自监督学习初步认识
自监督学习self-supervised learning)
目录
1、定义
2、自监督学习存在的意义以及能work的思考
1)利用了自然界中存在的先验信息
2)数据之间的连贯性
3)数据内部结构信息
3、自监督学习的两个阶段思路分析
3.1 第一阶段pretrain
3.2 第二个阶段
4.自监督学习第一阶段中的pretext task理解
4.1 博客1提到两种主要技术路线:对比学习和生成学习
4.1.1 对比学习
4.1.2 生成学习
4.2 博客2提到了这四种pretext task
4.2.1基于生成的方法:
4.2.3基于免费语义标签的方法:
4.2.4基于跨模态的方法:
4.3 博客3也提到了三类pretext task方法
5.自监督学习两个阶段的loss理解
1、定义
Self-Supervised Learning,又称为自监督学习,我们知道一般机器学习分为有监督学习,无监督学习和强化学习。 而 Self-Supervised Learning 是无监督学习里面的一种,主要是希望能够学习到一种通用的特征表达用于下游任务 (Downstream Tasks)。

自监督学习主要是利用辅助任务(pretext)从大规模的无标签数据中挖掘自身的标签信息,通过这种构造的标签信息对网络进行训练,从而可以学习到对下游任务有价值的表征。 也就是说,自监督学习不需要任何的有标签数据,这些标签是从输入数据自身中得到的。自监督学习的模式仍然是Pretrain-Fintune的模式,即第一阶段先在pretext上进行预训练,然后第二阶段将学习到的参数迁移到下游任务网络中,进行微调得到最终的网络。
2、自监督学习存在的意义以及能work的思考
减少人工成本:因为深度神经网络很大性能上取决于模型能力和训练的数据量。但是大规模数据集标注过程中需要大量的人力财力消耗。还有一种更未来的意义可能就是探索未来的AI学习的方式。
他为什么能wrok?这篇博客给出了几点思考,如下:
1)利用了自然界中存在的先验信息
物体的类别和颜色之间存在关联;物体类别和形状纹理之间的关联;物体默认朝向和类别之间的关联;运动学属性;

2)数据之间的连贯性
图像具有空间连贯性;视频具有时间连贯性;

3)数据内部结构信息
略。
3、自监督学习的两个阶段思路分析
Self supervised learning大致训练有两个阶段,第一个阶段需要对模型进行训练提取通用表征,官方语言表达叫做:in a task-agnostic way,第二阶段根据特定的下游任务(下游数据集,有标签)做fine tune,官方语言叫做in a task-specific way。

3.1 第一阶段pretrain
第1个阶段不涉及任何下游任务,就是拿着一堆无标签的数据去预训练,没有特定的任务,这个话用官方语言表达叫做:in a task-agnostic way。首先第一阶段也是和有监督训练一样是一个完整的训练过程。首先输入的数据有两组,虽然数据集是无标签数据,但是研究者还是想到了训练初始网络的办法。我们将原始数据X复制一份作为label,记作Y,然后将原始数据X进行mask或者其他pretext task(伪标签可以是根据数据属性自动生成的)操作,将pretext task之后的数据作为网络输入训练网络,我们期望网络可以尽可能完整的恢复原始的数据X,这个阶段的loss是通过网络预测的数据和原始的我们复制的那一份数据Y做loss。注意:这个阶段的loss函数选择我存在疑问,还需要查看资料和代码,初步了解到的信息是根据不同的pretext task选择不同的loss。等待后续补充。下图是以mask操作为例的图示。
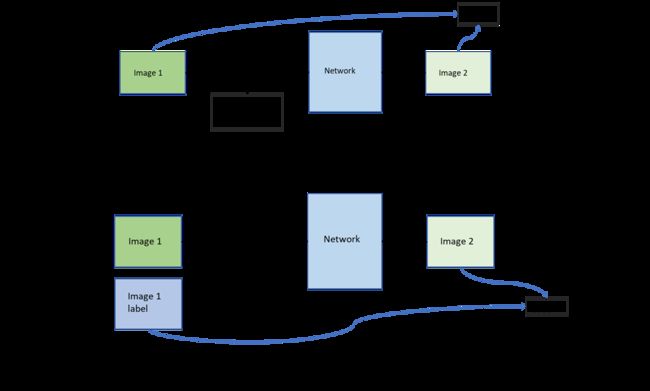
BERT的pretext Task举例:

在训练模型的时候使用mask随机覆盖输入数据的token,如图中的湾字。接下来把这个盖住的token对应位置输出的向量做一个Linear Transformation,再做softmax输出一个分布,这个分布是每一个字的概率。因为这时候BERT并不知道被 Mask 住的字是 "湾" ,但是我们知道啊,所以损失就是让这个输出和被盖住的 "湾" 越接近越好。
Pretext Task 就是填空的任务,这个任务和下游任务毫不相干,甚至看上去很笨,但是 BERT 就是通过这样的 Pretext Task学习到了很好的 Language Representation,很好地适应了下游任务。
3.2 第二个阶段
第二个阶段主要是使用pretrain的网络对特定下游任务做一个fine tune。比如针对分割任务,对于pretrain网络来说我们需要输入分割的image 和label 对网络进行简单的调整。这个阶段的loss大部分还是使用cross entropy(这个loss函数的选择就和有监督学习中的loss一致)。个人理解这个阶段可以类比有监督学习中的迁移学习,将网络的权重固定,然后对网络后几层进行微调。
4.自监督学习第一阶段中的pretext task理解
4.1 博客1提到两种主要技术路线:对比学习和生成学习
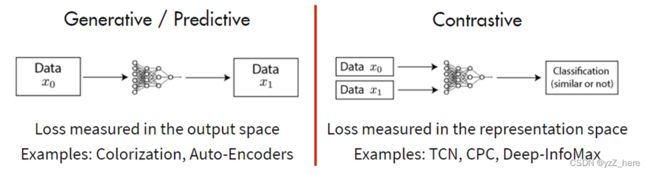
自监督学习又可以分为对比学习(contrastive learning) 和 生成学习(generative learning) 两条主要的技术路线。
4.1.1 对比学习
对比学习核心思想是将正样本和负样本在特征空间进行对比,学习样本的特征表示,难点在于如何构造正负样本。对比学习首先学习未标记数据集上图像的通用表示形式,然后可以使用少量标记图像对其进行微调,以提升在给定任务(例如分类)的性能。对比表示学习可以被认为是通过比较来学习样本的表示。而生成学习(generative learning)是学习某些(伪)标签的映射的判别模型然后重构输入样本。在对比学习中,通过在输入样本之间进行比较来学习表示。对比学习不是一次从单个数据样本中学习信号,而是通过在不同样本之间进行比较来学习。可以在“相似”输入的正对和“不同”输入的负对之间进行比较。
对比学习通过同时最大化同一类样本的表示之间的相似性,以及最小化不同类样本之间的相似性来学习的。 简单来说,就是对比学习要做到相同类别的样本的表示要相近,所以要最大化同一类样本的表示之间的相似性。相反,如果是不同类别的样本,就要最小化它们之间的相似度。通过这样的对比训练,编码器(encoder)能学习到样本的更高层次的通用特征 (sample-level representations),而不是属性(像素)级别的生成模型(attribute-level generation)。


4.1.2 生成学习
基于自监督学习的生成学习方法主要有AE、VAE、GAN这三大种,其中VAE是基于AE的基础上进行变形的生成模型,而GAN是近年来较为流行并有效的生成式方法。近期diffusion model也属于生成模型中的一大热点。
4.2 博客2提到了这四种pretext task
基于生成,基于上下文,基于免费语义标签和基于跨模态这四种,如下图所示。

4.2.1基于生成的方法:
这种类型的方法通过解决涉及图像或视频生成的代理任务来学习视觉特征。
• 图像生成:通过图像生成任务的过程学习视觉特征。这种类型的方法包括图像着色[18],图像超分辨率[15],图像修复[19],生成对抗网络(GAN)生成图像[83],[84]。
• 视频生成:通过视频生成任务的过程学习视觉特征。这种类型的方法包括使用GAN [85],[86]和视频预测[37]进行视频生成。
4.2.2基于上下文的方法:
基于上下文的代理任务的设计主要利用图像或视频的上下文特征,例如上下文相似性,空间结构,时间结构等。
• 上下文相似度:代理任务是根据图像块之间的上下文相似度设计的。这种类型的方法包括基于图像聚类的方法[34],[44]和基于图约束的方法[43]。
• 空间上下文结构:代理任务是根据图像块之间的空间关系设计的。这种类型的方法包括图像拼图[20],[87],[88],[89],上下文预测[41]和几何变换识别[28],[36]等。
• 时间上下文结构:视频的时间顺序用作监控信号。对ConNet进行训练,以验证输入帧序列是否以正确的顺序[40],[90]或识别帧序列的顺序[39]。
4.2.3基于免费语义标签的方法:
这种类型的方法通过自动生成的语义标签来训练网络。 标签由传统的硬编码算法[50],[51]或游戏引擎[30]生成。 包括运动对象分割[81],[91],轮廓检测[30],[47],相对深度预测[92]等。
4.2.4基于跨模态的方法:
这种类型的代理任务训练ConvNet,以验证输入数据的两个不同通道是否彼此相对应。 这种类型的方法包括视音频对应验证[25],[93],RGB流对应验证[24]和自我感应[94],[95]。
4.3 博客3也提到了三类pretext task方法
略。
5.自监督学习两个阶段的loss理解
先占坑。
refer:
http://t.csdn.cn/Sf9wg;Self-Supervised Learning 超详细解读 (四):MoCo系列解读 (1) - 知乎 (zhihu.com);
自监督学习综述 | Self-supervised Visual Feature Learning with Deep Neural Networks: A Survey - 简书 (jianshu.com);
自监督学习_就叫俩美的博客-CSDN博客
Label smoothing Example:
当标签为labels = np.array([[7], [3]])时,编码后的标签为:

使用如下代码进行label smoothing

当标签为labels = [3, 5],编码后的标签为:
