STL库基础
文章目录
-
- STL基础
-
- 1.什么是标准模板库(STL)
-
- 1. C++ 标准模板库与C ++ 标准库的关系
- 2. STL六大组件
-
- 迭代器
- 容器
- list(双向链表)
-
- 1. list容器的概念
- 2. list容器的声明
- 3. list容器的使用方法
- vector库
-
- 1. vector容器的概念(变长数组)
- 2. vector容器的声明
- 3、vector特性
- queue(队列)
-
- 1. queue容器的概念
- 2. queue容器的声明
- 3. queue容器的使用方法
-
-
-
- 数组逆序
-
-
- stack库
-
- stack容器的概念
- stack容器的声明
- stack容器的使用方法
- priority_queue(优先级队列)
-
- 1、priority_queue容器的概念
- 2、priority_queue容器的声明
-
- 1、大根堆声明方式
- 2、小根堆声明方式
- 3、priority_queue容器的使用方法
- deque(双端队列)
-
- 1、deque容器的概念
- 2、deque容器的使用方法
- set(集合)
-
- 1、set容器的概念和性质
- 2、set容器的声明
- 3、set容器的使用
-
-
-
- 容器函数
- 添加函数
- 删除函数
- 访问函数
- 其他好用的函数
-
-
- multiset库
-
- 1、multiset容器的概念和性质
- bitset库
-
- 1、bitset容器概论
- 2、bitset容器的声明
- 3、对bitset容器的一些操作
-
- 1、常用的操作函数
-
- count() 函数
- any()/none() 函数
- set()函数
- reset()函数
- flip()函数
- 2、为运算操作在bitset中的实现
-
- 1、bitset容器的实际应用
- map库
-
- 1、map容器的概念
- 2、map容器的声明
- 3、map容器的用法
-
- 1、常规操作
- 2、插入操作
- 3、删除操作
- 4、遍历操作
- 5、查询操作
- 4、map和pair的关系
- vector 二维数组
-
- 1、定义
- 2、插入元素(两种方式)
-
- 1、第一种方式
- 2、第二种方式
- 3、长度
-
- 4、访问某元素
STL基础
1.什么是标准模板库(STL)
1. C++ 标准模板库与C ++ 标准库的关系
C++标准模板库属于C++标准库的一部分,C++标准模板库主要是定义了标准模板的定义与声明,而这些模板主要都是类模板,我们可以调用这些模板来定义一个具体的类;与之前的自己手动创建一个函数模板或者是类模板不一样,我们使用了STL就不用自己来创建模板类,这些模板都定义在标准模板库中,我们只需要学会怎么使用这些类模板来定义一个具体的类,然后能够使用类提供的各种方法来处理数据。
2. STL六大组件
- 容器
- 算法
- 迭代器
- 函数对象
- 适配器
- 分配器
迭代器
迭代器是一种对象,它能够用来遍历STL容器中的部分或全部元素,每个迭代器对象代表容器中的确定的地址,所以可以认为迭代器其实就是用来指向容器中数据的指针,我们可以通过改变这个指针来遍历容器中的所有元素
容器
首先,我们必须理解一下什么是容器,对比我们生活当中的容器,例如水杯,桶,水瓶等等这些东西,其实他们都是容器,我们的一个共同点就是:都是用来存放液体的,能够用来存放一些东西;其实我们的C++ 中说分这个容器其实作用也是用来存放“东西”,但是存放的是数据,在C++ 中容器就是一种用来存放数据的对象。
- C ++ 中的容器其实是容器类实例化之后的一个具体的对象,那么可以把这个对象看成就是一个容器
- 因为C++ 中容器类是基于了模板定义的,也就是我们这里说的STL(标准模板类)。为什么需要做成模板的形式呢?一维我们的容器中存放的数据类型其实是相同的,如果就因为数据类型不同而要定义多个具体的类,这样就不合适,而模板恰好又能解决这种问题,所以C++中的容器类是通过类模板的方式定义的,也就是STL。
