面试 | 3.5 万字总结 Java 后台研发常见面试题
面试 | 3.5 万字总结 Java 后台研发常见面试题
- 前言
- 1. 编程语言
-
- 1.1 Java 基础(部分)
-
- 1. String、StringBuffer 与 StringBuilder
- 2. 接口与抽象类
- 3. 成员变量与局部变量
- 4. == 与 equals
- 5. final
- 6. 重载与重写
- 7. 不想被序列化、IO流、继承调用优先级、反射、protect
- 8. 类与对象
- 9. 继承、封装、多态
- 10. Java 反射机制
- 11. 自动装箱与拆箱
- 1.2 Java 集合
-
- 1. ArrayList、LinkedList、Vector
- 2. ArrayList 扩容机制
- 3. HashMap、HashTable、ConcurrentHashMap、LinkedHashMap、TreeMap
- 4. HashMap 并发成环问题
- 5. HashMap 链表转红黑树阈值为什么是 8;红黑树转链表阈值为什么是 6
- 6. HashSet、LinkedHashSet、TreeSet
- 7. 红黑树
- 1.3 Java 多线程
-
- 1. 线程、进程基本状态
- 2. sleep() 与 wait()
- 3. start() 与 run()
- 4. 双重校验锁实现对象单例
- 5. synchronized 与 volatile
- 6. JMM(Java 内存模型)
- 7. ThreadLocal
- 8. Runnable 与 Callable 接口
- 9. execute() 方法与 submit() 方法
- 10. 创建线程池
- 11. ThreadPoolExecutor 饱和策略
- 12. Atomic 原子类、JUC 包下的原子类
- 13. AQS
- 14. AtomicLong 高并发性能问题
- 15. LongAdder 比 AtomicLong 的优化
- 16. CAS 算法
- 1.4 JVM
-
- 1. 运行时数据区、垃圾回收与内存分配、性能调优与案例分析
- 2. 类文件结构、类加载机制、虚拟机字节码执行引擎
- 1.5 Python 相关
- 2. 计算机基础
-
- 2.1 计算机网络
-
- 1. OSI 七层、CP/IP四层、五层协议
- 2. TCP 可靠传输、拥塞算法
- 3. URl-过程
- 4. 状态码
- 5. HTTP/1.0 与 HTTP/1.1
- 6. HTTPS 建立过程(SSL 建立的四次握手)
- 7. HTTPS 与 HTTP 特点
- 8. Session 与 Cookie
- 9. TCP 建立连接三次握手(TCP/IP 协议)
- 10. TCP 断开四次握手(TCP/IP 协议)
- 2.2 操作系统
- 2.3 数据结构与算法
-
- 1. 图的遍历
- 2. 排序算法
- 3. 参考文章
- 2.4 设计模式七大原则
- 3. 数据库
-
- 3.1 MySQL
-
- 1. MyISAM 与 InnoDB
- 2. InnoDB 引擎4大特性
- 3. MVCC
- 4. 共享锁、排它锁
- 5. 乐观锁、悲观锁
- 6. 事务的四大特性(ACID)
- 7. 并发 事务问题 与 隔离级别
- 8. join
- 9. 大表优化
- 10. 分库分表后的问题
- 11. 慢查询原因及解决方法
- 12. 索引使用场景
- 13. 索引类型
- 14. 创建索引的原则
- 15. 添加索引优化查询
- 16. MySQL 的联合索引
- 17. 查询、更新 SQL 如何执行
- 18. 为什么用两个日志模块,redo log 的两提交阶段
- 19. bin log 录入格式
- 20. MySQL中的七种日志
- 21. undo log、redo log、bin log 的应用
- 22. 数据库三大范式
- 23. SQL 偶尔执行慢
- 24. SQL 总是执行慢
- 25. InnoDB存储引擎锁算法
- 26. 数据库三大范式
- 27. MySQL 的权限表
- 28. B 树、B+ 树和 hash 索引
- 29. 如何理解稳定性
- 30. MySQL 为什么不用红黑树
- 31. B+ 树是如何降低 IO 的
- 32. B+ 树索引是怎么通过磁盘查找数据的
- 33. B 和 B+ 树的查找支持
- 34. 键
- 35. SQL 约束
- 36. int(10)、char(10)、varchar(10)
- 37. drop、delete、truncate
- 3.2 Redis
-
- 1. 分布式缓存区别:Memcached 和 Redis
- 2. 数据结构
- 3. 文件事件处理器
- 4. 过期数据删除策略
- 5. 内存淘汰机制
- 6. 两种持久化技术
- 7. Redis 事务
- 8. 缓存问题(数据库本身|数据|业务)
- 9. 缓存与数据库数据一致性
- 10. 服务器的复制
- 11. Sentinel 连接
- 12. Sentinel 主服务器下线
- 13. Redis为什么快
- 14. 应用场景
- 15. I/O 多路复用程序的实现
- 16. Redis 的单进程单线程误区
- 17. Sentinel 哨兵模式
- 18. 参考文章
- 4. 后端框架(这后面为加分项,可以不用看)
-
- 4.1 Spring
-
- 0. 参考文章
- 4.2 Spring Boot
-
- 0. 参考文章
- 4.3 Zookeeper
- 4.4 Oauth2
- 4.5 Nacos
-
- 1. SpringCloud 客户端集成 Nacos
- 2. 服务的注册服务实例
- 3. 服务端查询服务实例
- 4. Nacos 服务地址动态感知原理
- 5. Spring Cloud 加载配置原理
- 6. 客户端的长轮询定时机制
- 7. 服务端的长轮询定时机制
- 8. 服务器修改配置
- 4.6 Sentinel
-
- 1. 如何拦截请求
- 2. Sentinel 的工作原理
- 3. 流控槽 lowSlot
- 4. 熔断槽 DegradeSlot
- 5. 统计槽 StatisticSlot
- 4.7 Tars
-
- 1. 介绍
- 2. 协议
- 4.8 Spring Cloud Config
- 4.9 Eureka
- 5. 分布式相关
-
- 5.1 Spring Cloud 微服务架构
- 5.2 分布式事务
-
- 1. 术语
- 2. 2PC、3PC、TCC
- 3. Seata AT
- 4. Saga
- 5.3 常见 流量控制/限流 算法
- 5.4 Hash 算法相关(一致 hash)
- 5.5 CDN
-
- 1. CDN 是什么
- 2. 工作原理
- 5.6 CAP 理论
- 5.7 BASE 理论
- 5.8 分布式追踪
- 6. 机器学习
-
- 6.1 机器学习
-
- 1. 机器学习算法分类
- 2. 机器学习开发流程
- 3. 模型选择与调优
- 4. [分类] K-近邻算法(KNN 算法)
- 5. [分类] 朴素贝叶斯算法
- 6. [分类] 逻辑回归与二分类
- 7. [回归] 线性回归
- 8. [回归] 岭回归
- 最后
前言
回馈社区,第100篇,纪念秋招!
本篇笔记为笔者备战暑期实习生和秋招期间做的知识点总结与汇总。在 Java 大后端学习过程中有很多易难记的知识点,本篇笔记就是用来记录和区分这些知识点的;
本篇笔记面向的读者是准备面试的同学,问题源于平时积累与一些真实面试问题,因此不可能面面俱到,如有错误,欢迎指正!
如果您的时间足够,建议以本篇笔记的目录为索引,在网上找一些课程或书籍打好基础。打好基础很重要!打好基础很重要!打好基础很重要!如果您的时间不足,建议先阅读《Guide 哥的 Java 面试突击》里面对一些常见的高频面试问题做了很好的汇总;然后自己做笔记或参照这篇,对一些难记、易混淆的知识点做进一步巩固记忆;
最后,祝大家都能如愿收获 Offer!
1. 编程语言
1.1 Java 基础(部分)
1. String、StringBuffer 与 StringBuilder
| 比较项 | String | StringBuffer | StringBuilder |
|---|---|---|---|
| 安全 | final,线程安全 | 同步锁 | 非线程安全,性能较高 |
| 适用 | 少量数据 | 多线程,字符串缓冲区 | 单线程,字符串缓冲区 |
| 父类 | Object | AbstractStringBuilder | 同 AbstractStringBuilder |
2. 接口与抽象类
| 比较项 | 接口 | 抽象类 |
|---|---|---|
| 修饰符 | static、final | 没要求 |
| 访问修饰符 | 方法默认 public | 不能用 private |
| 设计角度 | 行为规范 | 模板设计 |
3. 成员变量与局部变量
| 比较项 | 成员变量 | 局部变量 |
|---|---|---|
| 归属 | 类 | 方法 |
| 修饰符语法 | 无限制 | 不能有访问修饰符与 static |
| 存储方式 | static 修饰类->方法区,修饰实例->堆 | 基本类型->栈,引用类型->堆内存的引用或指向常量池的地址 |
| 生命周期 | 对象 | 方法调用 |
| 赋初值 | 默认值 | 不会自动赋值 |
4. == 与 equals
| == | equals |
|---|---|
| 基本类型比较值,引用类型比较地址 | 未覆盖时比较地址,覆盖按自定义 |
5. final
| 修饰 | 说明 |
|---|---|
| 变量 | (一般静态变量 final + static)基本类型值不变。引用类型指向不变 |
| 类 | 不能继承。方法默认 final |
| 方法 | 不能修改。早期转为内嵌调用 |
6. 重载与重写
| 比较项 | 重载 | 重写 |
|---|---|---|
| 通俗来说 | 根据输入数据的不同,做出不同的处理 | 覆盖父类方法 |
| 发生范围 | 同一个类 | 子类 |
| 时期 | 编译期 | 运行期 |
| 返回值、异常 | 可改 | 相同或更小(子类) |
| 方法名 | 同 | 同 |
| 参数 | 必改 | 不可改 |
7. 不想被序列化、IO流、继承调用优先级、反射、protect
不想被序列化:transient 关键字。序列化时阻止,反序列化时不恢复;
IO 流:InputStream 字节输入流。OutputStream 字节输出流。Reader 字符输入流。Writer 字符输出流;
继承调用优先级:this.show(O)、super.show(O)、this.show((super)O)、super.show((super)O);
反射:获取类对象:对象.getClass [已有对象]、类.class [需要导包]、Class.forName(类路径) [常用]
protect:在同一个包下、存在继承关系时可以访问;
8. 类与对象
- 栈内存(类)与堆内存(对象):
- 栈内存:保存的是堆内存的地址(指针);
- 堆内存:保存对象的属性内容。堆内存需要用new关键字来分配空间;
9. 继承、封装、多态
- 继承:继承是使用已存在的类的定义作为基础建立新类的技术,新类的定义可以增加新的数据或新的功能,也可以用父类的功能,但不能选择性地继承父类。(证书项目的上传图片业务——向上转型)
- 构造器:不能被继承,如果父类没有默认构造器,我们就要必须显示的使用super()来调用父类构造器;
- protected:对于任何继承与此类的子类而言或者其他任何位于同一个包的类而言,他是可以访问的;
- 谨慎继承:继承是一种强耦合关系;
- 封装:用户是无需知道对象内部的细节,封装的是自己的属性和方法。隐藏信息,实现细节,减少耦合
- 多态:不修改程序代码就可以改变程序运行时所绑定的具体代码,让程序可以选择多个运行状态;多态性就是相同的消息使得不同的类做出不同的响应
- 对于面向对象而言,多态分为编辑时多态(方法重载)和运行时多态(动态绑定)。其中编辑时多态是静态的,主要是指方法的重载,它是根据参数列表的不同来区分不同的函数,通过编辑之后会变成两个不同的函数,在运行时谈不上多态。而运行时多态是动态的,它是通过动态绑定来实现的,也就是我们所说的多态性。(新建接口的方法重载)
- 在Java中有两种形式可以实现多态:继承和接口;
- 在继承链中对象方法的调用存在一个优先级:
this.show(O)、super.show(O)、this.show((super)O)、super.show((super)O)
10. Java 反射机制
- 一句话:动态获取的信息以及动态调用对象的方法;
