2023scrapy教程,超详细(附案例)
Scrapy教程
文章目录
- Scrapy教程
-
- 1. 基础
- 2. 安装
-
- Windows 安装方式
- 3. 创建项目
- 4. 各个文件的作用
-
- 1. Spiders
- 详细使用:
- 2. items.py
- 3. middlewares.py
- 4. pipelines.py
- 5. settings.py
- 6. scrapy.cfg
- 5. 项目实现(爬取4399网页的游戏信息)
1. 基础
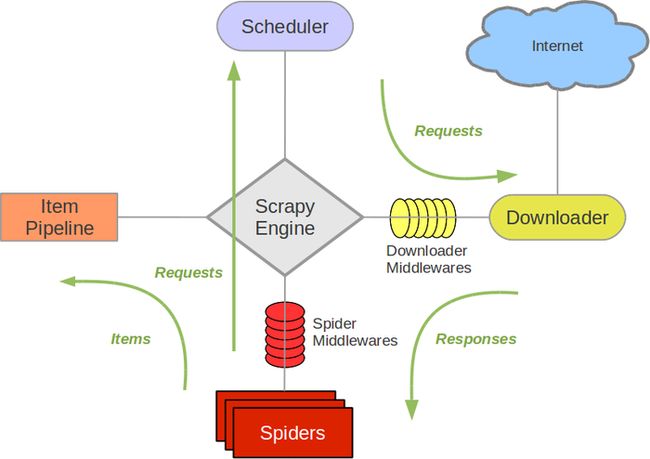
- Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
- Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
- Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
- Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器).
- Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
- Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
- Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
2. 安装
Windows 安装方式
升级 pip 版本:
pip install --upgrade pip
通过 pip 安装 Scrapy 框架:
pip install Scrapy
3. 创建项目
在开始爬取之前,必须创建一个新的Scrapy项目。进入自定义的项目目录中,运行下列命令:
scrapy startproject mySpider
其中, mySpider 为项目名称,可以看到将会创建一个 mySpider 文件夹,目录结构大致如下:
下面来简单介绍一下各个主要文件的作用:
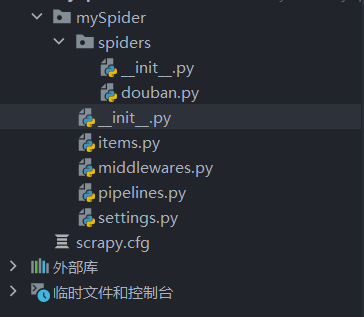
这些文件分别是:
- scrapy.cfg: 项目的配置文件。
- mySpider/: 项目的Python模块,将会从这里引用代码。
- mySpider/items.py: 项目的目标文件。
- mySpider/pipelines.py: 项目的管道文件。
- mySpider/settings.py: 项目的设置文件。
- mySpider/spiders/: 存储爬虫代码目录。
4. 各个文件的作用
1. Spiders
Scrapy的Spider文件是爬虫程序的核心部分,它定义了如何从网站中提取数据。Spider文件通常是一个Python类,通过继承Scrapy的Spider类来定义。下面我们将详细讲解Scrapy的Spider文件。
- Spider文件的基本结构 一个基本的Scrapy Spider文件包含以下几个部分:
import scrapy
class MySpider(scrapy.Spider):
name = "myspider"
allowed_domains = ["example.com"]
start_urls = ["http://www.example.com"]
def parse(self, response):
pass
在这个示例中,我们首先导入了Scrapy库。然后,定义了一个名为MySpider的Spider类,继承自Scrapy的Spider类。 接着,设置了Spider类的一些属性,包括name(爬虫程序的名称)、allowed_domains(指定爬虫程序所能访问的域名)、start_urls(指定爬虫程序的起始URL)。这些属性都是可选的,可以根据需要设置或省略。 最后,定义了一个名为parse()的方法,这是Spider程序中用于处理响应数据的核心方法。
- Spider文件的属性 在Spider类中,可以定义许多属性来控制爬虫程序的行为。下面我们将介绍一些常用的属性。
- name:爬虫程序的唯一名称,用于识别Spider类。如果未指定名称,则Scrapy将使用类名的小写形式作为默认名称。
- allowed_domains:一个Python列表,指定Spider类所能访问的域名。在爬取数据时,Spider程序只会访问这些域名下的页面。如果未指定allowed_domains属性,则Spider程序可以访问任何域名下的页面。
- start_urls:一个Python列表,指定Spider程序的起始URL。Spider程序会按照列表顺序依次访问这些URL,并将响应传递给parse()方法进行处理。