- 容器还有另一个特点是容器可以自行扩展。在解决问题时我们常常不知道我们需要存储多少个对象,也就是说我们不知道应该创建多大的内存空间来存放我们的数据。显然,数据在这一方面也力不从心。容器的优势就在这里,它不需要你预先告诉它你要存储多少对象,只要你创建一个容器对象,并合理的调用它所提供的方法,所有的处理细节将由容器来自身完成。它可以为你申请内存或释放内存,并且用最优的算法来执行您的命令
- 容器是随着面向对象语言的诞生而提出的,容器类在面向对象语言中特别重要,甚至它被认为是早期面向对象语言的基础。
- 容器的分类:STL对定义的通用容器分三类:顺序性容器,关联式容器和容器适配器
- 顺序性容器:vector,deque,list
- 关联性容器:set,multiset,map,multimap
- 容器适配器:stack,queue,priority_queue
list(双向链表)
1. list容器的概念
list又称双向链表容器,即该容器的底层是以双向链表的形式实现的。这就意味着list容器中的元素可以分散存储在内存空间里,而不是必须存储在一整块连续的内存空间中。
下图展示了list双向链表容器是如何存储元素的。

可以看出,list容器中各个元素的前后顺序是靠指针来维系的,每个元素都配备了2个指针,分别指向它的前一个元素和后一个元素。其中第一个元素的前向指针总为null,因为它前面没有元素;同样,尾部元素的后向指针也总为null
基于这样的存储结构,list容器具有一些其他容器(array,vector和deque) 所不具备的优势,即它可以在序列已知的任何位置快速插入或删除元素(时间复杂度为O(1))。并且在list容器中移动元素,也比其它容器的效率高
使用list容器的缺点是,它不能像array和vector那样,通过位置直接访问元素。举个例子,如果要访问list容器中的第6个元素,它不支持容器list[5]这种语法格式,正确的做法是从容器中第一个元素或最后一个元素开始遍历容器,直到找到该位置
2. list容器的声明
- 创建一个没有任何元素的空list容器:
std::list values;
空的list在创建之后仍可以添加元素,因此创建list容器的方式很常用。
- 创建一个包含n个元素的list容器:
std::list values(10);
通过此方式创建values容器,其中包含10个元素,每个元素的值都为相应类型的默认值(int类型的默认值为0)。
- 创建一个包含n个元素的list容器,并为每个元素指定初始值。例如:
std::list values(10,5);
如此就创建了一个包含10个元素并且值都为5的容器。
- 在已有list容器的情况下,通过拷贝该容器可以创建新的list容器。例如:
std::list value1(10);
std::list value2(value1);
注意,采用此方式,必须保证新旧容器存储的元素类型一致
- 通过拷贝其他类型容器(或者普通数组) 中指定区域内的元素,可以创建新的list容器。例如:拷贝普通数组,创建list容器
int a[]={1,2,3,4,5};
std::listvalues(a,a+5);
3. list容器的使用方法
| 用法 | 功能 |
|---|---|
| begin() | 返回指向容器中第一个元素的双向迭代器 |
| end() | 返回指向容器中最后一个元素所在位置的下一个位置的双向迭代器。 |
| rbegin() | 返回指向最后一个元素的反向迭代器 |
| rend() | 返回指向第一个元素所在位置前一个位置的反向双向迭代器 |
| cbegin() | 和begin() 功能相同,只不过在其基础上,增加了 const 属性,不能用于修改元素 |
| cend() | 和 end() 功能相同,只不过在其基础上,增加了 const 属性,不能用于修改元素 |
| crbegin() | 和 rbegin() 功能相同,只不过在其基础上,增加了 const 属性,不能用于修改元素 |
| crend() | 和 rend() 功能相同,只不过在其基础上,增加了 const 属性,不能用于修改元素 |
| empty() | 判断容器中是否有元素,若无元素,则返回true; 反之,返回false |
| size() | 返回当前容器实际包含的元素个数。(不包含 ‘\0’) |
| max_size() | 返回容器所能包含元素个数的最大值,这通常是一个很大的值,一般是 2^32-1 ,所以我们很少会用到这个函数 |
