Linux-不同进程变量地址相同,其物理地址相同吗?
1·printf 缓冲区
- 如果缓冲区满了-那么就直接输出
- 如果缓冲区未满-用户强制刷新会输出
- 程序结束会输出
举个例子我们来看下
# include # include 通过这两组代码,我们需要自己动手尝试运行一下会发现–
- 第一组代码:先打印 hello 再休眠5秒
- 第二组代码:先休眠5秒再答应hello
为什么会出现以上的不同呢?
其原因就是缓冲区,再第一个代码中,我们加有 \n 进行对应的换行,强制对缓冲区进行了刷新,而第2个程序没有对缓冲区进行刷新所以是等待了5秒之后,遇到程序结束,那将对应的内容打印到屏幕上
2·主函数 3个参数
#include 

3·复制进程Fork
什么是进程:
一个其中运行着多个线程的地址空间和这些线程所需要的系统资源
简单点来说“就是每一个运行着的程序就是一个进程”
怎么查看进程
ps
进程怎么管理:
通过进程表来进行管理
进程表就类似一个数据结构-里面有进程的相关信息,包括进程的PID,进程的状态,命令字符串等
操作系统通过进程的PID对进程进行管理,PID为进程表的索引
进程的表的长度是有限,所以一个操作系统,同时可以运行的程序是有限制的
进程的祖先
一般情况下,进程都是由另一个我们称之为父进程启动的,被父进程启动的叫子进程。
Linux系统启动时,它将运行一个名为 init的进程,该进程是系统的第一个进程
可以将 init 进程看成 操作系统的进程管理器
3·1 fork 方法
pid_t fork();
函数的返回类型为pid_t 实际为整形(int)
fork()函数会生成一个进程,调用fork()函数的进程为父进程,新生成的进程为子进程。
在父进程中返回子进程的pid -(进程编号),在子进程中返回0,失败返回-1.
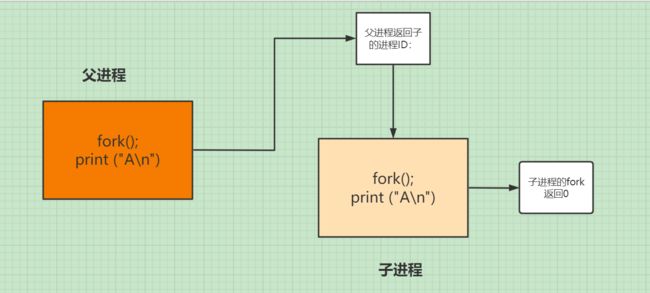
在这要注意–子进程执行 fork()后的所有内容,–特别注意:先fork()再返回对应的值
同时-子进程拷贝父进程的所有内容–在这有一个写实拷贝(要修改的拷贝,不修改的进行可以共享)
子进程和父进程是 并发 执行,所谓并发就是二者交替执行
3.2来看段代码
#include 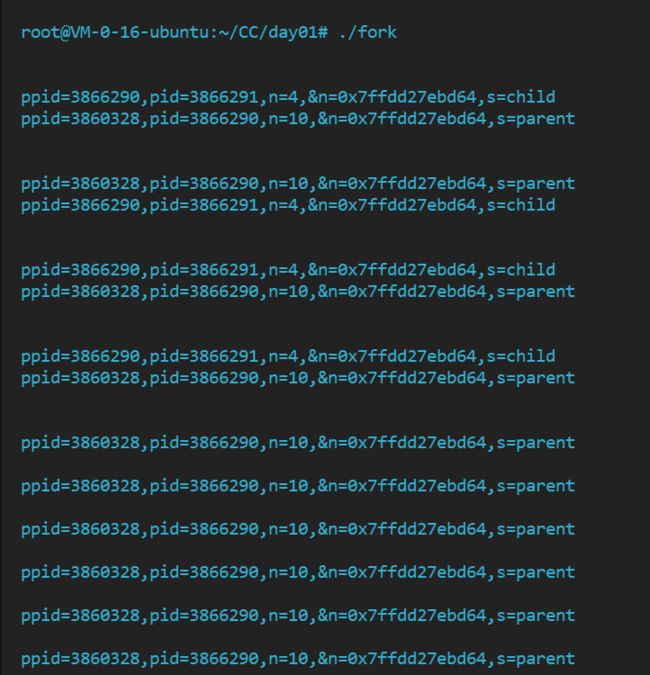
通过图片我们看到二者是进行交替进行的,没有问题,不过我们看到这里 n的地址是相同的,但实际上-在物理上是不是属于同一块儿内存空间呢❓
不过我们先来通过
./fork & //放在后台执行,通过 ps 来查看一下进程会出现什么情况
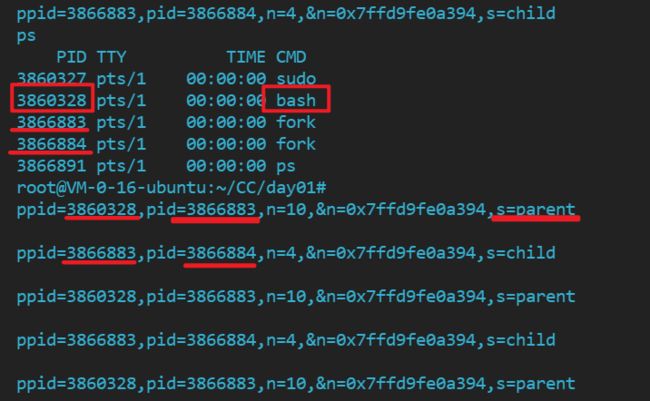
在这里我们可以明显的看到 子进程的 父进程ID 为上一个进程没有问题,在子进程未结束时,我们也可以看到子进程没有问题

