【Linux】进程管理命令,了解运维的五大性能监测
目录
一、程序与进程
1、程序是什么?
2、进程是什么?线程是什么?服务是什么?
3、进程的特点
4、进程使用内存的问题
二、运维相关命令学习
命令① ps 静态显示系统的进程
第一种静态查看进程信息:ps aux
第二种静态查看进程的组合:ps -elf
1、查看想要的进程属性,指定想要cpu的百分比,状态,命令,以及pid号
2、按照cpu利用率倒序排序
3、组合使用,排序,查找占用最多内存和CPU的进程
命令② top 动态查看系统进程(相当于Windows的任务管理器)
命令③htop,这是top的升级版,需要安装,另外还有glances 都是动态监控进程
命令④pgrep 查看指定进程
命令⑤pidof 已知进程名称,获取pid
命令⑥pstree 以树状显示进程
命令⑦lsof 可以列举系统中已经被打开的文件。
命令⑧vmstat 监控资源管理
总结一下,这里现在看不明白,以后有机会在生产环境中好好理解:
命令⑨内存空间查看,free以及查看具体进程占用内存资源 pmap pid
命令⑩磁盘读写性能iostat
命令11 uptime查看系统运行了多久时间
命令12 dstat 查看网络、磁盘读写、cpu的百分比
二、总结
一、程序与进程
1、程序是什么?
程序是一串特定功能的二进制代码,安安静静躺在硬盘里面,没有运行起来只消耗硬盘空间;
2、进程是什么?线程是什么?服务是什么?
进程:运行起来的程序,它有进程pid号标记,该pid由操作系统识别来管理,每一个进程都有自己的生命周期,每一个进程都是其父进程创建;它是需要消耗内存和cpu资源的;
进程一般由程序、数据集合和进程控制块三部分组成。
程序用于描述进程要完成的功能,是控制进程执行的指令集;
数据集合是程序在执行时所需要的数据和工作区;
程序控制块,包含进程的描述信息和控制信息,是进程存在的唯一标志。
线程:线程就是进程的真正执行者;
服务:服务就是进程所提供的功能;

3、进程的特点
动态性:进程是程序的一次执行过程,是临时的,有生命期的,是动态产生,动态消亡的;
并发性:任何进程都可以同其他进程一起并发执行;
独立性:进程是系统进行资源分配和调度的一个独立单位;
结构性:进程由程序、数据和进程控制块三部分组成。
4、进程使用内存的问题
内存泄漏:Memory Leak
指程序中用malloc或new申请了一块内存,但是没有用free或delete将内存释放,导致这块内存一直处于占用状态
内存溢出:Memory Overflow
指程序申请了10M的空间,但是在这个空间写入10M以上字节的数据,就是溢出,类似红杏出墙
内存不足:OOM
OOM 即 Out Of Memory,“内存用完了”,在情况在java程序中比较常见。系统会选一个进程将之杀死,在日志messages中看到类似下面的提示
Jul 10 10:20:30 kernel: Out of memory: Kill process 9527 (java) score 88 or sacrifice child
当JVM因为没有足够的内存来为对象分配空间并且垃圾回收器也已经没有空间可回收时,就会抛出这个error,因为这个问题已经严重到不足以被应用处理)。
原因:
给应用分配内存太少:比如虚拟机本身可使用的内存(一般通过启动时的VM参数指定)太少。
应用用的太多,并且用完没释放,浪费了。此时就会造成内存泄露或者内存溢出。
使用的解决办法:
1,限制java进程的max heap,并且降低java程序的worker数量,从而降低内存使用
2,给系统增加swap空间
二、运维相关命令学习
命令① ps 静态显示系统的进程
| ps命令的选项 | ||
| BSD格式 | a | 表示显示当前终端的进程 |
| u | 表示以用户身份显示进程 | |
| x | 表示显示当前用户的所有进程 | |
| unix格式 | -e | 表示显示系统内的所有进程信息 |
| -f | 完整的格式显示进程信息 | |
| -l | 使用长格式显示进程,ps -l表示只看当前shell产生的进程 | |
| 兼容 | o/-o | 属性,可以定制指定查看进程属性(用逗号分开) |
| k | 对属性进行排序(属性前面加“-”表示降序) | |
| --sort | 对属性进行排序(属性前面加“-”表示降序) | |
第一种静态查看进程信息:ps aux



