《ARMv8-A编程指南》阅读笔记-04
第六章 A64指令集
许多编程人员在应用层写代码,不需要接触底层的汇编语言。然而,汇编语言在需要高度优化的代码段中是非常有用的。
- 在写编译器这种类型的应用时。
- 需要使用C语言没有实现的底层功能时。
- 对boot代码进行移植时。
- 编写硬件驱动和操作系统时。
- 在对C语言代码进行调试,需要理解汇编指令和C语句之间的映射时。
以上场景中汇编语言的阅读能力可以提供很大的帮助。
6.1 指令助记符
A64汇编语言对助记符进行重载,并且按照操作寄存器的名称对不同形式的指令进行区分。例如,ADD指令,尽管下面几种ADD指令实际上使用不同的编码方式,但是你只需要记住一个指令符号。汇编器会自动根据操作数选择正确的编码方式。

6.2 数据处理指令
下面这些是处理器基本的算数、逻辑操作,操作数为通用寄存器或是一个寄存器和一个立即数。
数据处理指令大多数情况下只使用一个目的寄存器,但有两个源寄存器。通用的指令格式可以表示为指令后面跟上操作数。
I n s t r u c t i o n R d , R n , O p e r a n d 2 Instruction \ \ \ \ Rd, Rn, Operand2 Instruction Rd,Rn,Operand2
第二操作数可能是一个寄存器、一个被修改的寄存器,或是一个立即数。 R R R的含义是,这个寄存器可以是X开头(64位)或是以W开头(32位)。
数据处理操作包括:
- 算数或逻辑运算
- 移动或移位操作
- 有符号或0拓展指令
- 位或位域操作
- 条件比较或数据处理
6.2.1 算数和逻辑操作
下表中展示了一些可用的算数和逻辑运算指令
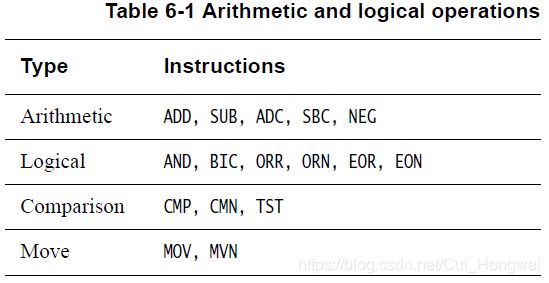
也有一些指令有一个S后缀,表示该指令会置位标志位。对于上表中给出的指令中,可以加S后缀的指令有:ADDS,SUBS,ADCS,SBCS,ANDS以及BICS。也有其他的一些指令会置位标志位,但是它们并没有显式的后缀,例如CMP,CMN和TST。
指令ADC和SBC分别实现加法和减法运算,它们也会将进位条件标志位作为输入:
A D C S : R d = R n + R m + C ADC{S}: Rd = Rn + Rm + C ADCS:Rd=Rn+Rm+C
S B C S : R d = R n − R m − 1 + C SBC{S}: Rd = Rn - Rm - 1 + C SBCS:Rd=Rn−Rm−1+C

逻辑操作本质上与对应的布尔操作一样,对寄存器的某一位进行操作。
BIC(Bitwise bit Clear)指令的执行过程是将目的寄存器后面的第一个操作数与第二个操作数取反后的结果进行与(AND)操作。例如,我们想清空寄存器X0的第11位:
M O V X 1 , # 0 x 800 MOV \ \ \ X1, \#0x800 MOV X1,#0x800
B I C X 0 , X 0 , X 1 BIC \ \ \ X0, X0, X1 BIC X0,X0,X1
ORN和EON实现的功能分别是与第二操作数按位取非(NOT)的结果进行或(OR)和异或(EOR)操作。
比较指令仅仅会修改标志位,没有其他的作用。这些指令使用的立即数长度为12位,并且这些立即数可以按照需要做不超过12位的左移操作。
6.2.2 乘除指令
A64乘指令所实现功能与ARMv7-A中的大致相同,但是可以使用单一指令完成64位的乘法。
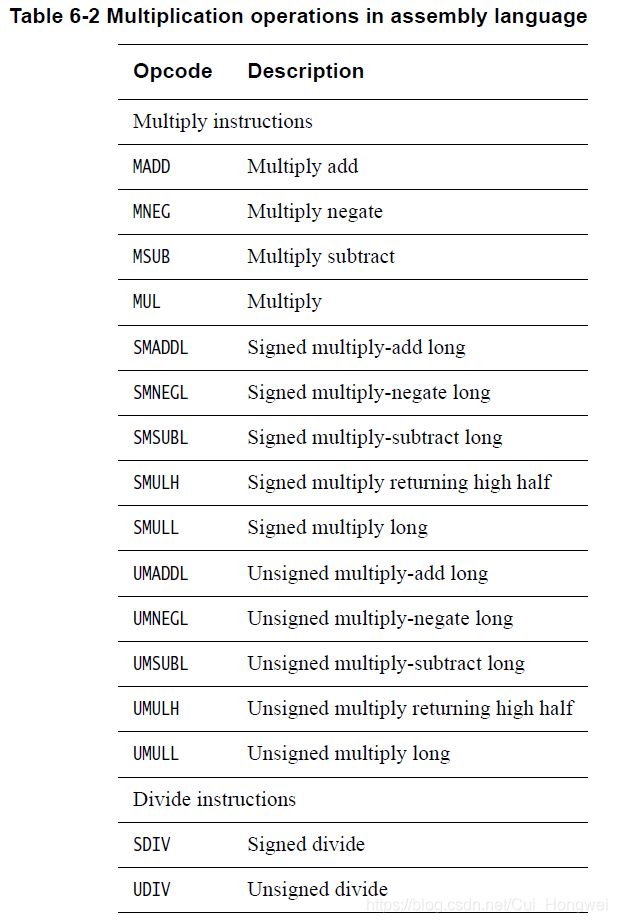
同时又对32位和64位操作数进行乘法运算的指令,返回结果的位数与操作数保持一致。例如,两个64位的寄存器可以使用MUL指令相乘得到一个64位的结果。
M U L X 0 , X 1 , X 2 / / X 0 = X 1 × X 2 MUL \ \ \ X0,X1, X2 \ \ \ // X0 = X1 × X2 MUL X0,X1,X2 //X0=X1×X2
A64指令集也提供乘加(减)融合的指令,分别是MADD和MSUB,加减运算的值需要放在第三源操作数的位置。
MNEG指令可以用于将乘法运算的结果取相反数:
M N E G X 0 , X 1 , X 2 / / X 0 = − ( X 1 × X 2 ) MNEG \ \ \ X0, X1, X2 \ \ \ //X0 = -(X1 × X2) MNEG X0,X1,X2 //X0=−(X1×X2)
另外,也有一些乘法指令可以得到更长数据类型的运算结果,例如,两个32位的数据相乘得到64位的运算结果。这类乘法运算还细分了有符号和无符号类型(分别是SMULL和UMULL),除此之外,还可以在之前的基础上再集成加减运算(UMADDL,SMADDL)或是取相反数(UMNEGL,SMNEGL)。
补充说明:
集成了加减或取相反数运算的乘法指令得到的结果的位数同样与操作数保持一致。
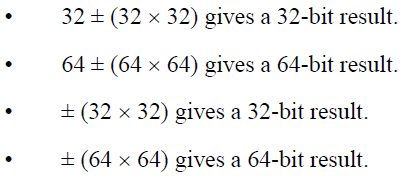
扩展位宽的乘法运算无论是有符号还是无符号、操作数列表中是否原本就包含64位的操作数,都会得到64位的运算结果。
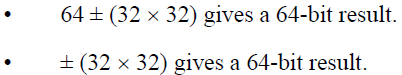
一个 64位 × 64位 得到 128位 运算结果的乘法操作需要两个指令构成一个序列来分配一对64位寄存器存放运算记结果。
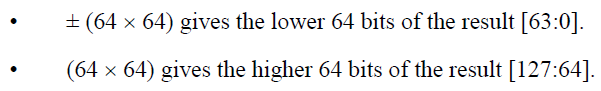
注意
不能使用32位的寄存器与64位的寄存器相乘(尽管上面的例子中显示可以在乘加指令的加减操作中混用不同位数的寄存器)
ARMv8-A架构的处理器支持32位或64位的有符号和无符号除法。
U D I V W 0 , W 1 , W 2 / / W 0 = W 1 / W 2 ( u n s i g n e d 32 − b i t s d i v i d e ) UDIV \ \ \ W0,W1,W2 \ \ \ // W0 = W1 / W2 \ (unsigned \ 32-bits \ divide) UDIV W0,W1,W2 //W0=W1/W2 (unsigned 32−bits divide)
S D I V X 0 , X 1 , X 2 / / X 0 = X 1 / X 2 ( u n s i g n e d 64 − b i t s d i v i d e ) SDIV \ \ \ X0,X1,X2 \ \ \ //X0 = X1 / X2 \ (unsigned \ 64-bits \ divide) SDIV X0,X1,X2 //X0=X1/X2 (unsigned 64−bits divide)
值得注意的是,运算结果产生溢出或是除数为0所造成的错误将不会被限制,而是有下面的处理方式:
- 任何整数被0所除得到的结果均为0。
- 溢出的现象仅仅会在有符号除法中出现(SDIV)
– INT_MIN / -1 返回 INT_MIN。在该式中INT_MIN是所能取到的整数最小值,除以-1,取相反数,则会造成溢出(以32位长度的有符号整型数据为例,范围是-65535~+65535)。除法得到的运算结果如果有小数,则向靠近0的方向取整,就像C/C++中约定俗成的那样。
6.2.3 移位操作
下面的指令是特别为移位操作所设计的:
- LSL 逻辑左移,逻辑左移一位,相当于在原数值的基础上乘2。
- LSR逻辑右移,逻辑右移一位,相当于在原数值的基础上除以2。
- ASR算数右移,与逻辑右移类似,算数右移一位相当于在原数值的基础上除以2,但与逻辑右不同的是,算数右移会保留最高位的符号位不变。
- ROR循环右移,循环右移将实现按位循环的操作,寄存器最低位被移出后将被重新写入到寄存器的最高位。
移位操作图示:
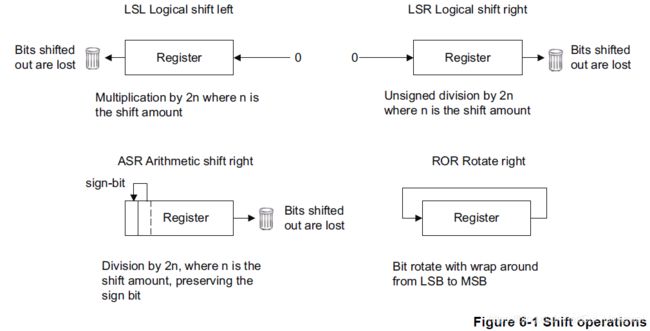
移位操作并不限制寄存器的位数,可以是32位或是64位的寄存器。移位的次数可以用立即数,但立即数的大小不能超过“寄存器长度 - 1”。移位的次数也可以从寄存器中读取,但是如果被移位的寄存器是32位的,那么移位数寄存器只有低5位有效;同理,如果被移位寄存器是64位的,移位数寄存器只有低6位有效。
6.2.4 位域和字节操作指令
有的指令也可以拓展字节、半字或是字的数据到32位、64位寄存器的位宽。这些指令既有适用于有符号变量的(SXTB,SXTH,SXTW)也有适用于无符号变量的(UXTB,UXTH)。这些指令的源寄存器通常是32位的W寄存器,目的寄存器可以是W寄存器也可以是X寄存器,但是有一个特例:SXTW,即将有符号数拓展到字位宽的指令,其目的寄存器必须是X寄存器。

实际上拓展变量位宽的指令实现的原理就是重复原数据的最高位,以填充寄存器中多出的高位。
A64中的位域指令域与ARMv7中已有的指令类似,并且包括位域插入(Bit Field Insert, BFI)以及有符号或无符号的位域提取(Bit Field Exact, [S/U]BFX)。还有其他的一些位域指令,例如BFXIL(Bit Field Extract and Insert Low)、UBFIZ(Unsigned Bit Field Insert in Zero),以及SBFIZ(Signed Bit Field Insert in Zero)。

一些位域操作的实际过程如上图所示,注意到:
- 位域插入会覆盖目的寄存器原有位中的值。
- 插入操作:BFI W0, W0, #n, #m; 将W0的低m位复制一份,覆盖W0从第n位开始延续到高位的m位。
- 提取操作:UBFX W1, W0, #n, #m; 把从W0的第n位开始延续到高位的m位提取出来,覆盖W0的低m位。
插入操作和提取操作的寄存器片段长度都是用第三操作数来规定的。第二操作数的意义对插入指令来说是插入位置的最低位编号(寄存器的位编号从0开始),对于提取指令来说是提取片段最低位的编号。
注意
A64中也新加入了BFM和UBFM指令,它们是位域转移指令。但在使用这两个指令时并不需要像其他指令那样在原有指令基础上添加前后缀,以区分应用场景(有符号、无符号,数据长度等)。
如果你对ARMv7架构熟悉,你也许还会认出其他位操作指令:
- CLZ:计算前导0。
类似的还有字节操作指令 - RBIT:将所有位取反。
- REV:将寄存器的字节顺序反向排列。
- REV16:将寄存器中所有半字中的字节反向排列(也就是每两个字节为一组,反向排列)。
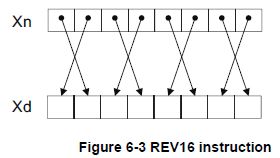
- REV32:将寄存器中所有字中的字节反向排列。
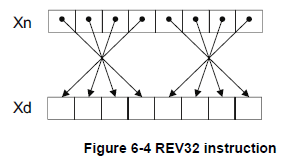
这些操作可以在每一个字或半字尺寸的寄存器中使用,但有一个特例,REV32指令只适用于64位宽的寄存器(以X开头的寄存器)。
6.2.5 条件指令
A64指令集并不支持所有指令的条件执行。指令的断言执行(带指令预测)没有带来足够的好处来抵偿它对操作数空间的大量使用。
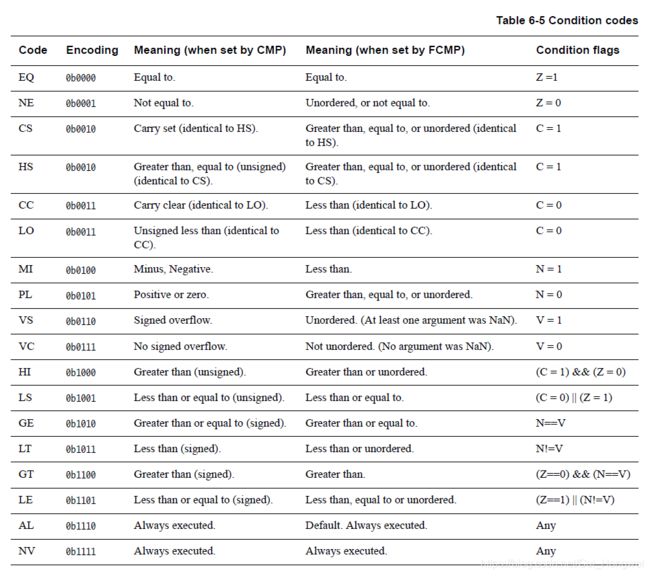
当前程序状态寄存器(CPSR)中有四个条件标志位,分别是N、Z、C、V。它们分别代表Negative、Zero、Carry、Overflow。下表中描述了这四个标志位被置位的条件:

其中C的置位代表无符号数操作造成存放运算结果的寄存器溢出。
V与C的置位条件类似,但适用于有符号数操作所产生的溢出。
注意
A64指令中的条件标志位和条件码与A32、T32中一致。但是A64条件码中加入了NV(0b1111)尽管它的行为同与之互补的AL(0b1110)一致。这一点与A32不同,在A32中并没有给0b1111赋予任何特殊含义。
只有很少的指令属于条件执行数据处理指令。有些指令属于非条件指令,但是会将条件标志位作为一个额外的指令输入。这些指令已经被用于代替ARM中被广泛应用的条件执行代码。
这些需要读取条件位的指令类型有:
带进位的加/减:这一类是传统的ARM指令,应用在多精度的算数运算和校验和中。
可带增量、取反或倒序的条件选择:在一个源寄存器,和另一个增量、取反、倒序或未被修改的源寄存器之间做条件选择。
在A32和T32指令集中,单一条件指令的典型用法有:条件计数、计算有符号数的绝对值。
条件操作
A64指令集仅使能了程序流分支控制指令的条件执行。对比A32指令集和T32指令集,它们中大多数指令可以用条件码进行预测。有如下总结:
条件选择(移动):
- CSEL,根据单一条件对两个寄存器进行选择。非条件指令后面跟一个条件选择可以代替短的条件序列。
- CSINC,根据单一条件对两个寄存器进行选择,返回第一个或第二个源寄存器加1后的值。
- CSINV,根据单一条件对两个寄存器进行选择,返回第一个源寄存器或逆序的第二个源寄存器。
- CSNEG,根据单一条件对两个寄存器进行选择,返回第一个云寄存器或取相反数的第二个寄存器。
条件置位:
有条件地选择从0、1中选择(CSET)或是从0和-1中选择(CSETM)。使用场景包括以布尔值设置条件标志位或是在通用寄存器中设置掩码。
条件比较:
CMP和CMN会根据比较的结果设置条件标志位。条件比较指令在表达嵌套或混合的比较时很有用。
注意
条件选择和条件比较同样适用于浮点寄存器,但是需要使用单独的FCSEL和FCCMP指令。
例如:
C S I N C X 0 , X 1 , X 0 , N E / / 寄 存 器 X 0 自 增 , 直 到 与 寄 存 器 X 1 相 等 , 返 回 X 0 的 值 CSINC \ \ \ X0,X1,X0,NE \ \ \ // 寄存器X0自增,直到与寄存器X1相等,返回X0的值 CSINC X0,X1,X0,NE //寄存器X0自增,直到与寄存器X1相等,返回X0的值
CSINC用法参考
这些指令提供了一个有效方式来避免使用分支或条件执行指令。编译器或是汇编代码的编写人员可以使用这些操作指令来实现原本“if-then-else”语句所完成的功能,得到完全一致的结果。

6.3 内存访问指令
与之前所有的ARM处理器一样,ARMv8仍然是Load/Store架构。这意味着数据处理指令不能直接在内存中进行操作,而是必须先将待处理的数据加载到寄存器中,处理完毕后,再转移到内存中保存。程序必须指定一个地址,将被传输的数据所占用的空间大小,以及一个目的寄存器或是源寄存器。也有一些额外的Load, Store指令能够实现进一步的操作,例如:非时间性Load/Store指令,互斥Load/Store指令以及Acquire/Release指令。
Load/Store令可以以非对齐的方式访问普通内存,但互斥访问,以及其他Load, Acquire / Store, Release的变体均不支持该属性。如果不需要进行内存的非对齐访问,可将其设定为错误。
6.3.1 Load 指令格式
Load指令的通用格式为:
L D R R t , < a d d r > LDR \ \ \ Rt, \ \ \
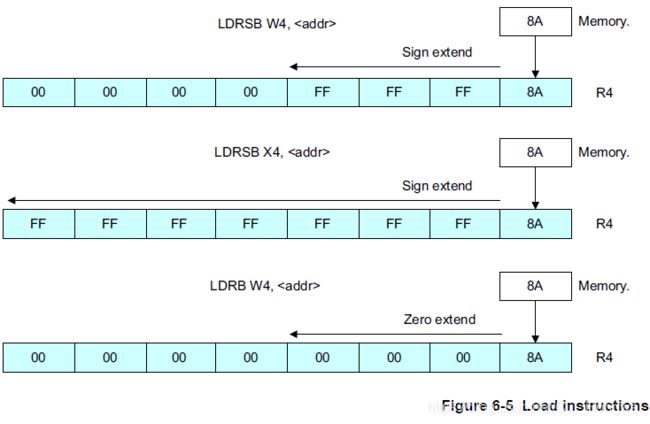
| 指令 | 作用 |
|---|---|
| LDRB | 源数据大小为8位,0拓展 |
| LDRSB | 源数据大小为8位,符号位拓展 |
| LDRH | 源数据大小为16位,0拓展 |
| LDRSH | 源数据大小为16位,符号位拓展 |
| LDRSW | 源数据大小为32位,符号位拓展 |
当然,也有自定义偏移量的加载指令(unscaled-offset),形如:
L D U R < X t > , [ < X n ∣ S P > ] { , # < s i m m > } ] LDUR \ \ \
当大括号里的内容有效时 X n 或 S P Xn或SP Xn或SP地址中的数据加载到寄存器 X t Xt Xt中,然后寄存器 X n 或 S P Xn或SP Xn或SP中存储的地址自增立即数 < s i m m >
下面的插图形象说明了0扩展和符号位拓展的操作过程:
6.3.2 Store指令模型
类似的,Store指令的通用格式是:
S T R R n , < a d d r > STR \ \ \ Rn, \ \ \
同样,也有自定义偏移量的的形式,形如 S T U R < t y p e > STUR \ \ \
同样,大多数汇编器能够选择根据所需的偏移量自动选择合适的指令版本,因此该类指令并不常用。
存入寄存器的数据尺寸也许比寄存器的位宽小,用户可以在Store(STR)后面加上一个B或H后缀用于表示寄存器所需要实用的最少有效位数。
6.3.3 浮点和NEON寄存器的批量加载和存储
Load/Store指令同样也可以访问 浮点/NEON 寄存器。这里,操作的数据尺寸仅由寄存器本身的位宽决定,这类寄存器根据位宽有B,H,S,D以及Q类型,具体可以参考下面的表格。
对于Load指令有:
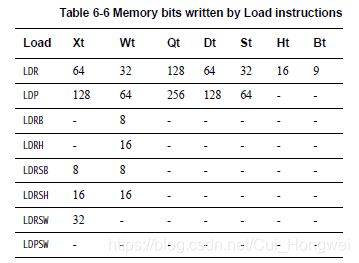
对于Store指令有:
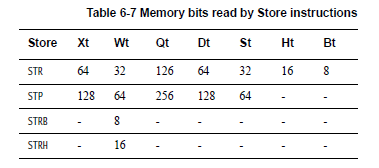
无符号拓展也可以用于FP/SIMD(浮点/单指令多数据)寄存器的加载。例如: L D R D 0 , [ X 0 , X 1 ] LDR \ \ \ D0, \ \ \ [X0, \ \ X1] LDR D0, [X0, X1]
上述指令所实现的功能是将X0和X1寄存器中存储内容相加的结果作为提取源数据的地址,以双字(doubleword)格式存储到D0寄存器中。
注意:
浮点存取指令和NEON顺次加载和存储指令与整数的寻址方式相同。
6.3.4 指定Load/Store指令的操作地址
A64指令集的寻址方式与A32和T32类似,但也新增了一些限制。
使用A64指令集,指令操作数的基寄存器必须是X寄存器(64位寄存器)。由于有些指令支持对寄存器的0扩展或符号位拓展,所以可以将X寄存器的低32位充当W寄存器使用。
偏置模式(offset mode)
偏置寻址模式是在64位基寄存器上加上一个立即数或寄存器的内容来生成一个新地址用于寻址。具体操作如下表所示:

通常来说,当指令了移位或拓展操作,移位的数量可以是0(省缺值)或目标偏移量的2次幂指数(例如,偏移8个字节,取偏移量为 l o g 2 8 log_2{8} log28)
索引模式(index mode)
索引模式与偏置模式类似,也回修改基寄存器的内容,语法同A32、T32指令集一致,但有更强的限制,通常,只有立即数的偏置才能用于索引模式。
索引模式一共有两种变体:预索引模式(pre-index),该变体在访问内存前先进行移位操作(修改基寄存器的值);另一种变体是后索引模式(post-index),该变体在访问内存后才修改基寄存器的值。
下表对这两种变体的操作进行对比

