多模态大语言模型综述来啦!一文带你理清多模态关键技术
作者 | 智商掉了一地、Python
随着 ChatGPT 在各领域展现出非凡能力,多模态大型语言模型(MLLM)近来也成为了研究的热点,它利用强大的大型语言模型(LLM)作为“大脑”,可以执行各种多模态任务。更让人感慨的是,MLLM 展现出了传统方法所不具备的能力,比如能够根据图像创作故事,无需 OCR 的数学推理等,这为实现人工智能的通用智能提供了一条潜在路径。
也不乏有全面和前沿的综述出现,本文作者的目标是追踪和总结 MLLM 的最新进展。介绍了 MLLM 的构建方式并对相关概念概述,还深入讨论了关键技术和应用。同时,他们也指出了当前研究中存在的挑战,并提出了一些有前景的研究方向。鉴于 MLLM 的时代刚刚开启,作者们将持续更新这篇综述,以期待能够激发更多的研究。
论文题目:
A Survey on Multimodal Large Language Models
论文链接:
https://arxiv.org/abs/2306.13549
Github 地址:
https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models
大模型研究测试传送门
GPT-4能力研究传送门(遇浏览器警告点高级/继续访问即可):
https://gpt4test.com
大模型AI全栈手册
行业首份AI全栈手册开放下载啦!!
长达3000页,涵盖大语言模型技术发展、AIGC技术最新动向和应用、深度学习技术等AI方向。微信公众号关注“夕小瑶科技说”,回复“789”下载资料
![[图片]](http://img.e-com-net.com/image/info8/bbca7a0148aa4cc99ef6f20fe54296e0.jpg)
论文速览
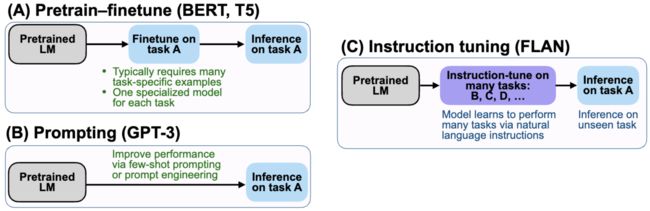
多模态指令调优(Multimodal Instruction Tuning)
指令是任务描述。指令调优是通过在一组以指令格式组织的数据集上微调预训练的 LLM,以实现对未见任务的泛化能力提升。这一简单而有效的思想已在自然语言处理领域的一系列工作中得到成功应用,如 ChatGPT、InstructGPT、FLAN 和 OPT-IML。
图 1 展示了指令调优与其他典型学习范式的比较。传统的监督微调方法需要大量特定任务的数据,而提示方法通过引入提示工程来减少对大规模数据的依赖,虽然少样本性能有所提升,但零样本性能相对平均。指令调优与这两种方法不同,它着重于学习如何推广到未见任务,并与多任务提示密切相关。传统的多模态模型仅适用于前两种调优方法,缺乏零样本能力。因此,最近的研究致力于将指令调优扩展到多模态领域。
在扩展到多模态时,需要对数据和模型进行相应的调整:
- 数据方面,研究人员通常通过改编现有基准数据集或进行自我指导来获取适用于多模态指令调优的数据集。
- 模型方面,一种常见的方法是将外部模态信息注入到 LLM 中,并将其作为强大的推理器。相关工作可以直接对齐外部嵌入和 LLM,也可以借助专家模型将外部模态转化为 LLM 可接受的自然语言。这些工作将 LLM 转化为多模态聊天机器人和多模态通用任务求解器。
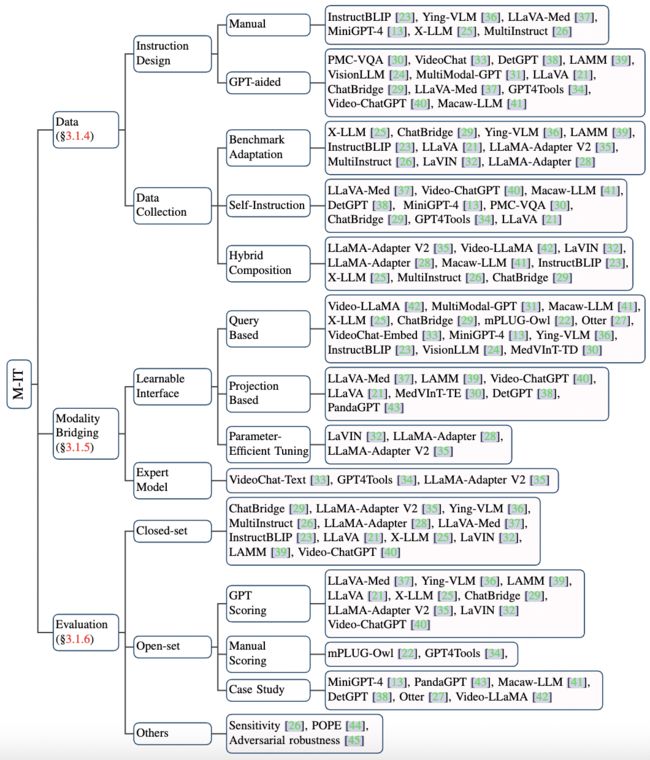

