Java源码学习笔记之lang包——包装类Integer.class
前言:仅为学习所发现而记录。
JDK 版本:1.8
同样的,在去除所有方法和静态变量之后,以下为核心内容。
public final class Integer extends Number implements Comparable<Integer> {
private final int value;
private static class IntegerCache{...}
}内部类一般是相对独立的内容,所以我们先进行分析:
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer cache[];
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
try {
int i = parseInt(integerCacheHighPropValue);
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
} catch( NumberFormatException nfe) {
// If the property cannot be parsed into an int, ignore it.
}
}
high = h;
cache = new Integer[(high - low) + 1];
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
// range [-128, 127] must be interned (JLS7 5.1.7)
**assert IntegerCache.high >= 127;**
}
private IntegerCache() {}
}看这个类名就知道,这是一个专门用来缓存的内部类。
把从low到high所有int值提前缓存完毕,同时high可以由-Djava.lang.Integer.IntegerCache.high命令进行配置。以上代码加粗部分表明,high必须大于127,
类似Boolean类,只不过只是把常用的int值提前生成缓存,正因为常用的int值比较多,所以特别使用了一个专门的内部类进行管理。这也给了我们启发,如果某一个类中的某一部分的实例会被经常使用,也可以使用这种方法,提前实例化部分对象,省去管理对象的开销。
那么,这一机制在哪里体现呢?
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
首先我们也得知道 自动装箱拆箱机制 (since 1.5)
简单的说就是把包装类类型转化为基本数据类型
例:Integer i=1; 实为 Integer i=Integer.valueOf(1);
i++ 实为 i.intvalue()++;
如需详细了解可以查阅:https://blog.csdn.net/cflys/article/details/75143809 @cflys
PS:π_π 一回头才发现我们才把一个内部类讲清楚。 没关系我们继续。
好了,我们已经大致了解了Integer的缓存机制。
接下来继续拓展静态成员。
经过整理,比较重要成员代码如下:
final static char[] digits = {
'0' , '1' , '2' , '3' , '4' , '5' ,
'6' , '7' , '8' , '9' , 'a' , 'b' ,
'c' , 'd' , 'e' , 'f' , 'g' , 'h' ,
'i' , 'j' , 'k' , 'l' , 'm' , 'n' ,
'o' , 'p' , 'q' , 'r' , 's' , 't' ,
'u' , 'v' , 'w' , 'x' , 'y' , 'z'
};
final static char [] DigitTens = {
'0', '0', '0', '0', '0', '0', '0', '0', '0', '0',
'1', '1', '1', '1', '1', '1', '1', '1', '1', '1',
'2', '2', '2', '2', '2', '2', '2', '2', '2', '2',
'3', '3', '3', '3', '3', '3', '3', '3', '3', '3',
'4', '4', '4', '4', '4', '4', '4', '4', '4', '4',
'5', '5', '5', '5', '5', '5', '5', '5', '5', '5',
'6', '6', '6', '6', '6', '6', '6', '6', '6', '6',
'7', '7', '7', '7', '7', '7', '7', '7', '7', '7',
'8', '8', '8', '8', '8', '8', '8', '8', '8', '8',
'9', '9', '9', '9', '9', '9', '9', '9', '9', '9',
} ;
final static char [] DigitOnes = {
'0', '1', '2', '3', '4', '5', '6', '7', '8', '9',
'0', '1', '2', '3', '4', '5', '6', '7', '8', '9',
'0', '1', '2', '3', '4', '5', '6', '7', '8', '9',
'0', '1', '2', '3', '4', '5', '6', '7', '8', '9',
'0', '1', '2', '3', '4', '5', '6', '7', '8', '9',
'0', '1', '2', '3', '4', '5', '6', '7', '8', '9',
'0', '1', '2', '3', '4', '5', '6', '7', '8', '9',
'0', '1', '2', '3', '4', '5', '6', '7', '8', '9',
'0', '1', '2', '3', '4', '5', '6', '7', '8', '9',
'0', '1', '2', '3', '4', '5', '6', '7', '8', '9',
} ;看数组命名和内容也能将功能猜个大概,同时我发现java源码中很多成员变量之后马上就是相关方法,或者说是成员变量被穿插在方法中。这给我们一个书写代码格式的启示,不必把成员变量跟方法完全的分割开来,假如有一个成员变量的使用范围比较小,那么就可以把它放在相关方法之上便于查看。
先从第一个开始入手digits[],相关代码如下:
public static String toString(int i, int radix) {
if (radix < Character.MIN_RADIX || radix > Character.MAX_RADIX)
radix = 10;
/* Use the faster version */
if (radix == 10) {
return toString(i);
}
char buf[] = new char[33];
boolean negative = (i < 0);
int charPos = 32;
if (!negative) {
i = -i;
}
while (i <= -radix) {
buf[charPos--] = digits[-(i % radix)];
i = i / radix;
}
buf[charPos] = digits[-i];
if (negative) {
buf[--charPos] = '-';
}
return new String(buf, charPos, (33 - charPos));
}先看第一个if,别看这两行简单,但是这也是我们常忽略的点。这就是 java 在 封装方面的具体体现,我们在内部函数可以不对数据做检测,但是一旦供外层(用户或者别的程序员)使用时,他可不清楚你编写的逻辑,那么一定得做数据范围的保护。
还有传入参数radix,在这里应该被翻译成进制。代码功能相对简单(不包括10进制)就不解释了。
这时候再回看digit[],也能知道java的Integer竟然包括2到36进制,但是一般也是只用到16进制就够了。
为什么反而十进制比较困难呢?
public static String toString(int i) {
if (i == Integer.MIN_VALUE)
return "-2147483648";
int size = (i < 0) ? stringSize(-i) + 1 : stringSize(i);
char[] buf = new char[size];
getChars(i, size, buf);
return new String(buf, true);
}static void getChars(int i, int index, char[] buf) {
int q, r;
int charPos = index;
char sign = 0;
if (i < 0) {
sign = '-';
i = -i;
}
// Generate two digits per iteration
while (i >= 65536) {
q = i / 100;
// really: r = i - (q * 100);
r = i - ((q << 6) + (q << 5) + (q << 2));
i = q;
buf [--charPos] = DigitOnes[r];
buf [--charPos] = DigitTens[r];
}
// Fall thru to fast mode for smaller numbers
// assert(i <= 65536, i);
for (;;) {
q = (i * 52429) >>> (16+3);
r = i - ((q << 3) + (q << 1)); // r = i-(q*10) ...
buf [--charPos] = digits [r];
i = q;
if (i == 0) break;
}
if (sign != 0) {
buf [--charPos] = sign;
}
}看见这一堆左移右移,还用到了digitOnes[]和digitTens[],就知道我说的没错了吧。
这里就涉及到了计算机组成的内容了。总的来说左右移的性能比乘法相对要好,这也是总是有人常说i*8写成i<<3更优。
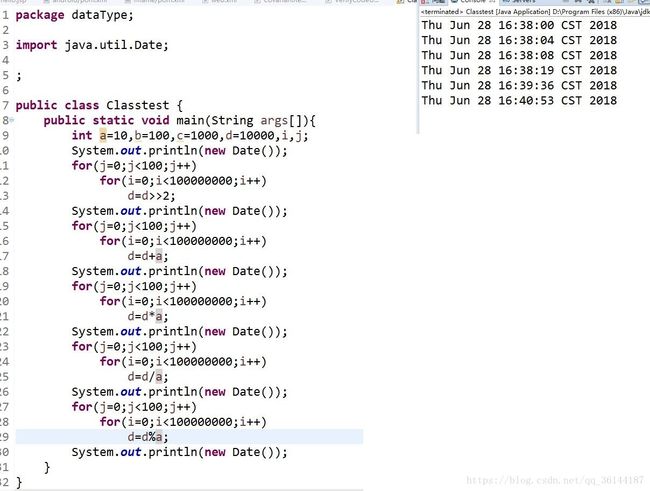
这个虽然不准确,受到时间片等干扰,但是能示意性的反映出,大概的性能之比。
所以这里先是把情况分为两种,以65536为界。把除法转化为无符号左移。为什么以65536为界以及下面为什么是52429>>>19呢?主要源于下面这张表。
2^10=1024, 103/1024=0.1005859375
2^11=2048, 205/2048=0.10009765625
2^12=4096, 410/4096=0.10009765625
2^13=8192, 820/8192=0.10009765625
2^14=16384, 1639/16384=0.10003662109375
2^15=32768, 3277/32768=0.100006103515625
2^16=65536, 6554/65536=0.100006103515625
2^17=131072, 13108/131072=0.100006103515625
2^18=262144, 26215/262144=0.10000228881835938
2^19=524288, 52429/524288=0.10000038146972656
2^20=1048576, 104858/1048576=0.1000003815
2^21=2097152, 209716/2097152 = 0.1000003815
2^22= 4194304, 419431/4194304= 0.1000001431刚好65535*52429不溢出且精度满足。
这一手操作逼格极高,也给了我们这样一个优化的角度,可以把很多除法转化为左右移了,假如按照上面得到的性能比较,快了五倍啊。
但是还有一个很大的问题!
r = i - ((q << 3) + (q << 1))这个语句虽然也能得到的理解两次移位运算和一次加法刚好等于一次乘法的时间。但是另一种情况的:
r = i - ((q << 6) + (q << 5) + (q << 2));这一条语句就十分费解了,从上方得到的性能比较 这就是反向优化啊。但是这确确实实又是Lee Boynton,Arthur van Hoff,Josh Bloch,Joseph D. Darcy这四个大佬鼓捣出来的。于是我陷入了沉思。

