Java并发编程第10讲——CAS相关知识点详解
前面介绍锁的时候顺便也提到了CAS,但作为JUC的“基石”和面试中的高频考点,还是不够。所以,本篇文章将从CAS的概念入手,逐步深入介绍12个Atomic原子操作类、CAS的实现原理(源码解析)、Unsafe类、CAS存在的问题以及LongAddr。
一、什么是CAS
CAS全称Compare And Swap,顾名思义就是先比较再交换。主要应用就是实现乐观锁和锁自旋。CAS操作包含三个操作数——内存位置(V)、预期值(A)和新值(B)。在并发修改的时候,会先比较A和V的值是否相等,如果相等,则会把值替换成B,否则就不做任何操作。
当多个线程尝试使用CAS同时更新同一个变量时,只有其中一个线程能更新变量的值,而其它线程都失败,失败的线程不会被挂起,而是被告知这次竞争失败,并可以再次尝试。
在JDK1.5中新增的java.util.concurrent(JUC)就是建立在CAS之上的。相对于synchronized这种阻塞型的同步,CAS是非阻塞算法的一种常见实现,所以JUC在性能上有了很大的提升。
二、举个例子
我们先看一个经典的例子:
public class Demo {
public static volatile int i=0;
public static void increase(){
i++;
}
public static void main(String[] args) throws InterruptedException {
//启动10个线程,每个线程累加10000次
for (int j = 0; j < 10; j++) {
new Thread(() -> {
for (int k = 0; k < 10000; k++) {
increase();
}
}, String.valueOf(j)).start();
}
while (Thread.activeCount() > 2) {
Thread.yield();
}
System.out.println("最后i的值为:" + i);
}
}这个例子在Java并发编程第5讲——volatile关键字中也用过,启动10个线程,每个线程累加10000次,那么i的预期的结果是100000,但运行完这段代码得到的结果都是小于100000的数字。
这是因为volatile只能保证可见性,无法保证原子性,而自增操作并不是一个原子操作,它会出现写回主存覆盖的问题,送一我们每次都无法获得想要的结果,那么如何解决呢?说白了,这也就是线程安全问题,那么我们可以从保障线程安全入手,以下提供几个方案:
- synchronized:线程内使用同步代码块,由JVM自身的机制来保障线程的安全性。
- Lock锁:基于AQS+CAS实现。
- Atomic原子类:这就是我们今天的主角,下面再细说。
- LongAdder原子类:和Atomic原子类在同一包下,不过LongAdder更适合于高并发场景下,特别是写大于读的场景,相较于Atomic性能更好,代价是消耗更多的空间,以空间换时间。(下面也会细说)。
三、12个Atomic原子操作类
Java从JDK 1.5开始提供了java.util.concurrent.atomic包,这个包中的原子操作类提供了一种用法简单、性能高效、线程安全地更新一个变量的方式。
因为变量的类型由很多种,所以在Atomic包里一共提供了12个类,可以分为4种类型,分别是基本类型、数组、引用、字段。Atomic包里的类基本都是使用Unsafe实现的包装类。
3.1 基本类型(3个)
- AtomicBoolean:布尔类型
- AtomicInteger:整型类型
- AtomicLong:长整型类型
它们三个提供的方法基本一样,所以就以AtomicInteger为例,下面是它常用的方法:
AtomicInteger(int initialValue):构造方法,设置初始值,若不设置则初始值为0。int getAndIncrement():以原子方式进行+1操作,并返回自增前的值。int IncrementAndGet():以原子方式进行+1操作,并返回自增后的值。int decrementAndGet():以原子方式进行-1操作,并返回自减后的值。int get():返回当前值。int addAndGet(int delta):以原子方式将输入的值于当前值相加,并返回结果。boolean compareAndSet(int expect,int update):如果输入的值(expect)等于AtomicInteger的当前值,则以原子的方式将该值设置为输入的值(update),成功返回ture,反之返回false。
现在,我们可以用AtomicInteger来改造一下上面的代码,使其正常运行:
public class Demo {
