2023年05月 Python(三级)真题解析#中国电子学会#全国青少年软件编程等级考试

Python等级考试(1~6级)全部真题・点这里
一、单选题(共25题,每题2分,共50分)
第1题
请选择,下面代码运行之后的结果是?( )
a = '2'
b = '4'
try:
c = a * b
print(c)
except:
print('程序出错!')
else:
print('程序正确!')
A: 24
B: 8
C: 程序出错!
D: 程序正确!
答案:C
变量a与b都是字符串,不能进行乘法运算,所以经过异常处理之后,会打印”程序出错!“。
第2题
下面程序执行结果是?( )
a=['春','夏','秋','冬']
c=list(enumerate(a))
print(c)
A: [(0, ‘春’), (1, ‘夏’), (2, ‘秋’), (3, ‘冬’)]
B: [[0, ‘春’], [1, ‘夏’], [2, ‘秋’], [3, ‘冬’]]
C: [(1, ‘春’), (2, ‘夏’), (3, ‘秋’), (4, ‘冬’)]
D: [[1, ‘春’], [2, ‘夏’], [3, ‘秋’], [4, ‘冬’]]
答案:A
enumerate()函数用于将可遍历的数据对象组合为一个索引序列。如果 enumerate(对象),数据下标从0开始;enumerate(对象,start=1),则数据下标从1开始。
第3题
下面程序执行结果是?( )
s='123456789'
print(min(s)+max(s))
A: 1
B: 9
C: 10
D: 19
答案:D
s=‘123456789’,min(s)=‘1’,max(s)=‘9’,所以结果为两个字符串相连,正确答案为:19。
第4题
打开b.txt文件,将"Hello Tom!"写入文件,下列语句正确的是?( )
A: f.write([‘Hello’],[Tom!])
B: f.read(‘Hello’,’ Tom!')
C: f.write(‘Hello Tom!’)
D: f.read(‘Hello Tom!’)
答案:C
A选项中的语法不正确,应该使用字符串拼接来写入内容,例如:f.write(‘Hello’ + ’ Tom!')
B选项中的语法也不正确,read()方法用于读取文件内容,而不是写入内容。同时,read()方法接受一个可选的参数,用于指定读取的字符数。
D选项中的语法也不正确,read()方法用于读取文件内容,而不是写入内容。同时,read()方法不接受参数。
因此,正确的语句是C: f.write(‘Hello Tom!’),它将"Hello Tom!"写入到文件中。
第5题
下列数据中,最大的数值是?( )
A: int(‘16’,10)
B: int(‘110’,2)
C: int(‘11’,16)
D: int(‘1111’,2)
答案:C
A为十进制16,B为十进制6,C为十进制17,D为十进制15。
第6题
十六进制数7E转换为二进制数是几位数?( )
A: 7
B: 6
C: 4
D: 2
答案:A
十六进制转二进制,从低位起,每位十六进制可转换为4位二进制数,合并后最左边的“0”去除。
第7题
表达式int(‘13’,8)的返回值是?( )
A: 12
B: 11
C: 10
D: 15
答案:B
此处int()函数的功能是将八进制的字符串解析成十进制数。可采用按权展开相加法:3×80+1×81=11。
第8题
有如下代码:
res = []
f = open('Python08.txt','r') #Python08.txt中共4行诗句
p = f.readlines()
for s in p:
res.append(s)
print(res)
f.close()
对于该段代码,说法不正确的是?( )
A: 程序的功能是按行读取文本文件中的内容,并将其逐一写入列表res
B: 此处readlines()用法错误,应改成readline()
C: 该文本文件和程序代码文件在同一文件夹下
D: 参数’r’不允许修改该文本文件
答案:B
readline()每次只读取文件的一行,而readlines()是每次按行读取整个文件的内容,返回list类型数据。
第9题
有代码如下:
s=["白日依山尽","黄河入海流","欲穷千里目","更上一层楼"]
f=open('sj.txt','w')
f.write('\n'.join(s))
f.close()
关于上述代码,说法不正确的是?( )
A: 写入文本文件的步骤主要是打开——写入——关闭
B: f.write(‘\n’.join(s))与f.write(’ ‘.join(s)+’\n’)的功能是相同的
C: write()的参数是一个字符串,而writelines()的参数可以是字符串也可以是字符序列
D: 该代码的功能是将列表中的诗句按行写入文本文件
答案:B
f.write(‘\n’.join(s))是将序列s中的元素用换行符连接并写入文件,而f.write(’ ‘.join(s)+’\n’)是将序列中的元素用空格符连接后换行写入文件,结果不一样。
第10题
编写程序代码时,我们经常会犯错,对于Python的异常处理,描述正确的是?( )
A: 可以用if…elif…else…进行异常处理
B: 异常处理可以弥补程序漏洞,让程序在任何情况下都不会终止运行
C: 通过异常处理语句,当程序输入错误时,仍可以让程序继续运行
D: 当遇到错误语句时,将执行try代码块语句
答案:C
Python程序对输入有一定要求,当输入不满足程序要求,可能会产生运行错误,这类错误可以被捕获并合理控制。异常处理不是针对任何错误。发生错误时,将执行except代码块语句。
第11题
若scores=“9,7,8,9,6,5”,则list(scores)的结果是?( )
A: [9,7,8,9,6,5]
B: [‘9’,‘7’,‘8’,‘9’,‘6’,‘5’]
C: [‘9’, ‘,’, ‘7’, ‘,’, ‘8’, ‘,’, ‘9’, ‘,’, ‘6’, ‘,’, ‘5’]
D: 9,7,8,9,6,5
答案:C
list()函数是python内置函数,功能是将序列中的元素转换为列表中的元素,转换中不改变元素的类型,故结果中的数字仍为字符串类型数字,元素包含逗号。
第12题
下列表达式的结果为True的是?( )
A: len(“13”+“4”)>14
B: ord(min(“banana”))<65
C: sum([13,14,16])==53
D: any([“a”,“b”,“”,“d”])
答案:D
len(“13”+“4”)的长度为3,ord(min(“banana”))为97,sum([13,14,16])为43,any()用于判断序列元素是否全为False。
第13题
下列有关于函数的说法,正确的是?( )
A: bool( )函数是一个类型转换函数,用于将给定参数转换为布尔类型,若没有参数,则出错
B: ascii()函数和ord()函数功能都是返回一个数值类型的数据
C: filter()函数用于过滤序列,过滤不符合条件的元素,一般由两个参数组成,即函数和序列
D: map()函数主要用于画地图
答案:C
bool()函数没有参数,则默认返回False。ascii()函数返回的是字符串。map()函数是一个映射函数,主要将参数中的函数作用在参数中的序列的每一个元素上。
第14题
下列表达中,和range(8)的结果相同的是?( )
A: range(0,8)
B: range(1,8)
C: range(0,8,2)
D: range(1,9)
答案:A
range(8)表示产生0~7范围的整数对象,初值默认从0开始,终值取不到。步长省略表示1。
第15题
已知x,y,z=map(int,[‘20’,‘2’,‘3’]),则表达式x+y+z的结果是?( )
A: 程序出错
B: 2023
C: 21
D: 25
答案:D
map()函数表示将函数功能一一应用到对应的序列中,因此字符串’20’,‘2’,'3’分别被转换为三个整数20,2,3,分别赋值给x,y,z三个变量。
第16题
《孙子算经》是我国古代重要的数学著作,其中有一题:“今有物不知其数,三三数之剩二,五五数之剩三,七七数之剩二,问物几何?”小王同学用Python编写了如下程序:
x=1
while x>0:
if not ( ):
x+=1
else:
print(x)
x+=1
关于上述程序,下列说法不正确的是?( )
A: 把第一个x+=1改成break,则程序输出一个结果
B: 括号内应填入的代码是x%3==2 and x%5==3 and x%7==2
C: 该程序是个死循环
D: 该程序将有无穷多个输出
答案:A
当x=1时,if条件取非后满足,执行break,则直接退出循环,程序并没有输出结果。故A错。由于x向上递增,while条件始终满足,故程序将是一个死循环,不断有满足条件的x将被输出。
第17题
下列关于二维数据的描述,正确的是?( )
A: 二维数据就是由两个一维数据组成
B: 二维数据由多个一维数据组成
C: 二维数据的每一个一维数据之间,只能采用逗号进行分隔
D: 二维数据不适合以表格的形式进行存储
答案:B
二维数据由多个一维数据组成,适合以表格的形式进行存储。
第18题
使用open函数打开某个CSV格式文件后,如果要将整个文件里的内容读取到一个列表中,需要使用以下文件对象的哪个函数?( )
A: read()
B: readline()
C: readlines()
D: flush()
答案:C
readlines()支持将整个文件里的内容读取到一个列表中。
第19题
abs()是Python的内置函数,执行abs(-1.00)语句返回的结果是?( )
A: -1.00
B: 1
C: 1.0
D: 1.00
答案:C
abs()函数用于返回一个数的绝对值,因此abs(-1.00)的绝对值是1.00,但由于浮点数的表示方式,结果会显示为1.0。
第20题
divmod()是Python的内置函数。对应变量x和y,divmod(y,x)返回的结果是?( )
A: (x//y, x%y)
B: (x%y, x//y)
C: (y//x, y%x)
D: (y%x,y//x)
答案:C
divmod()函数返回一个包含商和余数的元组,其中商是y除以x的整数部分,余数是y除以x的余数部分。因此,结果是(y//x, y%x)。
第21题
在交互式编程环境下执行a = input(“请输入考试成绩:”)语句后,通过数字键盘输入数值89.5。输入完成后,查看变量a的数据类型,会是下列哪一种?( )
A: float
B: int
C: str
D: bool
答案:C
input()函数始终将用户输入解释为字符串,无论输入的是什么类型的数据。所以,无论输入的是数字还是其他字符,变量a都会被赋值为字符串类型。
第22题
执行print(list(range(4)))语句后,显示的结果是?( )
A: [0,1,2,3]
B: [1,2,3,4]
C: [0,0,0,0]
D: [‘’ ,‘’ ,‘’ ,‘’ ]
答案:A
range(4)函数生成一个包含从0到3(不包括4)的整数序列,而list()函数将该序列转换为列表。因此,打印的结果是[0, 1, 2, 3]。
第23题
暴力破解是一种常见的网络攻击行为,它采用反复试错的方法去尝试破解用户的密码。这种黑客工具主要使用以下哪种算法进行设计?( )
A: 枚举算法
B: 解析算法
C: 排序算法
D: 对分查找算法
答案:A
解析算法是用解析的方法找出表示问题的前提条件与结果之间关系的数学表达式,并通过表达式的计算来实现问题求解。枚举算法的基本思想是把问题所有的解一一罗列出来,并对每一个可能解进行判断,以确定这个可能解是否是问题的真正解。
第24题
对一组数据"6,1,3,2,8"进行排序,按从小到大的顺序进行排列,使用冒泡算法进行编程,则第一轮过后,排序的结果是?( )
A: 1,6,3,2,8
B: 1,3,6,2,8
C: 1,3,2,6,8
D: 1,2,3,6,8
答案:C
冒泡算法的基本思想是:两两比较相邻的数据,如果反序则交换,直到没有反序的数据为止。
第25题
二进制数11110010转换为十六进制数是?( )
A: 1502
B: 152
C: F2
D: F02
答案:C
冒泡算法的基本思想是:两两比较相邻的数据,如果反序则交换,直到没有反序的数据为止。
二、判断题(共10题,每题2分,共20分)
第26题
下列这段代码能够正常运行。对吗?( )
while True :
a = input('请输入一个整数,若不是整数将会让你重新输入: ' )
try:
b = int(a)
except:
print('你输入的不是整数!将返回重输。')
else:
print('你输入的是整数,程序结束。')
break
答案:正确
本代码利用异常处理机制,强制用户必须输入数字,代码能正确运行。应该判断为正确。
第27题
一组有n个元素的数列,如采用顺序查找法找到数列中的某一个元素,平均查找次数为 (n+1)/2 次。( )
答案:正确
最坏找到次数为n次,最好找到次数为1次,因为顺序查找,所以平均找到次数为 (n+1)/2。
第28题
十进制数转十六进制数以后,位数一定变少了。( )
答案:错误
十进制0~9,在十六进制中也是同样的表示,故位数不一定变少。
第29题
二进制数1101011011转换成十六进制数是35B。( )
答案:正确
二进制转十六进制,从低位起,每4位二进制转1位,不足四位,高位补0。
第30题
使用open()方法一定要保证关闭文件对象,即调用close()方法。( )
答案:正确
使用open()方法一定要保证关闭文件对象,即调用close()方法。
第31题
file=open('fruits.csv','r')
name=file.read().strip('\n').split(',')
file.close()
上述代码的功能是读取文件中的数据到列表。( )
答案:正确
本题考查文件读取。read()函数的功能是一次性读取整个文件并生成一个字符串,split()函数是以’,'为分隔符将字符串分割成字符串列表。
第32题
a=['shanghai','beijing','tianjin','chongqing','hangzhou']
with open ('city.csv','w')as f:
f.write(','.join(a)+'\n')
本段代码最后还缺少一条’f.close()'语句以关闭文件。( )
答案:错误
使用with语句打开文件,处理结束后会自动关闭被打开的文件。
第33题
