Leetcode Hot 100题 题解
(Todo代表有思路知道怎么做却还没实际去做)
(myself代表自己做出来的题目)
(lookAnswer代表看答案后知道怎么做)
目录
(Todo代表有思路知道怎么做却还没实际去做)
(myself代表自己做出来的题目)
考试后得到的总结
1.两数之和
2. 两数相加
3.无重复字符的最长子串
4.寻找两个有序数组的中位数
5.最长回文子串
10.正则表达式匹配
11.盛最多水的容器
15.三数之和
17.电话号码的字母组合
19.删除链表的倒数第n个结点
20.有效的括号
21. 合并两个有序链表
22.括号生成
23. 合并K个升序链表(todo)
24.两两交换链表中的结点(myself)
31.下一个排列
34.在排序数组查找元素的第一个位置和最后一个位置(todo)
39.组合总和
42.接雨水(myself)
46.全排列(todo)
48.旋转图像(todo)
49.字母异位词分组(lookAnswer)
56.合并区间
62.不同路径
64.最小路径和
70.爬楼梯
72.编辑距离
75.颜色分类
76.最小覆盖子串
78.子集
79.单词搜索
84.柱状图中最大的矩形
85.最大矩形
94.二叉树的中序遍历
121.买卖股票的最佳时机
141.环形链表
142.环形链表II
146.LRU缓存(todo)
152.乘积最大子数组(lookAnswer)
155.最小栈
198.打家劫舍
200.岛屿数量
207.课程表
215.数组中的第k大元素
221.最大正方形
234.回文链表
236. 二叉树的最近公共祖先
253.会议室II
279.完全平方数
283.移动零
287.寻找重复数字
297.二叉树的序列化与反序列化
300.最长递增子序列
301.删除无效的括号(lookAnswer&&todo)
309.最佳买卖股票时机含冷冻期
347.前 K 个高频元素(todo)
399.除法求值(todo)
406. 根据身高重建队列(lookAnswer)
416.分割等和子集
438.找到字符串中所有字母异位词
448.找到所有数组中消失的数字
461.汉明距离
494.目标和
538.把二叉树转化为累加树
543.二叉树的直径
739.每日温度
617.合并二叉树
621.任务调度器
647.回文子串
考试后得到的总结
大概有三次了,考试时都是栽在这种二维矩阵,然后进行dfs的题目上的。
注意!做这题时以后不要使用x和y下标了,因为会产生歧义!对于x和y来说,假如使用的是什么
arr[x][y],那么在这里,x作为第一个元素,代表的是行,而y代表的是列,是横坐标。
那在坐标系中,x代表的是横坐标,y代表的是纵坐标!
那这样子就会容易产生判断失误!因此还是使用i和j好一点
arr[i][j]很明显就知道i代表行,而j代表列!!
- 对于最小值使用INT_MIN;来进行初始化
- 如果数据过长则使用unsighed long long
- 当出现段错误时,可以通过输出来判断错误出在哪一行。

- 有一些题如果只通过部分样例,而又看不到样例时,多给自己想一些特别的样例自己试一下!
1.两数之和
原来以为和剑指offer上的题一样,后面发现不是,本题不是有序数组所以不能用双指针和滑动窗口。
普通的暴力解法就是一个双循环,对于每个x,遍历数组查看是否有对应的target-x。
但是由于有一点,例如1 4 5 7 9 2 1
target为8的情况下,下标为1的1,和下标为4的7可以组成一个,但是当遍历到下标为4的7时,不能再和第一个1组成一个。原因在于题目的设定:

并且只需要遍历到倒数第二个数即可,最后一个数已经没有可以匹配的了
所以代码如下:
class Solution {
public:
vector twoSum(vector& nums, int target) {
int n = nums.size();
for (int i = 0; i < n-1; ++i) {
for (int j = i + 1; j < n; ++j) {
if (nums[i] + nums[j] == target) {
return {i, j};
}
}
}
return {};
}
};
方法二:哈希表

class Solution {
public:
vector twoSum(vector& nums, int target) {
unordered_map hashtable;
for (int i = 0; i < nums.size(); ++i) {
auto it = hashtable.find(target - nums[i]);
if (it != hashtable.end()) {
return {it->second, i};
}
hashtable[nums[i]] = i;
}
return {};
}
};
2. 两数相加(本题过程较复杂麻烦,有许多细节点)
一开始比较笨,看到这个题目是逆序的来相加的,就想着那我也自己动手把它逆序一下好了,但是后来发现不用这样,普通的加法是从低位加到高位,也就是从右向左,本题既然逆序,那我们就直接逆序就好了,直接从左往右走,然后相加,正好这也符合链表的顺序。
然后注意,本题还需要那种头节点和一个尾节点,头节点一直是头部,尾节点则用来不断的延长链表。
本题会让l1和l2不断往后走,结果会存放在一个新的节点
最终代码如下,看似思路简单,
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {
int carry=0;//代表进位
ListNode* head=nullptr,*tail=nullptr;
while(l1||l2){
int num1=l1?l1->val:0;//l1不为空的时候才有值,否则为0
int num2=l2?l2->val:0;
int sum=num1+num2+carry;
if(!head){//处理首个节点,不将其单独在前面处理,而是放在循环做一个特殊处理
head=tail=new ListNode(sum%10);
//tail=head;
}
else{
tail->next=new ListNode(sum%10);//在尾部创建新节点时可以直接使用这种方法,其实是创建了一个匿名节点
tail=tail->next;//尾节点自己也要后移
}
carry=sum/10;
if(l1)l1=l1->next;//l1后移前不能忘了判断是否非空
if(l2)l2=l2->next;
}
//最终还有一个特殊处理,如果前面加出了一个进位,那最后还需要补上那个进位
if(carry>0)tail->next=new ListNode(carry);
return head;
}
};
可以发现本题错了很多地方,本题有很多细节点需要注意!
此处本人实际上手写的时候犯了几个错误:
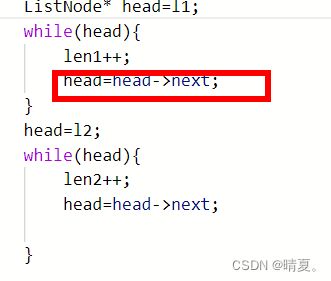
这个head->next往后移一位忘记移了
还有初始化结点,这样子并不能算初始化:
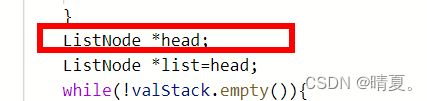
这样子才算初始化了:
![]()
以及还有此处,报了一个member access within null misaligned address的错误
原因在于
3.无重复字符的最长子串
暴力解法:

使用滑动窗口时候,过程如下:

如上图,此时将遇到第二个w,那我们需要将滑动窗口收缩,收缩到不包含第一个w:

然后就一直往右移动窗口:

对于几个特殊情况也需要进行考虑:

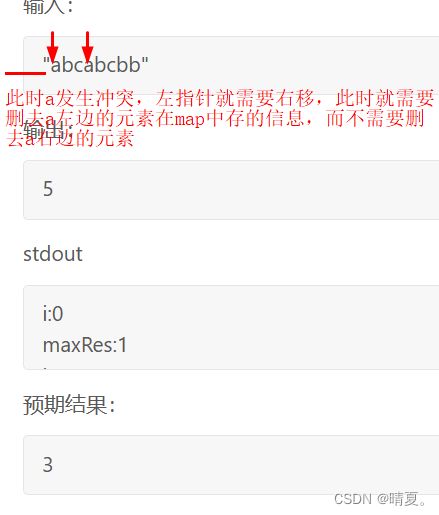
对于滑动窗口的剔除容易漏一点,那就是:

例如,当遇到第二个m的时候,第一个t也应该需要在集合中剔除才对。
思路就是维护一个map,如果没有map中没有则直接添加,如果map中有,则将左指针移动到相同的位置+1,并且删除该位置前面储存的map的值。(但不是全部删除,是只删除前面那一部分
并且还要设定新的该位置的值,然后别忘记让right++。
class Solution {
public:
int lengthOfLongestSubstring(string s) {
int left=0,right=0;
int maxRes=0;
map numAppearIndex;
for(int i=0;i 4.寻找两个有序数组的中位数
5.最长回文子串
暴力法:
枚举所有的子串

