Spring高频面试问题汇总
1 什么是spring?
Spring是一个轻量级Java开发框架,最早有Rod Johnson创建,目的是为了解决企业级应用开发的业务逻辑层和其他各层的耦合问题。它是一个分层的JavaSE/JavaEE full-stack(一站式)轻量级开源框架,为开发Java应用程序提供全面的基础架构支持。Spring负责基础架构,因此Java开发者可以专注于应用程序的开发。
Spring最根本的使命是解决企业级应用开发的复杂性,即简化Java开发。
Spring可以做很多事情,它为企业级开发提供给了丰富的功能,但是这些功能的底层都依赖于它的两个核心特性,也就是依赖注入(dependency injection,DI)和面向切面编程(aspectoriented programming,AOP)。
2.Spring 框架中都用到了哪些设计模式?
1.简单工厂——BeanFactory
2.工厂方法——FactoryBean
3.单例模式——Bean实例
4.适配器模式——SpringMVC中的HandlerAdatper
5.装饰器模式——BeanWrapper
6.代理模式——AOP底层
7.观察者模式——spring的事件监听
8.策略模式——excludeFilters、includeFilters
9.模版方法模式——Spring几乎所有的外接扩展都采用这种模式
10.责任链模式——Aop的方法调用
3.什么是Spring IOC 容器?
控制反转即IOC (Inversion of Control),它把传统上由程序代码直接操控的对象的调用权交给容器,通过容器来实现对象组件的装配和管理。所谓的“控制反转”概念就是对组件对象控制权的转移,从程序代码本身转移到了外部容器。Spring IOC 负责创建对象,管理对象(通过依赖注入(DI),装配对象,配置对象,并且管理这些对象的整个生命周期。
控制:指的是对象创建(实例化、管理)的权力
反转 :控制权交给外部环境(Spring 框架、IoC 容器)
通俗的讲,我现在需要一个房子住,没有ioc的做法是我自己去盖一个(new),房子的建造管理权都在我手里,但是我的目的只是用来住,至于房子是谁盖得谁管理并不重要。有了ioc的做法是,我要找个房子住,我就去找了个中介,这个中介就是spring,中介手里有很多房子,都在一个ioc容器里,我告诉中介我要一个南向的100平的房子,中介直接把房子钥匙给我就好了。中介负责房子的建造、管理,我把控制的权利反转给了中介,就是控制反转。
IOC 总体来说有两处地方最重要,一个是创建 Bean 容器,一个是初始化 Bean。
spring 主要提供了「两种 IOC 容器」,一种是 「BeanFactory」,还有一种「ApplicationContext」
它们的区别就在于,
BeanFactory 「只提供了最基本的实例化对象和拿对象的功能」,
而 ApplicationContext 是继承了 BeanFactory 所派生出来的产物,是其子类,它的作用更加的强大,比如支持注解注入、国际化等功能
4.什么是Spring的依赖注入?
控制反转IOC是一个很大的概念,可以用不同的方式来实现。其主要实现方式有两种:依赖注入和依赖查找
依赖注入:相对于IOC而言,依赖注入(DI)更加准确地描述了IOC的设计理念。
所谓依赖注入(Dependency Injection),即组件之间的依赖关系由容器在应用系统运行期来决定,也就是由容器动态地将某种依赖关系的目标对象实例注入到应用系统中的各个关联的组件之中。组件不做定位查询,只提供普通的Java方法让容器去决定依赖关系。
依赖注入的方式以及优缺点分析:
属性注入(Field Injection)
@Autowired
private UserService userService;
开发中最常用的注入方式
优点:属性注入最大的优点就是实现简单、使用简单,
只需要给变量上添加一个注解(@Autowired),就可以在不 new 对象的情况下,直接获得注入的对象了(这就是 DI 的功能和魅力所在),所以它的优点就是使用简单。
缺点:
功能性问题:无法注入一个不可变的对象(final 修饰的对象)
通用性问题:只能适应于 IoC 容器
设计原则问题:更容易违背单一设计原则(一个类中注入多个其他的类)

Setter 注入(Setter Injection)
优缺点分析
从上面代码可以看出,Setter 注入比属性注入要麻烦很多。要说 Setter 注入有什么优点的话,那么首当其冲的就是它完全符合单一职责的设计原则,因为每一个 Setter 只针对一个对象。但它的缺点也很明显,它的缺点主要体现在以下 2 点:
不能注入不可变对象(final 修饰的对象);
注入的对象可被修改。
构造方法注入(Constructor Injection)
spring4以后的版本加入的,优化了前两个的部分缺点
5.SpringIoC的加载过程。
1.实例化化容器:AnnotationConfigApplicationContext :(批一块地)
2.实例化工厂:DefaultListableBeanFactory(盖个厂房)
3.实例化建BeanDefinition读取器: AnnotatedBeanDefinitionReader:(想想厂房要干啥)
4.创建BeanDefinition扫描器:ClassPathBeanDefinitionScanner(开始下手干)
5.注册配置类为BeanDefinition: register(annotatedClasses);(去工商局注册)
6. refresh()(粉刷一下)
6.5-invokeBeanFactoryPostProcessors(beanFactory)(参考别的厂房的模式)
6-11-finishBeanFactoryInitialization(beanFactory);(开工)
6.什么是AOP
OOP(Object-Oriented Programming)面向对象编程,允许开发者定义纵向的关系,但并适用于定义横向的关系,导致了大量代码的重复,而不利于各个模块的重用。AOP(Aspect-Oriented Programming),一般称为面向切面编程,作为面向对象的一种补充,用于将那些与业务无关,但却对多个对象产生影响的公共行为和逻辑,抽取并封装为一个可重用的模块,这个模块被命名为“切面”(Aspect),减少系统中的重复代码,降低了模块间的耦合度,同时提高了系统的可维护性。可用于权限认证、日志、事务处理等。(身份认证、打印请求参数)
7.介绍下AspectJ和AOP和关系
AOP
Spring 提供了 AspectJ 的支持,但只用到的AspectJ的切点解析和匹配。
很多人会对比 Spring AOP 和 AspectJ 的性能,Spring AOP 是基于代理实现的,在容器启动的时候需要生成代理实例,在方法调用上也会增加栈的深度,使得 Spring AOP 的性能不如 AspectJ 那么好。
AspectJ:
AspectJ 出身也是名门,来自于 Eclipse 基金会,
AspectJ 能干很多 Spring AOP 干不了的事情,它是 AOP 编程的完全解决方案。Spring AOP 致力于解决的是企业级开发中最普遍的 AOP 需求(方法织入),而不是力求成为一个像 AspectJ 一样的 AOP 编程完全解决方案。
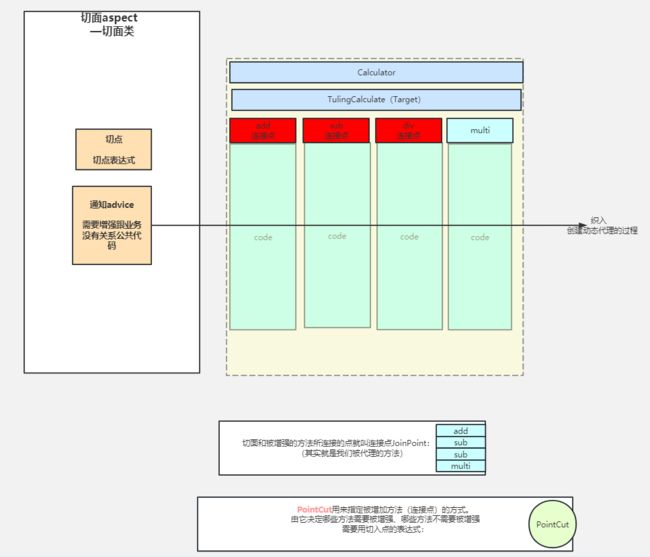
8.Spring AOP中aspect、advise、pointcut、advisor分别有什么意义?

9.介绍AOP有几种实现方式
方式一 使用SpringAPI接口
在SpringAOP中,通过Advice定义横切逻辑,Spring中支持5种类型的Advice:具体如下图所示:

方式二 自定义类实现
第一种方式是API接口,第二种方式可以简单一点,刚才的接口如果接口记不住或者接口找不到就没办法实现,那么使用自定义类来实现。
方式三 注解实现AOP
前面讲解了两种方式,现在来介绍第三种方式,这种方式采用注册实现,注解实现其实就是用注解来替代之前的xml配置。
即可以用@Aspect来标注类,表示该类为一个切面,用@Before标注类中方法,表示该方法为前置方法,注解中的参数即为切入点的位置。
10.简单介绍Spring-AOP的底层原理
「静态代理」
由程序员创建或由特定工具自动生成源代码,再对其编译。在程序运行前,代理类的.class文件就已经存在了
静态代理通常只代理一个类
静态代理事先知道要代理的是什么
「动态代理」
在程序运行时,运用反射机制动态创建而成
动态代理是代理一个接口下的多个实现类
动态代理不知道要代理什么东西,只有在运行时才知道
AOP低层说白了就是动态代理,其中有两种代理方式:
1.JDKProxy动态代理类创建,JDK代理使用的是反射机制生成一个实现代理接口的匿名类,在调用具体方法前调用InvokeHandler来处理。
2.Cglib动态代理,CGLIB代理使用字节码处理框架asm,对代理对象类的class文件加载进来,通过修改字节码生成子类。
11.什么是Spring beans?
Spring beans 是那些形成Spring应用的主干的java对象。它们被Spring IOC容器初始化,装配,和管理。这些beans通过容器中配置的元数据创建。比如,以XML文件中 的形式定义。
bean是一个由Spring IoC容器实例化、组装和管理的对象。
概念简单明了,可以提炼出如下三条关键信息:
bean是对象,数量不限,即可以为多个;
bean由Spring IoC容器管理;
应用程序由一个个bean构建。
Spring帮助我们通过两种方式管理bean,一种是注册Bean,另一种是装配Bean。完成管理动作的方式有如下三种:
使用自动配置。@Component注解及其衍生注解@RestController、@Controller、@Service和@Repository等都是组件注册注解。使用组件注册注解告诉Spring,我是一个bean,你要来管理我,然后使用@AutoWired注解去装配Bean;也可以使用由javax.annotation.Resource提供@Resource去装配Bean。所谓装配,就是管理各个对象之间的协作关系。
使用JavaConfig。使用@Configuration告诉Spring,IoC容器要怎么配置,即怎么去注册bean,怎么去处理bean之间的关系(装配)。
使用XML配置。标签就是告诉spring怎么获取这个bean,各种就是手动的配置bean之间的关系。
12.解释Spring支持的几种bean的作用域
作用域简单可以理解成:bean对象的存活范围。
Bean作用域本质上指的是多次调用context.getBean()方法获取到的是否是同一个bean对象。
Spring框架支持以下五种bean的作用域:
singleton : bean在每个Spring ioc 容器中只有一个实例。
prototype:一个bean的定义可以有多个实例。
request:每次http请求都会创建一个bean,该作用域仅在基于web的SpringApplicationContext情形下有效。
session:在一个HTTP Session中,一个bean定义对应一个实例。该作用域仅在基于web的Spring ApplicationContext情形下有效。
global-session:在一个全局的HTTP Session中,一个bean定义对应一个实例。该作用域仅在基于web的Spring ApplicationContext情形下有效。
注意: 缺省的Spring bean 的作用域是Singleton。使用 prototype 作用域需要慎重的思考,因为频繁创建和销毁 bean 会带来很大的性能开销。
13.解释Spring框架中bean的生命周期
实例化 Instantiation
属性赋值 Populate
初始化 Initialization
如果实现了 Aware 接口,会通过其接口获取容器资源
如果实现了 BeanPostProcessor 接口,则会回调该接口的前置和后置处理增强
