【Transformers-实践2】——Bert-CRF用于英语平坦实体(Flat NER)识别
本文是学习使用Huggingface的Transformers库的简单实践,我们简单的梳理一下模型的结构,以及具体的程序结构。我用的是Pytorch,虽然代码比较简单,但还是附上地址:https://github.com/zuochao912/Bert_CRF。
1、任务目标
本文的任务目标在于利用预训练的语言模型,辅助下游的英语的平坦命名实体识别任务。
2、模型结构
主要包括四大模块:tokenizer、Bert model、classifier、CRF layer,其大致的功能如下。
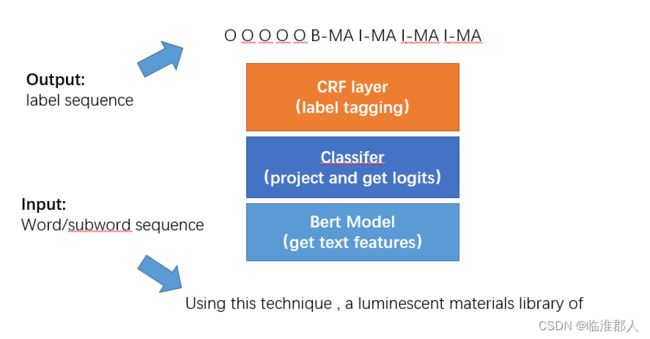
特别提醒,我们输入Bert前的数据为word分词的结果,但是我们需要将其tokenize化,因此输入Bert的实际上是subword的id序列,对应的输出label,也是subword对齐后的label,而不是原本的word的label。
3、程序结构
包括一般的网络搭建过程,以及Hugging face的Transformer库的Pipeline。实际上Hugging face提供的pipeline是比较简单的,直接通过简单的Api调用就可以完成。
- 参数设置;
- 数据预处理(使用tokenizer处理输入数据、标签)
- 预训练模型加载:model;
- 训练过程:设置优化器、train_step、Evaluate_step、save_model
3.1、参数设置
在这一部分,主要是对模型的学习率、batchsize等等进行设置。
parser = argparse.ArgumentParser()
parser.add_argument('--pretrain_model_name', type=str, default="bert-base-uncased", help='pretrain Model type')
parser.add_argument('--train_batch_size', type=int, default=32) #original is 16
parser.add_argument('--eval_batch_size', type=int, default=8)
parser.add_argument('--num_train_epochs', type=int, default=10)
parser.add_argument('--learning_rate', type=float, default=2e-5)
parser.add_argument('--seed', type=int, default=42)
parser.add_argument('--max_ckpt', type=int, default=2)
parser.add_argument('--model', type=str, default="bert_crf", help='Model type') #bert_crf
parser.add_argument('--ckpt_path', type=str, default="", help='trained model path') #ckpt_path
args = parser.parse_args()
在这里我们需要使用Bert的Tokenizer工具构建词表,以及获取相关数据,这里的设置如下,具体效果见数据预处理部分:
3.2、数据预处理
首先我们了解一下raw data的格式,该数据以json形式存储。

其次,我们统计数据集中的NER类型,并将标签转化为如下格式:
{"I-CH": 0, "I-PR": 1, "B-EQ": 2, "B-CH": 3, "B-PR": 4, "B-ST": 5, "I-MA": 6, "B-AP": 7, "B-SY": 8, "I-EQ": 9, "O": 10, "I-SY": 11, "I-ST": 12, "B-MA": 13, "I-AP": 14, "" : 15}
这样的格式并不利于我们进行序列标注,因此转化为BIO的标注模式,保存为txt文件,内容如下。
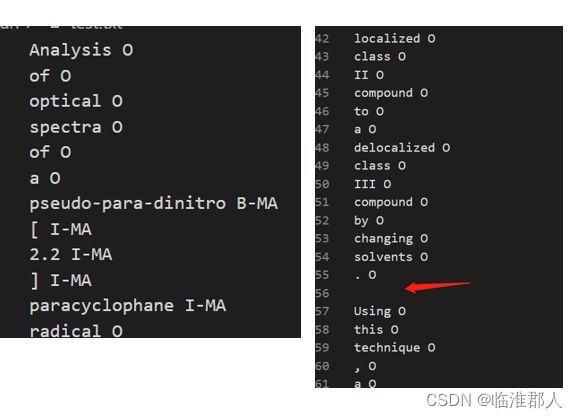
每一行就是一个词语+词语的标签。因此,一句话被分为若干行;一句话和一句话之间,使用一个空行断开。
我们进行相关的处理,将上述分开的词语再合并成一句话,代码和结果如下示意
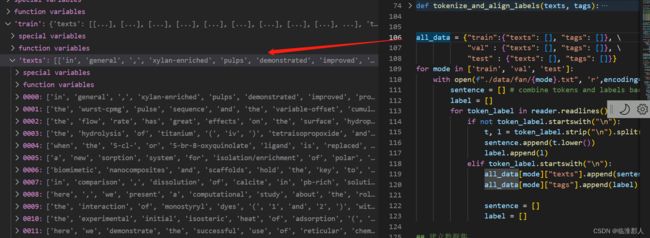
我们获取all_data后,对数据进行进一步的tokenize处理,这里使用tokenize_and_align_label完成该步骤。
首先对数据使用tokenizer,其设置与操作如下:
from transformers import BertTokenizerFast
parser.add_argument('--pretrain_model_name', type=str, default="bert-base-uncased", help='pretrain Model type')
tokenizer = BertTokenizerFast.from_pretrained(args.pretrain_model_name, do_lower_case=True) #这里我们使用bert-base-uncased模型
tokenized_inputs = tokenizer(
texts,
padding=True,
truncation=True,