我们看到,在预索引的两条指令最后都有一个感叹号,表示先根据规则修改基寄存器的内容,然后载根据修改后的地址进行存取操作。第三条指令,-16显然不是立即数,这里所表达的意思是就是简单的算数运算 S P − 16 SP-16 SP−16
即指针寄存器的值减少16。
如何判断32立即数:
- 什么是立即数
每一个32位立即数都可以由一个8位常数循环右移偶数位得到。循环右移的位数由一个四位二进制数的两倍表示。 - 判断方法
(1) 首先将数据转换成二进制形式。
(2) 如果1的个数大于8,则一定不是立即数。
(3) 如果最高和最低位的1之间有超过24个0,则一定不是立即数。
(4) 掐头去尾,分别去掉最高和最低位的1两侧最大偶数个0,如果剩下的位数仍然大于8,则一定不是立即数。
参考博客
相对地址访问模式
A64指令集中新增了另一个寻址模式,专门用于访问常量池。常量池是经过编码被插入到指令流中的数据块,通常被用于存储代码中用到的常量。这些常量不适合与不断执行、跳转的指令代码存放在一起。常量池中的数据是不可执行的,但它们可以被存储在常量池周边一定内存范围内的代码通过相对地址进行访问(相对于PC寄存器中的地址)。
在A32和T32指令集中,PC寄存器可以像通用寄存器那样被随意读取,所以常量池可以通过将PC寄存器设置为基寄存器,设置相对偏移量(相对地址)这种简单地方式来进行访问。
但是在A64指令集中,PC寄存器并不能像通用寄存器那样进行访问。为了实现A32、T32中的相对地址访问功能,新增了一个特殊的寻址模式。这种新增的寻址模式相较于A32、T32的版本有更大的相对地址范围,所以常量池在指令流中的分布可以更加稀疏。

注意:
6.3.5 访问多内存地址
A64指令集中并不包括A32和T32指令集中的批量加载指令(Load Multiple),即LDM指令或是批量存储指令(Store Multiple),STM。
在使用A64指令集的代码中有对加载(Load Pair)LDP,和对存储(Store Pair)STP指令。于A23指令集中的LDRD和STRD指令不同,LDP、STP可以同时对任意两个整数寄存器进行操作。
补充:A32、T32指令集对双字寄存器的限制
形如 L D R D { c o n d } R t , R t 2 , l a b e l LDRD \{cond\} \ \ \ Rt, \ \ \ Rt2, \ \ \ label LDRD{cond} Rt, Rt2, label
- R t Rt Rt必须是编号为偶数的寄存器
- R t Rt Rt不能是LD寄存器(链接寄存器)
- 不推荐将R12作为 R t Rt Rt使用
另补充:
R12(IP)不仅仅是作为通用寄存器使用。由于无论是A32指令集还是T32指令集中的BL指令都无法访问到全部的32位存储空间,所以,链接器有必要在程序转跳的路由、子路由之间插入一段胶水代码(veneer)来应对代码内部关联以及长分支中代码的重定位。插入的这段胶水代码必须对所有寄存器(除了R12)以及条件标志位中的内容进行保护。而R12(IP)将被作为胶水代码的专用寄存器,用于存储中间变量。在已知上述情况下,一段符合规范的代码必须假定R12会在任何分支指令中被修改,以避免意外的发生。结合指令简单理解:当汇编代码中存在BL指令,R12的内容可能会被连接器插入的胶水代码在编程人员并不知情的情况下修改。
这件事情给我们的启示:事实上纯C语言并不会受到影响,因为编译器自然会处理这些寄存器冲突,所以尽量不要使用内联汇编。
参考博客
- R t 2 Rt2 Rt2必须是 R ( t + 1 ) R(t+1) R(t+1),即该指令必须从连续的内存中读取到连续的寄存器中。
参考
作为对比,关于STP和LDP的使用方法可以参照下表。
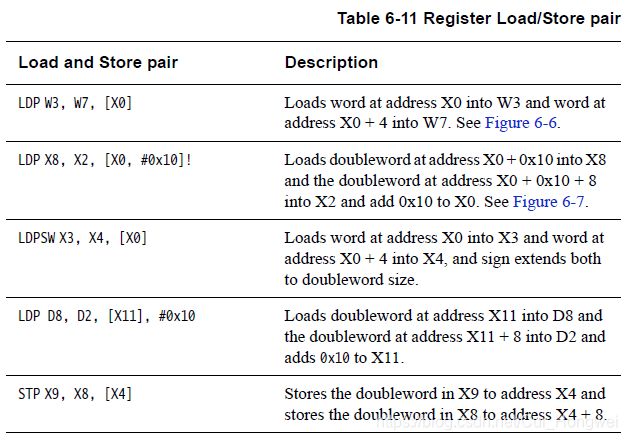