- 具体来说:在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;
- 使用的前提条件:必须先得到代表的字节码的Class;
- 通过反射获取类的对象的三种方式:
对象.getClass[已有对象]、类.class[需要导包]、Class.forName(类路径)[常用]; - 通过反射获取构造方法:先通过类路径获得类对象 clazz,
clazz.getConstructors()[所有公有构造方法]、clazz.getDeclaredConstructors()[所有的构造方法]、clazz.getConstructor(null)[获取公有、无参的构造方法]、clazz.getDeclaredConstructor(char.class)[获取私有构造方法,并调用] - 通过反射获取构造方法并创建对象:
clazz.getConstructor().newInstance() - 获取成员变量并调用:先通过类路径获得类对象 clazz,
clazz.getFields()[获取所有公有的字段]、clazz.getDeclaredFields()[获取所有的字段(包括私有、受保护、默认的)]、clazz.getField("xx")[获取公有字段xx并调用]、clazz.getDeclaredField("xx")[获取私有字段xx并调用——追加.setAccessible(true)可以暴力反射,解除私有限定] - 获取成员方法并调用:
stuClass.getMethods() - 反射main方法:
clazz.getMethod("main", String[].class)[第一个参数:方法名称,第二个参数:方法形参的类型];
11. 自动装箱与拆箱
- 装箱:将基本类型用它们对应的引用类型包装起来;
- 包装类的 valueOf() 方法:
Integer i = Integer.valueOf(10);
- 包装类的 valueOf() 方法:
- 拆箱:将包装类型转换为基本数据类型;
- xxxValue()方法:
int n = i.intValue();
- xxxValue()方法:
1.2 Java 集合
1. ArrayList、LinkedList、Vector
共同点:有序、可重复、实现List接口、类似数组;
| 比较项 | ArrayList | LinkedList | Vector |
|---|---|---|---|
| 线程安全 | 不安全 | 不安全 | 安全 |
| 底层 | Object[] | JDK1.6 前为循环链表,后为双向链表 | Object[],所有方法同步处理 |
| 修改操作 | 受元素位置影响 | 不影响 | |
| 快速随机访问 | 支持,实现 RandomAccess 接口 | 不支持 | |
| 内存 | 预留空间 | 每个元素空间较大 |
2. ArrayList 扩容机制
在调用 add() 方法时,会调用 ensureCapacityInternal() 方法扩容,其中形参为最小扩容量minCapacity。当修改后的数组容量大于当前的数组长度,调用grow()扩容。有三种情况:
1. 当前数组由默认构造方法生成,并且第一次添加数据:将数组容量由0扩容为10(最小扩容量为10),后续1.5倍扩容;
2. 当前数组由自定义初始容量构造方法生成:前4次+1(最小扩容量为1)扩容,后续1.5倍扩容;
3. 扩容量(newCapacity)大于Integer的最大值时:抛OutOfMemoryError异常;
3. HashMap、HashTable、ConcurrentHashMap、LinkedHashMap、TreeMap
共同点:键值对、Key 不可重复的(无序的)、value 可重复的(无序的);
| 比较项 | HashMap | HashTable | ConcurrentHashMap | LinkedHashMap | TreeMap |
|---|---|---|---|---|---|
| 线程安全 | 不安全,多线程下数据丢失 | 安全 | 安全 | 不安全 | 不安全 |
| 安全机制 | JDK1.8 前超过容量 rehash,可能形成环形链表 | synchronized 全局锁 | JDK1.8 前分段锁,后头节点锁(synchronized) | ||
| 底层 | JDK1.8 前数组+链表,后数组+链表/红黑树 | 数组+链表 | JDK1.8 前分段数组+链表,后数组+链表/红黑树 | 跟 HashMap 类似,不过引入双向链表保证有序 | 红黑树 |
| 效率 | 较高 | 较低,淘汰 | 较高 | ||
| Null key/value | key允许1个,value多个 | 不允许 | 不允许 | 允许 | key不允许,value允许 |
| 初始大小与扩容(无初始值) | 初始 16,扩容 2 倍 | 初始 11,扩容 2n+1 | |||
| 初始大小与扩容(有初始值) | 2的幂次方 | 按初始值 |
- TreeMap:通过实现 NavigableMap 接口(支持快速搜索符合条件的最近的元素)继承了 SortedMap 接口(支持有序),来实现有序;
4. HashMap 并发成环问题
假设 2 个线程同时进行 rehash,将数组大小由2扩展为4。线程1的 node.val 指向 Key(3),node.next 指向 Key(7)。这时线程2率先完成 rehash,让链表里 Key(7) 指向 Key(3)。这时线程1工作,让 key(3) 指向 Key(7),由此成环;
这里建议结合源码理解;
5. HashMap 链表转红黑树阈值为什么是 8;红黑树转链表阈值为什么是 6
链表转红黑树:hashcode 碰撞次数与泊松分布有关,hash 发生 8 次碰撞时概率降到了 0.00000006,几乎为不可能事件。所以在一般情况下都是为链表,只有在极端情况下才会使用红黑树提高性能;
红黑树转链表:如果也将该阈值设置于 8,那么当 hash 碰撞在 8 时,会反生链表和红黑树的不停相互激荡转换,白白浪费资源。中间有个差值 7 可以防止链表和树之间的频繁转换;
6. HashSet、LinkedHashSet、TreeSet
共同点:不可重复、唯一值、(无序);
| 比较项 | HashSet | LinkedHashSet | TreeSet |
|---|---|---|---|
| 特点 | 线程不安全的,可以存储 null 值 | 按照添加的顺序遍历 | 按照添加元素的顺序进行遍历,排序的方式有自然排序和定制排序 |
| 底层 | HashMap | LinkedHashMap | 红黑树 |
注意:在 Java 中没有线程安全的 ConcurrentHashSet,但可以根据 ConcurrentHashMap 创建支持线程安全的 ConcurrentHashSet;
7. 红黑树
- 《TreeMap》;
- TreeMap的实现是红黑树算法的实现;TreeMap是一个能比较元素大小的Map集合,会对传入的key进行了大小排序;
- 每个节点都只能是红色或者黑色;
- 根节点是黑色;
- 每个叶节点(NIL节点,空节点)是黑色的;
- 如果一个结点是红的,则它两个子节点都是黑的;
- 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点;
1.3 Java 多线程
1. 线程、进程基本状态
线程:初始、运行、阻塞、等待、超时等待、终止;
进程:创建、就绪、运行、阻塞、结束;
2. sleep() 与 wait()
共同点:暂停线程执行;
| 比较项 | sleep() | wait() |
|---|---|---|
| 锁 | 不释放(synchronized里使用该方法) | 释放 |
| 作用 | 暂停执行 | 线程间交互 |
| 苏醒 | 自动 | notify() 或者 notifyAll() |
3. start() 与 run()
| 比较项 | start() | run() |
|---|---|---|
| 含义 | 启动线程进入就绪状态,分配到时间片后开始运行——调用run()方法 | 当成一个 main 线程下的普通方法去执行 |
| 由谁决定调用 | 线程调度器 | Java虚拟机在运行相应线程时直接调用 |
4. 双重校验锁实现对象单例
public class Singleton {
private volatile static Singleton uniqueInstance;
private Singleton() {
}
public static Singleton getUniqueInstance() {
//先判断对象是否已经实例过,没有实例化过才进入加锁代码
if (uniqueInstance == null) {
//类对象加锁
synchronized (Singleton.class) {
if (uniqueInstance == null) {
uniqueInstance = new Singleton();
}
}
}
return uniqueInstance;
}
}
volatile 保证指令不重排:分配内存空间、初始化对象、对象引用指向堆内存;
5. synchronized 与 volatile
共同点:保证数据可见性、有序性(指令重排);
| 比较项 | synchronized | volatile |
|---|---|---|
| 级别 | 早期重量级,现在做了优化 | 轻量级 |
| 作用 | 方法与代码块 | 变量 |
| 数据可见性 | 保证 | 保证 |
| 原子性 | 保证(使用锁操作共享数据) | 不保证 |
| 解决 | 多线程间访问资源同步性 | 变量在多线程间可见性 |
| 其他作用 | 同步块里可能指令重排 | 禁止指令重排序(双重校验锁实现对象单例)、不能保证原子性 |
6. JMM(Java 内存模型)
Java虚拟机使用一种Java内存模型来屏蔽硬件与操作系统的差异。JDK1.2 前从共享内存(主存)读取变量。当前把变量保存在本地内存(寄存器),可能一个线程在修改主存,另一个线程修改本地内存,导致数据不一致。可以使用 volatile 保证数据可见性;
7. ThreadLocal
实现每一个线程都有自己的专属本地变量。底层是 ThreadLocalMap 类型的变量,通过 set 或 get 方法修改专属本地变量。其中 key 为弱引用,value 为强引用。无外部强应用情况下,垃圾回收导致 key 被清理,value 无法被回收,导致内存泄露。解决方法:使用完 ThreadLocal 后调用 remove() 方法;
8. Runnable 与 Callable 接口
共同点:都可以作为任务去执行、接口、可编写多线程程序、采用Thread.start()启动线程;
| 比较项 | Runnable | Callable |
|---|---|---|
| 时间 | JDK1.0 | JDK1.5 |
| 异常处理 | 不会返回结果或抛出检查异常 | 会 |
| 需要实现的方法 | run() | call() |
| 返回值 | 无 | 返回泛型,与Future、FutureTask配合可以用来获取异步执行的结果 |
| 实例创建 | 需要Thread包装启动 | 先通过FutureTask包装再通过Thread包装执行 |
9. execute() 方法与 submit() 方法
共同点:可向线程池中提交一个任务、可接受Runnable类型的任务、可从ExecutorService接口中调用;
| 比较项 | execute() | submit() |
|---|---|---|
| 适用 | 用于提交不需要返回值的任务 | 用于提交需要返回 值的任务 |
| 方法所在接口 | Executor接口 | ExecutorService接口 |
| 异常处理 | 异常信息会被打印到控制台 | 需要通过Future.get方法来获取异常 |
| 返回值-能否判断成功与否 | 无法 | 返回一个 Future 类型的对象 |
10. 创建线程池
- 使用 ThreadPoolExecutor
构造方法指定:最小可以同时运行的线程数量、任务队列容量、核心线程数; - 使用 Executor 框架的工具类 Executors 创建
FixedThreadPool(固定线程数量的线程池)、SingleThreadExecutor(只有一个线程的线程池)、CachedThreadPool(可根据实际情况调整线程数量的线程池); - 不推荐使用 Executors(请求队列长度太长、允许创建的线程太多)- 阿里巴巴开发手册规范;
11. ThreadPoolExecutor 饱和策略
