Task3 论文页数图表代码统计
1. 任务说明
- 任务主题:论文代码统计,统计所有论文出现代码的相关统计;
- 任务内容:使用正则表达式统计代码连接、页数和图表数据;
- 任务成果:学习正则表达式统计;`
# 导入所需的package
import seaborn as sns #用于画图
from bs4 import BeautifulSoup #用于爬取arxiv的数据
import re #用于正则表达式,匹配字符串的模式
import requests #用于网络连接,发送网络请求,使用域名获取对应信息
import json #读取数据,我们的数据为json格式的
import pandas as pd #数据处理,数据分析
import numpy as np
import matplotlib.pyplot as plt #画图工具
2. 数据读取
def readArxivFile(path, columns=['id', 'submitter', 'authors', 'title', 'comments', 'journal-ref', 'doi',
'report-no', 'categories', 'license', 'abstract', 'versions',
'update_date', 'authors_parsed'], count=None):
'''
定义读取文件的函数
path: 文件相对路径
columns: 需要选择的列
count: 读取行数(原数据有17万+行)
'''
data = []
with open(path, 'r') as f:
for idx, line in enumerate(f):
if idx == count: # 索引从0开始,所以idx=count-->已经是第count+1条数据
break
# 读取每一行数据
d = json.loads(line) # **关心所有列**--原始的样本:包含所有列的字典形式
d = {col : d[col] for col in columns} # **关心其中某几列**--用字典生成式,key=列名,value=样本中对应列名的值 # 如果需要所有列,直接json.loads就行
#print(d)
data.append(d)
data = pd.DataFrame(data)
return data
data = readArxivFile(path="./data/arxiv-metadata-oai-2019.json",columns = ["id","abstract","categories","comments"])
data.head()
| id | abstract | categories | comments | |
|---|---|---|---|---|
| 0 | 0704.0297 | We systematically explore the evolution of t... | astro-ph | 15 pages, 15 figures, 3 tables, submitted to M... |
| 1 | 0704.0342 | Cofibrations are defined in the category of ... | math.AT | 27 pages |
| 2 | 0704.0360 | We explore the effect of an inhomogeneous ma... | astro-ph | 6 pages, 3 figures, accepted in A&A |
| 3 | 0704.0525 | This paper has been removed by arXiv adminis... | gr-qc | This submission has been withdrawn by arXiv ad... |
| 4 | 0704.0535 | The most massive elliptical galaxies show a ... | astro-ph | 32 pages (referee format), 9 figures, ApJ acce... |
data["comments"][0]
'15 pages, 15 figures, 3 tables, submitted to MNRAS (Low resolution\n version; a high resolution version can be found at:\n http://www.astro.uva.nl/~scyoon/papers/wdmerger.pdf)'
for index,comment in enumerate(data["comments"].head(10)):
print(index,comment) # comments字段中会有具体代码的链接
0 15 pages, 15 figures, 3 tables, submitted to MNRAS (Low resolution
version; a high resolution version can be found at:
http://www.astro.uva.nl/~scyoon/papers/wdmerger.pdf)
1 27 pages
2 6 pages, 3 figures, accepted in A&A
3 This submission has been withdrawn by arXiv administrators due to
inappropriate text reuse from external sources
4 32 pages (referee format), 9 figures, ApJ accepted
5 8 pages, 13 figures
6 5 pages, pdf format
7 30 pages
8 6 pages, 4 figures, Submitted to Physical Review Letters
9 34 pages, 9 figures, accepted for publication in ApJ
3. 统计论文页数–comments字段中的pages
data.info()
RangeIndex: 170618 entries, 0 to 170617
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 170618 non-null object
1 abstract 170618 non-null object
2 categories 170618 non-null object
3 comments 118104 non-null object
dtypes: object(4)
memory usage: 5.2+ MB
3.1 re.findall(pattern, string, flags=0)
Return a list of all non-overlapping matches in the string.