可以看到,A64指令集中并不要求LDP的目的寄存器或STP的源寄存器编号必须连续。

6.3.6 未经授权的访问
A64指令集中的LDTR和STTR指令实现了未授权的加载和存储操作。
- 在L0、EL2或EL3异常等级下,它们和普通Load/Store指令的功能相同。
- 但在EL1异常等级下,它们表现出的特性就像已经在EL0异常等级下已经执行过一样。这些指令等价于A32指令集下的LDRT和STRT指令。
- A32中的STRT和LDRT指令的作用是:在用户模式下进行存取操作。
6.3.7内存预取
内存预取指令 P R F M PRFM PRFM指令使能代码向存储系统发出提示信息,告诉存储系统特定地址的数据将很快被程序用到。这个提示所起到的作用以及收到提示后所进行的操作需要用户自己实现。但通常来说,接下来需要将指令或数据加载到对应的缓冲区中。
该指令的语法:
P R F M < p r f o p > , < a d d r > ∣ l a b e l PRFM \ \ \
其中 < p r f o p >
| 选项名称 | 选项内容 |
|---|---|
| 预取类型 | PLD(prefetch for load)或PST(prefetch for store) |
| 目标缓冲区 | L1、L2或L3 |
| 预取策略 | KEEP(keep in cache)或STRM(streaming data) |
例如: P L D L 1 K E E P PLDL1KEEP PLDL1KEEP
这个指令与A32指令集中的PLD和PLI类似。
6.3.8 非临时-对-加载/存储(Non-temporal load and store pair)
非临时(non-temporal)是ARMv8中引入的新概念。指令 L D N P LDNP LDNP和 S T N P STNP STNP指令不仅会对一对寄存器进行存取操作,同时它们会向存储系统发出提示:对于当前数据而言,cache不能很好地发挥加速指令运行的作用。这条提示并不会禁止存储系统进行诸如将数据从地址加载到cache中、预加载或是数据收集这些活动。这类指令的一个典型应用场景也许是对数据流的处理,但是注意,有效使用这些指令需要特定于微结构的方法。
非临时加载和存储减轻了内存调用需求。在上述案例中,如果LDNP指令与LDR指令联用,LDNP指令可能会在LDR命令之前生效,例如:
![]()
此时X0中的内容是不确定的。为了纠正这个问题,需要插入一个加载屏障,使屏障之前的指令执行完毕后再继续向下执行。

注:
DMB指令是内存屏障指令,即Data Memory Barrier。
参考链接
6.3.9 内存访问的原子操作
一次使用单一通用寄存器且对齐的内存访问就是内存访问的原子操作。对两个通用寄存器使用对齐的对加载、对存储指令,实际上是进行了两次独立的原子操作。未对齐的内存访问都不是原子操作,因为处理未对齐的情况通常需要两次内存访问操作才能完成。另外,浮点以及SIMD(单指令多数据)内存访问不是原子操作。
6.3.10 内存屏障和栅栏指令
ARMv7和ARMv8架构都提供不同的屏障操作。
- DMB指令,Data Memory Barrier,内存访问屏障。强制该指令之前所有的内存访问全局可见后再去执后面的其他指令。
- DSB指令,Data Synchronization Barrier,数据同步屏障。将所有被挂起的加载、存储,cache维护指令以及转换后援缓冲区(TLB, Translation Look-aside Buffer。)维护指令执行完毕才可以继续执行下面的指令。DSB指令与DMB指令类似,但还有一些附加性质。
- ISB指令,Instruction Synchronization Barrier,指令同步屏障。这条指令将清空CPU的流水线以及预取缓冲区(prefetch buffer),这将导致在ISB之后的指令需要从内存或cache中抓取或重新抓取。
