TDengine学习笔记
文章目录
- 1. 基本概念
-
- 1.1 表设计的优点
- 2. 开发指南
-
- 2.1 建立连接
-
- 2.1.1 原生连接
- 2.1.2 REST 连接
- 2.2 数据建模
-
- 2.2.1 建库
- 2.2.2 创建超级表
- 2.2.3 创建表
- 2.2.4 多列模型 vs 单列模型
- 2.3. 写入数据
-
- 2.3.1 InfluxDB 行协议
- 2.3.2 OpenTSDB 行协议
- 2.3.3 OpenTSDB JSON 格式协议
- 2.4. 查询数据
-
- 2.4.1 多表聚合查询
- 2.4.2 降采样查询、插值
- 2.5. 连续查询
-
- 2.5.1 使用
- 2.5.2 Note
- 2.5.3 管理连续查询
- 2.6. 数据订阅
-
- 2.6.1 提出问题
- 2.6.2 问题解决
-
- 2.6.2.1 创建订阅
- 2.6.2.2 参数解析
- 2.6.2.3 消费数据
- 2.6.2.4 测试订阅功能
- 2.6.2.5 问题
- 2.7. 缓存
- 2.8. 用户自定义函数(难)
- 3. 集群管理
-
- 3.1 集群部署
-
- 3.1.1 准备步骤:
- 3.1.2 启动集群
- 3.2 数据节点管理
-
- 3.2.1 dnode 、vnode 、mnode三者关系
- 3.2.2 数据节点常规操作
- 3.2.3 手动迁移数据节点
-
- 3.2.3.1 参数解析
- 3.2.3.2 Note
- 3.2.4 高可用与负载均衡
-
- 3.2.4.1 高可用
- 3.2.4.2 负载均衡
- 4. SQL手册
-
- 4.1 My
- 4.2 INFO
- 4.3 TIP
- 4.4 NOTE
- 5. 运维指南
-
- 4.3 TIP
- 4.4 NOTE
- 5. 运维指南
观测云简介
数据洞察
基础设施监测:进程资源消耗,类似TOP命令
日志监测:检查日志,过滤,分析查询,安全排查
应用性能监测:程序运行结点的消耗和API请求,SQL语句
CI可视化、用户访问监测、安全巡检
可用性监测:服务结点的响应情况,数据的表现,网络延迟和出错的情况
智能监控:配置告警的检测项
协作、使用场景、SRE套件
可编程性:可二次开发,自定义场景,告警的开发
存储架构
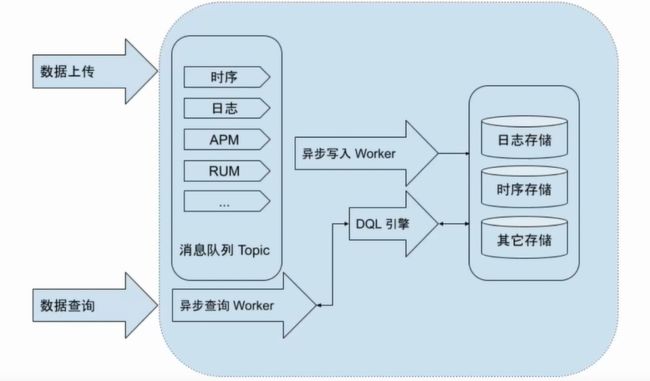
小的知识点
超级表的列分成两部分:动态部分、静态部分
TDengine使用的是Posix标准,所以是UTC-8,表示东八区,而UTC+8表示的是西八区
子查询注意事项

1. 基本概念
- All in One:将数据库、消息队列、缓存、流式计算等功能融合一起,应用无需再集成 Kafka/Redis/HBase/Spark 等软件,大幅降低应用开发和维护成本。
- 无缝集成:不用一行代码,即可与 Telegraf、Grafana、Prometheus、EMQX、HiveMQ、StatsD、collectd、icinga、TCollector、Matlab、R 等第三方工具无缝集成。
1.1 表设计的优点
- 由于不同数据采集点产生数据的过程完全独立,每个数据采集点的数据源是唯一的,一张表也就只有一个写入者,这样就可采用无锁方式来写,写入速度就能大幅提升。
- 对于一个数据采集点而言,其产生的数据是按照时间排序的,因此写的操作可用追加的方式实现,进一步大幅提高数据写入速度。
- 一个数据采集点的数据是以块为单位连续存储的。如果读取一个时间段的数据,它能大幅减少随机读取操作,成数量级的提升读取和查询速度。
- 一个数据块内部,采用列式存储,对于不同数据类型,采用不同压缩算法。
2. 开发指南
- 如果你要基于时序数据做实时的统计分析,包括各种监测看板,那么建议你采用TDengine的连续查询功能,而不用上线Spark, Flink等复杂的流式计算系统。
- 如果你的应用有模块需要消费插入的数据,希望有新的数据插入时,就能获取通知,那么建议你采用TDengine提供的数据订阅功能,而无需专门部署Kafka或其他消息队列软件。
- 在很多场景下(如车辆管理),应用需要获取每个数据采集点的最新状态,那么建议你采用TDengine的cache功能,而不用单独部署Redis等缓存软件。
2.1 建立连接
2.1.1 原生连接
public class JNIConnectExample {
public static void main(String[] args) throws SQLException {
String jdbcUrl = "jdbc:TAOS://localhost:6030?user=root&password=taosdata";
Properties connProps = new Properties();
connProps.setProperty(TSDBDriver.PROPERTY_KEY_CHARSET, "UTF-8");
connProps.setProperty(TSDBDriver.PROPERTY_KEY_LOCALE, "en_US.UTF-8");
connProps.setProperty(TSDBDriver.PROPERTY_KEY_TIME_ZONE, "UTC-8");