判断回文的方法:
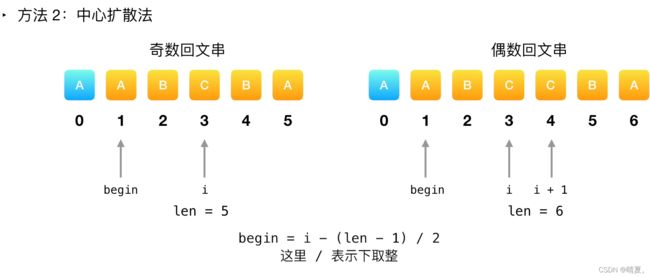
方法二:中心扩散法

那么我们需要遍历一遍数组,对于每个下标,我们对其判断其是否满足从中心扩散能产生回文子串,这样只需要O(n)的时间复杂度。判断是否是回文串再需要O(n)的时间复杂度,因此总的时间复杂度为O(n²)
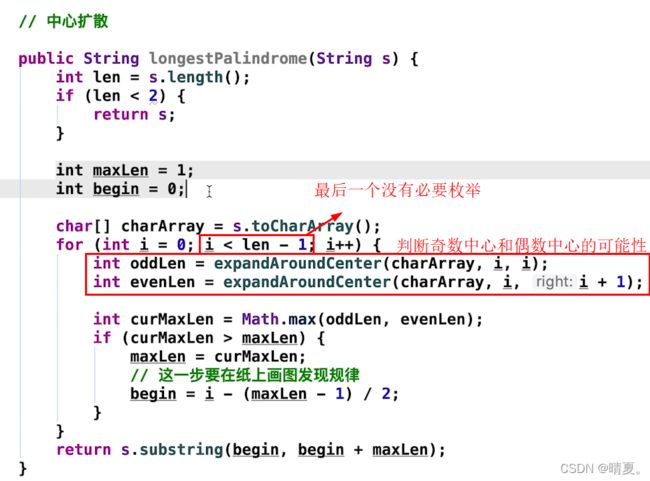
此处数学begin开始位置的计算方法可能比较麻烦,如下:
也可以在判断回文的函数里直接返回,这样最简单
class Solution {
public:
string str;
string longestPalindrome(string s) {
str=s;
if(str.size()==1)return s;
int maxLen=0;
string res;
for(int i=0;imaxLen){
res=huiwen;
maxLen=len;
}
len=0;
huiwen=centreSpread(i,i+1,len);
if(len>maxLen){
maxLen=len;
res=huiwen;
}
}
return res;
}
string centreSpread(int left,int right,int &len){
while(left>=0&&right0){
string res=str.substr(left,right-left+1);
cout<<"res:"< 细节点注意:平常我们比如用for循环,
int i;
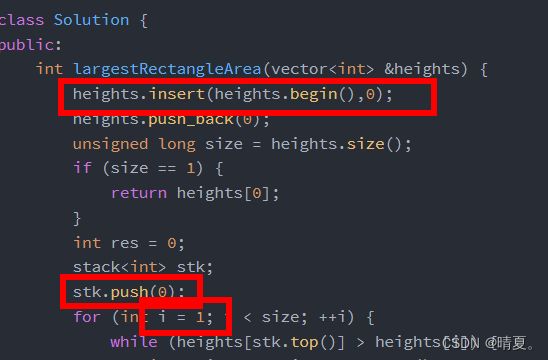
for(i=0;i } 当我们跳出这个循环时,i已经大于等于len了。 同理: 有了动规后,中间还需要记录下来左、右的边界,并计算出长度,在遍历的过程中还要把最大长度记录下来。 视频解析: 视频图解 动态规划 正则表达式 - 正则表达式匹配 - 力扣(LeetCode) (leetcode-cn.com) https://alchemist-al.com/algorithms/regular-expression-matching 使用dp[i][j]代表0到第i个字符和0到第j个字符是匹配的 先考虑最简单的情况 解决方法,用二维的列表,如果s的第i-1位和p的第j-1位相同(因为dp的初始第一行第一列用来做为空字符),或者是其中一个是 · 则让这两者相同,那么该点dp[i][j]的值就等于dp[i-1][j-1] 首先需要初始化第一列: 如果其中一个是*号,则看其前两个位置是否是true,如果是true,则该位置也是true,因为这相当于前一个位置出现0次,如下图所示: 因此初始化的时候,如果*号出现了,那么其前面的元素我们可以视为出现0次,在第一列中这样: 非第一列的情况 (出现0次的写法已经在上面写过了 如下图所示,此时j的位置为*,而j的位置前一个则为A,同时当前i的位置为A(两个红框中的A所示),说明相等。那么当前的dp[i][j]就等于的dp[i-1][j]的值。(有没有多出这个A,结果都和之前一样,所以是dp[i][j]=dp[i-1][j]) 如下图所示,红框和红框,绿框和绿框,元素一一对应,相当于没出先过,所以就等于上一行的值 于是这部分的代码如下: 最终完整代码如下: 首先最简单的思路就是暴力法,遍历所有的左和右区间,然后用区间长度乘以高度的最小值即可。代码如下: 接下来想想 使用双指针,我们希望区域越长越好,所以右指针从最右边开始。 然后把右指针往左移的过程中,如果高度比原来右边中最高的高度要矮或者相等,则不需要计算,因为此时宽短。 对于左指针右指针,我们如何移动呢? 我们优先移动高度较小的那一个。 为什么呢? 这样理解: 首先初始时,左右指针均在左右边界上,此时宽度达到最大,那么面积的高度由较小的那一个决定。 假设此时左指针的高度较小,那么此时所组成的面积,右指针再怎么左移,面积也不可能再增大。 原因在于,高度已经由左边较小的那个决定了,右指针左移,宽度只会缩小,而高度不可能增大,故面积只可能减小。 所以我们移动左右指针中,高度较小的那个。 首先第一种暴力遍历法 第二种: 对其进行排序,按照一定的顺序求解可以避免重复答案。 这道题也可以使用哈希法, 一开始没想起来用递归 注意一下char转string的方法: 容易想到的思路: 因为是获取倒数第n个结点,因此先遍历一遍求出长度,然后走到倒数第n个的前一个,然后让其list->next=list->next->next即可。 因此代码如下: 易错细节点注意! 但是这样的代码会有问题,对于如果比较短的,想要删除,例如这样的例子: 因此加入一个判断: 当我们删除的是第一个元素时,直接返回该元素的next即可。 考虑出现以上的原因在于头结点没有前驱结点,因此我们可以给头节点添加一个前驱结点作为哑结点: 随后即可对包括头节点在内的所有结点都采用同样的操作。 此时真正的头结点是dummy这个哑结点,而 上述操作的时间复杂度是O(2n),为简化操作,我们可以不用求其长度,而是使用快慢指针的方式: 简单来说就是让一个指针先提前多走n步,然后当快的那个指针走到尽头时,前面那个指针也走到了倒数第n个。 快慢指针代码如下: (做这种链表的题时,移动多少位,要看图) 和上面同理,对于如果删除的结点是头节点的情况要区分对待。 什么时候知道删除的是头节点呢?当fast走了n步之后已经走到了null说明要删除的是头节点。 方法思路三:栈 根据栈后进先出的特点可以实现该功能。 我们首先添加一个哑结点。 然后依次所有元素入栈直到全部入栈,如果要求删除倒数第n个结点,则将栈弹出n个元素即可。这样就可以找到被删除的结点的前驱结点。 一开始想着套用之前在算法班学的内容: 但是会有样例过不了: 于是需要使用栈,遇到右括号时,后进的括号先匹配,看能否匹配成功。 换种方法,使用栈: 代码如下: 还有一点,如果仅出现右括号,那么此时栈是没有值的因此不能访问,因此我们在调用栈时要先判断栈中有无值。(下面的代码先垫了个0) 需要一个基础的结点,我们可以看作是哑结点,也就是最初的头结点 过程如下: 方法二递归: 方法一暴力法: 生成所有带括号的子序列,时间复杂度为O(2^2n),遍历查看这个字符串是否满足括号的要求。 方法二: 放置左括号的条件比较简单,只要左括号数没有超过系统给的限制n就行了。 对于右括号的条件就比较苛刻了,右边的括号数不能超过左边的括号。 暴力法: 代码如下: 为了方便对头节点做处理,添加一个哑结点,这样所有结点都有前驱结点,就可以一视同仁。 方法一:两遍扫描 注意到下一个排列总是比当前排列要大,除非该排列已经是最大的排列。我们希望找到一种方法,能够找到一个大于当前序列的新序列,且变大的幅度尽可能小。具体地: 我们来看1、3、5、6、7、9的字典有 135679 135697 135769 135796 135976 136579 136597 136759 136795 …… 可以发现,其排列依次增大,我们希望每次增大的幅度较小,则需要从最右边的数字开始改变而不是左边,因为左边一旦改变则变化幅度就很大 可以类比一百二十三这个数字:123,越靠近左边,则其代表的位权越大。 观察这个序列是怎么变的? 注意到前面135为顺序,976为逆序,而我们知道,逆序排的序列是最大的序列,所以此时我们想让这个变大无法从后面三位入手(即无法从这部分逆序的子序列下手!只能往前一位),因为后面三位已经最大(976),只能从前面权力更大的一位改变。所以我们必须再往前一位改变才行。 那接下来我们要做的事情如下: 那么抽象出来的步骤如下: 代码如下: 暴力法自不用说,对于这种变相的二分查找,我们要做的就是用一个数值去记录拆查询到的下标,并且当我们查询到数值之后,更新下标,并且继续查询 顺带补充一下二分查找中查找第一个大于等于该数的代码 和我看过的一道硬币找零是一样的题目 代码如下: 每次出栈元素时都需要计算雨水,此时左柱子的高度是当前元素pop完之后的栈顶。 算法班有一样的题,简单来说就是每次旋转一个边框,这个边框由四条边组成,将这四条边上的数字依次进行交换即可。 注意一下下标,本题自己写的时候犯了两个错误: 犯了两个细节错误: 方法一:排序分组法 由于不同的字母异位词,如abc,acb,bca,cba,虽然看上去不同,但是一旦对其排序,则其结果一定相同。上面三个都会变成abc。 所以我们将排序结果相同的划分到一个组里面。 使用map来存储,key是排序后的结果,即将不同的字母序列的排序结果作为代表元素,key,然后value则是该字符串原本的样子。使用vector 最后依次输出每组中的字符串即可。 代码如下: (emplace_back和push_back功能相同,但是前者性能更高。) 方法二:统计字母出现次数 两个字符串互为异位词,则其每个字母出现次数一定相同,则我们将不同字母出现的次数用一个字符串表示。 如用一个26位的序列表示: 00000000000000000000000000 如果是eaat,则序列即为: 20001000000000000001000000 读取到字母e时,在第五位让其对应的字符++,读到字母a时,让其在第五位++,读到t时,让其在20位++。 那么如果这个数字超过9怎么办?超过9怎么表示呢? 不用担心,虽然此时不再是数字,但也是acii码的下一位!所以依然可以表示。 代码如下: 对二维数组直接排序则默认按照第一列,详细的排序如下: (194条消息) c++二维数组用sort排序具体是怎样排序的?_c++二维数组怎么用sort排序_穿过漫长林径的博客-CSDN博客 比较普通的dfs遍历图,但是遇到了点问题: 代码: 这样的方法在数据量小的时候没有问题,但是数据量大起来的时候就会超时。 动态规划: 打红框的地方错了好多次,报错都是什么栈溢出啊 heap overflow这种 除了dfs还可以使用动态规划。 直接递归 动态规划: 我们需要比较两个单词,我们可以对单词A做插入删除替换三种操作,对单词B也可以做在这三种操作。 但是, 对单词 A 删除一个字符和对单词 B 插入一个字符是等价的。例如当单词 A 为 doge,单词 B 为 dog 时,我们既可以删除单词 A 的最后一个字符 e,得到相同的 dog,也可以在单词 B 末尾添加一个字符 e,得到相同的 doge; 同理,对单词 B 删除一个字符和对单词 A 插入一个字符也是等价的; 对单词 A 替换一个字符和对单词 B 替换一个字符是等价的。例如当单词 A 为 bat,单词 B 为 cat 时,我们修改单词 A 的第一个字母 b -> c,和修改单词 B 的第一个字母 c -> b 是等价的。 这样以来,本质不同的操作实际上只有三种: 在单词 在单词 A 中删除一个字符; 修改单词 虽然可以直接排序,但是时间复杂度为O(nlogn),可能会超时。 方法一:重写数组(计数排序) 根据题目中的提示,我们可以统计出数组中 0, 1, 2的个数,再根据它们的数量,重写整个数组。这种方法较为简单,也很容易想到,而本题解中会介绍两种基于指针进行交换的方法。 方法二:单指针 我们可以考虑对数组进行两次遍历。在第一次遍历中,我们将数组中所有的 0 交换到数组的头部。在第二次遍历中,我们将数组中所有的 1 交换到头部的 0 之后。此时,所有的 2 都出现在数组的尾部,这样我们就完成了排序。 在第一次遍历中,我们从左向右遍历整个数组,如果找到了 0,那么就需要将 0 与「头部」位置的元素进行交换,并将「头部」向后扩充一个位置。在遍历结束之后,所有的 0 都被交换到「头部」的范围,并且「头部」只包含 0。 在第二次遍历中,我们从「头部」开始,从左向右遍历整个数组,如果找到了 1,那么就需要将 1 与「头部」位置的元素进行交换,并将「头部」向后扩充一个位置。在遍历结束之后,所有的 1 都被交换到「头部」的范围,并且都在 0 之后,此时 2 只出现在「头部」之外的位置,因此排序完成。 方法三:双指针 (滑动窗口其实也是使用双指针的思想来做的) 如何判断滑动窗口包含了T的所有元素? 我们使用一个变量haveEssentialNum,记录当前必须所拥有的“必须字母”的个数, 什么叫必须字母呢?比如说,假如该字符串需要2个a,但是此时长的字符串有3个a,那么很明显有一个多的a我们是不需要计算的。 当我们所拥有的必须字母的个数等于所需的字母个数,则此时达到满足条件。 达到满足条件时,我们则需要将左指针去不断的右移,直到不满足当前的窗口包含全部所需字母。 写本题的时候以为会错很多地方,但是一边写的时候一边写注释,整理思路,没想到竟然一遍过了! 方法一:回溯 方法二:迭代法实现子集枚举 使用01序列组成代表每个数字出现与否, 而这个做法的具体代码实现就是通过位运算来实现的: 想获取2^n种不同的序列,通过位运算,其实就是让i从0开始,当i小于1< 我们可以将序列存储下来,然后根据每个序列来映射出数字。但是存储再读取的方法较为麻烦,我们可以每次生成出来时直接使用该序列。 而根据每个位是否为1,然后来判断是否读取。也是通过位运算的方式,就是让1去左移,(注意,1左移一位是10,而不是11) 于是最终代码如下: 本题是比较经典的dfs题目。不过自己写的时候出错了几个地方,下面记录下犯的错误。 此处忘记初始化这个bool二维数组了,所以导致访问必然越界出错!对于这种需要声明大小的数组必须不要忘记初始化! 除此之外,此处还犯了个错误在于,下标设置错了,会导致越界 初始化二维数组的方法: 做这种题一定要细心判断数组是否越界了。我这次出错的两个地方,一个是忘了初始化,另外一个是在于不小心越界了。 最终代码如下: 方法一:暴力枚举宽度 我们需要在柱状图中找出最大的矩形,因此我们可以考虑枚举矩形的宽和高,其中「宽」表示矩形贴着柱状图底边的宽度,「高」表示矩形在柱状图上的高度。 如果我们枚举「宽」,我们可以使用两重循环枚举矩形的左右边界以固定宽度 w,此时矩形的高度 h,就是所有包含在内的柱子的「最小高度」,对应的面积为w×h。下面给出了这种方法的 C++ 代码。 方法二:暴力枚举不同高度下的矩形的面积 我们在缓存数据的时候,是从左向右缓存的,我们计算出一个结果的顺序是从右向左的,并且计算完成以后我们就不再需要了,符合后进先出的特点。因此,我们需要的这个作为缓存的数据结构就是栈。 方法三:单调栈 本题为什么可以用单调栈呢?或者说,怎么想到使用单调栈的。 先来看看单调栈的特点: 单调栈分为单调递增栈和单调递减栈 操作规则(下面都以单调递增栈为例) 单调栈的应用场景 当你需要高效率查询某个位置左右两侧比他大(或小)的数的位置的时候。 接下来看看我们本题要想求最大面积,该如何做? 首先我们在遍历的时候需要存储信息,那么应该存储高度还是宽度呢? 答案是宽度。 因为宽度可以通过下标的差值得到,并且高度可以通过查找数组里对应下标的值得到。但是如果我们记录高度,则宽度信息就无法保留下来了。所以我们需要存储的信息是宽度,也就是下标! 接下来通过实际例子讲解为什么本题可以套用单调栈的模型: 想要求解矩形面积,如果我们从左往右走,如果已经确定了这个矩形的高度,那么其面积的大小,是由其右边有多少高度大于等于它的矩形所决定的,也就是宽度最多能延伸到多长! 但是我们一开始不知道右边有多少比当前高度长的矩形,那么我们只能一直往右走。往右走时,只要矩形高度在增加,这就代表此前的矩形面积的宽度都能不断延伸。我们就往栈里存入下标。 但是如果一旦出现了高度变小的情况,那么此时就有矩形可以确定出面积了(但不是全部) 例如下图,一开始1到3往,我们往右走,高度不断增加。但是走到4的时候,高度减小。 (当前index为4) 那么此时有哪些矩形可以确定面积呢?以下标为3,高度为6的矩形举例:对于它来说,确定宽度得往右往左延申,它是栈中最后一个元素,自然无右边。而左边的元素一定比它小,自然无左边,所以宽度为1. 我们继续往左边看,以下标为2,高度为5的矩形来看,首先它的高度大于当前以4为下标的矩形,代表它往右延申只能延申到当前栈顶的位置,也就是3的位置。