ARMv8架构中引入了单边的栅栏指令,这些指令与Release Consistency模型相关,被称作Load-Acquire (LDAR) 以及Store-Release (STLR),并且它们都是基于地址的同步基础同步操作(同步原语)。两个操作可以搭配使用形成一个完整的栅栏。但这些指令仅支持基寄存器寻址,不支持相对寻址或上面所提到的其他任何形式的索引寻址。
6.3.11 同步原语
ARMv7-A和ARMv8-A架构都提供对内存互斥访问的支持。在A64指令集中就是Load/Store互斥对(LDXR/STXR)。
LDXR指令从内存地址中加载一个数据并且尝试对该地址静默声明一个互斥锁。然后只有在互斥锁成功获取并启用后STXR指令才能向该地址中写入一个新的值。LDXR/STXR这对指令被用于构建标准同步原语,例如自旋锁(spinlock)。互斥存取操作也提供对存取指令LDXRP/STXRP,让代码可以自动对横跨两个寄存器的数据进行更新。互斥操作同样也支持字节、半字、字以及双字操作。就像Load-Acquire/Store-Release 配对机制,互斥指令仅支持使用基地址,不支持相对寻址以及其他任何形式的索引寻址。
CLREX指令可以清空监视器,但是与ARMv7架构不同的是:进入异常或从异常中返回也会清空监视器。监视器也有可能被意外地清空,例如cache回收或与应用程序不直接相关的其他原因。软件自身必须避免对内存的直接访问以及对系统控制寄存器的更新抑或是在LDXR、STXR指令中间调用对cache的维护指令。
也有一个Load-Acquire/Store-Release指令的互斥对,LDAXR/STLXR。
6.4 流控制
A64指令集提供了许多不同种类的分支指令。对于简单的相对分支(即相对地址跳转),有 B B B指令。非条件简单相对分支以当前程序运行位置为基地址,前向、后向寻址128MB。简单的条件相对寻址,附加一段条件代码到B指令上,有相对较小的寻址空间为±1MB。
对子程序的调用,将返回地址存储到链接寄存器(X30)中是十分必要的,此时需要使用 B L BL BL指令。BL指令没有条件转跳的版本。相对于 B B B指令而言, B L BL BL指令只是又增加了一个存储返回地址的操作。
其他分支指令可以参考下面的表格:

另外对于这些以PC作为基寄存器的指令,A64指令集包括两个绝对分支指令。 B R X n BR \ \ \ Xn BR Xn 指令实现的就是转跳到寄存器 X n Xn Xn中存储的绝对地址。对应的 B L R BLR BLR起到的作用与 B R BR BR相同,但会将返回地址存储到链接寄存器(X30)中。 R E T RET RET指令起到的作用也与 B R BR BR相同,但会向分支预测逻辑发出信息,表明这是一个函数返回时产生的跳转。默认情况下,如果没有规定返回的绝对地址, R E T RET RET会转跳到之前存储在X30中的地址。
A64指令集中包括一些特殊的条件分支,这些指令可以在一些场景中提高代码密度,因为省去了不必要的比较指令。

这些指令会将32位或64位的源寄存器 R t Rt Rt同0进行比较,然后有条件地执行分支。分支地相对地址偏移范围需要在±1MB以内。这些指令实际上并没有读取或写入系统状态寄存器中的条件标志位(NZCV)。
下面是两个类似的测试和分支指令。
![]()
![]()
这些指令检测源寄存器 R t Rt Rt中被立即数 b i t bit bit标志的特定位,根据该位是否被置位有条件地进行转跳。分支地相对地址偏移范围在±32kB以内。同CBZ/CBNZ指令一样,这两条指令都不会读写系统寄存器中的条件标志位。