Connection conn = DriverManager.getConnection(jdbcUrl, connProps);
System.out.println("Connected");
conn.close();
}
}
// if you want to connect a specified database named "dbName"
// String jdbcUrl = "jdbc:TAOS://localhost:6030/dbName?user=root&password=taosdata";
2.1.2 REST 连接
public static void main(String[] args) throws SQLException {
String jdbcUrl = "jdbc:TAOS-RS://localhost:6041?user=root&password=taosdata";
Connection conn = DriverManager.getConnection(jdbcUrl);
conn.close();
}
使用 REST 连接时,如果查询数据量比较大,还可开启批量拉取功能。
public static void main(String[] args) throws SQLException {
String jdbcUrl = "jdbc:TAOS-RS://localhost:6041?user=root&password=taosdata";
Properties connProps = new Properties();
connProps.setProperty(TSDBDriver.PROPERTY_KEY_BATCH_LOAD, "true");
Connection conn = DriverManager.getConnection(jdbcUrl, connProps);
conn.close();
}
2.2 数据建模
2.2.1 建库
CREATE DATABASE power KEEP 365 DAYS 10 BLOCKS 6 UPDATE 1;
上述语句将创建一个名为 power 的库,这个库的数据将保留 365 天(超过 365 天将被自动删除),每 10 天一个数据文件,内存块数为 6,允许更新数据。
2.2.2 创建超级表
CREATE STABLE meters (ts timestamp, current float, voltage int, phase float) TAGS (location binary(64), groupId int);
| Device ID | Time Stamp | Collected Metrics | Tags | |||
|---|---|---|---|---|---|---|
| Device ID | Time Stamp | current | voltage | phase | location | groupId |
| d1001 | 1538548685000 | 10.3 | 219 | 0.31 | California.SanFrancisco | 2 |
| d1002 | 1538548684000 | 10.2 | 220 | 0.23 | California.SanFrancisco | 3 |
2.2.3 创建表
CREATE TABLE d1001 USING meters TAGS ("California.SanFrancisco", 2);
其中 d1001 是表名,meters 是超级表的表名,后面紧跟标签 Location 的具体标签值 “California.SanFrancisco”,标签 groupId 的具体标签值 2。虽然在创建表时,需要指定标签值,但可以事后修改。
自动建表(在写数据时并不确定某个数据采集点的表是否存在)
INSERT INTO d1001 USING meters TAGS ("California.SanFrancisco", 2) VALUES (now, 10.2, 219, 0.32);
2.2.4 多列模型 vs 单列模型
TDengine 支持多列模型,只要物理量是一个数据采集点同时采集的(时间戳一致),这些量就可以作为不同列放在一张超级表里。
但还有一种极限的设计,单列模型,每个采集的物理量都单独建表,因此每种类型的物理量都单独建立一超级表。比如电流、电压、相位,就建三张超级表。
TDengine 建议尽可能采用多列模型,因为插入效率以及存储效率更高。但对于有些场景,一个采集点的采集量的种类经常变化,这个时候,如果采用多列模型,就需要频繁修改超级表的结构定义,让应用变的复杂,这个时候,采用单列模型会显得更简单。
2.3. 写入数据
2.3.1 InfluxDB 行协议
InfluxDB Line 协议采用一行字符串来表示一行数据。分为四部分:
measurement,tag_set field_set timestamp
分别用英文逗号、半角空格、半角空格来分隔四个部分的数据
measurement 将作为超级表名;
tag_set 将作为标签数据;
field_set 将作为普通列数据;
timestamp 即本行数据对应的主键时间戳。
