Redis相关知识【缓存, 布隆过滤器, 一致性哈希, 底层数据结构...】(个人总结)
声明: 1. 本文为我的个人复习总结, 并非那种从零基础开始普及知识 内容详细全面, 言辞官方的文章
2. 由于是个人总结, 所以用最精简的话语来写文章
3. 若有错误不当之处, 请指出
Redis介绍:
Redis是一个基于key-value类型并有许多其他复杂高级类型的NoSQL数据库; key为String, value为RedisObject
应用场景:
- 短信验证码
- 旁路缓存
- 布隆过滤器
- UV统计
- 分布式Session
- 分布式锁
引入多线程:
Redis从4.x版本开始,逐渐引入多线程
引入多线程的原因:
单线程有时会造成不必要的阻塞,比如del 一个2G的key,删起来太慢了,阻碍了后续命令的执行
哪些地方用了多线程?
在核心的工作线程(如set key value)中, 依旧是单线程;
而 网络socket读写、请求协议解析、持久化、异步后台删除、集群数据同步等是由额外的多线程执行的
多线程机制默认是关闭的,需要改配置:
io-threads 6(最好略小于核数)
io-threads-do-reads no
异步后台删除的命令(大key时使用): unlink key
Redis快的原因:
基于内存+IO多路复用+核心处理机制采用单线程(省去了线程上下文切换带来的开销)
Redis的IO多路复用:
用epoll函数来实现IO多路复用, 将连接信息和事件放到队列中, 事件分派器将队列中的事件分发给事件处理器(这一步是单线程的, 所以Redis核心是单线程模型)
Redis基于Reactor模式开发了网络(文件)事件处理器:
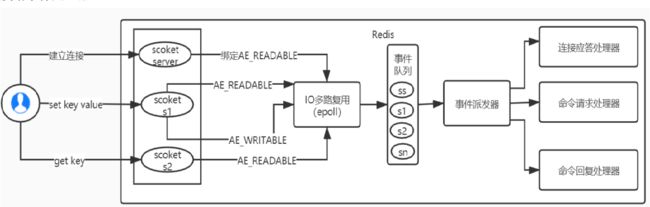
组成架构:
- 多个Socket套接字连接
- IO多路复用器(epoll)
- 事件分派器
- 事件处理器Handler
双写一致性:
双写指的就是 删缓存 & 更新数据库
几种策略:
先删缓存后更新数据库, 还没来得及更新数据库呢, B线程来了把数据库里的老数据放到缓存里, 导致缓存里放的是上一次老数据, 直到下一次删该缓存为止
解决策略: 延时双删缓存, 先删除缓存, 等数据库更新完毕后, sleep一小会后再次删除缓存
延时,是为了A线程删完缓存,还没来得及更新数据库。这时B线程读完数据库老数据后还没来得放缓存,你就执行了第二次删除,然后B线程再放缓存,缓存里又有了脏数据。
所以需要延时确保B线程已经把老数据放缓存了,这时双删可以挽救。延时期间就那么一会, 部分线程读到老数据也无伤大雅。所以 sleep时间>B线程读老数据+B线程把老数据放到缓存+网络传输
先更新数据库后删缓存, 还没来得及删缓存呢, B线程来了读到缓存老数据, 等待删除缓存执行完毕后, 问题即可解决; 导致短时间内 缓存里放的是上一次老数据, 这个短暂比上述要略长一些, 因为操作mysql数据库一般比操作redis慢
加 写锁, 锁住删缓存+更新数据库, 可保证缓存里一直放的都是最新数据, 但降低了并发性
重试机制可以考虑MQ, 重试次数超出上限再通知运维人员
两种不好的策略:
-
先更新数据库, 再更新缓存
缺点: 可能导致长时间数据不一致。当A线程把total改成了2, B线程又紧接着把total改成3; 然后B线程更新缓存为3, A线程再更新缓存为2, 老数据覆盖新数据, 导致缓存存放了老数据
-
先更新更新缓存, 再更新缓存数据库
不会导致一致性问题, 但浪费内存; 因为这样是只要数据发生更新, 就放到缓存了, 而更新的数据未必接下来会被查询, 浪费了一些Redis的内存
所以, 缓存要删不要更新; 删缓存会在数据下一次查询时重新放入缓存, 既保证数据是最新, 又保证了只存放被查寻的数据
EX, PX, NX, XX:
- EX: 多少秒后过期
- PX: 多少毫秒后过期
- NX: key不存在时才创建, key存在时啥也不干
- XX: key存在时才更新, key不存在时啥也不干
Set的应用场景:
SCARD 查看集合size
用作抽奖的场景:
SRANDOMEMBER key [参数数字, 默认1] 从集合随机查看一个元素,不删除
SPOP key [参数数字, 默认1] 从集合随机弹出一个元素, 删除
集合运算:
差集: SDIFF set1 set2
交集: SINTER set1 set2
并集: SUNION set1 set2
最大占用内存配置:
maxmemory 1024000 #单位是字节, 默认情况下64位操作系统 该值为0代表不限制内存
