pandas数据分析41——不同地区不同城市数据分级统计汇总
案例背景
实习一段时间,发现很多领导用Excel喜欢添加一个汇总行,若只有一个类别的汇总很简单,但是多个类别嵌套,不同层级嵌套都要进行汇总行添加,那就有点麻烦了,这个案例就是教大家怎么模板化输出带汇总的表。
代码实现
生成数据
先生成一个案例数据,不同地区,不同城市,不同销售商品:
import pandas as pd
from faker import Faker
import random
fake = Faker()
# 假设的销售地区列表
regions = ['华北', '华东', '华南', '华中', '西北', '西南', '东北']
# 商品示例列表
products = ['电视', '冰箱', '洗衣机', '空调']
# 根据地区生成对应的城市列表
region_cities = {
'华北': ['北京', '天津', '石家庄'],
'华东': ['上海', '南京', '杭州'],
'华南': ['广州', '深圳', '海口'],
'华中': ['武汉', '长沙', '郑州'],
'西北': ['西安', '兰州', '银川'],
'西南': ['成都', '重庆', '昆明'],
'东北': ['沈阳', '大连', '哈尔滨']
}
# 生成数据集
def generate_data(num_records):
data = []
for _ in range(num_records):
region = random.choice(regions)
city = random.choice(region_cities[region])
product = random.choice(products)
amount = round(random.uniform(1000, 5000), 2) # 生成金额
quantity = random.randint(1, 100) # 生成销售数量
data.append([region, city, product, amount, quantity])
return data
# 使用DataFrame存储数据
df = pd.DataFrame(generate_data(1000), columns=['销售地区', '销售城市', '销售商品', '销售金额', '销售数量'])
print(df.shape)
df.head()
本想用Faker库生成的,但是gpt直接random库搞定了...这个数据集还是很好用的,1000条。
一层汇总
一层就是指不同地区,或者不同商品进行一个简单的汇总,例如我们计算不同销售地区的所有商品的销售金融和数量汇总,然后加上一个汇总行:
#一层
df.groupby('销售地区').sum(numeric_only=True).T.assign(汇总=lambda x:x.sum(1)).T
上面是统计不同的地区,这种方法直观一点,然后可以使用数据透视功能也行,下面统计不同商品
pd.pivot_table(df,index='销售商品',values=['销售金额','销售数量'],aggfunc='sum',margins=True,margins_name=f"合计")
上面是一层,若领导想看不同地区不同层数的商销售数量和金额,那就是二层了:
二层汇总
#二层
df.groupby('销售地区').apply(lambda x: pd.pivot_table(x,index='销售城市',values=['销售金额','销售数量'],aggfunc='sum',margins=True,margins_name=f"{x['销售地区'].values[0]}合计"))
也不难,先分类汇总,然后数据透视,对每个地区都进行了合计项的添加。
下面是三层。
三层汇总
有时候领导想看不同地区,不同城市的不同商品的销售数量和金额,还要对每个城市每个地区都进行汇总,3级嵌套有点麻烦,但是也能实现:
def Statistical_summary(df,a,b):
'''作用:三层嵌套汇总
参数说明
a:要汇总的值字段,列表,如:["销售金额",'销售数量']
b:要汇总的维度,列表,如:「"销售地区","销售城市","销售商品"]'''
df1=(
df.pivot_table(values=a,aggfunc='sum',margins=True,margins_name='总计',index=b).reset_index()
.groupby(b[0]).apply(lambda x:pd.pivot_table(x,index=b[1:],values=a,aggfunc='sum',margins=True,margins_name=f'{x[b[0]].values[0]}合计')).reset_index()
.groupby(b[:2],sort=False)
.apply(lambda y: pd.pivot_table(y,index=b[-1],values=a,aggfunc='sum',margins=True,margins_name=f'{y[b[1]].values[0]}小计'))
)
return df1[~df1.index.get_level_values(-1).str.endswith(('合计小计'))]
Statistical_summary(df,['销售金额','销售数量'],['销售地区','销售城市','销售商品']).head(20)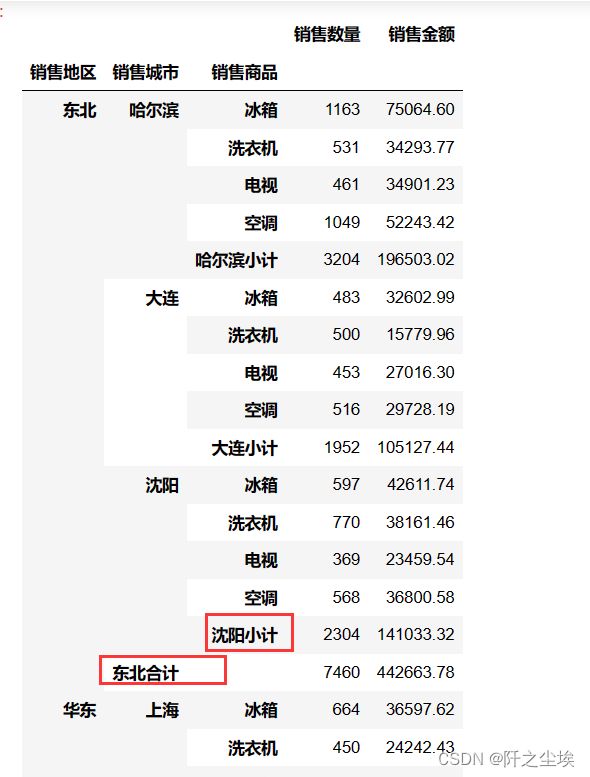
这样不同的城市和不同的地区合计都有,一目了然,可以直接导出Excel表。
四层五层也是差不多的思路,分组聚合然后数据透视,多弄几次。