表 1 是一个简化的模板,用于组织多模态指令数据。其中,

表 2 是 VQA 数据集指令模板,其中
多模态上下文学习(Multimodal In-Context Learning)
ICL 是 LLM 的一项重要且新兴的能力。它具有两个显著优点:
- 与传统的监督学习范式通过大量数据学习隐含模式不同,ICL 的核心在于通过类比学习。在 ICL 的设置中,LLM 通过少量示例和可选指令进行学习,并能够在新问题上进行推广,以实现少样本学习并解决复杂且未见过的任务。
- ICL 通常以无需训练的方式实,因此可以灵活地集成到不同的框架中的推理阶段。与 ICL 密切相关的技术是指令调优,经过实证验证指令调优能够增强 ICL 的能力。
在 MLLM 的背景下,ICL 已经扩展到更多的模态,形成了多模态 ICL(M-ICL)。在推理阶段,M-ICL 可以通过在原始样本中添加一个演示集(即一组上下文样本)来实现。表 3 展示了这种扩展。
在多模态应用中,M-ICL 主要用于两种场景:
- 解决各种视觉推理任务,
- 教导LLM使用外部工具。
前一种情况通常涉及从少量特定任务的示例中学习,并推广到新的但类似的问题。通过指令和演示所提供的信息,LLM 可以理解任务的目标和输出模板,并生成预期的答案。而与之相反,关于工具使用的示例通常仅包含文本信息,并且更加精细。这些示例通常由一系列可以按顺序执行的步骤组成,以完成特定任务。因此,第二种情景与 CoT 密切相关。

表 3 是一个简化的模板示例,用于构建 M-ICL 查询。为了说明,本文列出了两个上下文示例和一个通过虚线分隔的查询。其中 {instruction} 和 {response} 是数据样本中的文本内容。
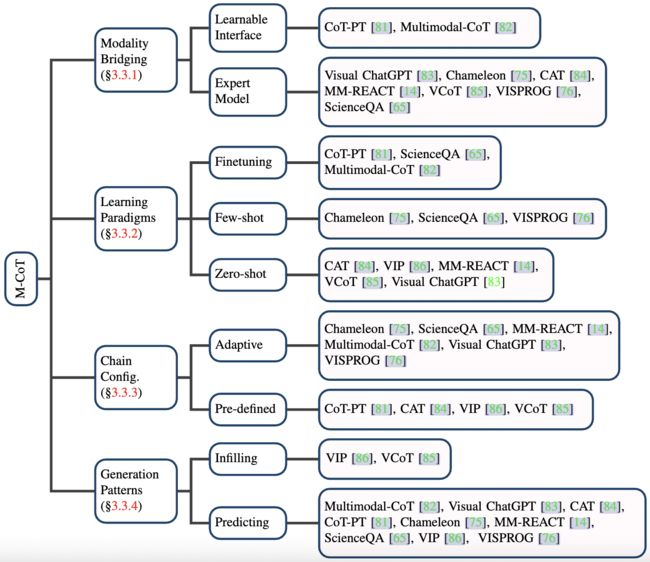
多模态思维链(Multimodal Chain of Thought)
正如先前工作所指出的那样,CoT 是“一系列中间推理步骤”,已被证明在复杂推理任务中非常有效。CoT 的主要思想是提示 LLM 不仅输出最终答案,还要输出导致答案的推理过程,类似于人类的认知过程。受到 NLP 领域的成功启发,已经提出了多个工作来将单模态的 CoT 扩展到多模态 CoT(M-CoT)。作者在图 3 中总结了这些工作,关键是需要填补模态差距。
LLM 辅助视觉推理(LLM-Aided Visual Reasoning)
受到工具增强的 LLM 成功的启发,一些研究探索了调用外部工具或视觉基础模型进行视觉推理任务的可能性。这些工作将 LLM 作为具有不同角色的辅助工具,构建了任务特定或通用的视觉推理系统。与传统的视觉推理模型相比,这些工作表现出几个优点:
- 强大的泛化能力。这些系统通过大规模预训练学习到丰富的开放世界知识,能够在零/小样本情况下轻松推广到未见过的对象或概念,具有显著的性能。
- 新兴的能力。在 LLM 的强大推理能力和丰富知识的辅助下,这些系统能够执行复杂的任务。例如,给定一张图片,MM-REACT 能够解释其中的意义,比如解释为什么一个梗很有趣。
- 更好的互动性和控制性。传统模型通常只允许有限的控制机制,并且通常需要昂贵的策划数据集。相比之下,基于 LLM 的系统具有在用户友好界面上进行精细控制的能力(例如点击和自然语言查询)。
而图 4 总结了相关文献。

小结
本文对现有的 MLLM 文献进行了调研,并对其主要方向提供了广泛的概述,包括三种常见技术(M-IT、M-ICL 和 MCoT)以及构建任务解决系统的通用框架(LAVR)。
挑战与未来方向
MLLM 的发展仍处于初级阶段,需要在以下方面进行改进:
-
提升感知能力:目前的 MLLM 在感知能力方面受限,可能导致获取的视觉信息不完整或错误。为了解决这个问题,可以考虑引入大型视觉基础模型如 SAM,以更高效地压缩视觉信息。
-
加强推理能力:MLLM 的推理链可能较为脆弱。在某些情况下,即使 MLLM 能够计算出正确的结果,但推理过程中仍可能出现错误。因此,有必要研究改进多模态推理的方法。
-
提升指令跟随能力:部分 MLLM 在明确的指令下仍无法生成预期的答案,这需要指令调优覆盖更多任务以提高泛化能力。
-
解决对象幻觉问题:对象幻觉普遍存在,影响了 MLLM 的可靠性。为了解决这个问题,可以进行更细粒度的视觉和文本模态对齐,关注图像的局部特征和相应的文本描述。
-
实现参数高效的训练:目前的两种模态桥接方式仍属初步探索,需要更高效的训练方法来发挥有限计算资源下 MLLM 的潜力。
总之,MLLM 领域正处于快速发展阶段,未来将充满机遇和挑战。我们期待着能够看到更多全面的研究工作,以推动 MLLM 技术的突破和应用的广泛普及~