python excel转json文件
在开发中可能会遇到需要将大量表格文件转换为json数据库的情况.本文试图用python使这个步骤半自动化.
目录
1.准备工作
2.打开excel文件
xlrd特性
3.读取数据转换为字典,再转为json
3-1.一种方式(基础款式)
3-2.更复杂的方式*
完整代码
3-1
3-2
1.准备工作
pip install "xlrd == 1.2.0"安装xlrd(excel read),注意要指定版本号,最新的几个版本只能读取单一格式表格.(不要打引号)
import xlrd
import json导入以上两个库.
2.打开excel文件
这里有个excel文件等待处理……
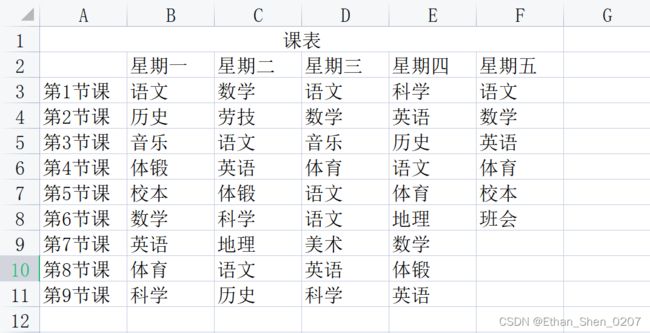
找到指定excel文件.
workbook = xlrd.open_workbook(r'c:\Users\……#输入文件地址')指定sheet.你要指定哪张sheet就写这张sheet的名字.
sheetname = 'Sheet1'
worksheet = workbook.sheet_by_name(sheetname)![]()
xlrd特性
与表格中的行与列计数不同,xlrd中A1单元格的位置用(0(行),0(列))表示.所以注意输入.
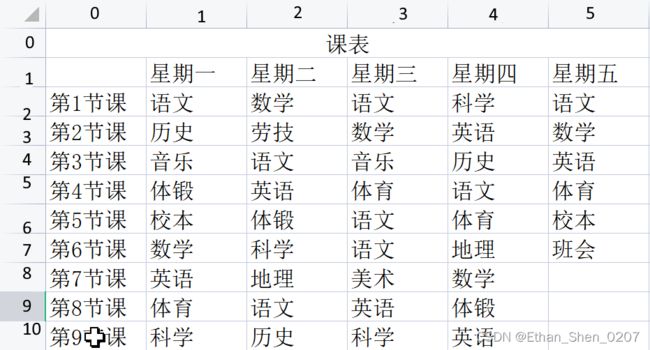
如图中B4单元格即用(3,1)表示;另外我们注意到(0,0)处的课表(标题)将(0,0-5)的单元格合并(通常用(0,0)表示,(0,1-5)读取不到信息),但在这标题是不用读取的,所以读取数据时不要把这一行读取.
3.读取数据转换为字典,再转为json
3-1.一种方式(基础款式)

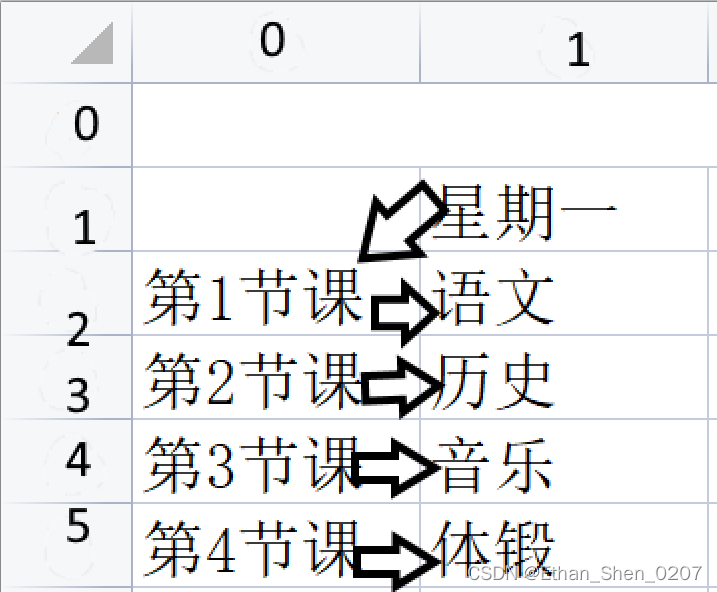
大致顺序如上图,格式为' "星期一第1节课":"语文" ; "星期一第2节课":"历史" '
代码如下:
dictionary = {}
for col, day in enumerate(worksheet.row_values(1, 1)):
for row, time in enumerate(worksheet.col_values(0, 2), start=2):
lesson = worksheet.cell_value(row, col+1)
ID = day + time
dictionary[ID] = lesson
print(dictionary)这里使用了`enumerate`函数来同时遍历行和列,并且使用`start`参数来指定起始行数为2(0,1的位置为空).同时使用了`row_values`和`col_values`函数来获取行和列的值.使用列表推导式可以使代码更加简洁.等效于:
column,row,dictionary = 1,2,{}
for i in range(5):
for i in range(9):
day = worksheet.cell_value(1, column)
time = worksheet.cell_value(row, 0)
lesson = worksheet.cell_value(row,column)
ID = day+time
dictionary[ID] = lesson
row += 1
row = 2
column += 1
print(dictionary)运行结果:
{'星期一第1节课': '语文', '星期一第2节课': '历史', '星期一第3节课': '音乐', '星期一第4节课': '体锻', '星期一第5节课': '校本', '
星期一第6节课': '数学', '星期一第7节课': '英语'……}
把字典转化为json:
jsondata = json.dumps(dictionary,ensure_ascii=False,indent=1)
print(jsondata)