#如果一个服务器只放redis, 就没必要限制内存, 超出内存会OOM
Redis过期key的三大删除策略:
-
定时立刻删除
好处: 对内存友好, 及时释放内存
坏处: 对CPU不友好, 得时刻检查key是否过期
-
惰性删除
先不着急删除,等下次访问时再进行删除
对内存不友好, 对CPU友好
-
定期删除
折中一下, 每隔一段时间进行随机抽查key是否过期, 依然会有部分垃圾未被回收, 但依然不是那么完美
虽然不及时删除但不影响业务, 因为下次访问时是要检查是否过期的
三大删除策略都不是那么完美, 所以引入了缓存淘汰策略
LRU & LFU
LRU是最近最少使用原则, 看的是上一次使用时间距离现在是否遥远
LFU是最不经常使用原则, 看的是最近一段时间内, 使用的频率高低
缓存淘汰策略:
两个维度: 设置过期时间的key中筛选, 所有key中筛选
四个方面: LRU, LFU, random, ttl
maxmemory-policy allkeys-lru
- 对 设置过期时间的key
- valatile-lru
- volatile-lfu
- valatile-ttl 删除马上要过期的key
- volatile-random 随机删除
- 对 所有的key
- allkeys-lru 最好设置成这个
- allkeys-lfu
- noeviction 不会驱逐任何key(内存不足直接OOM), 是默认策略,很坑
- allkeys-random 随机删除
三大缓存问题:
-
缓存穿透: 频繁访问一个不存在的key, 比如用一个不存在的userId去查用户信息, 此key在缓存里找不到便频繁打在了MySQL上, 穿透了缓存
解决方案:
- 对这个不存在的key进行缓存,并设置几分钟的过期时间, value设为空值
- 查key前, 先使用布隆过滤器判断这个key是否存在, 若不存在(一定是准的), 则直接返回不存在, 避免了查询MySQL
- 使用布隆过滤器或者BitMap数据结构, 设置黑名单, 把可疑ip加入黑名单一段时间, 不在黑名单里才能去正常访问Redis服务器; 布隆过滤器说这个元素(即ip)不存在,那一定不存在, 就可以进行访问了
-
缓存击穿: 热点key突然失效, 此key在缓存里找不到便频繁打在了MySQL上
解决方案:
-
加长这些热点key的过期时长
-
实时调整, 现场监控哪些数据热门并进行实时调整
-
使用锁, 双重检查
// 加读锁, 防止其它线程对缓存更改 lock.readLock( ).lock( ); try { T value = map.get(key); if (value != null) { return value; } } finally { lock.readLock( ).unlock( ); } // 缓存里没数据, 开始准备查询MySQL // 可能多个线程发现缓存没数据, 就都来到了此位置 // 加写锁, 防止其它线程对缓存读取和更改 lock.writeLock( ).lock( ); // 多个线程排队进入 try { // 双重检验, 第一次查MySQL的那个线程已经把数据放入缓存了, 后续线程不应该再重复查询MySQL T value = map.get(key); if (value == null) { // 如果没有, 就再查询MySQL value = xxxMapper.queryOne(sql, params); // 把从MySQL查到的数据放入缓存 map.put(key, value); } return value; } finally { lock.writeLock( ).unlock( ); } }
-
-
缓存雪崩: 大量的key在同一时间失效, 缓存里没数据了查询便频繁打在了MySQL上
解决方案: 将缓存失效时间分散开, 过期时间给个某范围内的随机值, 比如1-5分钟随机值
事务:
Redis事务的主要作用就是串联多个命令防止别的命令插队(像是原语)
这里的原子性,更像原语, 命令中途不可被打断; 而MySQL的原子性指的是同生共死,要么都成功要么都失败
组队时支持事务, 命令出错后立即放弃组队;
组队完成后不支持事务, 前面出错也不影响后面的命令执行
Multi、Exec、Discard
Redis是单线程, 由于多路复用产生了并发问题; 因为是单线程, 所以不能用悲观锁, 只能用CAS乐观锁(watch)比较版本号
秒杀案例:
出现的问题:
-
超卖: 用乐观锁可以解决
-
