redis通关面试宝典
文章目录
-
-
- 1.redis基本的数据结构有哪些
- 2. Redis高级类型
- 3.布隆过滤器实现的原理和使用场景(高级数据类型)
-
- 3.1. 原理
- 3.2. 案例
- 3.3 Bloom Filter的缺点
- 3.4. Bloom Filter 实现
- 3.5 使用场景
- 4.redis锁
-
- 4.1 watch乐观锁(对key变化监视)
- 4.2 分布式锁(悲观锁,对数据value监视)
- 5.redis主从复制
-
- 5.1redis集群的主从复制模型是怎样?
- 5.2 redis 主从复制的核心原理?
-
- 5.2.1 建立连接阶段
- 5.2.2 数据同步阶段
- 5.2.3 命令传播阶段
- 5.2.4 redis主从复制的工作流程
- 5.3 主从复制会存在哪些问题呢?
- 5.4 配置主从复制
- 6.Redis消息队列的几种模式
-
- 6.1 基于List的 LPUSH+BRPOP 的实现
- 6.2 PUB/SUB,订阅/发布模式
- 6.3 基于Sorted-Set的实现
- 6.4基于Stream类型的实现
- 8.消息队列如何保证可靠消息传输,如何设计消息队列
- 9.redis 持久化机制
-
- 9.1持久化流程
- 9.2 RDB(数据快照)
- 9.3 AOF(日志,**仅追加文件**)
- 10.redis集群怎么搭建的
-
- 10.1 创建集群
- 10.2 查看集群状态
- 10.3 添加主节点
- 10.4 添加从节点
- 10.5 删除副本节点
- 10.6 集群在线分片
- 19.redis 大key问题.
- 20.缓存预热,缓存雪崩,缓存击穿,缓存穿透
- 21.为什么要用 redis/为什么要用缓存
- 22.redis 和 memcached 的区别
- 23.跳跃表(链表)
- 24.redis这么快,为什么是单线程的?
- 25.redis是单线程的,为什么还这么快
- 26.Redis事务
-
- 1. redis事务的概念
- 2.redis事务的三个阶段和相关命令
- 3.事务错误
- 4.redis事务支持ACID吗?支持回滚吗
- 27.删除策略
-
- 27.1 redis的过期键的删除策略
- 27.2 redis的内存淘汰策略
- 28. redis缓存和数据库双写一致性问题
- 29.多个系统同时操作Redis带来的数据问题?(并发竞争key)
- 30.哨兵有哪些功能?
-
- 30.1 哨兵配置
- 30.2 springboot配置文件 哨兵
- 31. java整合redis
- 32. SpringBoot整合redis
- 33. redis应用场景
- 34. Redis分布式缓存
-
1.redis基本的数据结构有哪些
数据类型的大小
| 数据类型 | 最大存储数据量 |
|---|---|
| key(key是字符串) | 512M |
| string | 512M |
| hash | 2^32-1 |
| list | 2^32-1 |
| set | 2^32-1 |
| sorted set | |
| bitmap | 512M |
| hyperloglog | 12K |
| geo |
异常快:每秒大概有110000次的设置(set),每秒大概有81000次的读取(get),速度很快。
支持丰富的数据类型:支持字符串、集合、链表、排序等特性的数据结构。一般redis很容易被解决各种问题。
操作具有原子性:所有Redis操作都是原子操作,这确保两个或多个客户端并发访问时,Redis服务器能接收到更新的值。
多实用工具:Redis是一个多实用工具,用于缓存、消息堆栈。
2.五种基本数据类型:
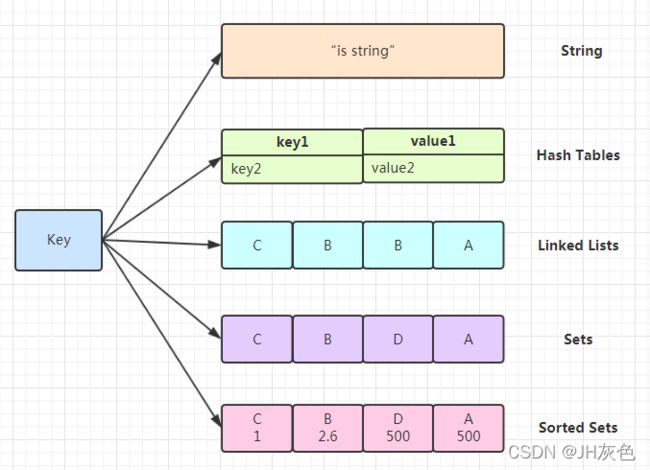
Redis有5种基础数据结构,它们分别是:string(字符串),list(列表),hash(字典),set(集合)和zset(有序集合)。
1)字符串:Redis中的字符串是一个动态字符串,意味着用户可以修改,它的实现就有点类似java中的ArrayList。Redis将同一个结构用泛型定义了很多次。以key +value存
常用命令(大小写都行):set,get,EXISTS key,DEL key,mget,mset,incr,decr
应用场景:1.缓存:把常用信息,字符串,图片或者验证码放到redis中,Redis作为缓存层,mysql做持久化层,降低mysql数据读写压力。2.计数器:redis能够保持原子性操作。可以快速实现计数和查询的功能。而且最终的数据结果可以按照特定的时间落地到数据库或者其他存储介质永久存储。3.共享用户Session:用户重新刷新一次界面,可能需要访问一下数据进行重新登录,或者访问页面缓存Cookie,但是可以利用Redis将用户的Session集中管理,在这种模式只需要保证Redis的高可用,每次用户Session的更新和获取都可以快速完成。大大提高效率。
2)list(列表清单):Redis的列表相当于Java语言中的LinkedList,注意它是链表而不是数组。这意味着list的插入和删除操作非常快,时间复杂度为O(1),但是索引定位很慢,时间复杂度为O(n))。可以队列规则也可以栈规则。它就是有序可重复的,存进去什么样取出来还是什么样。以key+列表
常用命令:lpush,rpush,lpop,rpop,lrange mylist 0 -1 取第一个元素到最后一个元素,llen key,lindex key index
应用场景:1.文章列表或者数据分页展示的应用:例如微博的时间轴,有人发布微博,用lpush加入时间轴,展示新的列表信息。每次都以原先添加的顺序访问数据。2.消息队列:Redis的链表结构,可以轻松实现阻塞队列,可以使用左进右出的命令组成来完成队列的设计。比如:数据的生产者可以通过Lpush命令从左边插入数据,多个数据消费者,可以使用BRpop命令阻塞的“抢”列表尾部的数据。3.
3)Hash(字典哈希):这个Redis中的字典Hash相当于java中的HashMap,内部实现也差不多,都是通过"数组+链表"的链地址法解决哈希冲突。无序不可重复,以key+属性field+value。
常用命令:hget,hset,hdel,hlen,hkeys,hvals,hincrby,hdecrby
应用场景:比如客户id+购买商品id+购买数量
4)set(集合集):Redis的集合相当于Java语言中的HashSet,它内部的键值对是无序不可重复的。它的内部实现相当于一个特殊的字典,字典中所有的值都是一个值NULL。以key+属性field(相当于value)
常用命令:sadd,spop,scard,smembers,srem移除,sismember
场景:点赞,或点踩,收藏等,可以放到set中实现
5)有序列表zset:相当于java中的SortedSet,保证了无序不可重复,但是取出来的元素是排序好的,以key+value+排序score
常用命令:zadd,zrange,zrevrange,zcard计数,zcore指定 value 的 score,zrank排名
场景:1.排行榜:有序集合经典使用场景。例如小说视频等网站需要对用户上传的小说视频做排行榜,榜单可以按照用户关注数,更新时间,字数等打分,做排行。2.用Sorted Sets来做带权重的队列,比如普通消息的score为1,重要消息的score为2,然后工作线程可以选择按score的倒序来获取工作任务。让重要的任务优先执行。
2. Redis高级类型
1.Bitmap(位图数据结构) :数据以0和1存储,通常设1是有,0是无,这样就可以过滤掉0的数据,和布隆过滤器(BloomFilter)差不多。
常用命令:
- 设置指定key对应偏移量offset(相当于hash(key)与数组-1位运算得到的索引值)上的bit值, value只能是1或0
setbit key offset value - 获取指定key对应偏移量上的bit值
getbit key offset - 对指定key按位进行交、并、非、异或操作,并将结果保存到destKey中
bitop or destKey key1 [key2...]- or处还可以填 and交 not非 xor异或
- 统计指定key中1的数量
bitcount key [start end]
2.HyperLogLog:就是去除重复的数据,比较适合用来做大规模数据的去重统计。
常用命令:
- 添加数据:
pfadd key element [element ...] - 统计数据:
pfcount key [key ...] - 合并数据:
pfmerge destkey sourcekey [sourcekey...]
3.Geo:就是获取坐标点的位置和计算两点之间的距离。增加了地理位置 GEO 模块
常用命令:
-
添加坐标点:
geoadd key longitude latitude member [longitude latitude member ...]georadius key longitude latitude radius m|km|ft|mi [withcoord] [withdist] [withhash] [count count] -
获取经纬度坐标点:
geopos key member [member ...] georadiusbymember key member radius m|km|ft|mi [withcoord] [withdist] [withhash] [count count] -
计算坐标点距离:
geodist key member1 member2 [unit] geohash key member [member ...]
3.布隆过滤器实现的原理和使用场景(高级数据类型)
布隆过滤器实际上是一个很长的二进制向量和一系列随机映射函数(哈希函数)。布隆过滤器可以用与检索一个元素是否在一个集合中。它的优点就是空间效率和查询时间都超过一般算法,缺点是有一定的误判率和删除困难。
3.1. 原理
当一个元素被加入集合时,通过K个哈希散列函数将这个元素映射成一个位数组中的K个点(就是通过K次哈希函数和数组运算得出K个索引值(偏移量)),并把数组中K个索引处置为1。检索时,我们只要看这些点的数组是不是1,如果是1,(大概率范围)默认集合中有该元素了(因为通过Hash算法的哈希值与数组长度相关运算,得出数组的索引值,和哈希表一样,只能说索引值相同,但是数组存储的元素不一定相同,所以说存在误判率)。如果K个点中只要任何一个为0,则检测元素一定不在数组中;如果都是1,则检测元素很可能在。
布隆过滤器跟单哈希函数BitMap不同之处在于:Bloom Filter使用了k个哈希函数,就是需要k次哈希运算,每个字符串跟k个bit对应,降低了冲突的概率;但是BitMap是一个单一的哈希函数,只用一次哈希运算,即只能得出一个索引值(偏移量),放一个value(0或1)。

3.2. 案例
布隆过滤器是一个 bit 向量或者说 bit 数组,长这样:

如果添加一个字符串"baidu",那么这个字符串会和K个bit对应,图中"baidu"和3个不同的索引值对应,通过3次哈希函数和数组相关运算得出索引值,即偏移量为1,4,7,把这些位置置为1,则添加成功。(说明:检索“baidu”,需要索引值1、4、7均为1才行,这还只能是大概率说明存在该字符串,只要其中任何一个为0说明该元素不存在)
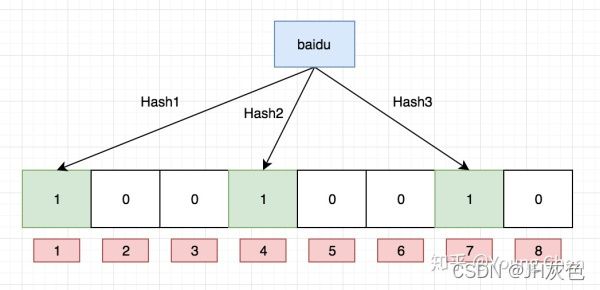
再存一个"tencent",得出3、4、8, 发现它在某次哈希算法的哈希值与数组位运算时得出的索引值也为4。

