自整理---JVM笔记
JVM的体系结构
JVM的简单介绍
JDK、JRE、JVM的区别

常见的JVM
-
Hotspot
-oracle官方,我们做实验用的JVM
-
Jrockit
-BEA,曾经号称世界上最快的JVM,被Oracle收购,合并于hotspot
-hotspot深度定制版(收费)
-
J9-IBM
-
Microsoft VM
-
TaobaoVM
-hotspot深度定制版
-
LiqidVM
-直接针对硬件 -
azul zing
-最新垃圾回收业界标杆
JVM—从跨平台的语言到跨语言的平台
一次编译,到处运行 : 当Java源代码成功编译成字节码后,如果想在不同的平台上面运行,则无须再次编译
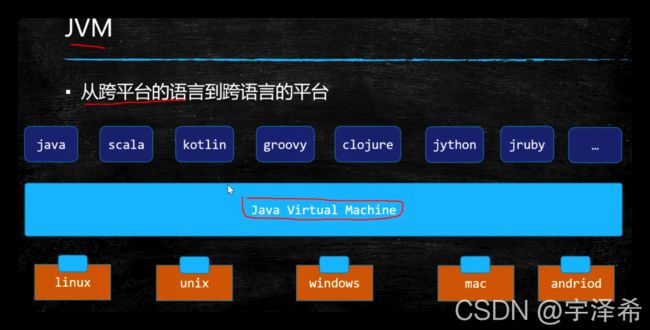
虽然名字叫做Java Virtual Machine,Java虚拟机可不仅仅支持Java语言。任何语言只要编译成.class字节码文件,就可以被JVM识别
JVM体系架构(Hotspo)

程序计数器、本地方法栈、虚拟机栈(灰色区域)是每个线程独有的,不存在垃圾回收。
Native Interface本地方法接口
在内存中专门开辟的一块区域处理标记为native的c语言本地库
Native Method Stack本地方法栈和JVM Stack虚拟机栈
栈是用于描述方法执行的内存模型。其生命周期随着线程结束而结束
JVM Stack和Native Method Stack不同的是本地方法栈服务的对象是JVM执行的native方法,而虚拟机栈服务的是JVM执行的java方法
Native Method Stack(本地方法栈)
JVM Stack(虚拟机栈)
虚拟机栈中存的是每个方法对应的一个栈帧(Frame) ,每个方法的栈帧包含
-
本地变量表(Local Variable Table)本地变量表就放各种具体类型的数值
-
操作数栈(Operand Stack )
对于long的处理(store and load),多数虚拟机的实现都是原子的,没必要加volatile -
动态链接 (Dynamic Linking)
将类属性和方法的符号引用解析为直接引用并指向常量池
-
返回地址(return address)
a() -> b(),方法a调用了方法b, b方法的返回值放在什么地方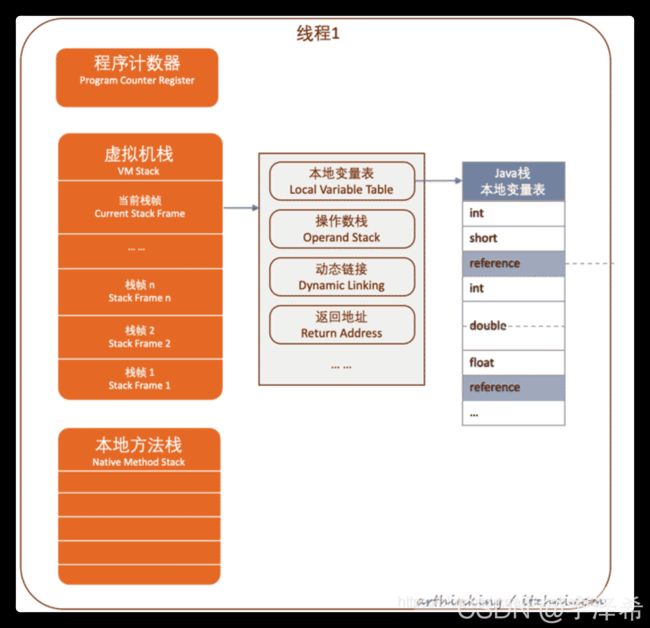
注:注意本地变量表和局部变量表的区别,局部变量表是这个
Execution Engine
执行引擎负责解释命令,提交操作系统执行。
PC程序计数器
用来记录每个线程中的指令执行的位置信息,在多线程的情况下存在CPU时间片的切换和线程的调度,如果没有记录位置会导致线程执行错乱
虚拟机的运行,类似于这样的循环:
while( not end ) {
取PC中的位置,找到对应位置的指令;
执行该指令;
PC ++;
}
方法区
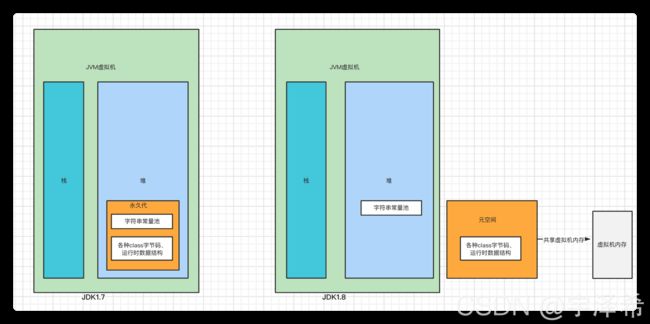
方法区在所有Java虚拟机线程之间共享,它存储每个类的结构信息,各种class,常量池也在其中。
方法区是逻辑概念,实际的JVM内存中不存在方法区。在HotSpot虚拟机中,jdk8之前方法区是永久代,jdk8及之后是元空间
永久带使用的JVM的堆内存,元空间并不在虚拟机中而是使用本机物理内存。
-
永久代Perm Space (JDK version<1.8)
字符串常量位于永久代
不会触发FGC清理
永久代大小启动的时候指定,不能变类的方法的信息大小难以确定,因此给永久带的大小指定比较困难,太小容易出现永久代溢出,太大则容易导致老年代溢出
-
元空间Meta Space (JDK version>=1.8)
字符串常量位于堆
会触发FGC清理
元空间不设定的话,最大就是物理内存
元空间对比永久代最大的好处就是受限于物理内存,永久代非常容易溢出,元空间解决了这个问题
永久代和元空间
-
永久代 存放各种字节码class信息,方法和代码编译后的信息,字节码指令等
-
永久代必须指定大小限制 ;元数据可以设置,也可以不设置,无上限,因为受限于物理内存。
-
字符串常量 1.7 - 在永久代,1.8 - 在堆
-
方法区是逻辑上的概念 ,其实它是:1.7 - 永久代、1.8 - 元数据
字节码常量池,运行时常量池,字符串常量池的区别详见:https://blog.csdn.net/darkLight2017/article/details/117090705
heap堆
堆内存被所有线程共享,主要存放使用new关键字创建的对象。所有对象实例以及数组都要在堆上分配。垃圾收集器根据GC算法收集堆上对象所占用的内存空间(收集的是对象占用的空间而不是对象本身)。
堆内存逻辑上分为两部分:新生代,老年代
JVM Direct Memory
JVM可以直接访问的内核空间的内存 (OS 管理的内存)
通过NIO实现零拷贝 , 提高效率
思考:
如何证明1.7字符串常量位于PermSpace,而1.8位于Heap?
提示:结合GC, 一直创建字符串常量,观察堆,和Metaspace
Class字节码
字节码文件结构
Class文件的总体结构如下:
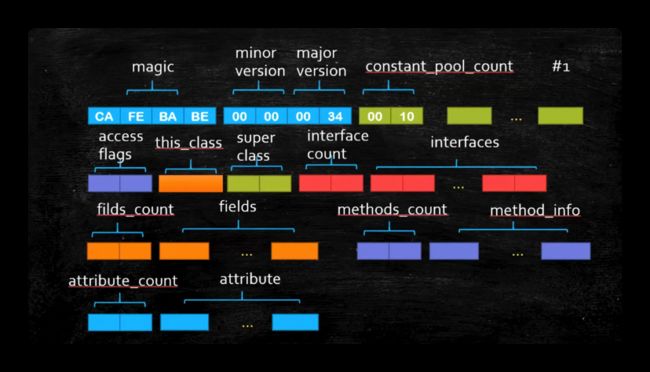
- 魔数
- Class文件版本
- 常量池
- 访问标识(或标志)
- 类索引,父类索引,接口索引集合
- 字段表集合
- 方法表集合
- 属性表集合
魔数
每个字节码文件的开头为 ca fe ba be 永远是这四个字节的固定格式,代表字节码文件的标识符,有了它才能被虚拟机识别
文件版本
用四个字节表示
前两个字节:minor version(副版本)
后两个字节:major version(主版本)
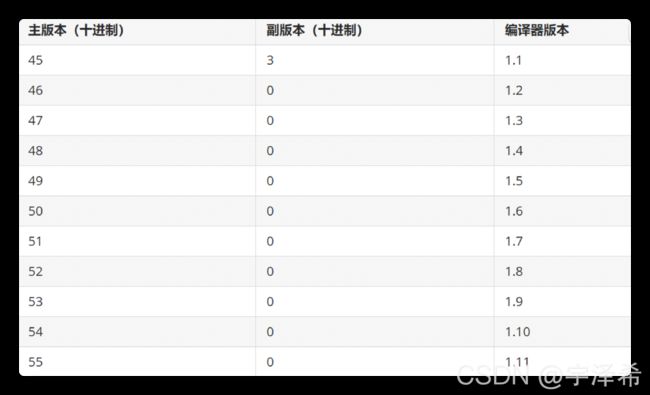
例如jdk1.8中就会用 00 00 00 34 表示
常量池
首先const_pool_count 用两个字节表示的是常量池中常量池的数量
例如 00 10,十六进制的10表示成十进制为16,实际上表示有15个常量。因为系统将第0项常量空出来留作后提拓展
demo:
常量池表:
访问标识
使用两个字节表示,用于识别一些类或者接口层次的访问信息。例如:是Class还是Interface;是否定义为 public 类型;是否定义为 abstract 类型;如果是类的话,是否被声明为 final 等。各种访问标记如下所示:

。。。。。
字节码指令
常用指令
istore 操作数栈中的变量赋值
- istore_1 :将操作数栈中的变量,弹出放在索引为1的局部变量表中
iload 加载与存储
- iload_1:将局部变量表中索引为1位置上的数据压入操作数栈中。
- iload_2:将局部变量表中索引为2位置上的数据压入操作数栈中。
pop
计算指令
- mul
- sub
invoke
- InvokeStatic
- InvokeVirtual
- InvokeInterface
- InovkeSpecial
可以直接定位,不需要多态的方法
private 方法 , 构造方法 - InvokeDynamic
JVM最难的指令
lambda表达式或者反射或者其他动态语言scala kotlin,或者CGLib ASM,动态产生的class,会用到的指令
Demo1:
分析 i= 8这个指令
public class Test {
public static void main(String[] args) {
int i = 8;
}
}