# We use this argument because the texts in our dataset are lists of words (with a label for each word).
is_split_into_words=True,
)
具体得到结果如下。
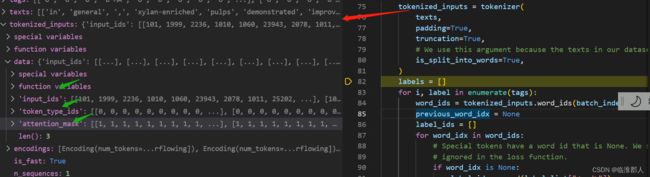
这里,对齐函数需要产生label,原因是原本的输入序列是完整的word,但是tokenize后是subword,因此需要把label和subword对齐。这里的方案是比较简单的,如下:
- 如果是tokenizer产生的额外token,那么对应标签为pad的标签,即15。
- 如果不是subword,而是正常的词语,或者是拆分词语后的subword头部时,那么对应标签为原本word的标签;
- 其它情况均对应标签为pad的标签,即15。换句话说,一个word被拆分为subword的时候,第一个subword继承了原本word的标签,其后的各个subword都标注为pad。
加载数据集如下:
class NER_dataset(Dataset):
def __init__(self, encodings, labels):
self.encodings = encodings
self.labels = labels
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
item['labels'] = torch.tensor(self.labels[idx])
return item
def __len__(self):
return len(self.labels)
这里还是要做个提醒,之前没有注意到。当getitem方法返回的是字典,其中键值对的值都是tensor的情况下,我们通过dataloader所得到依然是字典,只不过其中的数据已经被转化为batch类型了,我原先不知道原来字典也可以这样转换的。
3.3、模型结构
这里我们基于Bert的预训练模型进行NER工作,我们对模型包装为BERT_CRF_Model,并执行如下的单步训练过程。
model = BERT_CRF_Model.from_pretrained(args.pretrain_model_name, num_labels = 16)
def train_step(epoch,tokenizer,model,device,loader,optimizer):
model.train()
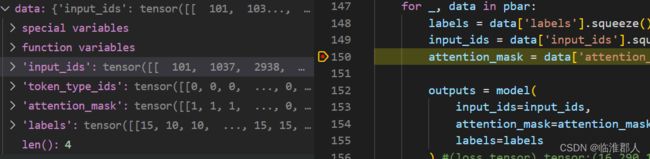
pbar = tqdm(enumerate(loader), total=len(loader)) #这个写法也挺有意思啊
for _, data in pbar:
labels = data['labels'].squeeze().to(device) #(Batch,290)
input_ids = data['input_ids'].squeeze().to(device) #(Batch,290)
attention_mask = data['attention_mask'].to(device) #(Batch,290)
outputs = model(
input_ids=input_ids,
attention_mask=attention_mask,
labels=labels
) #(loss,tensor),tensor:(16,290,16)
loss = outputs[0]
pbar.set_postfix(loss=float(loss.detach().cpu()), refresh=True)
optimizer.zero_grad()
loss.backward()
optimizer.step()
模型具体的结构如下,这里的参数、模型的初始化有自己的方法。表面上我们只传入了两个参数,但是实际上__init__的config参数是完整的Bert参数。
model = BERT_CRF_Model.from_pretrained(args.pretrain_model_name, num_labels = 16)
class BERT_CRF_Model(BertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.bert = BertModel(config, add_pooling_layer=False)
classifier_dropout = (
config.classifier_dropout if config.classifier_dropout is not None else config.hidden_dropout_prob
)
self.dropout = nn.Dropout(classifier_dropout)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
self.crf = CRF(num_tags=config.num_labels, batch_first=True)
# Initialize weights and apply final processing
self.post_init()

模型由Bert+Classifier+CRF层组成。在这里,我们不解释Bert模型和CRF的结构,CRF结构请见我的其它博客。
注意,Bert模型其实具体只用到了input_ids和attention_mask,其他参数都是None。CRF模型用到了Label。
其前馈过程如下:
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the token classification loss. Indices should be in `[0, ..., config.num_labels - 1]`.
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.bert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0] #Bert output object
sequence_output = self.dropout(sequence_output) #(batch,seqlen,hidden_size)
# crf_outputs = self.crf(sequence_output, )
logits = self.classifier(sequence_output) #logits:(batch,seqlen,num_tags)
loss = None
if labels is not None:
crf_loss = self.crf(emissions = logits, tags=labels, mask=attention_mask)
loss = -1*crf_loss
# outputs =(-1*loss,)+outputs
return loss, logits
我们可以查看中间结果,注意Bert输出的模型是一个比较全面的对象,包含了我们需要的种种信息。

4、Tokenizer库函数解释
这里比较重要的是tokenizer库函数。在本例子中,我们使用的是Transformer库的BertTokenizerFast,其继承于父类PreTrainedTokenizerFast。因此本小节从实用主义的出发,仅仅覆盖我们本次实验用到的一些对象和方法。
4.1 概述
原文对Tokenizer的解释如下:
A tokenizer is in charge of preparing the inputs for a model. The library contains tokenizers for all the models.
更为具体的,一般有两种实现方式
- full python implementation,基类为
PreTrainedTokenizer - “Fast” implementation,基于HuggingFace的Tokenizers库,其使用Rust具体部署。基类为
PreTrainedTokenizerFast。
在本样例中,我们使用的是“Fast” implementation,按照官方的说法,具有两个特点:
- 做batched tokenization 特别快;
- 有更丰富的功能函数:additional methods to map between the original string (character and words) and the token space (e.g. getting the index of the token comprising a given character or the span of characters corresponding to a given token).
但是二者作为tokenzier,都有其基本的功能,即:
- Tokenizing (splitting strings in sub-word token strings), converting tokens strings to ids and back, and encoding/decoding (i.e., tokenizing and converting to integers).
- Adding new tokens to the vocabulary in a way that is independent of the underlying structure (BPE, SentencePiece…).
- Managing special tokens (like mask, beginning-of-sentence, etc.): adding them, assigning them to attributes in the tokenizer for easy access and making sure they are not split during tokenization.
tokenizer使用时,输出一般是类BatchEncoding,包括使用__call__, encode_plus batch_encode_plus方法。BatchEncoding在基于不同Tokenizer的情况下,也有不同的行为。除了一些基础的输出内容外,Fast的tokenizer的输出还有相关的“对齐方法”,提供了Oiginal string (character and words) 和 token space (e.g., getting the index of the token comprising a given character or the span of characters corresponding to a given token)之间的转换函数。
4.2 基类方法
Transformer库中的PreTrainedTokenizerFast,实际上依赖于Huggingface的另一个库:tokenizers library。 原文说,如果想要充分了解tokenizer的类,那么建议去HuggingFace的官网仔细研读一下。但是这里就不读了,以后准备专门开一个栏目,叫做“Tokenizer——从理论到实践”,这里附上链接一条:https://huggingface.co/docs/tokenizers/index
我们在如下调用的时候,其实只用了几个参数,设置如下,并作详细的解释。
tokenized_inputs = tokenizer(
texts,
padding=True,
truncation=True,
# We use this argument because the texts in our dataset are lists of words (with a label for each word).
is_split_into_words=True,
)
- padding (bool, str or PaddingStrategy, optional, defaults to False) — 控制是否对输入进行填充(padding),可以输入布尔值(True)或者是控制字符串,例如“longest、max_length”。在这里,我们输入True等价于“longest”,Pad to the longest sequence in the batch (or no padding if only a single sequence if provided).
- truncation (bool, str or TruncationStrategy, optional, defaults to False) — 控制是否对句子进行截断(truncation )操作,可以输入布尔值(True)或者是控制字符串( ‘longest_first’、‘only_first’、‘only_second’)。在这里,输入True等价于’longest_first’,意思是当我们给定argument max_length参数的时候,将过长的句子剪裁到最大长度,当没有给定参数的时候,剪裁到模型的maximum acceptable input length。(其实后面还有一句说明,但没看懂,见参考文献【1】。
4.3 输出类:BatchEncoding
在训练过程中,我们用到重要的数据:
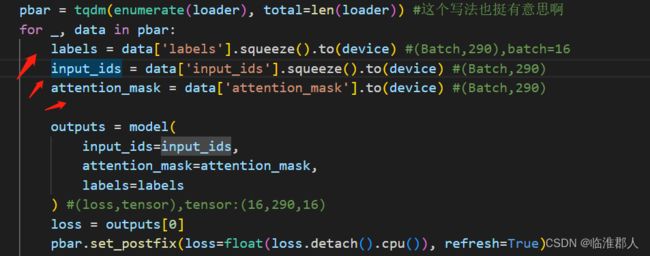
在经过处理后,相关的BatchEncoding对象在放入Dataset前,数据如下:
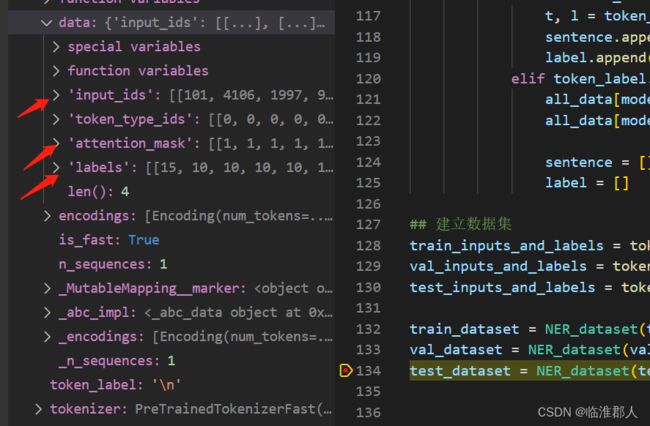
在Dataset中,有相关处理:
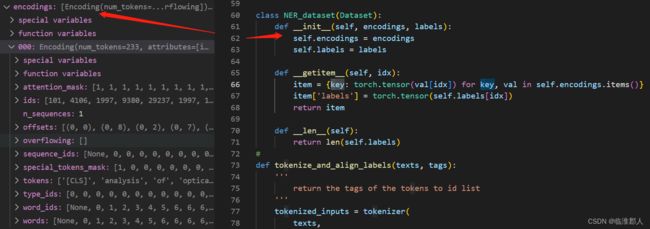
最后提取出的内容如下:
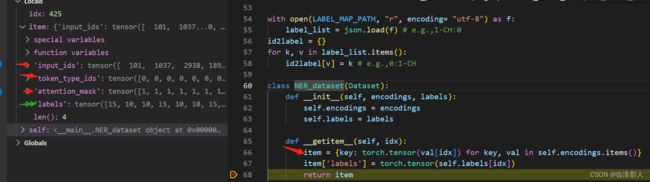
感觉有点奇怪,因为self.encodings似乎应该是之前的那个encoding列表,但是其实并不是,我们可以看到它是一个奇怪的对象,这里就暂时不纠结了,先做个记录。
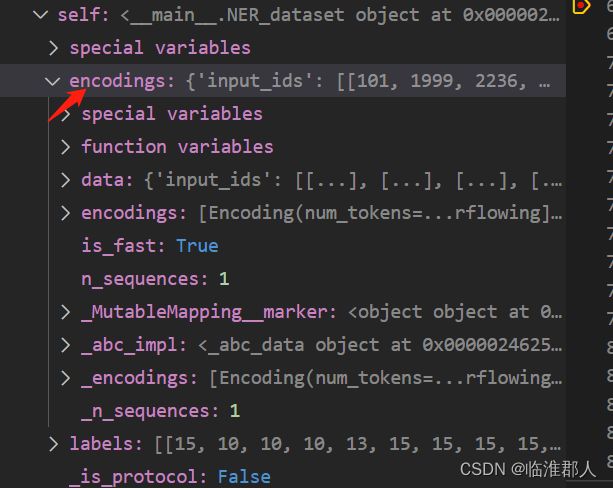
回过头,我们并没有解释input_ids、attention_mask、labels的含义。label是我们经过重新处理的对象,不做解释,前两者做如下解释,参见[2]。
4.3.1 attr:input_ids
input_ids其实就是输入的文本经过tokenize后,然后获得的token的下标号序列。token在中文应该叫“词元”,实际上可以是word或者subword。其中,subword一般用“##”开头,但是一个词语的第一个subword,不加“##”。
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-cased") # Bert a WordPiece tokenizer:
sequence = "A Titan RTX has 24GB of VRAM"
tokenized_sequence = tokenizer.tokenize(sequence)
print(tokenized_sequence) # ['A', 'Titan', 'R', '##T', '##X', 'has', '24', '##GB', 'of', 'V', '##RA', '##M']