1、关于进程几种状态的学习:
| 常见的STAT进程状态 | |
| R | 该进程正在运行 |
| S | 该进程出于睡眠,可以被唤醒 |
| D | 该进程出于不可以被唤醒,通常用于I/O |
| T | 该进程停止状态,可能是在后台暂停或者进程正处于除错状态 |
| Z | 僵尸进程,进程已经终止但是父进程不知道,并没有被收回资源,所以该进程还是继续占用资源,但是并没有工作 (运维就需要清理这种僵尸进程) |
| -< | 高优先级 |
| N | 低优先级 |
| L | 被锁在内存 |
| s | 包含子进程 |
| L | 多线程 |
| + | 位于后台 |
2、关于终端TTY有几种常见的:
| 常见的TTY | |
| tty1~tty6 | 本地的字符界面终端; |
| tty7 | 图形终端 |
| pts/0 ~ 255 | 代表虚拟终端,一般是远程连接的终端,第一个远程连接占用 pts/0,第二个远程连接占用 pts/1,依次増长。 |
| ? | 代表和终端无关,系统进程 |
3、注意TIME是占用cpu运算的时间,并不是占用系统的时间,比如程序被加载到内存并没有处理的时候是不算时间的;
第二种静态查看进程的组合:ps -elf




| ps -elf显示所有字段的含义 | |
| F | 进程标志,说明进程的权限,常见的标志有两个: 1:进程可以被复制,但是不能被执行;4:进程使用超级用户权限; |
| S | 具体的状态和"psaux"命令中的 STAT 状态一致 |
| UID | 运行此进程的用户的 ID |
| PID | 进程ID |
| PPID | 父进程ID |
| C | 该进程的 CPU 使用率,单位是百分比;与ps aux的%cpu一样 |
| PRI | 进程的优先级,数值越小,该进程的优先级越高,越早被 CPU 执行;系统定义不可以人为修改 |
| NI | 进程的优先级,数值越小,该进程越早被执行;可以人为修改 |
| ADDR | 该进程在内存的哪个位置 |
| SZ | 该进程占用多大内存 |
| WCHAN | 该进程是否运行。"-"代表正在运行; |
| TTY | 该进程由哪个终端产生,与ps aux的TTY一样 |
| TIME | 该进程占用 CPU 的运算时间,注意不是系统时间; |
| CMD | 产生此进程的命令名 |
1、表示进程优先级的有两个参数,PRI和NI
最终进程的优先级(最终)=PRI (原始) + NI
要知道PRI是系统最初就定义的优先级,无法更改,NI是可以修改的;
拓展:关于NI优先级的修改规则:
- NI的范围:-20至19
- 普通用户调整的范围是0-19,只能调整自己的进程
- 普通用户只能调高NI值,不能降低,如果原本NI=0,那么只能调整为大于0
- 只有root才有权限把NI调整为负数,root可以调整任何用户的进程

拓展,关于指定属性排序
1、查看想要的进程属性,指定想要cpu的百分比,状态,命令,以及pid号
[root@localhost ~]#ps -efo c,pid,cmd,s |head -5
C PID CMD S
0 21383 -bash USER=root LOGNAME=roo S
0 21327 -bash USER=root LOGNAME=roo S
0 24556 \_ ps -efo c,pid,cmd,s XDG R
0 24557 \_ head -5 XDG_SESSION_ID= S
[root@localhost ~]#ps ax o %cpu,pid,cmd,stat |head -5
%CPU PID CMD STAT
0.0 1 /usr/lib/systemd/systemd -- Ss
0.0 2 [kthreadd] S
0.0 3 [ksoftirqd/0] S
0.0 5 [kworker/0:0H] S<