- custom_settings:一个Python字典,指定Spider程序的自定义设置。可以在这个字典中设置诸如下载延迟、User-Agent等属性,以及自定义的中间件和管道(Pipeline)等配置。
- download_delay:爬虫程序在访问每一个页面之间的下载延迟(单位为秒)。可以用来控制爬虫程序的速度,避免对目标网站造成过大的负载。
- start_requests():一个Python方法,用于生成初始请求。如果未定义这个方法,则Scrapy会默认使用start_urls属性生成初始请求。
- Spider文件的方法 在Spider类中可以定义多个方法来实现不同的功能,例如提取页面内容、跟踪链接、保存数据到数据库等。下面我们将介绍一些常用的方法。 - parse():这是Spider程序中最重要的方法,用于处理响应数据。在parse()方法中,可以使用各种选择器(如CSS选择器、XPath选择器)来提取页面中的内容,并将提取的数据存储到数据项(Item)中。 - parse_start_url():这是与parse()方法类似的方法,在爬虫程序开始访问每个起始URL时被调用。可以用来处理起始页面的信息,并将提取的数据存储到数据项中。 - parse_item():这是一个可选的方法,在从页面中提取数据后对数据进行处理的方法。通常用于对提取出的数据进行清洗、格式化或去重等操作。 - closed():当Spider程序结束运行时,这个方法将被调用。通常用于进行一些清理工作,例如关闭数据库连接或保存爬取状态等。
- Spider文件的使用 在定义好Spider类之后,可以使用Scrapy的命令行工具来启动Spider程序。打开命令行终端,进入项目的根目录,执行以下命令:
scrapy crawl <spider_name>
其中,
创建爬虫代码的实现
在当前目录下输入命令,将在mySpider/spider目录下创建一个名为itcast的爬虫,并指定爬取域的范围:
scrapy genspider 爬虫名 "爬取域的范围,例:4399.com"
scrapy genspider game "4399.com"
详细使用:
-
定义Spider类
在Scrapy中,每个爬虫都必须是一个Spider类的实例。在Spider类中,可以定义一些属性和方法,包括爬虫名称、起始URL、回调函数等。
-
定义start_requests()方法
start_requests()方法用于生成初始请求,通常用于指定要爬取的起始URL和请求头部信息。如果未定义start_requests()方法,则Scrapy会默认使用默认的start_urls属性作为起始URL列表。 下面是一个start_requests()方法的示例代码:
def start_requests(self): urls = [ 'http://www.example.com/page1.html', 'http://www.example.com/page2.html', 'http://www.example.com/page3.html', ] headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3' } for url in urls: yield scrapy.Request(url=url, headers=headers, callback=self.parse) -
定义parse()方法
parse()方法是Scrapy爬虫中最重要的方法之一。它会接收response对象作为参数,并对获取到的HTML文档进行解析和处理。在这个方法中,可以使用XPath或CSS选择器等工具对文档进行解析,并提取出需要的数据。
XPath选择器 XPath是一种基于XML的查询语言,也可以用于HTML文档的查询。XPath选择器使用XPath表达式来查询匹配的节点,每个节点有多个属性,例如标签名、属性名和文本内容等。 XPath表达式的示例: - 选择节点:
//div # 选择所有div标签节点- 选择属性:
//div[@class="example"] # 选择class属性值为example的div标签节点- 选择文本:
//div/text() # 选择div标签节点的文本内容XPath选择器的常见方法: - xpath(expression) 该方法从当前响应的HTML文档中,选取与XPath表达式相匹配的所有节点。
response.xpath('//title/text()').get()- extract() 该方法将匹配的节点的文本内容返回为一个字符串。
response.xpath('//title/text()').extract()css选择器
- 类选择器 使用类选择器可以选取所有具有指定类名的元素。 例如,选取所有class属性为example的div标签:
response.css('div.example')- ID选择器 ID选择器可以选取具有指定id属性值的元素。 例如,选取id属性为main的div标签:
response.css('div#main')- 子元素选择器 子元素选择器可以选取指定元素的直接子元素。 例如,选取body标签下的所有div标签:
response.css('body > div')- 后代元素选择器 后代元素选择器可以选取指定元素下的所有后代元素。 例如,选取body标签下的所有div标签:
response.css('body div')- 相邻兄弟选择器 相邻兄弟选择器可以选取指定元素后面的紧邻着的兄弟元素。 例如,选取class属性为example的div标签后面的一个p标签:
response.css('div.example + p')- 通用兄弟选择器 通用兄弟选择器可以选取指定元素后面的所有兄弟元素。 例如,选取class属性为example的div标签后面的所有p标签:
response.css('div.example ~ p')- 伪类选择器 伪类选择器可以选取元素的特定状态。 例如,选取所有第一行的表格单元格:
response.css('td:first-child')以上是Scrapy CSS选择器的一些基本示例,可以根据需要进一步结合不同类型的选择器和属性来进行更具体的元素选取。
注意:
-
Scrapy框架提供了一个Response对象,其中包含请求URL的HTML响应。Response对象提供了直接选择和提取HTML元素的方法,即response.css()和response.xpath(),因此不需要显式地创建一个Selector对象。这样可以使代码更加简洁和易于阅读。同时,使用response.css()和response.xpath()方法可以直接使用Scrapy的内置选择器,而无需导入Selector对象。因此,直接使用response.css()和response.xpath()方法是更好的做法。
-
使用
getall()方法获得元素的文本是Scrapy中推荐的做法。它返回一个包含所有匹配到元素的文本的列表,而不仅仅是第一个匹配到的元素的文本。相比之下,extract()方法只返回第一个匹配到的元素的文本。使用getall()方法可以更轻松地处理多个匹配,而无需使用循环或列表解析。此外,从性能角度来看,使用getall()方法可以更快地提取多个元素的文本,因为它只需要执行一次搜索操作,而不是多次搜索。因此,使用getall()方法获得元素的文本是更好的做法。
-
定义其他辅助方法
除了start_requests()和parse()方法之外,还可以在Spider文件中定义其他辅助方法。这些方法可以用于将提取出的数据存储到数据库或文件中,或者实现其他一些爬虫功能。
-
定义Spider的一些属性
在Scrapy的Spider文件中,还可以定义一些属性,比如name、allowed_domains、start_urls等。这些属性可以用于控制爬虫的行为,比如限制爬取的域名范围、设置起始URL等。
2. items.py
Scrapy的items.py文件定义了在Spider中要提取的数据类型和字段。当Spider解析网页时,它会从中提取数据并将其存储到Item实例中。在items.py文件中,可以定义一个或多个类来表示不同类型的数据,如电影、书籍或新闻。这些类通常是基于Python字典构建的,其中键代表数据字段,值代表字段的值。 Scrapy中的Item类是Python字典的子类,它可以处理不同类型的数据。通过定义一个类来表示一个Item,可以为数据指定字段名称和数据类型,并定义一个默认值。
例如,以下是一个简单的Item类定义:
import scrapy
class MyItem(scrapy.Item):
name = scrapy.Field()
age = scrapy.Field(serializer=int)
address = scrapy.Field()
这个类有三个字段:name、age和address。name和address是由默认值None创建的字符串字段,而age是一个整数字段(由serializer=int参数指定)。在Spider中,可以创建一个MyItem类的实例,并将提取的数据存储在字段中,然后将此实例传回给Scrapy引擎进行处理。例如:
import scrapy
from myproject.items import MyItem
class MySpider(scrapy.Spider):
name = "myspider"
# ...
def parse(self, response):
item = MyItem()
item["name"] = "John Smith"
item["age"] = "30"
item["address"] = "123 Main St."