If one or more capturing groups are present in the pattern, return
a list of groups; this will be a list of tuples if the pattern
has more than one group
If no such pattern detected in the string–>return 空list
pages_pattern = "[1-9][0-9]* pages"
re.findall(pages_pattern,"10 pages,11 figures,20 pages") #如果findall有多个匹配,都会放到list里--len就不是1了
['10 pages', '20 pages']
pages_pattern = "[1-9][0-9]* pages" # 匹配至少一位的数字
# 至少是一位数--肯定在1--9的范围内,其他位数的范围就是0-9了,[0-9]* 代表0-9的数字匹配0次/多次(0次:1位数 多次:至少两位数)
re.findall(pages_pattern,data["comments"][0])
['15 pages']
data.comments.apply(lambda x:re.findall(pages_pattern,str(x))).head(10) #保险一点,用str函数进行数据类型的转换--但其实comments这一列都是object类型
# 只显示前10行
0 [15 pages]
2 [6 pages]
4 [32 pages]
5 [8 pages]
8 [6 pages]
...
170594 [9 pages]
170596 [5 pages]
170603 [8 pages]
170604 [88 pages]
170608 [12 pages]
Name: comments, Length: 49690, dtype: object
3.2 抽取出comments字段里面的pages
- 用coln.apply(lambda x: re.findall(pattern,str(x)))
data["pages"] = data.comments.apply(lambda x:re.findall(pages_pattern,str(x)))
data.head()
| id | abstract | categories | comments | pages | |
|---|---|---|---|---|---|
| 0 | 0704.0297 | We systematically explore the evolution of t... | astro-ph | 15 pages, 15 figures, 3 tables, submitted to M... | [15 pages] |
| 1 | 0704.0342 | Cofibrations are defined in the category of ... | math.AT | 27 pages | [27 pages] |
| 2 | 0704.0360 | We explore the effect of an inhomogeneous ma... | astro-ph | 6 pages, 3 figures, accepted in A&A | [6 pages] |
| 3 | 0704.0525 | This paper has been removed by arXiv adminis... | gr-qc | This submission has been withdrawn by arXiv ad... | [] |
| 4 | 0704.0535 | The most massive elliptical galaxies show a ... | astro-ph | 32 pages (referee format), 9 figures, ApJ acce... | [32 pages] |
# pages这一列是object类型,但每个元素是list
3.3 筛选出有pages的论文
(data["pages"].apply(len) > 0)[:10]
0 True
1 True
2 True
3 False
4 True
5 True
6 True
7 True
8 True
9 True
Name: pages, dtype: bool
# 方法一:
# 对pages这一列的每个值(list),运行len函数,再判断是否>0-->得到一列布尔值
(data["pages"].apply(len) > 0)[:10] # 这里的len是在求每个list的长度
0 True
1 True
2 True
3 False
4 True
...
170613 False
170614 False
170615 True
170616 True
170617 True
Name: pages, Length: 170618, dtype: bool
# 方法二:
# 对pages这一列的每个值,运行len是否>0的函数,返回结果已经是布尔值
data.pages.apply(lambda x:len(x)>0)
0 True
1 True
2 True
3 False
4 True
...
170613 False
170614 False
170615 True
170616 True
170617 True
Name: pages, Length: 170618, dtype: bool
# 判断长度是否>0
df.coln.apply(len) > 0 # 结果是一列布尔值 # len函数不需要参数么??
df.coln.apply(lambda x:len(x) > 0) # 结果也是一列布尔值
# 筛选出有pages的论文--直接修改原始数据集
data = data[data["pages"].apply(len) > 0]
data.pages.head(10)
0 [15 pages]
1 [27 pages]
2 [6 pages]
4 [32 pages]
5 [8 pages]
6 [5 pages]
7 [30 pages]
8 [6 pages]
9 [34 pages]
10 [4 pages]
Name: pages, dtype: object
3.4 从列表包含的字符串中提取出想要的数字
- 由于re.findall的结果是个list eg:[“15 pages”]–要从中提取出15这个数字
data.pages[0][0]
'15 pages'
re.match(r"([1-9][0-9]*)",data.pages[0][0]).group(1)
'15'