meters,location=California.LosAngeles,groupid=2 current=13.4,voltage=223,phase=0.29 1648432611249500
Note:
- tag_set 中的所有的数据自动转化为 nchar 数据类型;
- field_set 中的每个数据项都需要对自身的数据类型进行描述, 比如 1.2f代表 float 类型的数值 1.2, 如果不带类型后缀会被当作 double 处理;
- timestamp 支持多种时间精度。写入数据的时候需要用参数指定时间精度,支持从小时到纳秒的 6 种时间精度。
2.3.2 OpenTSDB 行协议
OpenTSDB 行协议同样采用一行字符串来表示一行数据。OpenTSDB 采用的是单列模型,因此一行只能包含一个普通数据列。标签列依然可以有多个。分为四部分:
= [ = ]
- metric 将作为超级表名
- timestamp 本行数据对应的时间戳
- value 度量值,必须为一个数值。对应的列名也是 “value”
- 最后一部分是标签集, 用空格分隔不同标签, 所有标签自动转化为 nchar 数据类型
meters.current 1648432611250 11.3 location=California.LosAngeles groupid=3
2.3.3 OpenTSDB JSON 格式协议
[
{
"metric": "sys.cpu.nice",
"timestamp": 1346846400,
"value": 18,
"tags": {
"host": "web01",
"dc": "lga"
}
},
{
"metric": "sys.cpu.nice",
"timestamp": 1346846400,
"value": 9,
"tags": {
"host": "web02",
"dc": "lga"
}
}
]
2.4. 查询数据
和MySQL差不多
2.4.1 多表聚合查询
通过指定标签的过滤条件,TDengine 提供了一高效的方法将超级表(某一类型的数据采集点)所属的子表进行聚合查询。
示例一
查找加利福尼亚州所有智能电表采集的电压平均值,并按照 location 分组。
SELECT AVG(voltage) FROM meters GROUP BY location;
| avg(voltage) | location |
|---|---|
| 222.000000000 | California.LosAngeles |
| 219.200000000 | California.SanFrancisco |
示例二
查找 groupId 为 2 的所有智能电表过去 24 小时的记录条数,电流的最大值
select count(*) , max(current) from meters where groupId = 2 and ts > now -24h;
| count(*) | max(current) |
|---|---|
| 5 | 13.4 |
2.4.2 降采样查询、插值
通过降采样(down sampling)将采集的数据按时间段进行聚合
TDengine 提供了一个简便的关键词 interval 让按照时间窗口的查询操作变得极为简单
将智能电表 d1001 采集的电流值每 10 秒钟求和
SELECT sum(current) FROM d1001 INTERVAL(10s);
降采样也适用于超级表
将加利福尼亚州所有智能电表采集的电流值每秒钟求和
SELECT SUM(current) FROM meters where location like “California%” INTERVAL(1s);
降采样操作也支持时间偏移
将所有智能电表采集的电流值每秒钟求和,但要求每个时间窗口从 500 毫秒开始
SELECT SUM(current) FROM meters INTERVAL(1s, 500a);
2.5. 连续查询
TDengine 可提供定期自动执行的连续查询(Continuous Query)。每次执行的查询是一个时间窗口,时间窗口随着时间流动向前滑动。
2.5.1 使用
指定时间窗口(time window, 参数 interval)大小和每次前向增量时间(forward sliding times, 参数 sliding)。
以一分钟为时间窗口、30 秒为前向增量统计这些电表的平均电压
每隔 30 秒执行一次来增量计算最近一分钟的数据
create table avg_vol as select avg(voltage) from meters interval(1m) sliding(30s);
会自动创建一个名为
avg_vol的新表,然后每隔 30 秒,TDengine 会增量执行as后面的 SQL 语句,并将查询结果写入这个表中,用户程序后续只要从avg_vol中查询数据即可。
2.5.2 Note
-
查询时间窗口的最小值是 10 毫秒,没有时间窗口范围的上限。
-
此外,TDengine 还支持用户指定连续查询的起止时间。
如果不输入开始时间,连续查询将从第一条原始数据所在的时间窗口开始;