可是运行证明,确实快了一丢丢,假如移位再多一次

还是快了一丢丢,这就很神奇了。(暂时无视GC的性能损耗)我尝试着使用javap -c 命令得到的JVM汇编指令。
不同之处为 ![]()

这里还是找不到答案。这里的偶然发现(当int取值-1~5采用iconst指令,取值-128~127采用bipush指令,取值-32768~32767采用sipush指令,取值-2147483648~2147483647采用 ldc 指令)。 可以参考 另一个大佬的文章
询问大佬,他也给出了他的理解:计算机中乘法本就是要归结为位移运算,那能够直接用位移为什么还要中间用乘法转一下?这几天我也在学习编译原理的相关知识,发现上面javap得到的只是中间代码而优化却在之后,同时也佐证大佬说话的。这里人工的帮计算机减少了一步操作,所以显得更快。

PS:时隔一个星期多,终于可以继续往下走了。
digitOnes[]和digitTens[]这两个数组的运用就是典型的,以空间换取时间的操作了,把本来两次的取数据的操作换做一次取数据两次查表,查表的时间可是log(O)啊。代价就是更大的空间,所以他并没有列出所有的可能性,只是恰到好处的0~99的可能,这也给了我们启示:一次可以不用拘泥与一次操作数,可以取多个操作数用更大的可能性数组去覆盖。已达到用空间换取时间的目的。
目前先暂时分析到这。
PS:CSDN的编辑器简直无力吐槽,好不容易搞的排版,上传了 跟我说字数限制,吃了我一部分内容,逼我换一个编辑器。所以现在很丑也没办法了。
本文部分参考 https://www.cnblogs.com/vinozly/p/5173477.html