with open('jsondata1.json',"a+",newline='\n',encoding='utf-8') as js:
#每打完一串换行
js.write(jsondata)
print('成功')完成:

3-2.更复杂的方式*
3-1的方法效率比较低啊
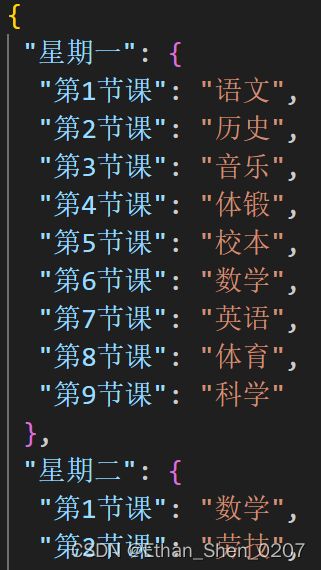
如上图所示,格式为:' "星期一":{"第1节课":"语文","第2节课":"历史"……}'
data = {}
for col, day in enumerate(worksheet.row_values(1, 1)):
dictionary = {}
for row, time in enumerate(worksheet.col_values(0, 2), start=2):
lesson = worksheet.cell_value(row, col+1)
dictionary[time] = lesson
data[day] = dictionary
jsondata = json.dumps(data, ensure_ascii=False, indent=1)
with open('jsondata1.json', 'w', encoding='utf-8') as f:
f.write(jsondata)
print('成功')该代码将dictionary字典再次嵌套到data中,从而减少字数.结果如下:
完整代码
3-1
import xlrd
import json
workbook = xlrd.open_workbook(r'c:\Users\…………')
sheetname = '…………'
worksheet = workbook.sheet_by_name(sheetname)
dictionary = {}
for col, day in enumerate(worksheet.row_values(1, 1)):
for row, time in enumerate(worksheet.col_values(0, 2), start=2):
lesson = worksheet.cell_value(row, col+1)
ID = day + time
dictionary[ID] = lesson
print(dictionary)
jsondata = json.dumps(dictionary,indent=1,ensure_ascii=False)
print(jsondata)
with open('jsondata1.json',"a+",newline='\n',encoding='utf-8') as js:
js.write(jsondata)
print('成功')3-2
import xlrd
import json
workbook = xlrd.open_workbook(r'c:\Users\…………')
sheetname = '…………'
worksheet = workbook.sheet_by_name(sheetname)
data = {}
for col, day in enumerate(worksheet.row_values(1, 1)):
dictionary = {}
for row, time in enumerate(worksheet.col_values(0, 2), start=2):
lesson = worksheet.cell_value(row, col+1)
dictionary[time] = lesson
data[day] = dictionary
jsondata = json.dumps(data, ensure_ascii=False, indent=1)
with open('jsondata1.json', 'w', encoding='utf-8') as f:
f.write(jsondata)
print('成功')