sort()与sorted()函数的区别在于前者默认是升序,后者默认是降序。( )
答案:错误
sort()是列表的方法之一,使用方法是li.sort(),默认升序;sorted()是内建函数,可对所有可迭代对象进行排序,使用方法是sorted(li),默认升序。
第34题
round()函数属于数学函数,可用于近似保留小数位数。( )
答案:正确
round()函数是数学函数,一般情况下可四舍五入保留小数位数。
第35题
sum()函数不仅可以对列表数据进行求和,也可以对元组数据进行求和。( )
答案:正确
sum()函数可以对列表和元组等可迭代对象进行求和操作。无论是列表还是元组,只要元素是可加的,都可以使用sum()函数对其进行求和。
三、编程题(共3题,共30分)
第36题
某班级期中考试成绩汇总在文件“score.csv”中,包含了语文、数学、英语三科的分数,数据内容如下图显示:
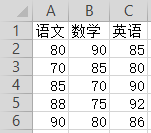
小明编写了如下程序,读取成绩文件中的数据,并分别计算语文、数学、英语三科成绩的平均分,请你补全代码。
import csv
ChineseNum=0
MathNum=0
EnglishNum=0
num=0
with open('/data/score.csv',encoding='utf-8') as csv_file:
row = csv.reader(csv_file, delimiter=',')
next(row) # 读取首行
for r in row:
ChineseNum += float( ① )
MathNum += float( ② )
EnglishNum += float( ③ )
num += ④
print("语文平均成绩是:%.2f"%(ChineseNum/num))
print("数学平均成绩是:%.2f"%(MathNum/num))
print("英语平均成绩是:%.2f"%(EnglishNum/num))
答案:
import csv
ChineseNum = 0
MathNum = 0
EnglishNum = 0
num = 0
with open('/data/score.csv', encoding='utf-8') as csv_file:
row = csv.reader(csv_file, delimiter=',')
next(row) # 读取首行
for r in row:
ChineseNum += float(r[0]) # 补全代码(①)
MathNum += float(r[1]) # 补全代码(②)
EnglishNum += float(r[2]) # 补全代码(③)
num += 1 # 补全代码(④)
print("语文平均成绩是:%.2f" % (ChineseNum / num))
print("数学平均成绩是:%.2f" % (MathNum / num))
print("英语平均成绩是:%.2f" % (EnglishNum / num))
在代码中,我们使用 float() 函数将读取到的分数转换为浮点数类型,并通过索引访问每一行的对应科目的成绩。num 用于记录学生的数量,每读取一行成绩,num 值加一。最后,通过除以 num 来计算每科的平均成绩
第37题
新学期到了,学校接收了一批捐赠的图书,小明编写了一个简单的程序用来管理图书,并支持借阅功能。为了提高查找图书的效率,小明使用了二分查找法来设计图书借阅功能。以下是小明编写的图书借阅管理程序,请你补全代码。
library=dict() #用字典生成一个图书管理数据结构(字典的键为编号,字典的值为['书名',本数])
#书籍入库
nums=len(library) #先计算图书编号总数
library[nums+1]=['红楼梦',5] #在编号总数的基础上继续添加新书:library[新编号]=['书名',本数]
library[nums+2]=['西游记',10]
library[nums+3]=['水浒传',5]
library[nums+4]=['三国演义',10]
print(library)
blist=list(library.keys())
#按书名借阅:
bookname=input('请输入借阅图书名称:')
min_v = blist[0]
max_v = blist[-1]
turns=0
while min_v <= ① :
turns += 1
cur = (min_v + max_v) ②
print(cur)
if library[cur][0] == ③ :
if library[cur][1] > 0:
library[cur][1] -= ④
print('《%s》借阅成功!'%bookname)
else:
print('抱歉,您选择的书籍已被借完!')
break
elif blist[cur-1] > cur:
min_v = ⑤
else:
max_v = ⑥
print("经过%d轮二分查找,完成图书的搜索。"%turns)
答案:
#学校图书管理系统
library=dict() #用字典生成一个图书管理数据结构(字典的键为编号,字典的值为['书名',本数])
#书籍入库
nums=len(library) #先计算图书编号总数
library[nums+1]=['红楼梦',5] #在编号总数的基础上继续添加新书:library[新编号]=['书名',本数]
library[nums+2]=['西游记',10]
library[nums+3]=['水浒传',5]
library[nums+4]=['三国演义',10]
print(library)
blist=list(library.keys())
#按书名借阅:
bookname=input('请输入借阅图书名称:')
min_v = blist[0]
max_v = blist[-1]
turns=0
while min_v <= max_v:
turns += 1
cur = (min_v + max_v) // 2
print(cur)
if library[cur][0]==bookname:
if library[cur][1] > 0:
library[cur][1] -= 1
print('《%s》借阅成功!'%bookname)
else:
print('抱歉,您选择的书籍已被借完!')
break
elif blist[cur -1] > cur:
min_v = cur +1
else:
max_v = cur -1
print("经过%d轮二分查找,完成图书的搜索。"%turns)
在这个程序中,我们先创建了一个图书管理数据结构 library,用字典的键作为图书的编号,值是一个列表,包含书名和图书数量。然后,通过二分查找的方式来查找要借阅的图书。在查找过程中,我们通过不断更新 min_v 和 max_v 来缩小查找范围,直到找到目标图书的编号。然后,我们判断该图书的数量是否大于0,如果是,则将图书数量减1,并输出借阅成功的消息;如果不是,则输出图书已被借完的消息。最后,输出经过的查找轮数。
第38题
某班“天天向上”小组共有6个同学,姓名和身高数据分别存放在列表a中,编写程序实现小组同学按身高从高到低输出名单,运行结果如图所示:

程序代码如下,请在划线处补充完整:
a=[["李洪全",135],["王倩倩",154],["吴乐天",148],["周立新",165],["鲁正",158],["杨颖颖",150]]
for i in range(1,len(a)):
for j in range(0, ① ):
if a[j][1] ② a[j+1][1]:
a[j],a[j+1]=a[j+1],a[j]
print("小组名单是:")
for i in range(len(a)):
print( ③ )
答案:
a=[["李洪全",135],["王倩倩",154],["吴乐天",148],["周立新",165],["鲁正",158],["杨颖颖",150]]
for i in range(1,len(a)):
for j in range(0, len(a)-i):
if a[j][1] < a[j+1][1]:
a[j],a[j+1]=a[j+1],a[j]
print("小组名单是:")
for i in range(len(a)):
print(a[i][0])
本题考查冒泡排序算法。从外循环看,6个元素排5趟,应该能全部排整齐。内循环每趟主要从第一个元素开始,相邻元素两两相比,i=1时,j最终取到4,i=2时,j最终取到3,i=3时,j最终取到2,i=2时,j最终取到1,i=1时,j最终取到0,由于range()的终值是取不到的,故第一空应填len(a)-i;根据题目从高到低的要求,若前一个数小于后一个数,则应将其往后移,故第二空应为”<”;由输出结果观察可知,只需要输出排序后列表中的姓名部分,故第三空应填a[i][0]。