return item
在此示例中,MySpider类中的parse()方法使用MyItem类的实例来存储提取的数据。通过将字段名称和字段值赋给item字典,可以将数据添加到Item实例中。 总之,items.py文件是将提取的数据保存到Item实例中的地方。定义Item类可以指定数据类型和字段名称,并将其传递给Spider以存储提取的数据。
注意:提取到item的数据可以在管道(Pipeline)将提取的数据进行处理。管道是一组Python类,它们分别处理从Spider中提取的Item实例。在管道中,可以执行各种操作,例如数据清理、验证、转换和持久化。每个管道类都定义一个process_item()方法,该方法接收Item实例并返回Item实例或Raise DropItem异常。
3. middlewares.py
Scrapy中的middlewares.py是用来处理请求和响应的过程的模块,它可以在不同的阶段对请求和响应进行处理和修改,方便开发者进行定制化的处理流程。
Scrapy中的middlewares可以分为下载中间件和爬虫中间件:
-
下载中间件:主要用于处理请求和响应,如设置代理、处理cookie和设置请求头等操作。
- UserAgentMiddleware:随机设置User-Agent,模拟不同的浏览器和设备访问网站。
- ProxyMiddleware:设置代理IP,用于避免IP被封禁的情况。
- RetryMiddleware:在请求失败时自动重试请求。
- HttpErrorMiddleware:用于处理请求出现HTTP错误的情况,可以设置处理不同类型的HTTP错误的方式。
- CookiesMiddleware:用于自动管理cookies,在爬取需要登录的网站时特别有用。
-
爬虫中间件:主要用于处理爬虫逻辑,对爬取的数据进行处理和过滤,如数据清洗和去重等操作。
- UserAgentMiddleware:随机设置User-Agent,模拟不同的浏览器和设备访问网站。
- ProxyMiddleware:设置代理IP,用于避免IP被封禁的情况。
- RetryMiddleware:在请求失败时自动重试请求。
- HttpErrorMiddleware:用于处理请求出现HTTP错误的情况,可以设置处理不同类型的HTTP错误的方式。
- CookiesMiddleware:用于自动管理cookies,在爬取需要登录的网站时特别有用。
具体来说,middlewares.py中定义了一些中间件类,每个类都包含了一些方法用于对请求和响应进行处理和修改。其中一些常用的方法包括:
- process_request(request, spider):处理请求,可以修改请求的URL、请求头、代理、Cookie等。
- process_response(request, response, spider):处理响应,可以修改响应的内容、状态码等。
- process_exception(request, exception, spider):处理异常,可以对请求发生异常时进行处理,如重新发送请求或记录日志等。
- spider_opened(spider):爬虫打开时的处理,可以在爬虫启动时进行初始化操作。
- spider_closed(spider):爬虫关闭时的处理,可以在爬虫结束时进行清理操作。
通过在middlewares.py中定义自己的中间件类,并在settings.py中进行配置,可以方便地在Scrapy中添加自定义的请求处理流程。
设置User-agent
class RandomUserAgentMiddleWare:
def __init__(self):
self.user_agent_list = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.50"]
def process_request(self, request, spider):
request.headers['User-Agent'] = random.choice(self.user_agent_list)
设置代理
class ProxyMiddleWare:
def __init__(self):
self.proxies = {
"http": "http://127.0.0.1:1080",
"https": "https://58.240.110.171:8888"
}
def process_request(self, request, spider):
request.meta['proxy'] = random.choice(list(self.proxies.keys()))
4. pipelines.py
Scrapy的pipelines.py是用于数据处理和数据存储的模块,被用于对爬虫爬取到的数据进行处理和存储。
在Scrapy中,爬虫爬取到的数据是通过Item对象传递到pipelines中进行处理和存储的。pipelines中可以定义多个管道,每个管道对传入的Item对象进行处理,处理完后再传递给下一个管道进行下一步处理。
Scrapy中常用的pipelines包括:
- 数据清洗pipeline:用于对数据进行清洗和去重,如去除HTML代码、去除重复的数据等。
- 数据存储pipeline:用于将爬虫获取到的数据存储到数据库中或写入文件中,支持多种存储方式,如MySQL、MongoDB等。
- 数据转换pipeline:用于将数据进行转换,如将Item对象转换为json格式,或将数据进行格式化等。
使用Scrapy的pipelines,可以将数据处理和存储分离开来,方便进行代码解耦和灵活性的提升。同时,可以通过设置管道的优先级来决定各个管道的执行顺序,从而实现更加灵活的数据处理和存储需求。
在pipelines.py文件中,可以通过定义一些处理函数来实现数据的处理和存储,同时也可以在setting.py文件中进行管道的设置和优先级的调整。