3.3 Bloom Filter的缺点
- 存在误判率:之前的哈希算法已经解释。如果bloom filter中存储的是黑名单,那么可以通过建立一个白名单来存储可能会误判的元素。
- 删除元素困难。因为一个元素对应K个bit位的数组值1,删除的时候不能把这K个索引处都置为0,因为可能存在其他元素的索引值也含有这些索引位(如上述案例’tencent’和’baidu’都含有索引值4),贸然删除,可能导致存储的其他元素也失效了。
3.4. Bloom Filter 实现
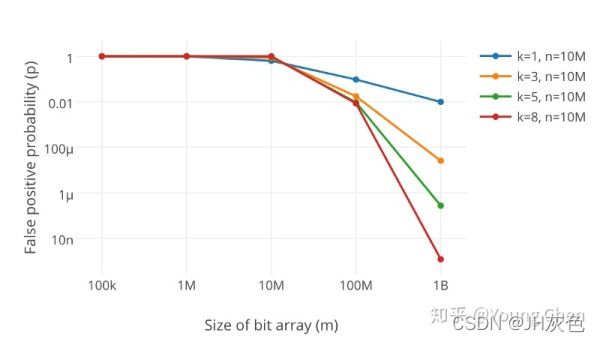
k 为哈希函数个数,m 为布隆过滤器长度,n 为插入的元素个数,p 为误报率。
在实现布隆过滤器的时候,需要考虑 1)数据量n和设定误判率; 2)Hash函数的选取和bit数组的大小
(1)Bit数组大小选择:根据数据量n,误判率fpp计算bit数组大小。
(2)哈希函数选择K多少个:预估数据量n以及bit数组长度m,可以得到一个hash函数的个数k。
一般过小的Bloom Filter,放入很多字符串时,很快数组的位都置为1了,那么查询任何值都会返回“可能存在”,起不到过滤的目的了。一般过滤器越长,误判率就越小。另外哈希函数的个数K,个数越多,则置为1的速度就越快,但是效率就变低;如果太少,误判率就越高。
3.5 使用场景
一般在缓存穿透下,使用较多,可以过滤掉大部分无效请求.
4.redis锁
4.1 watch乐观锁(对key变化监视)
业务场景:天猫双11热卖过程中,对已经售罄的货物追加补货, 4个业务员都有权限进行补货。补货的
操作可能是一系列的操作(即使事务有隔离性,最后补货还是最开始的那个人,其他业务员补货会被隔离,但是他们都执行补货这个动作了,虽然结果不影响,但是多做了3次无用功的补货动作,耗费性能),牵扯到多个连续操作,如何保障不会重复操作? 比如A补货了,B、C、D就都不再补货。
业务分析:多个客户端有可能同时操作同一组数据,并且该数据一旦被操作修改后,将不适用于继续操
作 在操作之前锁定要操作的数据,一旦发生变化,终止当前操作 。
解决方法: watch 对 key 添加监视锁,在执行exec前如果key发生了变化,终止事务执行 。
当客户端断开连接时, 该客户端对键的监视也会被取消。用无参数的 unwatch 命令可以手动取消对所
有键的监视。
watch,unwatch指令都是放在multi指令前,即事务之前加锁和释放锁,它假设数据访问时没有其他客户端的写操作,等到提交执行事务时才会检测是否有写操作,如果有写操作则终止事务,体现一种乐观的思想。
加不加锁和并发有关系,它是指多个线程在同一时间对同一个数据的并发访问,key变化则终止事务:
127.0.0.1:6379> set name zhangsan
OK
127.0.0.1:6379> set age 13
OK
127.0.0.1:6379> watch name -- watch要在multi之前监控,不能在事务中watch
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set aa bb
QUEUED
127.0.0.1:6379> exec -- 执行前让其他事务修改 set name lisi,那么该事务就不会再
执行
(nil)
127.0.0.1:6379> unwatch -- 释放对所有锁的监控
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set aa bb
QUEUED
127.0.0.1:6379> exec
1) OK
127.0.0.1:6379>
说明:redis的锁和隔离性没有任何关系!!!!
redis的隔离性是开启了事务multi之后,在事务之内的指令的执行,它会先把这些指令放入事务队列,在执行事务exec时,会按照添加队列的顺序依次执行这些指令,中途不会被中断、干扰。与其他客户端请求隔离,即使其他客户端执行写操作,也会无视操作。
那就提出一个问题:既然事务有了隔离性,最终结果不会变化,为什么还要加监视器锁watch监视key的变化呢?
[就拿之前的业务员补货问题,即使事务有隔离性,最后补货还是最开始的那个人,其他业务员补货会被隔离,但是他们都执行补货这个动作了,虽然结果不影响,但是多做了3次无用功的补货动作,耗费性能。你说重复劳动有必要么。]
4.2 分布式锁(悲观锁,对数据value监视)
业务场景:天猫双11热卖过程中,对已经售罄的货物追加补货,且补货完成。客户购买热情高涨, 3秒
内将所有商品购买完毕。本次补货已经将库存全部清空,如何避免最后一件商品不被多人同时购买?
【超卖问题】就是说如果只剩一件商品,但是有5个人要买,如何保证不被超卖???
业务分析:使用watch监控一个key有没有改变已经不能解决问题,此处要监控的是具体数据 ,我们要
监控的是商品的数量什么时候到 1 ,这个商品的数量是一直变化的,不可能别每次变化,都放弃执行。
虽然redis是单线程的,但是多个客户端对同一数据同时进行操作时,如何避免不被同时修改?
解决方案:
使用 setnx 设置一个公共锁: setnx key value ,这个value设置任意值都行,无关紧要;操作完毕通过del key操作释放锁 。
利用setnx命令的返回值特征,有值则返回设置失败,无值则返回设置成功
- 对于返回设置成功的,拥有控制权,进行下一步的具体业务操作
- 对于返回设置失败的,不具有控制权,排队或等待
操作完毕通过del操作释放锁
127.0.0.1:6379> set num 10
OK
127.0.0.1:6379> setnx num 1 -- 加锁
(integer) 1
127.0.0.1:6379> incrby num -1 ---当前加锁客户端内可以继续操作
(integer) 9
127.0.0.1:6379> del num -- 释放锁
(integer) 1
--------------------------------
127.0.0.1:6379> setnx num 1 -- 当前客户端加锁,在加锁客户端内可以继续操作
(integer) 1
127.0.0.1:6379> setnx num 1 -- 其他客户端获取不到锁
(integer) 0
**死锁:**如果加了锁,但是没有释放,就会导致死锁,其他下客户端一直获取不到锁。
使用 expire 为锁 key 添加时间限定,到时不释放,放弃锁。 由于操作通常都是微秒或毫秒级,因此该锁
定时间不宜设置过大。具体时间需要业务测试后确认。
指令:加锁时间expire key seconds ;pexpire key milliseconds
127.0.0.1:6379> set name 123
OK
127.0.0.1:6379> setnx name 1
(integer) 1
127.0.0.1:6379> expire name 20 -- 使用expire为锁key添加时间限定
(integer) 1
127.0.0.1:6379> get name
"123
5.redis主从复制
5.1redis集群的主从复制模型是怎样?
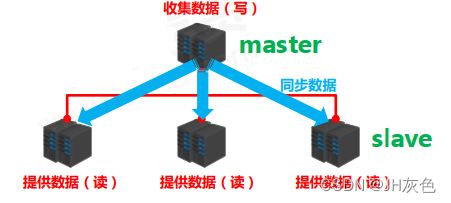
master : 写数据,执行写操作时,将出现变化的数据自动同步到slave 。
slave :读数据 。
主从复制:是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master),后
者称为从节点(slave),数据的复制是单向的,只能由主节点到从节点。默认情况下,每台Redis服务器
都是主节点;且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点 。
高可用集群:
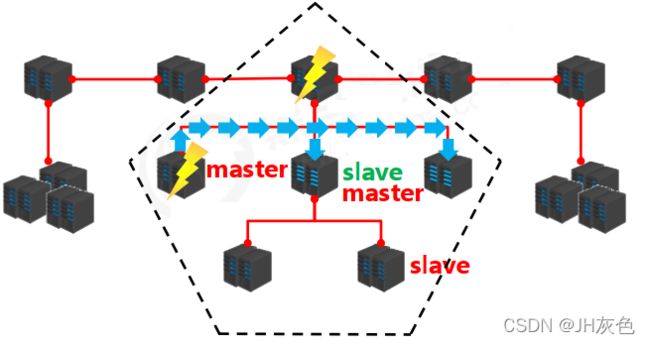
主从复制的作用:
① 数据冗余,实现数据的热备份
② 故障恢复,避免单点故障带来的服务不可用读写分离,
③ 负载均衡,主节点负载读写,从节点负责读,提高服务器并发量
④ 高可用基础,是哨兵机制和集群实现的基础
5.2 redis 主从复制的核心原理?
主从复制是将主机的数据同步到从机上,即主从复制仅是数据同步,但是不能解决故障迁移(主机宕机,从机无法提供服务)
-
主从复制过程大体可以分为3个阶段
- 建立连接阶段(即准备阶段)
- 数据同步阶段
- 命令传播阶段

5.2.1 建立连接阶段
建立slave到master的连接,使master能够识别slave, 并保存slave端口号 。


5.2.2 数据同步阶段
(1) 在 slave 初次连接 master 后,复制 master 中的所有数据到 slave。
(2) 将 slave 的数据库状态更新成master当前的数据库状态 。

5.2.3 命令传播阶段
当上一步执行完数据同步后,之后每一次主服务器master每执行一次写操作,就需要向从服务器slaver同步该命令,保证主从一致。这就是命令传播阶段。
(1) 当master数据库状态被修改后,导致主从服务器数据库状态不一致,此时需要让主从数据同步到一
致的 状态,同步数据一致的动作称为命令传播 .
(2) master将接收到的数据变更命令发送给slave, slave接收命令后执行命令 。
命令传播阶段出现了断网现象: 网络闪断闪连、 短时间网络中断、 长时间网络中断
部分复制的三个核心要素: 服务器的运行 id、 主服务器的复制积压缓冲区、 主从服务器的复制偏移量
服务器的运行 id:运行id被用于在服务器间进行传输,识别身份,如果想两次操作均对同一台服务器进
行,必须每次操作携带对应的运行id,用于对方识别。
复制缓冲区:当master接收到主客户端的指令时,除了将指令执行,会将该指令存储到缓冲区中 ,是
一个先进先出( FIFO)的队列, 用于存储服务器执行过的命令, 每次传播命令, master都会将传播
的命令记录下来, 并存储在复制缓冲区 。
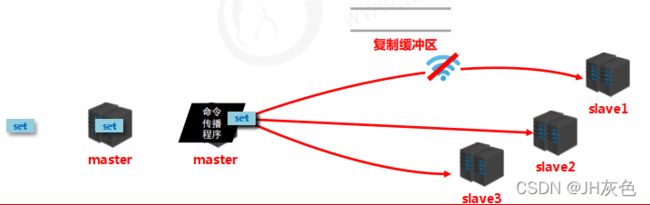
工作原理:
-
通过offset区分不同的slave当前数据传播的差异.
-
master记录已发送的信息对应的offset
-
slave记录已接收的信息对应的offset
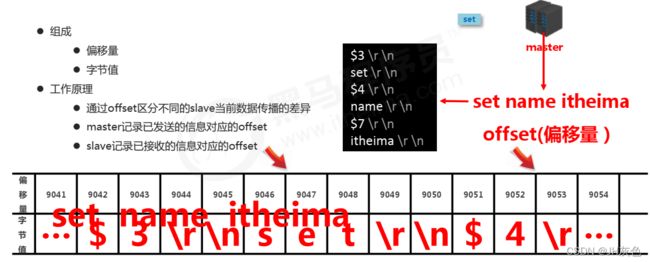
主从服务器的复制偏移量:
master复制偏移量:记录发送给所有slave的指令字节对应的位置(多个)
slave复制偏移量:记录slave接收master发送过来的指令字节对应的位置(一个)
master端:发送一次记录一次
slave端:接收一次记录一次
作用:同步信息,比对master与slave的差异,当slave断线后,再次启动可以恢复数据使用 。
5.2.4 redis主从复制的工作流程
主要包括:全量复制、部分复制、命令传播
1.如果设置了一个slave,无论是第一次连接还是重连到master,他都会发出一个psync2命令;
- 当
master收到`` psync2命令之后,会做两件事: a)master执行bgsave,即在后台保存数据到磁盘(rdb快照文件,因为恢复速度比较快); b)master` 同时将新收到的写入和修改数据集的命令存入缓冲区(非查询类); - 当
master在后台把数据保存到快照文件完成之后,master会把这个快照文件传送给slave,而
slave则把内存清空后,加载该文件到内存中恢复数据; 到这一步是全量复制(RDB快照数据就是) - 而 master 也会把此前收集到缓冲区中的命令,通过Reids命令协议形式转发给 slave , slave 执
行这些命令,实现和 master 的同步; 单独这一步是部分复制(AOF文件重写) - master/slave 此后会不断通过异步方式进行命令的同步,达到最终数据的同步一致;(命令传播
阶段:主服务器master每执行一次写操作,就需要向从服务器slaver同步该命令,保证主从一致。)
主服务器端操作:
1.等待命令进入
2.开始执行BGSAVE,并使用缓冲区记录BGSAVE之后执行的所有写命令
3.BGSAVE执行完毕,向从服务器发送快照文件,并在发送期间继续使用缓冲区记录被执行的写命令
4.快照文件发送完毕,开始向从服务器发送存储在缓冲区里面的写命令
5.缓冲区存储的写命令发送完毕;从现在开始,每执行一个写命令,就向从服务器发送相同的写命令
(命令传播)
从服务器端操作:
1.连接(或者重连接)主服务器,发送SYNC命令
2.根据配置选项来决定是否使用现有的数据(如果有的话)来处理客户端的命令请求,还是向发送请求
的客户端返回错误
3.丢弃所有旧数据(如果有的话),开始载入主服务器发来的快照文件
4.完成对快照文件的恢复操作,像往常一样开始接受命令请求
5.执行主服务器发来的所有存储在缓冲区里面的写命令;并从现在开始接收并执行主服务器传来的每个
写命令
下面这个主从复制的过程非常清晰了:



5.3 主从复制会存在哪些问题呢?
主从复制无法解决单节点故障迁移(即主节点故障,从机无法提供服务)
(1) 频繁的全量复制
(2) 频繁的网络中断
(3) 数据不一致
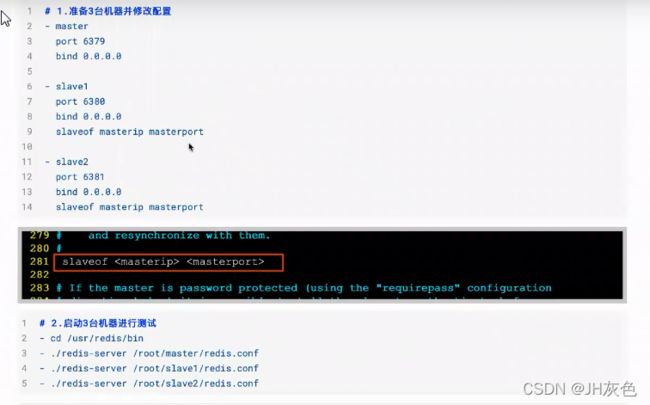
5.4 配置主从复制
在redis.conf中配置
6.Redis消息队列的几种模式
Redis消息队列的4种模式:
-
基于List的 LPUSH+BRPOP 的实现
-
PUB/SUB,订阅/发布模式
-
基于Sorted-Set的实现
-
基于Stream类型的实现
6.1 基于List的 LPUSH+BRPOP 的实现
使用rpush和lpush操作入队列,lpop和rpop操作出队列,保证先进先出的队列规则。
List支持多个生产者和消费者并发进出消息,每个消费者拿到都是不同的列表元素。
但是当队列为空时,lpop和rpop会一直空轮训,消耗资源;所以引入阻塞读blpop和brpop(b代表blocking),阻塞读在队列没有数据的时候进入休眠状态,一旦数据到来则立刻醒过来,消息延迟几乎为零。
注意
你以为上面的方案很完美?还有个问题需要解决:空闲连接的问题。
如果线程一直阻塞在那里,Redis客户端的连接就成了闲置连接,闲置过久,服务器一般会主动断开连接,减少闲置资源占用,这个时候blpop和brpop或抛出异常。
所以在编写客户端消费者的时候要小心,如果捕获到异常,还有重试。
缺点:
- 做消费者确认ACK麻烦,不能保证消费者消费消息后是否成功处理的问题(宕机或处理异常等),通常需要维护一个Pending列表,保证消息处理确认。
- 不能做广播模式,如pub/sub,消息发布/订阅模型
- 不能重复消费,一旦消费就会被删除。相当于Kafka点对点模式
- 不支持分组消费
6.2 PUB/SUB,订阅/发布模式
SUBSCRIBE,用于订阅信道
PUBLISH,向信道发送消息
UNSUBSCRIBE,取消订阅
此模式允许生产者只生产一次消息,由中间件负责将消息复制到多个消息队列,每个消息队列由对应的消费组消费。
优点
- 典型的广播模式,一个消息可以发布到多个消费者
- 多信道订阅,消费者可以同时订阅多个信道,从而接收多类消息
- 消息即时发送,消息不用等待消费者读取,消费者会自动接收到信道发布的消息
缺点
- 消息一旦发布,不能接收。换句话就是发布时若客户端不在线,则消息丢失,不能寻回
- 不能保证每个消费者接收的时间是一致的
- 若消费者客户端出现消息积压,到一定程度,会被强制断开,导致消息意外丢失。通常发生在消息的生产远大于消费速度时
可见,Pub/Sub 模式不适合做消息存储,消息积压类的业务,而是擅长处理广播,即时通讯,即时反馈的业务。
6.3 基于Sorted-Set的实现
Sortes Set(有序列表),类似于java的SortedSet和HashMap的结合体,一方面她是一个set,保证内部value的唯一性,另一方面它可以给每个value赋予一个score,代表这个value的排序权重。内部实现是“跳跃表”。
有序集合的方案是在自己确定消息ID时比较常用,使用集合成员的Score来作为消息ID,保证顺序,还可以保证消息ID的单调递增。通常可以使用时间戳+序号的方案。确保了消息ID的单调递增,利用SortedSet的依据
Score排序的特征,就可以制作一个有序的消息队列了。
优点
就是可以自定义消息ID,在消息ID有意义时,比较重要。
缺点
缺点也明显,不允许重复消息(因为是集合),同时消息ID确定有错误会导致消息的顺序出错。
6.4基于Stream类型的实现
Stream为redis 5.0后新增的数据结构。支持多播的可持久化消息队列,实现借鉴了Kafka设计。
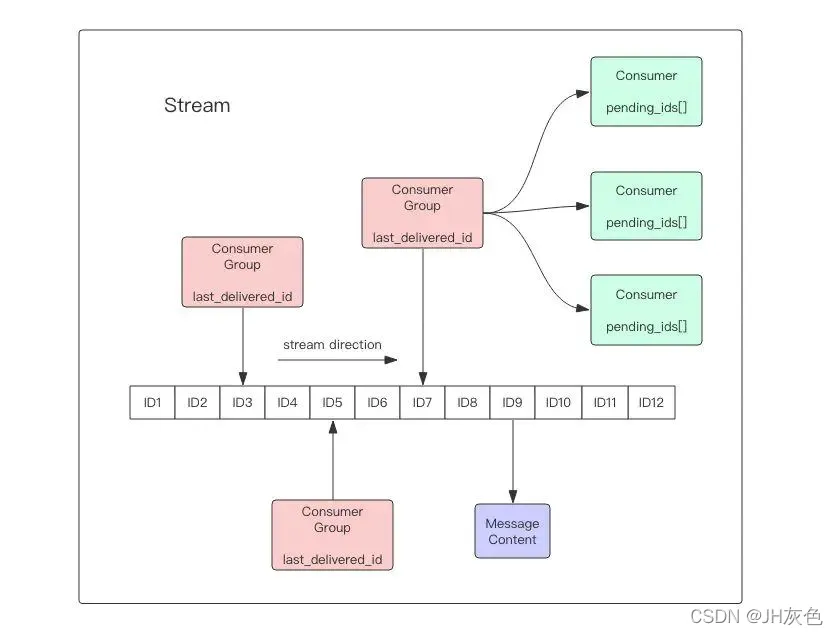
Redis Stream的结构如上图所示,它有一个消息链表,将所有加入的消息都串起来,每个消息都有一个唯一的ID和对应的内容。消息是持久化的,Redis重启后,内容还在。
每个Stream都有唯一的名称,它就是Redis的key,在我们首次使用xadd指令追加消息时自动创建。
每个Stream都可以挂多个消费组,每个消费组会有个游标last_delivered_id在Stream数组之上往前移动,表示当前消费组已经消费到哪条消息了。每个消费组都有一个Stream内唯一的名称,消费组不会自动创建,它需要单独的指令xgroup create进行创建,需要指定从Stream的某个消息ID开始消费,这个ID用来初始化last_delivered_id变量。
每个消费组(Consumer Group)的状态都是独立的,相互不受影响。也就是说同一份Stream内部的消息会被每个消费组都消费到。
同一个消费组(Consumer Group)可以挂接多个消费者(Consumer),这些消费者之间是竞争关系,任意一个消费者读取了消息都会使游标last_delivered_id往前移动。每个消费者者有一个组内唯一名称。
消费者(Consumer)内部会有个状态变量pending_ids,它记录了当前已经被客户端读取的消息,但是还没有ack。如果客户端没有ack,这个变量里面的消息ID会越来越多,一旦某个消息被ack,它就开始减少。这个pending_ids变量在Redis官方被称之为PEL,也就是Pending Entries List,这是一个很核心的数据结构,它用来确保客户端至少消费了消息一次,而不会在网络传输的中途丢失了没处理。
增删改查
- xadd 追加消息
- xdel 删除消息,这里的删除仅仅是设置了标志位,不影响消息总长度
- xrange 获取消息列表,会自动过滤已经删除的消息
- xlen 消息长度
- del 删除Stream
7.Redis消息队列里如果有大量数据进入会怎么样
8.消息队列如何保证可靠消息传输,如何设计消息队列
- 写入时候要求启用事务处理,保证写一定成功。
- redis配置成任何变更一定实时持久化,比如存储端是磁盘的话,每次变更马上同步写入磁盘,才算完成。redis是支持这种方式配置的,但是这么做会使它的内存数据库特性完全消失,性能变得十分低下。
- 消费端也要实现事务方式,处理完成后,再回来真实删除消息。
- 多线程或者多端同时并发处理,可以通过锁的方式来规避。
- 3 4的需求需要自己实现,可以一起考虑,用另外一个队列实现的方式也可以,但是更好的方式是在队列内部实现个计数器。hash格式的加个字段加数值,list的先推一个数值打底,string的头上加个数值再加个分隔符,就可以做个简单计数器了,虽然土,胜在够实用
9.redis 持久化机制
Redis的数据全部存储在内存中,如果突然宕机,数据就会全部丢失,因此需要一套机制来保证redis的数据不会因为故障而丢失。这种机制就是Redis持久化,有RDB和AOF机制。它会将数据库状态保存到磁盘中。
流程图:

9.1持久化流程
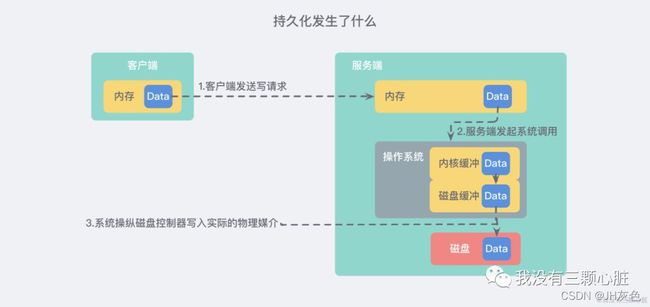
大概有5步流程:
(1)客户端向服务端发送写操作(数据在客户端的内存中)。
(2)数据库服务端接收到写请求的数据(数据在服务端的内存中)。
(3)服务端调用write这个系统调用,将数据往磁盘上写(数据在操作系统内存的缓冲区/内核缓冲区)。
(4)操作系统将内核缓冲区的数据转移到磁盘控制器上(数据在磁盘缓冲区)。
(5)磁盘控制器将数据写到磁盘的物理介质中(数据真正落到磁盘中)。
上述5个过程是在理想的情况下的一个正常持久化过程。但是大多数情况下,机器或者软件都会发生故障,有两种情况:
(1)如果redis数据库发生故障,只要完成前三步即可,在第三步成功返回后,我们就认为成功了,即使进程崩溃,操作系统仍会帮助我们把数据正确写入磁盘。
(2)如果操作系统发生故障( 停电/ 火灾 等 更具灾难性 的事情),那么上面5步都完成才可以。
总结:AOF和RDB

9.2 RDB(数据快照)
RDB其实就是将数据以快照的形式保存到磁盘中。快照可以理解为把某一时刻的数据拍成一张照片存储下来。
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘中。这种方式将内存中的数据以快照形式写入到二进制文件中,默认生成dump.rdb文件代表持久化。
1.RDB的实现有4种机制:save指令、bgsave指令,自动化配置,服务器接收客户端关机指令(shutdown)
(1)save触发方式
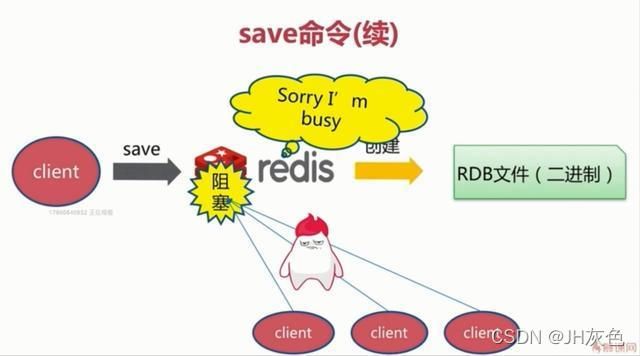
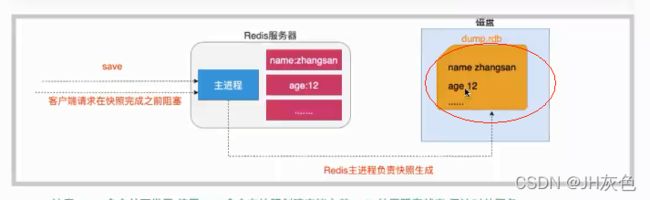
save命令会阻塞当前的redis服务器,因为redis是单线程操作,如果在执行save命令期间,Redis不能处理其他命令,直到RDB过程完成为止。这种方式对于大量的客户端请求来说,可能会造成他们的阻塞,这样等待太耗费时间了。
(2)bgsave触发方式

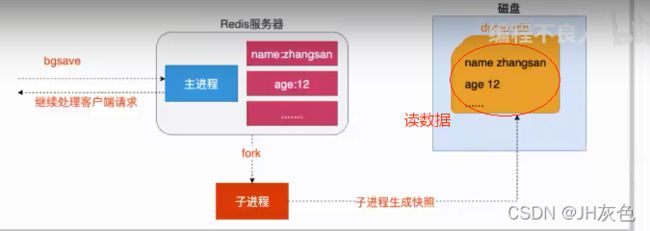
执行bgsave命令时,redis在后台会异步进行快照操作,持久化RDB的同时,还能响应其他客户端的请求。
- 具体操作就是redis在持久化时会调用fork函数创建一个子进程,就是把当前进程复制了一个子进程,父进程和子进程会共享代码块和数据(但是当父进程进行写操作,就不再共享内存数据)。
- 所以快照持久化的过程都会交由子进程去处理,父进程会继续处理其他客户端的请求。子进程处理持久化时,阻塞只发生在fork阶段,但一般时间很短,它不会修改现有的内存数据结构(写命令),只是对数据结构进行遍历读取,然后序列化写到磁盘中。
- 但是父进程不一样,它必须持续服务客户端请求,然后对内存数据结构进行不间断的修改。基本上 Redis 内部所有的RDB操作都是采用 bgsave 命令。

(3)自动化配置触发方式
![]()
在redis.conf配置文件中,里面有如下配置,我们可以去设置:
-
save配置
save second changes(默认配置)在限定时间内key的变化数量达到指定数量就要执行bgsave 持久化。
//表示900 秒内如果至少有 1 个 key 的值变化,则保存save 900 1 save 900 1 //300 秒内如果至少有 10 个 key 的值变化,则保存save 300 10 save 300 10 //60 秒内如果至少有 10000 个 key 的值变化,则保存save 60 10000 save 60 10000 -
stop-writes-on-bgsave-error :默认值为yes。当启用了RDB且最后一次后台保存数据失败,Redis是否停止接收数据
-
rdbcompression :默认值是yes。对于存储到磁盘中的快照,可以设置是否进行压缩存储。
-
rdbchecksum :默认值是yes。在存储快照后,我们还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能。
-
省略
(4) 服务器接收客户端关机指令(shutdown)

上述关机指令后,会通过save指令生成dump.rdb文件进行持久化,之后才会关机,下次开机后还会保存关机前的数据(因为dump.rdb)。注意:这里的shutdown不是宕机和断电,宕机和断电的时刻可能不会立即触发下次持久化(创建dump.rdb文件),所以宕机和断电可能会丢失数据。
2.RDB 的优势和劣势
优势:
(1)RDB文件紧凑,全量备份,非常适合用于进行备份和灾难恢复。
(2)在bgsave命令持久化时,可以异步操作,主进程fork()的子进程会处理快照持久化,主进程继续处理其他客户端请求,主进程不需要进行任何磁盘IO操作。
(3)RDB在恢复大数据集的速度比AOF的恢复速度要快,因为RDB是全量备份,自然全量恢复。
劣势:
(1)在持久化时,子进程不会对内存数据结构进行修改,所以子进程的页面是没有变化的,它是进程刚产生时的一瞬间数据,所以叫快照,像暂停一样。但是父进程会修改数据,在持久化期间修改的数据,子进程不会保存(每次快照持久化有时间差,立即修改的数据不会立刻持久化只能等待下次快照持久化),可能造成数据丢失(当突然宕机时,就会丢失数据)。
(2)bgsave指令每次运行要执行fork操作创建子进程, 要牺牲掉一些性能 。
(3)存储数据量较大,效率较低。基于快照思想,每次读写都是全部数据,当数据量巨大时,效率非常低 。
9.3 AOF(日志,仅追加文件)
全量备份是耗时的,如果不写全部数据,仅记录部分数据,那么可以用AOF记录日志的方式。工作机制很简单,redis会将每一个收到写命令(set/hset/lpush、rpush/sadd/zadd…)的数据都通过write函数追加到文件中,就是append追加,日志记录。
在redis的默认配置中(只开启了RDB快照持久化)AOF持久化机制是没有开启的,需要在配置中开启,如下:redis.conf配置文件
1.AOF持久化原理
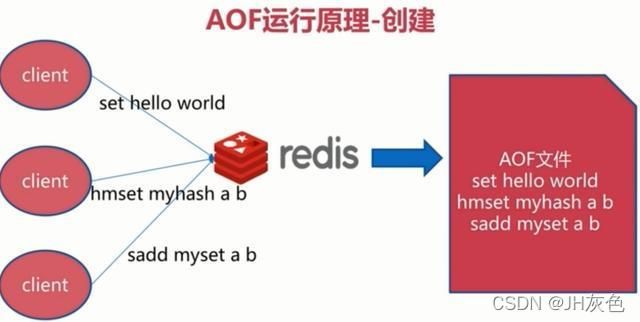
每当有一个写命令过来时,就直接保存在我们的AOF文件中。AOF的主要作用是解决了数据持久化的实时性,目前已经是Redis持久化的主流方式 。
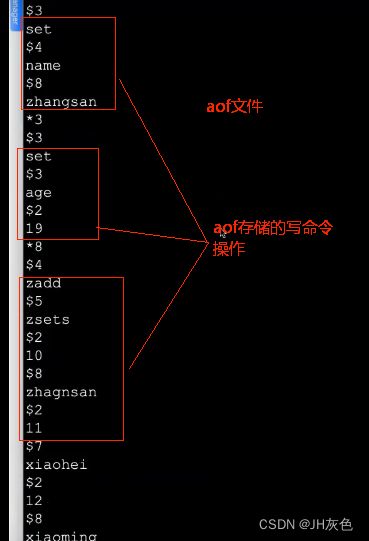
2.AOF文件重写原理
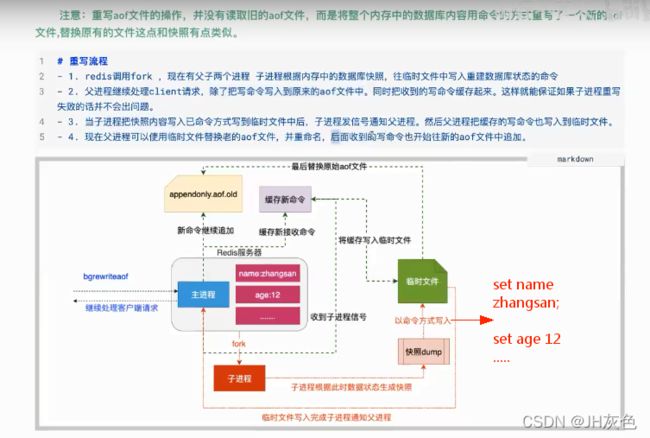
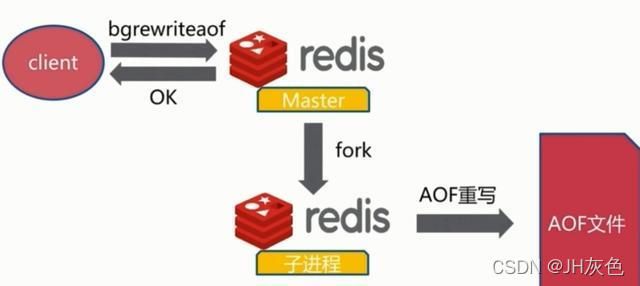
AOF的方式也同时带来一个问题,持久化文件会变得越来越大。为了压缩aof文件,redis提供了bgrewriteaof命令。将内存中的数据以命令的方式保存到临时文件中,同时会fork出一条新进程来将文件重写。重写AOF文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库数据用命令的方式重写了一个新的aof文件,这和快照类似。
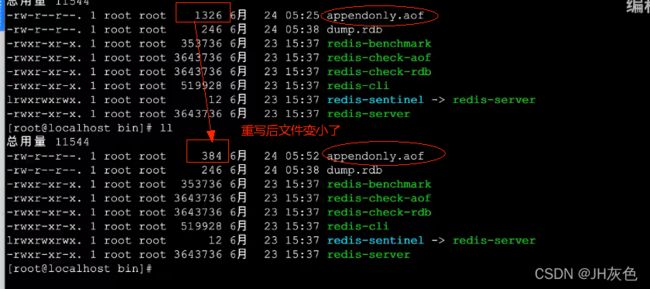
(1)重写方式一:执行bgrewriteaof命令:压缩aof文件
(2)重写方式二:服务器配置方式自动触发
# ① 配置redis.conf中的auto-aof-rewrite-percentage选项
# ② 如果设置auto-aof-rewrite-percentage值为100和auto-aof-rewrite-min-size 64mb,并且启用的AOF持久化时,那么当AOF文件体积大于64mb,并且AOF文件的体积比上一次重写之后体积大了至少一倍(100%)时,会自动触发重写命令,如果重写过于频繁,用户可以考虑将auto-aof-rewrite-percentage设置为更大
如下:
# 64MB--->20MB--->40MB--->18--->36--->26--->52
①第一次大于64MB时,触发`bgrewriteaof`命令重写,之后每次以压缩后的倍数达到设置的倍数后再次重写压缩。
64重写后是20,当达到一倍时(auto-aof-rewrite-percentage:100%)即40MB,再次重写压缩到18,下次到36再次重写压缩到26,到52再重写压缩
参数自行设置:
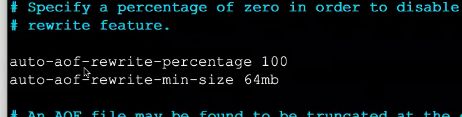
重写作用:
降低磁盘占用量,提高磁盘利用率
提高持久化效率,降低持久化写时间,提高IO性能
降低数据恢复用时,提高数据恢复效率
3、AOF也有三种触发机制

- always(每次)
每次写命令操作均同步到AOF文件中,虽然数据零误差,但是性能低,不建议使用。
- everysec(每秒)
每秒将缓冲区中的写指令同步(追加)到AOF文件中,数据准确性较高,性能较高,建议使用,也是redis默认配置。但是不足处就是在系统宕机时会丢失1秒的数据,这也无足轻重。
- no(系统控制)
由操作系统控制每次同步到AOF文件的周期,整体过程不可控 。

4.AOF 的优势和劣势
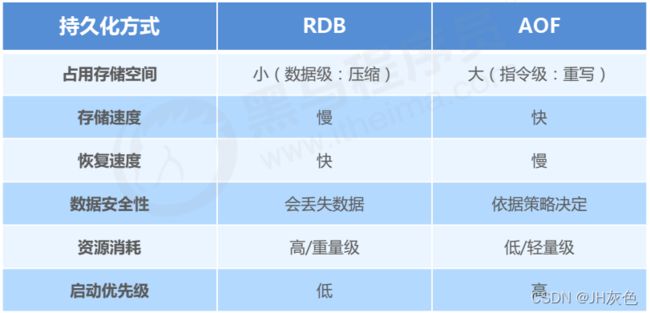
优势:
(1)AOF可以更好的保护数据不丢失,一般AOF会每隔1秒,将写命令从缓冲区同步到AOF文件中,就是执行fsync操作,最多丢失1秒的数据。
(2)AOF日志文件没有任何磁盘寻址的开销,写入性能非常高,文件不容易破损。
(3)AOF日志文件即使过大的时候,出现后台重写操作,也不会影响客户端的读写。
(4)AOF日志文件的命令通过非常可读的方式进行记录,这个特性非常适合做灾难性的误删除的紧急恢复。比如某人不小心用flushall命令清空了所有数据,只要这个时候后台rewrite还没有发生,那么就可以立即拷贝AOF文件,将最后一条flushall命令给删了,然后再将该AOF文件放回去,就可以通过恢复机制,自动恢复所有数据
劣势:
(1)对于同一份数据来说,AOF日志文件通常比RDB数据快照文件更大,因为是指令级别。
(2)AOF开启后,支持的写QPS会比RDB支持的写QPS低,因为AOF一般会配置成每秒fsync一次日志文件,当然,每秒一次fsync,性能也还是很高的。
(3)当AOF恢复数据时,可能存在数据丢失,1秒的丢失,没有恢复一模一样的数据出来。
10.redis集群怎么搭建的
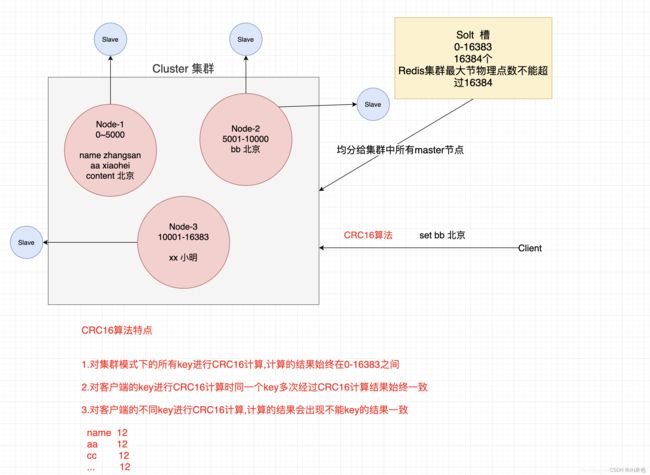
判断一个是集群中的节点是否可用,是集群中的所用主节点选举
过程,如果半数以上的节点认为当前节点挂掉,那么当前节点就
是挂掉了,所以搭建redis集群时建议节点数最好为奇数,搭建
集群至少需要三个主节点,三个从节点,至少需要6个节点。
1.安装ruby环境
yum install ruby
yum install rubygems
2.安装redis gem
gem install redis
遇到问题:
[root@localhost ~]# gem install redis
Fetching: redis-4.1.2.gem (100%)
ERROR: Error installing redis:
redis requires Ruby version >= 2.3.0.
解决方案:先安装rvm,再把ruby版本提升至2.3.0
1.安装curl
yum install curl
2.安装RVM
curl -sSL https://get.rvm.io | bash -s stable
3.安装一个ruby版本
rvm install 2.6.3
可能会报错:执行以下命令
curl -sSL https://rvm.io/mpapis.asc | gpg2 --import -
curl -sSL https://rvm.io/pkuczynski.asc | gpg2 --import -
补充:
1.查看rvm库中已知的ruby版本
rvm list known
2.使用一个ruby版本
rvm use 2.6.3
3.卸载一个已知版本
rvm remove 2.0.0
2.在一台机器上创建如下

3.每个目录复制一份配置文件

4.修改不同目录配置文件
port 6379 ..... //修改端口
bind 0.0.0.0 //开启远程连接
cluster-enabled yes //开启集群模式
cluster-config-file nodes-port.conf //集群节点配置文件
cluster-node-timeout 5000 //集群节点超时时间
appendonly yes //开启AOF持久化
5.指定不同目录配置文件启动七个节点
[root@localhost bin]# ./redis-server /root/7000/redis.conf
[root@localhost bin]# ./redis-server /root/7001/redis.conf
[root@localhost bin]# ./redis-server /root/7002/redis.conf
[root@localhost bin]# ./redis-server /root/7003/redis.conf
[root@localhost bin]# ./redis-server /root/7004/redis.conf
[root@localhost bin]# ./redis-server /root/7005/redis.conf
[root@localhost bin]# ./redis-server /root/7006/redis.conf
6.查看进程
[root@localhost bin]# ps aux|grep redis