| front() | 返回第一个元素的引用 |
| back() | 返回最后一个元素的引用 |
| assign() | 用新元素替换容器中原有内容 |
| emplace_front | 在容器头部生成一个元素。该元素和 push_front() 的功能相同,但效率更高 |
| push_front() | 在容器头部插入一个元素 |
| pop_front() | 删除容器头部的一个元素 |
| emplace_back() | 在容器尾部直接生成一个元素。该函数和 push_back() 的功能相同,但效率更高。 |
| push_back() | 在容器尾部插入一个元素 |
| pop_back() | 删除容器尾部的一个元素 |
| emplace() | 在容器中的指定位置插入元素。该函数和insert() 功能相同,但效率更高。 |
| insert() | 在容器中的指定位置插入元素 |
| erase() | 删除容器中一个或某区域内的元素 |
| swap() | 交换两个容器中的元素,必须保证这两个容器中存储的元素类型是相同的。 |
| resize() | 调整容器的大小 |
| clear() | 删除容器存储的所有元素 |
| splice() | 将一个list容器中的元素插入到另一个容器的位置 。 |
| remove(val) | 删除容器中所有等于 val 的元素 |
| remove_if() | 删除容器中满足条件的元素 |
| unique() | 删除容器中相邻的重复元素,只保留一个。 |
| merge() | 合并两个事先已排好序的list容器,并且合并之后的list容器依然是有序的。 |
| sort() | 通过更改容器中元素的位置,将它们进行排序。 |
| reverse() | 反转容器中元素的顺序。 |
#include
#include
using namespace std;
int main() {
//创建空的list容器
list values;
//向容器中添加元素
values.push_back(3.1);
values.push_back(2.2);
values.push_back(2.9);
cout << "values size:" << values.size() << endl;
//对容器中的元素进行排序
values.sort();
//使用迭代器输出list容器中的元素
for (list::iterator it = values.begin(); it != values.end(); ++it) {
cout << *it << " ";
}
return 0;
}
vector库
1. vector容器的概念(变长数组)
我们知道,一个数组必须要有固定的长度,在开一个数组的时候,这个长度也就被静态地确定下来了。但是vector确实数组的“加强版”,对于一组数据来讲,你往vector里存多少数据,vector的长度就有多大。也就是说,我们可以将其理解为一个“变长数组”。
事实上,vector的实现方式是基于倍增思想的:假如vector的实际长度为n,m为vector当前的最大长度,那么在加入一个元素的时候,先看一下,假如当前的n=m,则再动态申请一个2m大小的内存。反之,在删除的时候,如果n<=m/2,则再释放一半的内存。
2. vector容器的声明
vector容器的使用方法大致如下表:
| 用法 | 作用 |
|---|---|
| vec.begin(),vec.end() | 返回vector的首尾迭代器。 |
| vec.front(),vec.back() | 返回vector的首,尾元素 |
| vec.push_back() | 从vector 末尾加入一个元素 |
| vec.size() | 返回vector当前的长度(大小) |
| vec.pop_back() | 从vector末尾删除一个元素 |
| vec.empty() | 返回vector是否为空,1为空,0不为空 |
| vec.clear() | 清空vector |
3、vector特性
- vector容器是支持随机访问的
#include
#include