而其左边的元素自然比它小,无需考虑。因而宽度为2。 继续往前走,遍历到下标为1,但是与前面不同,高度为1的矩形仍然可以继续往右延申!这是因为当前下标为4的矩形高度还是大于下标为1的矩形高度。所以此处下标为1的矩形不能确定面积。因此往前找能确定面积的矩形到此处结束。 有没有发现,此处停止往前搜索的条件和单调栈停止往前的条件是一样的,都是找到第一个小于当前元素高度即停止。 并且往回走的过程中,一些高度确定的矩形,其宽度也可以确定下来,即面积也可以确定下来。于是此处就可以套用单调栈的模型了。 单调栈的模板代码: 接下来以实际例子来书写代码,判断下宽度如何计算 当遍历完一遍后,栈内仍然有剩余的情况: 于是最终代码如下: 到这里为止就可以通过了,但是你以为本题到此为止了? 有没有发现,我们在计算最大矩形的时侯,没有考虑过高度相等的情况? 事实上,即使不考虑,也不会有影响。因为即使右边那个矩形不会计算面积,可是轮到左边那个矩形时,也会往右延申将面积一起计算了。 除此之外,我们还可以继续优化! 仔细观察可以发现,这两部分代码十分类似,区别仅仅是在于right不同。后半部分是因为遍历到结尾时,数组结尾无了。 此处可以使用一个哨兵法!来使得结尾能将所有的元素出栈,方法就是在数组末尾添加一个元素为0!这样可以保证前面所有的元素全部出栈,于是就可以调用前面的代码! 于是代码如下: 除此之外,观察到我们的代码中有两处判断栈是否为空的情况: 这个方法也可以做优化,只需要在最开始时添加一个为0的哨兵,这样就可以保证栈绝对不会为空了!(要实现这个方法有三处改动:)需要在数组头部添加0,栈头部添加0,数组index循环从1开始。 好耶是简单题!ヽ(✿゚▽゚)ノ 看到本题找最长连续序列,每个人都会想到两种最朴素的解法之一: 1.先排序,从前往后找最长连续上升序列即可。该思路简单有效,但是复杂度已经至少有O(nlogn)。实现起来也比较简单,在此不讨论该解法。 (1)从查找角度优化:判断num+1,num+2,num+3...是否在数组中。直接遍历的方式去查找的,时间复杂度为O(n),我们可以改为哈希表查找,时间复杂度为O(1)。 (2)从遍历角度优化,假设num~num+4都连续存在,那么我们只需要从num开始每次往后遍历即可,也就是说num+1、num+2都不需要遍历。意味着对于任意的一个数x来说,假设x-1存在,那么我们就不需要遍历x了,因为x-1一定会遍历经过x。 还有另外两种方法,暂时看不太懂,并查集和动态规划的,暂时放一下。 题目中有一个解释很重要!: 重点在于说,除了边界上的O我们不需要考虑,其他的O,假如这个O和边界的O相邻,那么这个O也不需要画成X! 问题转化为,如何寻找和边界联通的 OO,我们需要考虑如下情况。 给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。 普通的做法如下: 1.使用集合存储数字。遍历数组中的每个数字,如果集合中没有该数字,则将该数字加入集合,如果集合中已经有该数字,则将该数字从集合中删除,最后剩下的数字就是只出现一次的数字。 2.使用哈希表存储每个数字和该数字出现的次数。遍历数组即可得到每个数字出现的次数,并更新哈希表,最后遍历哈希表,得到只出现一次的数字。 上面这两种方法都是需要使用额外的O(n)的空间复杂度。接下来介绍不需要空间O(n)空间复杂度的方法: 别忘了亦或的运算符是^ 第一种方法:dfs 假如leet是单词表的单词,那么还剩下code,接下来就对code进行递归的遍历。遍历即: 判断c在不在字典中,判断co在不在字典中,判断cod在不在字典中,判断zode在不在字典中。 本题思路看似没什么问题,但是实际上写的时候容易在各种细节处犯错。通过调试了好一会才做出来答案。 尤其对于这种字符串处理的,下标是容易在细节上会犯的错误。 对于dfs函数,有两个地方要注意,一个是参数选什么,一个是返回值要不要是void。 参数部分:由于我们需要截取部分字符串,那么此处通过将start和end使用这两个下标作为dfs的参数比较合适,因为start和end会一直变。 返回值部分:我们只需要最终判断是否找到即可,不需要保存后一轮dfs得到的结果,所以返回值设为void。因此只需要如果找到,只需要设定一个外部的flag值为true即可达到效果。 (返回值设为非void值代表的是希望用到子树的dfs的结果,然后一步步往回推) (当然上面这种void值作为返回值的,还可以改成使用bool值作为返回,然后判断所有遍历的情况中,用or来连接 bool true=递归子串1||递归子串2||递归子串3,在这样的情况下,只要存在一个子集中满足目标条件,那么最终就会就会返回true,否则返回false。) 容易出错的细节点!: 如leetcode,当start为0,end为3时,此时字符串为leet,那么找到单词后,需要对其剩余字串进行递归的判断。 那么此时的下标为4到4,4到5,4到6,4到7, 所以注意此处的下标赋值: 以及只有当前字符串是满足条件的,我们才会继续去递归搜索其剩余的!所以搜索剩余子串的要放在flag为true的情况里面。 所以最终代码如下: 上面这样的做法是对的,但是数据大会超时。 140题是单词拆分2,此处补充一下对于140题的解法。 140题与139题很像,区别就在于139只需要判断是否存在,而140需要将遍历成功的结果储存下来: 为了将过程中的结果储存下来,可以有两种方式, 如果是矩阵访问型,那么需要在每访问完一个格子后设置访问位为true,退出当前dfs函数时再设为false。(访问矩阵是全局变量) 如果是过程加和型,例如求数字总和大小,或者本题的将字符串组合的情况,那么就需要在遍历函数中多设定一个参数,在遍历过程中传递,每到一个新的地方都进行加和。如果传递成功到最后一步,则将该结果储存到全局变量中。如果没有传递到最后一步,也不需要像上面的访问位一样改回原样,因为此处我们修改的是作为函数传递的参数,是一个局部变量,直接返回即可 完整代码如下: dfs函数中新增一个字符串参数,如果满足则把它加进去。 只需要在flag为真时,添加字符串,当达到最后一位时,把字符串添加进vector即可。 方法二:动态规划法 考虑本问题,可以将字符串进行分割成两部分,如果这个字符串的前面部分存在解,那么只需要考虑字符串的后面部分是否存在解即可。 而整个字符串就可以不断分解为上述小的子问题。 所以使用dp[i]代表0到i-1位置的字符串是否存在字典解。 注意此处下标,dp[j]代表的是0到j-1个字符组成的字符串能否满足有字典解 例如abcdef,dp[2]为true代表abc的0到1位置满足有字典解。 那剩下的字符串即为cdef,也就是substr,从第2个位置开始,往后4个个字母,如果它存在解,则dp[i]的值即为真。 (代码下标细节)也就是从第j个位置,开始往后j-i个字母。 最终代码解析: remainStr代表的是剩余的字符串。 进行一个双循环,双循环遍历如下: i从1开始,到等于length,j从0开始,到等于i-1为止结束,每一个外轮循环,是为了确定dp[i]是否为真。也就是0~i-1所组成的单词能否拆成字典里的单词! 比如对于字符串leetcode当i=6时,此时是为了确定0~5所组成的字符, 即“leet”是否能由字典单词所组成。 为了达成这个目标,此时让j遍历,从0、1、2、3、4、5,依次判断l、le、lee、leet、leetc、leetco是否能匹配字典里的东西。 但是假如我们遍历到index为3的时候的时候,还要重新依次判断前面的l、le、lee、leet、leetc、leetco的话,那这样就很浪费时间,违背了动态规划的“存储前面已经计算过的值并应用”的思想。 为了将前面计算的值利用起来,我们将leetco再拆分!l和eetco,le和etco,lee和tco,leet和co,leetc和o。 然后我们依次判断拆分的这两部分,前半部分对应的dp值是否为true,如果为true只需要判断后面的能否在字典中查找到即可。如果为false,比如dp[2]为false,代表“le”找不到对应的,那么etco也不需要判断了,直接判断后部分即可。 最简单的方法是使用集合。 还可以使用快慢指针。 本题实际写的时候,代码如下: 此时可以观察到,测试样例都通过: 但是一些特殊样例却出现了错误: 原因如下: 当在上面的情况,此时fast已经到了2的后面一个也就是空指针,那么接下来会再次判断执行循环的条件: 此时fast已经是空指针了,故不能访问其fast->next,因此把条件改为: 即可通过。 本来想套用第一问的代码,发现不行,第一问当相遇的时候不一定在循环的入口结点上。 根据一个数学公式: 当相遇时,则在初始位置设立一个指针ptr,接下来让该ptr和slow指针移动,这两个结点相遇的结点即为入口结点。 最终代码如下: LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。 本题题目中,见到key和value,想到使用哈希表: 由于要求get和put的时间结点时间复杂度为O(1),所以使用哈希表。 由于希望出现访问某数据的之后,其的顺序被放到最前面,所以也就是希望将数据能插入到头部,那么使用链表。 如果哈希表的值,包含链表的位置信息,那么我们就可以在O(1)时间内去访问链表,所以链表中的元素必须储存键,这样才能通过键找到哈希表的项目,进而实现删除要求。 接下来看一个具体的例子: 使用双向链表,里面的元素则是用哈希表存储。 接下来这里由于访问了结点1,所以将结点1移动至链表尾部: 当第五步,再加入新的元素时,超出容量,所以删除该元素 然后再将该结点移至链表尾部。 直接求负数的数量,然后根据负数的数量返回结果,也不一定对:因为可能会有0的情况 考虑到,会出现说有负数的情况,所以情况较为复杂,接下来分析一下。 我们用dp[i]代表以i结尾的数组的最大乘积,考虑一下,dp[i]的值如何决定呢?有三种情况: 例如-1,2 此时dp[1]=nums[0] 例如3,2, 此时dp[1]=nums[1]*dp[0] 还有一种情况: 例如,-3,-2, 此时dp[1]=negaDp[0] 对于第三种情况,如果nums[i]本身是负数时,且前面存在一个负的最大值,那么我们最大值即为num[i]*negaDp[i-1]。 也就是说,dp[i]有三种不同来源转移的可能性。 于是说我们可以对不同情况进行分类,但是实际上那样写起来会发现很麻烦还容易出错, 像上面那样写起来会出错。 所以dp[i]的状态转移,我们是知道其转移方程的,只需要选取三个来源中最大的即可: dp[i]=max(nums[i],nums[i]*dp[i-1],nums[i]*negaDp[i-1]); 而对于negaDp[i]也是同样的道理,它也有三种来源: negaDp[i]=min(nums[i],nums[i]*dp[i-1],nums[i]*negaDp[i-1]); 最终代码如下: 上述方法使用了数组存储结果。考虑到每间房屋的最高总金额只和该房屋的前两间房屋的最高总金额相关,因此可以使用滚动数组,在每个时刻只需要存储前两间房屋的最高总金额。 首先要明白岛屿是怎么计算的: 其实就是个经典求联通量问题,使用深度优先搜索,对于所有没访问过的结点1进行访问,总共访问的次数就是联通量。 广度优先搜索 为了加快速度,在遍历时,可以增加一个“假如右一行和下一列的交叉点的值不为1,则此时可以直接跳出循环。” 接下来介绍动态规划法,动态规划的方法难以想到。此处我们思考,为了使用动态规划要怎么去做呢? 此处是一个二维数组,我们需要构建一个状态转移方程,状态转移方程,对于第i,j个位置我们通常都是考虑如何从第i-1个,j-1个转移过来的。 对于第(i,j)个位置,首先其要为1,才需要考虑后续。 我们定义dp(i,j)代表的是以(i,j)结尾的最大正方形的面积。 那么假如dp(i-1,j)、dp(i,j-1)、dp(i-1,j-1)都是为1,那么此时最大正方形面积为2. 如下图所示 假如dp(i,j-1)的值为2,而另外两个值都为1,如下图所示:此时dp(i,j)最大面积还是2 假如dp(i-1,j-1)的值为2,而另外两个值都为1,如下图所示:此时dp(i,j)最大面积还是2 假如dp(i-1,j)的值为2,而dp(i-1,j-1)的值也为2,第三个dp的值为1如下图所示:此时dp(i,j)最大面积还是2 而只有当这三个dp值都为2时,此时最终的dp值才会为3: 这个如何理解呢? 我们思考下图所示的这个九宫格, 假设我们希望以这个1作为右下角的正方形面积为3:,那么必须满足三个条件,其所在列上方均为1,所在行左边均为1,且左上的正方形的面积边长必须满足2,一旦有一个条件不满足,那么最终正方形的面积就做不到3x3,只能降低为2x24。 而对应这三种条件的,首先要想让左上角的值为2,也就是dp(i-1,j-1)的值为2即可。 那么对于同行和同列如何判断呢?我们仔细思考可以发现,红框的值为多大,则该1的同列上方就有多少个1!因此可以用dp(i-1,j)的值代表这个1上方有多少个1!对于绿框来说同理。 所以最终所能凑出来的最大的正方形面积大小即为这三者最小值+1。 即动态转移方程: 最终代码如下: 注意,由于存在dp(i-1,j-1) 首先对于dp(0,0) dp(0,1) dp(1,0)就需要通过人工进行初始化。 本题乍一看就是翻转左右子节点,不过有个细节需要注意: 由于翻转是从最底部先做起,翻转完后再一步步的往前翻转,所以在递归遍历时,是先递归子函数,再进行交换左右子结点。 方法一:最简单的办法是将其用数组储存起来,然后使用双指针的方式判断是否是回文。 方法二:使用递归的方法,将一个结点移到最末端,然后逐渐回移,回移的同时让垨结点往后走,判断是否匹配。 首先不断调用递归函数,把下一个结点作为参数调用递归函数,直到为空,则返回。 为空返回之后,此时执行的函数为链表最后一个节点的参数,然后我们此时和最头部的front结点做对比,看看是否相等。 如果不相等,则可以直接返回,跳出循环。如果相等,则我们让front结点后移动一步(注意!front结点要设定为全局变量,才能使得在递归函数中也能操控它往后移动),然后当前递归的函数return。 在递归函数中,假设我们在递归的过程中一旦发现此时找不到正确答案,那么接下来往前回溯时,我们也不需要再做任何操作了。举个例子,这其实就相当于,A让B去办事,B就让C办事,然后C让D去办事。(办事的过程其实就是递归子函数,调用递归函数,参数是子参数的过程。) 假如D的子工程办事不利,那么需要通告C,C得知此事,他就明白他的工程也不需要做了,于是往回禀报上头B,B得知此事后也停下了手中的工作,回禀给了A。 为了实现这一操作需要在往前回溯时传递信息,怎么传递呢? 递归法常见的传递信息的方式就是通过将返回值设定为bool变量! 假如我递归的子函数,当子函数执行完毕时就会返回一个bool值,bool值为真代表我交给子函数去做的事情成功了! 根据子函数的思想得到的代码如下: 方法三:反转后半部分链表 如果不使用额外的数组来存储应该怎么做呢? 即使使用递归,也会产生O(n)的空间复杂度,因为每次递归都会产生一个栈帧。 避免使用O(n) 额外空间的方法就是改变输入。 我们可以将链表的后半部分反转(修改链表结构),然后将前半部分和后半部分进行比较。比较完成后我们应该将链表恢复原样。 整个流程可以分为以下五个步骤: 执行步骤一,我们可以计算链表节点的数量,然后遍历链表找到前半部分的尾节点。 我们也可以使用快慢指针在一次遍历中找到:慢指针一次走一步,快指针一次走两步,快慢指针同时出发。当快指针移动到链表的末尾时,慢指针恰好到链表的中间。通过慢指针将链表分为两部分。 若链表有奇数个节点,则中间的节点应该看作是前半部分。 步骤二可以使用「206. 反转链表」问题中的解决方法来反转链表的后半部分。 步骤三比较两个部分的值,当后半部分到达末尾则比较完成,可以忽略计数情况中的中间节点。 步骤四与步骤二使用的函数相同,再反转一次恢复链表本身。 