如果配置了 init-method 方法,会执行该方法
销毁 Destruction
如果实现了 DisposableBean 接口,则会回调该接口的 destroy 方法
如果配置了 destroy-method 方法,则会执行 destroy-method 配置的方法

实例化Bean对象,这个时候Bean的对象是非常低级的,基本不能够被我们使用,因为连最基本的属性都没有设置,可以理解为连Autowired注解都是没有解析的;(实打实的招了一个刚毕业的大学生员工)
填充属性,当做完这一步,Bean对象基本是完整的了,可以理解为Autowired注解已经解析完毕,依赖注入完成了;(入职报道,成为了新公司的一员,赋予该新人公司工号、工牌)
如果Bean实现了BeanNameAware接口,则调用setBeanName方法;(如果需要工作花名BeanNameAware,起个花名)
如果Bean实现了BeanClassLoaderAware接口,则调用setBeanClassLoader方法;(如果需要班车BeanClassLoaderAware,给班车打个招呼)
如果Bean实现了BeanFactoryAware接口,则调用setBeanFactory方法;(如果要参观工厂BeanFactoryAware,带着去参观一下工厂)
调用BeanPostProcessor的postProcessBeforeInitialization方法;(正式工作前入职培训一下)
如果Bean实现了InitializingBean接口,调用afterPropertiesSet方法;(培训完有作业,每天培训完做一下总结)
如果Bean定义了init-method方法,则调用Bean的init-method方法;(培训如果需要电脑,电脑上装好需要的工作软件)
调用BeanPostProcessor的postProcessAfterInitialization方法;当进行到这一步,Bean已经被准备就绪了,一直停留在应用的上下文中,直到被销毁;(培训完成后,来个考试看看培训结果,完成后就可以正式工作了)
如果应用的上下文被销毁了,如果Bean实现了DisposableBean接口,则调用destroy方法,如果Bean定义了destory-method声明了销毁方法也会被调用。(不想干了,走了)
源码分析:docreate()方法中,主要是三个方法对应前三个阶段,createbeaninstance()方法对应实例化阶段,populatebean()方法对应属性赋值,initialzebean()对应初始化阶段。
Aware接口补充:
Aware接口从字面上翻译过来是感知捕获的含义。单纯的bean(未实现Aware系列接口)是没有知觉的;实现了Aware系列接口的bean可以访问Spring容器。这些Aware系列接口增强了Spring bean的功能,但是也会造成对Spring框架的绑定,增大了与Spring框架的耦合度。(Aware是“意识到的,察觉到的”的意思,实现了Aware系列接口表明:可以意识到、可以察觉到)
13.@Component, @Controller, @Repository, @Service 有何区别?
@Component:这将 java 类标记为 bean。它是任何 Spring 管理组件的通用构造型。spring 的组件扫描机制现在可以将其拾取并将其拉入应用程序环境中。
@Controller:这将一个类标记为 Spring Web MVC 控制器。标有它的 Bean 会自动导入到 IOC 容器中。
@Service:此注解是组件注解的特化。它不会对 @Component 注解提供任何其他行为。您可以在服务层类中使用 @Service 而不是 @Component,因为它以更好的方式指定了意图。
@Repository:这个注解是具有类似用途和功能的 @Component 注解的特化。它为 DAO 提供了额外的好处。它将 DAO 导入 IOC 容器,并使未经检查的异常有资格转换为 SpringDataAccessException
14.@Controller注解的作用
在Spring MVC 中,控制器Controller 负责处理由DispatcherServlet 分发的请求,它把用户请求的数据经过业务处理层处理之后封装成一个Model ,然后再把该Model 返回给对应的View 进行展示。
在Spring MVC 中提供了一个非常简便的定义Controller 的方法,你无需继承特定的类或实现特定的接口,只需使用@Controller 标记一个类是Controller ,然后使用@RequestMapping 和@RequestParam 等一些注解用以定义URL 请求和Controller 方法之间的映射,这样的Controller就能被外界访问到。
此外Controller 不会直接依赖于HttpServletRequest 和HttpServletResponse等HttpServlet 对象,它们可以通过Controller 的方法参数灵活的获取到。
@Controller 用于标记在一个类上,使用它标记的类就是一个Spring MVC Controller 对象。分发处理器将会扫描使用了该注解的类的方法,并检测该方法是否使用了@RequestMapping 注解。
@Controller 只是定义了一个控制器类,而使用@RequestMapping 注解的方法才是真正处理请求的处理器。单单使用@Controller 标记在一个类上还不能真正意义上的说它就是Spring MVC 的一个控制器类,因为这个时候Spring 还不认识它。那么要如何做Spring 才能认识它呢?这个时候就需要我们把这个控制器类交给Spring 来管理。有两种方式:在Spring MVC 的配置文件中定义MyController 的bean 对象。在Spring MVC 的配置文件中告诉Spring 该到哪里去找标记为@Controller 的Controller 控制器
15.Spring支持的事务管理类型, spring 事务实现方式有哪些?
Spring支持两种类型的事务管理:
编程式事务管理:这意味你通过编程的方式管理事务,给你带来极大的灵活性,但是难维护。(自己编写提交、事务、回滚逻辑,在业务代码中侵入式实现)
声明式事务管理:这意味着你可以将业务代码和事务管理分离,你只需用注解和XML配置来管理事务。使用@Transactional注解实现,可以作用于接口、接口方法、类、类方法,通常是在类的方法上使用。常用的配置参数有@Transactional(rollbackFor = Exception.class),即当方法中抛出指定异常时进行回滚。readonly设置当前事务是否为只读,@Transactional(isolation = Isolation.DEFAULT)isolation 设置事务隔离级别,timeout设置事务的超时秒数。

16.说一下Spring的事务传播行为spring事务的传播行为
当多个事务同时存在的时候,spring如何处理这些事务的行为。
spring的7种传播行为:
1.required:(默认传播行为),如果当前有事务,其他就用当前事务,不会新增事务。
例如:方法A调用方法B,它们用同一个事务。(如果B没有事务,它们会用同一个事务。)(只要有一个回滚,整体就会回滚)
2.requires_new:如果当前有事务,其他不会加入当前事务,会新增事务。即他们的事务没有关系,不是同一个事务。
如果其他没有事务,那么以当前事务运行。
例如:方法A调用方法B,它们用不同的事务。(B不会用A的事务,会新增事务。)
3.supports:当前没有事务,就以非事务运行。当前有事务呢?就以当前事务运行。
例如:方法A调用方法B,如果A没有事务,那么B就以非事务运行。
如果A有事务就以A事务为准。如果A没有事务,那么B就会以非事务执行。
4.mandatory:其他没有事务就会抛异常。当前没有事务抛出异常,当前有事务则支持当前事务。
支持当前事务,如果当前没有事务就会抛出异常。
例如:方法A调用方法B,如果方法A没有事务,那么就会抛出异常。
5.not_supported:以非事务执行。
例如:方法A调用方法B,方法B会挂起事务A以非事务方式执行。
6.never:以非事务执行,如果存在事务,抛出异常。
总是以非事务执行,如果存在事务,那么就抛出异常。
7.nested:如果当前已经存在一个事务,那么该方法将会在嵌套事务中运行。嵌套的事务可以独立于当前事务进行单独地提交或回滚。
如果当前事务不存在,那么其行为与Required一样。
例如:方法A中调用了方法B,B中try catch手动回滚,A不会回滚。
17.请描述Spring MVC的工作流程?描述一下 DispatcherServlet 的工作流程?

(1)用户发送请求至前端控制器DispatcherServlet;
(2) DispatcherServlet收到请求后,调用HandlerMapping处理器映射器,请求获取Handle;
(3)处理器映射器根据请求url找到具体的处理器,生成处理器对象及处理器拦截器(如果有则生成)一并返回给DispatcherServlet;
(4)DispatcherServlet 调用 HandlerAdapter处理器适配器;
(5)HandlerAdapter 经过适配调用 具体处理器(Handler,也叫后端控制器);
(6)Handler执行完成返回ModelAndView;
(7)HandlerAdapter将Handler执行结果ModelAndView返回给DispatcherServlet;
(8)DispatcherServlet将ModelAndView传给ViewResolver视图解析器进行解析;
(9)ViewResolver解析后返回具体View;
(10)DispatcherServlet对View进行渲染视图(即将模型数据填充至视图中)
(11)DispatcherServlet响应用户。
18.springboot启动流程
SpringBoot启动过程主要分为bootstrapContext创建、环境准备、applicationContext准备、bean加载、runner调用五个步骤
Springboot启动入口是启动类的Springapplication.run方法,先封装了一个SpringApplication的实例,又执行该实例的run()方法。SpringApplication封装了ApplicationContextInitializer(容器初始化器)还有ApplicaiontListener(侦听器),run方法初始化了Annotation(注解)配置的容器AnnotationConfigApplicationContext,然后执行ApplicationContextInitializer的inital方法,最后加载bean到容器中。
SpringApplication的实例,再执行该实例的run方法,
SpringApplication.run中执行了两步操作,先封装了一个SpringApplication的实例,再执行该实例的重载run方法
SpringApplication封装实例时,读取了classpath下所有的MTEA-INF/spring.factories xml配置文件的ApplicationContextInitializer(容器初始化器)还有ApplicaiontListener(侦听器),将这两者封装到SpringApplication实例中
执行SpringApplication实例的run方法
run方法中默认初始化了Annotation配置的容器AnnotationConfigApplicationContext
执行上面ApplicationContextInitializer的initial方法
然后加载Bean到容器中
19.SpringBoot自动配置原理?
1.容器在启动的时候会调用 EnableAutoConfigurationImportSelector.class 的 selectImports方法「获取一个全面的常用 BeanConfiguration 列表」
2.之后会读取 spring-boot-autoconfigure.jar 下面的spring.factories,「获取到所有的 Spring 相关的 Bean 的全限定名 ClassName」
3.之后继续「调用 filter 来一一筛选」,过滤掉一些我们不需要不符合条件的 Bean
4.最后把符合条件的 BeanConfiguration 注入默认的 EnableConfigurationPropertie 类里面的属性值,并且「注入到 IOC 环境当中」
@SpringBootApplication注解进入后有@EnableAutoConfiguration注解,它要开启自动配置
@EnableAutoConfiguration (开启自动配置) 该注解引入了AutoConfigurationImportSelector,该类中的方法会扫描所有存在META-INF/spring.factories的jar包。当我们在启动SpringBoot项目的时候,内部就会加载这个spring.factories文件,进而去加载“有需要”的配置类。那我们在使用相关组件的时候,就会非常的方便(因为配置类已经初始化了一大部分配置信息)。一般我们只要在application配置文件写上对应的配置,就能通过各种template类直接操作对应的组件啦。也不是所有的配置类都会加载的,假设我们没有引入redis-starter的包,那Redis的配置类就不会被加载。具体Spring在实现的时候就是使用@ConditionalXXX进行判断的。比如Redis的配置类就会有@ConditionalOnClass({RedisOperations.class})的配置,说明当前环境下如果有RedisOperations.class这个字节码,才会去加载Redis的配置类。
20.Spring Boot 中的 starter 到底是什么 ?