2、按照cpu利用率倒序排序
[root@localhost ~]#ps aux k -%cpu |head -5
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 21985 0.3 0.4 385544 19124 ? S 13:22 0:39 /usr/bin/vmtoolsd -n vmusr
root 797 0.2 0.1 305316 6344 ? Ssl 02:57 2:14 /usr/bin/vmtoolsd
root 21819 0.1 5.3 1697576 207316 ? Sl 13:22 0:16 /usr/bin/gnome-shell
root 23743 0.1 0.0 0 0 ? S 15:32 0:07 [kworker/0:0]
[root@localhost ~]#ps -elf k -%cpu |head -5
F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD
4 S root 21985 1 0 80 0 - 96386 poll_s 13:22 ? 0:39 /usr/bin/vmtoolsd -n vmusr
4 S root 797 1 0 80 0 - 76329 poll_s 02:57 ? 2:14 /usr/bin/vmtoolsd
4 S root 21819 21614 0 80 0 - 424394 poll_s 13:22 ? 0:16 /usr/bin/gnome-shell
1 S root 23743 2 0 80 0 - 0 worker 15:32 ? 0:07 [kworker/0:0]
[root@localhost ~]#ps aux --sort -%cpu |head -5
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 21985 0.3 0.4 385544 19124 ? S 13:22 0:39 /usr/bin/vmtoolsd -n vmusr
root 797 0.2 0.1 305316 6344 ? Ssl 02:57 2:14 /usr/bin/vmtoolsd
root 21819 0.1 5.3 1697576 207316 ? Sl 13:22 0:16 /usr/bin/gnome-shell
root 23743 0.1 0.0 0 0 ? S 15:32 0:08 [kworker/0:0]
[root@localhost ~]#ps -elf --sort -%cpu |head -5
F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD
4 S root 21985 1 0 80 0 - 96386 poll_s 13:22 ? 00:00:39 /usr/bin/vmtoolsd -n vmusr
4 S root 797 1 0 80 0 - 76329 poll_s 02:57 ? 00:02:14 /usr/bin/vmtoolsd
4 S root 21819 21614 0 80 0 - 424394 poll_s 13:22 ? 00:00:16 /usr/bin/gnome-shell
1 S root 23743 2 0 80 0 - 0 worker 15:32 ? 00:00:08 [kworker/0:0]

3、组合使用,排序,查找占用最多内存和CPU的进程
ps -eo pid,ppid,cmd,%mem,%cpu --sort -%mem | head -5
ps -eo pid,ppid,cmd,%mem,%cpu --sort -%cpu | head -5
命令② top 动态查看系统进程(相当于Windows的任务管理器)