库存遗留: 总共1000库存, 1000个请求来了,并不能抢购完
问题分析:
-
乐观锁不是锁, 乐观锁比较版本号失败后,这个商品就卖不出去了
-
get判断操作和set操作形成大的事务队列原子, 但中间混有其他操作(判断该用户是否重复秒杀,不是Redis队列任务)无法组成完整队列
解决方案: 加悲观锁 或者 用Lua脚本
-
持久化:
子进程是对父进程的拷贝
fork一个子进程进行备份实际数据到临时文件, 等备份完了再用临时文件替换上次持久化的文件
主进程正常工作, 子进程进行备份数据, 用到了写诗复制技术, 提供了读写分离, 读写同时进行的现象
-
RDB
是定时备份
优点: 1. 更节省磁盘 实际数据相比于操作日志, 数据量少,
2. 恢复速度快 恢复数据时, 直接读取数据即可, 不用计算
缺点: 因为是定时备份, 所以时间粒度不够细, 机器宕机后会丢失这个定时时间间隔内的数据
-
AOF
记录追加操作日志, 顺序写磁盘
3种方式:
-
appendfsync always Redis每有数据变更, 便会立刻记录日志
-
appendfsync everysec 每秒记入日志一次
-
appendfsync no Redis不主动同步, 把同步时机交给操作系统
AOF文件大小 超过rewrite策略 或 手动执行bgrewriteaof命令时, 会对AOF文件rewrite重写来压缩文件
优点: 1. 备份时间粒度更细, 丢失数据概率更低
2. 日志文件人可以看懂, 可以处理误操作
缺点: 1. 更占用磁盘
2. 恢复速度慢 恢复数据时需要执行操作日志 重新计算, 占用时间
3. 存在个别Bug, 无法正常恢复
-
官方建议: 两种持久化方式都开启, 恢复数据时Redis优先使用数据更全的AOF来恢复, 如果AOF不能正常恢复, 再采用备用的RDB
布隆过滤器:
介绍:
布隆过滤器用来判断某个数据是否存在于某个集合中
不关心数据叫啥名, 只关心数据存在与否, 所以一个数据只占用一个1bit, 省内存
性质:
-
说这个数据不存在, 那就一定不存在
-
说这个数据存在, 那么它时可能存在的, 即小概率误判
这是因为 极少数不同元素经过hash散列后具备了相同的散列值; 比如"你好"和"hello"散列值相同, 都到了桶下标为2的位置, 那么查询下标2位置时发现二进制数组值为1, 没法区分这是"你好"造成的, 还是"hello"造成的
不要进行删除:
布隆过滤器不要去删除元素, 因为假设添加两个数据"你好"和"hello"都落在了桶下标为2的位置, 如果想删除"你好" 而将此位置置为0, 那么"hello"就被误删了
减少误判:
为了减少误判, 可以设置多个hash函数
多个hash散列值, 都存在二进制数组里; 查询时 多个hash都说它在, 才认为它在, 减少了误判率
注意: 至于不同的hash规则, hash1(hello)可能与hash2(world)相同了, 但还有别的hash函数呢, 我们的目的是减小误判, 并不是避免误判;
既然多个(k个)hash函数, 那么计算的哈希值就会增多(但并不是k倍的增加, 因为 hash1(hello)可能与hash2(world)相同了), 就会更占内存
优点:
- 省内存, 二进制数数组, 一个元素只占用一个bit
- 查询 & 增加 元素速度快, 通过哈希计算, 直接计算出桶下标, 二进制数组按下标去查找数据是很快的, 时间复杂度为O(k), k为hash函数的个数
- 更安全, 因为二进制数组里并没有存实际数据, 只是一堆比特1和0, 即使数据泄露了别人也看不懂
不适用场景:
少量的数据不适合用布隆过滤器, 因为那样大部分数据都是bit0,也占用不少内存
实际应用场景:
- 黑名单
- 反垃圾邮件, 一些邮箱被拉近了黑名单
- 浏览器识别恶意URL, 一些URL被拉近了黑名单
- 不重复推荐用户已经读过的文章
- 缓存穿透, 避免对不存在的数据进行没必要的查找
- HBase, 避免对不存在的数据进行没必要的查找
一致性哈希算法:
是一种在存储方面的 负载均衡算法
目的: 解决分布式缓存问题, 减少因Redis集群服务器数量变更 带来的数据查不到问题, 即缓存命中率大大降低的问题
不好的做法:
存数据时使用
hash(a.jpg)%集群数量来决定a.jpg存储在哪台Server上, 查看a.jpg时再通过hash(数据)%集群数量求得它在哪台Server, 再去这个Server上取数据;在集群数量不变时, 这样不会产生问题。担当集群数量变化时, 那么存数据和读数据 时用的公式里的被除数不一样的, 就很可能导致在此Server上找不到a.jpg, 那么当大量数据都查不到时, 便都会打在数据库上 造成缓存雪崩