首先,这个 Starter 并非什么新的技术点,基本上还是基于 Spring 已有功能来实现的。首先它提供了一个自动化配置类,一般命名为 XXXAutoConfiguration ,在这个配置类中通过条件注解来决定一个配置是否生效(条件注解就是 Spring 中原本就有的),然后它还会提供一系列的默认配org.springframework.bootspring-boot-devtools置,也允许开发者根据实际情况自定义相关配置,然后通过类型安全的属性(spring.factories)注入将这些配置属性注入进来,新注入的属性会代替掉默认属性。正因为如此,很多第三方框架,我们只需要引入依赖就可以直接使用了。当然,开发者也可以自定义 Starter。
starter这东西就是为了方便调用方去使用相关的组件的嘛,Spring框架也给我们实现了很多好用的starter。
比如以前我们要用Mybatis框架,可能会引入各种的包才能使用。而starter就是做了一层封装,把相关要用到的jar都给包起来了,并且也写好了对应的版本。这我们使用的时候就不需要引入一堆jar包且管理版本类似的问题了。
21.BeanFactory和FactoryBean的区别?
区别:BeanFactory是个Factory,也就是IOC容器或对象工厂,FactoryBean是个Bean。
在Spring中,所有的Bean都是由BeanFactory(也就是IOC容器)来进行管理的。
但对FactoryBean而言,这个Bean不是简单的Bean,而是一个能生产或者修饰对象生成的工厂Bean,它的实现与设计模式中的工厂模式和修饰器模式类似。
BeanFactory和FactoryBean都可以用来创建对象,只不过创建的流程和方式不同
当使用BeanFactory的时候,必须要严格的遵守bean的生命周期,经过一系列繁杂的步骤之后可以创建出单例对象,是流水线式的创建过程,
而FactoryBean是用户可以自定义bean对象的创建流程,不需要按照bean的生命周期来创建,在此接口中包含了三个方法,
isSingleton:判断是否是单例对象
getObjectType:获取对象的类型
getObject:在此方法中可以自己创建对象,使用new的方式或者使用代理的方式都可以,用户可以按照自己的需要随意去创建对象,在很多框架继承的时候都会实现FactoryBean接口,比如Feign
22.请介绍BeanFactoryPostProcessor在Spring中的用途。
BeanFactoryPostProcessor在容器实例化任何bean之前读取bean的定义(配置元数据),并可以修改它。
类似的:
BeanPostProcessor 可以在 spring 容器实例化 bean 之后,在执行 bean 的初始化方法前后,添加一些自己的处理逻辑。 这里说的初始化方法,指的是以下两种:
bean 实现 了 InitializingBean 接口,对应的方法为 afterPropertiesSet 。
在 XML 文件中定义 bean 的时候,标签有个属性叫做 init-method,来指定初始化方法。
注意:BeanPostProcessor 是在 spring 容器加载了 bean 的定义文件并且实例化 bean 之后执行的。BeanPostProcessor 的执行顺序是在 BeanFactoryPostProcessor 之后。
23.Spring中有哪些扩展接口及调用时机。
1.InitializingBean接口
InitializingBean接口中只有一个afterPropertiesSet方法,从方法的名称上很容易理解,这个方法是在Bean的属性都设置值后被调用,用于完成一些初始化工作。当然,在Spring的配置文件中init-method的配置也是在Bean的属性都设置值后被调用,用于完成一些初始化工作,不过在执行顺序上,接口的方法先于配置。值得注意的是,这两种方式都是用于完成一些初始化工作,所以相应的方法中不要编写一些复杂且执行时间很长的逻辑。
2.DisposableBean接口
DisposableBean接口中只有一个destroy方法,该方法会在Bean被销毁、生命周期结束之前被调用,用于做一些销毁的收尾工作。同样,在Spring的配置文件中destroy-method配置也完成同样的工作,不过在执行顺序上,接口的方法先于配置。
3.ApplicationContextAware接口
ApplicationContextAware中只有一个setApplicationContext方法。实现了ApplicationContextAware接口的类,可以在该Bean被加载的过程中获取Spring的应用上下文ApplicationContext,通过ApplicationContext可以获取Spring容器内的很多信息。
4.BeanFactoryAware接口
BeanFactoryAware接口中只有一个setBeanFactory方法。实现了BeanFactoryAware接口的类,可以在该Bean被加载的过程中获取加载该Bean的BeanFactory,同时也可以获取这个BeanFactory中加载的其它Bean。
5.FactoryBean接口
FactoryBean接口可以实现Bean实例化的个性定制,让Spring容器加载我们想要的Bean。实现了FactoryBean接口的类,可以通过实现getObject方法,实现加载我们想要的Bean(如:SqlSessionFactoryBean)。
6.BeanPostProcessor接口
BeanPostProcessor接口中有两个方法,分别为postProcessBeforeInitialization和postProcessAfterInitialization。实现了BeanPostProcessor接口的类,会在每个Bean初始化(即调用setter)之前和之后,分别调用这个类中的postProcessBeforeInitialization方法和postProcessAfterInitialization方法,实现初始化的逻辑控制。
7.InstantiationAwareBeanPostProcessor接口
InstantiationAwareBeanPostProcessor接口中,常用的方法是postProcessBeforeInstantiation和postProcessAfterInstantiation。每个Bean的实例化(即调用构造函数)之前和之后,会分别调用实现了该接口的类中的postProcessBeforeInstantiation和postProcessAfterInstantiation方法。
8.BeanFactoryPostProcessor接口
BeanFactoryPostProcessor接口中只有postProcessBeanFactory方法。实现了该接口的类,可以在Bean被创建之前,获取容器中Bean的定义信息,并且可以进行修改。实现类中的postProcessBeanFactory方法只会被执行一次,且先于BeanPostProcessor接口的方法。
24.Spring循环依赖
1.什么是循环依赖?
所谓的循环依赖是指,A 依赖 B,B 又依赖 A,它们之间形成了循环依赖。或者是 A 依赖 B,B 依赖 C,C 又依赖 A。它们之间的依赖关系如下:

2.如何解决循环依赖?
使用三级缓存
3.为什么要二级缓存和三级缓存
一级缓存-singletonObjects是用来存放就绪状态的Bean。保存在该缓存中的Bean所实现Aware子接口的方法已经回调完毕,自定义初始化方法已经执行完毕,也经过BeanPostProcessor实现类的postProcessorBeforeInitialization、postProcessorAfterInitialization方法处理;
二级缓存-earlySingletonObjects是用来存放早期曝光的Bean,一般只有处于循环引用状态的Bean才会被保存在该缓存中。保存在该缓存中的Bean所实现Aware子接口的方法还未回调,自定义初始化方法未执行,也未经过BeanPostProcessor实现类的postProcessorBeforeInitialization、postProcessorAfterInitialization方法处理。如果启用了Spring AOP,并且处于切点表达式处理范围之内,那么会被增强,即创建其代理对象。
这里额外提一点,普通Bean被增强(JDK动态代理或CGLIB)的时机是在AbstractAutoProxyCreator实现的BeanPostProcessor的postProcessorAfterInitialization方法中,而处于循环引用状态的Bean被增强的时机是在AbstractAutoProxyCreator实现的SmartInstantiationAwareBeanPostProcessor的getEarlyBeanReference方法中。
三级缓存-singletonFactories是用来存放创建用于获取Bean的工厂类-ObjectFactory实例。在IoC容器中,所有刚被创建出来的Bean,默认都会保存到该缓存中。
Bean在这三个缓存之间的流转顺序为(存在循环引用):
通过反射创建Bean实例。是单例Bean,并且IoC容器允许Bean之间循环引用,保存到三级缓存中。
当发生了循环引用时,从三级缓存中取出Bean对应的ObjectFactory实例,调用其getObject方法,来获取早期曝光Bean,从三级缓存中移除,保存到二级缓存中。Bean初始化完成,生命周期的相关方法执行完毕,保存到一级缓存中,从二级缓存以及三级缓存中移除。 Bean在这三个缓存之间的流转顺序为(没有循环引用):
通过反射创建Bean实例。是单例Bean,并且IoC容器允许Bean之间循环引用,保存到三级缓存中。Bean初始化完成,生命周期的相关方法执行完毕,保存到一级缓存中,从二级缓存以及三级缓存中移除。
4.Spring有没有解决构造函数的循环依赖
从流程图应该不难看出来,在Bean调用构造器实例化之前,一二三级缓存并没有Bean的任何相关信息,在实例化之后才放入三级缓存中,因此当getBean的时候缓存并没有命中,这样就抛出了循环依赖的异常了。
5.Spring有没有解决多例下的循环依赖
我们自己手写了解决循环依赖的代码,可以看到,核心是利用一个map,来解决这个问题的,这个map就相当于缓存。
为什么可以这么做,因为我们的bean是单例的,而且是字段注入(setter注入)的,单例意味着只需要创建一次对象,后面就可以从缓存中取出来,字段注入,意味着我们无需调用构造方法进行注入。
如果是原型bean,那么就意味着每次都要去创建对象,无法利用缓存;
如果是构造方法注入,那么就意味着需要调用构造方法注入,也无法利用缓存。
25.什么是微服务架构?

马丁富勒说微服务其实是一种架构风格,我们在开发一个应用的时候这个应用应该是由一组小型服务组成,每个小型服务都运行在自己的进程内;小服务之间通过HTTP的方式进行互联互通。(平生不识秃头男,学遍Java也枉然)

26.开发中Spring Cloud Alibaba环境组件版本
SpringCloud Alibaba 依赖 Java 环境来运行。还需要为此配置 Maven环境,请确保是在以下版本环境中安装使用:
1. 64 bit JDK 1.8+;下载 & 配置。 1.8.0_131
2. Maven 3.2.x+;下载 & 配置。 3.6.1
Spring Cloud Alibaba:2.2.5.RELEASE
Spring Boot :2.3.2.RELEASE
Spring Cloud:Hoxton.SR8
27.Nacos(2.2.5.RELEASE)
定义:一个更易于构建云原生应用的动态服务发现(Nacos Discovery )、服务配置(Nacos Config)和服务管理平台。
关键特性包括:
服务发现和服务健康监测
动态配置服务
动态 DNS 服务
服务及其元数据管理
作用:管理所有微服务、解决微服务之间调用关系错综复杂、难以维护的问题;
服务注册:Nacos Client会通过发送REST请求的方式向Nacos Server注册自己的服务,提供自身的元数据,比如ip地址、端口等信息。Nacos Server接收到注册请求后,就会把这些元数据信息存储在一个双层的内存Map中。
服务心跳:在服务注册后,Nacos Client会维护一个定时心跳来持续通知Nacos Server,说明服务一直处于可用状态,防止被剔除。默认5s发送一次心跳。
服务同步:Nacos Server集群之间会互相同步服务实例,用来保证服务信息的一致性。
服务发现:服务消费者(Nacos Client)在调用服务提供者的服务时,会发送一个REST请求给Nacos Server,获取上面注册的服务清单,并且缓存在Nacos Client本地,同时会在Nacos Client本地开启一个定时任务定时拉取服务端最新的注册表信息更新到本地缓存
服务健康检查:Nacos Server会开启一个定时任务用来检查注册服务实例的健康情况,对于超过15s没有收到客户端心跳的实例会将它的healthy属性置为false(客户端服务发现时不会发现),如果某个实例超过30秒没有收到心跳,直接剔除该实例(被剔除的实例如果恢复发送心跳则会重新注册