public static AtomicInteger i=new AtomicInteger();
public static void increase(){
i.getAndIncrement();
}
public static void main(String[] args) throws InterruptedException {
//启动10个线程,每个线程累加1000次
for (int j = 0; j < 10; j++) {
new Thread(() -> {
for (int k = 0; k < 10000; k++) {
increase();
}
}, String.valueOf(j)).start();
}
while (Thread.activeCount() > 2) {
Thread.yield();
}
System.out.println("最后i的值为:" + i.get());//100000
}
}我们把i改成使用AtomicInteger定义,i++改为“i.incrementAndGet()”使其变成原子操作,所以我们可以确保每次都可以获得正确的结果,并且性能上也有了不错的提升。
3.2 数组类型(3个)
通过原子的方式更新数组里的某个元素。
- AtomicIntegerArray:整型数组
- AtomicLongArray:长整型数组
- AtomicReferenceArray:引用类型数组
这三个提供的方法也基本一样,下面以AtomicIntegerArray为例,先看一下它的常用方法:
AtomicIntegerArray(int length):构造方法,创建指定长度的AtomicIntegerArray对象,所有元素的初始值都是0。AtomicIntegerArray(int[] array):构造方法,使用指定的整型数组初始化AtomicIntegerArray对象,数组的长度就是AtomicIntegerArray的长度。int get(int index):获取指定索引处的元素值。int length:返回数组的长度。void set(int index,int newValue):设置指定索引处的新值。int getAndIncrement(int index):获取指定索引处的旧值,并将其+1。int getAndDecrement(int index):获取指定索引处的旧值,并将其-1。int getAndAdd(int index,int delta):获取指定索引处的旧值,并将其加delta。
举个例子:
public class ArrayDemo {
public static void main(String[] args) {
//指定长度为3的AtomicIntegerArray对象,初始值都是0
AtomicIntegerArray array=new AtomicIntegerArray(3);
//获取索引为0的元素值
System.out.println(array.get(0));//0
//给索引为1的元素值设置为5
array.set(1,5);
System.out.println(array.get(1));//5
}
}3.3 引用类型(3个)
如果要原子更新多个变量,就需要使用这个原子更新引用类型提供的类。
- AtomicReference:原子更新引用类型。
- AtomicStampedReference:在AtomicReference的基础上增加了版本号的功能。
- AtomicMarkableReference:在AtomicReference的基础上增加了布尔标记的功能。
下面就以AtomicReference为例,常用方法:
AtomicReference(V initialValue):构造方法,创建一个AtomicReference对象,并将初始值设置为initialValue。V get():获取当前的引用值。void set(V newValue):设置新的引用值。boolean compareAndSet(V expect,V update):如果引用值于期望值相等,则设置update为新值。V getAndSet(V newValue):设置新的引用,并返回旧的引用。
举个例子:
public class ReferenceDemo {
public static void main(String[] args) {
Student student = new Student("张三", 20);
//创建一个指定引用为Student的AtomicReference对象
AtomicReference reference=new AtomicReference<>(student);