如果没有输入结束时间,连续查询将永久运行;如果用户指定了结束时间,连续查询在系统时间达到指定的时间以后停止运行。比如使用下面的 SQL 创建的连续查询将运行一小时,之后会自动停止。
create table avg_vol as select avg(voltage) from meters where ts > now and ts <= now + 1h interval(1m) sliding(30s); -
为了尽量避免原始数据延迟写入导致的问题,TDengine 中连续查询的计算有一定的延迟。也就是说,一个时间窗口过去后,TDengine 并不会立即计算这个窗口的数据,所以要稍等一会(一般不会超过 1 分钟)才能查到计算结果。
2.5.3 管理连续查询
用户可在控制台中通过 show streams 命令来查看系统中全部运行的连续查询,并可以通过 kill stream 命令杀掉对应的连续查询。
2.6. 数据订阅
TDengine 在内部严格按照数据时间序列单调递增的方式保存数据。本质上来说,TDengine 中每一张表均可视为一个标准的消息队列。
TDengine中与订阅相关的API有以下三个:
taos_subscribe、``taos_consume、taos_unsubscribe`
2.6.1 提出问题
我们希望当某个电表的电流超过一定限制(比如 10A)后能得到通知并进行一些处理==(也就是告警)==
有两种方法:一是分别对每张子表进行查询,每次查询后记录最后一条数据的时间戳,后续只查询这个时间戳之后的数据:
select * from D1001 where ts > {last_timestamp1} and current > 10;
select * from D1002 where ts > {last_timestamp2} and current > 10;
存在的问题是:随着电表数量的增加,查询数量也会增加,客户端和服务端的性能都会受到影响,当电表数增长到一定的程度,系统就无法承受了。
另一种方法是对超级表进行查询。这样,无论有多少电表,都只需一次查询:
select * from meters where ts > {last_timestamp} and current > 10;
存在的问题是:如何选择 last_timestamp,因为数据产生的时间(timeStamp)和数据入库的时间不一致。
如果选用最慢的一台电表的数据的时间戳作为last_timestamp,就可能会重复读取其他电表的数据;
如果选用最快的一台电表的数据的时间戳作为last_timestamp,就可能造成其他电表的数据的遗漏。
2.6.2 问题解决
TDengine的订阅功能解决了此问题
2.6.2.1 创建订阅
首先是使用 taos_subscribe 创建订阅:
TAOS_SUB* tsub = NULL;
if (async) { // 异步
// create an asynchronized subscription, the callback function will be called every 1s
tsub = taos_subscribe(taos, restart, topic, sql, subscribe_callback, &blockFetch, 1000);
} else { // 同步
// create an synchronized subscription, need to call 'taos_consume' manually
tsub = taos_subscribe(taos, restart, topic, sql, NULL, NULL, 0);
}
上面的代码会根据从命令行获取的参数 async 的值来决定使用哪种方式。
这里,同步的意思是用户程序要直接调用 taos_consume 来拉取数据,而异步则由 API 在内部的另一个线程中调用 taos_consume,然后把拉取到的数据交给回调函数 subscribe_callback去处理。(注意,subscribe_callback 中不宜做较为耗时的操作,否则有可能导致客户端阻塞等不可控的问题。)
2.6.2.2 参数解析
-
参数
taos是一个已经建立好的数据库连接,在同步模式下无特殊要求。但在异步模式下,需要注意它不会被其它线程使用,否则可能导致不可预计的错误,因为回调函数在 API 的内部线程中被调用,而 TDengine 的部分 API 不是线程安全的。 -
参数
sql是查询语句,可以在其中使用 where 子句指定过滤条件。 -
订阅的
topic实际上是它的名字,因为订阅功能是在客户端 API 中实现的,所以没必要保证它全局唯一,但需要它在一台客户端机器上唯一。如果名为
topic的订阅不存在,参数restart没有意义;但如果用户程序创建这个订阅后退出,当它再次启动并重新使用这个
topic时,restart就会被用于决定是从头开始读取数据,还是接续上次的位置进行读取。本例中,如果restart是 true,用户程序肯定会读到所有数据。但如果这个订阅之前就存在了,并且已经读取了一部分数据,且
restart是 false,用户程序就不会读到之前已经读取的数据了。 -
参数
taos_subscribe的最后一个参数是以毫秒为单位的轮询周期。在同步模式下,如果前后两次调用