如果p、q在当前结点的左右两侧,说明此时的结点就是我们要找的公共祖先。 如果p、q其中一个结点是根结点,那么该结点就是公共祖先。 如果p、q都在当前结点的左侧,说明公共祖先在当前结点的左侧里去找。 如果p、q都在当前结点的右侧,说明公共祖先在当前结点的右侧去找。 此处递归使用两个函数,一个函数用于判断上面四种情况是否属实,一个函数用来判断某结点是否在该结点的左或者右子树中。 最终代码如下: 方法一:使用前缀后缀乘积列表 用x前面的前缀乘以后缀即可 提前运算好左右乘积列表,然后依次相乘即可 前缀积和后缀积计算的过程。 有没有办法可以优化空间复杂度呢?不使用额外的空间来存储,(不包括结果的数组) 方法很简单,就是把先用结果的数组来存储前缀数组的结果。 我们知道最终结果其实就是前缀数组和后缀数组相乘。我们得出前缀数组后,从后往前遍历,每次遍历的时候多乘一个数,这个数就是当前下标的右边所有数的乘积。 最终代码如下: 经典单调队列的题目,思想类似单调栈,队列中元素均为单调递减。 为什么使用队列?因为对于滑动窗口从左往右移动的过程来说,先进窗口的会先弹出。 如果出现了某个元素比当前队列内后面元素大的,那么就依次出元素,直到仍然满足递减的情况。例如: 当队列内已有5、3这两个数,此时再往内进元素4: 此时4大于队尾元素3,这表明元素3不可能是窗口「5 3 4」中的最大元素,因此需要将其从队列移除。但队首有元素5存在,因此不能将其从队首移除,那怎么办呢?我们可以将其从队尾移除。就这样移除直到数字满足递减的情况。 也就是说,我们的元素会从右端进队和左端出队,但是也有可能右端出队,对于这种两端均可出入队的,使用双端队列。 而每当窗口右移的过程中,我们需要判断当前窗口最左端元素是否和队列内的首元素相同,如果相同说明此处出掉的元素会导致队列内最大值发生改变。则队列头要出,如果不是,则说明当前滑动窗口元素不是头元素因此不需要出。 最终代码如下: 看下边的例子。 如果 target = 9,如果我们从 15 开始遍历, cur = 15 target > 7, 去掉当前行, cur = 8 target > 8, 去掉当前行, cur = 9, 遍历结束 代码如下: 0 10 5 20 15 30 本题可以理解为上车下车问题。不用在意是谁上车还是下车,只需要注意什么时候上下车就可以。即 把上车和下车的时间分成两组,通过两个指针滑动的方式,判断同时在车上的最大数就可以了。 因此可以将开始和结束看作两个数组,并对他们进行排序。 然后代码怎么写呢?看下面这个例子,分别代表开会的时间。 0 10 5 20 15 30 接下来代码执行的思路如下,首先判断start[0]和end[0],那start[0] 接下来i++,start[1]为5,而小于end[0],说明还需要一个新的会议室。 然后继续i++,此时start[i]为15,而大于end[0],也就是大于10。那么此时说明一个会议已经结束了。 至此,我们的代码思路可以理解为,让时间分别流逝到不同的时间点,这几个时间点就是开始的时间点,假如有会议结束的时间比当前时间要晚,说明需要多一个新的会议室。如果时间继续流逝,此时有会议结束的时间比当前所在时间要遭早,说明该会议结束,说明此时正在运行的会议室数量--。 最终我们只要存储这个期间最多的会议室即可。 关于这题一开始想到的是采用类似背包找零的方法去递归,但是那样做的方法,时间复杂度恐怕会很大,而且有很多重复。 考虑到,对于但是可以采用动态规划的方法去做。 于是我们从小做到大,从f(1)一直计算到f(n) 对于每个f(i),例如f(14),我们就要去计算 f(14-1²)和f(14-2²)、f(14-3²)找到哪个是最小的。 也就是在 对于每个f(i)都有 因此总体代码如下: 方法一:暴力法 找到为0的元素,然后从这之后遍历,找到第一个不为0的元素,然后交换。 方法二:基于上述冒泡排序改进的双指针法 上述每次找到一个0后,就往后找第一个非0数,然后交换。但是因为多了一个for循环,时间复杂度提高为n²级别的。 解决方法是使用两个指针,一个指针b停留在0元素,一个指针a走在后面指向非0元素,遇到非0元素则与前面的进行交换,遇到0元素则继续往后走。 每次交换完后,b指针就不再是非0元素了,但是此时只要让指针b往后走一位,则一定是0元素。具体可以看下图: 方法三:将后面的非0元素的信息储存到前面的双指针法 一个指针a用来不断往后走,如果遇到非0元素,我们就把它往前面放,怎么放在前面呢? 用另外一个指针,这个指针如果指向了第三个位置,说明前两个位置已经储存好了非0元素。 整体思路就是,指针a从头到尾去遍历数组,每次寻找到非0的数字,就将该数字存放到指针b所放的位置的数字。而指针b当前位置如果已经放了元素,那么自然指针b需要往后走一步了。 如果遇到非0元素,则指针a继续往后走,不做任何操作,指针b也不用动。 为什么a动,b不动呢?因为思想是需要把非0信息存储起来放置在前面,而如果遇到0元素,就不需要存储这个信息。因为我们只需要把非0元素放到前面。而指针b当前位置没有存储信息,自然也不需要往后移动了。 如果使用哈希表那很容易做。 首先难点在于要先知道有多少左括号和右括号需要删除,那就先判断有多少括号是多余的,什么时候会多余呢? 我们用lremove记录需要删除的左括号的数量,用rremove记录需要删除的右括号的数量。 遍历到左括号,则让左括号++,遍历到右括号时,假如说,此时左括号数量为1,那么此时这个右括号就是和左括号匹配的,没有问题。但是假如此时左括号为0,即“)”这种情况,也就是初始时只有一个右括号的情况,说明此时这个右括号是多的,那我们让rremove++。 zui在这样就可以得到多出来的左括号和右括号了。 代码如下: 简单来说就是按顺序,如果需要剔除的括号数量还有,就剔除该括号,从左到右遍历字符串,这样去递归即可。 剔除括号的方式有很多种,知道有几个左右括号需要去删除,就使用递归法,一个一个去尝试,比如删去字符串中第一个左括号,然后递归子串,或者删去第二个左括号,然后递归子串。 r安徽增加一个判断字符串是否合理的函数,当需要删除的括号删除完时,判断当前字符串是否有效,有效则加入存储即可。 关于股票类的所有题解析见这篇文章: 一个解法解决所有力扣买卖股票问题_晴夏。的博客-CSDN博客 假设先不考虑冷冻期。 接下来解析一下这道题,(红色代表分隔线) 简单来说就是,对于have数组(也就是buy),是今天持有股票的情况,那就是要么之前买的,今天什么都没做,要么就是之前没买今天买的,那么在二者里选利益最大的即可。而j代表完成交易的次数,完成交易的次数最多为k次。 只有当售卖出去才算完成交易,买入不算完成交易! 因为买入的话,只是代表当前天数时,花最少的钱买的情况,后面随着天数的增加,可能会遇到可以花更少的钱买股票的情况。 对于no数组也就是sell数组,代表的是当前没有股票的情况,那么就是之前就没有股票,或者是之前有买过股票,今天卖出去了。 难点来了! 假如当前为第二次交易,那么就还需要算上第一次交易赚的钱,所以是要加上buy[i-1][j-1],i-1代表前一天所能获得的最大利润,j-1代表前面j-1次交易所能获得的最大利润。 j代表当前是第几笔交易!而have[i][j],假如j是3,代表是已经完成了三笔收益的情况下,再次购买股票时的最大利润,这个是用于给下一笔交易做参考用的,因为此时j=3,代表已经交易过了3次。 而no[i][j]里的j,代表的是,今天这一天即将完成第三笔交易的最大利润。 no[i-1][j]代表的是,前i-1天已经完成了j笔交易,那么是最大利润吗?不一定,得看看假如只进行了前j-1场交易,加上今天的第j场的情况下,交易金额是多少。 有了状态转移方程之后,接下来的思路就是简单的遍历表然后填表即可。 在填表之前需要初始化。 注意初始化的过程很重要, 由于dp是二维数组,对于第i个位置和第j个位置会涉及到i-1和j-1的情况,所以遍历的时候,i和j均是从1开始:也就是从绿色的地方开始。而红框部分需要初始化 如果忘记初始化则会导致产生问题。 先来看二维数组的第一行: 设置成非法状态防止其由这个后续的状态由这个状态转化而来。 对于第一列的初始化,来分析一下: have[1][0] have[2][0] 分别代表的是第一天,第二天的情况下持有股票,但是交易次数为0的情况下,花钱最少的情况。 那么有两种可能,一种是昨天买了,今天就不用买了,第二种情况就是昨天没买今天买了,那二者取最小的即可。 即方程: 对于no[i][0],代表的是第i天的情况下,没买股票的收益,那自然就是0,设定成0即可。 即no[i][0]=0; (如果此处忘记初始化,则会出错,因为二维数组默认初始化都是随机的数。)(vector会默认初始化为0) 此处补充一下,vector的构造方法: vector 而二维数组的构造如下: 所以最终代码如下: 对于有冷冻期的状况: 在做这题之前先来看普通的topK问题: 思路很简单,首先优先队列自动会保持一个大顶堆,加入数据时会自动改变数据顺序使其保持大顶堆。 那么想要保存一个数组中的topK元素只需要,先将该元素加入优先队列中,加入此时元素数量超过k,则弹出一个数据即可,弹出的数据自动会弹出最小的那个数据。 那么接下来回到本题,思路就是首先使用哈希表存储每个数字的出现次数,接下来要求前K个高频元素,就相当于找出「出现次数数组」的前 k 大的值。然后接下来声明优先队列的时候,就让原来是int元素的优先队列变为,是pair 接下来步骤则和TOPK问题一样。 最简单的做法是给「出现次数数组」排序。但由于可能有 O(N) 个不同的出现次数(其中 N 为原数组长度),故总的算法复杂度会达到 O(NlogN),不满足题目的要求。 注意如果这个比较函数是在类里面的话要声明成static的函数才行。 然后接下来就使用TOPk算法进行计算。 因为接下来使用优先级队列,所以需要自己书写自定义排序方法。注意,给优先级队列书写自定义排序函数的方法有固定格式,在此补充一下: 自定义的书写方法如下:(208条消息) c++优先队列priority_queue(自定义比较函数)_菊头蝙蝠的博客-CSDN博客_c++ priority_queue自定义比较函数 因此本题最终代码如下: 说实话有点难度 做这题之前先来看看并查集,算法学习笔记(1) : 并查集 - 知乎 (zhihu.com) 对于本题首先要明白题目是什么意思: 首先,我们先根据身高降序排列,我们优先分配身高高的人。 因为假如身高高的人安排好了之后,无论怎么安排身高比他矮的人,都不会对身高高的人产生影响。 对于身高相同的,使用值的升序排列。为什么是值[5,2]和[5,3], 对于最后排完的数组,[5,2]必然在[5,3]的前面。所以如果遍历的时候[5,3]在前面,等它先插入完,这个时候它前面会有3个大于等于它的数组对,遍历到[5,2]的时候,它必然又会插入[5,3]前面(因为它会插入链表索引为2的地方),这个时候[5,3]前面就会有4个大于等于它的数组对了,这样就会出错。的升序排列呢?例如身高同样为5的, 之后按顺序往里插入,插入的时候将值插在res数组中对应的index位置,后面的元素依次往后移动,如动画所示。 这道题可以换一种表述:给定一个只包含正整数的非空数组 nums[0],判断是否可以从数组中选出一些数字,使得这些数字的和等于整个数组的元素和的一半。因此这个问题可以转换成「0-1 背包问题」。这道题与传统的「0-1 背包问题」的区别在于,传统的「0-1 背包问题」要求选取的物品的重量之和不能超过背包的总容量,这道题则要求选取的数字的和恰好等于整个数组的元素和的一半。类似于传统的「0-1 背包问题」,可以使用动态规划求解。 注意:作为「0-1 背包问题」,它的特点是:「每个数只能用一次」。解决的基本思路是:物品一个一个选,容量也一点一点增加去考虑,这一点是「动态规划」的思想,特别重要。 不过本题具有本题的特殊性,有一些特别的例子是无法符合题目要求的,具体如下: 接下来使用二维dp数组,怎么做呢? dp数组包含n行,target+1列。dp[i][j]代表的就是在0到~i件物品中做选择,容量为j,最终看dp[n-1][target]的值是否等于target即可。 代码如下: 最简单的方法是使用哈希表, 上面空间复杂度为O(n)有没有办法优化为O(1)呢? 这题用鸽笼原理实现,由题意可得,1~n的位置表示1~n个笼子,如果出现过,相应的“鸽笼”就会被占掉,我们将数字让其+n,表示被占掉了。 最后再遍历一遍,如果“鸽笼”为正数就是没出现的数字。 (如果在往后的遍历过程中发现该数字大于n,那么我们设置其对应的鸽笼那应该就对下标取余的方式) (注意,比如出现1,那应该是把第0个位置给设置占位) 注意:本题细节较多,尤其下标处, 方法二:移位实现位计数 两个数异或的结果是按位来的,如果不同则都为1,相同则为0,通过异或即可找到哪些位是不同的,然后接下来移位一个一个去判断即可。 异或也叫半加运算,其运算法则相当于不带进位的二进制加法。 法二:使用动态规划 首先我们要这样考虑,我们从前往后,每个点有两种选择。 然后可能会凑出很多种不同的可能的目标值。 我们以某个普遍情况考虑: 对于第i个点,假如要我们凑出目标为k,我们有两种选择, 1.选择该点,那么假如目标值是k,那么只需要前i-1个点凑出k-nums[i]值即可, 2.选择该点的负值,假如目标值为k,那么需要前i-1个点凑出的是k+nums[i], 所以对于第i个点,它凑出目标值为j的情况,就有两种,一种是选择该点,那么前i-1个点0凑出k-nums[i]的方法数就为dp[i-1][j-nums[i]] 选择该点的负值则,前i-1个点凑出k-nums[i]的方法数就为dp[i-1][j+nums[i]](如果凑不出则方法数为0) 所以可以得到动态规划方程: dp[i][j]=dp[i-1][j-nums[i]]+dp[i-1][j+nums[i]]; 我们要这样想:把二叉搜索树转化为累加树,按照题目的意思,越小的数则会累加前面所有的和。 另一方面我们知道,对二叉搜索树进行中序遍历即可得到从小到大有序的序列,进行中右左即可得到从大到小的数字。 事实上本题相当于把从大到小的数进行求和,并且在这个过程中赋值给自身,这样问题就迎刃而解了。 思路很简单, 首先: 如果我们要求从4到5的路径,那么我们不可能是说,去求4到2的路径,再求2到5的路径 因为4到2的话路径是不能反向求的,只能求从2到4的路径。 那么意味着对于每个结点我们需要求其左右子树的深度。 首先这是普通求深度的函数: 那最长路径就是让根节点的左右子树的结点加起来吗? 不对,例如下图: 很明显最长路径不经过根节点。 于是, 多了这两个地方:即对于每个根节点,将其左右子树长度加起来,存储下最大值即可得到最大的路径长度。 前缀和+哈希算法 对于本题有两种情况,一种是冷却时间短,或者冷却时间可以全部用来执行其他任务。那么此时最短时间就是长度。 另外一种情况是未填满,这样会导致cpu有时间在等待,那么此时最短时间的分析如下所示: 可以注意到若如果是上面那种情况,B和A的数量相同,那么此时最后一行的第二格必然被填满,因此要多加一个1。 如果B的任务数量少于A的任务数量的话。 那么此时最后一行的第二格就不需要填数据了: 因此我们计算最后一桶的任务数量也就是相当于计算有多少个和A的数量相同的任务即可。 除了最普通的列举所有子串然后判断的方法,还有其他的方法: 此处可以使用中心扩散法,对于字符串的每一个位置,例如 aabcbac 从第一个位置到最后一个位置,首先单个字符肯定满足,接下来考虑将其朝两边扩散,例如 1.从a开始,不能往左扩, 2.第二个a左右也不等 2.到b,b的左右两个不相等,跳到下一个 3.c的左一位,右一位置相等,则答案+1,c的左2位,右2位相等,则答案+2。 上面是以奇数点作为中心的情况,我们接下来考虑中心点是两个点的偶数,例如上面的aa 那么这种情况就是,left先作为自己,right作为自己的位置+1,然后判断是否相同 统一起来后代码如下: 使用单调栈的思想 


