关于学习《机器学习算法代码实现》的问题,主要使用的是sklearn工具包遇到的问题汇总
多项式回归——拟合非线性函数
在之前的学习中 我们比较了三种策略:批量梯度下降,随机梯度下降,和小批量梯度下降Mini Batch方法,根据效果显示,批量梯度下降得到的拟合效果最好,直接逼近最优theta,但是缺点是速度太慢,需要用到的数据量巨大,耗费资源多,而且数据集越大,它的效率越低,随机梯度下降的范围太广,无法确定而且具有随机性,最后得出小批量梯度下降具有更实用的可用性,它的范围可确定且因为只取一小部分的数据集,每次进行的打乱操作shuffled(np.random.permutation)能确保实验数据不单一。
现在我们来做一个自定义随机数据集,要求非线性,然后用线性回归的方法拟合这个数据集,来看看效果如何:
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
m=100
x=6*np.random.rand(m,1)-3
y=0.5*x**2+x+np.random.randn(m,1)
plt.plot(x,y,'b.)
plt.xlable('x_1')
plt.ylable('y')
plt.axis([-3,3,-5,10])
pit.show()
from sklearn preprocessing import PolynomialFeatures
poly_features=PolynomialFeatures(degree=2,include_bias=False)
x_poly=poly_features.fit_transform(x)
from sklearn.linear_model import LinearRegression
lin_reg=LinearRegression()
lin_reg.fit(x_poly,y)
print(lin_reg.coef_)
print(lin_reg.intercept_)
##out:[[1.10879671 0.53435287]]
[-0.0376546]
可以看出最后输出的结果已经很好接近我们开始随机构造的函数y=0.5x^2+x+random
下面看一下模型复杂度:做实验 用不同的degree值看一下拟合效果长什么样子,可以看出degree值越大,过拟合风险越高
下面是在使用sklearn工具包时遇到的问题:
1.问:x=2*np.random.rand(100,1)是什么意思
1.这段代码是使用NumPy库生成一个形状为(100,1)的随机数组。
首先,import numpy as np语句是导入NumPy库,可以使用NumPy提供的函数和方法来进行数值计算和数组操作。
然后,x = 2*np.random.rand(100,1)这行代码将随机生成一个形状为(100,1)的数组,并将其赋值给变量x。
np.random.rand()是NumPy库中的一个函数,用于生成指定形状的随机数组。在这里,np.random.rand(100,1)生成了一个形状为(100,1)的随机数组,即包含100行、1列的数组。这里的随机数取值范围是0到1之间。
最后,乘以2的操作2*np.random.rand(100,1)会将生成的随机数组中的每个元素都乘以2,将数值范围从0到1扩大到0到2之间。
因此,将这个随机数组赋值给变量x后,x将包含100个随机数,且每个随机数的取值范围为0到2之间。
2.问:y=4+3*x+np.random.randn(100,1)是什么意思
2.
这段代码是在给定的输入数据 x 的基础上生成一个带有噪声的输出数据 y。
np.random.randn(100,1) 这部分代码使用了 NumPy 库的 random.randn 函数来生成一个形状为(100,1)的数组,其中的元素是从标准正态分布(均值为0,标准差为1)中随机抽样得到的。这个随机部分表示噪声。
在这个表达式中:
1、4 表示一个常数项,相当于函数的截距(intercept)。
2、3*x 表示一个线性项,其中的 3 是线性系数(slope),x 是输入数据。
3、np.random.randn(100,1) 是噪声项,用于模拟真实世界中的不确定性和随机性。
通过将这些项相加,即 4+3*x+np.random.randn(100,1),就得到了具有线性趋势并添加了噪声的输出数据 y。这个模型可以被用来模拟一个简单的线性回归问题,其中 x 是自变量,y 是因变量。模型的目标是根据 x 的值预测出相应的 y 值。噪声项的引入可以使模型更贴近真实世界的数据。
3.问:linspace(-3,3,100).reshape(100,1)是什么意思
3.