top是动态地查看cpu和内存、进程的状态,展示的信息比较多,主要分两部分来看
第一部分是显示的是整个系统的资源使用状况,通过这些输出来判断服务器的资源使用状态
第二部分是当前所有进程状态
第一部分的第一行
![]()
表示系统开启的时间,up后面是执行的时长,当前登录用户数量,cpu的平均载荷(1分钟,5分钟,15分钟)
第一部分的第二行
![]()
总进程数量208,其中1个在运行,207处于睡眠等待被唤醒,0停止,没有僵尸进程,这个僵尸进程是需要关注的!!
第一部分的第三行
![]()
分别表示占用cpu的百分比,us为个人用户开启的进程占用百分比,sy为系统模式占用cpu百分比,ni表示改变过优先级的用户进程占cpu的百分比,id表示空闲占用cpu的百分比,wa表示等待输入输出进程的百分比,hi是硬中断请求服务占比,si表示软中断请求服务占比
第一部分的第四和五行
![]()
表示占用物理和虚拟内存的大小,重点关注buff/cache 这是缓存的意思,缓存是为了提高读取,将硬盘内容加载到内存,读取更快;缓冲是为了更好的写入,先将内容存在内存中,一起写入硬盘中;但是这个太大也会影响cpu的处理,所以需要及时清理缓存
第二部分:
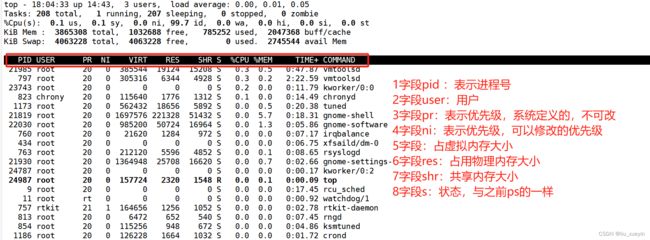
需要了解的top选项和交互操作
| top的命令选项 | |
| -d 秒数 | top -d 5表示每5秒刷新一次(默认是3秒) |
| -n 次数 | top -n 10 表示刷新10次退出 |
| -p pid | 表示查看指定进程 |
| -u 用户名 | 表示监听某个用户 |
| -H | 表示查看线程 |
| top的交互操作 | |
| ?或h | 表示交互模式的帮助 |
| c | 表示按照%cpu排序 |
| M | 按照内存的使用率排序 |
| N | 按照pid排序 |
| T | 按照cpu的运算时间排序 |
| k pid | 可以杀进程(不建议使用) |
| q | 表示退出 |
| z | 显示颜色 |
| s | 修改刷新时间 |
| 1 | 显示所有的cpu核数 |
| m | 显示内存空间的信息 |
| esc | 交互退出 |
拓展:%cpu的大小可以大于100% 嘛?
可以!!!
这个和cpu的核数有关系,比如4核,那么%cpu不能大于4,可以大于1
如果 1 分钟、5 分钟、15 分钟的平均负载接近核数,则证明系统压力较大。如果 CPU 的使用率过高或空闲率过低,则证明系统压力较大。如果物理内存的空闲内存过小,则也证明系统压力较大。
这时,我们就应该判断是什么进程占用了系统资源。如果是不必要的进程,就应该结束这些进程;如果是必需进程,那么我们该増加服务器资源(比如増加虚拟机内存),或者建立集群服务器。
缓冲(buffer)和缓存(cache)的区别:
-
缓存(cache)是在读取硬盘中的数据时,把最常用的数据保存在内存的缓存区中,再次读取该数据时,就不去硬盘中读取了,而在缓存中读取。
-
缓冲(buffer)是在向硬盘写入数据时,先把数据放入缓冲区,然后再一起向硬盘写入,把分散的写操作集中进行,减少磁盘碎片和硬盘的反复寻道,从而提高系统性能。
简单来说,缓存(cache)是用来加速数据从硬盘中"读取"的,而缓冲(buffer)是用来加速数据"写入"硬盘的。
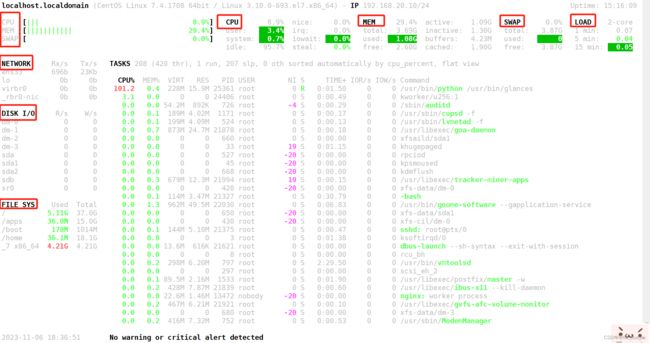
命令③htop,这是top的升级版,需要安装,另外还有glances 都是动态监控进程
htop界面

glances界面,非常全面!!!
命令④pgrep 查看指定进程
| pgrep选项 | |
| -l | 指定进程名称 |
| -U | 指定用户 |
| -p | 指定pid,查其子进程 |