28.CAP特性:
C (Consistency)一致性
A(Availability)可用性
P(Partition tolerance) 分区容错性一致性指的是所有节点在同一时间的数据完全一致可用性指服务一直可用,而且是正常响应时间。
分区容错性指在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。
一个服务如果舍弃了p(分区容错性),那么它就是一个单体应用,没必要上微服务了,因此,微服务一定不会舍弃p,而是舍弃A和c中的某一个,
舍弃C一致性,意味着不同的用户看到的结果是不一致的,比如12306抢票的时候,我们明明看到有票,可是就是抢不到,在别人那看到的是票早就抢完了,这就是牺牲了一致性。
舍弃A可用性,意味着服务在某一段时间内不可用,比如你抢票的时候告诉你服务器开小差了,或者给你跳到一个错误页,过一段时间恢复服务就是舍弃可可用性。
29.微服务的负载均衡
1.常见负载均衡算法
随机,通过随机选择服务进行执行,一般这种方式使用较少;
轮训,负载均衡默认实现方式,请求来之后排队处理;
加权轮训,通过对服务器性能的分型,给高配置,低负载的服务器分配更高的权重,均衡各个服务器的压力;
地址Hash,通过客户端请求的地址的HASH值取模映射进行服务器调度。 ip --->hash
最小链接数,即使请求均衡了,压力不一定会均衡,最小连接数法就是根据服务器的情况,比如请求积压数等参数,将请求分配到当前压力最小的服务器上。
2.Ribbon
目前主流的负载方案分为以下两种:
集中式负载均衡,在消费者和服务提供方中间使用独立的代理方式进行负载,有硬件的(比如 F5),也有软件的(比如 Nginx)。
客户端根据自己的请求情况做负载均衡,Ribbon 就属于客户端自己做负载均衡。
Spring Cloud Ribbon是基于Netflix Ribbon 实现的一套客户端的负载均衡工具,Ribbon客户端组件提供一系列的完善的配置,如超时,重试等。通过Load Balancer获取到服务提供的所有机器实例,Ribbon会自动基于某种规则(轮询,随机)去调用这些服务。Ribbon也可以实现我们自己的负载均衡算法。
3.Spring Cloud LoadBalancer
Spring Cloud LoadBalancer是Spring Cloud官方自己提供的客户端负载均衡器, 用来替代Ribbon。
Spring官方提供了两种负载均衡的客户端:
RestTemplate
RestTemplate是Spring提供的用于访问Rest服务的客户端,RestTemplate提供了多种便捷访问远程Http服务的方法,能够大大提高客户端的编写效率。默认情况下,RestTemplate默认依赖jdk的HTTP连接工具。
WebClient
WebClient是从Spring WebFlux 5.0版本开始提供的一个非阻塞的基于响应式编程的进行Http请求的客户端工具。它的响应式编程的基于Reactor的。WebClient中提供了标准Http请求方式对应的get、post、put、delete等方法,可以用来发起相应的请求
30.微服务调用组件Feign
Feign可以做到使用 HTTP 请求远程服务时就像调用本地方法一样的体验,开发者完全感知不到这是远程方法,更感知不到这是个 HTTP 请求。它像 Dubbo 一样,consumer 直接调用接口方法调用provider,而不需要通过常规的 Http Client 构造请求再解析返回数据。它解决了让开发者调用远程接口就跟调用本地方法一样,无需关注与远程的交互细节,更无需关注分布式环境开发。
31.sentinel
随着微服务的流行,服务和服务之间的稳定性变得越来越重要。Sentinel 是面向分布式服务架构的流量控制组件,主要以流量为切入点,从限流、流量整形、熔断降级、系统负载保护、热点防护等多个维度来帮助开发者保障微服务的稳定性
问题:服务雪崩效应,因服务提供者的不可用导致服务调用者的不可用,并将不可用逐渐放大的过程,就叫服务雪崩效应
原因:大量请求线程同步等待造成的资源耗尽。当服务调用者使用同步调用时, 会产生大量的等待线程占用系统资源。一旦线程资源被耗尽,服务调用者提供的服务也将处于不可用状态, 于是服务雪崩效应产生了。
解决方案:
超时机制
在不做任何处理的情况下,服务提供者不可用会导致消费者请求线程强制等待,而造成系统资源耗尽。加入超时机制,一旦超时,就释放资源。由于释放资源速度较快,一定程度上可以抑制资源耗尽的问题。
服务限流

隔离
原理:用户的请求将不再直接访问服务,而是通过线程池中的空闲线程来访问服务,如果线程池已满,则会进行降级处理,用户的请求不会被阻塞,至少可以看到一个执行结果(例如返回友好的提示信息),而不是无休止的等待或者看到系统崩溃。
服务熔断
远程服务不稳定或网络抖动时暂时关闭,就叫服务熔断。现实世界的断路器大家肯定都很了解,断路器实时监控电路的情况,如果发现电路电流异常,就会跳闸,从而防止电路被烧毁。
软件世界的断路器可以这样理解:实时监测应用,如果发现在一定时间内失败次数/失败率达到一定阈值,就“跳闸”,断路器打开——此时,请求直接返回,而不去调用原本调用的逻辑。跳闸一段时间后(例如10秒),断路器会进入半开状态,这是一个瞬间态,此时允许一次请求调用该调的逻辑,如果成功,则断路器关闭,应用正常调用;如果调用依然不成功,断路器继续回到打开状态,过段时间再进入半开状态尝试——通过”跳闸“,应用可以保护自己,而且避免浪费资源;而通过半开的设计,可实现应用的“自我修复“。所以,同样的道理,当依赖的服务有大量超时时,在让新的请求去访问根本没有意义,只会无畏的消耗现有资源。比如我们设置了超时时间为1s,如果短时间内有大量请求在1s内都得不到响应,就意味着这个服务出现了异常,此时就没有必要再让其他的请求去访问这个依赖了,这个时候就应该使用断路器避免资源浪费。