以下是一个使用管道处理从Spider中提取的MyItem实例的示例:
from myproject.items import MyItem
class MyPipeline:
def process_item(self, item, spider):
# 对item进行处理
item['age'] = int(item['age'])
item['address'] = item['address'].strip()
# 存储item到数据库或文件中
# 这里省略具体实现
return item
在此示例中,MyPipeline类是一个简单的管道类,它将MyItem实例中的数据处理后存储到数据库或文件中。process_item()方法接收item和spider作为参数。在该方法中,可以按照需要对item进行处理,例如将age字段转换为整数并删除address字段的空格。最后,将处理后的item返回,以便它可以传递给下一个管道或Spider的回调函数。 要使用管道,请在配置文件中启用它们。管道的启用顺序也很重要,因为它们按顺序处理Item实例。可以在配置文件中通过ITEM_PIPELINES设置来指定管道及其顺序。例如:
ITEM_PIPELINES = {
'myproject.pipelines.MyPipeline': 300,
# 其他管道类及其顺序
}
在此示例中,MyPipeline类被指定为第一个处理管道,并使用300作为其顺序。顺序从低到高,数字越小的管道首先被处理。配置文件中的其他管道类可以根据需要添加。
5. settings.py
Scrapy的setting.py文件包含了许多参数设置,以下是所有参数的详细说明:
- ROBOTSTXT_OBEY (bool): 是否遵循网站的robots.txt文件中的规则,如果为True,则遵循;如果为False,则不遵循。
- LOG_LEVEL (str): 日志等级,设置输出的日志等级,可以设置为DEBUG, INFO, WARNING, ERROR, CRITICAL。
- DOWNLOAD_DELAY (float): 爬取延迟时间,设置下载延迟的时间,以秒为单位。
- USER_AGENT (str): 用户代理,用于模拟网页访问时的浏览器类型。
- DEFAULT_REQUEST_HEADERS (dict): 默认请求头,设置默认的请求头,可以设置一些常用的请求头信息。
- COOKIES_ENABLED (bool): 是否启用Cookies,如果为True,则携带Cookies进行访问;如果为False,则不携带Cookies进行访问。
- ITEM_PIPELINES (dict): Item管道,设置Item的处理管道,可以设置多个管道进行处理。
- CONCURRENT_REQUESTS (int): 并发请求数,设置同时发起的请求的数量,建议设置在16-32之间。
- CONCURRENT_REQUESTS_PER_DOMAIN (int): 每个域名的并发请求数,设置每个域名同时发起的请求的数量,建议设置在8-16之间。
- CONCURRENT_REQUESTS_PER_IP (int): 每个IP地址的并发请求数,设置每个IP地址同时发起的请求的数量,建议设置在0(不限制)-8之间。
- DOWNLOAD_TIMEOUT (int): 下载超时时间,设置下载超时的时间,以秒为单位。
- RETRY_TIMES (int): 重试次数,设置请求失败时的重试次数。
- RETRY_HTTP_CODES (list): 重试的HTTP状态码,设置请求失败时需要重试的HTTP状态码。
- HTTP_PROXY (str): HTTP代理,设置HTTP代理服务器的地址。
- EDIRECT_ENABLED (bool): 是否启用重定向,如果为True,则允许请求发生重定向。
- REDIRECT_MAX_TIMES (int): 最大重定向次数,设置请求最大的重定向次数。
- DNSCACHE_ENABLED (bool): 是否启用DNS缓存,如果为True,则启用DNS缓存。
- DNSCACHE_SIZE (int): DNS缓存大小,设置DNS缓存的最大数量。
- DNSCACHE_EXPIRATION (int): DNS缓存过期时间,设置DNS缓存的过期时间,以秒为单位。
- COOKIES_DEBUG (bool): 是否启用Cookies调试模式,如果为True,则启用Cookies调试模式。
- DOWNLOADER_MIDDLEWARES (dict): 下载器中间件,用于修改请求和处理响应。
- SPIDER_MIDDLEWARES (dict): 爬虫中间件,用于修改爬虫请求和处理响应。
- EXTENSIONS (dict): 扩展组件,用于添加自定义的扩展组件。
- FEED_FORMAT (str): 输出文件格式,设置输出文件的格式,如JSON、CSV等。
- FEED_URI (str): 输出文件路径,设置输出文件的保存路径。
- FEED_EXPORT_ENCODING (str): 输出文件编码,设置输出文件的编码,默认为utf-8。
- FEED_EXPORT_FIELDS (list): 输出文件字段,设置输出文件需要包含的字段。
- FEED_STORAGES (dict): 输出文件存储方式,可以设置为本地存储、S3存储等。
- JOBDIR (str): 保存爬虫状态,设置保存爬虫状态的路径。
- **FILES_STORE:**为我们要保存文件的目录路径
- **IMAGES_STORE:**为图片保存的目录路径
使用Scrapy的Settings对象导入配置:我们也可以在Scrapy的Spider类中使用Settings对象来导入配置参数,例如:
from scrapy import Spider
from scrapy.utils.project import get_project_settings