解决方案:
假想出一个哈希环,
hash(每个Server ip)%2^32来确定Server落在环上的哪个位置; 然后存数据时使用hash(a.jpg)%2^32计算的值 即对应在哈希环上的位置, 然后沿着环顺时针移动, 遇到的第一个Server来存储它。这样的话集群数量变更, 对公式造成的影响较小, 只有少部分数据查询不到, 不会造成缓存雪崩。哈希环偏斜问题:Server1, Server2, Server3在哈希环上分布的越均匀越好, 那样查找不到数据的情况会较少; 反之, 则查找不到数据的情况会相对较多些
优化:使用虚拟节点映射, Server1虚拟出Server1-1, Server1-2, Server2虚拟出Server2-1, Server2-2, 这样节点数量变多了, 就在哈希环上分布越均匀;
读写数据时, 可以先根据数据计算出它应该落在哪个虚拟Server上, 再由虚拟Server映射到真实的Server
分布式锁(RedLock):
锁的本质是对同一资源的互斥, 普通的锁只能锁住当前JVM进程, 而分布式锁是锁住多个JVM进程
三种实现方式:
- Redis
- Redisson
- ZooKeeper
Redis 对比 ZooKeeper 分布式锁
-
Redis分布式锁, 需要自己不断去尝试获取锁, 比较消耗性能;
ZooKeeper分布式锁, 注册个监听器即可, 不需要不断主动尝试获取锁, 开销小从而性能较高
-
Redis获取锁的那个客户端挂掉了, 那么只能等待超时后才能释放锁;
而ZooKeeper, 因为创建的是临时节点, 只要客户端挂了节点就没了, 此时就自动释放了锁
所以ZooKeeper分布式锁实现起来更简单些
Redis分布式锁:
这个结点数据存在, 就代表锁住了; 解锁就是删除该结点数据
问题:
- 如果一个业务上了锁后宕机了, 那么这个锁就永远得不到释放
- 如果一个业务上了锁后卡住了, 那么这个锁就长时间得不到释放
- 判断锁是否被占用 & 进行加锁 不具有原子性
- 判断锁是否是自己的(UUID) & 进行删除锁 不具有原子性
解决: 1. 给锁设置过期时间
引发新的问题: 即问题2中这个业务姗姗来迟后准备解锁, 把别的业务的锁给删了
问题解决: 锁中存放UUID, 删除锁前看一下UUID是否匹配, 不匹配则说明不是自己上的锁, 不能删除
2. 使用lua脚本, 使 判断&加锁 和 判断&解锁 具备原子性
集群:
Redis3.0开始使用无中心化集群配置, 能直接进行访问任何一个Server, 然后这个Server帮你转交给masterServer, 任何一个Server都可以看作是代理, 是一个分区
集群模式:
-
一主二仆: 一个Master, 两个Slave
-
薪火相传: 上一个Slave可以是下一个Slave的Master, 可以有效减轻master的写压力
-
反客为主: 当一个master宕机后,手动输入slaveof no one命令将从机变为主机
-
哨兵: 反客为主的自动版,能够后台监控master是否故障,如果故障了选举新的master; 原先master重启后变成slave
选举规则: 先看规则1, 再看2, 再看3
-
优先级靠前的: 优先级在redis.conf中默认为: slave-priority 100,值越小优先级越高
-
选择偏移量最大的: 偏移量大的 获得原主机数据最全
-
选择uuid最小的: 每个redis实例启动后都会随机生成一个40位的runid
-
集群的缺点:
- 多键的Redis事务是不被支持的
- lua脚本不被支持
新型数据结构:
-
Bitmaps: 相当于布隆过滤器, 一堆bit0和bit1
偏移量从0开始算
命令:
把zhangsan加进blacklist: setbit blacklist zhangsan 1
把zhangsan移出blacklist: setbit blacklist zhangsan 0
查看zhangsan是否在blacklist里: getbit blacklist zhangsan
查看blacklist偏移量[1*8, 3*8]范围内 1的个数: bitcount blacklist 1 3
查看blacklist偏移量[1*8, 倒数第3*8]范围内 1的个数: bitcount blacklist 1 -3
bittop集合操作:
bitop and/or/not/xor result blacklist1 blacklis2 blacklist3
-
HyperLogLog: 基数统计, 如UV统计, 多次重复出现的uid只记作出现一次
命令:
添加数据: pfadd uv_2021-06-14 zhangsan
查看某一个key的基数: pfcount uv_2021-06-14
查看多个key的基数(多个key当作一个key): pfcount uv_2021-06-14 uv_2021-06-15
合并key(可多个)的数据到别的key: pfmerge uvAll uv_2021-06-14 uv_2021-06-15
-
Geospatial: 地理位置, 手动输入经纬度, 然后帮你判断周围有啥城市
命令:
添加地理位置(经度, 纬度, 名称): geoadd china:city 121.47 31.23 shanghai
获得指定地区的经纬度: geopos china:city shanghai
获取两个位置之间的直线距离: geopos china:city shanghai beijing km
m 表示单位为米(默认值)
km 表示单位为千米
mi 表示单位为英里
ft 表示单位为英尺
以给定的经纬度为中心, 找出某一半径内的元素: georadius china:city 121.47 31.23 1000km
底层数据结构:
数据结构:
-
sds:
Redis没有直接使用C语言的 char* 字符数组来表示字符串, 而是封装了一个叫SDS(动态字符串)数据结构来表示字符串
数据结构组成:
-
len 记录字符串长度, 因此不需要以’\0’作为字符串结尾标志
好处: 这样获取字符串长度时, 时间复杂度为 O(1)
-
alloc 分配给字符数组的空间长度
好处: 这样在修改字符串时, 可以通过
alloc - len计算出剩余的空间大小用来判断空间是否足够,如果不满足的话, 就会自 动扩容, 所以不会出现缓冲区溢出的问题 -
flags 用来表示不同类型的SDS (sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64)
sdshdr16类型的 len和 alloc 的数据类型都是uint16_t, 表示字符数组长度 和 分配空间大小 不能超过 2^16
-
buf[] 用来存储实际数据
-
-
ziplist(压缩列表):
当k-v对比较少, 且每个k-v的长度都比较短 时使用压缩列表更好(本质是链表)
原因: k-v的长度都比较短时, pre指针和next指针本身的长度 就大于了k-v实际数据的长度了, 显得太浪费了
但当k-v对比较多时, 就不合适了:
原因: 遍历时是按加减len长度来寻找相邻节点, 没有pre指针和next指针快; 累积下来占用了过长的时间
组成: zlbytes+zltail+zllen+entryX+zlend
- zlbytes 4字节, 记录整个ziplist的占用内存字节数
- zltail 4字节, 记录尾节点距离ziplist起始位置有多少字节
- zllen 2字节, 记录节点数量
- entryX 一个个节点, 节点里存放着自己的长度 和 上一个节点的长度
- zlend 1字节, 标记ziplist的末尾
-
quicklist:
是linkedlist, 不过每个节点都是ziplist
-
skiplist(跳表):
每下一级索引就个数减半, 空间复杂度O(n), 时间复杂度O(logN)
相当于多级稀疏索引
Redis数据结构:
-
String
底层使用sds结构
-
List
底层是quicklist结构
-
Set
底层是int[] / 哈希表 结构
-
如果是整数类型, 且数字位数不超过 set-max-intset-entries的值, 那就是用int[] intset存储
-
否则, 就用哈希表存储
-
-
Hash
底层是 ziplist / 哈希表 结构
-
初始时用的是ziplist
-
当k-v对数量超过hash-max-ziplist-entries的值 或 有元素的长度大于hash-max-ziplist-value的值时, 就变为哈希表
-
-
ZSet
底层是ziplist / skiplist 结构
-
初始时用的是ziplist
-
当元素数量超过server.zset_max_ziplist_entries的值 或 有元素的长度大于server.zset_max_ziplist_value的值时, 就变为skiplist
-