# 方法一:用x[0]提取出list中的string;用正则表达式提取出pages的数字部分--结果是string!
data.pages.apply(lambda x:re.match(r"([1-9][0-9]*)",x[0]).group(1))[:10] # x--是pages这一列的每个元素:list;x[0] -- string
# 只显示前10
0 15
1 27
2 6
4 32
5 8
6 5
7 30
8 6
9 34
10 4
Name: pages, dtype: object
# 方法二:# 用x[0]提取出list中的string;将" pages"(数字后面的所有)替换成空-->这样就只有数字存在了--结果也是string
data.pages[0][0].replace(" pages","")
'15'
data.pages.apply(lambda x:int(x[0].replace(" pages","")))[:10] # lambda匿名函数的参数是x--list,要用x[0]取出里面的string 才能进行str.replace
0 15
1 27
2 6
4 32
5 8
6 5
7 30
8 6
9 34
10 4
Name: pages, dtype: int64
data["pages"] = data.pages.apply(lambda x:int(x[0].replace(" pages",""))) # 用int函数转换数据类型从string-->int
data.info()
Int64Index: 80696 entries, 0 to 170617
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 80696 non-null object
1 abstract 80696 non-null object
2 categories 80696 non-null object
3 comments 80696 non-null object
4 pages 80696 non-null int64
dtypes: int64(1), object(4)
memory usage: 3.7+ MB
data.pages.describe()
count 80696.000000
mean 18.965872
std 20.377207
min 1.000000
25% 9.000000
50% 14.000000
75% 24.000000
max 1958.000000
Name: pages, dtype: float64
data.pages.describe(percentiles=[0.1,0.25,0.5,0.75,0.85,0.9,0.95,0.99]).astype(int) # pages右偏很严重
count 80696
mean 18
std 20
min 1
10% 6
25% 9
50% 14
75% 24
85% 30
90% 36
95% 46
99% 81
max 1958
Name: pages, dtype: int32
3.5 由于右偏–这里只考虑pages前99%的数据
data_no_outlier = data[data.pages<81] # 这里不考虑99%分位数以上的数
data_no_outlier.head()
| id | abstract | categories | comments | pages | |
|---|---|---|---|---|---|
| 0 | 0704.0297 | We systematically explore the evolution of t... | astro-ph | 15 pages, 15 figures, 3 tables, submitted to M... | 15 |
| 1 | 0704.0342 | Cofibrations are defined in the category of ... | math.AT | 27 pages | 27 |
| 2 | 0704.0360 | We explore the effect of an inhomogeneous ma... | astro-ph | 6 pages, 3 figures, accepted in A&A | 6 |
| 4 | 0704.0535 | The most massive elliptical galaxies show a ... | astro-ph | 32 pages (referee format), 9 figures, ApJ acce... | 32 |
| 5 | 0704.0710 | Differential and total cross-sections for ph... | nucl-ex | 8 pages, 13 figures | 8 |
plt.figure(figsize=(10, 6))
plt.hist(data_no_outlier.pages); # 即使过滤掉extreme case: pages整体还是右偏的趋势--85%的论文页数在0-30之间
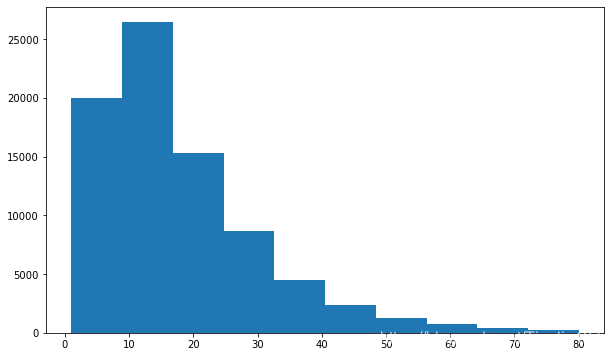
对pages进行统计,统计结果如下: 论文平均页数为18,最少1页,最多1958页,75%的论文页数在24页以内
4. 按照分类统计论文页数
- 这里为了简单:只看论文第一个类别的主要类别(默认类别是按照相关性从高到低排序的 所以第一个类别和论文的相关性最高)
data.categories[1].split(' ')[0]
'math.AT'
first_cat = data.categories.apply(lambda x:x.split(" ")[0]) # 取类别字段中的第一个类别--str.split(空格)--结果是list,取出第一个
first_cat.head(10)
0 astro-ph
1 math.AT
2 astro-ph
4 astro-ph
5 nucl-ex
6 quant-ph
7 math.DG
8 hep-ex
9 astro-ph
10 hep-ex
Name: categories, dtype: object
first_cat[1].split(".")[0]
'math'
data["categories"] = first_cat.apply(lambda x: x.split(".")[0])
# 取出第一个类别的主要类别--.前面的部分
data.groupby("categories")["pages"].mean().sort_values() # 每个主要类别的论文平均页数 # 并按照mean从小到大排序
categories
chem-ph 4.000000
cmp-lg 6.500000
acc-phys 8.500000
comp-gas 9.000000
nucl-ex 9.468104
dg-ga 10.500000
chao-dyn 10.888889
hep-ex 11.158023
eess 11.503799
cond-mat 13.790076
patt-sol 14.000000
nucl-th 14.730808
cs 15.143570
quant-ph 15.302526
hep-lat 15.905822
physics 16.032428
astro-ph 16.369079
nlin 17.575139
gr-qc 18.852640
hep-ph 19.230494
alg-geom 20.000000
q-bio 20.473860
q-fin 24.691877
stat 24.817099
math 25.805516
adap-org 26.333333
q-alg 27.333333
hep-th 27.607584
solv-int 27.666667
math-ph 28.016901
econ 28.618056
Name: pages, dtype: float64
plt.figure(figsize=(12,6))
data.groupby("categories")["pages"].mean().sort_values().plot(kind="barh");
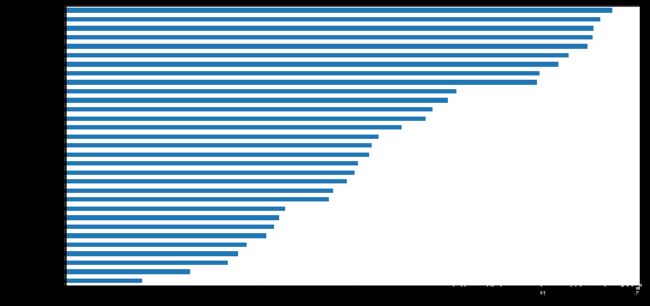
- 单从论文平均页数来看:最多的类别是经济econ;其次是Mathematical Physics(math-ph)
# 只看论文平均页数top5的类别--画箱线图: 是否存在偏态
top5_cat = data.groupby("categories")["pages"].mean().sort_values().tail(5).index
top5_cat # index类型
Index(['q-alg', 'hep-th', 'solv-int', 'math-ph', 'econ'], dtype='object', name='categories')
top5_cat.values # array数组类型
array(['q-alg', 'hep-th', 'solv-int', 'math-ph', 'econ'], dtype=object)
data.categories.isin(top5_cat).head(10) # 查看某一列的值是否在一个list/array中--如果在:返回True
0 False
2 False
4 False
5 False
8 False
9 False
10 False
12 False
15 False
16 False
Name: categories, dtype: bool
top5_data = data[data.categories.isin(top5_cat.values)]
top5_data.head()
| id | abstract | categories | comments | pages | |
|---|---|---|---|---|---|
| 30 | 0704.2912 | In distinction to the Neumann case the squee... | math-ph | LaTeX, 16 pages | 16 |
| 44 | 0705.0646 | Intersecting stacks of supersymmetric fracti... | hep-th | 8 pages, no figures | 8 |
| 56 | 0705.1407 | We consider Schr\"odinger operator in dimens... | math-ph | LaTeX 2e, 12 pages | 12 |
| 60 | 0705.1641 | For the complex Clifford algebra Cl(p,q) of ... | math-ph | 39 pages | 39 |
| 78 | 0705.2487 | In this paper we attempt to reconstruct one ... | math-ph | LaTeX, 9 pages; in memoriam Vladimir A. Geyler... | 9 |
sns.boxplot(x=top5_data.categories,y=top5_data.pages);
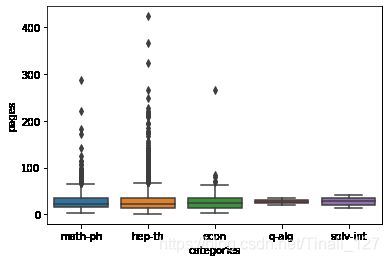
- 可以看出math-ph(Mathematical Physics) 和 hep-th(High Energy Physics - Theory)的论文页数偏大的值特别多(异常值特别多)
- 反而平均页数最多的类别econ的异常值很少–说明平均页数多是因为整体论文页数都多,而不是因为存在很多异常值拉高了平均水平
5. 统计论文图表个数–comments字段里面的figures
figure_pattern = r"[1-9][0-9]* figures"
# 从comments字段中抽取符合pattern的部分
data["figures"] = data.comments.apply(lambda x:re.findall(figure_pattern,str(x)))
# 筛选出figures>0的论文
data = data[data["figures"].apply(len) > 0]
# 从列表中抽取str抽取想要的数字--string类型 要用float进行转换
data["figures"] = data["figures"].apply(lambda x:float(x[0].replace(" figures","")))
data.head()
| id | abstract | categories | comments | pages | figures | |
|---|---|---|---|---|---|---|
| 0 | 0704.0297 | We systematically explore the evolution of t... | astro-ph | 15 pages, 15 figures, 3 tables, submitted to M... | 15 | 15.0 |
| 2 | 0704.0360 | We explore the effect of an inhomogeneous ma... | astro-ph | 6 pages, 3 figures, accepted in A&A | 6 | 3.0 |
| 4 | 0704.0535 | The most massive elliptical galaxies show a ... | astro-ph | 32 pages (referee format), 9 figures, ApJ acce... | 32 | 9.0 |
| 5 | 0704.0710 | Differential and total cross-sections for ph... | nucl-ex | 8 pages, 13 figures | 8 | 13.0 |
| 8 | 0704.1000 | We report a measurement of D0-D0bar mixing i... | hep-ex | 6 pages, 4 figures, Submitted to Physical Revi... | 6 | 4.0 |
data.figures.describe(percentiles=[0.1,0.25,0.5,0.75,0.85,0.9,0.95,0.99]).astype("int")
count 49690
mean 7
std 23
min 1
10% 3
25% 4
50% 6
75% 10
85% 12
90% 15
95% 19
99% 33
max 4989
Name: figures, dtype: int32
- 很明显figures图片也是右偏的
- 最小值=1,最大值快5K,90%的论文包含的图片个数都是15个以下
6. 最后对论文的代码链接进行提取–判断这篇论文有无代码链接
- 为了简化:只考虑github链接
# 筛选包含github的论文
data_with_code = data[
(data.comments.str.contains('github'))|
(data.abstract.str.contains('github'))
]
# 可以不写str.contains() == True:因为str.contains()的返回结果已经是T/F了 如果包含github这个子字符串,则返回True
# comments/abstract的关系是或 | 二者有一个包含github就可以
data_with_code.isnull().mean()
id 0.0
abstract 0.0
categories 0.0
comments 0.0
pages 0.0
figures 0.0
dtype: float64
data_with_code['text'] = data_with_code['abstract'].fillna('') + data_with_code['comments'].fillna('')
# 将abstract列和comments列进行拼接
# 如果这两列有空值NaN的地方,填补为空
# 但according to isnull().mean()的结果--这两列都没有空值;实际操作是这两列拼接起来
data_with_code.reset_index(inplace=True) # 进行了行的筛选之后always 重置索引
data_with_code.text[0]
" Bayesian inference involves two main computational challenges. First, in\nestimating the parameters of some model for the data, the posterior\ndistribution may well be highly multi-modal: a regime in which the convergence\nto stationarity of traditional Markov Chain Monte Carlo (MCMC) techniques\nbecomes incredibly slow. Second, in selecting between a set of competing models\nthe necessary estimation of the Bayesian evidence for each is, by definition, a\n(possibly high-dimensional) integration over the entire parameter space; again\nthis can be a daunting computational task, although new Monte Carlo (MC)\nintegration algorithms offer solutions of ever increasing efficiency. Nested\nsampling (NS) is one such contemporary MC strategy targeted at calculation of\nthe Bayesian evidence, but which also enables posterior inference as a\nby-product, thereby allowing simultaneous parameter estimation and model\nselection. The widely-used MultiNest algorithm presents a particularly\nefficient implementation of the NS technique for multi-modal posteriors. In\nthis paper we discuss importance nested sampling (INS), an alternative\nsummation of the MultiNest draws, which can calculate the Bayesian evidence at\nup to an order of magnitude higher accuracy than `vanilla' NS with no change in\nthe way MultiNest explores the parameter space. This is accomplished by\ntreating as a (pseudo-)importance sample the totality of points collected by\nMultiNest, including those previously discarded under the constrained\nlikelihood sampling of the NS algorithm. We apply this technique to several\nchallenging test problems and compare the accuracy of Bayesian evidences\nobtained with INS against those from vanilla NS.\n28 pages, 6 figures, 2 tables. Accepted for publication in The Open\n Journal of Astrophysics. Code available from\n https://github.com/farhanferoz/MultiNest/"