命令⑤pidof 已知进程名称,获取pid

命令⑥pstree 以树状显示进程
| pstree选项 | |
| -a | 显示所有 |
| -u | 显示用户 |
| -p | 显示pid号 |

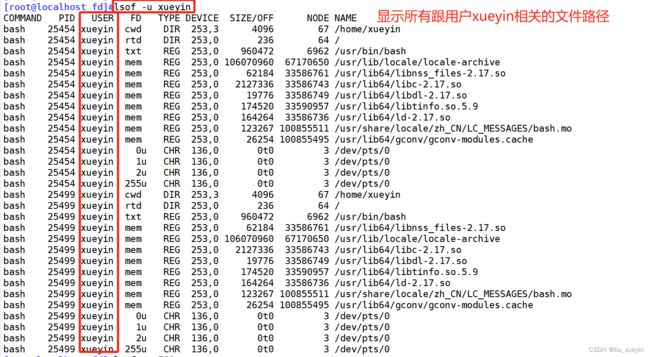
命令⑦lsof 可以列举系统中已经被打开的文件。
通过 lsof 命令,可以根据文件找到对应的进程信息,也可以根据进程信息找到进程打开的文件。

命令⑧vmstat 监控资源管理

| vmstat的显示 | |
| procs | 进程信息字段: -b:不可被唤醒的进程数量,数量越大,系统越繁忙。 |
| memory | 内存信息字段: -swpd:虚拟内存的使用情况,单位为 KB。 -free:空闲的内存容量,单位为 KB。-buff:缓冲的内存容量,单位为 KB。-cache:缓存的内存容量,单位为 KB。 |
| swap | 交换分区信息字段: -si:从磁盘中交换到内存中数据的数量,单位为 KB。 -so:从内存中交换到磁盘中数据的数量,单位为 KB。这两个数越大,表明数据需要经常在磁盘和内存之间进行交换,系统性能越差。 |
| io | 磁盘读/写信息字段: -bi:从块设备中读入的数据的总量,单位是块。 -bo:写到块设备的数据的总量,单位是块。这两个数越大,代表系统的 I/O 越繁忙。 |
| system | 系统信息字段: -in:每秒被中断的进程次数。 -cs:每秒进行的事件切换次数。这两个数越大,代表系统与接口设备的通信越繁忙。 |
| cpu | CPU信息字段: -us:非内核进程消耗 CPU 运算时间的百分比。 -sy:内核进程消耗 CPU 运算时间的百分比。 -id:空闲 CPU 的百分比。 -wa:等待 I/O 所消耗的 CPU 百分比。 -st:被虚拟机所盗用的 CPU 百分比 |
总结一下,这里现在看不明白,以后有机会在生产环境中好好理解:
通过分析 vmstat 命令的执行结果,可以获得一些与当前 Linux 运行性能相关的信息。比如说:
-
r 列表示运行和等待 CPU 时间片的进程数,如果这个值长期大于系统 CPU 的个数,就说明 CPU 不足,需要增加 CPU。
-
b 表示不可中断睡眠的进程
-
swpd 列表示切换到内存交换区的内存数量(以 kB 为单位)。如果 swpd 的值不为 0,或者比较大,而且 si、so 的值长期为 0,那么这种情况下一般不用担心,不用影响系统性能。
-
cache 列表示缓存的内存数量,一般作为文件系统缓存,频繁访问的文件都会被缓存。如果缓存值较大,就说明缓存的文件数较多,如果此时 I/O 中 bi 比较小,就表明文件系统效率比较好。
-
一般情况下,si(数据由硬盘调入内存)、so(数据由内存调入硬盘) 的值都为 0,如果 si、so 的值长期不为 0,则表示系统内存不足,需要增加系统内存。
-
如果 bi+bo 的参考值为 1000 甚至超过 1000,而且 wa 值较大,则表示系统磁盘 I/O 有问题,应该考虑提高磁盘的读写性能。
-
输出结果中,CPU 项显示了 CPU 的使用状态,其中当 us 列的值较高时,说明用户进程消耗的 CPU 时间多,如果其长期大于 50%,就需要考虑优化程序或算法;sy 列的值较高时,说明内核消耗的 CPU 资源较多。通常情况下,us+sy 的参考值为 80%,如果其值大于 80%,则表明可能存在 CPU 资源不足的情况。
总的来说,vmstat 命令的输出结果中,我们应该重点注意 procs 项中 r 列的值,以及 CPU 项中 us 列、sy 列和 id 列的值。
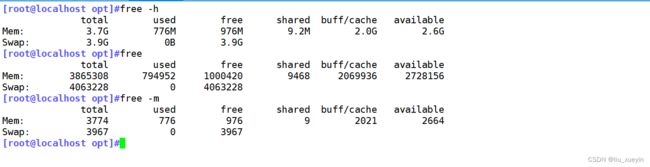
命令⑨内存空间查看,free以及查看具体进程占用内存资源 pmap pid

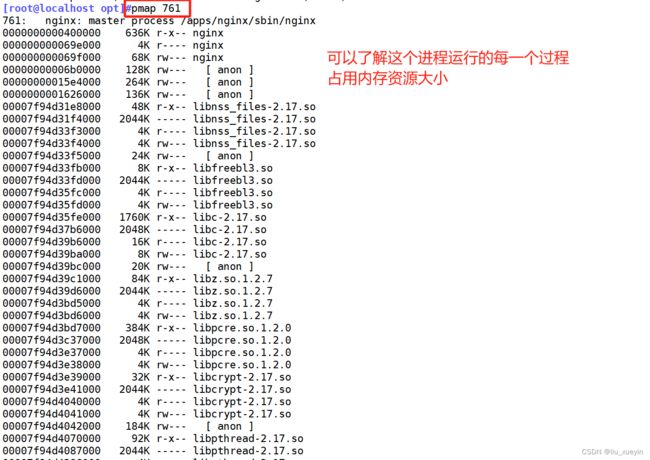
命令⑩磁盘读写性能iostat
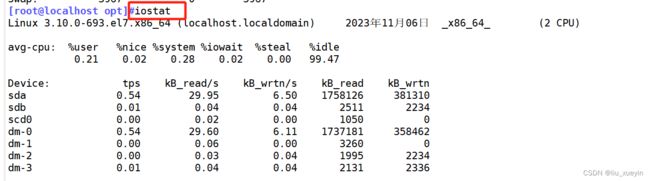

命令11 uptime查看系统运行了多久时间

命令12 dstat 查看网络、磁盘读写、cpu的百分比
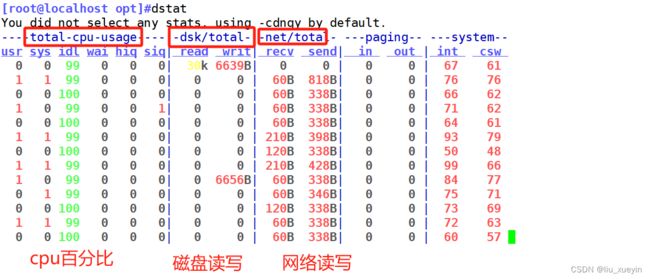
二、总结
运维运维实际上就是关注资源使用,总结为五大性能:
| 命令 | cpu | 内存 | 磁盘读写 | 磁盘空间 | 网络 | |||
| 1\5\15平均负载 | %cpu | 单项项百分比 | %mem | free空间和buff/cache | ||||
| ps aux | √ | √ | ||||||
| ps -elf | √ | |||||||
| top | √ | √ | √ | √ | √ | |||
| htop | √ | √ | √ | √ | √ | |||
| glances | √ | √ | √ | √ | √ | √ | √ | √ |
| iostat | √ | √ | ||||||
| vmstat | √ | √ | √ | |||||
| mpstat | √ | |||||||
| dstat | √ | √ | √ | |||||
| iftop | √ | |||||||
| free | √ | |||||||
| uptime | √ | |||||||
| lsblk | √ | |||||||
| df | √ | |||||||