taos_consume的时间间隔小于此时间,taos_consume会阻塞,直到间隔超过此时间。异步模式下,这个时间是两次调用回调函数的最小时间间隔。 -
参数
taos_subscribe的倒数第二个参数用于用户程序向回调函数传递附加参数,订阅 API 不对其做任何处理,只原样传递给回调函数。此参数在同步模式下无意义。
2.6.2.3 消费数据
if (async) {
getchar();
} else while(1) {
TAOS_RES* res = taos_consume(tsub);
if (res == NULL) {
printf("failed to consume data.");
break;
} else {
print_result(res, blockFetch);
getchar();
}
}
这里是一个 while 循环,用户每按一次回车键就调用一次 taos_consume,而 taos_consume 的返回值是查询到的结果集,与 taos_use_result 完全相同
print_result函数没看懂
2.6.2.4 测试订阅功能
package com.taosdata.example.test;
import com.taosdata.jdbc.TSDBConnection;
import com.taosdata.jdbc.TSDBDriver;
import com.taosdata.jdbc.TSDBResultSet;
import com.taosdata.jdbc.TSDBSubscribe;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSetMetaData;
import java.sql.SQLException;
import java.util.Properties;
import java.util.concurrent.TimeUnit;
public class SubscribeDemo {
// topic 是一个订阅的名字,可以自定义,但是需要保证在一台机器上不重复
private static final String topic = "topic-meter-current-bg-10";
// sql 是订阅的条件
private static final String sql = "select * from meters where current > 10";
public static void main(String[] args) {
Connection connection = null;
TSDBSubscribe subscribe = null;
/**
* 数据订阅debug记录
* 1、首先创建一个TSDBSubscribe对象
* 2、设置订阅100次,每次订阅间隔1秒,防止频繁回调
* 3、消费数据,将符合sql结果的数据存入TSDBResultSet对象中
* 4、设置回调函数,回调函数中输出订阅结果
* 5、每成功订阅一次就count++,订阅不结束,程序不结束
* 6、当订阅数据获取到100次,则结束订阅
*/
try {
// 获取连接对象
Class.forName("com.taosdata.jdbc.TSDBDriver");
Properties properties = new Properties();
properties.setProperty(TSDBDriver.PROPERTY_KEY_CHARSET, "UTF-8");
properties.setProperty(TSDBDriver.PROPERTY_KEY_TIME_ZONE, "UTC-8");
String jdbcUrl = "jdbc:TAOS://192.168.116.201:6030/power?user=root&password=taosdata";
connection = DriverManager.getConnection(jdbcUrl, properties);
// 创建订阅对象
// 但如果用户程序创建这个订阅后退出,当它再次启动并重新使用这个 `topic` 时,
// `restart` 就会被用于决定是从头开始读取数据,还是接续上次的位置进行读取。
// 本例中,如果 `restart` 是 true,用户程序肯定会读到所有数据。
// 我们设置为false,只订阅最新的数据。
subscribe = ((TSDBConnection) connection).subscribe(topic, sql, false);
// 设置订阅次数
int count = 0;
while (count < 100) { // 订阅100次
// wait 1 second to avoid frequent calls to consume
TimeUnit.SECONDS.sleep(1);
// consume 详细的可debug进去查看消费流程
TSDBResultSet resultSet = subscribe.consume();
if (resultSet == null) {
continue;
}