using namespace std;
int main() {
vector v;
v.push_back(3);
v.push_back(2);
v.push_back(1);
v.push_back(0);
cout << "下标" << v[3] << endl;//下标0
cout << "迭代器" << endl;//迭代器
for (vector::iterator i = v.begin(); i != v.end(); ++i) {
cout << *i << " ";//3 2 1 0
}
cout << endl;
//在第一个元素之前插入111,insert begin+n是在第n个元素之前插入
v.insert(v.begin(), 111);
//在最后一个元素之后插入222,insert+n 是在n个元素之后插入
v.insert(v.end(), 222);
for (vector::iterator i = v.begin(); i != v.end(); ++i) {
cout << *i << " ";//111 3 2 1 0 222
}
cout << endl;
vector arr(10);
for (int i = 0; i < 10; i++) {
arr[i] = i;
}
for (vector::iterator i = arr.begin(); i != arr.end(); ++i) {
cout << *i << " ";//0 1 2 3 4 5 6 7 8 9
}
cout << endl;
//删除 同insert
arr.erase(arr.begin());
for (vector::iterator i = arr.begin(); i != arr.end(); ++i) {
cout << *i << " ";//1 2 3 4 5 6 7 8 9
}
cout << endl;
arr.erase(arr.begin(), arr.begin() + 5);
for (vector::iterator i = arr.begin(); i != arr.end(); ++i) {
cout << *i << " ";//6 7 8 9
}
cout << endl;
return 0;
}
vector动态输入
vector nums;
for (int temp = 0; cin >> temp;)
{
nums.push_back(temp);
if (cin.get() == '\n')
break;
}
queue(队列)
1. queue容器的概念
queue 在英文中是队列的意思。队列是一种基本的数据结构。而 C++ STL 中的队列就是把这种数据结构模块化了。我们可以在脑中想象买票时人们的队列。我们发现,在一个队列中,只可以从对首离开,从队尾进来。即一个先进先出的数据结构。
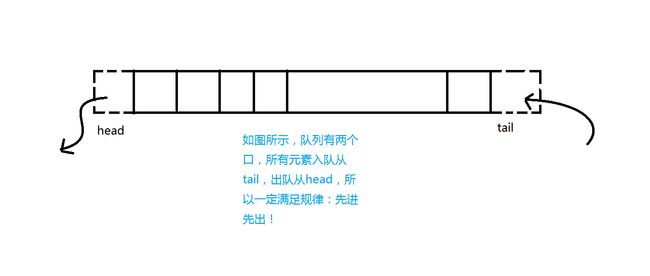
2. queue容器的声明
queue容器存放在模板库:
#include
#include
queue q;
queue q;
queue>q;
queue q;
struct node{...};
3. queue容器的使用方法
queue容器的使用方法大致如下所示:
| 用法 | 作用 |
|---|---|
| q.front(),q.back() | 返回queue的首,尾元素 |
| q.push() | 从queue末尾加入一个元素 |
| q.size() | 返回queue当前的长度(大小) |
| q.pop() | 从queue 队首删除一个元素 |
| q.empty() | 返回queue是否为空,1为空,0不为空 |
注意,虽然vector 和queue 是两种最基本的STL 容器,但请记住他们两个不是完全一样的。就从使用方法来讲:
queue不支持随机访问,即不能像数组一样地任意取值。并且,queue并不支持全部的 vector的内置函数。比如 queue 不可以用 clear() 函数清空,清空 queue 必须一个一个弹出。同样 queue 也并不支持遍历,无论是数组型还是迭代器型遍历统统不支持,所以没有begin(),end();函数,使用的时候一定要清楚异同!