0 bipush 8 # 将8这个数压入操作数栈
2 istore_1 # 将8弹出放在下标为1的局部变量表中(将8赋值给i)
3 return
int i = 8 这个指令就是将8这个数压入操作数栈(bipush 8),然后将8弹出放在下标为1的局部变量表中(istore1)
为什么下标为1?因为下标为0的局部变量表为this
Demo2:
public class Test {
public static void main(String[] args) {
int i = 8;
i= i++;
System.out.println(i);
}
}
0 bipush 8 # 将8压入操作数栈
2 istore_1 # 将8弹出放在下标为1的局部变量表中(将8赋值给i)
3 iload_1 # 将变量i = 8再压入操作数栈
4 iinc 1 by 1 # 将变量i的8变为9
7 istore_1 # 将8弹出放在下标为1的局部变量表中 (此时是将变量从9又变成了8)
8 getstatic #2
11 iload_1 # 将i压入操作数栈
12 invokevirtual #3
15 return
Demo3:
public class Test {
public static void main(String[] args) {
int i = 8;
i= ++i;
System.out.println(i);
}
}
0 bipush 8 # 将8压入操作数栈
2 istore_1 # 将8弹出放在下标为1的局部变量表中(将8赋值给i)
3 iinc 1 by 1 # 将变量i的8变为9
6 iload_1 # 将变量 i= 9 压入操作数栈
7 istore_1 # 将再次压入栈的9再次赋值给变量i
8 getstatic #2
11 iload_1 # 将变量i = 9 再次压入操作数栈
12 invokevirtual #3
15 return
Demo4:
类加载
类加载器和双亲委派
ClassLoader负责将类的二进制数据加载到虚拟机中。
类加载器
所有的classloader都有一个顶级的父类:Classloader
加载到内存之后,内存创建了两块内容:类load成二进制文件,第二个是生成了一个Class类的对象,指向二进制文件,class对象是在metaspace元空间
类加载器的分类
-
BootStrapClassLoader :引导类加载器,,负责加载一些核心的jar,例如rt.jar(runtime.jar)、charset.jar。。如果通过反射拿到的类加载器是空值的话,就代表已经拿到了这个加载器,最顶层的加载器,因为这个加载器使用C/C++语言实现的,嵌套在JVM内部
-
ExtentionClassLoader :ext扩展类加载器,负责加载扩展包,jre/lib/ext下面的jar包。Java语言编写,继承于ClassLoader
-
AppClassLoader:系统类加载器,加载classpath目录下的内容,是加载我们自己写好的程序
-
custonClassLoader:自定义类的加载器
类加载器的范围:

双亲委派
一个类申请加载 --> 从自定义加载器开始自底向上从缓存检查该类是否加载(find in cache从缓存检查,缓存可以理解为类内部维护的容器),如果自底向上的过程从哪个类加载器缓存中找到类被加载,就返回。如果没找到,就自顶向下进行加载,哪个类加载器加载到就返回结果,如果到最下面都没加载到,就抛出异常ClassNptFoundException
双亲委派是子加载器向父加载器方向委派,然后父加载器向子加载器方向的 双亲委派过程
即子到父 + 父到子的过程
思考:为什么要搞双亲委派
-
主要为了安全,特定的类由特定的类加载器进行加载,如果任何类加载器都能加载任何类,就会替换掉核心类库
试想一下你自己写的java.lang.String类由自定义类加载器加载到。就完全可以肆无忌惮的搜集客户密码了
-
避免类的重复加载,加载器进行向上委托的过程就是在检查类是否已经加载过。
沙箱安全机制
采用双亲委派的一个好处是比如加载位于 rt.jar 包中的类 java.lang.Object,不管是哪个加载器加载这个类,最终都是委托给顶层的启动类加载器进行加载,这样就保证了使用不同的类加载器最终得到的都是同样一个 Object对象。
举例
我自己恶搞创建一个java.lang.String类
public class String {
public static void main(String[] args) {
System.out.println("hello!");
}
}

String 默认情况下是启动类加载器进行加载的。假设我也自定义一个String 。会发现自定义的String 可以正常编译,但是永远无法被加载运行。
双亲委派机制可以确保Java核心类库所提供的类,不会被自定义的类所替代。
类加载过程
loading装载阶段
-
将类loading成二进制文件放入内存。
-
解析类的二进制数据流为方法区内的数据结构(Java类模型)
-
生成Class类的对象,指向二进制文件,通过Class类的对象访问二进制文件

LazyLoading的五种情况
- new getstatic putstatic invokestatic指令,访问final变量除外
- java.lang.reflect对类进行反射调用时
- 初始化子类的时候,父类首先初始化
- 虚拟机启动时,被执行的主类必须初始化
- 动态语言支持java.lang.invoke.MethodHandle解析的结果为REF_getstatic REF_putstatic REF_invokestatic的方法句柄时,该类必须初始化
linking阶段
-
verification验证 : 验证文件是否符合JVM规范
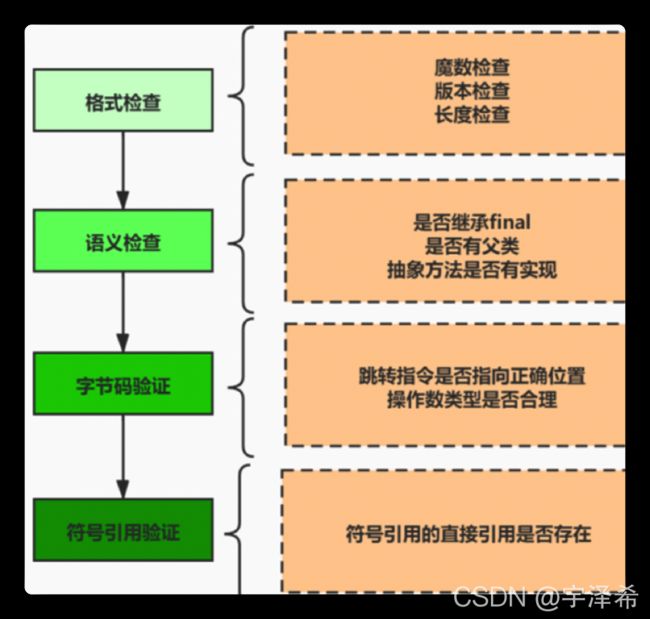
-
resolution解析:将类属性和方法的符号引用解析为直接引用。 常量池中的各种符号引用解析为指针、偏移量等内存地址的直接引用
-
preparation准备 : 虚拟机为类的静态成员变量赋默认值。如int,short,byte赋默认值0
initializing阶段
调用类初始化代码 ,给静态成员变量赋初始值(你定义的值)
gc垃圾回收阶段
类的生命周期结束被垃圾回收
demo:
public class T001_ClassLoadingProcedure {
public static void main(String[] args) throws Exception {
System.out.println(T.count);
}
}
class T {
public static T t = new T(); // null
public static int count = 2; //0
private T() {
count++;
System.out.println("-----" + count);
}
}
运行结果
-----1
2
先将类加载到内存 --> 然后verify --> initializing将t设为null,count 设为null —> resolution --> prepareing 将两个静态成员变量设初始值此时new T走构造器,此时count为0,加加后变为1,然后输出,最后count又在静态成员变量中被prepareing为2,在mian方法中输出
注:
-
静态成员变量的初始化过程:随着类被类加载器load进内存,静态变量通过preparation被赋默认值,随后通过initializing附初始值
load - 默认值 - 初始值
-
非静态成员变量的初始化: 随着对象的new申请内存在堆中开辟新的空间,先赋默认值,在赋初始值
new - 申请内存 - 默认值 - 初始值
双亲委派的打破
重写loadClass()
类加载器源码
// 从内存中找类是否已经加载到内存
// Launcher类中
protected final Class<?> findLoadedClass(String name) {
if (!checkName(name))
return null;
return findLoadedClass0(name);
}
private native final Class<?> findLoadedClass0(String name);
// ============================================================================================
// ClassLoader类中
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// First, check if the class has already been loaded 先从内存中找
Class<?> c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
try {
if (parent != null) {
c = parent.loadClass(name, false);
} else {
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
if (c == null) {
// If still not found, then invoke findClass in order 如果最终仍未找到调用findClass()
// to find the class.
long t1 = System.nanoTime();
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
resolveClass(c); // 加载类
}
return c;
}
}
// ============================================================================================
protected final void resolveClass(Class<?> c) {
resolveClass0(c);
}
private native void resolveClass0(Class<?> c);
类加载器源码都在Launcher.class中
通过ClassLoader的源码发现加载类的步骤为:
findInCache从缓存找 -> parent.loadClass -> findClass()
如何自定义类加载器
- 继承 ClassLoader
- 重写 findClass( )方法
如何打破双亲委派
重写loadClass( )
何时打破过双亲委派
- 在JDK1.2之前,自定义ClassLoader都必须重写loadClass()
- ThreadContextClassLoader可以实现基础类调用实现类代码,通过thread.setContextClassLoader指定
- 热启动,热部署 例如tomcat有自己模块指定的classloader
编译器
Java是解释型语言,讲一个类load成二进制文件后,由Java的解释器去执行,但是Java有个JIT编译器(Just In Time compiler)它可以将一部分Java代码编译成本地代码执行(native代码),因此Java即使编译型语言也是解释型语言,默认是混合模式:解释器+ 热点代码编译。当一段代码在单位时间重复执行超过一定次数时(多次被调用,多次被循环),JVM会将其热点代码编译成本地代码来执行(通过方法计数器,循环计数器检测)。
- Xmixed:混合模式 ,hotspot版JVM默认使用这个模式,热点代码编译,非热点代码解释执行
- Xint:纯解释模式,启动速度快,执行速度稍慢
- Xcomp:纯编译模式,启动很慢,执行速度快
一个参数 :检测热点代码 -XX:CompileThreshold = 10000 循环或调用超过这些次JVM就会将热点代码编译成本地代码
对象的创建
对象的创建过程
- class loading
- class linking (verification, preparation, resolution)
- class initializing
- 申请对象内存
- 成员变量赋默认值
- 调用构造方法<init>
-
成员变量顺序赋初始值
-
执行构造方法语句
-
注:前三步静态成员变量完成初始化并赋值 ,后三步非静态成员变量完成初始化并赋值
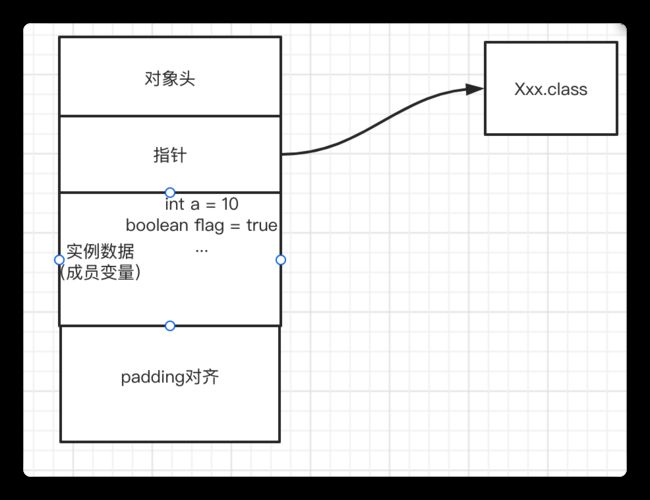
对象在内存中的存储布局
普通对象
-
对象头:markword 8字节
-
ClassPointer指针:指向类的元数据,虚拟机通过指针确定是哪个类的实例,开启指针压缩
-xxUseCompressedClassPointers为4字节,不开启为8字节 -
实例数据 :存储对象真正的有效信息。 开启指针压缩
-xxUseCompressedClassOops为4字节,不开启为8字节 -
Padding对齐,对象大小必须是8的倍数,因此需要对其填充(比如对象大小为15,实际上就要填充为16)
数组对象
- 对象头
- ClassPointer指针
- 数组长度
- 数组真实数据
- Padding对齐
-
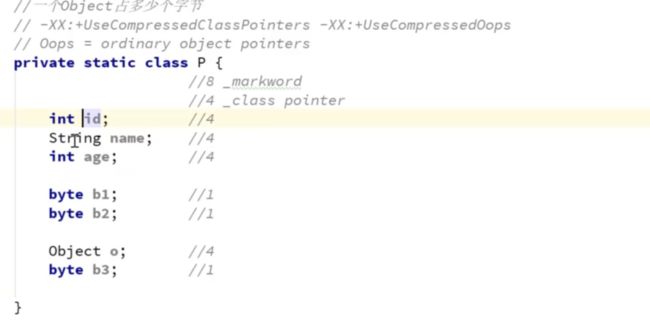
一个Object对象大小为16字节 ,因为一个markword对象头8字节,一个class指针,本来8字节打开指针压缩变为4字节,后面4字节padding对其
-
int[] 16字节 markword 8字节, classpointer 4字节,长度4字节
-
一个这样的对象: 32字节
有两个JVM参数:
-
xxUseCompressedClassPointers: 指针压缩(class对象的指针,对象头下面的那个指向class的指针),默认指针8字节压缩成4字节
-
xxUseCompressedClassOops :压缩指针(引用类型成员变量的指针),默认8 压缩成4。
oops就是ordinary object pointers 成员变量指针,小心网上的文章是错的
Java对象头 (MarkWord)
对象头源码如下:(JDK1.8)

