DeepLearning - 余弦退火热重启学习率 CosineAnnealingWarmRestartsLR
欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://spike.blog.csdn.net/article/details/134249925
CosineAnnealingWarmRestartsLR,即 余弦退火热重启学习率,周期性修改学习率的下降和上升,间隔幅度逐渐增大,避免模型的性能抖动。其中核心参数:
- optimizer 的参数,
lr学习率,默认学习率是 lr * GPU 数量,例如 lr 设置成 0.00001,32卡实际是 0.00032。 T_0,衰减的 global step 数,即单卡的运行次数,根据运行时间确定,例如 step 是 28.5 秒一次,(28.5 * 2000) / 3600 = 15.8 小时。T_mult,周期间隔,逐渐加大,例如T_mult是 2,则表示,第n次是 T 0 ∗ T m u l t n T_0*T_{mult}^{n} T0∗Tmultn 步。eta_min,从 LR 衰减的最小步数,可以设置成0。
源码:
optimizer = deepspeed.ops.adam.FusedAdam(self.model.parameters(), lr=learning_rate, eps=eps)
lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0=lr_t_0, T_mult=2, eta_min=0, last_epoch=-1)
LR 曲线如下:
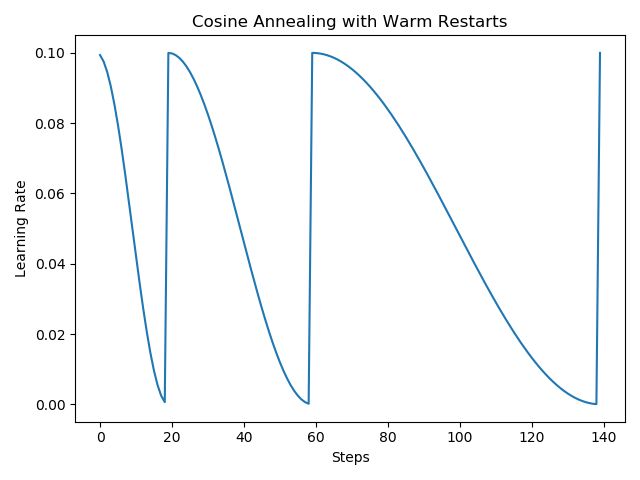
源码:CosineAnnealingWarmRestarts
class CosineAnnealingWarmRestarts(LRScheduler):
r"""Set the learning rate of each parameter group using a cosine annealing
schedule, where :math:`\eta_{max}` is set to the initial lr, :math:`T_{cur}`
is the number of epochs since the last restart and :math:`T_{i}` is the number
of epochs between two warm restarts in SGDR:
.. math::
\eta_t = \eta_{min} + \frac{1}{2}(\eta_{max} - \eta_{min})\left(1 +
\cos\left(\frac{T_{cur}}{T_{i}}\pi\right)\right)
When :math:`T_{cur}=T_{i}`, set :math:`\eta_t = \eta_{min}`.
When :math:`T_{cur}=0` after restart, set :math:`\eta_t=\eta_{max}`.
It has been proposed in
`SGDR: Stochastic Gradient Descent with Warm Restarts`_.
Args:
optimizer (Optimizer): Wrapped optimizer.
T_0 (int): Number of iterations for the first restart.
T_mult (int, optional): A factor increases :math:`T_{i}` after a restart. Default: 1.
eta_min (float, optional): Minimum learning rate. Default: 0.
last_epoch (int, optional): The index of last epoch. Default: -1.
verbose (bool): If ``True``, prints a message to stdout for
each update. Default: ``False``.
.. _SGDR\: Stochastic Gradient Descent with Warm Restarts:
https://arxiv.org/abs/1608.03983
"""
def __init__(self, optimizer, T_0, T_mult=1, eta_min=0, last_epoch=-1, verbose=False):
if T_0 <= 0 or not isinstance(T_0, int):
raise ValueError(f"Expected positive integer T_0, but got {T_0}")
if T_mult < 1 or not isinstance(T_mult, int):
raise ValueError(f"Expected integer T_mult >= 1, but got {T_mult}")
if not isinstance(eta_min, (float, int)):
raise ValueError(f"Expected float or int eta_min, but got {eta_min} of type {type(eta_min)}")
self.T_0 = T_0
self.T_i = T_0
self.T_mult = T_mult
self.eta_min = eta_min
self.T_cur = last_epoch
super().__init__(optimizer, last_epoch, verbose)
def get_lr(self):
if not self._get_lr_called_within_step:
warnings.warn("To get the last learning rate computed by the scheduler, "
"please use `get_last_lr()`.", UserWarning)
return [self.eta_min + (base_lr - self.eta_min) * (1 + math.cos(math.pi * self.T_cur / self.T_i)) / 2
for base_lr in self.base_lrs]
[docs] def step(self, epoch=None):
"""Step could be called after every batch update
Example:
>>> # xdoctest: +SKIP("Undefined vars")
>>> scheduler = CosineAnnealingWarmRestarts(optimizer, T_0, T_mult)
>>> iters = len(dataloader)
>>> for epoch in range(20):
>>> for i, sample in enumerate(dataloader):
>>> inputs, labels = sample['inputs'], sample['labels']
>>> optimizer.zero_grad()
>>> outputs = net(inputs)
>>> loss = criterion(outputs, labels)
>>> loss.backward()
>>> optimizer.step()
>>> scheduler.step(epoch + i / iters)
This function can be called in an interleaved way.
Example:
>>> # xdoctest: +SKIP("Undefined vars")
>>> scheduler = CosineAnnealingWarmRestarts(optimizer, T_0, T_mult)
>>> for epoch in range(20):
>>> scheduler.step()
>>> scheduler.step(26)
>>> scheduler.step() # scheduler.step(27), instead of scheduler(20)
"""
if epoch is None and self.last_epoch < 0:
epoch = 0
if epoch is None:
epoch = self.last_epoch + 1
self.T_cur = self.T_cur + 1
if self.T_cur >= self.T_i:
self.T_cur = self.T_cur - self.T_i
self.T_i = self.T_i * self.T_mult
else:
if epoch < 0:
raise ValueError(f"Expected non-negative epoch, but got {epoch}")
if epoch >= self.T_0:
if self.T_mult == 1:
self.T_cur = epoch % self.T_0
else:
n = int(math.log((epoch / self.T_0 * (self.T_mult - 1) + 1), self.T_mult))
self.T_cur = epoch - self.T_0 * (self.T_mult ** n - 1) / (self.T_mult - 1)
self.T_i = self.T_0 * self.T_mult ** (n)
else:
self.T_i = self.T_0
self.T_cur = epoch
self.last_epoch = math.floor(epoch)
class _enable_get_lr_call:
def __init__(self, o):
self.o = o
def __enter__(self):
self.o._get_lr_called_within_step = True
return self
def __exit__(self, type, value, traceback):
self.o._get_lr_called_within_step = False
return self
with _enable_get_lr_call(self):
for i, data in enumerate(zip(self.optimizer.param_groups, self.get_lr())):
param_group, lr = data
param_group['lr'] = lr
self.print_lr(self.verbose, i, lr, epoch)
self._last_lr = [group['lr'] for group in self.optimizer.param_groups]
WandB 测试效果:

参考:
- 知乎 - PyTorch中学习率调度器可视化介绍