服务降级
有服务熔断,必然要有服务降级。所谓降级,就是当某个服务熔断之后,服务将不再被调用,此时客户端可以自己准备一个本地的fallback(回退)回调,返回一个缺省值。 例如:(备用接口/缓存/mock数据) 。这样做,虽然服务水平下降,但好歹可用,比直接挂掉要强,当然这也要看适合的业务场景。
32.分布式事务seata
2PC两阶段提交协议:
2PC(两阶段提交,Two-Phase Commit)
顾名思义,分为两个阶段:Prepare 和 Commit
Prepare:提交事务请求
基本流程如下图:

1. 询问 协调者向所有参与者发送事务请求,询问是否可执行事务操作,然后等待各个参与者的响应。
2. 执行 各个参与者接收到协调者事务请求后,执行事务操作(例如更新一个关系型数据库表中的记录),并将 Undo 和 Redo 信息记录事务日志中。
3. 响应 如果参与者成功执行了事务并写入 Undo 和 Redo 信息,则向协调者返回 YES 响应,否则返回 NO 响应。当然,参与者也可能宕机,从而不会返回响应。
Commit:执行事务提交
执行事务提交分为两种情况,正常提交和回退。
正常提交事务
流程如下图:

1. commit 请求 协调者向所有参与者发送 Commit 请求。
2. 事务提交 参与者收到 Commit 请求后,执行事务提交,提交完成后释放事务执行期占用的所有资源。
3. 反馈结果 参与者执行事务提交后向协调者发送 Ack 响应。
4. 完成事务 接收到所有参与者的 Ack 响应后,完成事务提交。
中断事务
在执行 Prepare 步骤过程中,如果某些参与者执行事务失败、宕机或与协调者之间的网络中断,那么协调者就无法收到所有参与者的 YES 响应,或者某个参与者返回了 No 响应,此时,协调者就会进入回退流程,对事务进行回退。流程如下图红色部分(将 Commit 请求替换为红色的 Rollback 请求):

1. rollback 请求 协调者向所有参与者发送 Rollback 请求。
2. 事务回滚 参与者收到 Rollback 后,使用 Prepare 阶段的 Undo 日志执行事务回滚,完成后释放事务执行期占用的所有资源。
3. 反馈结果 参与者执行事务回滚后向协调者发送 Ack 响应。
4. 中断事务 接收到所有参与者的 Ack 响应后,完成事务中断。
2PC 的问题
1. 同步阻塞 参与者在等待协调者的指令时,其实是在等待其他参与者的响应,在此过程中,参与者是无法进行其他操作的,也就是阻塞了其运行。 倘若参与者与协调者之间网络异常导致参与者一直收不到协调者信息,那么会导致参与者一直阻塞下去。
2. 单点 在 2PC 中,一切请求都来自协调者,所以协调者的地位是至关重要的,如果协调者宕机,那么就会使参与者一直阻塞并一直占用事务资源。
如果协调者也是分布式,使用选主方式提供服务,那么在一个协调者挂掉后,可以选取另一个协调者继续后续的服务,可以解决单点问题。但是,新协调者无法知道上一个事务的全部状态信息(例如已等待 Prepare 响应的时长等),所以也无法顺利处理上一个事务。
3. 数据不一致 Commit 事务过程中 Commit 请求/Rollback 请求可能因为协调者宕机或协调者与参与者网络问题丢失,那么就导致了部分参与者没有收到 Commit/Rollback 请求,而其他参与者则正常收到执行了 Commit/Rollback 操作,没有收到请求的参与者则继续阻塞。这时,参与者之间的数据就不再一致了。当参与者执行 Commit/Rollback 后会向协调者发送 Ack,然而协调者不论是否收到所有的参与者的 Ack,该事务也不会再有其他补救措施了,协调者能做的也就是等待超时后像事务发起者返回一个“我不确定该事务是否成功”。
4. 环境可靠性依赖 协调者 Prepare 请求发出后,等待响应,然而如果有参与者宕机或与协调者之间的网络中断,都会导致协调者无法收到所有参与者的响应,那么在 2PC 中,协调者会等待一定时间,然后超时后,会触发事务中断,在这个过程中,协调者和所有其他参与者都是出于阻塞的。这种机制对网络问题常见的现实环境来说太苛刻了。
3PC
3PC对于协调者(Coordinator)和参与者(Partcipant)都设置了超时时间,而2PC只有协调者才拥有超时机制。
这个优化点,主要是避免了参与者在长时间无法与协调者节点通讯(协调者挂掉了)的情况下,无法释放资源的问题,因为参与者自身拥有超时机制会在超时后,自动进行本地commit从而进行释放资源。而这种机制也侧面降低了整个事务的阻塞时间和范围。
(AT、TCC、Saga、XA)模式分析
四种分布式事务模式,分别在不同的时间被提出,每种模式都有它的适用场景
AT 模式是无侵入的分布式事务解决方案,适用于不希望对业务进行改造的场景,几乎0学习成本。
TCC 模式是高性能分布式事务解决方案,适用于核心系统等对性能有很高要求的场景。
Saga 模式是长事务解决方案,适用于业务流程长且需要保证事务最终一致性的业务系统,Saga 模式一阶段就会提交本地事务,无锁,长流程情况下可以保证性能,多用于渠道层、集成层业务系统。事务参与者可能是其它公司的服务或者是遗留系统的服务,无法进行改造和提供
TCC 要求的接口,也可以使用 Saga 模式。
XA模式是分布式强一致性的解决方案,但性能低而使用较少。
总结
分布式事务本身就是一个技术难题,业务中具体使用哪种方案还是需要不同的业务特点自行选择,但是我们也会发现,分布式事务会大大的提高流程的复杂度,会带来很多额外的开销工作,「代码量上去了,业务复杂了,性能下跌了」。
所以,当我们真实开发的过程中,能不使用分布式事务就不使用。
33.gateway
所谓的API网关,就是指系统的统一入口,它封装了应用程序的内部结构,为客户端提供统一服务,一些与业务本身功能无关的公共逻辑
可以在这里实现,诸如认证、鉴权、监控、路由转发等等
33.微服务如何拆分?
按照业务拆分
DDD拆分