当前同时运行的线程数达到最大线程数量并且队列满。抛出异常、调用自己的线程执行任务、丢弃不处理、丢弃最早未处理任务;
12. Atomic 原子类、JUC 包下的原子类
| 基本类型 | 数组类型 | 引用类型 | 对象的属性修改类型 |
|---|---|---|---|
| AtomicInteger:整形原子类 | AtomicIntegerArray:整形数组原子类 | AtomicReference:引用类型原子类 | AtomicIntegerFieldUpdater:原子更新整形字段的更新器 |
| AtomicLong:长整型原子类 | AtomicLongArray:长整形数组原子类 | AtomicStampedReference:原子更新带有版本号的引用类型 | AtomicLongFieldUpdater:原子更新长整形字段的更新器 |
| AtomicBoolean:布尔型原子类 | AtomicReferenceArray:引用类型数组原子类 | AtomicMarkableReference :原子更新带有标记位的引用类型 | AtomicReferenceFieldUpdater:原子更新引用类型字段的更新器 |
13. AQS
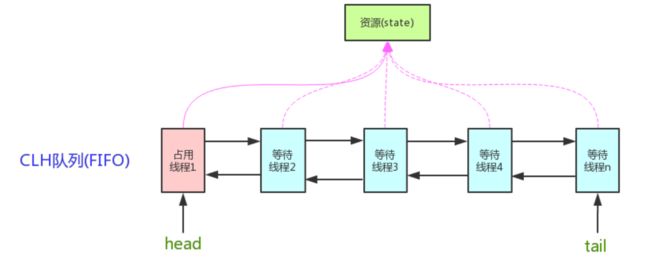
用来构建锁和同步器的框架。核心思想:如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就使用一套线程阻塞等待以及被唤醒时锁分配的机制。使用 CLH 队列实现。使用一个 volatile 修饰的 state 共享变量表示同步状态,通过内置的 FIFO 队列来完成获取资源线程的排队工作。公平锁:先到先得,非公平锁:谁抢到给谁;
14. AtomicLong 高并发性能问题
使用 CAS 算法,过多线程同时竞争同一个变量,大量线程会竞争失败,处于自旋状态消耗性能。LongAdder 内部维护一个 Cells 数组,把一个变量分解为多个变量,避免大量线程同时失效;
15. LongAdder 比 AtomicLong 的优化
使用Cells数组分解变量、获取资源失败时尝试获取其他原子变量的锁而不是自旋 CAS 重试、Cells 数组占用内存较大-使用惰性加载;
16. CAS 算法
在不使用锁的情况下实现多线程安全,是一种非阻塞算法实现,是一种乐观锁技术。使用三个参数:当前内存值V、旧的预期值A、即将更新的值B,当且仅当预期值A和内存值V相同时,将内存值修改为B;(缺点:循环时间长、开销很大、只能保证一个共享变量的原子操作、存在ABA问题);
1.4 JVM
1. 运行时数据区、垃圾回收与内存分配、性能调优与案例分析
- 具体参考笔者这篇笔记:JVM | 第1部分:自动内存管理与性能调优《深入理解 Java 虚拟机》;
2. 类文件结构、类加载机制、虚拟机字节码执行引擎
- 具体参考笔者这篇笔记:JVM | 第2部分:虚拟机执行子系统《深入理解 Java 虚拟机》;
3. 运行时数据区:
| 数据区 | 内容 | 二级内容 |
|---|---|---|
| 程序计数器(私) | 虚拟机字节码指令的地址/Undefined(本地方法) | |
| 虚拟机栈(私) | 栈帧 | 局部变量表(编译期可知的基本类型,对象引用)、操作数栈、动态链接、方法出口、附加信息 |
| 本地方法栈(私) | 类似虚拟机栈, Native 方法 | |
| 堆 | 对象实例和数组 | |
| 方法区 | JDK8 后为元空间,(运行时常量池) | (对象类型)、类信息、常量、静态变量、即时编译器编译后的代码 |
| 直接内存 |
4. Java 对象创建:类加载检查、分配内存(碰撞指针与空闲列表)、初始化零值、设置对象头(哈希码,GC 分代年龄,锁状态标志,线程持有的锁)、执行 init 方法;
5. GC Roots:虚拟机栈中引用的对象、方法区中类静态引用的对象、方法区中常量引用的对象;
6. 引用:强引用(不回收)、软引用(空间不足回收)、弱引用(发现就回收)、虚引用(任何时候都可以回收);
7. 方法区回收:废弃常量(没有引用)、无用的类(实例回收、ClassLoader 回收、无反射);
8. 垃圾回收算法:引用计数、标记清除(老年代)、标记整理(老年代)、复制(新生代)、分代收集;
9. 垃圾收集器:Serial(单线程,复制算法)、ParNew(多线程,复制算法)、Parallel Scavenge(吞吐量,多线程,复制)、Serial Old(单线程,标记整理)、Parallnel old(多线程,标记整理)、CMS(最短回收停顿时间,多线程,标记清除)、G1(多线程,标记整理+复制);
10. 必须进行初始化的5种时机:new关键字、反射、父类还没初始化、主启动类、静态方法句柄对应的类没有初始化;
11. 类加载过程:加载(class文件读入内存)、连接(验证-魔数,准备-static分配变量,解析-常量池的符号引用替换为直接引用)、初始化(init赋值)、使用、卸载;
12. 几种类加载器:启动类加载器(加载 Java 的核心类,C++实现)、扩展类加载器、系统类加载器、自定义类加载器;
13. 确定被调用的方法:解析符号引用(静态解析-编译期,动态解析-运行期)、分派确定目标方法(静态分派-重载,动态分派-重写);
1.5 Python 相关
- 具体参考笔者 Python 相关笔记:
- Python | Python语法基础;
- Python | Python常用函数、方法示例总结(API);
2. 计算机基础
2.1 计算机网络
1. OSI 七层、CP/IP四层、五层协议
OSI 七层:物理层、数据链路层、网络层、运输层、会话层、表示层、应用层;
TCP/IP:网络接口层、网际层、运输层、应用层;
五层协议:物理层(IEEE 802.)、数据链路层(ARP,RARP,PPTP)、网络层(ip,icmp)、运输层(TCP,UDP)、应用层(DNS,HTTP,HTTP);
2. TCP 可靠传输、拥塞算法
TCP 协议保证可靠传输:数据分块排序、校验和、流量控制(发送窗口)、拥塞控制(拥塞窗口+拥塞算法)、ARQ协议(停止等待ARQ协议-分组,连续ARQ协议-窗口)、超时重传;
拥塞算法:慢开始 、 拥塞避免 、快重传与快恢复;
3. URl-过程
URl-过程:1.解析域名(浏览器缓存,操作系统缓存-hosts文件,(开始递归查询),本地域名服务器,根域名服务器,主域名服务器,网站注册的域名服务器)、2.TCP连接(三次握手)、3.发送HTTP请求(发送Cookies)、4.服务器处理请求(Controller,Service,Mapper)、5.服务器返回HTML页面(80端口,response,信息头,html)、6.浏览器显示HTML(html-dom树-dom元素与属性-根是docunment对象,css,js)、7.连接结束;
4. 状态码
| 类型 | 原因短语 | |
|---|---|---|
| 1XX | 信息性状态码 | 接收的请求正在处理 |
| 2XX | 成功状态码 | 请求正常处理 |
| 3XX | 重定向状态码 | 需要其他附加操作完成请求 |
| 4XX | 客户端错误状态码 | 服务器无法处理请求 |
| 5XX | 服务器错误状态码 | 服务器处理请求错误 |
5. HTTP/1.0 与 HTTP/1.1
| 比较项 | HTTP/1.0 | HTTP/1.1 |
|---|---|---|
| 长连接 | 短连接 | 长连接 |
| 错误状态响应码 | 增加24个 | |
| 缓存处理 | 使用header里的If-Modified-Since,Expires来做为缓存判断的标准 | 引入更多标准 |
| 带宽优化及网络连接的使用 | 存在带宽浪费 | 引入range头域,方便了开发者自由的选择 |
6. HTTPS 建立过程(SSL 建立的四次握手)
- 与HTTP区别:HTTPS 就是 HTTP 加上 SSL 加密处理(一般是 SSL 安全通信线路)+认证+完整性保护;
- 建立过程:
-
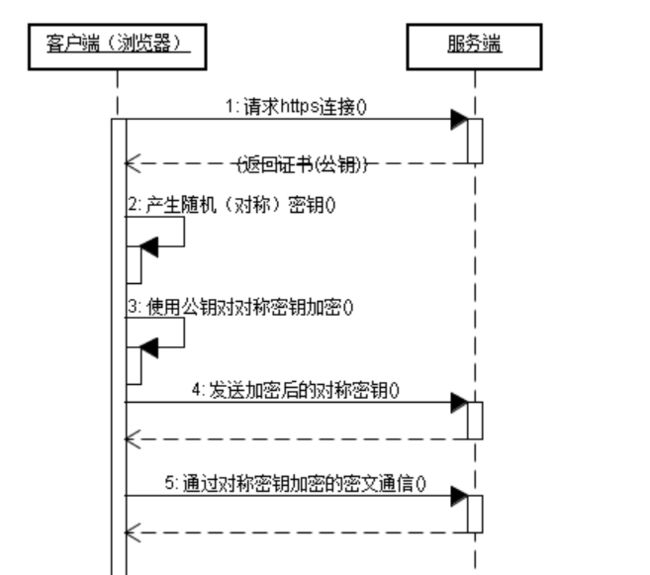
HTTPS 建立过程:(SSL 建立)
一次握手:- client 端请求访问:客户使用https的URL访问Web服务器,要求与Web服务器建立SSL连接(信息包括:SSL 指定版本、加密组件-支持的加密算法、随机数a)- 明文传输;
二次握手:- server 端返回证书:Web服务器收到客户端请求后,会生成一对公钥和私钥,并把公钥放在数字证书中发给客户端浏览器(信息包括:数字证书、随机数b、加密算法);
三次握手:- cilent 端解析证书:TLS 解析证书,验证公钥是否有效,有效则生成一个随机值c(预主密钥)。客户端浏览器根据双方同意的SSL连接的安全等级,建立会话,然后用公钥将会话加密,并传送给服务器;(过程见下点)
- client 端加密会话:使用随机值a、随机值b、随机数c(预主密钥) 组装
会话密钥,使用证书的公钥加密会话密钥。传输会话密钥;
四次握手:- server 端解析会话密钥:用私钥解析得到随机数a、随机数b,随机数c(预主密钥),组装
会话密钥,与客户端相同; - 测试连接:客户端用
会话密钥加密一条信息,服务端能接收说明 SSL 层建立成功;
- server 端解析会话密钥:用私钥解析得到随机数a、随机数b,随机数c(预主密钥),组装
-
cilent 端解析证书:
- 证书内容有:服务器公钥、权威机构信息、服务器域名、证书数字签名(通过hash函数计算得证书数字摘要,权威机构私钥加密数字摘要得数字签名 )、签名计算方法、证书对应域名;
- 使用本地配置的权威机构的公钥解密证书得服务器公钥和证书数字签名;
- 证书数字签名经过 CA 公钥解密得到证书信息摘要;
- 使用证书签名方法计算证书信息摘要,与解密后的信息摘要对比;
-
解决问题:
- 中间人攻击:中间人不知道服务器私钥,不能解析得到会话密钥;
7. HTTPS 与 HTTP 特点
| HTTP | HTTPS |
|---|---|
| 无状态、无连接、基于请求和响应、通信使用明文 | 内容加密、验证身份、保护数据完整性、混合加密、数字摘要、数字签名技术 |
8. Session 与 Cookie
使用原因:HTTP 协议是一种无状态的协议;
关系:可以理解成 Cookie 是的 Session 的 Id;
相同点:用来跟踪浏览器用户身份的会话方式;
服务端如何下发 Cookie:服务器第一次接收到请求时,开辟了一块 Session 空间(创建了 Session 对象),同时生成一个 Session id,通过响应头的 Set-Cookie:“JSESSIONID=XXXXXXX” 命令,向客户端发送要求设置 Cookie 的响应。客户端收到响应后,在本机客户端设置了一个 JSESSIONID=XXXXXXX 的 Cookie 信息,该 Cookie 的过期时间为浏览器会话结束;
| 比较项 | cookie | session |
|---|---|---|
| 所在端 | 客户端 | 服务端 |
| 原理 | 户端访问服务器,服务器会生成一份 Cookie 传输给客户端,客户端保存 Cookie,以后每次访问服务器带上 Cookie | 客户端再次访问服务器只需要从该 Session 中查找该客户的状态 |
| 特点 | 简单易懂 | 安全 |
| 缺点 | 容易被篡改、保存的数据量有限 | 占用服务器性能 |
9. TCP 建立连接三次握手(TCP/IP 协议)

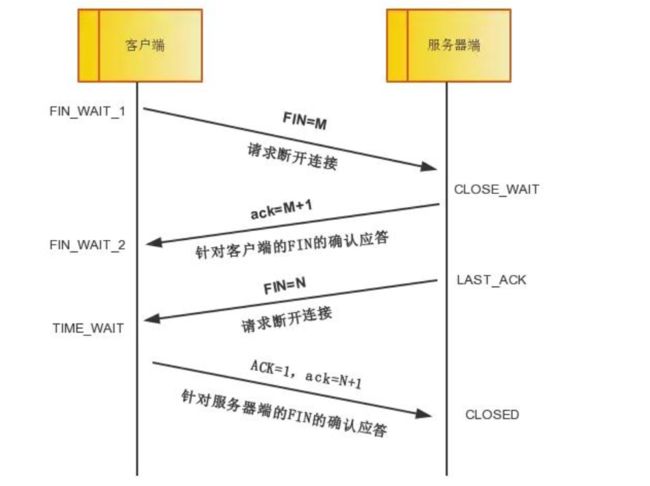
10. TCP 断开四次握手(TCP/IP 协议)
2.2 操作系统
1. 进程通信方式:匿名管道、有名管道、信号、消息队列、信号量、共享内存、套接字;
2. 线程间同步方式:互斥量、信号量、事件;
3. 进程调度算法:先到先服务(FCFS)、短作业优先(SJF)、时间片轮转、多级反馈队列调度、优先级;
4. 死锁条件:互斥条件、请求与保持条件、不剥夺条件、循环等待条件;
5. 内存管理机制:块式管理、页式管理、段式管理、段页式管理机制;
6. 快表与多级页表:虚拟地址到物理地址的转换要快。解决虚拟地址空间大,页表也会很大的问题;
7. 虚拟内存技术实现:请求分页存储管理、请求分段存储管理、请求段页式存储管理;
8. 页面置换算法:OPT 最佳页面置换算法、FIFO 先进先出页面置换算法、LRU 最近最久未使用页面置换算法、LFU 最少使用页面置换算法;
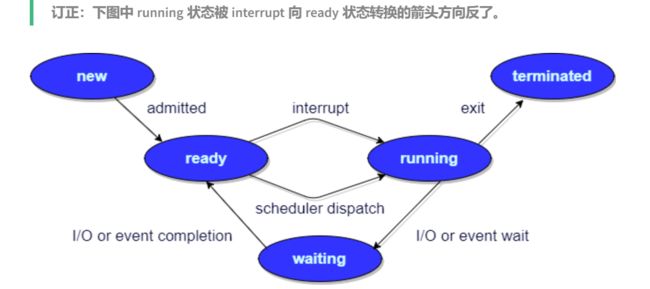
9. 线程状态:初始、运行、阻塞、等待、超时等待、终止;
10. 进程状态:创建、就绪、运行、阻塞、结束;
11. 系统调用:用户态(user mode) : 用户态运行的进程可以直接读取用户程序的数据。系统态(kernel mode):系统态运行的进程或程序几乎可以访问计算机的任何资源,不受限制(设备管理、文件管理、进程管理、内存管理);