10.1 创建集群
1.复制集群操作脚本到bin目录中
[root@localhost bin]# cp /root/redis/src/redis-trib.rb .
2.创建集群
./redis-trib.rb create --replicas 1 192.168.202.205:7000 192.168.202.205:7001 192.168.202.205:7002 192.168.202.205:7003 192.168.202.205:7004 192.168.202.205:7005
10.2 查看集群状态
1.查看集群状态 check [原始集群中任意节点]
./redis-trib.rb check 192.168.202.205:7000
2.集群节点状态说明
主节点
主节点存在hash slots,且主节点的hash slots 没有交叉
主节点不能删除
一个主节点可以有多个从节点
主节点宕机时多个副本之间自动选举主节点
从节点
从节点没有hash slots
从节点可以删除
从节点不负责数据的写,只负责数据的同步
10.3 添加主节点
1.添加主节点 add-node [新加入节点] [原始集群中任意节点]
./redis-trib.rb add-node 192.168.1.158:7006 192.168.1.158:7005
注意:
1.该节点必须以集群模式启动
2.默认情况下该节点就是以master节点形式添加
10.4 添加从节点
1.添加从节点 add-node --slave [新加入节点] [集群中任意节点]
./redis-trib.rb add-node --slave 192.168.1.158:7006 192.168.1.158:7000
注意:
当添加副本节点时没有指定主节点,redis会随机给副本节点较少的主节点
2.为确定的master节点添加主节点 add-node --slave --master-id master节点id [新加入节点] [集群任意节点]
./redis-trib.rb add-node --slave --master-id 3c3a0c74aae0b56170ccb03a76b60cfe7dc1912e 127.0.0.1:7006 127.0.0.1:7000
10.5 删除副本节点
1.删除节点 del-node [集群中任意节点] [删除节点id]
./redis-trib.rb del-node 127.0.0.1:7002 0ca3f102ecf0c888fc7a7ce43a13e9be9f6d3dd1
注意:
1.被删除的节点必须是从节点或没有被分配hash slots的节点
10.6 集群在线分片
1.在线分片 reshard [集群中任意节点]
./redis-trib.rb reshard 192.168.1.158:7000
11.redis的持久化方式,区别?持久化过程时如何保证不会出现新的写覆盖数据?
15.redis zset实现
19.redis 大key问题.
大key问题:大key问题就是存储本身的key值空间太大,或者hash,list,set等存储的value值过多。
主要包括:
1、单个简单的key存储的value很大
2、hash, set,zset,list 中存储过多的元素
3、一个集群存储了上亿的key
带来的问题:
1.读写bigkey会导致超时严重,甚至阻塞服务;
2.大key相关的删除或者自动过期时,会出现QPS(每秒查询率QPS是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准)突降或者突升的情况:,极端情况下,会造成主从复制异常,Redis服务阻塞无法响应请求。bigkey的体积与删除耗时可参考下表:
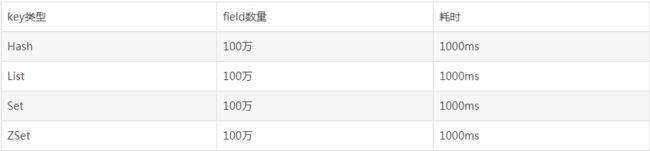
redis 是单线程,操作 bigkey 比较耗时,那么阻塞 redis 的可能性增大。每次获取 bigKey 的网络流量较大,假设一个 bigkey 为 1MB,每秒访问量为 1000,那么每秒产生 1000MB 的流量,对于普通千兆网卡,按照字节算 128M/S 的服务器来说可能扛不住。而且一般服务器采用单机多实例方式来部署,所以还可能对其他实例造成影响。
对于bigkey常用的解决办法:
1、单个简单的key存储的value很大的大key解决
(1)对象需要每次都整存整取
可以尝试将对象分拆成几个key-value, 使用multiGet获取值,这样分拆的意义在于分拆单次操作的压力,将操作压力平摊到多个redis实例中,降低对单个redis的IO影响;
比如一个商品对象,可能包含商品的内容、价格、性能、评价等多种信息,为了避免大key热点数据,可以将商品对象拆分成几个key-value,也可以将对象单个评价按好评、差评、中评拆分几个key-value
(2)该对象每次只需要存取部分数据
可以像第一种做法一样,分拆成几个key-value, 也可以将这个存储在一个hash中,每个field代表一个具体的属性,使用hget,hmget来获取部分的value,使用hset,hmset来更新部分属性
2、 hash, set,zset,list 中存储过多的元素的大key解决
可以对存储元素按一定规则进行分类,分散存储到多个redis实例中。
对于一些榜单类的场景,用户一般只会访问前几百及后几百条数据,可以只缓存前几百条以及后几百条,即对用户经常访问的数据做缓存(正序倒序的前几页),而不是全部都做,对于获取中间的数据则可以直接从数据库获取
3、一个集群存储了上亿的大key的解决
如果key的个数过多会带来更多的内存空间占用,
1.key本身的占用。
2.集群模式中,服务端有时需要建立一些slot2key的映射关系,这其中的指针占用在key多的情况下也是浪费巨大空间。
所以减少key的个数可以减少内存消耗,可以参考的方案是转Hash结构存储,即原先是直接使用Redis String 的结构存储,现在将多个key存储在一个Hash结构中。执行淘汰策略。
20.缓存预热,缓存雪崩,缓存击穿,缓存穿透
-
缓存预热
缓存预热就是将热数据或者频繁使用的数据提前嵌入到redis中,但是不可能将所有数据写入redis中,因为数据量太大,第一太耗费时间,第二redis根本容纳不了太多的数据,因为存入Redis中的key可以设置过期时间的。
解决方案:(1)定时刷新缓存页面或者手动刷新;(2)数据量不大,可以在项目启动的时候自动进行加载。
-
缓存雪崩
缓存雪崩就是在一个较短的时间内,缓存中较多的key集中过期 。比如一个首页所有的key都设置失效时间是12h,它们都是中午12点刷新的,在零点有个秒杀活动,那么当大量的用户请求这些key时,本来可以抗住这些请求,但是当时redis缓存所有的key都失效了。那么这些请求就越过缓存直接去访问数据库,假如同时有上万个请求落入数据库,那么数据库可能就会崩溃,即使数据库立马重启,又会被新来的请求打死。
分析:试想一下,同一时间大面积的数据失效,那么这个redis缓存等于没有,它们会直接越过缓存去访问数据库,那么数据库就是灾难性崩溃。同时如果有其他库关联这个库,那么依赖这个库的所有接口都会报错,即使重启数据库,用户也会不断发新的请求,只有用户不再请求,你才能重启成功。
解决方案:(1)如果非要设置key失效时间,可以把每一个key的失效时间都加一个随机值,这样可以保证数据不会在同一时间大面积失效。(2)如果redis是集群部署,可以将热点数据均匀分布在不同的redis库中也能避免全部失效的问题。(3)还有一种就是设置热点数据永久不过期,有更新操作就更新缓存就好了,这个是比较保险的。(4)LRU与LFU删除策略切换。(5)构建多级缓存,通过增加本地缓存和redis缓存构成,这样就多加了一级屏障,多级缓存同时失效的概率很小。(6)启用限流和降级,限制请求的数量,可以将其他请求的value值设为null或稍后重试等返回。
-
缓存击穿
缓存击穿和缓存雪崩类似,只是缓存击穿是指某一个key非常热点,在不停的并发访问时,如果很多请求对这一个key进行并发访问,当该热点key突然失效,那么大量的请求就会穿过缓存直接访问数据库,而数据库可能会短时间处理不了该请求而崩溃。
解决方案:(1)预先设定:对热点数据延迟失效时间,比如购物节当天和前后几天加大某些热点数据的过期时长。(2)现场调整:监控访问量,对临时激增的数据延长过期时间或者设置永久key。(3)后台刷新数据:启动定时任务,在高峰期来临之前,刷新数据有效期,确保不丢失。(4)分布式锁,防止被击穿,不得已加锁,因为可能会中途锁挂掉,没有释放锁。
-
缓存穿透
缓存穿透是指缓存和数据库中都没有的数据,而用户不断地发起请求,那就会导致穿过缓存到数据库中拿数据,发现数据库也没有数据,这就会造成数据库的压力,严重会使数据库崩溃。
分析:比如我们数据库的数据id都是从1自增开始,如果访问的请求是id<0的多个数据,-1,-2,-4等这些redis缓存和数据库都没有的数据,则这些用户就可能是网站攻击者,蓄意破坏数据库
解决方案:(1)缓存无效key:可以将对应Key的Value数据写为null、位置错误、稍后重试这样的值进行缓存,设定30秒的短时限存活,到期自动清理。(2)白名单策略:通过提前预热数据id对应的bitmaps,id作为offset偏移量(索引值),加载正常数据就是1即放行,加载异常数据即0就拦截。还可以用布隆过滤器进行过滤,效率高点(相当于哈希表查找元素是否存在)。(3)进行校验:可以在接口层增加校验,比如用户权限校验,参数校验,不合法的参数直接代码return,id<0就可以拦截。
21.为什么要用 redis/为什么要用缓存
1.高性能:假如用户第一次访问数据库中的某些数据。这个过程会很慢,因为是从硬盘上读取数据。如果将这些数据放在缓存中,那么下一次用户直接从缓存中拿数据,操作缓存就是操作内存,不需要经历磁盘I/O读写,速度很快。如果数据库中的对应数据改变了,也要同步到缓存中。可以把缓存当作一个数据库。
2.高并发:直接操作缓存可以承受的请求远远大于直接访问数据库,可以把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存里取而不经过数据库。
与传统数据库不同的是 Redis 的数据是 存在内存 中的,所以 读写速度 非常 快,因此 Redis 被广泛应用于 缓存 方向,每秒可以处理超过 10 万次读写操作,是已知性能最快的 Key-Value 数据库
3.使用redis的好处:1)速度快:因为数据以键值对存储在内存中,类似于HashMap,查找元素都是O(1)级别。(2)支持丰富的数据类型:支持string/list/hash/set/zset,还有bitmap,hyperloglog,geo,布隆滤波器。(3)支持事务:redis对事务是部分支持的。如果在入队时报错(语句写错),那么都不会执行;入队时,指命令格式正确,但是无法正确的执行 ,能够正确运行的命令会执行,运行错误的命令不会被执行 。(4)丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除。(5)支持多种语言,java/python/C++
22.redis 和 memcached 的区别
1.redis支持更丰富的数据类型:redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储。而memcached支持简单的数据类型,String。
2.Redis支持数据的持久化:,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而memcached不支持持久化。
3.集群模式:memcached没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是redis目前是原生支持cluster模式的。
4.redis使用单线程的多路IO复用模型,memcached是多线程,非阻塞的IO的网络模型
23.跳跃表(链表)
1.有序列表 zset 的数据结构,它类似于 Java 中的 SortedSet 和HashMap 的结合体,一方面它是一个 set 保证了内部 value 的唯一性,另一方面又可以给每个 value 赋予一个排序的权重值 score,来达到 排序 的目的。它的内部实现就依赖了一种叫做 「跳跃列表」 的数据结构。
2.使用跳跃表的原因:
- 性能考虑: 在高并发的情况下,树形结构需要执行一些类似于 rebalance 这样的可能涉及整棵树的操作,相对来说跳跃表的变化只涉及局部 (下面详细说);
- 实现考虑: 在复杂度与红黑树相同的情况下,跳跃表实现起来更简单,看起来也更加直观;
3.跳跃表的查增删
1)跳跃表的查找:时间复杂度O(logn),和二分查找类似,时间复杂度也一样。
如果查找元素9,元素都是有序的链表。如果遍历查找9需要8次