这段代码使用NumPy库中的linspace函数生成一个包含从-3到3的等间隔值的数组,并通过reshape方法将其形状改变为(100,1)。
具体解释如下:
1、linspace(-3, 3, 100) 是使用NumPy库的linspace函数生成一个包含100个等间距的数值的一维数组。
2、-3 是生成的数值范围的起始值。
3、3 是生成的数值范围的结束值。
4、100 是在指定的范围内生成的数值数量。
5、然后,.reshape(100,1) 是对生成的一维数组进行形状变换,将其改变为一个有100行、1列的二维数组。
6、reshape是NumPy数组对象的一个方法,用于改变数组的形状。
7、(100, 1) 是指定要将数组变换为100行、1列。
总结起来,linspace(-3, 3, 100).reshape(100, 1)的作用是生成一个形状为(100,1)的二维数组,其中包含从-3到3的等间距值。这个数组可以用作数据的输入(自变量)或者其他需要这种形状的操作。
4.preprocessing模块的作用
sklearn.preprocessing是scikit-learn(简称sklearn)库中的一个模块,用于数据预处理和特征工程。它提供了一系列预处理方法和工具函数,用于对数据进行转换、缩放、标准化、编码等操作,以准备数据用于机器学习算法的训练或评估。
在机器学习任务中,数据预处理是一个重要的步骤,它有助于提高模型的性能、处理缺失数据、处理异常值、将不同尺度的特征归一化等。sklearn.preprocessing模块提供了多种常用的预处理技术,包括但不限于以下几个方面:
1.数据缩放和标准化:如MinMaxScaler、StandardScaler,这些方法可以将特征缩放到指定的范围,或者对特征进行标准化,使其均值为0,方差为1。
2.特征编码:如OneHotEncoder、LabelEncoder,这些方法用于将离散的分类特征转换为数字编码,以便于算法处理。
3.数据变换:如PolynomialFeatures,这个类用于生成多项式特征,通过对原始特征的组合来引入非线性关系。
4.数据预处理管道:Pipeline,该类用于组合多个预处理步骤,使数据流水线化,便于数据的连续处理。
通过使用sklearn.preprocessing模块中的函数和类,可以在机器学习任务中更方便地进行数据预处理和特征工程,以提高模型的效果和泛化能力。
5.问:linearRegression.predict()能干嘛
linearRegression.predict()是线性回归模型中的一个方法,使用它应先from sklearn.linear_model import LinearRegression.用于根据输入数据预测对应的输出值。
线性回归是一种用于建模和预测连续数值输出的机器学习算法。它建立了输入特征和输出之间的线性关系,并通过找到最佳拟合线来进行预测。训练得到的线性回归模型可以用于预测新的输入数据对应的输出。
linearRegression代表线性回归模型的一个实例,而.predict()方法将用于预测新的输入数据的输出值。
具体使用方法如下:
1、在训练阶段,你需要先使用一组已知的输入数据和对应的输出数据来拟合(训练)线性回归模型。这可以通过调用线性回归模型的 .fit(X, y) 方法来完成,其中 X 是输入特征的数组,y 是对应的输出(目标)值的数组。
2、在模型训练完成后,你可以使用 .predict(new_X) 方法对新的输入数据 new_X 进行预测,得到对应的输出值。预测的结果是根据之前训练的模型参数和新的输入数据计算得到的。
这样,.predict() 方法可以帮助你使用已经训练好的线性回归模型来对新的输入数据进行预测,从而得到相应的输出值。
6.问:polynominalFeatures.fit_transform(x)用来干嘛,这个transform是啥意思?