// 获取结果集的元数据做一个简单的输出
ResultSetMetaData metaData = resultSet.getMetaData();
while (resultSet.next()) {
int columnCount = metaData.getColumnCount();
for (int i = 1; i <= columnCount; i++) {
System.out.print(metaData.getColumnLabel(i) + ": " + resultSet.getString(i) + "\t");
}
System.out.println();
count++;
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (null != subscribe)
// close subscribe
subscribe.close(true);
if (connection != null)
connection.close();
} catch (SQLException throwable) {
throwable.printStackTrace();
}
}
}
}
2.6.2.5 问题
REST 连接没有订阅功能,使用原生连接可以体验 TDengine 的全部功能。
但我本机REST连接可以连接到TDengine,但是原生连接失败
数据订阅暂时没实现
问题解决
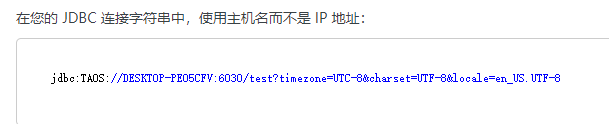
$ systemctl taos adapter
报错:JNI ERROR (2351): failed to create subscription
去本地配置host,然后再下图:
2.7. 缓存
TDengine 采用时间驱动缓存管理策略(First-In-First-Out,FIFO),又称为写驱动的缓存管理机制,直接将最近写入的数据保存在系统的缓存中。当缓存达到临界值的时候,将最早的数据批量写入磁盘。一般意义上来说,对于物联网数据的使用,用户最为关心最近产生的数据,即当前状态。TDengine 充分利用了这一特性,将最近到达的(当前状态)数据保存在缓存中。
Note
需要注意的是,TDengine 重启以后系统的缓存将被清空,之前缓存的数据均会被批量写入磁盘,缓存的数据将不会像专门的 key-value 缓存系统再将之前缓存的数据重新加载到缓存中。
TDengine 分配固定大小的内存空间作为缓存空间,缓存空间可根据应用的需求和硬件资源配置。通过适当的设置缓存空间,TDengine 可以提供极高性能的写入和查询的支持。
可以通过函数 last_row() 快速获取一张表或一张超级表的最后一条记录,这样很便于在大屏显示各设备的实时状态或采集值。例如:
select last_row(voltage) from meters where location=‘California.SanFrancisco’;
2.8. 用户自定义函数(难)
先C语言定义UDF,(有规定的参数模板)
然后编译,(gcc -g -O0 -fPIC -shared add_one.c -o add_one.so)
再在TDengine中使用:
-
创建:CREATE FUNCTION add_one AS “/home/taos/udf_example/add_one.so” OUTPUTTYPE INT;
-
管理:删除(DROP FUNCTION ids(X);)、查看(SHOW FUNCTIONS;)
-
调用:SELECT X© FROM table/stable;
3. 集群管理
TDengine 支持集群,提供水平扩展的能力。如果需要获得更高的处理能力,只需要多增加节点即可。
TDengine 采用虚拟节点技术,将一个节点虚拟化为多个虚拟节点,以实现负载均衡。同时,TDengine可以将多个节点上的虚拟节点组成虚拟节点组,通过多副本机制,以保证供系统的高可用。
进行了一些实践操作,但卡壳了,后续再学习
3.1 集群部署
3.1.1 准备步骤:
1.配置FQDN,在每个物理节点的hosts中都要进行修改;
2.打开6030-6042的TCP/UDP协议端口;(systemctl stop firewalld)
3.安装TDengine(版本一致),先不启动taosd,第一个物理节点直接回车创建新的,后续的输入任何一个在线的物理节点的FQDN:端口号;
4.检查集群里的各个节点是否能互通;
5.修改taso.cfg,每个节点的配置文件都需要修改,
// firstEp 是每个数据节点首次启动后连接的第一个数据节点
firstEp h1.taosdata.com:6030// 必须配置为本数据节点的 FQDN,如果本机只有一个 hostname,可注释掉本项
fqdn h1.taosdata.com// 配置本数据节点的端口号,缺省是 6030
serverPort 6030// 副本数为偶数的时候,需要配置,请参考《Arbitrator 的使用》的部分
arbitrator ha.taosdata.com:6042在每个数据节点,firstEp 需全部配置成一样,但 fqdn 一定要配置成其所在数据节点的值
3.1.2 启动集群