data_with_code.abstract[0]
" Bayesian inference involves two main computational challenges. First, in\nestimating the parameters of some model for the data, the posterior\ndistribution may well be highly multi-modal: a regime in which the convergence\nto stationarity of traditional Markov Chain Monte Carlo (MCMC) techniques\nbecomes incredibly slow. Second, in selecting between a set of competing models\nthe necessary estimation of the Bayesian evidence for each is, by definition, a\n(possibly high-dimensional) integration over the entire parameter space; again\nthis can be a daunting computational task, although new Monte Carlo (MC)\nintegration algorithms offer solutions of ever increasing efficiency. Nested\nsampling (NS) is one such contemporary MC strategy targeted at calculation of\nthe Bayesian evidence, but which also enables posterior inference as a\nby-product, thereby allowing simultaneous parameter estimation and model\nselection. The widely-used MultiNest algorithm presents a particularly\nefficient implementation of the NS technique for multi-modal posteriors. In\nthis paper we discuss importance nested sampling (INS), an alternative\nsummation of the MultiNest draws, which can calculate the Bayesian evidence at\nup to an order of magnitude higher accuracy than `vanilla' NS with no change in\nthe way MultiNest explores the parameter space. This is accomplished by\ntreating as a (pseudo-)importance sample the totality of points collected by\nMultiNest, including those previously discarded under the constrained\nlikelihood sampling of the NS algorithm. We apply this technique to several\nchallenging test problems and compare the accuracy of Bayesian evidences\nobtained with INS against those from vanilla NS.\n"
data_with_code.comments[0] # text这个字段是把abstract和comments拼接在一起了-->为了方便找到github连接 不用去两个字段里找了
'28 pages, 6 figures, 2 tables. Accepted for publication in The Open\n Journal of Astrophysics. Code available from\n https://github.com/farhanferoz/MultiNest/'
# 使用正则表达式匹配论文
pattern = '[a-zA-z]+://github[^\s]*'
data_with_code['code_flag'] = data_with_code['text'].str.findall(pattern).apply(len)
- 匹配前面的子表达式一次或多次
- 匹配前面的子表达式零次或多次
- [a-zA-z]+://github[^\s]*
- 字母(大小写)匹配1次或多次,匹配:,匹配//(双斜杠),匹配github,匹配除了(空白符 包括换行)以外的 且匹配0次或多次
pattern = '[a-zA-z]+://github[^\s]*'
data_with_code['text'].str.findall(pattern) # 找出text中所有匹配的部分,return结果是list
0 [https://github.com/farhanferoz/MultiNest/]
1 []
2 [https://github.com/jeanluct/braidlab]
3 [https://github.com/compops/pmh-tutorial]
4 [https://github.com/COINtoolbox/DRACULA).]
...
436 [https://github.com/sfeeney/ddspectra]
437 [https://github.com/infrontofme/UWGAN_UIE.]
438 [https://github.com/closest-git/ONNet.]
439 []
440 [https://github.com/JWFangit/LOTVS-DADA.]