对象头markword基本组成结构
着重说 有2位代表锁状态的标志位,和GC标记(标记分代的年龄),对象头和对象的锁状态有关,不同的状态对象头会记录不同的数据
 为什么GC年龄默认为15: 因为对象头的分代年龄标记只有四位
为什么GC年龄默认为15: 因为对象头的分代年龄标记只有四位
对象定位
https://blog.csdn.net/clover_lily/article/details/80095580
- 句柄池
- 直接指针
GC(Garbage Collector)
GC基础知识
Java中的垃圾和C语言中的垃圾的区别

C语言处理垃圾的劣势就是需要手动处理垃圾,这样就会导致经常出现垃圾忘记回收导致内存泄漏,或者垃圾被回收系统多次将被其他人正在使用的对象当做垃圾回收,开发效率低
什么是垃圾
没有任何引用指向的一个对象,或者多个对象(循环引用是一团垃圾)都是垃圾
单个垃圾: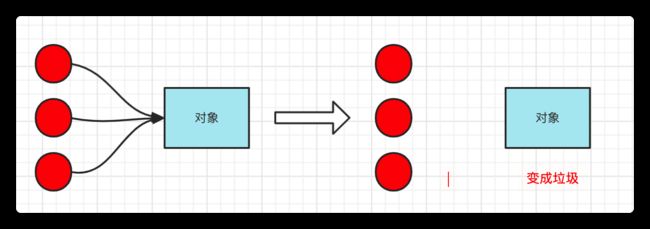
一团垃圾:
如何定位垃圾
-
引用计数(ReferenceCount)
当引用计数为0就变成垃圾
-
优点: 实现简单,垃圾对象便于辨识;判定效率高,回收没有延迟性。
-
缺点:
-
它需要单独的字段存储计数器,这样的做法增加了存储空间的开销。
-
每次赋值都需要更新计数器,伴随着加法和减法操作,这增加了时间开销。
-
无法处理循环引用。在Java 的垃圾回收器中没有使用这类算法。
-
-
-
根可达算法(RootSearching)
首先要知道什么是根对象:线程栈变量,静态变量,常量池,JNI指针
根可达算法:通过根对象的引用链一直往下搜找能往下找到的就是有用的,没有与引用链相连的对象就是垃圾
解决了循环引用的问题
常见的垃圾回收算法
-
标记清除(mark sweep) 缺点:位置不连续 产生碎片 效率偏低(两遍扫描,因为先标记再清除)
-
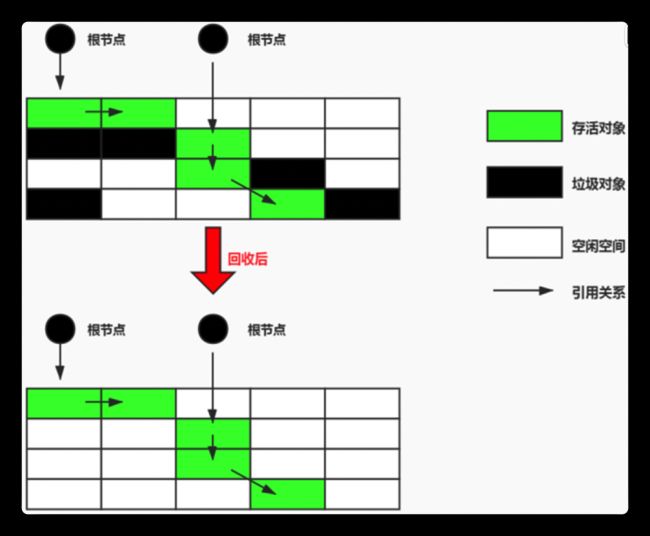
拷贝算法 (copying) - 没有碎片,但是浪费空间
将存活的对象内存空间拷贝相同的一份,在垃圾回收时将存活的对象复制到拷贝后的内存空间,之后清除旧的内存块空间中所有对象,交换两个内存的角色,最后完成垃圾回收。
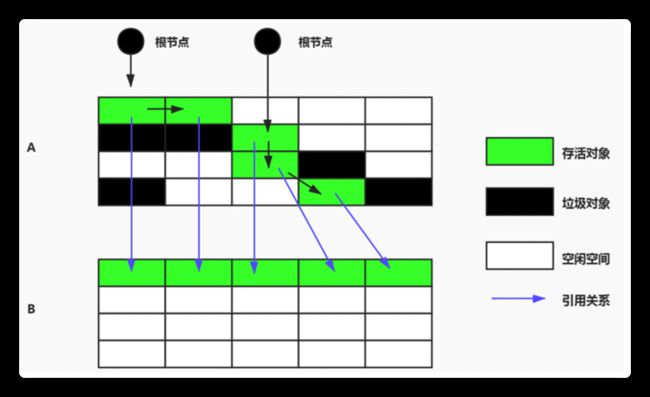
适用于存活对象比较少的情况,只扫描一次,便可形成没有碎片的连续空间
缺点是浪费空间,移动复制对象,需要调整对象引用
-
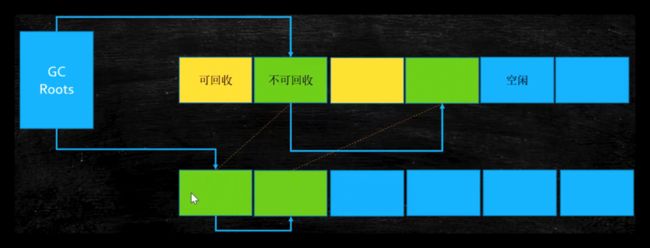
标记压缩(mark compact) - 没有碎片,效率偏低(两遍扫描,指针需要调整)
标记的是所有存活对象。步骤:标记 ->清除 -> 压缩。比标记清除算法多了个压缩步骤
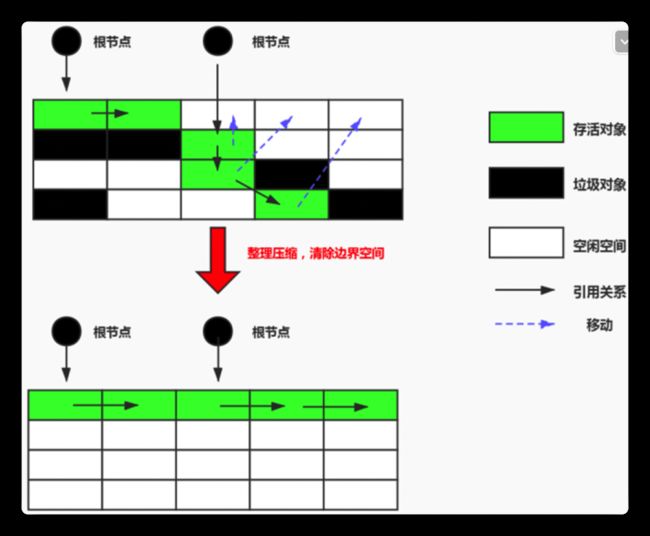
使用建议:新生代大量死去,少量存活,采用复制算法Copying;老年代存活率高,回收较少,采用MC或MS
JVM内存分代模型(用于分代垃圾回收算法)
部分垃圾回收器的分代模型
除Epsilon ZGC Shenandoah之外的GC都是使用逻辑分代模型
G1是逻辑分代,物理不分代
除此之外其他垃圾收集器不仅逻辑分代,而且物理分代
新生代 + 老年代 + 永久代(1.7)Permanent Generation/ 元数据区(1.8) Metaspace
永久代
- 永久代 存放各种字节码class信息,方法和代码编译后的信息,字节码指令等
- 永久代必须指定大小限制 ;元数据可以设置,也可以不设置,无上限,因为受限于物理内存。
- 字符串常量 1.7 - 在永久代,1.8 - 在堆
- 方法区是逻辑上的概念 ,其实它是:1.7 - 永久代、1.8 - 元数据
新生代、老年代
什么是YGC 什么是FGC?
-
YGC:对新生代范围进行GC
-
FGC:FULL GC全堆范围的GC,FCG触发时,年轻代和老年代分别根据自身的垃圾收集器的算法和规则进行相应的垃圾回收。FGC比较少触发,一般一周一次、十天一次。
什么时候触发FGC?老年代内存不够了就会触发FGC,JVM默认是 PS + PO 可以设置为PN + CMS
-
新生代 = Eden + 2个suvivor幸存者区 (幸存者0区和幸存者1区)
- YGC回收之后,大多数的对象会被回收,活着的进入s0
- 再次YGC,活着的对象eden + s0 -> s1
- 再次YGC,eden + s1-> s0
- 年龄足够 进入 -> 老年代 (15次GC后)
- 幸存者区装不下 -> 老年代
s0 - s1 之间的复制年龄超过限制时,进入old区通过参数:-XX:MaxTenuringThreshold配置
注:s0和s1有时会被叫成to和from,空的是to
-
老年代
- 顽固分子
- 老年代满了执行FGC (Full GC)
-
GC Tuning (Generation)
- 尽量减少FGC
- MinorGC = YGC
- MajorGC = FGC
-
对象分配过程图
注:次数上 频繁对新生代GC,较少对老年代GC,对老年代而言只有FGC
-
动态年龄:(不重要)
https://www.jianshu.com/p/989d3b06a49d
-
分配担保:(不重要)
YGC期间 在Survivor空间中相同年龄所有对象大小的总和大于Survivor空间的一半,年龄大于或等于该年龄的对象就可以直接进入老年代,无须等到MaxTenuringThreshold中要求的年龄。survivor区空间不够了 空间担保直接进入老年代
参考:https://cloud.tencent.com/developer/article/1082730
栈上分配内存和线程本地分配内存
如果开启栈上内存分配的话,一些小的对象是可以分配到栈上的。每次创建对象会优先检查是否可以在栈上进行内存分配,如果可以且内存足够就分配到栈上,如果不能分配到栈上才会将对象new到Eden区,见上图
逃逸分析:逃逸分析其实就是分析java对象的动态作用域
- 如果一个对象被定义之后,被外部对象引用,则称之为
方法逃逸 - 如果被其它线程所引用,则称之为
线程逃逸
TLAB:Thread Local Allocation Buffer,即线程本地分配缓存区,这是一个线程专用的内存分配区域。