2.3 数据结构与算法
1. 图的遍历
深度优先搜索(DFS):
- 访问图中所有节点,或者访问最少节点直至找到某节点,DFS 一般比较简单;
- 前序和树遍历的其他形式都是一种 DFS;
广度优先搜索(BFS):
- 如果想找到两个节点的最短路径(或任意路径),BFS一般比较适宜;
2. 排序算法
- 具体参考笔者这篇笔记:Java 常见排序算法(纯代码);
3. 参考文章
- 具体参考笔者的算法系列笔记:
- 面试 | Java 算法的 ACM 模式;
- 算法 | 第1章 数组与字符串相关《程序员面试金典》;
- 算法 | 第2章 链表相关《程序员面试金典》;
- 算法 | 第3章 栈与队列相关《程序员面试金典》;
- 算法 | 第4章 树与图相关《程序员面试金典》;
- 算法 | 第5章 位操作相关《程序员面试金典》;
2.4 设计模式七大原则
- 具体参考笔者这篇笔记:《设计模式的七大原则》;
- 单一职责原则:个类应该只负责一项职责;
- 接口隔离原则:一个类对另一个类的依赖应该建立在最小的接口上;
- 依赖倒转(倒置)原则:上层模块应该依赖抽象,而不应该依赖具体的实现;抽象不应该依赖细节;细节应该依赖抽象;
- person类 人要调用 car类、train类、plane类 的 drive 驾驶方法(上层模块是人,下层模块是交通工具)。不应该在每个交通工具类里重载 drive 方法(否则就是上层模块是人依赖了下层模块是交通工具)。应该在用一个 Vehicle接口 定义 drive 方法,每个交通工具类重写drive 方法(即用 Vehicle接口 隔离人与交通工具);
- 在 uml 图上体现就是交通工具(细节)依赖 Vehicle接口(抽象);
- 对“依赖倒置原则”的理解;
- 里氏替换原则:
- 开闭原则:
- 迪米特法则:
- 合成复用原则:
3. 数据库
3.1 MySQL
1. MyISAM 与 InnoDB
| 比较项 | MyISAM | InnoDB |
|---|---|---|
| 版本 | 5.5之前 | 5.5之后 |
| 锁级别 | 表级锁(共享锁、排他锁) | 表级锁、行级锁(共享锁、排他锁) |
| 事务 | 不支持 | 支持(通过 redo log) |
| 崩溃后安全恢复 | 有崩溃修复能力 | |
| 外键 | 不支持 | 支持 |
| MVCC | 不支持 | 支持 |
| 索引 | 非聚簇索引。索引与数据分离(不支持hash索引) | 聚簇索引。数据文件本身就是索引 |
| 存储结构 | 三个文件(表格定义、数据文件、索引文件) | 数据文件 |
| 数据检索 | 叶节点的data域存放的是数据记录的地址。需要根据地址读取数据 | 叶节点data域保存了完整的数据记录 |
| 存储顺序 | 按记录插入顺序保存 | 按主键大小有序插入 |
| 默认隔离级别 | 可重复读(使用 Next-Key Lock 锁算法可避免幻读) | |
| 应用范围 | SELECT密集型 | INSERT和UPDATE密集型 |
2. InnoDB 引擎4大特性
插入缓冲(要插入的索引页不在内存中时放进 change buffer)、二次写(两次操作 redo log 表)、自适应哈希索引(自动根据访问频率和模式建立 hash 索引)、预读(异步将磁盘页读取到缓存池中);
3. MVCC
| MVCC | |
|---|---|
| 是什么 | 多版本并发控制 |
| 目的 | 为了实现读-写冲突时不加锁的并发控制,是一个抽象概念 |
| 实现方式 | 快照读(当前读-读取时加悲观锁) |
| 实现原理 | 依赖3个隐式字段(最近修改事务ID,回滚指针,隐式自增ID)+undo日志(链表,记录历史数据)+read view(做可见性判断,记录某个事务快照读时其他事务活跃状态) |
| 具体过程 | 事务A对某行数据执行快照读,数据库对该行数据生成read view读视图,其中有 up_limit_id(活跃事务ID列表里最小值)、活跃事务 ID 列表、low_limit_id(当前尚未分配的下一个事务ID),判断最近修改事务ID是否在read view读视图范围内,不在时说明符合可见性,可以并发修改 |
| 应用 | MVCC(解决读写冲突)+乐/悲观锁(解决写写冲突)提高并发性能 |
4. 共享锁、排它锁
| 对比项 | 共享锁 | 排它锁 |
|---|---|---|
| 说明 | 用户要进行数据的读取时,对数据加上共享锁 |
用户要进行数据的写入时,对数据加上排他锁 |
5. 乐观锁、悲观锁
| 比较项 | 乐观锁 | 悲观锁 |
|---|---|---|
| 说明 | 假设不会发生并发冲突,只在提交操作时检查是否违反数据完整性(修改数据时上锁) | 假定会发生并发冲突,屏蔽一切可能违反数据完整性的操作(查询完数据就锁起来) |
| 适用 | 多读场景 |
多写场景 |
6. 事务的四大特性(ACID)
原子性、一致性(事务前后数据一致)、隔离性(事务不被其他事务干扰)、持久性(事务对数据库修改是持久的);
7. 并发 事务问题 与 隔离级别
并发问题:脏读(读取到未提交的事务)、丢失修改(修改了未提交的事务)、不可重复读(读取到已修改的数据)、幻读(读取到已增删的数据);
隔离级别:读未提交、读已提交(解决脏读)、可重复读(默认-解决脏读、不可重复读)、可串行化(全解决);
8. join
对数据库中的两张或两张以上表进行连接操作。分为内连接、外连接(左外连接、右外连接、全外连接)
9. 大表优化
限定查询数据范围、加缓存redis、读/写分离、垂直拆分(缺点是出现冗余)、水平拆分(缺点是可能造成分布式事务)、引擎(MyISAM适合SELECT密集型的,InnoDB适合INSERT和UPDATE密集型的表);
10. 分库分表后的问题
事务支持(分布式事务)、跨库join、跨节点的count,order by,group by以及聚合函数问题、数据迁移,容量规划,扩容等问题、ID问题(雪花算法);
11. 慢查询原因及解决方法
| 序号 | 原因 | 解决 |
|---|---|---|
| 1 | 加载了额外的数据列 | 使用limit |
| 2 | 索引没有命中 | 重写SQL,避免在 where 子句使用 !=、<>、or操作符 |
| 3 | 数据量太大 | 大表优化 |
| 4 | 总是返回全部列 | 避免使用SELECT * |
| 5 | 重复查询相同的数据 | 加缓存redis |
| 6 | 存在锁竞争 | 执行单个查询 |
| 7 | 统计所有列数使用count(*)-忽略所有的列 |
12. 索引使用场景
where、order by(没有时:分批从硬盘读取数据后排序合并,有时:索引本身有序)、join(对 on 涉及的字段建立索引);
13. 索引类型
主键索引、唯一索引、普通索引、全文索引;
14. 创建索引的原则
最左前缀匹配原则(MySQL匹配到范围查询就停止匹配)、频繁查的字段建立索引、更新频繁的字段不建立索引、区分度低的数据不建立索引、有外键的数据列必须建立索引、重复值多的列不建立索引、text/image/bit类型的列不建立索引;
15. 添加索引优化查询
PRIMARY KEY(主键索引)、UNIQUE(唯一索引) 、INDEX(普通索引)、FULLTEXT(全文索引) 、多列索引 ;
16. MySQL 的联合索引
| 联合索引 | |
|---|---|
| 含义 | 对表上的两个或两个以上的列字段进行索引 |
| 形式 | index (a,b,c),可以支持 a | a,b | a,b,c 3种组合进行查找(最左前缀原则) |
| 创建语法 | create index 索引名 on 表名 (字段名1,字段名2,…) |
| 删除索引 | alter table 表名 drop index 索引名 |
17. 查询、更新 SQL 如何执行
查询:连接器(权限校验)、(查询缓存)、分析器(词法、语法分析)、优化器、执行器、引擎;
更新:连接器(权限校验)、(查询缓存)、分析器(词法、语法分析)、执行器、引擎、redo log prepare(重做日志)、binlog(归档日志)、redo log commit;
18. 为什么用两个日志模块,redo log 的两提交阶段
一开始 MySQL没有使用 InnoDB(redo log 是 InnoDB 引擎特有的,用来支持事务);
先 redo log 直接提交,然后写 binlog:完 redo log 后,机器挂了,binlog 日志没有被写入。机器重启时会通过 redo log 恢复数据。导致主从数据库数据不一致;
先 binlog,后 redo log:写完 binlog 后,机器重启,由于没有 redo log,无法恢复数据;
19. bin log 录入格式
statement(记录每条会修改数据的sql,节省IO提高性能)、row(记录每行改动,性能较差)、mixed(折中方案)
20. MySQL中的七种日志
| 比较项 | redo log | undo log | binlog | error log | slow query log | general log | relay log |
|---|---|---|---|---|---|---|---|
| 中文名 | 重做日志 | 回滚日志 | 归档日志 | 错误日志 | 慢查询日志 | 普通查询日志 | 中继日志 |
| 记录内容 | 记录了xxx页做了xx修改的信息 | 发生修改数据的补偿sql(相反操作,比如删除与添加) | 记录MySQL中增删改时的记录日志 | MySQL在启动、关闭或者运行过程中的错误信息 | 记录执行时间超过指定阈值的SQL语句 | 客户端连接信息以及执行的SQL语句信息 | |
| 使用目的 | 用于宕机后数据恢复 | 用来回滚到某一个版本 | 进行主从复制,以及数据库的恢复 | 获取到错误日志的位置等信息 | 找出慢的原因 | ||
| 储存与格式 | 以块为单位的一种内存格式 | 二进制、三种格式(修改数据的sql、每行改动、折中) | |||||
| 日志类型 | 物理日志 | 逻辑日志 | 逻辑日志 | ||||
| 用途 | 事务。更新的数据先放在redo log,然后刷新到磁盘 | 主从复制、提供回滚、MVCC |
21. undo log、redo log、bin log 的应用
事务:开启事务 -> 查询待更新的记录到内存,并加 X 锁 -> 记录 undo log 到内存 buffer -> 记录 redo log 到内存 buffer -> 更改内存中的数据记录 -> 提交事务,触发 redo log 刷盘 -> 记录 bin log -> 事务结束;
崩溃恢复:redo log和binlog有个共有数据字段,XID -> 按顺序扫描 redo log -> 既有prepare、又有commit的redo log直接提交 -> 只有prepare、没有commit的redo log,就拿着XID去binlog找对应的事务,找到就提交,否则回滚;(为什么不使用binlog:需要重做事务,可能涉及多个事务);
22. 数据库三大范式
列不可再分、属性完全依赖主键、属性不依赖其他非主属性;
23. SQL 偶尔执行慢
数据库在刷新脏页(redolog写满导致数据库全身心执行数据同步,内存不够换页频繁)、拿不到锁(show processlist命令查看);
24. SQL 总是执行慢
字段没有索引、数据库选错索引;
25. InnoDB存储引擎锁算法
| 比较项 | Record lock | Gap lock | Next-key lock |
|---|---|---|---|
| 锁算法 | 单个行记录上的锁 | 间隙锁,锁定一个范围,不包括记录本身 | record+gap 锁定一个范围,包含记录本身 |
| 应用 | 查询的索引含有唯一属性时 | 为了阻止多个事务将记录插入到同一范围内 | 行的查询,解决幻读 |
26. 数据库三大范式
列不可再分、属性完全依赖主键、属性不依赖其他非主属性;
27. MySQL 的权限表
user权限表(用户账号)、db权限表(账号对应操作权限)、table_priv(表的操作权限)、columns_priv(列的权限)、host(更细致的一种);
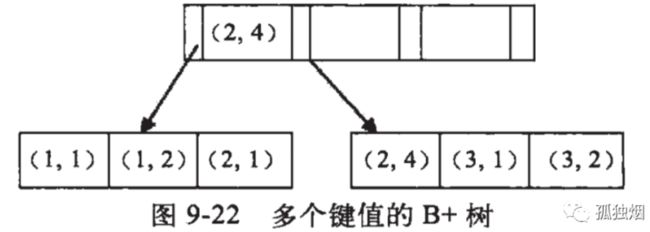
28. B 树、B+ 树和 hash 索引
| 比较项 | B 树 | B+ 树 | hash 索引 |
|---|---|---|---|
| 内部节点 | 键和值 | 键 | \ |
| 叶子节点 | 键和值 | 键和值,有链连接 | \ |