public String longestPalindrome(String s) {
if (s == null || s.length() < 2) {
return s;
}
int strLen = s.length();
int maxStart = 0; //最长回文串的起点
int maxEnd = 0; //最长回文串的终点
int maxLen = 1; //最长回文串的长度
boolean[][] dp = new boolean[strLen][strLen];
for (int r = 1; r < strLen; r++) {
for (int l = 0; l < r; l++) {
if (s.charAt(l) == s.charAt(r) && (r - l <= 2 || dp[l + 1][r - 1])) {
dp[l][r] = true;
if (r - l + 1 > maxLen) {
maxLen = r - l + 1;
maxStart = l;
maxEnd = r;
}
}
}
}
return s.substring(maxStart, maxEnd + 1);
}

10.正则表达式匹配(动规法有难度)
if(s[i-1]==p[j-1]||p[j-1]=='.')
dp[i][j]=dp[i-1][j-1];
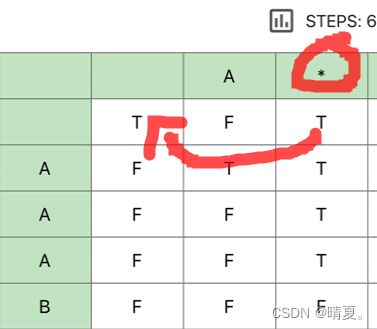
for(int j=1;j<=len2;j++){
if(j>=2&&p[j-1]=='*'){
dp[0][j]=dp[0][j-2];
}
} else if(p[j-1]=='*'){
if(j>=2&&dp[i][j-2]){
dp[i][j]=dp[i][j-2];
}
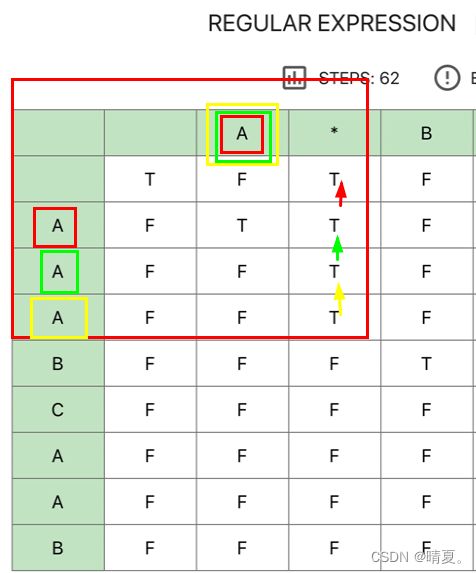
else if(p[j-1]=='*'){
if(s[i-1]==p[j-2]||p[j-2]=='.'){
dp[i][j]=dp[i-1][j];
}class Solution {
public:
bool isMatch(string s, string p) {
int len1=s.size();
int len2=p.size();
vector11.盛最多水的容器
class Solution {
public:
int maxArea(vector
class Solution {
public:
int maxArea(vector15.三数之和




17.电话号码的字母组合
class Solution {
public:
vector
19.删除链表的倒数第n个结点
class Solution {
public:
ListNode* removeNthFromEnd(ListNode* head, int n) {
ListNode *list=head;
int len=0;
while(list){
len++;
list=list->next;
}
list=head;
cout<

![]()



20.有效的括号
class Solution {
public:
bool isValid(string s) {
int small=0,middle=0,big=0;
for(int i=0;i
class Solution {
public:
bool isValid(string s) {
stackclass Solution {
public:
bool isValid(string s) {
stack21. 合并两个有序链表剑指offer里面有
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {
ListNode *head=new ListNode(0,nullptr);
ListNode *newList=head;
ListNode *head1=list1;
ListNode *head2=list2;
while(head1&&head2){
if(head1->val
class Solution {
public:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
if (l1 == nullptr) {
return l2;
} else if (l2 == nullptr) {
return l1;
} else if (l1->val < l2->val) {
l1->next = mergeTwoLists(l1->next, l2);
return l1;
} else {
l2->next = mergeTwoLists(l1, l2->next);
return l2;
}
}
};
22.括号生成
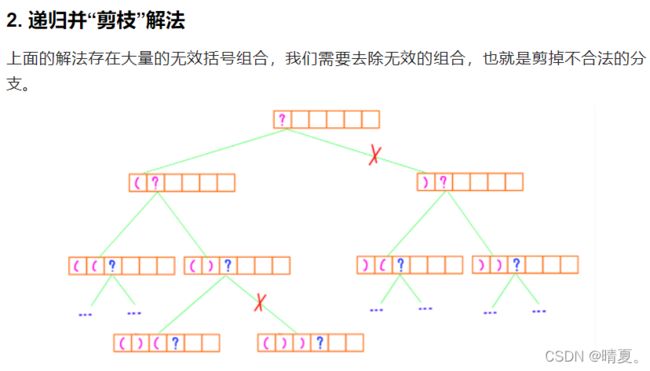
class Solution {
public:
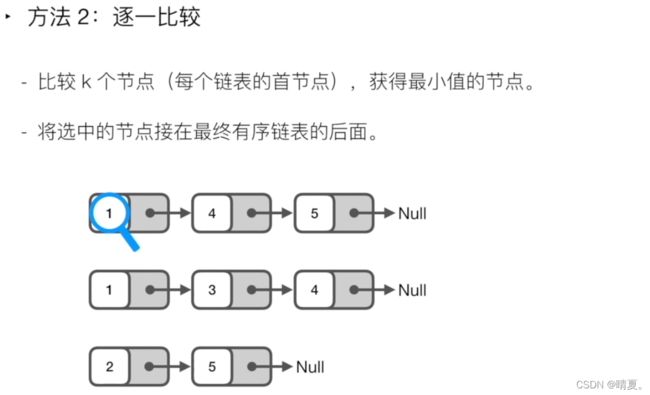
vector23. 合并K个升序链表(todo)






24.两两交换链表中的结点(myself)
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* swapPairs(ListNode* head) {
ListNode *dummy=new ListNode(0,head);
ListNode *list=head;
ListNode *pre=dummy;
while(list){
if(list->next){
ListNode *tmp=list->next;
list->next=list->next->next;
tmp->next=list;
pre->next=tmp;
pre=pre->next->next;
list=list->next;
}
else break;
}
return dummy->next;
}
};
31.下一个排列
思路及解法

class Solution {
public:
void nextPermutation(vector34.在排序数组查找元素的第一个位置和最后一个位置
class Solution {
public:
vectorint BinarySearch(vector39.组合总和
class Solution {
public:
vector42.接雨水(myself)
class Solution {
public:
int trap(vector46.全排列
class Solution {
public:
vector48.旋转图像(todo)
class Solution {
public:
void rotate(vector
49.字母异位词分组(lookAnswer)
class Solution {
public:
vector
vector56.合并区间
class Solution {
public:
vector62.不同路径
class Solution {
public:
int res=0;
int row,col;
int uniquePaths(int m, int n) {
row=m,col=n;
dfs(1,1);
return res;
}
void dfs(int i,int j){
if(i>row||j>col)return;
dfs(i+1,j);
dfs(i,j+1);
if(i==row&&j==col)res++;
return;
}
};
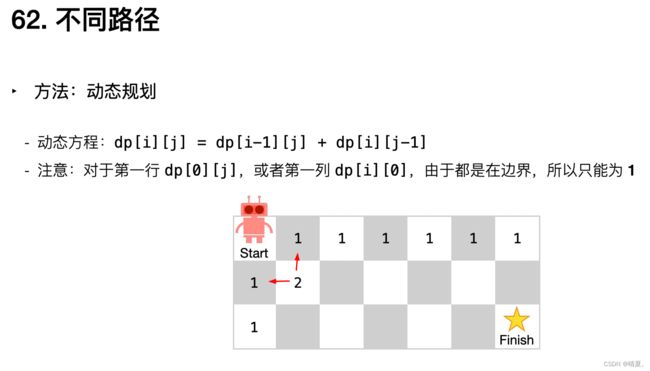
class Solution {
public:
int uniquePaths(int m, int n) {
vector64.最小路径和
class Solution {
public:
int minPathSum(vector70.爬楼梯
class Solution {
public:
int climbStairs(int n) {
if(n==1)return 1;
if(n==2)return 2;
return climbStairs(n-1)+climbStairs(n-2);
}
};class Solution {
public:
int climbStairs(int n) {
vector72.编辑距离
A 中插入一个字符;A 的一个字符。75.颜色分类
思路与算法
class Solution {
public:
void sortColors(vector
76.最小覆盖子串

78.子集
class Solution {
public:
vector


class Solution {
public:
vector79.单词搜索


// 初始化一个 二维的matrix, 行M,列N,且值为0
vectorclass Solution {
public:
vector84.柱状图中最大的矩形
class Solution {
public:
int largestRectangleArea(vector
public class Solution {
public int largestRectangleArea(int[] heights) {
int len = heights.length;
// 特判
if (len == 0) {
return 0;
}
int res = 0;
for (int i = 0; i < len; i++) {
// 找左边最后 1 个大于等于 heights[i] 的下标
int left = i;
int curHeight = heights[i];
while (left > 0 && heights[left - 1] >= curHeight) {
left--;
}
// 找右边最后 1 个大于等于 heights[i] 的索引
int right = i;
while (right < len - 1 && heights[right + 1] >= curHeight) {
right++;
}
int width = right - left + 1;
res = Math.max(res, width * curHeight);
}
return res;
}
}
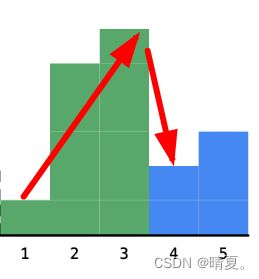