栈上分配内存要比线程本地分配效率高,因为分配到栈上不需要进行垃圾回收,随着栈的弹出对象即消失
内存溢出和内存泄漏
内存溢出:(out of memory)就是内存不够用了,使用大程序在小内存机器上运行,程序在申请内存时,没有足够的内存空间供其使用,肯定内存溢出。比如申请了一个integer,但给它存了long才能存下的数,那就是内存溢出
内存泄漏:(Memory Leak)是指程序在申请内存后,由于种种原因无法释放已申请的内存空间,造成系统内存的浪费。一次内存泄露危害可以忽略,但内存泄露堆积后果很严重最终会导致内存溢出
Java的内存泄露多半是因为对象存在无效的引用,得不到释放,如果发现Java应用程序占用的内存出现了泄露的迹象,那么我们一般采用下面的步骤分析:
- 用工具生成java应用程序的heap dump(如jmap)
- 使用Java heap分析工具(如jamp,jvisualvm,arthas),找出内存占用超出预期的嫌疑对象
- 根据情况,分析嫌疑对象和其他对象的引用关系。
- 分析程序的源代码,找出嫌疑对象数量过多的原因。
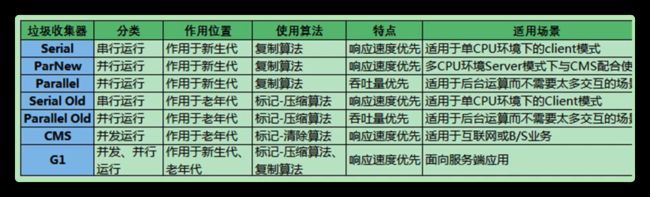
常见的垃圾回收器
随着JDK诞生出现了第一款Serial GC ,为了提高效率,诞生了PS,为了配合CMS,诞生了PN,CMS是1.4版本后期引入,CMS是里程碑式的GC,它开启了并发回收的过程,但是CMS毛病较多
并发垃圾回收是因为无法忍受STW
查看你的JDK的默认垃圾收集器
java -XX:+PrintCommandLineFlags -version

为什么这么多垃圾收集器,因为Java 的使用场景很多,移动端,服务器等。所以我们需要针对不同的场景,选择适合的垃圾收集器,提高垃圾回收效率。
STW (stop the world)
GC事件发生过程中,会产生应用程序的停顿。 使整个应用程序的所有线程暂停,没有任何响应。每个垃圾收集器都有STW现象,只是更优秀的垃圾收集器会减少STW的发生
串行回收和并行回收
- 串行回收:同一时间段内只能有一个线程进行垃圾回收
- 并行回收: 同一时间段内有多个线程同时进行垃圾回收
并发回收:表示回收垃圾的过程中可以产生新的垃圾
并行回收提高了回收效率,不过还是会引发STW
Serial GC
Serial配合和SerialOld使用,最早期的GC版本。Serial收集年轻代,SerialOld收集老年代
Serial和SerialOld为串行回收机制 ,STW,年轻代采用复制算法,老年代采用标记整理算法
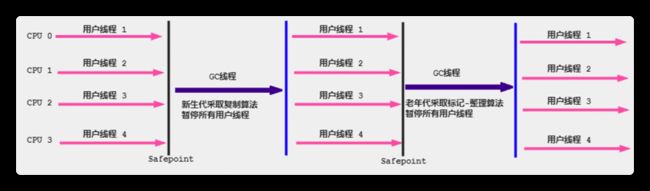
这种串行垃圾回收机制在单核cpu中效率高。现在都不是单核cpu了,因此这种垃圾回收器逐渐废弃
Parallel Scavenge
年轻代垃圾回收期,采用并行回收机制 ,STW,采用复制算法。
默认线程数为cpu的核数
Parallel Scavenge配合Parallel old一起使用
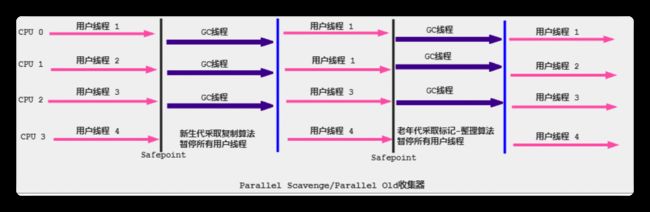
Java8中默认使用PS + PO收集器
ParNew
年轻代垃圾回收期,采用并行回收机制 ,STW,采用复制算法
ParNew对比Parallel Scavenge对比
- PN响应时间快,配合CMS
- PS吞吐量优先
CMS
全称ConcurrentMarkSweep ,老年代垃圾收集器 ,支持并发操作,也就是说垃圾回收和应用程序同时运行,降低STW的时间(200ms)
CMS问题比较多,会产生内存碎片,所以现在没有一个版本默认是CMS,只能手工指定
CMS使用标记清楚,那就一定会有碎片化的问题,碎片到达一定程度,CMS的老年代分配对象分配不下的时候,使用SerialOld对老年代区域标记压缩
CMS只管Full GC
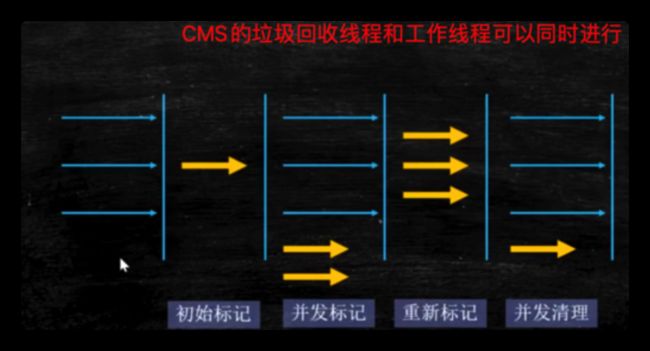
-
初始标记(STW):找到GC roots根节点对象。暂停时间非常短
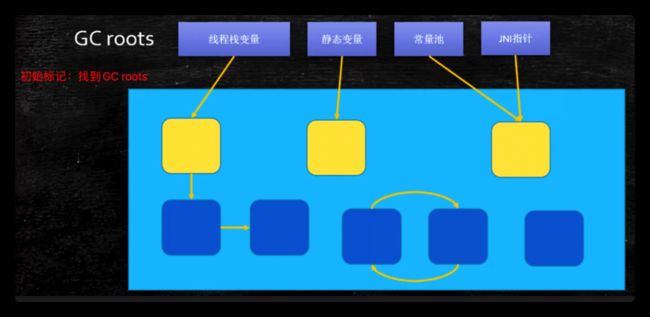
-
并发标记(最耗时):从GC Roots开始遍历整个对象图。不会停顿用户线程。该阶段最耗时。
-
重新标记:(STW):并发标记的同时会出现垃圾引用的改动,该阶段对改动过的引用进行重新标记
-
并发清理(最耗时):清理删除掉标记阶段判断的已经死亡的对象,释放内存空间。用户线程和GC线程同时执行
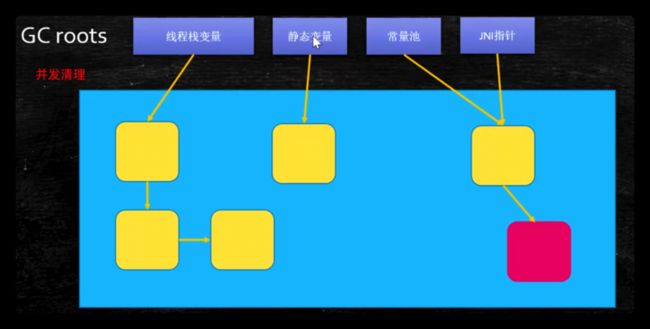
CMS的优势:使用了并发收集缩短了STW的时间。经实验:10g的内存在垃圾回收的过程中会STW 11 秒,这是无法忍受的
CMS的弊端:
-
会产生大量内存碎片,当碎片过多时,年轻代的对象想要往老年代转移发现已经没有足够空间,CMS会将Serial Old这个“老奶奶”请过来进行标记压缩,且SerialOld进行标记压缩的过程是STW的,如果内存空间非常大会导致整个应用线程停止相当长的时间!
-
会产生浮动垃圾:在并发标记阶段产生的垃圾即为浮动垃圾,这些浮动垃圾会在下一次GC中被回收
解决方案:降低触发CMS的阈值
-XX:CMSInitiatingOccupancyFraction 92% # 92%是默认的降低这个值,保证老年代足够的空间
demo:硬件升级系统反而卡顿?
有一个50万PV的资料类网站(从磁盘提取文档到内存)原服务器32位,1.5G的堆,用户反馈网站比较缓慢,因此公司决定升级,新的服务器为64位,16G的堆内存,结果用户反馈卡顿十分严重,反而比以前效率更低了,为什么?
答:FGC时STW的时间长了
G1
G1的核心思想—分而治之。G1物理不分代,逻辑分代
G1逻辑分为4个区:
- Eden区
- Survivor区
- Old区
- Humongous区
G1垃圾收集器的特点
- 并发收集
- 压缩空闲空间不会延长GC的暂停时间;
- 更易预测的GC暂停时间;
- 适用不需要实现很高的吞吐量的场景
说明:
G1上的分区只是逻辑上的分区,每个分区都可能是年轻代也可能是老年代,是可变的,但是在同一时刻只能属于某个代,非常灵活。在物理上不需要连续,则带来了额外的好处-有的分区内垃圾对象特别多,有的分区内垃圾对象很少,G1会优先回收垃圾对象特别多的分区,这样可以花费较少的时间来回收这些分区的垃圾,这也就是G1名字的由来,即首先收集垃圾最多的分区。
新生代其实并不是适用于这种算法的,依然是在新生代满了的时候,对整个新生代进行回收-----整个新生代中的对象,要么被回收、要么晋升,至于新生代也采取分区机制的原因,则是因这样跟老年代的策略统一,方便调整代的大小。
G1还是一种带压缩的收集器,在回收老年代的分区时,是将存活的对象从一个分区拷贝到另一个可用分区,这个拷贝的过程就实现了局部的压缩。每个分区的大小从1M到32M不等,但是都是2的冥次方。
Card Table
如果在年轻代中想要找到存活的对象,就要遍历老年代中的每一个对象,看是否有老年代中的某个对象作为年轻代某个对象的引用指向年轻代中的对象,说明每次GC都要遍历老年代。优化:使用Card Table标记。
由于做YGC时,需要扫描整个OLD区,效率非常低,所以JVM设计了CardTable,用cardtable将内存分为一些小块块,如果一个OLD区CardTable中有对象指向Y区,就将它设为Dirty,下次扫描时,只需要扫描Dirty Card。这样就避免了扫描整个老年代
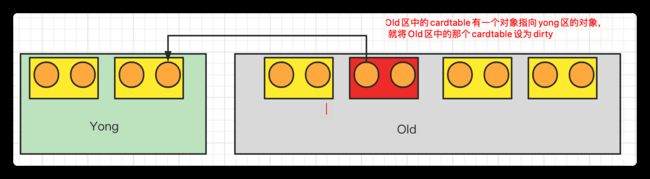
在结构上,Card Table用BitMap来实现,如上图bitmap [0,1,0,0]
因此,使用Card Table + Drity标记是为了使得年轻代的回收效率变高避免扫描整个老年代
cardtable 和region的关系?
cardtable是比region更小的逻辑单元,一个region逻辑上可能是yong、surviver、old、Humomgous,而每个region又分为很多cardtable
CSet(Collection Set)
表示一组可被回收的分区的集合,用来表示哪些card需要被回收。
在CSet中存活的数据会在GC过程中被移动到另一个可用分区,CSet中标记的分区可以来自Eden空间、survivor空间、或者老年代。CSet会占用不到整个堆空间的1%大小。
RSet(RememberedSet)
记录了其他Region中的对象到本Region的引用。
RSet的价值在于
使得垃圾收集器不需要扫描整个堆找到谁引用了当前分区中的对象,只需要扫描RSet即可。
由于RSet 的存在,那么每次给对象赋引用的时候,就得做一些额外的操作
- 指的是在RSet中做一些额外的记录(在GC中被称为写屏障)
- 这个写屏障 不等于 内存屏障
G1新老年代比例
不用手工指定,也不要手工指定,G1可以根据young区的STW时间动态调整比例 (5% ~60%)
G1中的GC方式
-
YGC(注意:G1的YGC是STW的)
何时触发? Eden区空间不足,采用多线程并行回收(用户线程和垃圾回收线程并存,多个垃圾回收线程并行)
-
MixedGC
已存活的对象占用堆空间超过45%触发MixedGC(默认)。 通过参数 XX:InitiatingHeapOccupacyPercent
-
FGC (标记清除,JDK10之前串行,JDK10以后并行)
何时触发? Old区内存空间不足 ,或者System.gc( )触发。
使用G1和使用CMS的核心目的都是为了减少FGC的发生,尽量不要有!
G1垃圾回收器会产生FGC吗?如果G1产生FGC,你应该做什么?
- 扩内存
- 提高CPU性能(回收的快,业务逻辑产生对象的速度固定,垃圾回收越快,内存空间越大)
- 降低MixedGC触发的阈值,让MixedGC提早发生(默认是45%)
MixedGC的过程
- 初始标记(STW)
- 并发标记
- 重新标记(STW)
- 筛选回收(STW + 并行)优先选择垃圾多的区域进行回收并将回收后区域存活的对象放入其他区域中,相当于压缩
G1的三色标记法
如下图:A对象包含域B、C,B对象包含域D。
- A自身和A中的域B、C都已经被标记(黑色)。C中没有别的域,C被标记(黑色)
- B中的域D未被标记(灰色)
- D未被标记(白色)
漏标:黑色对象的引用指向白色对象,与此同时指向白色对象的其他引用没了。黑色已经是被标记过的, 后面不会再扫描,因此白色对象永远也不会被扫描到
漏标发生在MixGC的并发标记阶段,因为该阶段工作线程和和GC线程同时进行,并发标记的过程其他工作线程也在改变引用的指向,并发标记的过程产生新垃圾,甚至不可达对象变成了可达对象(垃圾变成非垃圾)。所以漏标是这么来的
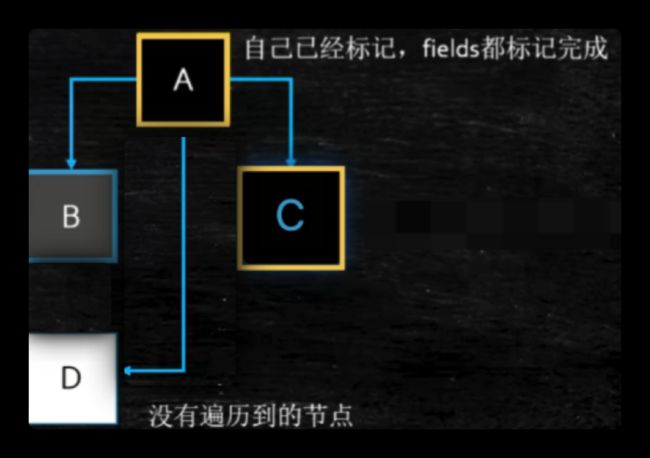
如何解决漏标