数组逆序
/*数组逆序*/
#include
#include
using namespace std;
int main() {
queue pq;
pq.push(1);
pq.push(3);
pq.push(2);
pq.push(8);
pq.push(9);
pq.push(0);
cout << "size:" << pq.size() << endl;
while (pq.empty() != true) {
cout << pq.front() << endl;
pq.pop();
}
return 0;
}
/*
size:6
1
3
2
8
9
0*/
stack库
stack容器的概念
stack(栈)。栈是一种基本的数据结构。而 C++ STL 中的栈就是把这种数据结构模板化了。
栈的示意图如下:这是一个先进后出的数据结构。这非常重要

事实上,stack容器并不是一种标准的数据结构,它其实是一个容器适配器,里面还可以存放其他的STL 容器
stack容器的声明
stack 容器存放在模板库:
#include
#include
stack st;
stack st;
stack>st;
stack st;
struct node{...};
stack容器的使用方法
stack容器的使用方法大致如下表所示:
| 用法 | 作用 |
|---|---|
| st.top() | 返回stack的栈顶元素 |
| st.push() | 从stack栈顶加入一个元素 |
| st.pop() | 从stack栈顶弹出一个元素 |
| st.size() | 返回stack当前的长度(大小) |
| st.empty() | 返回stack是否为空,1为空,0不为空 |
#include
#include
using namespace std;
int main() {
stack s;
s.push(1);
s.push(2);
s.push(4);
s.push(5);
cout << s.size() << endl;
while (s.empty() != true) {
cout << s.top() << endl;
s.pop();
}
}
/*
4
5
4
2
1
*/
priority_queue(优先级队列)
1、priority_queue容器的概念
priority_queue 在英文中是优先队列的意思
队列是一种基本的数据结构。其实现的基本示意图如下所示:

而 C++ STL中的优先队列就是在这个队列的基础上,把其中的元素加以排序。其内部实现是一个二叉堆。所以优先队列其实就是把堆模板化,将所有入队的元素排成具有单调性的一队,方便我们调用。
2、priority_queue容器的声明
priority_queue容器存放在模板库里,使用前需要先打开这个库。
#include
这里需要注意的是,优先队列的声明与一般STL模板的声明方式并不一样。事实上,我认为是C++STL中最难声明的一个容器
1、大根堆声明方式
大根堆就是把大的元素放在堆顶的堆。优先队列默认实现的就是大根堆,所以大根堆的声明并不需要其他操作,直接按C++STL 的声明规则声明即可。
#include
priority_queue q;
priority_queue q;
priority_queue>q;
C++ 中的int,string等类型可以直接比较大小,所以不用我们多操心,优先队列自然会帮我们实现。但如果是我们自己定义的结构体,就需要进行重载运算符了。
struct node{
int id;
double c,y;
}//定义结构体
bool operator<(const node &a,const node &b){
return a.x2、小根堆声明方式
大根堆是把大的元素放栈顶,小根堆就是把小的元素放到堆顶。
实现小根堆有两种方式:
- 第一种是比较巧妙的,因为优先队列默认实现的是大根堆,所以我们可以把元素取反放进去,取出是再取反。
- 第二种
小根堆的声明方式
priority_queue,greater>q;
3、priority_queue容器的使用方法
priority_queue容器的使用方法大致如下表所示:
| 用法 | 作用 |
|---|---|
| q.top() | 返回priority_queue的首元素 |
| q.push() | 向priority_queue中加入一个元素 |
| q.size() | 返回priority_queue当前的长度(大小) |
| q.pop() | 从priority_queue堆顶删除一个元素 |
| q.empty() | 返回priority_queue 是否为空,1位空,0不为空 |
注意:priority_queue取出队首元素是使用top,而不是front,这一点要注意
#include
#include
using namespace std;
int main() {
priority_queue pq;
pq.push(1);
pq.push(3);
pq.push(2);
pq.push(8);
pq.push(9);
pq.push(0);
cout << "size:" << pq.size() << endl;
while (pq.empty() != true) {
cout << pq.top() << endl;
pq.pop();
}
}
/*
size:6
9
8
3
2
1
0
*/
deque(双端队列)
1、deque容器的概念
deque的意义是:双端队列。队列是我们常用而且必须掌握的数据结构。