PolynomialFeatures.fit_transform(x) 是多项式特征转换的方法,用于生成给定输入数据 x 的多项式特征矩阵。
多项式特征转换是一种常见的数据预处理技术,用于将原始输入数据 x 转换为包含多项式特征的扩展版本。这个转换可以帮助我们在线性模型中建模非线性关系。
在使用 PolynomialFeatures.fit_transform(x) 之前,首先需要导入 from sklearn.preprocessing import PolynomialFeatures,其中 sklearn 是 scikit-learn 库的简写。
具体解释如下:
1、PolynomialFeatures 是 scikit-learn 库中的一个类,用于生成多项式特征。
2、fit_transform() 是 PolynomialFeatures 类中的一个方法,用于拟合模型并进行特征转换。
3、x 是输入数据的特征矩阵,维度为 (nsamples, nfeatures)。
fit_transform(x) 方法的实际操作是进行以下几个步骤:
4、将输入数据 x 转换为包含多项式特征的形式。
例如,如果 x 是一个二维数组,形状为 (nsamples, nfeatures),经过多项式特征转换后,输出的特征矩阵将包含所有输入特征的各种次方组合。这将产生一组新的特征列,用于捕捉输入特征之间的多项式关系。
5、对转换后的特征矩阵应用适当的标准化(可选步骤)。
这一步骤有助于确保特征具有相似的尺度,以避免某些特征对模型的影响过大。
最终,fit_transform(x) 返回转换后的多项式特征矩阵,具有扩展的特征空间,可以用于训练和拟合模型。这个转换可以帮助我们更好地捕捉数据中的非线性关系,从而提高模型的准确性和表现力。
———————————————————————————————————————————
模型复杂度
那么在实际实验过程中,我们应该尽可能选择什么样的模型拟合数据使得拟合结果更好呢?这里我们手动做一个数据集
from sklearn preprocessing import PolynomialFeatures
poly_features=polynomialFeatures(degree=2,include_bias=False)
x_new=np.linspace(-3,3,100).reshape(100,1)
x_new_poly=poly_features.transform(x_new)
y_new=lin_reg.predict(x_new_poly)
plt.plot(x,y,'b')
plt.plot(x_new,y_new,'r__',lable='prediction')
plt.axis([-3,3,-5,10])
plt.show()
这里的degree值选的是2,符合线性方程表达式,我们再做一个实验,看看不同的degree值会表现出什么样的拟合程度:
这里我们用到sklearn中的pipeline,简单说明一下这个类的作用:
sklearn.pipeline.Pipeline 是scikit-learn库中的一个类,用于将多个数据处理步骤(例如特征提取、预处理和模型训练)组合成一个整体的机器学习流水线。
Pipeline类的主要目的是将数据处理流程封装为一个可执行的模型对象,使得数据的处理过程更加简洁、可读性更高,并且方便进行交叉验证和模型评估。
使用Pipeline有几个好处:
1.简化代码:通过将多个步骤连接在一起,代码更加简洁易读,并且可以以一种连续流水线的方式直接进行数据处理和模型训练。
2.避免数据泄露:通过将数据处理步骤和模型训练步骤封装在同一个流水线中,可以避免在交叉验证或测试集上的数据泄露问题。
3.重复使用和共享:将数据处理和模型训练封装为一个Pipeline对象后,可以方便地进行复用和共享,减少重复代码的编写。
使用Pipeline需要以下步骤:
4.定义步骤:创建一个由多个元组组成的列表,每个元组表示一个处理步骤,包括步骤的名称和对应的处理器(如特征变换器、预处理器或模型)。
5.创建Pipeline对象:使用定义的步骤列表来实例化Pipeline对象。
6.拟合和预测:使用Pipeline对象的fit方法拟合数据并使用predict方法进行预测。
通过使用Pipeline,可以将多个数据处理和模型训练步骤组织在一起,形成一个整体的机器学习流水线,并简化机器学习工作流程的实现和管理。
可以看出,模型越复杂 拟合效果越不好过拟合风险越大,所以我们应尽可能使用简单模型。
———————————————————————————————————————————
样本数量对结果的影响
在sklearn中还有一个Metrics模块,里面包括有且不限于classification metrics,regression metrics类分别解决分类问题和回归问题,回顾一下之前我们用Mnist数据集做的分类模型,里面包括数据集切分,洗牌操作(np.random.permutation),交叉验证,交叉验证的具体做法用到了sklearn.model_selection模块下的cross_val_score函数,该函数可以将数据集自动切分成你要的份数,并且根据你要的评判指标给出结论,分类器(sgd_clf),分类器必须配备两个阵列,一个大小为[n_samples,n_features]的数组x,用于保存训练样本,一个大小为[n_samples]的数组y,用于保存训练样本的类标签。又学了混淆矩阵 TP,FP,FN,TN。评估指标对比分析(精度和召回率分别只能表现出一个维度,这里我们用f1_score值精度和召回率调和平均的结果更可靠,这仨指标都在sklearn.metrics模块中,另外我们还学到一个ROC曲线,它是一个二维的图像,纵轴是True positive rate横轴是false positive rate,要计算这俩值,首先需要使用sklearn.metrics模块中的roc_curve()函数,这个曲线的物理意义是曲线下的阴影面积越大,分类越完美,纯随机分类器的ROC AUC等于0.5,要计算ROC AUC用from sklearn.metrics import roc_auc_score).