Name: text, Length: 441, dtype: object
data_with_code['code_flag'] = data_with_code['text'].str.findall(pattern).apply(lambda x: 0 if len(x) < 1 else 1)
data_with_code
# 新字段:code_flag--这篇论文有无代码的出现
# 匿名函数的参数x是list
# 如果x的长度<1 i.e list的长度=0:这个text没有匹配--没有github代码连接--映射成0(无)
# 如果x的长度>1 i.e 至少一个github代码连接--映射成1(有)
# 只关心有没有代码连接(1/0)不关心几个代码连接 所以0 if len(x) < 1 else 1
:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data_with_code['code_flag'] = data_with_code['text'].str.findall(pattern).apply(lambda x: 0 if len(x) < 1 else 1)
| index | id | abstract | categories | comments | pages | figures | text | code_flag | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 5578 | 1306.2144 | Bayesian inference involves two main computa... | astro-ph | 28 pages, 6 figures, 2 tables. Accepted for pu... | 28 | 6.0 | Bayesian inference involves two main computa... | 1 |
| 1 | 7180 | 1407.5514 | We present the concept of an acoustic rake r... | cs | 12 pages, 11 figures, Accepted for publication... | 12 | 11.0 | We present the concept of an acoustic rake r... | 0 |
| 2 | 7475 | 1410.0849 | Braidlab is a Matlab package for analyzing d... | math | 52 pages, 32 figures. See https://github.com/j... | 52 | 32.0 | Braidlab is a Matlab package for analyzing d... | 1 |
| 3 | 9857 | 1511.01707 | This tutorial provides a gentle introduction... | stat | 41 pages, 7 figures. In press for Journal of S... | 41 | 7.0 | This tutorial provides a gentle introduction... | 1 |
| 4 | 10207 | 1512.06810 | The existence of multiple subclasses of type... | astro-ph | 16 pages, 12 figures, accepted for publication... | 16 | 12.0 | The existence of multiple subclasses of type... | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 436 | 166505 | 1912.09498 | Upcoming million-star spectroscopic surveys ... | astro-ph | 15 pages, 9 figures, code available from\n ht... | 15 | 9.0 | Upcoming million-star spectroscopic surveys ... | 1 |
| 437 | 166901 | 1912.10269 | In real-world underwater environment, explor... | eess | 10 pages, 8 figures | 10 | 8.0 | In real-world underwater environment, explor... | 1 |
| 438 | 167132 | 1912.10730 | Diffractive deep neural network (DNNet) is a... | cs | 5 pages,5 figures | 5 | 5.0 | Diffractive deep neural network (DNNet) is a... | 1 |
| 439 | 167296 | 1912.11032 | Learning robotic manipulation tasks using re... | cs | 10 pages, 4 figures and 1 table in main articl... | 10 | 4.0 | Learning robotic manipulation tasks using re... | 0 |
| 440 | 167894 | 1912.12148 | Driver attention prediction has recently abs... | cs | 12 pages, 13 figures, submitted to IEEE-TITS | 12 | 13.0 | Driver attention prediction has recently abs... | 1 |
441 rows × 9 columns
# 只筛选出有代码连接的论文
data_with_code = data_with_code[data_with_code.code_flag == 1]
plt.figure(figsize=(10,6))
data_with_code.groupby("categories")["code_flag"].count().sort_values().plot(kind="barh")
plt.xlabel("count")
Text(0.5, 0, 'count')
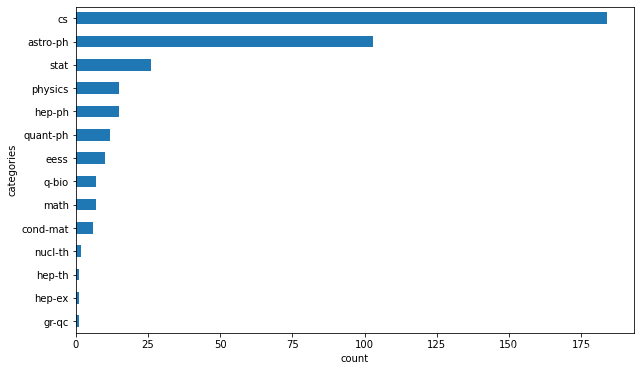
- 可以看出来类别为cs(Computer Science)& astro-ph(Astrophysics)的论文中:包含代码连接的论文数量是最多的top2 远超过其他的类别