队列的性质是先进先出,即从队尾入队,从队首出队。而deque的特点则是双端进出,即处于双端队列中的元素既可以从队首进/出队,也可以从队尾进/出队。
即:deque 是一个支持在两端高效插入,删除元素的线性容器
deque 模板存储在 C++ STL的
#include
2、deque容器的使用方法
因为deque容器真的和queue容器大体相同,其使用方式也大体一致。下面把deque容器的使用方式以列表的方式放在下面:
| 用法 | 作用 |
|---|---|
| q.begin(),q.end() | 返回deque的首,尾迭代器 |
| q.front,q.back() | 返回deque的首,尾元素 |
| q.push_back() | 从队尾入队一个元素 |
| q.push_front() | 从队头入队一个元素 |
| q.pop_back() | 从队头出队一个元素 |
| q.pop_front() | 从队头出队一个元素 |
| q.clear() | 清空队列 |
除了这些用法外,deque比queue更优秀的一个性质是它支持随机访问,即可以向数组下标一样取出其中的一个元素,即
q[i]
#include
#include
using namespace std;
int main() {
deque d;
//尾部插入
d.push_back(1);
d.push_back(3);
d.push_back(2);
for(deque::iterator it = d.begin(); it != d.end(); ++it) {
cout << (*it) << " ";
}
cout << endl << endl;
//头部插入
d.push_front(10);
d.push_front(-23);
for (deque::iterator it = d.begin(); it != d.end(); ++it) {
cout << (*it) << " ";
}
cout << endl << endl;
d.insert(d.begin() + 2,9999);
for (deque::iterator it = d.begin(); it != d.end(); ++it) {
cout << (*it) << " ";
}
cout << endl << endl;
//反向遍历
for (deque::reverse_iterator rit = d.rbegin(); rit != d.rend(); ++rit) {
cout << (*rit) << " ";
}
cout << endl << endl;
/*
删除元素pop pop_front从头部删除元素
pop_back从尾部删除元素
erase从中间删除
clear全删
*/
d.clear();
d.push_back(1);
d.push_back(2);
d.push_back(3);
d.push_back(4);
d.push_back(5);
d.push_back(6);
d.push_back(7);
d.push_back(8);
for (deque::iterator it = d.begin(); it != d.end(); ++it) {
cout << (*it) << endl;
}
cout << endl;
d.pop_front();
d.pop_front();
for (deque::iterator it = d.begin(); it != d.end(); ++it) {
cout << (*it) << " ";
}
cout << endl;
d.pop_back();
d.pop_back();
for (deque::iterator it = d.begin(); it != d.end(); ++ it) {
cout << (*it) << " ";
}
cout << endl;
d.erase(d.begin() + 1);
for (deque::iterator it = d.begin(); it != d.end(); ++it) {
cout << (*it) << " ";
}
cout << endl;
return 0;
}
/*
1 3 2
-23 10 1 3 2
-23 10 9999 1 3 2
2 3 1 9999 10 -23
1
2
3
4
5
6
7
8
3 4 5 6 7 8
3 4 5 6
3 5 6
*/
set(集合)
1、set容器的概念和性质
set容器的作用就是维护一个集合,其中的元素满足互异性。我们可以将其理解为一个数组。这个数组的元素是两两不同的。这个两两不同是指,如果这个set容器中已经包含了一个元素i,那么无论我们后续再往里加入多少个i,这个set中还是只有一个元素i,而不会出现一堆i的情况。这就为我们提供了很多方便。
set 实现了红黑树的平衡二叉树的数据结构,插入元素时,它会自动调整二叉树的排列,把元素放到适当的位置,以保证每个子树根节点键值大于左子树所有节点的键值,小于右子树所有节点的键值;另外,还得保证根节点左子树的高度与右子树高度相等。平衡二叉检索树使用中序遍历算法,检索效率高于 vector,deque和list等容器,另外使用中序遍历可将键值按照从小到大遍历出来。
2、set容器的声明
#include
set s;
set s;
setpair>s;
set s;
struct node{...};
3、set容器的使用
容器函数
#include
#include