incremenal upadate 就是既然A多了个指向的D,干脆将A变为灰色。
SATB就是将删除过的引用放入栈中,再次重新标记时,扫描栈中的引用就知道哪些引用发生了改变。
CMS用的是incremenal uodate,G1使用的是SATB
为什么G1使用SATB
灰色 ->白色 引用消失时,如果没有黑色指向白色,引用会被push到堆栈下次扫描时拿到这个引用,由于有Rset的存在,不需要扫描整个堆去查找指向白色的引用,效率比较高
SATB 配合Rset浑然天成!
使用G1垃圾回收器的优缺点
-
G1 优点:
- 停顿时间短,追求吞吐量;
- 追求响应时间,用户可以通过参数对STW时间进行控制;
- 灵活—优先回收垃圾比例高,花费时间少的区域
-
G1 缺点:
G1 需要记忆集 Cset,Rset,这些数据可能达到整个堆内存容量的 20% 甚至更多。而且 G1 中维护记忆集的成本较高,带来了更高的执行负载,影响效率。
了解其他版本的JVM

JMM -JAVA内存模型
硬件层数据一致性
存储器的层次结构

总线锁—只要有一个cpu在访问缓存中的数据,其他线程只能等待不能访问,相当于阻塞。这样效率低下(老的cpu使用这种办法)
而现在的cpu是使用各种协议保证数据一致的,我们常用的 intel 使用的是 :MESI。
现代CPU的数据一致性实现是通过缓存锁(MESI) + 总线锁
cacheline的概念
图中main memory相当于内存,多个cpu中每个cpu都包含单独的L1一级缓存和L2二级缓存,L3相当于cpu的三级缓存(多个cpu的共同缓存)
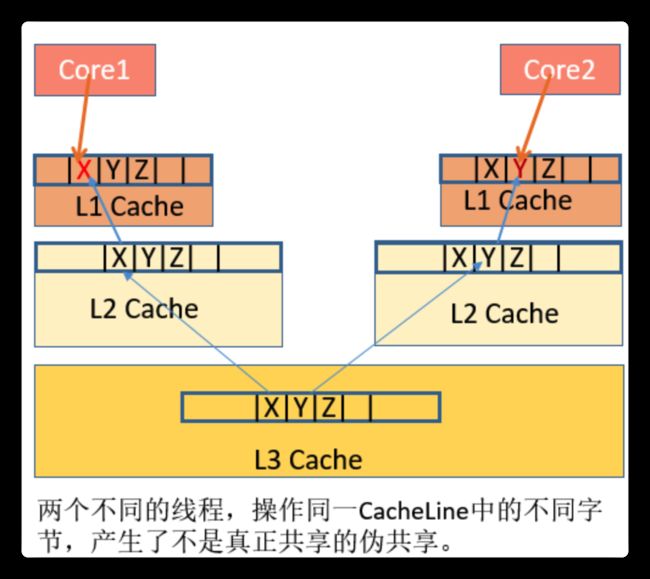
cacheline缓存行的伪共享:读取缓存以cache line为基本单位,缓存行大小为64bytes。位于同一缓存行的两个不同数据,被两个不同CPU锁定。如图,两个cpu1,cpu2分别访问同一个缓存行中的相邻数据x, y ,cpu1不可能单独读取缓存行中的x,cpu2不可能单独读取缓存行中的y,这两个cpu将整个缓存行中的数据64bytes都加载进去了。此时若cpu1对的操作是x,导致这段地址上的数据对于其他cpu的缓存失效,cpu2也需要重新去主存中load这段数据,导致了额外的开销。由于缓存行的特性,当多个cpu修改同一个缓存行中的数据会影响彼此的性能。
伪共享带来的问题就是:当处理器发现自己缓存行对应的内存数据被修改,就会将当前处理器的缓存行设置成无效状态,当处理器要对这个数据进行修改操作的时候,会强制重新从系统内存里把数据读取到处理器缓存里
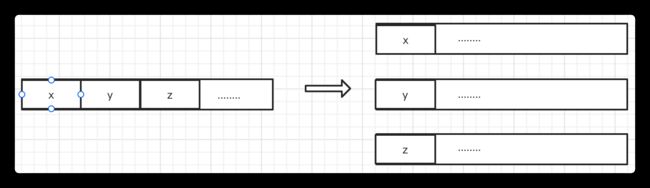
解决伪共享办法:
使用缓存行的对齐,也就是说多个cpu修改同一个缓存行中的不同数据,那我把同一个缓存行中的不同数据设置到不同的缓存行中,这样他们就修改不同的缓存行了。
乱序问题
cpu的执行时间远大于内存读取时间(cpu比内存至少快100倍),因此CPU为了提高指令执行效率,会在一条指令执行过程中,去同时执行另一条指令,前提是,两条指令没有依赖关系。
产生一个问题–指令重排
如何保证特定情况下不乱序
硬件层级:内存屏障(X86)
- storefence 写屏障: 在sfence指令前的写操作当必须在sfence指令后的写操作前完成。
- loadfence 读屏障: 在lfence指令前的读操作当必须在lfence指令后的读操作前完成。
- modify/mix fence :读写屏障在modify/mix fence 指令前的读写操作当必须在modify/mix fence 指令后的读写操作前完成。
原子指令,如x86上的”lock …” 指令是一个Full Barrier,执行时会锁住内存子系统来确保执行顺序,甚至跨多个CPU。Software Locks通常使用了内存屏障或原子指令来实现变量可见性和保持程序顺序
JVM层级 屏障
-
LoadLoad屏障:对于这样的语句
Load1LoadLoad; Load2, 在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。 -
StoreStore屏障:对于这样的语句
Store1; StoreStore; Store2,在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。 -
LoadStore屏障:对于这样的语句
Load1; LoadStore; Store2,在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。 -
StoreLoad屏障:对于这样的语句
Store1; StoreLoad; Load2, 在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。
volatile的实现细节
-
字节码层面
ACC_VOLATILE -
JVM层面
volatile内存区的读写 都加屏障StoreStoreBarrier
volatile 写操作
StoreLoadBarrier
LoadLoadBarrier
volatile 读操作
LoadStoreBarrier
-
OS和硬件层面
https://blog.csdn.net/qq_26222859/article/details/52235930
hsdis - HotSpot Dis Assembler
windows lock 指令实现 | MESI实现
synchronized实现细节
-
字节码层面
ACC_SYNCHRONIZED
monitorenter monitorexit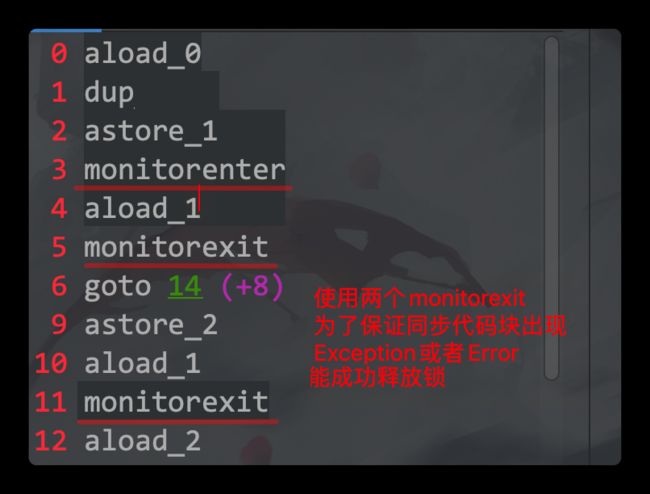
-
JVM层面
C C++ 调用了操作系统提供的同步机制 -
OS和硬件层面
X86 : lock cmpxchg指令实现
JVM调优实战
常见垃圾回收器组合参数设定:(1.8)
-
-XX:+UseSerialGC = Serial New (DefNew) + Serial Old
- 小型程序。默认情况下不会是这种选项,HotSpot会根据计算及配置和JDK版本自动选择收集器
-
-XX:+UseParNewGC = ParNew + SerialOld
- 这个组合已经很少用(在某些版本中已经废弃)
-
-XX:+UseConcurrentMarkSweepGC = ParNew + CMS + Serial Old
-
-XX:+UseParallelGC = Parallel Scavenge + Parallel Old (1.8默认) 【PS + SerialOld】
-
-XX:+UseParallelOldGC = Parallel Scavenge + Parallel Old
-
-XX:+UseG1GC = G1
-
Linux中没找到默认GC的查看方法,而windows中会打印UseParallelGC
- java +XX:+PrintCommandLineFlags -version
- 通过GC的日志来分辨
-
Linux下1.8版本默认的垃圾回收器到底是什么?
- 1.8.0_181 默认(看不出来)Copy MarkCompact
- 1.8.0_222 默认 PS + PO
了解JVM常用命令行参数
-
JVM的命令行参数参考:https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html
1)HotSpot参数分类
- 标准: - 开头,所有的HotSpot都支持
- 非标准:-X 开头,特定版本HotSpot支持特定命令
- 不稳定:-XX 开头,下个版本可能取消
java -X
2)查询参数的方法
采用命令:-XX: PrintFlagsFinal -version | grep 待查询的东西
例如寻找所有与CMS垃圾回收器相关的参数,使用指令-XX:PrintFlagsFinal -version | grep CMS试验用程序:
import java.util.List;import java.util.LinkedList;public class HelloGC { public static void main(String[] args) { System.out.println("HelloGC!"); List list = new LinkedList(); for(;;) { byte[] b = new byte[1024*1024]; list.add(b); } }}3)关于GC的常用命令行参数
-
a)
-XX:+PrintCommandLineFlags功能:查看程序使用的默认JVM参数:堆的最大值、堆的最小值 -
b) -Xmn10M -Xms40M -Xmx60M
功能:设置新生代大小为10M,堆的最小值为40M(默认为物理内存的 1/64),堆的最大值为60M(默认为物理内存的 1/4)。在实际生产中,最好设置堆的最大值和最小值是一样大的,目的是防止在程序运行过程中堆大小弹性变化。 -
c)
-XX:+PrintGCXxx
功能:打印GC的信息。类似的命令行参数有PrintGCDetails(查看详细的GC日志信息)、PrintGCTimeStamps(查看产生GC的时间信息)、PrintGCCauses(查看产生GC的原因)。 -
d)
-XX:+UseConcMarkSweepGC -XX:+PrintCommandLineFlags功能:查看运行过程中CMS的信息。 -
e)
-XX:+PrintFlagsInitial功能:查看JVM默认参数值 -
f )
-XX:+PrintFlagsFinal功能:查看JVM最终参数值 -
g)
-XX:+PrintFlagsFinal | grep xxx功能:查看xxx的相关参数 , 例如-XX:+PrintFlagsFinal -version |grep GC查看所有GC相关的参数信息
OOM堆溢出案例
public static void main(String[] args) { long maxMemory = Runtime.getRuntime().maxMemory();//返回 Java 虚拟机试图使用的最大内存量。 long totalMemory = Runtime.getRuntime().totalMemory();//返回 Java 虚拟机中的内存总量。 System.out.println("MAX_MEMORY = " + maxMemory + "(字节)、" + (maxMemory / (double) 1024 / 1024) + "MB"); System.out.println("TOTAL_MEMORY = " + totalMemory + "(字节)、" + (totalMemory / (double) 1024 / 1024) + "MB"); }
创建一个StringBuffer一直无限append也可以导致堆溢出
调优过程详解
每种垃圾回收器的日志格式是不同的!
调优前的基础概念:
- 吞吐量:用户代码时间 /(用户代码执行时间 + 垃圾回收时间)。吞吐量越大说明系统正常工作时间比率高
- 响应时间:STW越短,响应时间越好
所谓调优,首先确定,追求啥?吞吐量优先,还是响应时间优先?还是在满足一定的响应时间的情况下,要求达到多大的吞吐量…
例如:
-
科学计算,吞吐量。数据挖掘,thrput。吞吐量优先的一般:(PS + PO)
-
响应时间:网站 GUI API (1.8 G1)
什么是调优?
- 根据需求进行JVM规划和预调优
- 优化运行JVM运行环境(慢,卡顿)
- 解决JVM运行过程中出现的各种问题(OOM)
调优,从规划开始
-
调优,从业务场景开始,没有业务场景的调优都是耍流氓
-
无监控(压力测试,能看到结果),不调优
-
步骤:
-
熟悉业务场景(没有最好的垃圾回收器,只有最合适的垃圾回收器)
- 响应时间、停顿时间 [CMS G1 ZGC] (需要给用户作响应)
- 吞吐量 = 用户时间 /( 用户时间 + GC时间) [PS]
-
选择回收器组合
-