| 好处 | 将重复查询是数据靠近根节点,提高效率 | 内部节点内存小,一次读取可以获取更多键,缩小查找范围。通过叶子节点的链遍历数据提高效率。IO次数少 | 等值查询更快(但是不稳定、性能不可预测-hash碰撞) |
| 缺点 | 不稳定 | 不支持:范围查询(无序)、模糊查询、最左前缀匹配 | |
| 适用 | 随机检索 | 随机检索、顺序检索 |
29. 如何理解稳定性
与操作系统的磁盘操作相关。我们知道一次磁盘读/写操作需要的时间 = 寻道时间(操作系统可控) + 延迟时间 + 传输时间。延迟时间和传输时间与磁盘转速相关,操作系统不可控。因此我们每一次 IO 的时间大致是确定、稳定的。B+ 树的稳定性体现在所有数据查询的路径长度相同,每一个数据的查询效率相当。IO 时间与 B+ 树查找时间稳定,系统就相对比较稳定;
30. MySQL 为什么不用红黑树
红黑树特点:保证深度一致、数据量大时深度大。B+树特点:节点存数据、每层节点多、节点小,层数少。MySQL通过减少磁盘IO提高效率,B+树每层节点多,层数少,节点小,能在较少IO下加载更多key进内存。AVL和红黑树更多是存储在内存,红黑树可能导致树的深度过大造成磁盘IO读写过于频繁;
*补充:操作系统按页读取硬盘中的数据,一次读取一页,如果要读取的数据量超过一页的大小,就会触发多次 IO 操作。因此B+树每层节点不是越多越好;
31. B+ 树是如何降低 IO 的
首先,数据查询需要经过两步:1. 将索引页加载到缓存中,然后从缓存中找到数据页;2. 将数据页数据加载到缓存,然后将数据返回出去;
B+ 树索引降低了 IO 次数:B+ 树的索引页中全部是都是索引,这样一个数据页中能查询到很多索引降低了下一次去磁盘再拿索引页的可能性;(B 树在非叶子节点存储数据了,这样在一个索引页上有数据又有索引,效率肯定低了)
32. B+ 树索引是怎么通过磁盘查找数据的
首先我们要知道,B+ 树索引并不能直接找到行,只是找到行所在的页,通过把整页读入内存,再在内存中查找;B+ 树高度一般为 2-4 层,查找记录时最多只需要 2-4 次 IO;
假设现在有个 2 层的 B+ 树索引,首先通过一次 IO 加载非叶子节点(非叶子节点不存储行数据,存储索引键,其中 data 域里存储的是地址)。在内存中使用二分法查找到数据项,获取 data 域的地址。然后根据地址通过二次 IO 加载叶子节点(叶子节点存放行数据),在内存中进行二分查找找到数据;
*每个磁盘块大小为 4KB,能存储上百万的数据,3 层的 B+ 树能够表示上百万的数据,因此只需要 3 次 IO 就能在百万级数据中进行查找;
33. B 和 B+ 树的查找支持
B 树支持随机查找:在单个节点内部支持随机查找;
B+ 树支持随机查找和顺序查找:在单个节点内部支持随机查找。B+ 树的叶子节点有指针相互连接,实现顺序查找(方便范围查询);
34. 键
超键(唯一标识元组的属性集)、候选键(最小超键)、主键(唯一数据行)、外键(一个表存在另一个表的主键);
35. SQL 约束
not null(非空)、unique(独一)、primary key(主键)、foreign key(外键)、check(控制值范围);
36. int(10)、char(10)、varchar(10)
| 比较项 | int(10) | char(10) | varchar(10) |
|---|---|---|---|
| 含义 | 10位数字长度 | 10位固定字符串 | 10位可变字符串 |
| 实际长度 | 占32个字节,int型4位 | 不足补空格(空格不算字符) | 不足补空格(空格算字符) |
37. drop、delete、truncate
| 比较项 | Delet | Truncate | Drop |
|---|---|---|---|
| 类型 | DML | DDL | DDL |
| 回滚 | 可 | 不可 | 不可 |
| 删除内容 | 表结构在,删除全部或者一部分数据行 | 表结构在,删除所有数据 | 表结构不在 |
| 删除速度 | 速度慢,逐行删除 | 速度快 | 速度最快 |
3.2 Redis
1. 分布式缓存区别:Memcached 和 Redis
| 比较项 | Memcached | Redis |
|---|---|---|
| 数据类型 | 只有 key/value | 多种 |
| 持久化 | 内存 | RDB AOF |
| 容灾恢复 | 无 | 基于持久化 |
| 内存溢出 | 报错 | 持久化到硬盘 |
| 集群 | 无原生集群 | 支持 cluster 模式 |
| 线程模型 | 多线程非阻塞IO复用 | 单线程IO多路复用 |
| 高级功能 | 发布订阅模型、Lua 脚本、事务、支持更多的编程语言 | |
| 过期数据删除 | 惰性删除 | 惰性删除与定期删除 |
2. 数据结构
SDS、链表、字典、跳跃表、整数集合、压缩列表、对象;
3. 文件事件处理器
多个 socket、IO 多路复用程序、文件事件分派器、事件处理器;
4. 过期数据删除策略
惰性删除(CPU友好)、定期删除(内存友好);
5. 内存淘汰机制
最近最少未使用(LRU)、即将过期、任意选择、最近最少使用、报错;
6. 两种持久化技术
持久化 RDB(默认,存数据)、AOF(实时性好、更新频率高,存操作);
7. Redis 事务
MULTI,EXEC,DISCARD 和 WATCH 等命令。不支持原子性,不支持回滚;
8. 缓存问题(数据库本身|数据|业务)
| 问题 | 描述 | 数据库层面解决 | 数据层面解决 | 业务层面解决 |
|---|---|---|---|---|
| 缓存穿透 | 访问一个数据库和缓存都没有的key,导致每次请求都到数据库 | 缓存无效 key / 布隆过滤器(过滤不存在的key) | 前端参数校验 | |
| 缓存雪崩 | 大量key有相同过期时间,集体失效 / redis 大量宕机 | 集群+哨兵 | 延长数据过期时间 | 限流 |
| 缓存击穿 | 热点key过期导致短时间内大量访问落到数据库上,压垮数据库 | 数据库加锁,只允许一个客户访问 | 热数据不过期 | 热点限流 |
| 缓存预热 | 高频数据放缓存(秒杀系统) | 系统上线先加载部分数据 | 定时刷新缓存 | |
| 缓存降级 | 大量访问导致服务非关键部分不可用,保证关键部分可用 | 返回默认值 |
9. 缓存与数据库数据一致性
先更新数据库,然后再删除缓存;
10. 服务器的复制
设置主服务器的地址和端口、建立套接字连接、发送 PING 命令、身份验证、发送端口信息、同步、命令传播;
11. Sentinel 连接
Sentinel 默认每 10 秒向主服务器发送 INFO 命令。Sentinel 默认每 2 秒向被监视的主从服务器发送命令。Sentinel 默认每秒向所有实例发送 PING 命令;
12. Sentinel 主服务器下线
发送 PING 命令判断主观下线、询问其他 Sentinel 判断客观下线、协商选出领头 Sentinel(Raft 算法)、选新主服务器(状态良好、数据完整)、通过 SLAVEOF 复制新主服务器、将下线的主服务器设置为从服务器;
13. Redis为什么快
基于内存、非阻塞的IO多路复用机制、单线程避免上下文切换与竞争;
14. 应用场景
缓存、计数器、会话缓存、查找表(DNS记录)、分布式锁、消息队列(双向链表);
15. I/O 多路复用程序的实现
- Redis 使用文件事件处理器(file event handler)处理文件事件:
- 文件事件处理器是基于 Reactor 模式实现的网络通信程序;
- 由四个部分:套接字、I/O 多路复用程序、文件事件分派器、事件处理器;
- I/O 多路复用技术会将所有产生事件的套接字(Socket)放在一个队列,逐个传送套接字;
- I/O 多路复用技术的底层实现:
- 通过包装常见的 select、epoll、evport 和 kqueue 这些 I/O 多路复用函数库来实现;
- I/O 多路复用函数库实现了相同的API,底层实现跨越互换;
- 程序会在编译时自动选择系统中性能最高的 I/O 多路复用函数库作为底层实现;
16. Redis 的单进程单线程误区
- Redis 并不完全是单进程单线程的,在进行 RBD 持久化,执行 BGSAVE 命令时,会创建一个子进程在后台进行备份;
- Redis 的单进程指的是:文件事件处理器是单进程单线程模式运行的,也即 Redis 处理大部分请求时是用单线程;
- Redis 使用单线程模式还能保持高效率,主要是因为:
- 纯内存操作(主要);
- 核心是基于非阻塞的 I/O 多路复用机制(主要);
- 单线程避免了多线程的频繁上下文切换问题;
- I/O 多路复用程序总是将所有产生事件的套接字放到一个队列,以有序、同步、每次一个套接字的方式向文件事件分派器传送套接字;
- Redis 的 I/O 多路复用程序通过包装常见的底层 I/O 多用复用函数库实现,程序在编译时自动选择系统中性能最高的 I/O 多路复用函数库作为底层实现;
17. Sentinel 哨兵模式
- 启动:
- 初始化 Sentinel 服务器;
- 初始化 Sentinel 状态和 masters 属性(维护被监视的服务器);
- 创建连向主服务器的网络连接;(命令连接、订阅连接)
- 命令连接:
- Sentinel 默认每 10 秒向主服务器发送 INFO 命令,获取主服务器信息;
- Sentinel 默认每 2 秒通过命令连接向所有被监视的主从服务器发送命令,告知 Sentinrl 自己的信息与主服务器的信息;
- Sentinel 默认每秒向与它建立的所有实例(包括主服务器、从服务器和其他 Sentinel)发送 PING 命令;
- 主服务器主/客观下线:
- 发送 PING 命令判断主观下线;
- 当 Sentinel 将一个主服务器判断主观下线后,会询问其他 Sentinel。当从其他 Sentinel 接受到足够数量的已下线判断后,Sentinel 会将从服务器判断为客观下线,并对主服务器执行故障转移操作;
- 当主服务器被判断客观下线时,监视这个下线主服务器的各个 Sentinel 会进行协商,选举出一个领头 Sentinel,并由领头 Sentinel 对下线的主服务器执行故障转移操作;
- 选举领头 Sentinel:
- Sentinel 系统选举领头 Sentinel 的方法是对 Raft 算法的领头选举方法的实现;
- 领头 Sentinel 在从服务器中选出一个状态良好、数据完整的从服务器;
- 领头 Sentinel 通过 SLAVEOF 命令让从服务器复制新的主服务器;
- 将已下线的主服务器设置为新主服务器的从服务器;
18. 参考文章
- 具体参考笔者 Redis 系列笔记:
- Redis | Redis常用命令及示例总结(API)
- Redis | 第1章 SDS、链表与字典《Redis设计与实现》;
- Redis | 第2章 跳跃表、整数集合与压缩列表《Redis设计与实现》;
- Redis | 第3章 对象《Redis设计与实现》;
- Redis | 第4章 Redis中的数据库《Redis设计与实现》;
- Redis | 第5章 Redis 中的持久化技术《Redis设计与实现》;
- Redis | 第6章 事件与客户端《Redis设计与实现》;
- Redis | 第7章 Redis 服务器《Redis设计与实现》;
- Redis | 第8章 发布订阅与事务《Redis设计与实现》;
- Redis | 第9章 Lua 脚本与排序《Redis设计与实现》;
- Redis | 第10章 二进制数组、慢查询日志和监视器《Redis设计与实现》;
- Redis | 第11章 服务器的复制《Redis设计与实现》;
- Redis | 第12章 Sentinel 哨兵模式《Redis设计与实现》;
4. 后端框架(这后面为加分项,可以不用看)
4.1 Spring
0. 参考文章
- 具体参考笔者这篇笔记《Spring | Spring5学习笔记》;
1. Spring 中的 bean 的作用域:singleton(单例)、prototype(多例)、request(一次请求一个)、session(一次请求一个)、global-session(全局);
2. @Component 和 @Bean:
| 比较项 | @Component | @Bean |
|---|---|---|
| 作用对象 | 类 | 方法 |
| 加载类型 | 通过类路径扫描 | 在标有该注解的方法中定义 bean |
| 自定义 | 自定义性更强 |
3. Spring MVC:DispatcherServlet、HandlerMapping、HandlerAdapter(Handler,ModelAndView)、ViewResolver、View;