在第一个节点里面使用:CREATE DNODE “h2.taos.com:6030”;
3.2 数据节点管理
3.2.1 dnode 、vnode 、mnode三者关系
dnode:数据节点,是 TDengine 服务器侧执行代码 taosd 在物理节点上的一个运行实例,一个工作的系统必须有至少一个数据节点。在系统中的唯一标识由实例的End Point (EP )决定。
vnode:虚拟节点,保存采集的时序数据,而且查询、计算都在这些节点上进行。为便于负载均衡、数据恢复、支持异构环境,TDengine 将一个物理节点根据其计算和存储资源切分为多个 vnode。这些 vnode 的管理是 TDengine 自动完成的,对应用完全透明。
vgroup:虚拟节点组,不同数据节点上的 vnode 可以组成一个虚拟节点组(vnode group)来保证系统的高可靠。
mnode:管理节点,dnode会报告状态(包括硬盘空间、内存大小、CPU、网络、虚拟节点个数等),因此 mnode 了解整个集群的状态。基于整体状态,当 mnode 发现某个 dnode 负载过重,它会将 dnode 上的一个或多个 vnode 挪到其他 dnode。在挪动过程中,对外服务继续进行,数据插入、查询和计算操作都不受影响。负载均衡操作结束后,应用也无需重启,将自动连接新的 vnode。
3.2.2 数据节点常规操作
show、create 、drop dnode;
WARNING
数据节点一旦被 drop 之后,不能重新加入集群。需要将此节点重新部署(清空数据文件夹)。
集群在完成 drop dnode 操作之前,会将该 dnode 的数据迁移走。 请注意 drop dnode 和 停止 taosd 进程是两个不同的概念,不要混淆:因为删除 dnode 之前要执行迁移数据的操作,因此被删除的 dnode 必须保持在线状态。待删除操作结束之后,才能停止 taosd 进程。
一个数据节点被 drop 之后,其他节点都会感知到这个 dnodeID 的删除操作,任何集群中的节点都不会再接收此 dnodeID 的请求。 dnodeID 是集群自动分配的,不得人工指定。它在生成时是递增的,不会重复。
3.2.3 手动迁移数据节点
$ ALTER DNODE <source-dnodeId> BALANCE "VNODE:-DNODE:" ;
3.2.3.1 参数解析
source-dnodeId 是源 dnodeId,也就是待迁移的 vnode 所在的 dnodeID;
vgId 可以通过 SHOW VGROUPS 获得,列表的第一列;
dest-dnodeId 是目标 dnodeId。
举个例子:
先通过show vgroups;查看分布情况
| vgId | tables | status | onlines | v1_dnode | v1_status | compacting |
|---|---|---|---|---|---|---|
| 14 | 5000 | ready | 1 | 2 | master | 0 |
| 15 | 5000 | ready | 1 | 2 | master | 0 |
| 16 | 5001 | ready | 1 | 2 | master | 0 |
| 17 | 5001 | ready | 1 | 1 | master | 0 |
观察得到的结果是:dnode2中有3个vgroup,而dnode1中只有1个vgroup,我们想要把vgid为16的vroup从dnode2迁移到dnode1
alter dnode 2 balance “vnode:16-dnode:1”;
结果:DB error: Balance already enabled
表示数据库已经启动了balance选项,无法进行手动迁移,
需要先停止集群,将两个dnode的配置文件的balance的值设为0之后,重新启动集群,再次执行alter dnode
3.2.3.2 Note
只有在集群的自动负载均衡选项关闭时(balance 设置为 0),才允许手动迁移。 只有处于正常工作状态的 vnode 才能被迁移:master/slave;当处于 offline/unsynced/syncing 状态时,是不能迁移的。 迁移前,务必核实目标 dnode 的资源足够:CPU、内存、硬盘。
3.2.4 高可用与负载均衡
3.2.4.1 高可用
无论是 vnode 还是 mnode,都必须配置多个副本。
3.2.4.2 负载均衡
有三种情况,将触发负载均衡,而且都无需人工干预。
-
当一个新数据节点添加进集群时,系统将自动触发负载均衡,一些节点上的数据将被自动转移到新数据节点上,无需任何人工干预。
-
当一个数据节点从集群中移除时,系统将自动把该数据节点上的数据转移到其他数据节点,无需任何人工干预。
-
如果一个数据节点过热(数据量过大),系统将自动进行负载均衡,将该数据节点的一些 vnode 自动挪到其他节点。
当上述三种情况发生时,系统将启动各个数据节点的负载计算,从而决定如何挪动。
负载均衡由参数 balance 控制,它决定是否启动自动负载均衡,0 表示禁用,1 表示启用自动负载均衡。
上面我们提到手动迁移数据节点需要把balace设置为0,就是这个原因。
4. SQL手册
4.1 My
My
- 自动建表语法也支持在一条语句中向多个表插入记录。例如:
INSERT INTO d21001 USING meters TAGS ('California.SanFrancisco', 2) VALUES ('2021-07-13 14:06:34.630', 10.2, 219, 0.32) ('2021-07-13 14:06:35.779', 10.15, 217, 0.33)
d21002 USING meters (groupId) TAGS (2) VALUES ('2021-07-13 14:06:34.255', 10.15, 217, 0.33)
d21003 USING meters (groupId) TAGS (2) (ts, current, phase) VALUES ('2021-07-13 14:06:34.255', 10.27, 0.31);
-
获取当前所在的数据库 ,如果登录的时候没有指定默认数据库,且没有使用USE命令切换,则返回 NULL。
SELECT DATABASE();
-
获取服务器和客户端版本号:
SELECT CLIENT_VERSION(); SELECT SERVER_VERSION();
-
服务器状态检测语句: 如果服务器正常,返回一个数字(例如 1)。如果服务器异常,返回 error code。
SELECT SERVER_STATUS();
-
官网有个小技巧部分:
-- 获取一个超级表所有的子表名及相关的标签信息: SELECT TBNAME, location FROM meters; -- 统计超级表下辖子表数量: SELECT COUNT(TBNAME) FROM meters; -- 以上两个查询均只支持在 WHERE 条件子句中添加针对标签(TAGS)的过滤条件。 暂不支持含列名的四则运算表达式用于条件过滤算子(例如,不支持 where a*2>6;,但可以写 where a>6/2;)。 暂不支持含列名的四则运算表达式作为 SQL 函数的应用对象(例如,不支持 select min(2*a) from t;,但可以写 select 2*min(a) from t;)。 -
关于嵌套查询,官网写了很多规则
4.2 INFO
INFO
- 批量建表方式要求数据表必须以超级表为模板。
- 如果不指定列,也即使用全列模式——那么在 VALUES 部分提供的数据,必须为数据表的每个列都显式地提供数据。全列模式写入速度会远快于指定列,因此建议尽可能采用全列写入方式,此时空列可以填入 NULL。
4.3 TIP
TIP
- TDengine 对 SQL 语句中的英文字符不区分大小写,自动转化为小写执行。因此用户大小写敏感的字符串及密码,需要使用单引号将字符串引起来。
aBc和abc是不同的表名,但是 abc 和 aBc 是相同的表名。
4.4 NOTE
NOTE
-
SQL 语句中的数值类型将依据是否存在小数点,或使用科学计数法表示,来判断数值类型是否为整型或者浮点型,因此在使用时要注意相应类型越界的情况。例如,9999999999999999999 会认为超过长整型的上边界而溢出,而 9999999999999999999.0 会被认为是有效的浮点数。
-
字符串格式的时间戳写法不受所在 DATABASE 的时间精度设置影响;而长整形格式的时间戳写法会受到所在 DATABASE 的时间精度设置影响——例子中的时间戳在毫秒精度下可以写作 1626164208000,而如果是在微秒精度设置下就需要写为 1626164208000000,纳秒精度设置下需要写为 1626164208000000000。
-
JOIN 语句存在如下限制要求:
-
不支持只对其中一部分表做 GROUP BY。
-
JOIN 查询的不同表的过滤条件之间不能为 OR。
-
JOIN 查询要求连接条件不能是普通列,只能针对标签和主时间字段列(第一列)。
-
5. 运维指南
4.3 TIP
TIP
- TDengine 对 SQL 语句中的英文字符不区分大小写,自动转化为小写执行。因此用户大小写敏感的字符串及密码,需要使用单引号将字符串引起来。
aBc和abc是不同的表名,但是 abc 和 aBc 是相同的表名。
4.4 NOTE
NOTE
-
SQL 语句中的数值类型将依据是否存在小数点,或使用科学计数法表示,来判断数值类型是否为整型或者浮点型,因此在使用时要注意相应类型越界的情况。例如,9999999999999999999 会认为超过长整型的上边界而溢出,而 9999999999999999999.0 会被认为是有效的浮点数。
-
字符串格式的时间戳写法不受所在 DATABASE 的时间精度设置影响;而长整形格式的时间戳写法会受到所在 DATABASE 的时间精度设置影响——例子中的时间戳在毫秒精度下可以写作 1626164208000,而如果是在微秒精度设置下就需要写为 1626164208000000,纳秒精度设置下需要写为 1626164208000000000。
-
JOIN 语句存在如下限制要求:
-
不支持只对其中一部分表做 GROUP BY。
-
JOIN 查询的不同表的过滤条件之间不能为 OR。
-
JOIN 查询要求连接条件不能是普通列,只能针对标签和主时间字段列(第一列)。
-