//获取当前引用
System.out.println(reference.get());//ReferenceDemo.Student(name=张三, age=20)
//修改student引用
student.setAge(18);
student.setName("小黑子");
//设置新的引用
reference.set(student);
System.out.println(reference.get());//ReferenceDemo.Student(name=小黑子, age=18)
}
@AllArgsConstructor
@NoArgsConstructor
@Data
static class Student{
private String name;
private int age;
}
} 3.4 字段类型(3个)
如果需要原子地更新某个类的某个字段时,那么就可以用原子更新字段类。
- AtomicIntegerFieldUpdater:整型,可以在指定的对象上进行原子更新操作,支持原子地设置、获取、增加、减少等操作。
- AtomicLongFieldUpdater:长整型,可以在指定的对象上进行原子更新操作,支持原子地设置、获取、增加、减少等操作。
- AtomicReferenceFieldUpdater:引用类型,可以在指定的对象上进行原子更新操作,支持原子地设置、获取、增加、减少等操作。
下面以AtomicIntegerFieldUpdater为例,常用方法:
AtomicIntegerFieldUpdater newUpdater(Class tclass,String fieldName):用于操作指定类种的指定字段。int get(T obj):获取指定对象的字段的当前值。void set(T obj,int newValue):设置指定对象的字段的值为指定的新值。int getAndIncrement(T obj):以原子的方式将指定对象的字段+1,并返回旧值。int getAndDecrement(T obj):以原子的方式将指定对象的字段-1,并返回旧值。
举个例子:
@Data
public class IntegerUpdaterDemo {
//字段必须是 volatile 类型的
private volatile int score;
//创建AtomicIntegerFieldUpdater 实例
private static final AtomicIntegerFieldUpdater SCORE_UPDATER =
AtomicIntegerFieldUpdater.newUpdater(IntegerUpdaterDemo.class, "score");
public static void main(String[] args) {
IntegerUpdaterDemo demo = new IntegerUpdaterDemo();
demo.setScore(80);
//使用AtomicIntegerFieldUpdater进行原子性更新操作
int newValue = 90;
int oldValue = SCORE_UPDATER.getAndSet(demo, newValue);
System.out.println("原始值: " + oldValue + ", 更新后的值: " + demo.getScore()); //原始值: 80, 更新后的值: 90
}
} 四、CAS实现原理
下面以AtomicInteger原子整型类为例,分析一下CAS底层实现机制。
4.1 AtomicInteger的getAndIncrement方法
上面解决i++问题的时候用到了AtomicInteger的getAndIncrement方法,通过方法调用,可以发现getAndIncrement方法调用了getAndAddInt方法,最后调用的是Unsafe类的compareAndSwapInt方法,也就是我们今天要介绍的CAS:
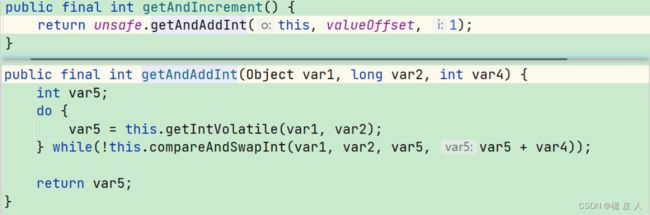
compareAndSwapInt方法参数解释:
- var1:Unsafe对象本身,需要通过这个类获取value的内存偏移地址。
- var2:value变量的内存偏移地址。
- var4:需要增加或减少的数。
- var5:内存位置的最新值。
- var5+var4:要更新的最新值。
就是拿到内存位置的最新值var5,使用CAS尝试将内存位置的值修改为目标值var5+var4,如果修改失败,则获取改内存位置的新值var5,然后继续尝试,直到成功。
4.2 Unsafe类
读到这我们知道Java中Atomic类的实现都是基于Unsafe类实现的,那么Unsafe类是什么呢?