4. 设计模式:工厂(通过 BeanFactory/ApplicationContex 创建对象)、代理(Spring AOP)、单例(Bean 默认单例)、包装器(动态切换数据源)、观察者(事件驱动模型)、适配器(spring MVC);
5. AOP 代理方式:JDK动态代理(创建接口实现类)、CGLIB动态代理(创建子类的代理对象);
6. AOP 术语:连接点(增强哪些方法)、切入点(实际被真正增强的方法)、通知(增强的类型)、切面(动词,把通知应用到切入点的过程);
7. 事务传播行为:@Transactional。支持当前事务、不支持当前事务、其他;
4.2 Spring Boot
0. 参考文章
- 具体参考笔者 Spring Boot 系列笔记:
- SpringBoot | 1.1 SpringBoot简介;
- SpringBoot | 1.2 全注解下的Spring IoC;
- SpringBoot | 1.3 约定编程Spring AOP;
- SpringBoot | 1.4 数据库事务处理;
- SpringBoot | 2.1 SpringBoot自动装配原理;
- SpringBoot | 3.1 配置数据源及JDBC;
- SpringBoot | 3.2 整合MyBatis;
- SpringBoot | 3.3 整合MyBatis-Plus;
- SpringBoot | 4.1 SpringMVC的自动配置;
1. 三个注解:@Configuration、@EnableAutoConfiguration、@ComponentScan;
2. 启动过程:1.始化准备 ApplicationContext、告知服务启动、2.准备 Environment、告知 Environment 环境准备好、(打印banner)、3.Environment设置进ApplicationContext、4.初始化 ApplicationContext、告知上下文环境准备好、5.加载 Config 配置到 ApplicationContext、告知上下文环境加载完毕、6.refresh() 方法刷新应用上下文、告知应用程序启动完毕;
4.3 Zookeeper
1. 数据:结构化存储、由 Znode(key/value形式)组成、维护 stat 状态信息;
2. 节点类型:持久化节点、临时节点、有序节点、容器节点、TTL 节点;
4.4 Oauth2
1. 工作原理:第三方客户端向资源所有者(用户)申请认证请求、资源所有者同意请求返回许可、客户端根据许可向认证服务器申请认证令牌 Token、客户端根据认证令牌向资源服务器申请相关资源;
2. Oauth2.1:不建议隐式授权(授权码模式的简化版本,用户同意授权后直接返回访问令牌)。使用访问令牌时不应该通过 url 传递,而是http header或post body;
4.5 Nacos
1. SpringCloud 客户端集成 Nacos
- spring-cloud-commons 的
META-INF/spring.factories包下包含 Spring Cloud 自动配置类的全类名; - 其中有个
AutoServiceRegistrationAutoConfiguration服务注册相关的配置类; - 这个配置类注入了一个
AutoServiceRegistration实例; - 我们的
NacosAutoServiceRegistration间接实现了这个接口(中间隔了个 AbstractAutoServiceRegistration); - 同时,AutoServiceRegistration 类实现了
EventListener接口,说明 Nacos 通过事件监听机制注册进 Spring Cloud; - 当 Webserver 初始化完成之后,调用
this.bind ( event )方法启用事件监听; - 最终会调用
NacosServiceRegistry.register()方法进行服务注册; - register() 方法中调用
namingService.registerInstance()完成服务的注册。具体来说会做这几件事:- 通过
BeatReactor.addBeatInfo()创建心跳信息实现健康检测; - 通过
NamingProxy.registerService(),最终使用open API 或 SDK 方式发生HTTP请求给Nacos服务器;
- 通过
2. 服务的注册服务实例
- 在 nacos-naming 模块下的
InstanceController中使用接口 nacos/v1/ns/instance 接受请求; - 请求参数获得
serviceName(服务名)和namespaceId(命名空间Id); - 调用
registerInstance注册实例; - 根据服务名和命名空间id从缓存获取,service对象,没有则构建一个保存到
ConcurrentHashMap集合中(也就是 Nacos控制台的服务信息),并加到缓存; - 使用定时任务对当前服务下的所有实例建立心跳检测机制;
- 基于数据一致性协议服务数据进行同步;
3. 服务端查询服务实例
- 客户端通过sdk或api发生请求;
- 解析请求参数;
- 根据
namespaceId、serviceName获得 Service 实例; - 从 Service 实例中基于 srvIPs 得到所有服务提供者实例;
- 遍历组装 JSON 字符串并返回;
4. Nacos 服务地址动态感知原理
- 客户端通过
subscribe()方法来实现监听; - Nacos 客户端中有一个
HostReactor类,实现服务的动态更新,基本原理是:- 客户端发起时间订阅后,在 HostReactor 中有一个
UpdateTask线程,每 10s 发送一次Pull请求,获得服务端最新的地址列表; - 对于服务端,它和服务提供者的实例之间维持了心跳检测,一旦服务提供者出现异常,则会发送一个
Push消息给 Nacos 客户端,也就是服务端消费者; - 服务消费者收到请求之后,使用
HostReactor中提供的processServiceJSON解析消息,并更新本地服务地址列表;
- 客户端发起时间订阅后,在 HostReactor 中有一个
5. Spring Cloud 加载配置原理
- Nacos 的配置初始化依赖于 Spring Cloud 的配置自动加载;
- Spring Cloud 的配置自动加载在 Spring Cloud
主程序类加载时加载进来; - 而主程序类加载有这么几个关键的步骤:始化准备 ApplicationContext、准备 Environment、Environment 设置进 ApplicationContext、加载 Config 配置到 ApplicationContext、refresh() 方法刷新应用上下文;
- 其中在准备完
Environment环境后会使用事件监听机制通知BootstrapApplicationListener加载 classpath 路径下查找 META-INF/spring.factories 预定义的配置类。这些配置类是 Spring Cloud 提供的; - 在最后一步
刷新应用上下文时会执行一些Spring Cloud非官方的操作,比如从 Nacos 服务器里加载配置文件等;(最终调用的是 NacosPropertySourceLocator.locate() 方法)- 该方法的主要作用是:初始化
ConfigService对象,按照顺序分别加载共享配置、扩展配置、应用名称对应的配置;
- 该方法的主要作用是:初始化
6. 客户端的长轮询定时机制
- 在创建 ConfigService 对象时使用反射机制创建
NacosConfigService对象; - 在 NacosConfigService 的构造方法里有规定长轮询定时机制的一些基本属性:
HttpAgent、ClientWorker; - ClientWorker 创建了
两个定时调度的线程池,其中一个每隔 10s 检查一次配置是否发生变化。另一个用于实现客户端的定时长轮询功能。 - (配置用一个 cacheMap 来存储,key 是根据 datalD/group/tenant 拼接的值,值是配置文件)
- (超过 3000 个配置集会启动多个 LongPollingRunnable 去执行)
- 检查配置这里先会
检查本地配置,再检查服务端的配置是否发生改变,发生改变就使用 HttpAgent 调用接口请求变更配置的 id 等信息; - (等待30s)
- 然后在 30s 后收到一个
HttpResult,里面有存在数据变更的 Data ID、Group、Tenant; - 然后通过
getServerConfig()调用 HttpAgent 的接口请求去 Nacos 服务器上读取具体的配置内容;
7. 服务端的长轮询定时机制
- 服务器使用
ConfigController类里的 /listener 接口接受请求,然后执行主要两个逻辑: 获取客户端请求的变化的配置,使用 MD5 值校验。和执行长轮询定时机制;- 长轮询定时机制首先会
将客户端的长轮询请求封装成 ClientPolling; - 然后使用一个
ClientLongPolling 线程池执行长轮询定时机制; - 具体来说就是把 ClientLongPolling 实例放进一个
allSubs 队列中。在 29.5s 后拿出来执行任务。校验配置是否发生改变,发生改变则通过 response 返回给客户端; - 返回的是存在数据变更的 Data ID、Group、Tenant;
- (提前 0.5s 是避免客户端超时);
- 缺点是:服务器连接会消耗资源,服务器开销;
- 好处是:使得客户端和服务端之间在 30s 之内数据没有发生变化的情况下一直处于连接状态。解决了轮询机制请求频繁对资源的消耗;
8. 服务器修改配置
- 服务器谁配置的修改是通过
监听机制实现的; - 我们在 Nacos 服务器或通过 API 方式变更配置后,会发布一个
LocalDataChangeEvent 事件,该事件会被LongPollingService 监听; - 然后会使用线程池执行
DataChangeTask 任务,修改服务器上的配置;
4.6 Sentinel
1. 如何拦截请求
SentinelWebAutoConfiguration配置类里有个FilterRegistrationBean;- 这个 Bean 注册了个
CommonFilter; - 默认情况下通过
/*规则拦截所有的请求,并且将这些请求设置为Sentinel 的资源;
2. Sentinel 的工作原理
- Sentinel 依赖
ProcessorSlot 调用链进行工作,使用的是责任链模式,链表元素是一个Slot 槽; - Sentinel 里给我们实现了很多 Slot 槽,其中有
FlowSlot(流控槽)、StatisticSlot(统计槽)、DegradeSlot(熔断槽); - 先调用
lookProcessChain()方法从缓存中获取 slot 调用链,没有就创建一个; - 然后以遍历链表的方式完成流控、熔断和统计等功能;
- 进入每个槽的方法是:
xxxSlot.entry()方法,里面都是调用两个方法(除了统计槽外),checkXxx() 检查规则和fireEntry() 调用下一个Slot槽;
3. 流控槽 lowSlot
- 先到 Sentinel 控制台获取流控规则;
- 会根据获取到的信息做一些判断和匹配,如:
请求路径、是否集群、阈值类型(QPS,并发线程数)、流控类型(直接,关联,链路)、流控效果(快速失败,排队等待等); - 在代码层面根据:
流控类型(Strategy)和针对来源(limitApp)用 if-else 的方式给我们实现了三种场景:- 1. 优先保证针对来源(QPS - 每秒的响应请求数);
- 2. 优先保证规则,所有来源共用一个规则;
- 3. 其他情况(针对场景1中没有配置规则的应用来源);
- 选定场景后会根据流控效果进行相应处理,有四种处理策略:
- 1. 直接拒绝:抛异常;
- 2. 匀速排队:请求以匀速的速度通过;
- 3. 冷启动:QPS阈值除以冷加载因子得预热时长,预热时长后达到QPS阈值(秒杀场景);
- 4. 匀速+冷启动;
4. 熔断槽 DegradeSlot
- 熔断功能在 Sentinel-1.8.0 版本前后有较大变化;
- 先根据资源名称 resourceName (请求路径)获取断路器;
- 循环判断每个断路器;
- 如果断路器状态为关闭(State.CLOSED),则
通过; - 如果断路器状态为半开,则
拒绝; - 如果断路器状态为打开,则
尝试转换状态为半开;
- 如果断路器状态为关闭(State.CLOSED),则
- 状态转为半开会重置(retry)一个超时时间,如果在这个时间内请求成功,则断路器关闭。反之打开;