计算内存需求(经验值 1.5G 16G)
-
选定CPU(越高越好)
-
设定年代大小、升级年龄
-
设定日志参数
-
-Xloggc:/opt/xxx/logs/xxx-xxx-gc-%t.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5
-XX:GCLogFileSize=20M -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCCause
-
或者每天产生一个日志文件
**注:**这里一定是要设置多个日志文件,因为一个日志文件太大会导致问题寻找排查困难当最后一个日志文件满了,从第一个日志文件开始覆盖写
-
-
观察日志情况
-
-
案例1:垂直电商,最高每日百万订单,处理订单系统需要什么样的服务器配置?
这个问题比较业余,因为很多不同的服务器配置都能支撑(无论1.5G 还是16G堆)
1小时360000集中时间段, 100个订单/秒,(找一小时内的高峰期,1000订单/秒)
经验值,
非要计算:一个订单产生需要多少内存?一个订单大概512KB,高峰时段最高每秒可达512K * 1000 500M内存
专业一点儿问法:要求响应时间100ms
压测!
-
案例2:12306遭遇春节大规模抢票应该如何支撑?
12306应该是中国并发量最大的秒杀网站:
号称并发量100W最高
CDN -> LVS -> NGINX -> 业务系统 -> 每台机器1W并发(10K问题) 100台机器
普通电商订单 -> 下单 ->订单系统(IO)减库存 ->等待用户付款
12306的一种可能的模型: 下单 -> 减库存 和 订单(redis kafka) 同时异步进行 ->等付款
减库存最后还会把压力压到一台服务器
可以做分布式本地库存 + 单独服务器做库存均衡
大流量的处理方法:分而治之
-
怎么得到一个事务会消耗多少内存?
-
弄台机器,看能承受多少TPS?是不是达到目标?扩容或调优,让它达到
-
用压测来确定
-
优化环境
- 有一个50万PV的资料类网站(从磁盘提取文档到内存)原服务器32位,1.5G
的堆,用户反馈网站比较缓慢,因此公司决定升级,新的服务器为64位,16G
的堆内存,结果用户反馈卡顿十分严重,反而比以前效率更低了- 为什么原网站慢?
很多用户浏览数据,很多数据load到内存,内存不足,频繁GC,STW长,响应时间变慢 - 为什么会更卡顿?
内存越大,FGC时间越长 —> STW的时间越长 - 咋办?
PS -> PN + CMS 或者 G1
- 为什么原网站慢?
- 系统CPU经常100%,如何调优?(面试高频)
CPU100%那么一定有线程在占用系统资源,- 找出哪个进程cpu高(top)
- 该进程中的哪个线程cpu高(top -Hp PId)
- 导出该线程的堆栈 (jstack)
- 查找哪个方法(栈帧)消耗时间 (jstack)
- 看工作线程占比高 |还是垃圾回收线程占比高
- 系统内存飙高,如何查找问题?(面试高频)
- 导出堆内存 (jmap)
- 分析 (jhat jvisualvm mat jprofiler … )
- 如何监控JVM
- jstat jvisualvm jprofiler arthas top…
解决JVM运行中的问题
一个案例理解常用工具
-
测试代码:
package com.mashibing.jvm.gc;import java.math.BigDecimal;import java.util.ArrayList;import java.util.Date;import java.util.List;import java.util.concurrent.ScheduledThreadPoolExecutor;import java.util.concurrent.ThreadPoolExecutor;import java.util.concurrent.TimeUnit;/** * 从数据库中读取信用数据,套用模型,并把结果进行记录和传输 */public class T15_FullGC_Problem01 { private static class CardInfo { BigDecimal price = new BigDecimal(0.0); String name = "张三"; int age = 5; Date birthdate = new Date(); public void m() {} } private static ScheduledThreadPoolExecutor executor = new ScheduledThreadPoolExecutor(50, new ThreadPoolExecutor.DiscardOldestPolicy()); public static void main(String[] args) throws Exception { executor.setMaximumPoolSize(50); for (;;){ modelFit(); Thread.sleep(100); } } private static void modelFit(){ List<CardInfo> taskList = getAllCardInfo(); taskList.forEach(info -> { // do something executor.scheduleWithFixedDelay(() -> { //do sth with info info.m(); }, 2, 3, TimeUnit.SECONDS); }); } private static ListgetAllCardInfo(){ List taskList = new ArrayList<>(); for (int i = 0; i < 100; i++) { CardInfo ci = new CardInfo(); taskList.add(ci); } return taskList; }} -
java -Xms200M -Xmx200M -XX:+PrintGC com.mashibing.jvm.gc.T15_FullGC_Problem01
-
一般是运维团队首先受到报警信息(CPU Memory)
-
top命令观察到问题:内存不断增长 CPU占用率居高不下
-
top -Hp 观察进程中的线程,哪个线程CPU和内存占比高
-
jps定位具体java进程
使用jstack-pId 定位线程状况,重点关注:WAITING BLOCKED
eg.
例如:waiting on <0x0000000088ca3310> (a java.lang.Object)
假如有一个进程中100个线程,很多线程都在waiting on ,一定要找到是哪个线程持有这把锁,怎么找?搜索jstack dump的信息,找 ,看哪个线程持有这把锁RUNNABLE
作业:1:写一个死锁程序,用jstack观察 2 :写一个程序,一个线程持有锁不释放,其他线程等待 -
为什么阿里规范里规定,线程的名称(尤其是线程池)都要写有意义的名称
怎么样自定义线程池里的线程名称?(自定义ThreadFactory) -
jinfo pid
-
jstat -gc 可以动态观察gc情况 / 阅读GC日志发现频繁GC / arthas观察
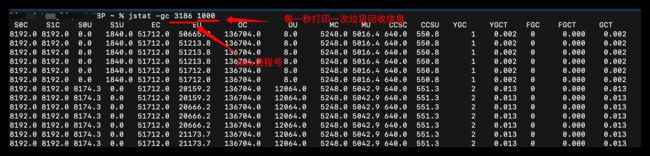
其他阅读GC的工具还有: jconsole、jvisualVM、Jprofiler(最好用,但是收费)
如果面试官问你是怎么定位OOM问题的?如果你回答用图形界面:错误!
1:已经上线的系统不用图形界面用什么?可以使用cmdline(命令行) arthas(也是基于命令行)
2:图形界面到底用在什么地方?测试!测试的时候进行监控!(压测观察) -
jmap -histo 查找有多少对象产生
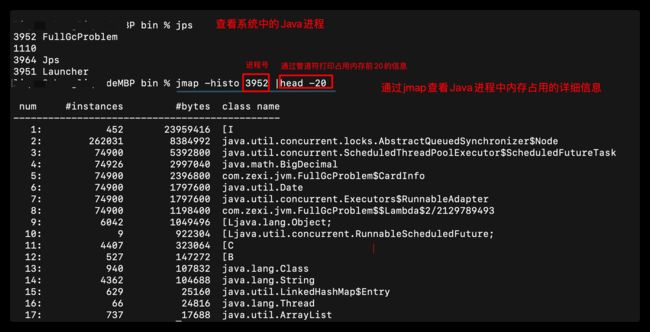
该命令在线执行时对线上系统影响不大~
-
jmap -dump:format=b,file=xxx pid :
线上系统,内存特别大,jmap执行期间会对进程产生很大影响,甚至卡顿(电商一定不适合!)
解决方案:
1:设定参数HeapDump,OOM的时候会自动产生堆转储文件(JVM 的堆转储文件(heap dump)是某个时间点、Java 进程的内存快照。包含了当时内存中还没有被 full GC 回收的对象和类信息。)
2:有很多服务器的备份(高可用),停掉这台服务器对其他服务器不影响
3:在线定位(一般小点儿公司用不到) -
java -Xms20M -Xmx20M -XX:+UseParallelGC -XX:+HeapDumpOnOutOfMemoryError com.mashibing.jvm.gc.T15_FullGC_Problem01
-
使用MAT / jhat /jvisualvm 进行dump文件分析
https://www.cnblogs.com/baihuitestsoftware/articles/6406271.html
jhat -J-mx512M xxx.dump
http://192.168.17.11:7000
拉到最后:找到对应链接
可以使用OQL查找特定问题对象 -
找到代码的问题
jconsole远程连接
-
程序启动加入参数:
java -Djava.rmi.server.hostname=192.168.17.11 -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=11111 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false XXX -
如果遭遇 Local host name unknown:XXX的错误,修改/etc/hosts文件,把XXX加入进去
192.168.17.11 basic localhost localhost.localdomain localhost4 localhost4.localdomain4::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 -
关闭linux防火墙(实战中应该打开对应端口)
service iptables stopchkconfig iptables off #永久关闭 -
windows上打开 jconsole远程连接
jvisualvm远程连接
查看具体线程情况
查看每个类占用的内存信息,可以方便的定位OOM在哪个类上,该界面为定位OOM的最重要的界面
具体简单用法详见 https://www.cnblogs.com/liugh/p/7620336.html
jprofiler (收费)
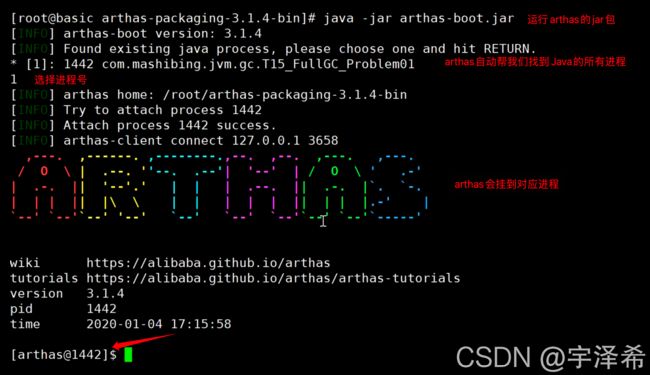
arthas在线排查工具
-
为什么需要在线排查?
在生产上我们经常会碰到一些不好排查的问题,例如线程安全问题,用最简单的threaddump或者heapdump不好查到问题原因。为了排查这些问题,有时我们会临时加一些日志,比如在一些关键的函数里打印出入参,然后重新打包发布,如果打了日志还是没找到问题,继续加日志,重新打包发布。对于上线流程复杂而且审核比较严的公司,从改代码到上线需要层层的流转,会大大影响问题排查的进度。 -
jvm:观察jvm信息
-
thread:定位线程问题
-
dashboard: 观察系统情况
-
heapdump + jhat分析
-
jad反编译
作用
- 动态代理生成类的问题定位
- 第三方的类(观察代码)
- 版本问题(确定自己最新提交的版本是不是被使用)
-
redefine 热替换
在其他窗口vim修改Java文件并javac,然后再此窗口redefine Xxx.class即可
目前有些限制条件:只能改方法实现(方法已经运行完成),不能改方法名, 不能改属性
m() -> mm() -
sc - search class
-
watch - watch method
-
没有包含的功能:jmap -histo
GC日志分析
PS日志分析

