【Redis】掌握篇--Redis与SSM进行整合
Welcome Huihui's Code World ! !
接下来看看由辉辉所写的关于Redis的相关操作吧
目录
Welcome Huihui's Code World ! !
一.Redis与SSM的整合
1.添加Redis依赖
2.spring-redis.xml的相关配置
①注册一个redis.properties
applicationContext
②.配置数据源【连接池】
③.连接工厂
④.配置序列化器
⑤.配置缓存管理器
⑥.配置redis的key生成策略
二.Redis的注解式开发
注解中的常用参数
1.@Cacheable
2.@CachePut
@CachePut与@Cacheable的区别
3.@CacheEvict
三.Redis的击穿、穿透、雪崩
1.击穿
2.穿透
3.雪崩
解决方案
一.Redis与SSM的整合
1.添加Redis依赖
在Maven中添加Redis的依赖
2.9.0 1.7.1.RELEASE redis.clients jedis ${redis.version} 2.spring-redis.xml的相关配置
①注册一个redis.properties
redis.hostName=localhost redis.port=6379 redis.password=123456 redis.timeout=10000 redis.maxIdle=300 redis.maxTotal=1000 redis.maxWaitMillis=1000 redis.minEvictableIdleTimeMillis=300000 redis.numTestsPerEvictionRun=1024 redis.timeBetweenEvictionRunsMillis=30000 redis.testOnBorrow=true redis.testWhileIdle=true redis.expiration=3600但是当spring-context.xml中需要注册多个properties文件,那么我们就不能够直接在spring-*.xml中添加注册,因为这样子的话,只能够读取一个配置文件,另一个配置文件会被覆盖掉,我们可以建一个文件用来专门引入外部文件
applicationContext
classpath:jdbc.properties classpath:redis.properties 那么pom.xml中也需要进行修改,我们现在需要读取到所有的properties文件,所以需要是*.properties文件,而不能够指定是某一个配置文件
src/main/resources *.properties *.xml ②.配置数据源【连接池】
③.连接工厂
④.配置序列化器
⑤.配置缓存管理器
⑥.配置redis的key生成策略
键名的生成规则
package com.zking.ssm.redis; import lombok.extern.slf4j.Slf4j; import org.springframework.cache.interceptor.KeyGenerator; import org.springframework.util.ClassUtils; import java.lang.reflect.Array; import java.lang.reflect.Method; @Slf4j public class CacheKeyGenerator implements KeyGenerator { // custom cache key public static final int NO_PARAM_KEY = 0; public static final int NULL_PARAM_KEY = 53; @Override public Object generate(Object target, Method method, Object... params) { StringBuilder key = new StringBuilder(); key.append(target.getClass().getSimpleName()).append(".").append(method.getName()).append(":"); if (params.length == 0) { key.append(NO_PARAM_KEY); } else { int count = 0; for (Object param : params) { if (0 != count) {//参数之间用,进行分隔 key.append(','); } if (param == null) { key.append(NULL_PARAM_KEY); } else if (ClassUtils.isPrimitiveArray(param.getClass())) { int length = Array.getLength(param); for (int i = 0; i < length; i++) { key.append(Array.get(param, i)); key.append(','); } } else if (ClassUtils.isPrimitiveOrWrapper(param.getClass()) || param instanceof String) { key.append(param); } else {//Java一定要重写hashCode和eqauls key.append(param.hashCode()); } count++; } } String finalKey = key.toString(); // IEDA要安装lombok插件 log.debug("using cache key={}", finalKey); return finalKey; } }
二.Redis的注解式开发
如果我们不使用redis的话,那么我们拿数据就要从数据库拿,但如果数据量过多,或者拿数据的频次过多,则会增加服务器压力,导致运行效率变低,所以我们要考虑减轻服务器的压力,那么我们可以用到redis,要用到redis,就不得不提及一下spring中的redis缓存注解啦,如果你也想将redis用到项目中,那么就看看下面的内容吧
package com.zking.ssm.biz; import com.zking.ssm.model.Clazz; import com.zking.ssm.util.PageBean; import org.springframework.cache.annotation.CacheEvict; import org.springframework.cache.annotation.CachePut; import java.util.List; import java.util.Map; public interface ClazzBiz { int deleteByPrimaryKey(Integer cid); int insert(Clazz record); int insertSelective(Clazz record); Clazz selectByPrimaryKey(Integer cid); int updateByPrimaryKeySelective(Clazz record); int updateByPrimaryKey(Clazz record); ListlistPager(Clazz clazz, PageBean pageBean); List
注解中的常用参数
value 指定缓存的名称,可以是一个或多个缓存名字的数组 key 指定缓存的键值,支持SpEL表达式,用于自定义缓存的键生成策略 condition 指定一个SpEL表达式,用于决定是否要缓存方法的结果 1.@Cacheable
▲@Cacheable是Spring框架提供的注解,它标识的方法会在调用时先从缓存中查找是否存在所需的数据,如果缓存中已存在,直接返回该数据;否则会去调用该方法获取数据并将其缓存起来
@Cacheable主要应用于查询操作,例如查询用户信息、查询文章列表等。通过将查询结果缓存起来,可以减少对数据库的访问压力,提高系统性能
package com.zking.ssm.biz; import com.zking.ssm.model.Clazz; import com.zking.ssm.util.PageBean; import org.springframework.cache.annotation.CacheEvict; import org.springframework.cache.annotation.CachePut; import org.springframework.cache.annotation.Cacheable; import java.util.List; import java.util.Map; public interface ClazzBiz { @Cacheable(value = "xx",key = "'cid:'+#cid",condition = "#cid > 6") Clazz selectByPrimaryKey(Integer cid); }
相应的redis中便会将数据储存起来
2.@CachePut
▲ @CachePut也是Spring框架提供的注解,它标识的方法会同时更新缓存和数据库中的数据。常用于保存、更新操作,例如保存用户信息、更新文章内容等
@CachePut会将方法的返回值写入缓存中,如果已经存在缓存,则会覆盖原来的缓存数据
package com.zking.ssm.biz; import com.zking.ssm.model.Clazz; import com.zking.ssm.util.PageBean; import org.springframework.cache.annotation.CacheEvict; import org.springframework.cache.annotation.CachePut; import org.springframework.cache.annotation.Cacheable; import java.util.List; import java.util.Map; public interface ClazzBiz { @CachePut(value = "xx",key = "'cid:'+#cid",condition = "#cid > 6") Clazz selectByPrimaryKey(Integer cid); }
@CachePut与@Cacheable的区别
- @Cacheable: 使用该注解的方法将会先查询缓存,如果缓存中存在相应的数据,则直接返回缓存中的数据;如果缓存中不存在,则执行方法体,并将方法返回结果存入缓存中
- @Cacheable: 在方法执行之前,会先查找缓存中是否存在相应的数据,如果存在,则直接返回缓存数据;如果不存在,则执行方法体,并将方法返回结果存入缓存中
--------------------------------------------------------------------------------------------------------------------------
- @CachePut: 无论缓存中是否存在相应的数据,都会先执行方法体,并将方法返回结果存入缓存中
- @CachePut: 使用该注解的方法无论如何都会执行方法体,并将方法返回结果存入缓存中,通常用于更新缓存中的数据
总而言之,就是@Cacheable会走缓存,而@CachePu不走缓存,只是更新缓存中的数据
3.@CacheEvict
▲ @CacheEvict是Spring框架提供的注解,它用于删除缓存中的数据。涉及到数据变更的操作(例如添加、删除、修改)时,需要将相应的缓存数据删除,以保证缓存和数据库数据一致
@CacheEvict可以指定要删除的缓存数据的key,或者清除所有缓存数据
package com.zking.ssm.biz; import com.zking.ssm.model.Clazz; import com.zking.ssm.util.PageBean; import org.springframework.cache.annotation.CacheEvict; import org.springframework.cache.annotation.CachePut; import org.springframework.cache.annotation.Cacheable; import java.util.List; import java.util.Map; public interface ClazzBiz { @CacheEvict(value = "xx",key = "'cid:'+#cid") int deleteByPrimaryKey(Integer cid); }清除特定id的缓存
清除缓存后,缓存的数据便没有了

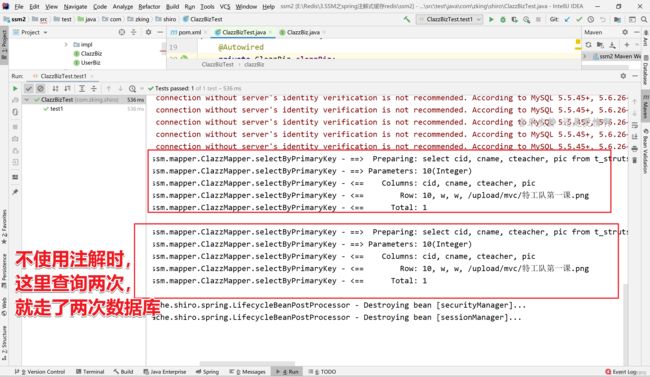





三.Redis的击穿、穿透、雪崩
1.击穿
击穿指的是一个非常热门的数据在缓存中不存在,导致所有的请求都直接到达数据库,从而造成数据库负载过高,甚至可能引起系统崩溃。这种情况常常发生在缓存中设置了过期时间的数据,在数据失效的瞬间,有大量请求同时涌入,导致缓存无法命中并且每个请求都需要去访问数据库
解决方案:
- 使用互斥锁机制:当一个请求发现缓存中不存在时,可以使用互斥锁机制来确保只有一个线程去查询数据库,其他线程等待查询结果。
- 提前异步加载:在缓存过期之前,提前异步加载数据到缓存,避免缓存过期时大量请求同时到达数据库
2.穿透
穿透指的是请求的数据在缓存和数据库中都不存在,这种情况通常是由于恶意请求或者非法请求导致的。这些请求绕过了缓存层直接访问数据库,造成了数据库的压力增加,资源浪费
解决方案:
- 参数校验:在请求到达缓存之前,可以进行参数校验,过滤掉无效的请求。
- 布隆过滤器(Bloom Filter):使用布隆过滤器可以判断一个请求对应的数据是否存在于数据库中,如果不存在则可以直接拦截请求,避免访问数据库
3.雪崩
雪崩指的是缓存中大量的数据同时失效,导致所有请求都直接访问数据库,从而造成数据库负载激增,甚至导致系统崩溃。这种情况可能发生在缓存中的数据设置了相同的过期时间,当过期时间到达时,所有数据同时失效
解决方案:
- 设置不同的过期时间:为不同的缓存数据设置稍有差异的过期时间,避免所有数据同时失效。
- 使用热点数据预加载:通过预先加载一些热门数据到缓存中,来降低缓存同时失效的风险。
- 分布式锁机制:在缓存数据失效时,使用分布式锁机制确保只有一个线程去重新加载缓存,其他线程等待缓存重新加载完成后再读取
解决方案
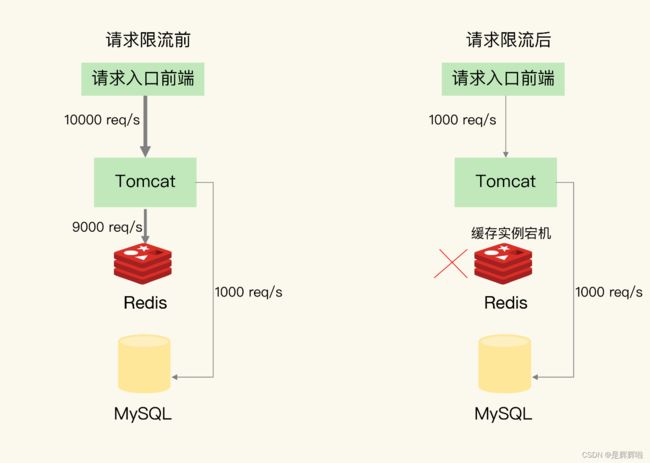
其实上述的这三种问题,都有自己对应的解决方法,但是他们也有一个共同的方法可以解决--限流
在Redis中,限流是一种控制系统访问频率的机制,用于限制对某个资源或服务的并发访问数量,以防止系统过载或被恶意请求攻击。
限流的目的是通过限制请求的速率,保护系统的稳定性和可用性。它可以帮助平衡系统的负载,防止过多的请求同时涌入,导致系统不堪重负。
Redis提供了多种限流的实现方式,其中常用的包括:
令牌桶算法(Token Bucket Algorithm):这种算法基于令牌桶的概念,系统以一定的速率生成令牌放入桶中,每个请求需要获取一个令牌才能执行,当桶中没有足够的令牌时,请求将被阻塞或拒绝。通过调整令牌生成速率和桶的容量,可以控制系统的请求速率。
漏桶算法(Leaky Bucket Algorithm):漏桶算法的原理是,将请求均匀地以固定的速率从一个漏桶中流出,如果请求的速率超过了漏桶的处理能力,多余的请求将被丢弃或延迟处理。漏桶算法可以平滑请求的流量,防止突发的大量请求压垮系统。
计数器和时间窗口:这种实现方式通过统计一段时间内的请求次数,然后与预设的阈值进行比较,从而判断是否超过了访问限制。可以通过Redis的计数器(如INCR)和过期时间设置来实现



好啦,今天的分享就到这了,希望能够帮到你呢!