- 断路器打开的条件根据
熔断策略去配置,有:慢比例调用、异常比例、异常数; - 断路器打开的条件如下:
- 慢比例调用:统计时间内请求数大于最小请求数 + 慢调用(响应时间大于RT)比例大于阈值;
- 异常比例:统计时间内请求数大于最小请求数 + 请求异常的比例大于阈值;
- 异常数:统计时间内的异常数目超过阈值;
5. 统计槽 StatisticSlot
- 统计槽的实现与其他槽不一样,它先调用
fireEntry()方法执行后续槽,再进行统计; - 它主要统计的是两个核心指标:
增加线程数和请求通过数; - Sentinel 使用的是滑动窗口算法来统计单位时间内的请求数;
- 简单来说就是用一个环形数组,数组元素表示单位时间内的请求统计量,随单位时间循环遍历数组;
- 具体实现来看是使用一个
ArrayMetric 指标数组,里面有个LeapArray 环形数组,ArrayMetric 指标数组里的所有方法都是操作LeapArray 环形数组的; LeapArray 环形数组里的元素是WindowWrap 窗口包装类,也就是我们说的窗口,包装类包装的是MetricBucket 指标桶;- 每个
MetricBucket 指标桶统计的是单位时间内的请求成功、失败、异常、响应时长等指标数据,指标数据存储在LongAdder[]数组里; LongAdder对象是 JDK1.8 新增的类,用于在高并发场景下代替 AtomicLong,以用空间换时间的方式降低了 CAS 失败的概率,从而提高性能;- (AtomicLong 的高并发性能问题:使用 CAS 算法,过多线程同时竞争同一个变量,大量线程会竞争失败,处于自旋状态消耗性能。LongAdder 内部维护一个 Cells 数组,把一个变量分解为多个变量,避免大量线程同时失效);
- (总结来说 LongAdder 比 AtomicLong 的有几处优化:使用Cells数组分解变量、获取资源失败时尝试获取其他原子变量的锁而不是自旋 CAS 重试、Cells 数组占用内存较大-使用惰性加载)
4.7 Tars
1. 介绍
Tars是【基于名字服务】【使用Tars协议】的高性能【RPC】开发框架,同时配套一体化的【服务治理平台】,能够快速的以微服务的方式构建自己稳定可靠的分布式应用。Tars 的最大特点是多语言、基于二进制 Tars 协议。它是基于节点的 RPC 框架,其中包括服务节点与公共框架节点:服务节点是业务部分,有一个服务管理节点和若干个业务服务节点构成;公共框架节点实现一些基础功能,包括路由管理、包发布管理、配置中心、远程日志管理、统计管理、异常信息管理等;
2. 协议
- 以.tars结尾的接口文件,里面的内容用tars语言或语法来定义接口;
- 基于这个接口语言可以进行tars编码;
- 网络通信可以采用基于Tars协议的RPC通信;
- Response 网络包:数据包的长度、协议版本号、请求id、消息类型、服务名称、函数名称、序列化后的byte数组、context、status等;
- Request 网络包:数据包的长度、协议版本号、消息类型、服务名称、函数名称、序列化后的byte数组、context、status等;
4.8 Spring Cloud Config
- config 分为 server 端和 client 端:
- server 端为分布式配置中心,是一个独立的微服务应用;
- client 端为分布式系统中的基础设置或微服务应用,通过指定配置中心来管理相关的配置;
- Spring Cloud Config 支持将配置存储在:git、数据库、svn 以及本地文件;
- 弊端是:将维护环境的责任放在开发人员身上;
- 服务器主程序类上标注注解:@EnableConfigServer;
- 主程序类上使用注解动态刷新:@RefreshScope;
4.9 Eureka
- Eureka 是服务器与客户端模型;
- 服务的注册中心,负责维护与管理注册的服务列表;
- 所有要注册进 Eureka 的服务都称为 Eureka 的客户端;
- Eureka 的 30s 启动机制:
- 当客户端服务通过 Eureka 注册时, Eureka 将在 30s 内等待 3 次连续的健康检查,然后才能通过 Eureka 获取该服务;
- 每次服务注册需要 30 s 的时间才能显示在 Eureka服务中,因为 Eureka需要从服务接收 3 次。连续心跳包 ping,每次心跳包 ping 间隔 10 s,然后才能使用这个服务;
- Eureka 注册服务的 IP:
- 在基于容器的部署,容器以随机生成的主机名启动,没有 DNS 支持的主机名;使用主机名将无法解析;(基于服务器的环境时有支持 DNS 的主机名);
5. 分布式相关
5.1 Spring Cloud 微服务架构
- 具体参考笔者 Spring Cloud 系列笔记:
- 微服务架构 | 1. 微服务相关基础知识;
- 微服务架构 | 2. 服务配置管理;
- 微服务架构 | 2.1 使用 Spring Cloud Config 管理服务配置项;
- 微服务架构 | 2.2 Alibaba Nacos 的统一配置管理;
- 微服务架构 | *2.3 Spring Cloud 启动及加载配置文件源码分析(以 Nacos 为例);
- 微服务架构 | *2.4 Nacos 获取配置与事件订阅机制的源码分析;
- 微服务架构 | *2.5 Nacos 长轮询定时机制的源码分析;
- 微服务架构 | 3. 注册中心与服务发现;
- 微服务架构 | 3.1 Netflix Eureka 注册中心;
- 微服务架构 | 3.2 Alibaba Nacos 注册中心;
- 微服务架构 | 3.3 Apache Zookeeper 注册中心;
- 微服务架构 | 3.4 HashiCorp Consul 注册中心;
- 微服务架构 | *3.5 Nacos 服务注册与发现的源码分析;
- 微服务架构 | 4. 服务调用;
- 微服务架构 | 4.1 基于 Ribbon 的负载均衡详解;
- 微服务架构 | 4.2 基于 Feign 与 OpenFeign 的服务接口调用;
- 微服务架构 | 5. 服务容灾;
- 微服务架构 | 5.1 使用 Netflix Hystrix 断路器;
- 微服务架构 | 5.2 基于 Sentinel 的服务限流及熔断;
- 微服务架构 | 5.4 Sentinel 流控、统计和熔断的源码分析;
- 微服务架构 | 7. 安全保护;
- 微服务架构 | 7.1 基于 OAuth2 的安全认证;
- 微服务架构 | 7.2 构建使用 JWT 令牌存储的 OAuth2 安全认证;
- 微服务架构 | 10. 分布式追踪;
- 微服务架构 | 10.1 使用 Sleuth 追踪服务调用链;
- 微服务架构 | 10.2 使用 Papertrail 实现日志聚合;
- 微服务架构 | 10.3 使用 Zipkin 可视化日志追踪;
- 微服务架构 | 11. 分布式事务;
- 微服务架构 | 11.1 整合 Seata AT 模式实现分布式事务;
- 微服务架构 | 12.1 使用 Apache Dubbo 实现远程通信;
5.2 分布式事务
1. 术语
| 术语 | 解释 |
|---|---|
| TC | 事务协调者 |
| TM | 事务管理器 |
| RM | 资源管理器(管理DB数据库) |
| 本地锁 | 可以理解成数据库自身的锁 |
| 全局锁 | 全局ID,在业务层实现 |
2. 2PC、3PC、TCC
| 比较项 | 2PC | 3PC | TCC |
|---|---|---|---|
| 含义 | 两阶段协议 | 三阶段协议 | 补偿事务 |
| 阶段 | 准备、提交/回滚 | 准备(CanCommit)、预提交(PreCommit)、提交/回滚(doCommit) | 准备(try)、提交(Confirm)、补偿(Cancel) |
| 锁 | 本地锁(数据库的锁) | 本地锁 | 全局ID |
| 锁释放时机 | 全程占用 | ||
| 层面 | DB数据库 | DB数据库 | 业务 |
| 缺点-改动 | 同步阻塞、单点故障问题、数据不一致、没办法超时只能不断重试 | 引入超时机制、预提交阶段 | |
| 超时响应 | 准备/预提交阶段超时失败,提交阶段超时默认提交 | ||
| 一阶段 | 准备:TC询问RM,RM响应成功与否,写本地的redo和undo日志 | 准备 | 准备 |
| 二阶段 | 预提交:TC询问RM,反馈成功就预执行:RM执行事务,将undo和redo信息记录到事务日志中。反之发送中断请求中断事务。 | 提交 | |
| 三阶段 | 提交/回滚 | 提交/回滚 | 补偿 |
3. Seata AT
- 锁:本地锁+全局锁;
- 一阶段:解析SQL,业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源(需要持有全局锁);
- 二阶段:成功则异步删除回滚日志,失败则补偿(还原前需要校验脏写);
- 特点:全局锁、SQL解析、TC独立部署、读隔离与写隔离;
4. Saga
- 核心思想是将长事务拆分为多个本地短事务并依次正常提交,因此没有两提交或者三提交阶段;
- Saga 使用补偿事务来进行回滚;
- Saga 有两种协调模式:协同式(事件监听) 和 编排式;
- Saga 只满足ACD(原子、一致、持久),不满足隔离性,可能导致:丢失更新、脏读或不可重复读;(解决方法)
5.3 常见 流量控制/限流 算法
| 比较项 | 固定窗口算法 | 滑动窗口算法 | 滑动日志算法 | 漏桶算法 | 令牌桶算法 | Redis 分布式限流 |
|---|---|---|---|---|---|---|
| 概念 | 通过一个支持原子操作的计数器来累计 1 秒内的请求次数,当 1 秒内计数达到限流阈值时触发拒绝策略。每过 1 秒,计数器重置为 0 开始重新计数 | 与固定窗口原理类似 | 记录下所有的请求时间点,新请求到来时先判断最近指定时间范围内的请求数量是否超过指定阈值,由此来确定是否达到限流 | 用一个队列以先入先出的方式来进行请求处理 | 桶里放令牌,拿到令牌就处理 | 基于 incr 自增命令。使用 ZSET 有序集合来实现滑动窗口限流 |
| 优点 | 简单方便 | 窗口滑动的间隔越短,时间窗口的临界突变问题发生的概率也就越小 | 没有突变问题 | 恒定速度,保护系统 | ||
| 缺点 | 时间窗口的临界突变问题(第 1s 中的后 500 ms 和第 2s 的前 500ms ) | 可能发生时间窗口的临界突变问题 | 占用的内存较多 | 恒定速度,不能同时处理响应 | 需要开定时线程加令牌,有很多个是消耗资源(解决:在每次令牌获取时才进行计算令牌是否足够的) | |
| 适用范围 | 流量比较均匀时 | 流量比较均匀时 | 流量比较少 | 异步处理,不要求及时响应 | ||
| 实际应用 | Sentinel(但是是分布式限流) | Google 的 Java 开发工具包 Guava 中的限流工具类 RateLimiter |
- 总结:
| 比较项 | 窗口算法 | 桶算法 |
|---|---|---|
| 优点 | 简单、直观的得到当前的 QPS 情况 | 速率恒定、 |
| 缺点 | 有时间窗口的临界突变问题、没有队列缓冲 | 不好统计 QPS、(漏桶)不能应对突发流量、(令牌)启动加载缓慢 |
5.4 Hash 算法相关(一致 hash)
| 比较项 | hash 算法 | 一致 hash 算法 | 带虚拟节点的一致 hash 算法 |
|---|---|---|---|
| 概念 | 先取 hash 值,对机器总数取余 | 先取 hash 值,映射到一个环里 | 按比例增加虚拟节点,时 hash 环均匀 |
| 优点 | 简单 | 解决机器增减问题群 | 解决均匀问题 |
| 缺点 | 一台机器宕机后不能正确命中 hash,导致缓存雪崩问题 | hash 分布不均匀引起 | 增减节点时可能会有点麻烦 |
| 适用范围 | 机器数量稳定不变 | 机器数量比较多,能分布均匀 | 机器数量经常改变 |
| 实际应用 | Java 里用 TreeMap 实现(问题是 TreeMap 不是线程安全) |
5.5 CDN
1. CDN 是什么
- Content Delivery Network/Content Distribution Network:内容分发网络;
- 内容:指静态资源,如:图片、视频、文档、JS、CSS、HTML;
- 分发网络:将这些静态资源分发到位于多个不同的地理位置机房中的服务器上,以实现就近访问(加快静态资源的访问速度,减轻服务器以及带宽的负担);
- 与 全站加速 的区别:全站加速可以加速静态资源和动态资源,CDN加速静态资源;
2. 工作原理
- 静态资源是如何被缓存到 CDN 节点中的?