heap dump部分:
eden space 5632K, 94% used [0x00000000ff980000,0x00000000ffeb3e28,0x00000000fff00000) 后面的内存地址指的是,起始地址,使用空间结束地址,整体空间结束地址
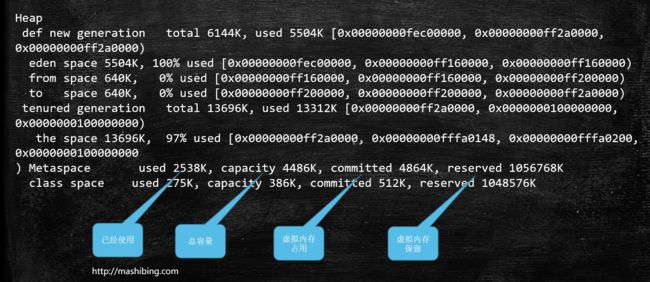
total = eden + 1个survivor区
CMS日志分析
执行命令:java -Xms20M -Xmx20M -XX:+PrintGCDetails -XX:+UseConcMarkSweepGC com.mashibing.jvm.gc.T15_FullGC_Problem01
[GC (Allocation Failure) [ParNew: 6144K->640K(6144K), 0.0265885 secs] 6585K->2770K(19840K), 0.0268035 secs] [Times: user=0.02 sys=0.00, real=0.02 secs]
ParNew:年轻代收集器
6144->640:收集前后的对比
(6144):整个年轻代容量
6585 -> 2770:整个堆的情况
(19840):整个堆大小
[GC (CMS Initial Mark) [1 CMS-initial-mark: 8511K(13696K)] 9866K(19840K), 0.0040321 secs] [Times: user=0.01 sys=0.00, real=0.00 secs] //8511 (13696) : 老年代使用(最大) //9866 (19840) : 整个堆使用(最大)[CMS-concurrent-mark-start][CMS-concurrent-mark: 0.018/0.018 secs] [Times: user=0.01 sys=0.00, real=0.02 secs] //这里的时间意义不大,因为是并发执行[CMS-concurrent-preclean-start][CMS-concurrent-preclean: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] //标记Card为Dirty,也称为Card Marking[GC (CMS Final Remark) [YG occupancy: 1597 K (6144 K)][Rescan (parallel) , 0.0008396 secs][weak refs processing, 0.0000138 secs][class unloading, 0.0005404 secs][scrub symbol table, 0.0006169 secs][scrub string table, 0.0004903 secs][1 CMS-remark: 8511K(13696K)] 10108K(19840K), 0.0039567 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] //STW阶段,YG occupancy:年轻代占用及容量 //[Rescan (parallel):STW下的存活对象标记 //weak refs processing: 弱引用处理 //class unloading: 卸载用不到的class //scrub symbol(string) table: //cleaning up symbol and string tables which hold class-level metadata and //internalized string respectively //CMS-remark: 8511K(13696K): 阶段过后的老年代占用及容量 //10108K(19840K): 阶段过后的堆占用及容量[CMS-concurrent-sweep-start][CMS-concurrent-sweep: 0.005/0.005 secs] [Times: user=0.00 sys=0.00, real=0.01 secs] //标记已经完成,进行并发清理[CMS-concurrent-reset-start][CMS-concurrent-reset: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] //重置内部结构,为下次GC做准备
G1日志分析
https://www.oracle.com/technical-resources/articles/java/g1gc.html
[GC pause (G1 Evacuation Pause) (young) (initial-mark), 0.0015790 secs]//young -> 年轻代 Evacuation-> 复制存活对象 //initial-mark 混合回收的阶段,这里是YGC混合老年代回收// 看到Pause: 一定是STW [Parallel Time: 1.5 ms, GC Workers: 1] //一个GC线程 [GC Worker Start (ms): 92635.7] [Ext Root Scanning (ms): 1.1] [Update RS (ms): 0.0] [Processed Buffers: 1] [Scan RS (ms): 0.0] [Code Root Scanning (ms): 0.0] [Object Copy (ms): 0.1] [Termination (ms): 0.0] [Termination Attempts: 1] [GC Worker Other (ms): 0.0] [GC Worker Total (ms): 1.2] [GC Worker End (ms): 92636.9] [Code Root Fixup: 0.0 ms] [Code Root Purge: 0.0 ms] [Clear CT: 0.0 ms] [Other: 0.1 ms] [Choose CSet: 0.0 ms] [Ref Proc: 0.0 ms] [Ref Enq: 0.0 ms] [Redirty Cards: 0.0 ms] [Humongous Register: 0.0 ms] [Humongous Reclaim: 0.0 ms] [Free CSet: 0.0 ms] [Eden: 0.0B(1024.0K)->0.0B(1024.0K) Survivors: 0.0B->0.0B Heap: 18.8M(20.0M)->18.8M(20.0M)] [Times: user=0.00 sys=0.00, real=0.00 secs] //以下是混合回收其他阶段[GC concurrent-root-region-scan-start][GC concurrent-root-region-scan-end, 0.0000078 secs][GC concurrent-mark-start]//无法evacuation,进行FGC[Full GC (Allocation Failure) 18M->18M(20M), 0.0719656 secs] [Eden: 0.0B(1024.0K)->0.0B(1024.0K) Survivors: 0.0B->0.0B Heap: 18.8M(20.0M)->18.8M(20.0M)], [Metaspace: 3876K->3876K(1056768K)] [Times: user=0.07 sys=0.00, real=0.07 secs]
JVM常用参数
GC常用参数
- -Xmn -Xms -Xmx -Xss
年轻代 最小堆 最大堆 栈空间 - -XX:+UseTLAB
使用TLAB,默认打开 - -XX:+PrintTLAB
打印TLAB的使用情况 - -XX:TLABSize
设置TLAB大小 - -XX:+DisableExplictGC
System.gc()不管用 ,FGC - -XX:+PrintGC
- -XX:+PrintGCDetails
- -XX:+PrintHeapAtGC
- -XX:+PrintGCTimeStamps
- -XX:+PrintGCApplicationConcurrentTime (低)
打印应用程序时间 - -XX:+PrintGCApplicationStoppedTime (低)
打印暂停时长 - -XX:+PrintReferenceGC (重要性低)
记录回收了多少种不同引用类型的引用 - -verbose:class
类加载详细过程 - -XX:+PrintVMOptions
- -XX:+PrintFlagsFinal -XX:+PrintFlagsInitial
必须会用 - -Xloggc:opt/log/gc.log
- -XX:MaxTenuringThreshold
升代年龄,最大值15 - 锁自旋次数 -XX:PreBlockSpin 热点代码检测参数-XX:CompileThreshold 逃逸分析 标量替换 …
这些不建议设置
Parallel常用参数
-
-XX:SurvivorRatio
Eden :S0 : S1 默认为8:1:1
-
-XX:PreTenureSizeThreshold
表示的是大对象到底多大 -
-XX:MaxTenuringThreshold
-
-XX:+ParallelGCThreads
并行收集器的线程数,同样适用于CMS,一般设为和CPU核数相同 -
-XX:+UseAdaptiveSizePolicy
自动选择各区大小比例
CMS常用参数
- -XX:+UseConcMarkSweepGC
- -XX:ParallelCMSThreads
CMS线程数量 - -XX:CMSInitiatingOccupancyFraction
使用多少比例的老年代后开始CMS收集,默认是68%(近似值),如果频繁发生SerialOld卡顿,应该调小,(频繁CMS回收) - -XX:+UseCMSCompactAtFullCollection
在FGC时进行压缩 - -XX:CMSFullGCsBeforeCompaction
多少次FGC之后进行压缩 - -XX:+CMSClassUnloadingEnabled
- -XX:CMSInitiatingPermOccupancyFraction
达到什么比例时进行Perm回收 - GCTimeRatio
设置GC时间占用程序运行时间的百分比 - -XX:MaxGCPauseMillis
停顿时间,是一个建议时间,GC会尝试用各种手段达到这个时间,比如减小年轻代
G1常用参数
- -XX:+UseG1GC
- -XX:MaxGCPauseMillis
建议值,G1会尝试调整Young区的块数来达到这个值 - -XX:GCPauseIntervalMillis
?GC的间隔时间 - -XX:+G1HeapRegionSize
分区大小,建议逐渐增大该值,1 2 4 8 16 32。
随着size增加,垃圾的存活时间更长,GC间隔更长,但每次GC的时间也会更长
ZGC做了改进(动态区块大小) - G1NewSizePercent
新生代最小比例,默认为5% - G1MaxNewSizePercent
新生代最大比例,默认为60% - GCTimeRatio
GC时间建议比例,G1会根据这个值调整堆空间 - ConcGCThreads
线程数量 - InitiatingHeapOccupancyPercent
启动G1的堆空间占用比例
思考题
-
-XX:MaxTenuringThreshold控制的是什么?
A: 对象升入老年代的年龄
B: 老年代触发FGC时的内存垃圾比例 -
生产环境中,倾向于将最大堆内存和最小堆内存设置为:(为什么?)
A: 相同 B:不同 -
JDK1.8默认的垃圾回收器是:
A: ParNew + CMS
B: G1
C: PS + ParallelOld
D: 以上都不是 -
什么是响应时间优先?
-
什么是吞吐量优先?
-
ParNew和PS的区别是什么?
-
ParNew和ParallelOld的区别是什么?(年代不同,算法不同)
-
长时间计算的场景应该选择:A:停顿时间 B: 吞吐量
-
大规模电商网站应该选择:A:停顿时间 B: 吞吐量
-
HotSpot的垃圾收集器最常用有哪些?
-
常见的HotSpot垃圾收集器组合有哪些?
-
JDK1.7 1.8 1.9的默认垃圾回收器是什么?如何查看?
-
所谓调优,到底是在调什么?
-
如果采用PS + ParrallelOld组合,怎么做才能让系统基本不产生FGC
-
如果采用ParNew + CMS组合,怎样做才能够让系统基本不产生FGC
1.加大JVM内存
2.加大Young的比例
3.提高Y-O的年龄
4.提高S区比例
5.避免代码内存泄漏
-
G1是否分代?G1垃圾回收器会产生FGC吗?
-
如果G1产生FGC,你应该做什么?
1. 扩内存 2. 提高CPU性能(回收的快,业务逻辑产生对象的速度固定,垃圾回收越快,内存空间越大) 3. 降低MixedGC触发的阈值,让MixedGC提早发生(默认是45%) -
问:生产环境中能够随随便便的dump吗?
小堆影响不大,大堆会有服务暂停或卡顿(加live可以缓解),dump前会有FGC -
问:常见的OOM问题有哪些?
栈 堆 MethodArea 直接内存
案例汇总
OOM产生的原因多种多样,有些程序未必产生OOM,不断FGC(CPU飙高,但内存回收特别少) (上面案例)
-
硬件升级系统反而卡顿的问题(见上)
-
线程池不当运用产生OOM问题(见上-FullGcProblem案例)
不断的往List里加对象(实在太LOW) -
smile jira问题
实际系统不断重启
解决问题 加内存 + 更换垃圾回收器 G1
真正问题在哪儿?不知道 -
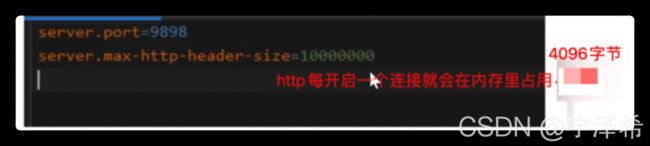