通过上面这幅图,我们看到当子进程执行结束之后,子进程并没有结束,还存在 同时被标记 僵尸状态,这是为什么呢?

接上图我们看到其进程结束之后,由一个 [1]+ 这表示的是什么呢?
这表示的是-这个程序是一个前台任务,它不是再等待其他进程结束或等待输入输出操作完成
3·3僵尸进程
在这首先我们说一下进程主要的3种状态
- 就绪
- 运行
- 阻塞
3.3.1那僵尸进程怎么出现的呢?
子进程比父进程先结束-如果父进程没有通过wait ,就会出现僵尸进程
因为虽然子进程虽然已经不在运行,但它仍然存在于系统中,因此退出码需要保存卡里,以备父进程今后的wait 调用使用,这时它就是一个僵尸进程
我们来看下这段代码-当父进程先结束的时候会出现什么情况️
#include 当父进程执行3次,子进程执行10次的时候我们来看下图:
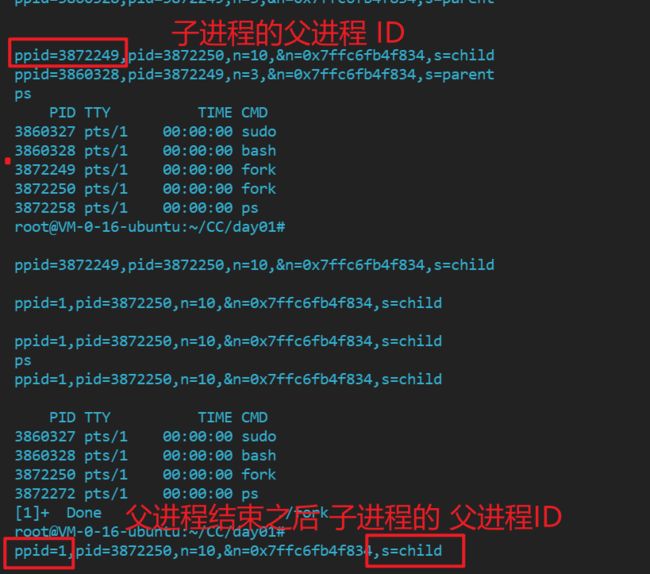
在这里我们明显的看到–当父进程结束之后,子进程的由 1号进程来接管了 –就是由我们上文提到的 init 进程来接管了
在上面代码中一部分被我注释掉的内容呢,就是通过 wait()来接受子进程的状态,如果子进程了,那么将其进程释放
3·4内存地址问题
& 地址的值都是相同的,在物理上是不是相同的呢?
我们一起来揭晓其答案
在物理上不是同一块儿内存
为什么呢?
因为子进程在赋值的时候–是赋值了所有的父进程有关的内容,到新的一块儿内存上,所以物理地址是不相同的
这会儿大家就有疑问了,为啥地址是相同的呢?
原因是因为,操作系统在分内存的时候,分了很多块,不是说是给你一整块你就自己用吧,它也需要一个管家来管理和分配。
所给的地址是一个逻辑地址,而逻辑地址是通过偏移量计算得来的。
它在这里是以4K的大小来进行分配内存块的,地址怎么计算呢?
32位操作系统用具体的地址 &n/4K 商就可以得知在哪个内存页面中,余数则为 它在那个页面的哪个位置
64位 &n/8K