inputs = tokenizer(sequence) # 获取BatchEncodings对象
encoded_sequence = inputs["input_ids"]
print(encoded_sequence) # 获取input_ids,[101, 138, 18696, 155, 1942, 3190, 1144, 1572, 13745, 1104, 159, 9664, 2107, 102]
decoded_sequence = tokenizer.decode(encoded_sequence) #将上面的id,再翻译回完整的句子,但是有首尾标记。
print(decoded_sequence) # [CLS] A Titan RTX has 24GB of VRAM [SEP]
4.3.2 attr:attention_mask
tensor对象。原本含义是,是否应该值得注意的对象。但是更为具体的, For the BertTokenizer, 1 indicates a value that should be attended to, while 0 indicates a padded value. This attention mask is in the dictionary returned by the tokenizer under the key “attention_mask”:
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
sequence_a = "This is a short sequence."
sequence_b = "This is a rather long sequence. It is at least longer than the sequence A."
encoded_sequence_a = tokenizer(sequence_a)["input_ids"]
encoded_sequence_b = tokenizer(sequence_b)["input_ids"]
len(encoded_sequence_a), len(encoded_sequence_b) # 8,19,注意,包括开头和结束的符号。
padded_sequences = tokenizer([sequence_a, sequence_b], padding=True) #由于两句话不一样长,因此作为batch,会把短句子补到和长句子一样长。
padded_sequences["input_ids"]
# [[101, 1188, 1110, 170, 1603, 4954, 119, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [101, 1188, 1110, 170, 1897, 1263, 4954, 119, 1135, 1110, 1120, 1655, 2039, 1190, 1103, 4954, 138, 119, 102]]
padded_sequences["attention_mask"]
#[[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]
4.3.3 function:.word_ids()
这里我们使用了相关方法:
word_ids = tokenized_inputs.word_ids(batch_index=i)
该函数的意思是,获取BatchEncoding的batch_index=i的token序列所对应的原词语的下标列表,如果是一些tokenizer新添加的token,那么它们不对应原本语句的词语,则对应的返回元素为None。
参考文献
[1]https://huggingface.co/docs/transformers/main/en/main_classes/tokenizer
[2]https://huggingface.co/docs/transformers/main/en/glossary