- 预热;
- 回源:不预热导致 CDN 向源站访问资源;(缓存预热)
- 命中率越高、回源率越低越好;
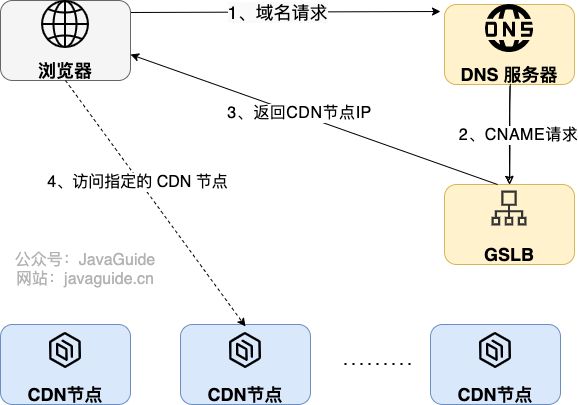
- 如何找到最合适的 CDN 节点?
- GSLB (Global Server Load Balance,全局负载均衡);
- 浏览器向 DNS 服务器发送域名请求;
- DNS 服务器向根据 CNAME( Canonical Name ) 别名记录向 GSLB 发送请求;
- GSLB 返回性能最好(通常距离请求地址最近)的 CDN 节点(边缘服务器,真正缓存内容的地方)的地址给浏览器;
- 浏览器直接访问指定的 CDN 节点;
- GSLB 会根据请求的 IP 地址、CDN 节点状态(比如负载情况、性能、响应时间、带宽)等指标来综合判断具体返回哪一个 CDN 节点的地址;
- GSLB (Global Server Load Balance,全局负载均衡);
- 如何防止资源被盗刷?
- Referer 防盗链:根据 HTTP 请求的头信息里面的 Referer 字段对请求进行限制;
- 时间戳防盗链:请求 URL 包含两个参数:
签名字符串、过期时间。签名字符串:通过对用户设定的加密字符串、请求路径。过期时间:通过 MD5 哈希算法取哈希的方式获得
5.6 CAP 理论
- 与《微服务架构 | 3. 注册中心与服务发现》中讲解的一样,指在分布式系统中不可能同时满足一致性(C:Consistency)、可用性(A:Availability)、分区容错性(P:Partition Tolerance)这三个基本需求,最多同时满足两个;
- C:数据在多个副本中要保持强一致,比如前面说的分布式数据一致性问题;
- A:系统对外提供的服务必须一直处于可用状态,在任何故障下,客户端都能在合理的时间内获得服务端的非错误响应;
- P:在分布式系统中遇到任何网络分区故障,系统仍然能够正常对外提供服务;
- 网络分区:不同节点分布在不同的子网络中时,在内部子网络正常的情况下,由于某些原因导致这些子节点之间出现网络不通的情况,导致整个系统环境被切分成若干独立的区域,这就是网络分区;
- 在分布式系统中,不会选择 CA,而是 AP 和 CP;
- AP:放弃了强一致性,实现最终的一致,是很多互联网公司解决分布式数据一致性问题的主要选择;
- CP:放弃了高可用性,实现强一致性。前面提到的两阶段提交和三阶段提交都采用这种方案。可能导致的问题是用户完成一个操作会等待较长的时间;
- CA:无法同时做到保证数据一致性和可用,要保证数据一致性可能要拒绝客户端请求,除非网络百分百可靠;
5.7 BASE 理论
- BASE 理论是由于 CAP 中一致性 C 和可用性 A不可兼得而衍生出来的一种新的思想,BASE 理论的核心思想是通过牺牲数据的强一致性来获得高可用性。它有如下三个特性;
- Basically Available(基本可用):分布式系统在出现故障时,允许损失一部分功能的可用性,保证核心功能的可用;
- Soft State(软状态):允许系统中的数据存在中间状态,这个状态不影响系统的可用性,也就是允许系统中不同节点的数据副本之间的同步存在延时;
- Eventually Consistent(最终一致性):中间状态的数据在经过一段时间之后,会达到一个最终的数据一致性;
- BASE 理论并没有要求数据的强一致,而是允许数据在一段时间内是不一致的,但是数据最终会在某个时间点实现一致;
- 在互联网产品中,大部分都会采用 BASE 理论来实现数据的一致,因为产品的可用性对于用户来说更加重要;
- 举个例子,在电商平台中用户发起一个订单的支付,不需要同步等待支付的执行结果,系统会返回一个支付处理中的状态到用户界面。对于用户来说,他可以从订单列表中看到支付的处理结果。而对于系统来说,当第三方的支付处理成功之后,再更新该订单的支付状态即可。在这个场景中,虽然订单的支付状态和第三方的支付状态存在短期的不一致,但是用户却获得了更好的产品体验;
5.8 分布式追踪
- Sleuth:
- 追踪服务调用链,只需要引入依赖文件即可;
- 格式:服务的应用程序名称,跟踪 ID(表示整个事务的唯一编号),跨度 ID(整个事务中某一部分的唯一 ID),是否将跟踪数据发送到 Zipkin;
- Papertrail:
- 日志聚合。是 Windows 的日志分析器,可自动扫描日志数据。过滤数据。
- Zipkin:
- 可视化日志追踪;
- 一请求链路,一条链路通过
Trace Id(跟踪 ID)唯一标识,Span 标识发起的请求信息,各 Span 通过Parent id(跨度 ID)关联起来; - 主程序类上标注注解:@EnableZipkinServer(创建相对简单,Zipkin提供);@EnableZipkinStreamServer(发布消息到 RabbitMQ 或 Kafka,Spring Cloud 提供)
- 一请求链路,一条链路通过
6. 机器学习
6.1 机器学习
1. 机器学习算法分类
- 利用目标值分类:
- 监督学习:输入数据有特征有标签,即有标准答案(目标值);
- 分类问题:目标值有类别(离散型);
- 算法:k-近邻算法、贝叶斯分类、决策树与随机森林、逻辑回归与二分类、神经网络;
- 回归问题:目标值是数据(连续型);
- 算法:线性回归、岭回归;
- 分类问题:目标值有类别(离散型);
- 无监督学习:无目标值;
- 算法:聚类:k-means;
- 监督学习:输入数据有特征有标签,即有标准答案(目标值);
2. 机器学习开发流程
- 获取数据(数据集);
- 数据处理;
- 特征工程;
- 机器学习算法训练,得到模型;
- 模型评估;(模型好则应用,不好则 2.数据处理 循环)
- 应用;
3. 模型选择与调优
- 交叉验证 cross validation
- 目的:为了让被评估的模型更加准确可信;
- 定义:将拿到的训练数据,分为训练和验证集。以下图为例:将数据分成 4 份,其中一份作为验证集。然后经过 4 次(组)的测试,每次都更换不同的验证集。即得到 4 组模型的结果,取平均值作为最终结果。又称 4 折交叉验证。

- 超参数搜索-网格搜索 Grid Search
- 超参数:有很多参数是需要手动指定的(如k-近邻算法中的K值),这种叫超参数;
- 网格搜索:但是手动过程繁杂,所以需要对模型预设几种超参数组合。每组超参数都采用交叉验证来进行评估。最后选出最优参数组合建立模型;
4. [分类] K-近邻算法(KNN 算法)
- 定义:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别;
- 距离公式:欧式距离 r = ( a 1 − b 1 ) 2 + ( a 2 − b 2 ) 2 + ( a 3 − b 3 ) 2 r=\sqrt{(a_1-b_1)^2 + (a_2-b_2)^2 + (a_3-b_3)^2} r=(a1−b1)2+(a2−b2)2+(a3−b3)2
- 其他:曼哈顿距离(绝对值距离)、明科夫斯基距离 minkowski;
- 问题:
- K 值取得过小,容易受到异常点影响;
- K 值取得过大,会有样本不均匀的影响;
- 需要先进行无量钢化处理-标准化;
- 优点:
- 简单,易于理解,易于实现,无需训练;
- 缺点:
- 懒惰算法,对测试样本分类时的计算量大,内存开销大;
- 必须指定 K 值,K 值选择不当则分类精度不能保证;
- 应用场景:小数据场景,几千~几万样本,具体场景具体业务去测试;
5. [分类] 朴素贝叶斯算法
- 朴素 + 贝叶斯公式:
- 朴素:假设特征与特征之间是相互独立的;
- 公式: P ( C ∣ W ) = P ( W ∣ C ) P ( C ) P ( W ) P(C|W)=\frac{P(W|C)P(C)}{P(W)} P(C∣W)=P(W)P(W∣C)P(C);
- 应用场景:文本分类;
- 优点:
- 朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率;
- 对缺失数据不太敏感,算法也比较简单,常用于文本分类;
- 分类准确度高,速度快;
- 缺点:
- 由于使用了样本属性独立性的假设,所以如果特征属性有关联时其效果不好;
6. [分类] 逻辑回归与二分类
- 定义:逻辑回归(Logistic Regression)是机器学习中的一种分类模型,逻辑回归是一种分类算法,虽然名字中带有回归,但是它与回归之间有一定的联系。由于算法的简单和高效,在实际中应用非常广泛;
7. [回归] 线性回归
- 定义:线性回归(Linear regression)是利用回归方程(函数)对一个或多个自变量(特征值)和因变量(目标值)之间关系进行建模的一种分析方式;
- 特点:只有一个自变量的情况称为单变量回归,大于一个自变量情况的叫做多元回归;
- 广义线性模型:自变量一次(线性关系) + 参数一次;
- 公式:w 为权重值(回归系数);b 为偏置;
8. [回归] 岭回归
- 定义:岭回归,其实也是一种线性回归。只不过在算法建立回归方程时候,加上正则化的限制,从而达到解决过拟合的效果。即:带有L2正则化的线性回归;