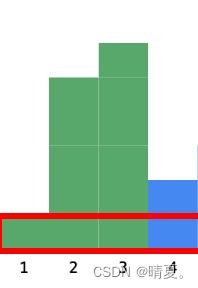
stack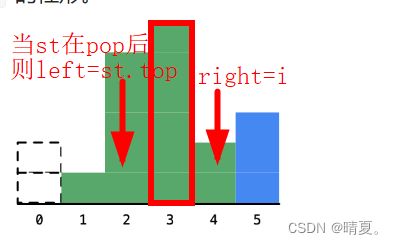

class Solution {
public:
int largestRectangleArea(vector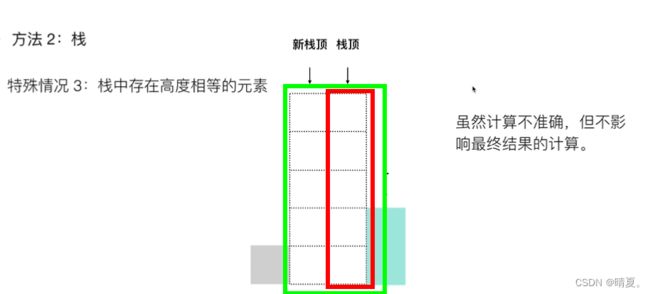

class Solution {
public:
int largestRectangleArea(vector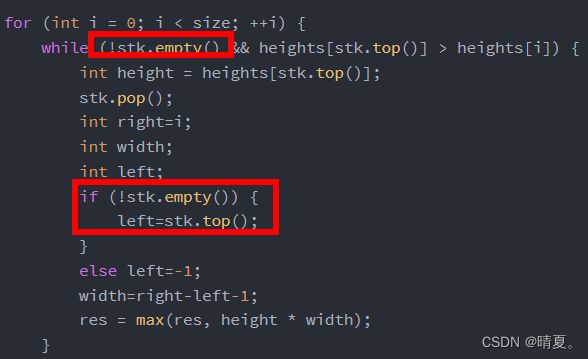
class Solution {
public:
int largestRectangleArea(vector94.二叉树的中序遍历
class Solution {
public:
vector96.不同的二叉搜索树
128.最长连续序列
2.遍历数组中的每个元素num,然后以num为起点,每次+1向后遍历num+1,num+2,num+3...,判断这些元素是否存在于数组中。假设找到的最大的连续存在的元素为num+x,那么这个连续序列的长度即为x+1。最后将每个num所开始序列长度取个最大值即可。class Solution {
public:
int longestConsecutive(vector130.被围绕的区域



class Solution {
public:
int n, m;
void dfs(vector136.只出现一次的数字


class Solution {
public:
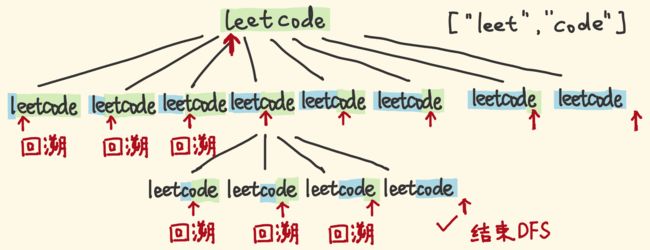
int singleNumber(vector139.单词拆分


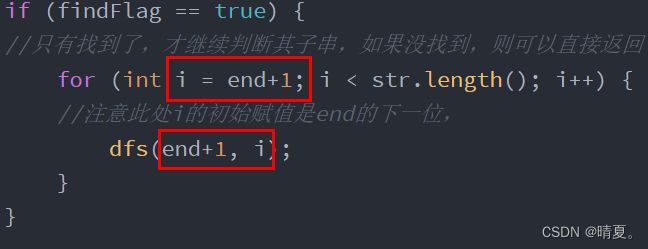
class Solution {
public:
string str;//待检查的字符串
vector
class Solution {
public:
string str;//待检查的字符串
vectorclass Solution {
public:
string str;//待检查的字符串
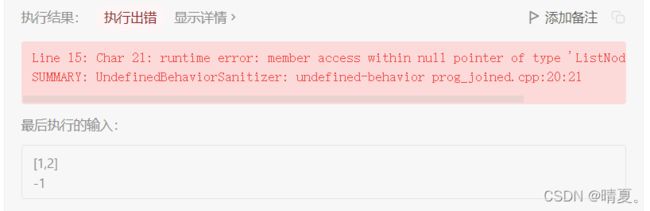
vector141.环形链表
class Solution {
public:
bool hasCycle(ListNode *head) {
if(head==nullptr)return false;
ListNode *slow=head;
ListNode *fast=head;
//如果有环,则必然相遇,则必然可以跳出循环,如果无环,也可以自然退出while循环
while(fast->next!=nullptr){
fast=fast->next->next;
slow=slow->next;
if(fast==slow)return true;
}
return false;
}
};


142.环形链表II

/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *detectCycle(ListNode *head) {
if(head==nullptr)return nullptr;
ListNode *slow=head;
ListNode *fast=head;
while(fast&&fast->next!=nullptr){
fast=fast->next->next;
slow=slow->next;
if(fast==slow){
ListNode *ptr=head;
while(ptr!=slow){
slow=slow->next;
ptr=ptr->next;
}
return ptr;
}
}
return nullptr;
}
};146.LRU缓存(待补充完整)



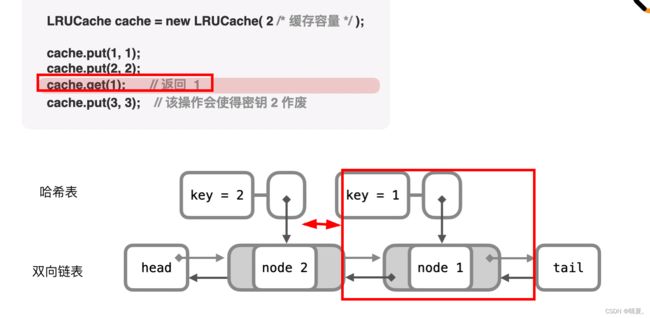

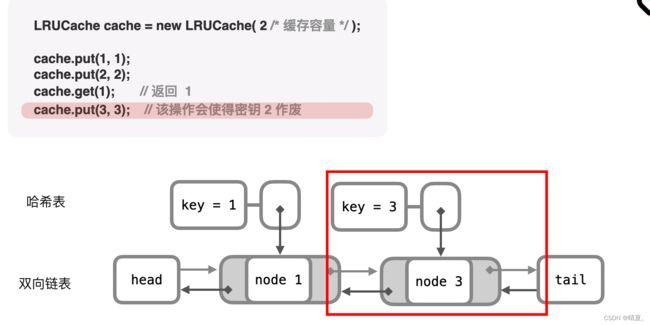
152.乘积最大子数组(lookAnswer)


class Solution {
public:
int maxProduct(vector155.最小栈
class MinStack {
public:
stack198.打家劫舍


class Solution {
public:
int rob(vectorclass Solution {
public:
int rob(vector200.岛屿数量(待补充)



207.课程表(待补充)




215.数组中的第k大元素
221.最大正方形

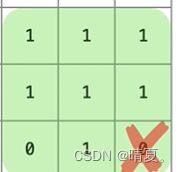
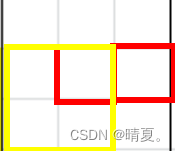
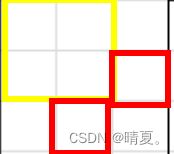
class Solution {
public:
int maximalSquare(vector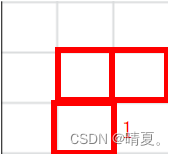
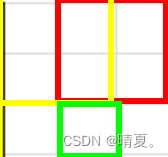



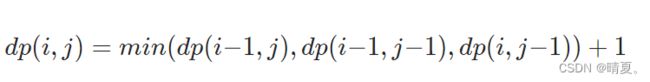
class Solution {
public:
int maximalSquare(vector226.翻转二叉树
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
TreeNode* invertTree(TreeNode* root) {
if(root==nullptr){
return nullptr;
}
invertTree(root->left);
invertTree(root->right);
TreeNode *tmp=root->left;
root->left=root->right;
root->right=tmp;
return root;
}
};234.回文链表
class Solution {
ListNode* frontPointer;
public:
bool recursivelyCheck(ListNode* currentNode) {
if (currentNode == nullptr)return true;
else {
//如果当前结点不为空,即没有走到尽头,则调用子函数去递归
bool flag=recursivelyCheck(currentNode->next);
//用一个变量去储存子函数递归的结果是否成功
if (flag==false) {
return false;
//如果子函数是失败的,那么我这个上级也理应是失败了
}
else if (currentNode->val != frontPointer->val) {
//else if里的语句是,如果子函数没失败,那就看看我的工作有没有失败,即判断结点是否相同。如果不匹配,说明失败从我这一步开始。
return false;
}
//如果失败会在上面return,如果走到这一步说明没失败,没失败就继续让front结点后移。并且返回真,说明我当前这步成功了。
frontPointer = frontPointer->next;
return true;
}
}
bool isPalindrome(ListNode* head) {
frontPointer = head;
return recursivelyCheck(head);
}
};
class Solution {
public:
bool isPalindrome(ListNode* head) {
if (head == nullptr) {
return true;
}
// 找到前半部分链表的尾节点并反转后半部分链表
ListNode* firstHalfEnd = endOfFirstHalf(head);
ListNode* secondHalfStart = reverseList(firstHalfEnd->next);
// 判断是否回文
ListNode* p1 = head;
ListNode* p2 = secondHalfStart;
bool result = true;
while (result && p2 != nullptr) {
if (p1->val != p2->val) {
result = false;
}
p1 = p1->next;
p2 = p2->next;
}
// 还原链表并返回结果
firstHalfEnd->next = reverseList(secondHalfStart);
return result;
}
ListNode* reverseList(ListNode* head) {
ListNode* prev = nullptr;
ListNode* curr = head;
while (curr != nullptr) {
ListNode* nextTemp = curr->next;
curr->next = prev;
prev = curr;
curr = nextTemp;
}
return prev;
}
ListNode* endOfFirstHalf(ListNode* head) {
ListNode* fast = head;
ListNode* slow = head;
while (fast->next != nullptr && fast->next->next != nullptr) {
fast = fast->next->next;
slow = slow->next;
}
return slow;
}
};
236. 二叉树的最近公共祖先

/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if (root == null) return null;
// 如果p,q为根节点,则公共祖先为根节点
if (root.val == p.val || root.val == q.val) return root;
// 如果p,q在左子树,则公共祖先在左子树查找
if (find(root.left, p) && find(root.left, q)) {
return lowestCommonAncestor(root.left, p, q);
}
// 如果p,q在右子树,则公共祖先在右子树查找
if (find(root.right, p) && find(root.right, q)) {
return lowestCommonAncestor(root.right, p, q);
}
// 如果p,q分属两侧,则公共祖先为根节点
return root;
}
private boolean find(TreeNode root, TreeNode c) {
if (root == null) return false;
if (root.val == c.val) {
return true;
}
return find(root.left, c) || find(root.right, c);
}
}238.除自身以外数组的乘积



class Solution {
public:
vectorclass Solution {
public:
vector239.滑动窗口最大值


class Solution {
public:
vector240.搜索二维矩阵 2
[1, 4, 7, 11, 15],
[2, 5, 8, 12, 19],
[3, 6, 9, 16, 22],
[10, 13, 14, 17, 24],
[18, 21, 23, 26, 30]
target < 15, 去掉当前列, cur = 11
[1, 4, 7, 11],
[2, 5, 8, 12],
[3, 6, 9, 16],
[10, 13, 14, 17],
[18, 21, 23, 26]
target < 11, 去掉当前列, cur = 7
[1, 4, 7],
[2, 5, 8],
[3, 6, 9],
[10, 13, 14],
[18, 21, 23]
[2, 5, 8],
[3, 6, 9],
[10, 13, 14],
[18, 21, 23]
[3, 6, 9],
[10, 13, 14],
[18, 21, 23] class Solution {
public:
bool searchMatrix(vector253.会议室II

class Solution {
public int minMeetingRooms(int[][] intervals) {
//创建开会和散会的数组并进行填充
int[] start = new int[intervals.length];
int[] end = new int[intervals.length];
for(int i = 0;i < intervals.length;i++){
start[i] = intervals[i][0];
end[i] = intervals[i][1];
}
//对开会和散会的数组进行排序
Arrays.sort(start);
Arrays.sort(end);
//定义开会的个数和散会的个数
int i = 0,j = 0;
//定义当前还在使用的会议室数
int curMeeting = 0;
int answer = 0;
while(i < intervals.length && j < intervals.length){
//当start[i] < end[j]时,说明会议未结束,需要开辟新会议室
if(start[i] < end[j]){
i++;
curMeeting++;
}else{
j++;
curMeeting--;
}
answer = Math.max(curMeeting,answer);
}
return answer;
}
}
279.完全平方数

for(int j=1;j*j<=i;j++){
int minFi=INT_MAX;
minFi=min(minFi,f(i-j*j));
}
f(i)=minFi+1;class Solution {
public:
int numSquares(int n) {
vector283.移动零
class Solution {
public:
void moveZeroes(vector
class Solution {
public void moveZeroes(int[] nums) {
if(nums==null) {
return;
}
//两个指针i和j
int j = 0;
for(int i=0;i
class Solution {
public:
void moveZeroes(vector287.寻找重复数字
297.二叉树的序列化与反序列化
300.最长递增子序列

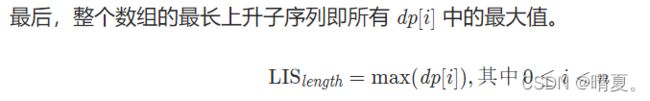
class Solution {
public:
int lengthOfLIS(vector301.删除无效的括号(lookAnswer&&todo)

class Solution {
public:
vector309. 最佳买卖股票时机含冷冻期





have[i][0]=max(have[i-1][0],no[i-1][0]-prices[i]);
vectorclass Solution {
public:
int maxProfit(vector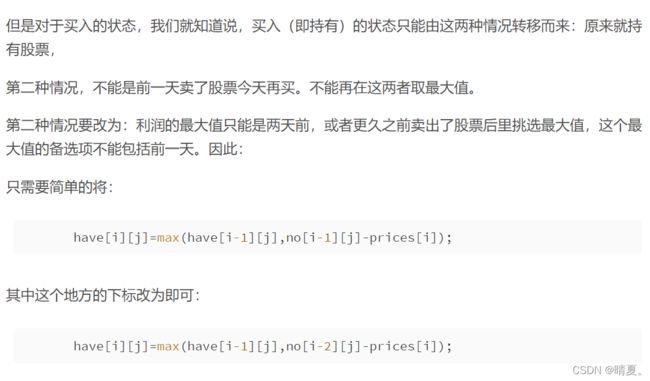
347.前 K 个高频元素(todo)
补充一下求最小的K个数TOPk的问题的求法及代码
(结果存储在vectorclass Solution {
public:
static bool cmp(pair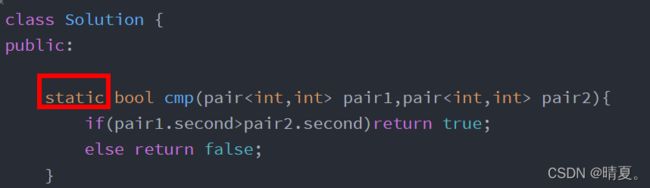
#include class Solution {
public:
class myComparison{
public:
bool operator()(pair399.除法求值(待补充)
int fa[MAXN];
void init(int n)
{
for (int i = 1; i <= n; ++i)
fa[i] = i;
}
void findFa(int x){
if(x==fa[x])return x;
else {
//如果当前结点不是最终的父节点,那么还需要继续往回找,并且使用路径压缩算法将该该结点的父结点设置为最终的父结点
fa[x]=findFa(fa[x]);
return fa[x];
}
}
void merge(int i,int j){
//合并i和j所在的集合很简单,将i集合的代表元素的父结点设置为j集合代表元素即可。
fa[findFa(i)]=findFa(j);
}406. 根据身高重建队列(lookAnswer)



416.分割等和子集

class Solution {
public:
bool canPartition(vector438.找到字符串中所有字母异位词

class Solution {
public:
vector448.找到所有数组中消失的数字
class Solution {
public:
vectorclass Solution {
public:
vector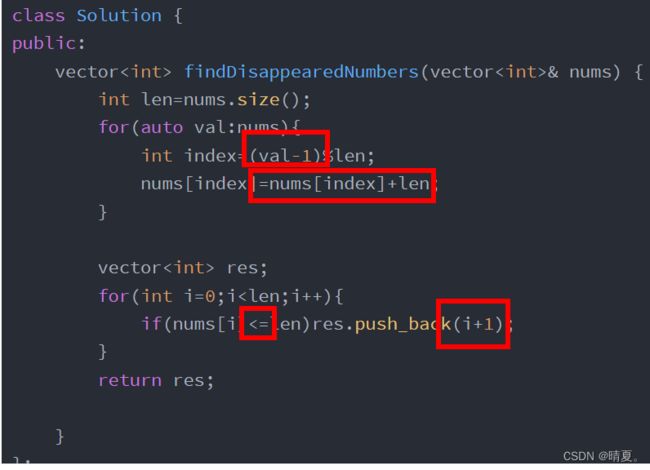
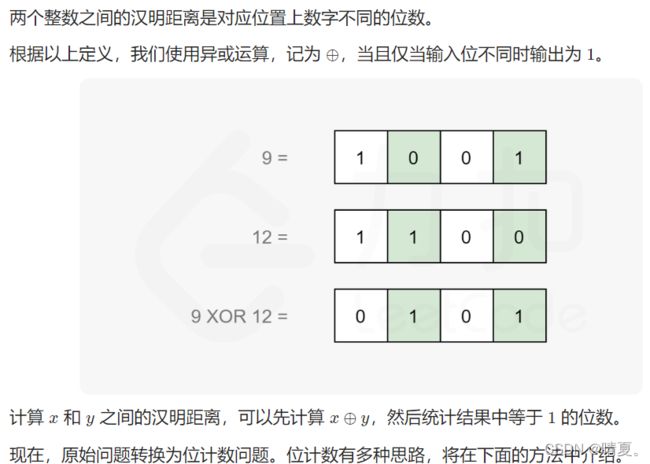
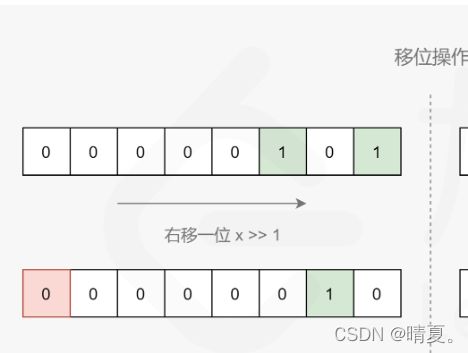
461.汉明距离


class Solution {
public:
int hammingDistance(int x, int y) {
int s = x ^ y, ret = 0;
while (s) {
ret += s & 1;
s >>= 1;
}
return ret;
}
};
494.目标和

class Solution {
public:
int count = 0;
int findTargetSumWays(vector
public static int findTargetSumWays(int[] nums, int s) {
int sum = 0;
for (int i = 0; i < nums.length; i++) {
sum += nums[i];
}
// 绝对值范围超过了sum的绝对值范围则无法得到
if (Math.abs(s) > Math.abs(sum)) return 0;
int len = nums.length;
// - 0 +
int t = sum * 2 + 1;
int[][] dp = new int[len][t];
// 初始化
if (nums[0] == 0) {
dp[0][sum] = 2;
} else {
dp[0][sum + nums[0]] = 1;
dp[0][sum - nums[0]] = 1;
}
for (int i = 1; i < len; i++) {
for (int j = 0; j < t; j++) {
// 边界
int l = (j - nums[i]) >= 0 ? j - nums[i] : 0;
int r = (j + nums[i]) < t ? j + nums[i] : 0;
dp[i][j] = dp[i - 1][l] + dp[i - 1][r];
}
}
return dp[len - 1][sum + s];
}
538.把二叉树转化为累加树
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int sum=0;
TreeNode* convertBST(TreeNode* root) {
if(!root){return nullptr;}
convertBST(root->right);
sum+=root->val;
root->val=sum;
convertBST(root->left);
return root;
}
};543.二叉树的直径
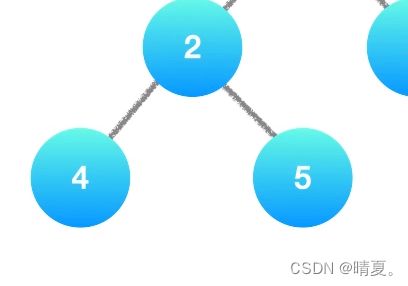
int depth(TreeNode* rt){
if (rt == NULL) {
return 0; // 访问到空节点了,返回0
}
int L = depth(rt->left); // 左儿子为根的子树的深度
int R = depth(rt->right); // 右儿子为根的子树的深度
return max(L, R) + 1; // 返回该节点为根的子树的深度
}
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int maxLen=0;
int diameterOfBinaryTree(TreeNode* root) {
track(root);
return maxLen-1;//为什么要减一呢?因为这个计算出来的是包含的结点数,减一则变成了长度
}
int track(TreeNode* root){
if(root==nullptr){
return 0;
}
int left=track(root->left);
int right=track(root->right);
maxLen=max(maxLen,left+right+1);
int height=max(left,right)+1;
return height;
}
};560.和为K的子数组
617.合并二叉树
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int sum=0;
TreeNode* mergeTrees(TreeNode* root1, TreeNode* root2) {
if(root1==nullptr&&root2==nullptr){
return nullptr;
}
if(root1==nullptr)return root2;
else if(root2==nullptr)return root1;
TreeNode* root=new TreeNode(root1->val+root2->val);
root->left=mergeTrees(root1->left,root2->left);
root->right=mergeTrees(root1->right,root2->right);
return root;
}
};
621.任务调度器




class Solution {
public:
int leastInterval(vector647.回文子串
class Solution {
public:
int countSubstrings(string s) {
int num = 0;
int n = s.size();
for(int i=0;i 739.每日温度
class Solution {
public:
vector