using namespace std;
int main(int argc, char* argv[]) {
set st;
for (int i = 0; i < 6; i++) {
st.insert(i);
}
cout << st.size() << endl;//输出:6
cout << st.max_size() << endl;//输出:214748364
cout << st.count(2) << endl;//输出:1
if (st.empty()) {
cout << "元素为空" << endl;//未执行
}
}
/*
6
214748364
1
*/
添加函数
#include
#include
using namespace std;
int main(int argc, char* argv[]) {
set st;//在容器中插入元素
st.insert(4);//任意位置插入一个元素
set::iterator it = st.begin();
st.insert(it, 2);//遍历显示
for (it = st.begin(); it != st.end(); it++) {
cout << *it << " ";//2 4
}
cout << endl;
return 0;
}
/*
2 4
*/
删除函数
#include
#include
using namespace std;
int main(int argc, char* argv[]) {
set st;
for (int i = 0; i < 8; i++) {
st.insert(i);
}
//删除容器中值为elem的元素
st.erase(4);
//任意位置删除一个元素
set::iterator it = st.begin();
st.erase(it);
//删除[first,list]之间的元素
st.erase(st.begin(), ++st.begin());
//遍历显示
for (it = st.begin(); it != st.end(); it++) {
cout << *it << " ";//输出:2 3 5 6 7
}
cout << endl;
st.clear();//判断set是否为空
if (st.empty()) {
cout << "集合为空" << endl;//输出:集合为空
}
return 0;
}
/*
2 3 5 6 7
集合为空
*/
访问函数
#include
#include
using namespace std;
int main(int argc, char* argv[]) {
set st;
for (int i = 0; i < 6; i++) {
st.insert(i);
}
//通过find(key)查找键值
set::iterator it;
it = st.find(2);
cout << *it << endl;//输出:2
return 0;
}
/*
2
*/
其他好用的函数
s.lower_bound()
s.upper_bound()
其中lower_ bound 返回集合中第一个大于等于关键字的元素。upper_ bound 返回集合中第一个严格大于关键字的元素。
multiset库
1、multiset容器的概念和性质
set 在英文中的意思是:集合。而multi-前缀则表示:多重的。所以multiset容器就叫做:有序多重集合
multiset的很多性质和使用方式和set 容器差不了多少。而multiset容器在概念上与set容器不同的地方就是:set的元素互不相同,而multiset的元素可以允许相同。
与set容器不太一样的地方:
s.erase(k);
erase(k) 函数在set容器中表示删除集合中元素k。但在multiset容器中表示删除所有等于k的元素。T(n)=(tot+logn),其中tot表示要删除的元素的个数。那么,如何只删除这些元素的一个元素呢?
if((it)=s.find(a))!=s.end())
s.erase(it);
if中的条件语句表示定义了一个指向一个a元素迭代器,入股go这个迭代器不等于 s.end() 就说明这个元素的确存在,就可以直接删除这个迭代器指向的元素了。
s.cout(k);
count(k) 函数返回集合中元素k的个数。set容器中并不存在这种操作。这是multiset独有的。
bitset库
1、bitset容器概论
bitset容器其实就是一个0101串。可以被看作是一个bool数组。它比bool数组更优秀的优点是:节约空间,节约时间支持基本的位运算。在bitset容器中,8位占一个字节,相比于bool数组4位一个字节的空间利用率要高很多。同时,n位的bitset在执行一次位运算的复杂度可以被看作是n/32,这就是bool数组所没有的优秀性质。
bitset容器包含在 C++ 自带的bitset库中
#include
2、bitset容器的声明
因为bitset容器就是装0101串的,所以不用在<> 中装数据类型,这和一般的STL容器不太一样。 <>中装0101串的2位数。
如:声明一个 10000 位的bitset
bitset<100000> s;
3、对bitset容器的一些操作
1、常用的操作函数
和其他的STL容器一样,对bitset的很多操作也是由自带函数来实现的。下面,我们来介绍一下bitset的一些常用函数及其使用方法。
count() 函数
数数的意思。它的作用是数出1的个数。即s.count()返回s中有多少个1。
s.count();
any()/none() 函数
s.any()//bitset容器中至少有一个1 返回true 否则返回 false
s.none()//bitset容器中全为0 返回true,否则返回 false
set()函数
作用:把bitset全部置为1 。特别地,set() 函数里面可以传参数。set(u,v)的意思是把bitset中的第u位变成v,v属于0/1
s.set();
s.set(u,v);
reset()函数
与set() 函数相对地,reset()函数将bitset的所有位置为0 。 而reset()函数只传一个参数,表示把这一位改成 0 。
s.reset();
s.reset(k);
flip()函数
flip() 函数与前两个函数不同,它的作用是将整个bitset容器按位取反。同上,其传进的参数表示把其中一位取反。
s.flip();
s.flip(k);
2、为运算操作在bitset中的实现
bitset 的作用就是帮助我们方便地实现位运算的相关操作。它当然支持位运算的一些操作内容。我们在编写程序的时候对数进行的二进制运算可以用在bitset函数上。比如:
~//按位取反
&//按位与
|//按位或
^//按位异或
<<>>//左/右移
==/!= //比较两个bitset是否相等
/*bitset容器支持直接取值和直接赋值的操作:具体操作方式如下*/
s[3]=1;
s[5]=0;
1、bitset容器的实际应用
bitset可以高效率地对01串,01矩阵等等只含0/1的题目进行处理。其中支持的许多操作对我们处理数据非常有帮助。如果碰到一道0/1题,使用bitset或许是不错的选择。
map库
1、map容器的概念
map是“映射容器”,其存储的两个变量构成了一个键值到元素的映射关系。比如下图。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2lDEfBdL-1626960662510)(…/StudyFile/YnoteFile/qq696E0BBC7CB2844D12BDF4792A6B5131/71f4ee5e15ef436a9c00f849bf68257f/image.png?ynotemdtimestamp=1614041709336)]
我们可以根据键值快速地找到这个映射出的数据。map容器的内部实现是一棵红黑树(平衡数的一种)。
2、map容器的声明
map容器存在于STL模板库
#include3、map容器的用法
因为map容器和set容器都是使用红黑树作为内部结构实现的。所以其用法比较相似。但由于二者用途大有不同,所以其用途还有微妙的差别。对于初学者来讲,其更容易涉及到的应该是vector容器,queue容器等。
1、常规操作
如其他C++STL容器一样,map支持基本相同的操作:比如清空操作,函数clear(),返回容器大小size(),返回首尾迭代器begin(),end() 等
2、插入操作
map容器的插入操作大约有两种方法,第一种是类似于数组类型,可以把键值作为数组下标对map进行直接赋值:
mp[1] = 'a';
当然,也可以使用insert()函数进行插入:
mp.insert(map::value_type(5,'d'));
3、删除操作
可以直接用erase() 函数进行删除,如:
mp.erase('b');
4、遍历操作
和其他容器差不多,map也是使用迭代器实现遍历的。如果我们要在遍历的时候查询键值(即前面的那个),也可以用
it->first
来查询,那么,也可用
it->second
查询对应值(后面那个)
5、查询操作
map中查询的都是键值,比如
mp.find(1);
即查找键值为1的元素。
4、map和pair的关系
map和C++ 内置二元组特别相似。那是不是map就是pair?(当然不是)
那么map和pair又有什么关系呢?
首先,map构建的关系是映射,也就是说,如果我们想查询一个键值,那么只会返回唯一的一个对应值。但是如果使用pair的话,不仅不支持O(logn)级别的查找,也不支持知一求一,因为pair的第一维可以有很多一样的,也就是说,可能会造成一个键值对多个对应值的情况,显然这不是映射。
vector 二维数组
1、定义
vector> A //错误的定义方式
vector > A //正确的定义方式
2、插入元素(两种方式)
1、第一种方式
//正确的插入方式
vector > A;
//A.push_back里必须是vector
vector B;
B.push_back(0);
B.push_back(1);
B.push_back(2);
A.push_back(B);
B.clear();
B.push_back(3);
B.push_back(4);
B.push_back(5);
A.push_back(B);
2、第二种方式
vector > A;
for(int i = 0; i < 2; ++i) A.push_back(vector());
A[0].push_back(0);
A[0].push_back(1);
A[0].push_back(2);
A[1].push_back(3);
A[1].push_back(4);
3、长度
//vector >A中的vector元素的个数
len = A.size();
//vector >A中第i个vector元素的长度
len = A[i].size();
4、访问某元素
访问某元素时,方法和二维数组相同,例如:
//根据前面的插入,可知输出5。
printf("%d\n", A[1][2]);