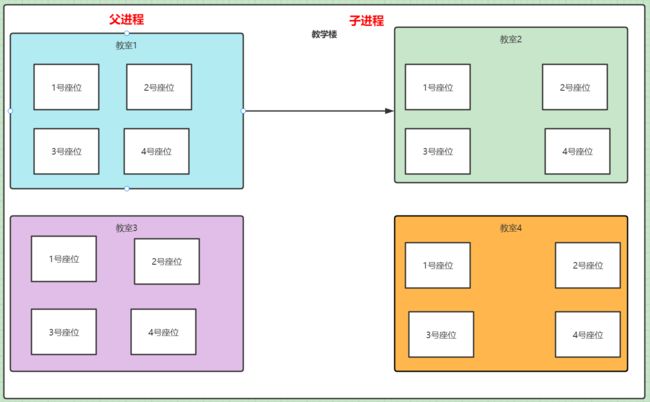
我们看到这张图,当教室1为子父进程的时候,fork 一个子进程,而子进程的这个教室和父进程的大小都是一样的,我们看里面的座位编码顺序,序号也都是一样的,所以它多打印的地址编号是一样的,不过他们在物理上并不属于同一块内存空间。
4·进程的3道经典面试题目
1·第一题
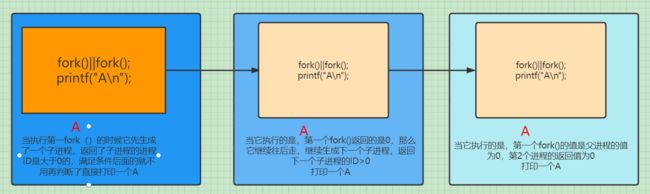
fork()||fork();
printf("A\n");
//请问打印几个A?
- 1
- 2
- 3–就是3个A
- 4
可以选择一自己的答案
画图分析
正确答案是什么呢?那就是3 啦~ 孩子第一次做也是错的()
将题目该一下如果给代码加上一个if():
-
if(fork()||fork()){ printf("A\n"); } //请问打印几个A?
那在这里就很明显就是2个了,我们用代码来验证一下
-
1 #include <stdlib.h> 2 #include <stdio.h> 3 #include <unistd.h> 4 int main(){ 5 fork()||fork(); 6 printf("\nA\n"); 7 exit(0); 8 }
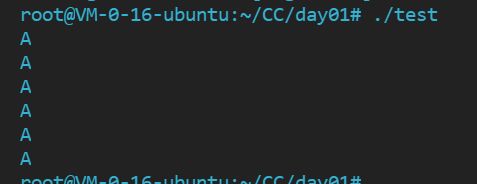
代码执行

题目变形
1 #include <stdlib.h>
2 #include <stdio.h>
3 #include <unistd.h>
4 int main(){
5 if(fork()||fork())
6 printf("\nA\n");
7 exit(0);
8 }
代码执行
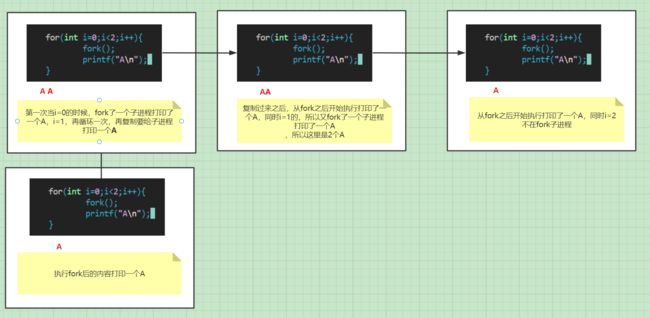
2·第2题
#include 请问打印几个A?
- 4
- 6
- 8
- 10
画图分析
代码执行
第3题-稍微修改第2题的代码
#include 请问打印几个A?
- 4
- 6
- 8
- 10
画图分析
那在这里,大家不要忘记,文章开篇的 缓存区问题
途中截图的代码–printf(“A”)少了引号,孩子忘记打了,不过可以解释清楚问题

代码验证

5·Linux目录和文件
5·1linux目录
| 目录 | |
|---|---|
| boot | Linux内核和启动文件 |
| bin | 命令文件目录 |
| lib | 共享库文件目录 |
| etc | 配置文件保存的位置 |
| home | 普通用户的家目录 |
5·2文件
- 普通文件 归档–(Mp3,mp4,txt,都属于普通文件)
- 目录文件 d
- 管道文件 p,链接 l ,设备 c,b, 套接字 s