tomcat http-header-size过大问题(Hector)
-
lambda表达式导致方法区溢出问题(MethodArea / Perm Metaspace)
LambdaGC.java -XX:MaxMetaspaceSize=9M -XX:+PrintGCDetails"C:\Program Files\Java\jdk1.8.0_181\bin\java.exe" -XX:MaxMetaspaceSize=9M -XX:+PrintGCDetails "-javaagent:C:\Program Files\JetBrains\IntelliJ IDEA Community Edition 2019.1\lib\idea_rt.jar=49316:C:\Program Files\JetBrains\IntelliJ IDEA Community Edition 2019.1\bin" -Dfile.encoding=UTF-8 -classpath "C:\Program Files\Java\jdk1.8.0_181\jre\lib\charsets.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\deploy.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\access-bridge-64.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\cldrdata.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\dnsns.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\jaccess.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\jfxrt.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\localedata.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\nashorn.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\sunec.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\sunjce_provider.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\sunmscapi.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\sunpkcs11.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\zipfs.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\javaws.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\jce.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\jfr.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\jfxswt.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\jsse.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\management-agent.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\plugin.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\resources.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\rt.jar;C:\work\ijprojects\JVM\out\production\JVM;C:\work\ijprojects\ObjectSize\out\artifacts\ObjectSize_jar\ObjectSize.jar" com.mashibing.jvm.gc.LambdaGC[GC (Metadata GC Threshold) [PSYoungGen: 11341K->1880K(38400K)] 11341K->1888K(125952K), 0.0022190 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] [Full GC (Metadata GC Threshold) [PSYoungGen: 1880K->0K(38400K)] [ParOldGen: 8K->1777K(35328K)] 1888K->1777K(73728K), [Metaspace: 8164K->8164K(1056768K)], 0.0100681 secs] [Times: user=0.02 sys=0.00, real=0.01 secs] [GC (Last ditch collection) [PSYoungGen: 0K->0K(38400K)] 1777K->1777K(73728K), 0.0005698 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] [Full GC (Last ditch collection) [PSYoungGen: 0K->0K(38400K)] [ParOldGen: 1777K->1629K(67584K)] 1777K->1629K(105984K), [Metaspace: 8164K->8156K(1056768K)], 0.0124299 secs] [Times: user=0.06 sys=0.00, real=0.01 secs] java.lang.reflect.InvocationTargetException at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at sun.instrument.InstrumentationImpl.loadClassAndStartAgent(InstrumentationImpl.java:388) at sun.instrument.InstrumentationImpl.loadClassAndCallAgentmain(InstrumentationImpl.java:411)Caused by: java.lang.OutOfMemoryError: Compressed class space at sun.misc.Unsafe.defineClass(Native Method) at sun.reflect.ClassDefiner.defineClass(ClassDefiner.java:63) at sun.reflect.MethodAccessorGenerator$1.run(MethodAccessorGenerator.java:399) at sun.reflect.MethodAccessorGenerator$1.run(MethodAccessorGenerator.java:394) at java.security.AccessController.doPrivileged(Native Method) at sun.reflect.MethodAccessorGenerator.generate(MethodAccessorGenerator.java:393) at sun.reflect.MethodAccessorGenerator.generateSerializationConstructor(MethodAccessorGenerator.java:112) at sun.reflect.ReflectionFactory.generateConstructor(ReflectionFactory.java:398) at sun.reflect.ReflectionFactory.newConstructorForSerialization(ReflectionFactory.java:360) at java.io.ObjectStreamClass.getSerializableConstructor(ObjectStreamClass.java:1574) at java.io.ObjectStreamClass.access$1500(ObjectStreamClass.java:79) at java.io.ObjectStreamClass$3.run(ObjectStreamClass.java:519) at java.io.ObjectStreamClass$3.run(ObjectStreamClass.java:494) at java.security.AccessController.doPrivileged(Native Method) at java.io.ObjectStreamClass.<init>(ObjectStreamClass.java:494) at java.io.ObjectStreamClass.lookup(ObjectStreamClass.java:391) at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1134) at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1548) at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1509) at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1432) at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1178) at java.io.ObjectOutputStream.writeObject(ObjectOutputStream.java:348) at javax.management.remote.rmi.RMIConnectorServer.encodeJRMPStub(RMIConnectorServer.java:727) at javax.management.remote.rmi.RMIConnectorServer.encodeStub(RMIConnectorServer.java:719) at javax.management.remote.rmi.RMIConnectorServer.encodeStubInAddress(RMIConnectorServer.java:690) at javax.management.remote.rmi.RMIConnectorServer.start(RMIConnectorServer.java:439) at sun.management.jmxremote.ConnectorBootstrap.startLocalConnectorServer(ConnectorBootstrap.java:550) at sun.management.Agent.startLocalManagementAgent(Agent.java:137) -
直接内存溢出问题(少见)
《深入理解Java虚拟机》P59,使用Unsafe分配直接内存,或者使用NIO的问题 -
栈溢出问题
-Xss设定太小 -
比较一下这两段程序的异同,分析哪一个是更优的写法:
Object o = null;for(int i=0; i<100; i++) { o = new Object(); //业务处理}for(int i=0; i<100; i++) { Object o = new Object();}当然是第一个最优,原因:
1中 栈里面只有一个对象引用指向新创建的对象实体,随着对象的不断更换,之前失去引用的对象都被当做垃圾回收。
2中 没创建一个新的对象就会有一个新的引用指向对象实体,没有垃圾被回收,占用堆空间
-
重写finalize引发频繁GC
小米云,HBase同步系统,系统通过nginx访问超时报警,最后排查,C++程序员重写finalize引发频繁GC问题
为什么C++程序员会重写finalize?为什么重写了finalize引发了频繁gc(c++ 创建对象和Java一样通过构造函数new,手动回收内存需要调用new delete析构函数)
因为finalize耗时比较长(200ms),回收不过来,频繁GC -
如果有一个系统,内存一直消耗不超过10%,但是观察GC日志,发现FGC总是频繁产生,会是什么引起的?
只有一种可能,有程序在显示的调用System.gc( ) (这个比较Low) -
Distuptor有个可以设置链的长度,如果过大,然后对象大,消费完不主动释放,会溢出 (来自 死物风情)
-
用jvm都会溢出,mycat用崩过,1.6.5某个临时版本解析sql子查询算法有问题,9个exists的联合sql就导致生成几百万的对象
-
new 大量线程,会产生 native thread OOM,(low)应该用线程池,
解决方案:减少堆空间(太TMlow了),预留更多内存产生native thread
JVM内存占物理内存比例 50% - 80%4