回到题目,样本数量对结果的影响,我们把数据集分为训练样本和验证样本,总样本数100,训练样本的数量从1-80,评判指标用均方误差来表示,看随着训练样本数目的增加,真实值与预测值之间的均方误差是否有变化,变化是怎么样的。
1.均方误差mean_squared_error
均方误差代表了两值差异大小,均方误差越大,说明两值越不同,使用:from sklearn.metrics import mean_squared_error
这个函数只需要输入真实值和预测值,就能计算出均方误差。
2.数据集切分函数
使用:from sklearn.model_selection import train_test_split
这个函数只需要给出样本值,标签值,测试集比例和随机种子,就可以返回切好的训练集样本,验证集样本,训练集标签,测试集标签。
先制造数据集
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
m=100
x=6*np.random.rand(m,1)-3
y=0.5*x**2+x+np.random.randn(m,1)
print(x[0])
plt.plot(x,y,'b.')
plt.xlabel('x_1')
plt.ylabel('y')
plt.axis([-3,3,-5,10])
plt.show()
数据集长这个样子

然后切分数据集,用均方误差求得模型的训练集样本和验证集样本在样本数量不同时预测结果与实际结果的误差大小变化对比:
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
def plot_learning_curves(model,x,y):
x_train,x_val,y_train,y_val=train_test_split(x,y,test_size=0.2,random_state=0)
train_errors,val_errors=[],[]
for m in range(1,len(x_train)):
model.fit(x_train[:m],y_train[:m])
y_train_predict=model.predict(x_train[:m])
y_val_predict=model.predict(x_val)
train_errors .append(mean_squared_error(y_train[:m],y_train_predict))
val_errors.append(mean_squared_error(y_val,y_val_predict))
plt.figure()
plt.plot(np.sqrt(train_errors),'r-+',linewidth=2,label='train_error')
plt.plot(np.sqrt(val_errors),'b-',linewidth=3,label='val_error')
plt.legend()
plt.axis([0,80,0,3])
plt.show()
lin_reg=LinearRegression()
plot_learning_curves(lin_reg,x,y)
最后的图长这个样子:
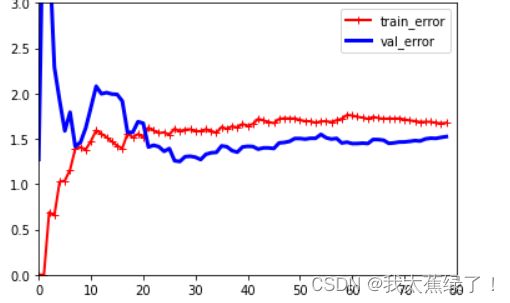
3.实验结果
训练样本少时,训练集均方误差小,但是测试集均方误差大,这样容易过拟合,当训练样本逐渐增多,训练集均方误差逐渐增大,测试集均方误差逐渐减小,最好的情况是两者差异越小越好,也就是缝隙最窄时,这时的过拟合风险降到最低。
正则化的作用
模型在训练时的效果很好,实际测试效果远达不到之前的效果,就叫过拟合,过拟合的表现形式是曲线过于复杂,模型泛化能力弱,适当减小高次项影响,就叫正则化。
正则化的目的:限制模型参数过多或过大,正则化可以一定程度防止过拟合,让模型获得抗噪声的能力,这将提升模型对未知样本的预测性能。
L2岭回归:
从公式可以看出,当θ大时,损失函数就会增大,所以就会尽可能使θ值变小,