全ssd作为后端存储池的高速缓存池,并且当有个别服务器宕机时,依然不影响数据的读写。
2.规划
创建两个root(hhd,ssd),6个host(node1_hhd,node2_hhd,node3_hhd,node1_ssd,node2_ssd,node3_ssd),最后将每个服务器对应的osd加入到crush中。
3.创建crush
ceph osd crush add-bucket hhd root
ceph osd crush add-bucket ssd root
ceph osd crush add-bucket node1_hhd host
ceph osd crush add-bucket node2_hhd host
ceph osd crush add-bucket node3_hhd host
ceph osd crush add-bucket node1_ssd host
ceph osd crush add-bucket node2_ssd host
ceph osd crush add-bucket node3_ssd host4.移动crush
ceph osd crush move node1_hhd root=hhd
ceph osd crush move node2_hhd root=hhd
ceph osd crush move node3_hhd root=hhd
ceph osd crush move node1_ssd root=ssd
ceph osd crush move node2_ssd root=ssd
ceph osd crush move node3_ssd root=ssd5.创建并移动osd crush
这里需要计算osd权重,权重计算公式(权重=osd大小%1T),如果osd大小为500G,权重就是0.50000,osd大小为2T,权重就是2.00000,我这里为了方便将osd权重全设为1.0000.
ceph osd crush create-or-move osd.0 1.00000 host=node1_hhd
ceph osd crush create-or-move osd.1 1.00000 host=node2_hhd
ceph osd crush create-or-move osd.2 1.00000 host=node3_hhd
ceph osd crush create-or-move osd.3 1.00000 host=node1_ssd
ceph osd crush create-or-move osd.4 1.00000 host=node2_ssd
ceph osd crush create-or-move osd.5 1.00000 host=node3_ssd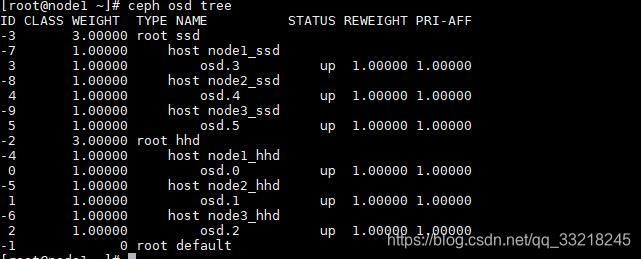
现在crush划分完毕,但是到这里还不能够使用,如果要创建存储池,需要给存储池创建rule规则。
6.创建rule
创建一个简单rule,参数说明:
hhd_rule:rule名称
hhd:crush名称
host:rule类型,对应不同的故障级别(root,rack,host)
firstn:副本存储池选firstn,纠删码存储池选indep
ceph osd crush rule create-simple hhd_rule hhd host firstn
ceph osd crush rule create-simple ssd_rule ssd host firstn三.创建存储池
1.创建两个存储池
ceph osd pool create hhd 64 64
ceph osd pool create ssd 64 642.给存储池指定rule
ceph osd pool set hhd crush_rule hhd_rule
ceph osd pool set ssd crush_rule ssd_rule![]()
现在存储池故障域已经划分完毕,两个存储池不会相互影响,完成故障隔离。