class MySpider(Spider):
name = 'myspider'
def __init__(self, *args, **kwargs):
super(MySpider, self).__init__(*args, **kwargs)
self.settings = get_project_settings()
def start_requests(self):
# 获取参数
download_delay = self.settings.get('DOWNLOAD_DELAY')
# 其他逻辑
这样就可以获取到DOWNLOAD_DELAY配置参数的值。
6. scrapy.cfg
# Automatically created by: scrapy startproject
#
# For more information about the [deploy] section see:
# https://scrapyd.readthedocs.io/en/latest/deploy.html
[settings]
default = demo.settings
[deploy]
#url = http://localhost:6800/
project = demo
5. 项目实现(爬取4399网页的游戏信息)
-
创建项目
scrapy startproject mySpider -
创建一个spider
scrapy genspider game 4399.com编写game.py文件
爬取网页上小游戏的
name :游戏名称
type :分类
time :
image :存储要下载的图片的URL
import scrapy from scrapy import Request class GameSpider(scrapy.Spider): name = "game" allowed_domains = ["4399.com"] start_urls = ["https://www.4399.com/flash"] def url_next(self): urls = [] for i in range(2, 11): url = f"https://www.4399.com/flash/new_{i}.htm" urls.append(url) return urls def parse(self, response): txts = response.xpath('//*[@id="skinbody"]/div[@class="bre oh"]/ul/li') for _ in txts: name = _.xpath('a/b/text()').get() type = _.xpath('em[1]/a/text()').get() time = _.xpath('em/text()').get() image = _.xpath('a/img/@lz_src').get() yield { 'name': name, 'time': time, 'type': type, 'image': image } urls = self.url_next() for url in urls: yield Request(url, callback=self.parse) -
处理下载请求
处理下载请求的工作由Images Pipeline完成。
这是一个Scrapy中的Image Pipeline,用于处理爬虫下载的图片。它继承自Scrapy中的ImagesPipeline类,重写了其中的几个方法。
其中的file_path方法定义了图片文件的保存路径,根据item中的name和type属性生成一个文件名。
item_completed方法在每个图片下载完成后执行,可以在这里对下载的图片进行一些额外的处理,比如打印下载信息、将图片路径保存到item中等。
get_media_requests方法定义了需要下载的图片的请求,这里将item中的image属性作为图片的URL,生成一个Request对象,进行下载。
class ImagePipeline(ImagesPipeline): def file_path(self, request, response=None, info=None, *, item=None): name = item['name'] type = item['type'] file_name = f'{type}/{name}.jpg' return file_name def item_completed(self, results, item, info): # image_paths = [x['path'] for ok, x in results if ok] # if image_paths: # item['image_paths'] = image_paths for ok, result in results: if ok: path = result['path'] print(f'Downloaded image saved in {path}') return item def get_media_requests(self, item, info): image_paths = "https:" + item['image'] yield scrapy.Request(image_paths) -
setting的设置
ITEM_PIPELINES = { # key是管道的路径 # value是管道的优先级,越小越高 # "demo.pipelines.DemoPipeline": 300, # "demo.pipelines.newPipeline": 200, 'mySpider.pipelines.ImagePipeline': 299 } IMAGES_STORE = './images' # 图片保存路径 -
运行项目
scrapy crawl game