【计算机组成】实模式/保护模式下地址分段(基段地址+偏移地址)的原因
一.硬编码/静态重定向
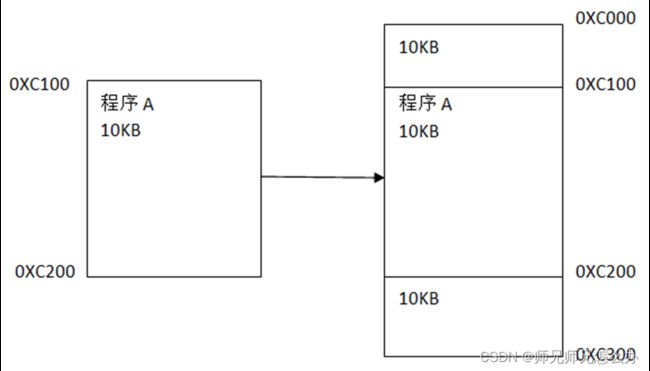
我们先来观察下没有地址分段时代CPU是怎么和内存们打交道,在8086CPU以前的老大哥们,访问内存时通常就是实打实的“指哪打哪”,程序指定要放在哪个地址,那就老老实实地放在哪个地址,比如程序A要放在以0XC100为起始的地址,那么如果内存中没有其他程序的情况下,程序A 就毫不客气地放进去:
这种指哪打哪的方式有个专业的名词来形容它:硬编码,也可以叫做静态重定向。程序首次装入内存后就不能再次在内存中移动了,在这个前提下再牛逼的操作系统也无法高效的完成内存的回收和分配,这种硬编码会导致的两个问题:
- 会导致内存碎片化
- 会导致程序长时间处于等待状态
内存碎片化很好理解,因为程序是固定地址的,如果下一个程序再来的时候一看,哎呦不够地方放了:

又或者说程序B也想从0XC100开始,但是恰好程序A也在:

这时候程序B只能站在一边扣着手指头等,一直等待程序A运行完之后主动让出空间来。眼看着程序的队伍排得越来越长,CPU开发工程师熬白了头发,终于发明了“段基址+段内偏移地址”的内存访问形式,并且首次应用于8086CPU中,从此8086CPU就称为了CPU界的里程碑,后续的286、386、586等x86CPU中“x”,其实指代的是Inter的86系列CPU。
二.动态重定向
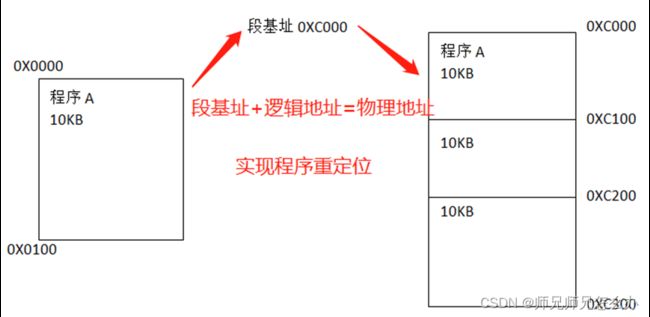
为了支持分段机制,CPU新增了诸如cs、ds以及es等段寄存器。CS段基址寄存器与IP逻辑地址寄存器组合在一起,实现程序的动态重定向。动态重定向的程序在逻辑地址上还是按照静态重定向的方式不变,区别在于动态重定向的程序在编译链接时,会在逻辑地址上加上段基址,用两者相加的结果作为实际的寻址地址进行内存寻址。该方法可以使得程序在内存中任意移动,比如前面出现的例子:

就可以通过动态重定向将程序A进行程序重定向:
进行内存空间管理,避免内存碎片化,程序B就有足够的空间放入内存:

采用“段基址+逻辑地址”的方法实现了即使程序的逻辑地址(如程序A和程序B都是以0x0000开头)相同,程序也能被放置在内存的不同位置,提高了CPU的运行效率。
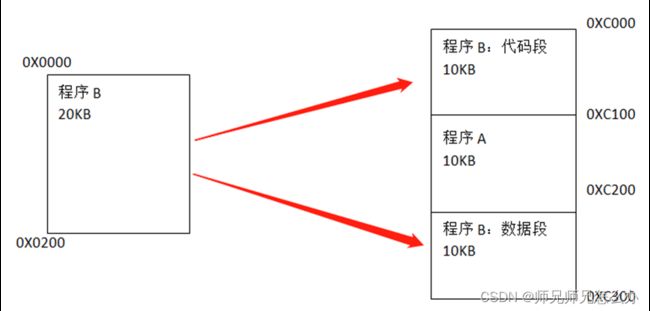
再到后来,研发人员在分段机制的基础上将程序分解成立:代码段+数据段+栈段+堆段+巴拉巴拉,将连续的逻辑地址空间分解成非连续的物理空间,也算是内存分配的一种优化:
三.8086CPU实模式下的段基址为啥左移四位
在实模式下进行CS:IP的地址偏移运算时,通常需要将CS的地址左移四位,再和IP里面的地址进行相加,这是为什么呢?
原因在于实模式下8086的CPU地址总线一共有20位(A0~A19),20位=1048576个字节=1MB,最大地址转换成16进制表示为0XFFFFF,也就是说20位的地址空间总共有1MB大小的地址空间,而寄存器一般为16位,也就是最大只能找到64KB的地址宽度,最大地址转换成16进制表示位0XFFFF,这也就说明了使用单个寄存器无法找到全部的地址总线。一个寄存器不行,那就用两个行不行?对不起,还是不行,用两个寄存器(我们给他们起个名字叫段基址寄存器和逻辑地址寄存器),就算是两个寄存器都取最大值0XFFFF,两者相加的结果是0X1FFFE

这个结果也只能到达17位,还不够16位(两个n位的数无论多大,其相加的结果也不会超过n+1位,原因很简单,因为即使n位的数能表示的最大数相加,也只是相当于乘以2,数值上与往左移动了1位而已),虽说直接使用立即数手动指定20位的地址也可以,但那是利用了程序员自身的软件办法来补了硬件的这个坑,但是作为一个严谨的CPU硬件,如果寄存器确实不支持1MB的寻址空间,那就写不支持就好,但是既然写了寄存器寻址支持1MB的寻址宽度,那么就得自圆其说。
那么最后CPU的研发人员采用了什么方法呢?方法就是将段基址左移四位便可以解决问题,比如段基址0XFFFF,左移四位就相当于乘以10H得出0XFFFF0
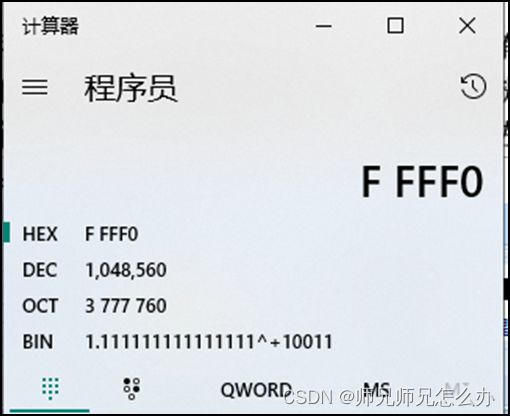
再与偏移地址0XFFFF相加,结果是0X10FFEF
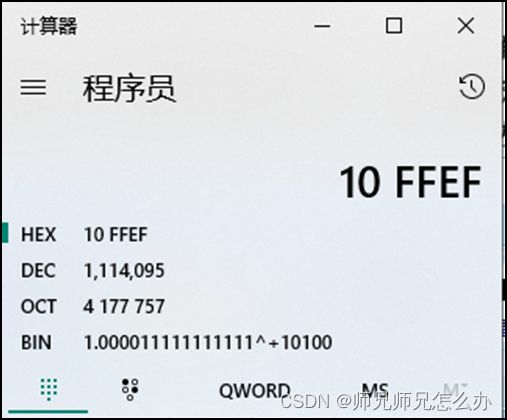
这个结果虽然可以访问20位的地址空间,但是也有点溢出了,原因是段基址如果取最大值0XFFFF的话,往左偏移4位结果为0XFFFF0(这个结果由地址加法器算出来后直接往控制电路方向送,如果对这部分感兴趣的可以参考以前写过的一篇文章:【汇编语言】CS:IP寄存器),那么偏移地址最大也只能等于0XF,而现在偏移地址是0XFFFF,整整多出来0XFFF0这么多的空间,也就是64K-16B,而这部分的内存有个专业的名称叫做高端内存区。
那么这个多出来的部分要怎么处理呢?事实上不用任何处理。你可以思考下,地址空间一共也就20位,而0X10FFEF一共有21位,比地址总线还多出来1位,那多出来的哪位能干什么用呢?什么用都没有,直接扔掉,也就相当于把地址对1MB取模了。
最后举个例子,0XFFFFF+2,理论上结果为0X10001,因为地址总线只有20位,所以实际上的结果为0x00001,这种超出最大范围后又从0重新计数的技术,叫做回卷。