在上面一层将数变为第一层的一半,那么查找变为第一层遍历的一半了。通过这种方法,我们只需要遍历5次就可以找到元素9了(红色的线为查找路径)。

再减少查询次数,只需要再添加层为上一层的一半(数量),4次就可以找到

当然,还能在增加一层,上面再分层只剩1个数了,就不需要比较了,也没意义,所以分层数最少为2个数
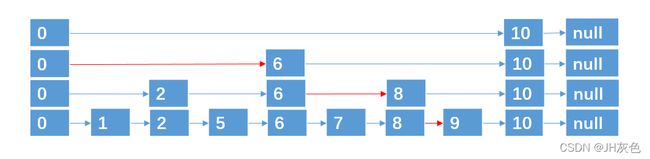
基于这种方法,对于具有 n 个元素的链表,我们可以采取 (logn + 1) 层指针路径的形式,就可以实现在 O(logn) 的时间复杂度内,查找到某个目标元素了,这种数据结构,我们也称之为跳跃表,**跳跃表也可以算是链表的一种变形,只是它具有二分查找的功能。
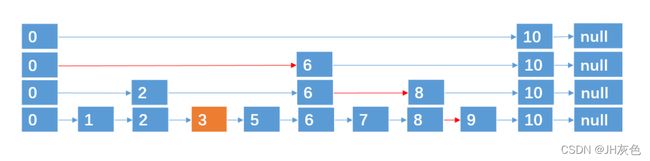
2)跳跃表的插入:根据抛硬币随机的次数,时间复杂度是O(logn),空间复杂度是O(n)
新插入的结点应该跨越多少层
采取的策略是通过抛硬币来决定新插入结点跨越的层数:每次我们要插入一个结点的时候,就来抛硬币,这是随机的次数,如果抛出来的是正面,向上添加,则继续抛,直到出现负面为止,统计这个过程中出现正面的次数,这个正面次数作为结点跨越的层数。
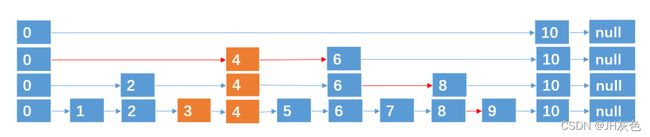
例如,我们要插入结点 3,4,通过抛硬币知道3,4跨越的层数分别为 0,2 (层数从0开始算),则插入的过程如下:
3直接出现“负面”,只能在第一层,跨越0层
插入 4,跨越2层。正面出现了2次
3)跳跃表的删除:时间复杂度O(logn),删除就是把所有层出现的该数字都删除,但是只有2个数的层,一旦删除待删除数字,就把该层剩下的数字也删除。
例如我们要删除4,那我们直接把4及其所跨越的层数删除就行了。
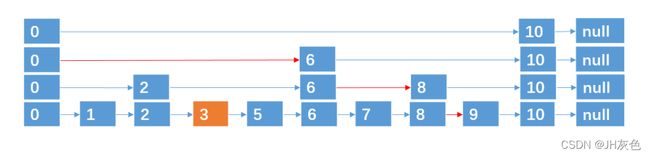
4.跳跃表的性质
(1). 跳跃表的每一层都是一条有序的链表.
(2). 跳跃表的查找次数近似于层数,时间复杂度为O(logn),插入、删除也为 O(logn)。
(3). 最底层的链表包含所有元素。
(4). 跳跃表是一种随机化的数据结构(通过抛硬币来决定层数)。
(5). 跳跃表的空间复杂度为 O(n)。
5.跳跃表与红黑树,跳跃表与二叉树
1)在做范围查找的时候,平衡树比跳跃表操作要复杂。
2)平衡树的插入和删除操作可能引发子树的调整,逻辑复杂,而skiplist的插入和删除只需要修改相邻节点的指针,操作简单又快速。
3)从内存占用上来说,skiplist比平衡树更灵活一些
4)从算法实现难度上来比较,skiplist比平衡树要简单得多。
5)一种特殊情况,当二叉树的子节点均比父节点大时,它会变成一条链表,查询速度就是O(n)级别。
24.redis这么快,为什么是单线程的?
因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。
既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了.
(1) 不需要各种锁的性能消耗
因为redis是单线程操作,就不需要去考虑各种锁问题,不存在加锁和释放锁的问题。不可能出现死锁导致性能消耗。
(2) 避免CPU消耗
采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗CPU。
但是如果CPU成为Redis瓶颈,或者不想让服务器其他CUP核闲置,那怎么办?
可以考虑多开启几个Redis服务器,相当于多个进程了,Redis是key-value数据库,不是关系数据库,数据之间没有约束。而为了减少切换的开销,有必要为每个进程指定其所运行的CPU。
25.redis是单线程的,为什么还这么快
1.redis是将数据存储在内存上的,内存的读写速度非常快,每秒100000次,不受磁盘IO速度的限制。
2.redis是单线程的,省去了很多上下文切换线程的时间;
3.redis使用多路复用技术,可以处理并发的连接。非阻塞IO 内部实现采用epoll,采用了epoll+自己实
现的简单的事件框架。epoll中的读、写、关闭、连接都转化成了事件,然后利用epoll的多路复用特
性,绝不在io上浪费一点时间 。
26.Redis事务
1. redis事务的概念
概念:redis事务就是一个命令执行的队列,当开启事务后,一系列指令就被加入队列,等到执行事务时,从队列中按添加顺序依次执行这些指令(先进先出),中间不会被打断或干扰。
一个队列中,一次性、顺序性、排他性的执行一系列命令
出现的场景:Redis执行指令过程中,多条连续执行的指令被干扰,打断,插队
没有加事务时:客户端A将name=zhangsan, 客户端B将name=lisi,此时
127.0.0.1:6379> set name zhangsan
OK
127.0.0.1:6379> get name
"lisi" -- 明明设置的zhangsan,但是却变成了lisi
127.0.0.1:6379>
添加事务后:开启事务后, 并不会立刻执行这些指令,而是让指令入队,然后一次性的执行:
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set age 18
QUEUED
127.0.0.1:6379> exec -- 这是才会执行事务中的指令,即使此时其他事务过来修改了,也会改回
来 1),比如其他客户端将 set age 24 ,之后执行exec命令还是age=18,这就是隔离性
OK
127.0.0.1:6379> get age
"18"
127.0.0.1:6379>
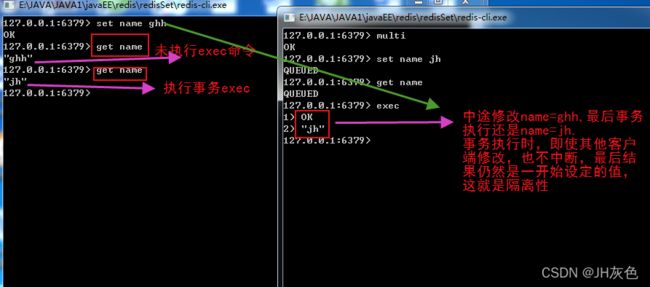
2.redis事务的三个阶段和相关命令
开启事务( multi )、命令入队、执行事务( exec )\放弃执行( discard )。
① 开启事务: multi
设置事务的开启位置,此指令执行后,后续的所有指令均加入到事务中。该命令可以让客户端从非事务
模式状态,变为事务模式状态。
127.0.0.1:6379> multi
OK
② 命令入队:客户端进入事务状态之后,执行的所有常规 Redis 操作命令会依次入列,命令入列成功后
会返回 QUEUED
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set name zhangsan
QUEUED
127.0.0.1:6379> set age 18
QUEUED
127.0.0.1:6379> set weight 34
QUEUED
③ 执行事务: exec / 放弃执行 discard
127.0.0.1:6379> multi -- 开启事务
OK
127.0.0.1:6379> set name zhangsan -- 命令入队
QUEUED
127.0.0.1:6379> set age 18 -- 命令入队
QUEUED
127.0.0.1:6379> exec -- 执行事务
1) OK
2) OK
127.0.0.1:6379> multi -- 开启事务
OK
127.0.0.1:6379> set name lisi -- 命令入队
QUEUED
127.0.0.1:6379> discard -- 放弃执行
OK
127.0.0.1:6379>
3.事务错误
① 语法错误:指命令书写格式有误 处理结果:整体事务中所有命令均不会执行。包括那些语法正确的
命令,会回滚 。
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set name zhangsan
QUEUED
127.0.0.1:6379> sett name lisi
(error) ERR unknown command `sett`, with args beginning with: `name`, `lisi`,
127.0.0.1:6379> exec
(error) EXECABORT Transaction discarded because of previous errors.
② 运行错误:指命令格式正确,但是无法正确的执行。例如对list进行incr操作 处理结果:能够正确运
行的命令会执行,运行错误的命令不会被执行,不会回滚。
127.0.0.1:6379> multi --开启事务
OK
127.0.0.1:6379> set name zhangsan -- 指令正确
QUEUED
127.0.0.1:6379> get name -- 指令正确
QUEUED
127.0.0.1:6379> lpush age 12 13 -- 指令正确
QUEUED
127.0.0.1:6379> sadd name zhangsan -- 指令正确,但是这里的set数据结构的key还是name,与之前Spring一样用相同的key,所以即使指令正确,也不会执行
QUEUED
127.0.0.1:6379> sadd name lisi --不会执行
QUEUED
127.0.0.1:6379> get name
QUEUED
127.0.0.1:6379> exec
1) OK
2) "zhangsan"
3) (integer) 2
4) (error) WRONGTYPE Operation against a key holding the wrong kind of value
5) (error) WRONGTYPE Operation against a key holding the wrong kind of value
6) "zhangsan"
已经执行完毕的命令对应的数据不会自动回滚,需要程序员自己在代码中实现回滚。
4.redis事务支持ACID吗?支持回滚吗
① 隔离性:事务中的所有指令都会序列化,按顺序的执行,事务在执行的过程中,不会被其他客户端送
来的命令请求所打断(exec指令会一次性的按顺序的排他的执行队列中的指令,不会受其他客户端请求
的指令的影响)。redis是单进程,开启事务之后,会执行完当前连接的所有命令直到遇到exec命令,
才处理其他连接的命令。
127.0.0.1:6379> multi -- 开启事务
OK
127.0.0.1:6379> set age 13 -- 指令入队
QUEUED
127.0.0.1:6379> set name lisi -- 指令入队
QUEUED
127.0.0.1:6379> exec -- 将要执行的指令放入队列,一次性的,排他的,按顺序的执
行队列中的指令
1) OK
2) OK
127.0.0.1:6379> get name
"lisi"
127.0.0.1:6379> get age
"13"
127.0.0.1:6379>
② 不满足原子性:当事务发生运行时错误时,事务是不会回滚的,因此不满足原子性。
③ 不支持回滚:Redis的作者在事务功能的文档中解释说,不支持事务回滚是因为这种复杂的功能和
Redis追求简单高效的设计主旨不相符,并且他认为,Redis事务的执行时错误通常都是编程错误产生
的,这种错误通常只会出现在开发环境中,而很少会在实际的生产环境中出现,所以他认为没有必要为
Redis开发事务回滚功能。
27.删除策略
Redis中的数据特征
- Redis是一种内存级数据库,所有数据均存放在内存中,内存中的数据可以通过TTL指令获取其状态
- XX :具有时效性的数据
- -1 :永久有效的数据
- -2 :已经过期的数据 或 被删除的数据 或 未定义的数据
设置过期时间
expire key time (以秒为单位)–这是最常用的方式
setex(String key, int seconds, String value) --字符串独有的方式
注意:
- 除了字符串自己独有设置过期时间的方法外,其他方法都需要依靠expire方法来设置时间
- 如果没有设置时间,那缓存就是永不过期
- 如果设置了过期时间,之后又想让缓存永不过期,使用
persist key
27.1 redis的过期键的删除策略
① 定时删除:在设置 key 的过期时间的同时,为该key创建一个定时器,让定时器在key的过期时间到
达时,立刻执行对键的删除操作。
优点:保证内存被尽快释放
缺点:若过期key很多,删除这些key会占用很多的CPU时间,在CPU时间紧张的情况下,CPU不能把所
有的时间用来做要紧的事儿,还需要去花时间删除这些key。(以时间换空间)
② 惰性删除:key过期的时候不删除,每次从数据库获取key的时候去检查是否过期,若过期则删除,
返回null。如果没有过期,就返回数据。
优点:删除操作只发生在从数据库取出key的时候发生,而且只删除当前key,所以对CPU时间的占用是
比较少的,而且此时的删除是已经到了非做不可的地步(如果此时还不删除的话,我们就会获取到了已
经过期的key了)
缺点:若大量的key在超出超时时间后,很久一段时间内,都没有被获取过,那么可能发生内存泄露
(无用的垃圾占用了大量的内存)(以空间换时间)
③ 定期删除:每隔一段时间执行一次删除过期key操作,周期性轮询redis库中的时效性数据,采用随机
抽取的策略,利用过期数据占比的方式控制删除频度。

redis采用的删除策略:惰性删除+定期删除
所谓定期删除,指的是redis默认是每隔100ms就随机抽取一些设置了过期时间的key,检查其是否过
期,如果过期就删除。注意,这里可不是每隔100ms就遍历所有的设置过期时间的key,那样就是一场
性能上的灾难。实际上redis是每隔100ms随机抽取一些key来检查和删除的。
但是,定期删除可能会导致很多过期key到了时间并没有被删除掉,所以就得靠惰性删除了。这就是
说,在你获取某个key的时候,redis会检查一下 ,这个key如果设置了过期时间那么是否过期了?如果
过期了此时就会删除,不会给你返回任何东西。并不是key到时间就被删除掉,而是你查询这个key的时
候,redis再懒惰的检查一下 。
总结:定期删除是随机抽查、重点抽查,访问时还要执行惰性删除策略,避免这个key没有被定期删除。
27.2 redis的内存淘汰策略
当新数据进入redis时,如果内存不足怎么办?
-
Redis使用内存存储数据,在执行每一个命令前,会调用
freeMemoryIfNeeded()检测内存是否充足。如
果内存不满足新加入数据的最低存储要求, redis要临时删除一些数据为当前指令清理存储空间。清理数据
的策略称为逐出算法。 -
注意:逐出数据的过程不是100%能够清理出足够的可使用的内存空间,如果不成功则反复执行。当对所
有数据尝试完毕后,如果不能达到内存清理的要求,将出现错误信息。(error) OOM command not allowed when used memory >'maxmemory
redis提供8种数据淘汰策略:
-
检测易失数据(可能会过期的数据集server.db[i].expires ) ,下面四种淘汰策略是在设置了过期时间的key中选择
- ①`` volatile-lru`:在设置了过期时间的key中,挑选最近最少使用的数据淘汰
- ②
volatile-lfu:在设置了过期时间的key中,挑选最近使用次数最少的数据淘汰 - ③
volatile-ttl:在设置了过期时间的key中,挑选将要过期的数据淘汰,即选择剩余寿命最短的key将其淘汰 - ④
volatile-random:在设置了过期时间的key中,任意选择数据淘汰 ,随机选择一些key将其淘汰

上图中:LRU淘汰策略选择了age,因为最近最少使用的就是age,是5秒时使用的。LFU选择了gender,因为是最近使用次数最少的,只有1次使用。
-
检测全库数据(所有数据集server.db[i].dict ),下面3种是在所有的key中选择
- ⑤
allkeys-lru:在所有的key中,挑选最近最少使用的数据淘汰 - ⑥
allkeys-lfu:在所有的key中,挑选最近使用次数最少的数据淘汰 - ⑦
allkeys-random:在所有的key中,任意选择数据淘汰,即随机选择一些key淘汰
- ⑤
-
放弃数据驱逐
- ⑧
no-enviction(驱逐):禁止驱逐数据( redis4.0中默认策略),会引发错误OOM( Out Of Memory)
- ⑧
28. redis缓存和数据库双写一致性问题
参考:https://www.lmlphp.com/user/4291/article/item/32463/
要解答这个问题,我们首先来看不一致的几种情况。我将不一致分为三种情况
- 数据库有数据,缓存没有数据;
- 数据库有数据,缓存也有数据,数据不相等;
- 数据库没有数据,缓存有数据。
在讨论这三种情况之前,先说明一下我使用缓存的策略,数据库与缓存读写模式策略(KV+DB读写模
式): 我们使用的缓存策略如下2种
- 读数据时,先从缓存读取,读到数据则直接返回;读不到,就读数据库,并将数据会写到缓存,并
返回。 - 数据变更时(写数据),先更新数据库,然后把缓存里对应的数据失效掉(删掉)。
写完数据库后为什么不是更新缓存而是直接删除缓存?
- 读的逻辑大家都很容易理解,谈谈更新。如果不采取我提到的这种更新方法,你还能想到什么更新
方法呢?大概会是:先删除缓存,然后再更新数据库的缺点。这么做引发的问题是,如果A,B两个线程同
时要更新数据,并且A,B已经都做完了删除缓存这一步,接下来,A先更新了数据库,C线程读取数
据,由于缓存没有,则查数据库,并把A更新的数据,写入了缓存(A的数据),最后B更新数据库(数据库是B的数据)。那么缓存和数据库的值就不一致了。 - 另外有人会问,如果采用你提到的方法,为什么最后是把缓存的数据删掉,而不是把更新的数据写
到缓存里。这么做引发的问题是,如果A,B两个线程同时做数据更新,A先更新了数据库,B后更新
数据库,则此时数据库里存的是B的数据。而更新缓存的时候,是B先更新了缓存,而A后更新了缓
存,则缓存里是A的数据。这样缓存和数据库的数据也不一致。
讨论完使用缓存的策略,我们再来看这三种不一致的情况。
- 对于第一种(数据库有数据,缓存没有数据),在读数据的时候,会自动把数据库的数据写到缓
存,因此不一致自动消除 。 - 对于第二种(数据库有数据,缓存也有数据,数据不相等),数据最终变成了不相等,但他们之前
在某一个时间点一定是相等的(不管你使用懒加载还是预加载的方式,在缓存加载的那一刻,它一
定和数据库一致)。这种不一致,一定是由于你更新数据所引发的。前面我们讲了更新数据的策
略,先更新数据库,然后删除缓存。因此,不一致的原因,一定是数据库更新了,但是删除缓存失
败了。 - 对于第三种(数据库没有数据,缓存有数据),情况和第二种类似,你把数据库的数据删了,但是
删除缓存的时候失败了。
因此,最终的结论是,需要解决的不一致,产生的原因是更新数据库成功,但是删除缓存失败。我想出
的解决方案大概有以下几种:
- 对删除缓存进行重试,数据的一致性要求越高,我越是重试得快。
- 定期全量更新,简单地说,就是我定期把缓存全部清掉,然后再全量加载。
- 给所有的缓存一个失效期。所有的写操作以数据库为准,只要到达缓存过期时间,则后面的读请求自然会从数据库中读取新值然后回填缓存。
第三种方案可以说是一个大杀器,任何不一致,都可以靠失效期解决,失效期越短,数据一致性越高。
但是失效期越短,查数据库就会越频繁。因此失效期应该根据业务来定 。
- 如果严格要求缓存和数据库保持一致,那就只能让读请求和写请求串行化,串到一个内存队列里
去。串行化可以保证一定不会出现不一致的情况,但是它也会导致系统的吞吐量大幅度降低。把一
些列的操作都放到队列里面,顺序肯定不会乱,但是并发高了,这队列很容易阻塞,反而会成为整
个系统的弱点。
29.多个系统同时操作Redis带来的数据问题?(并发竞争key)
方案1:使用redis自身提供的乐观锁watch
方案2:消息队列
在并发量很大的情况下,可以通过消息队列进行串行化处理
方案3:使用分布式锁(zookeeper,redis)+时间戳
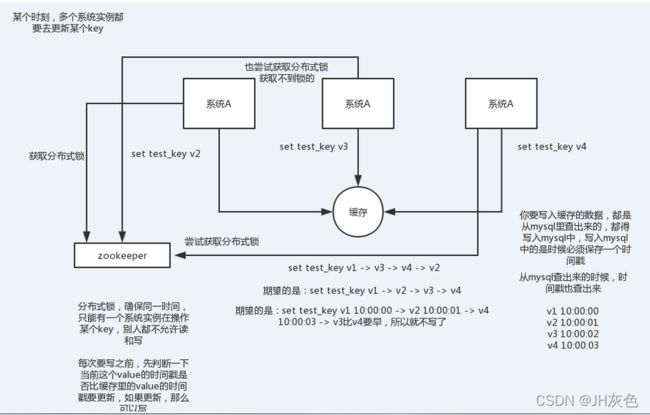
某个时刻,多个系统实例都去更新某个 key。可以基于 zookeeper 实现分布式锁。每个系统通过
zookeeper 获取分布式锁,确保同一时间,只能有一个系统实例在操作某个 key,别人都不允许读和
写。
你要写入缓存的数据,都是从 mysql 里查出来的,都得写入 mysql 中,写入 mysql 中的时候必须保存
一个时间戳,从 mysql 查出来的时候,时间戳也查出来。
每次要写之前,先判断一下当前这个 value 的时间戳是否比缓存里的 value 的时间戳要新。如果是的
话,那么可以写,否则,就不能用旧的数据覆盖新的数据。
30.哨兵有哪些功能?
单机redis的风险与问题:机器故障和容量瓶颈。 为了避免单点Redis服务器故障,准备多台服务器,互
相连通。 将数据复制多个副本保存在不同的服务器上, 连接在一起, 并保证数据是同步的。 即使有其
中一台服务器宕机,其他服务器依然可以继续提供服务(哨兵解决了主从复制不能迁移故障的问题),实现Redis的高可用, 同时实现数据冗余备份。
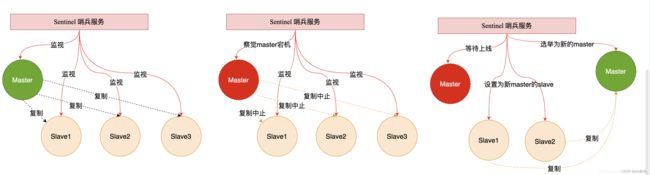
Sentinel(哨兵)是Redis 的高可用性解决方案:由一个或
多个Sentinel 实例 组成的Sentinel 系统可以监视任意多个主服
务器,以及这些主服务器属下的所有从服务器,并在被监视的
主服务器进入下线状态时,自动将下线主服务器属下的某个从
服务器升级为新的主服务器。简单的说哨兵就是带有自动故障转
移功能的主从架构。
无法解决: 1.单节点并发压力问题 2.单节点内存和磁盘物理上限
30.1 哨兵配置

具体操作如下
搭配1主6377 2从节点6378、6379,3个哨兵26377、26378、26379
我把配置文件放在了conf文件夹下
redis6377.conf redis6379.conf sentinel-26378.conf
redis6378.conf sentinel-26377.conf sentinel-26379.conf
下面列出的就是要改的地方
redis6377.conf (主的配置文件)
bind 0.0.0.0 # 表示任何ip都可以连接,这个要开启来,否则远程连接不起作用
port 6377 # redis-server端口号
dir ./data # 这个文件要自己创建,./表示命令所在的目录,比如redis-server这个命令所在目录为/usr/local/redis6377/bin。则./data表示/usr/local/redis6377/bin/data
redis6378.conf(slave从)
bind 0.0.0.0
port 6378
replicaof 192.168.42.137 6377 # 主的IP地址加端口
dir ./data
redis6379.conf (slave从)
bind 0.0.0.0
port 6379
replicaof 192.168.42.137 6377 # 主的IP地址加端口
dir ./data
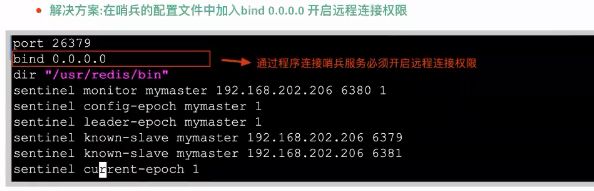
sentinel-26377.conf (哨兵)
port 26377 # 哨兵启动端口
bind: 0.0.0.0 # 开启远程连接
daemonize no # 是否以后台启动
dir ./data
sentinel monitor mymaster 192.168.42.137 6377 2 # mymaster可以随便命令,192.168.42.137 6377 表示主的主机加端口,2表示哨兵选举谁当master时的数量,一般为哨兵数量的一半加1。我这里哨兵为3.所以算出来的值为2,.当有两个及以上的sentinel哨兵服务检测到master宕机,才会去执行主从切换的功能。
sentinel down-after-milliseconds mymaster 30000 # 多长时间没响应算master挂了,这里为30s
sentinel parallel-syncs mymaster 1 # 选取新的master时,一次有多少个开始同步数据,值越小,服务器负担越小
sentinel failover-timeout mymaster 180000 # 同步数据的超时时间,这里为18s
sentinel-26378.conf (哨兵)
port 26378
bind: 0.0.0.0 # 开启远程连接
daemonize no
pidfile /var/run/redis-sentinel.pid
logfile ""
dir ./data
sentinel monitor mymaster 192.168.42.137 6377 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
sentinel-26379.conf (哨兵)
port 26379
bind: 0.0.0.0 # 开启远程连接
daemonize no
pidfile /var/run/redis-sentinel.pid
logfile ""
dir ./data
sentinel monitor mymaster 192.168.42.137 6377 2 #2个哨兵
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
30.2 springboot配置文件 哨兵

参考资料:https://www.ipcpu.com/2019/01/redis-sentinel/
1、概述:
主机宕机出现的问题:关闭期间的数据服务谁来承接?找一个主?怎么找法?修改配置后,原始的主恢
复了怎么办?
假如master宕机了,Redis本身没有实现自动进行主备切换,而Redis-sentinel本身是一个独立运行的
进程,它能监控多个master-slave集群,发现master宕机后能进行自动切换。
哨兵(sentinel) 是一个分布式系统,用于对主从结构中的每台服务器进行监控,当出现故障时通过投票
机制选择新的master并将所有slave连接到新的master。
2、功能:
- 监控 : sentinel 会不断地检查Master和Slave是否运作正常。
- 通知:当被监控的服务器出现问题时, 向其他(哨兵间 sentinel,客户端) 发送通知。
- 自动故障迁移 :当一个Master不能正常工作时,sentinel会开始一次自动故障迁移操作,它
会将失效Master的其中一个Slave升级为新的Master, 并让失效Master的其他Slave改为复制
新的Master; 当客户端试图连接失效的Master时,集群也会向客户端返回新Master的地址,使
得集群可以使用Master代替失效Master。 - 配置中心:如果故障转移发生了,sentinel会返回新的master地址。
3、工作原理:
只使用单个sentinel进程来监控redis集群是不可靠的,当sentinel进程宕掉后,整个集群系统将无法按
照预期的方式运行。所以有必要将sentinel集群。
在Sentinel哨兵的运行阶段,其会向其他的Sentinel哨兵、master和slave发送消息确认其是否存活,如
果在指定的时间内未收到正常回应,暂时认为对方挂起了(被标记为主观宕机–SDOWN)
当多个Sentinel哨兵都报告同一个master没有响应了,通过投票算法(Raft算法),系统判断其已死亡
(被标记为客观宕机–ODOWN)。
此时Sentinel集群会选取领头的哨兵进行故障恢复,从现有slave节点中选出一个提升为Master,并把
剩余Slave都指向新的Master,继续维护主从关系。
31. java整合redis
首先导入jedis依赖
<--导入jedis依赖->
<dependency>
<groupId>redis.clientsgroupId>
<artifactId>jedisartifactId>
<version>2.9.0version>
dependency>
java测试
public class RedisTest {
public static void main(String[] args) {
//连接redis数据库
Jedis jedis = new Jedis("localhost",6379);
//选择连接库(0-15)
jedis.select(0);
//keys * 命令
Set<String> keys = jedis.keys("*");
keys.forEach(key-> System.out.println("key = "+key));
//删除所有库的key
jedis.flushAll();
//jedis.flushDB();
//释放资源
jedis.close();
}
/**
* 结果:
* key = name
* key = class
* key = age
* */
}
5种基本数据类型:命令和redis窗口一致
public class TestKey {
private Jedis jedis;
@Before
public void redisBefore(){
//连接redis数据库
jedis = new Jedis("localhost",6379);
}
@After
public void redisAfter(){
//释放资源
jedis.close();
}
//测试相关key
@Test
public void testKeys(){
jedis.set("name","张三");
System.out.println(jedis.get("name"));//张三
jedis.lpush("stars","胡歌","黎明","成龙","黎明","周杰伦");
//弹出最左的一个值
//System.out.println(jedis.lpop("stars"));//周杰伦
//展示list集合的value值
List<String> lranges = jedis.lrange("stars", 0, -1);
lranges.forEach(v-> System.out.println("v = " + v));
jedis.hset("goodsType","水果","香蕉");
jedis.hset("goodsType","水果","苹果");
System.out.println(jedis.hget("goodsType","水果"));//苹果
//随机获取一个key
System.out.println(jedis.randomKey());//goodsType
//查看指定key是否存在
System.out.println(jedis.exists("goodsType"));//true
//查看value的类型
System.out.println(jedis.type("goodsType"));//hash
}
}
32. SpringBoot整合redis

1.StringRedisTemplate
StringRedisTemplate的默认序列化方式是StringRedisSerializer
//依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
//5种类型
@SpringBootTest
class SpringbootRedisApplicationTests {
@Autowired
private StringRedisTemplate stringRedisTemplate;
/**
* springBoot操作Redis:String类型
*/
@Test
void testString() {//key相同 value后面覆盖前面
stringRedisTemplate.opsForValue().set("nameValue","战三");
stringRedisTemplate.opsForValue().set("nameValue","胡歌");
String nameValue = stringRedisTemplate.opsForValue().get("nameValue");
System.out.println(nameValue);
stringRedisTemplate.opsForValue().set("code","3574",120, TimeUnit.SECONDS);//设置一个key超时时间
stringRedisTemplate.opsForValue().append("nameValue", "他是一好人");
String nameValue1 = stringRedisTemplate.opsForValue().get("nameValue");
System.out.println(nameValue1);
}
@Test
public void testKey(){
Boolean nameValue = stringRedisTemplate.hasKey("nameValue");//1.查询是否存在key
System.out.println("查询是否存在key,nameValue: " + nameValue);
DataType name1 = stringRedisTemplate.type("nameValue");//获取key的类型
System.out.println("获取key的类型name1: " + name1);
Set<String> keys = stringRedisTemplate.keys("*");//获取所有key
keys.forEach(key -> System.out.println("获取所有key = " + key));
Long name2 = stringRedisTemplate.getExpire("nameValue");//获取key的失效时间 -1代表永久有效 -2代表key不存在
System.out.println("name2获取key的失效时间: " + name2);
String randomKey = stringRedisTemplate.randomKey();//获取随机key
System.out.println("获取随机key: " + randomKey);
/*Boolean delateKey = stringRedisTemplate.delete("nameValue");//删除key
System.out.println(delateKey);*/
Boolean renameIfAbsent = stringRedisTemplate.renameIfAbsent("nameValue","nameNew");//仅当 newkey 不存在时,将 oldKey 改名为 newkey
System.out.println("仅当 newkey 不存在时,将 oldKey 改名为 newkey:" + renameIfAbsent);
Boolean move = stringRedisTemplate.move("nameValue", 1);//将key移动到指定库
System.out.println("将key移动到指定库: " + move);
/* JedisConnectionFactory connectionFactory = (JedisConnectionFactory) stringRedisTemplate.getConnectionFactory();
connectionFactory.setDatabase(1);//选择1号数据库*/
/**
查询是否存在key,nameValue: true
获取key的类型name1: STRING
获取所有key = nameNew1
获取所有key = goodsType
获取所有key = nameValue
获取所有key = stars
name2获取key的失效时间: -1
获取随机key: stars
仅当 newkey 不存在时,将 oldKey 改名为 newkey:true
将key移动到指定库: false
* */
}
/**
* springBoot操作Redis:List类型
*/
@Test
public void testList(){//有序可重复
stringRedisTemplate.opsForList().leftPush("names","小明");
stringRedisTemplate.opsForList().leftPushAll("names1","晓明","胡话","黄爸");
ArrayList<String> names2 = new ArrayList<>();
names2.add("胡歌");
names2.add("花花");
stringRedisTemplate.opsForList().leftPushAll("names2",names2);
System.out.println(stringRedisTemplate.opsForList().range("names2", 0, -1));//遍历List
stringRedisTemplate.opsForList().trim("names2",1,3);//截取
System.out.println(stringRedisTemplate.opsForList().range("names2", 0, -1));//遍历List
}
/**
* springBoot操作Redis:Set类型
*/
@Test
void testSet(){//无序不可重复
stringRedisTemplate.opsForSet().add("sets","战三","张三","张三");
System.out.println(stringRedisTemplate.opsForSet().members("sets"));//查看所有成员
System.out.println(stringRedisTemplate.opsForSet().size("sets"));//查看成员数量
/**
*[张三, 战三]
* 2
**/
}
/**
* springBoot操作Redis:Zset类型
*/
@Test
public void testZset(){//有序不可重复
stringRedisTemplate.opsForZSet().add("zsets","语文",90);//创建放入元素
stringRedisTemplate.opsForZSet().add("zsets","数学",100);//创建放入元素
stringRedisTemplate.opsForZSet().add("zsets","数学",120);//创建放入元素,key,value相同,score后面直接覆盖前面
stringRedisTemplate.opsForZSet().add("zset","数学",150);
System.out.println("zsets:" + stringRedisTemplate.opsForZSet().range("zsets", 0, -1));//指定范围查询,不带分数
System.out.println("zset" + stringRedisTemplate.opsForZSet().range("zset", 0, -1));
//获取带分数的zsets
Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet().
rangeByScoreWithScores("zsets", 0, 150);
typedTuples.forEach(typedTuple -> {System.out.println("typedTuple:" + typedTuple.getValue());
System.out.println("typedTuple:" + typedTuple.getScore());});
/**
*zsets:[语文, 数学]
* zset[数学]
* typedTuple:语文
* typedTuple:90.0
* typedTuple:数学
* typedTuple:120.0
*/
}
/**
* springBoot操作Redis:Hash类型
*/
@Test
public void testHash(){
stringRedisTemplate.opsForHash().put("maps","mapName","将军");//创建hash,放入大key、小key、value
HashMap<String, String> map = new HashMap<>();
map.put("age","14");
map.put("bir","2021-10-18");
stringRedisTemplate.opsForHash().putAll("maps",map);//插入map集合
System.out.println(stringRedisTemplate.opsForHash().get("maps", "mapName"));//获取hash中某个小key的value
System.out.println(stringRedisTemplate.opsForHash().values("maps"));//获取所有values
System.out.println(stringRedisTemplate.opsForHash().keys("maps"));//获取所有keys
List<Object> asList = new ArrayList<>();
asList.add("mapName");
asList.add("age");
asList.add("bir");
List<Object> values = stringRedisTemplate.opsForHash().multiGet("maps", asList);
values.forEach(value -> System.out.println(value));
/**
* 将军
* [将军, 2021-10-18, 14]
* [mapName, bir, age]
* 将军
* 14
* 2021-10-18
* */
}
}
注意:使用RedisTemplate默认是将对象序列化到Redis中,所以放入的对象必须实现对象序列化接口(Serializable)
2.RedisTemplate
RedisTemplate默认的序列化方式Jackson2JsonRedisSerializer。
@SpringBootTest
public class RedisTemplateTest {
@Autowired
private RedisTemplate redisTemplate;//存储的key-value可以为对象,但是需要实现序列化
@Test
public void testRedisTemplate(){
//实际业务中,redisTemplate存储的key我们只是想保存为字符串,而value可以为对象,因此需要重新对key进行修改序列化,以StringRedisSerializer序列化,这样就是字符串了
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
//存储的value是对象,所以user对象实体类必须实现序列化
User user = new User();
user.setId("12").setAge(56).setBir(new Date()).setName("jh");
redisTemplate.opsForValue().set("user",user);
System.out.println(redisTemplate.opsForValue().get("user"));
}
}
User(id=12, name=jh, age=56, bir=Sat Nov 27 15:26:38 CST 2021)
3.使用快捷绑定操作,bound api
@Test
public void testBoundApi(){
redisTemplate.setKeySerializer(new StringRedisSerializer());
/**--------------stringRedisTemplate------------------*/
//redisTemplate、stringRedisTemplate 将一个key多次操作进行绑定, 对key进行绑定
BoundValueOperations<String, String> university = stringRedisTemplate.
boundValueOps("university");
//对字符串类型key进行绑定 后续操作都是基于这个key的操作,也就是省略了key
university.set("北京大学");
university.append("中国的好学校");
System.out.println(university.get());//北京大学中国的好学校
/**------------redisTemplate如下--------*/
BoundListOperations boundListOps = redisTemplate.boundListOps("lists");
boundListOps.leftPushAll("张三丰","武当","将军","大人");
System.out.println(boundListOps.range(0, -1));//[大人, 将军, 武当, 张三丰]
}
4.总结:
1.针对处理key value 都是 string 使用 StringRedisTemplate
2.针对处理key value 中存在对象 使用 RedisTemplate
3.针对同一个key多次操作可以使用 boundXxxOps()的api 简化书写,相当于省略了key
33. redis应用场景

34. Redis分布式缓存
-
1.什么是缓存?
定义:就是计算机内存中一段数据 -
2.内存中数据特点
(1)读写快 (2)断电立即丢失 -
3.缓存解决了什么问题?
(1)提高网站吞吐量提高网站运行效率;
(2)核心解决问题:缓存的存在是用来减轻数据库访问压力; -
4.既然存在缓存能提高效率,那项目中所有数据加入缓存岂不是更好?
注意:使用缓存时一定是数据库中数据极少发生修改,更多用于查询这种情况。 -
5.本地缓存和分布式缓存区别:
(1)本地缓存:存在应用服务器内存中数据称之为本地缓存(local cache)
(2)分布式缓存:存储在当前应用服务器内存之外数据称之为分布式缓存(distribution cache),如redis分布式缓存 -
6.利用 mybatis本地缓存 结合 redis实现分布式缓存
a.mybatis中应用级缓存(二级缓存) SqlSessionFactory 级别缓存 所有会话共享;
b. 如何开启(二级缓存)二级缓存是mapper级别的。Mybatis默认是没有开启二级缓存。 下面就是开启二级缓存的步骤 1、 在核心配置文件SqlMapConfig.xml中加入以下内容(开启二级缓存总开关):cacheEnabled设置为 true <settings> <setting name="cacheEnabled" value="true"/> settings> 2、在映射文件中,加入以下内容,开启二级缓存: <mapper namespace="com.jh.dao.UserDao"> <cache/> 3、实现序列化 由于二级缓存的数据不一定都是存储到内存中,它的存储介质多种多样,所以需要给缓存的对象执行序列化。 如果该类存在父类,那么父类也要实现序列化。 @Data public class User implements Serializable { private static final long serialVersionUID = -6115872352203550772L; private Integer age; private String name; private String password; }
(1) mapper.xml
DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.jh.dao.UserDao">
<cache/>
<resultMap id="userMap" type="com.jh.entity.User">
<id column="id" jdbcType="INTEGER" property="id">id>
<result column="username" jdbcType="VARCHAR" property="userName">result>
<result column="password" jdbcType="VARCHAR" property="passWord">result>
<result column="salt" jdbcType="VARCHAR" property="salt">result>
<result column="email" jdbcType="VARCHAR" property="email">result>
<result column="type" jdbcType="INTEGER" property="type">result>
<result column="status" jdbcType="INTEGER" property="status">result>
<result column="activation_code" jdbcType="VARCHAR" property="activationCode">result>
<result column="header_url" jdbcType="VARCHAR" property="headerUrl">result>
<result column="create_time" jdbcType="TIMESTAMP" property="createTime">result>
resultMap>
<sql id="user">
id,username,password,salt,email,type,status,activation_code,header_url,create_time
sql>
<select id="selectUserById" resultType="com.jh.entity.User">
select
<include refid="user"/>
from user
where id = #{id}
select>
mapper>
(2) application.properties
server.port=8089
#redis
spring.redis.host=localhost
spring.redis.port=6379
spring.redis.database=0
# DataSourceProperties
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/community?characterEncoding=utf-8&useSSL=false&serverTimezone=Hongkong
spring.datasource.username=root
spring.datasource.password=root
# ------------MybatisProperties-----------
# 放mapper.xml文件的地方
mybatis.mapper-locations=classpath:com/jh/mapper/*.xml
# 配置化后,可以不用再mapper.xml中写全限定类名,在resultType等如com.jh.entity.User可以直接写User
mybatis.type-aliases-package=com.jh.entity
#自动将数据库id赋值给实体类id(自增主键)
mybatis.configuration.useGeneratedKeys=true
#实体类和数据库别名映射(在mapper中省略起别名),如user_name对应userName(mapper中不用再user_name as userName )
mybatis.configuration.mapUnderscoreToCamelCase=true
#在控制台可以看见sql语句(打印)
logging.level.com.jh.dao=debug
注意:这里碰见一个错误:resources目录下起com.jh.mapper不会逐级展开(需要逐个文件创建),而java目录下可以,这也导致mapper.xml文件绑定dao出错(mybatis.mapper-locations=classpath:com/jh/mapper/*.xml)
Invalid bound statement (not found): com.jh.dao.UserDao.selectUserById
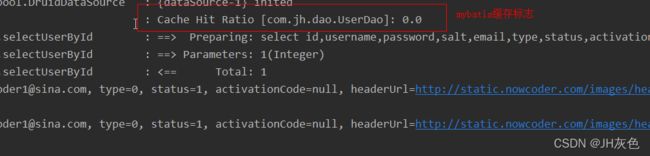
c.查看cache标签缓存实现

<!--开启mybatis的二级缓存-->
<cache type="org.apache.ibatis.cache.impl.PerpetualCache"/>
//结论:mybatis底层默认使用的是PerpetualCache实现
//通过hashMap去存储和获取 数据库数据
private final Map<Object, Object> cache = new HashMap<>();
@Override
public void putObject(Object key, Object value) {
cache.put(key, value);
}
@Override
public Object getObject(Object key) {
return cache.get(key);
}
d.自定义Rediscache分布式缓存实现
(1)通过mybatis默认cache源码得知 可以使用自定义Cache类 implements Cache接口 并对里面的方法进行实现
(2)使用自定义的RedisCache类实现(模仿PerpetualCache)
实现案例:
0 Mapper.xml
//使用自定义的RedisCache进行缓存操作
//①单表,在增删改(更新)操作时删除缓存,操作各自的mapper,但是如果多表关联,那么只能删除一个实体/mapper(表)缓存
<cache type = "com.jh.cache.RedisCache"/>
//②多表关联,避免出现只能删除某一个缓存
<cache-ref type = "com.jh.cache.RedisCache"/>
①Cache(重写Cache方法)
//自定义Redis缓存实现
public class RedisCache implements Cache {
//当前放入缓存的mapper的namespace
private final String id;
//必须存在构造方法
public RedisCache(String id) {
System.out.println("id:=====================> " + id);
this.id = id;
}
//返回cache唯一标识
@Override
public String getId() {
return this.id;
}
//缓存放入值 redis RedisTemplate StringRedisTemplate
@Override
public void putObject(Object key, Object value) {
System.out.println("key:" + key.toString());
System.out.println("value:" + value);
// //通过application工具类获取redisTemplate
// RedisTemplate redisTemplate = (RedisTemplate) ApplicationContextUtils.getBean("redisTemplate");
// redisTemplate.setKeySerializer(new StringRedisSerializer());
// redisTemplate.setHashKeySerializer(new StringRedisSerializer());
//使用redishash类型作为缓存存储模型 key hashkey value
getRedisTemplate().opsForHash().put(id.toString(),getKeyToMD5(key.toString()),value);
if(id.equals("com.cqm.dao.UserDAO")){
//缓存超时 client 用户 client 员工
getRedisTemplate().expire(id.toString(),1, TimeUnit.HOURS);
}
if(id.equals("com.cqm.dao.CityDAO")){
//缓存超时 client 用户 client 员工
getRedisTemplate().expire(id.toString(),30, TimeUnit.MINUTES);
}
//.....指定不同业务模块设置不同缓存超时时间
}
//获取中获取数据
@Override
public Object getObject(Object key) {
System.out.println("key:" + key.toString());
// //通过application工具类获取redisTemplate
// RedisTemplate redisTemplate = (RedisTemplate) ApplicationContextUtils.getBean("redisTemplate");
// redisTemplate.setKeySerializer(new StringRedisSerializer());
// redisTemplate.setHashKeySerializer(new StringRedisSerializer());
//根据key 从redis的hash类型中获取数据
return getRedisTemplate().opsForHash().get(id.toString(), getKeyToMD5(key.toString()));
}
//注意:这个方法为mybatis保留方法 默认没有实现 后续版本可能会实现
@Override
public Object removeObject(Object key) {
System.out.println("根据指定key删除缓存");
return null;
}
@Override
public void clear() {
System.out.println("清空缓存~~~");
//清空namespace
getRedisTemplate().delete(id.toString());//清空缓存
}
//用来计算缓存数量
@Override
public int getSize() {
//获取hash中key value数量
return getRedisTemplate().opsForHash().size(id.toString()).intValue();
}
//封装redisTemplate
private RedisTemplate getRedisTemplate(){
//通过application工具类获取redisTemplate
RedisTemplate redisTemplate = (RedisTemplate) ApplicationContextUtils.getBean("redisTemplate");
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
return redisTemplate;
}
//封装一个对key进行md5处理方法
private String getKeyToMD5(String key){
return DigestUtils.md5DigestAsHex(key.getBytes());
}
}
②由于只使用了mybatis,通过工厂去获取bean对象redisTemplate(这里没有使用spring注入)
//用来获取springboot创建好的工厂
@Component
public class ApplicationContextUtils implements ApplicationContextAware {
//保留下来工厂
private static ApplicationContext applicationContext;
//将创建好工厂以参数形式传递给这个类
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
this.applicationContext = applicationContext;
}
//提供在工厂中获取对象的方法 //RedisTemplate redisTemplate
public static Object getBean(String beanName){
return applicationContext.getBean(beanName);
}
}
③序列化对象 dao
@Data
@Accessors(chain = true)
public class Emp implements Serializable {
private String id;
private String name;
}
@Data
@Accessors(chain = true)
public class User implements Serializable {
private String id;
private String name;
private Integer age;
private Date bir;
}
④service层
//接口
public interface UserService {
List<User> findAll();
User findById(String id);
void delete(String id);
void save(User user);
void update(User user);
}
//接口实现类
@Service
@Transactional
public class UserServiceImpl implements UserService {
@Autowired
private UserDAO userDAO;
@Override
@Transactional(propagation = Propagation.SUPPORTS)
public User findById(String id) {
return userDAO.findById(id);
}
@Override
@Transactional(propagation = Propagation.SUPPORTS)
public List<User> findAll() {
return userDAO.findAll();
}
@Override
public void update(User user) {
userDAO.update(user);
}
@Override
public void save(User user) {
user.setId(UUID.randomUUID().toString());
userDAO.save(user);
}
@Override
public void delete(String id) {
userDAO.delete(id);
}
}