4.2.1 什么是Unsafe类
Unsafe类是CAS的核心类。因为Java无法直接访问底层操作系统,而是通过本地(native)方法来访问。不过JVM还是开了一个后门,JDK中有一个Unsafe类,他提供了硬件级别的原子操作,说白了Unsafe类就是跟底层硬件CPU指令通讯的复制工具。
Unsafe类包含了很多基础操作,比如数组操作、对象操作、内存操作、CAS操作、线程(park)操作,栅栏(Fence)操作,JUC包以及一些三方框架都是用Unsafe类来保证线程安全。
Unsafe类在jdk源码的多个类中用到,这个类提供了一些绕开JVM的更底层的功能,基于它的实现可以提高效率。不过,正如它名字那样——不安全类,他所分配的内存需要手动free(不会被GC回收)。
Unsafe类提供了硬件级别的操作,主要有以下功能:
- 通过Unsafe类可以分配内存,可以释放内存。
- 可以定位对象某字段的内存位置,也可以修改对象的字段值,即使它是私有的。
- 将线程进行挂起与恢复。
- CAS操作。
4.2.2 举个例子
Unsafe被设计的初衷,并不是希望被一般开发者调用,它的构造方法是私有的,所以我们不能通过new或工厂方法实例化Unsafe对象,通常用反射来获取Unsafe示例:
private static Unsafe getUnsafeInstance() throws NoSuchFieldException, IllegalAccessException {
//Unsafe类中提供了一个静态的getUnsafe方法,可以返回一个Unsafe实例
Field unsafeField = Unsafe.class.getDeclaredField("theUnsafe");
unsafeField.setAccessible(true);
return (Unsafe) unsafeField.get(null);
}来看一下分配内存的例子:
public class UnsafeDemo {
public static void main(String[] args) throws NoSuchFieldException, IllegalAccessException {
Unsafe unsafe = getUnsafeInstance();
//分配一个包含10个整数的连续内存空间
long size = 10 * Integer.BYTES;
//分配内存
long memoryAddress = unsafe.allocateMemory(size);
//在内存中存储值
for (int i = 0; i < 10; i++) {
unsafe.putInt(memoryAddress + i * Integer.BYTES, i);
}
for (int i = 0; i < 10; i++) {
//从内存中读取值
int value = unsafe.getInt(memoryAddress + i * Integer.BYTES);
System.out.println(value);
}
//释放内存
unsafe.freeMemory(memoryAddress);
}
//获取Unsafe实例
private static Unsafe getUnsafeInstance() throws NoSuchFieldException, IllegalAccessException {
Field unsafeField = Unsafe.class.getDeclaredField("theUnsafe");
unsafeField.setAccessible(true);
return (Unsafe) unsafeField.get(null);
}
}同样,也可以用Unsafe类实现一个CAS操作,这里就不做演示了。
4.2.3 Unsafe类的compareAndSwapInt方法
介绍完Unsafe类,我们书接4.1,接着继续深入探讨该方法,该方法在Unsafe中对应的C++源码如下:

可以看到调用了Atomic::cmpxchg方法,那么我们再来看看Atomic::cmpxchg方法:

标红框的地方就是调用了汇编指令cmpxchg,作用是比较并交换而CAS操作的原理就是基于硬件提供的原子操作指令——cmpxchg指令实现的:
- cmpxchg指令是一条原子指令。在cpu执行cmpxchg指令时,处理器会自动锁定总线,防止其它cpu刚问共享变量,然后执行比较和交换操作,最后释放总线。
- cmpxchg指令在执行期间,cpu会自动禁止中断。这样可以确保CAS操作的原子性,避免中断或其它干扰对操作的影响。
- cmpxchg指令时硬件实现的,可以保证其原子性和正确性。cpu中的硬件电路确保了cmpxchg指令的正确执行,以及对共享变量的访问原子性。
ps:同样是因为cmpxchg指令,这个指令基于cpu缓存一致性协议实现的。在多个cpu中,所有核心的缓存都是一致的。当一个cpu核心执行cmpxchg指令时,其它cpu核心的缓存会自动更新,以确保对共享变量的访问是一致的。
五、CAS存在的问题
任何技术都不是十全十美的,强如硬件级别实现的CAS操作也会有瑕疵。
5.1 ABA问题
CAS算法实现一个重要前提是需要取出内存中某时刻的数据,而在下个时刻进行比较和交换,那么这个时间差会导致数据的变化。
比如,当线程1要修改A时,会先读取A的值,如果此时有一个线程2,经过一系列操作,将A修改为B,再由B修改为A,然后线程1在比较A时,发现A的值没有改变,于是就修改了。但此时A的版本已经不是最先读取的版本了,这就时ABA问题。
如何解决?解决这个问题的办法也很简单,就是添加版本号,修改数据时带上一个版本号,如果版本号我数据的版本号一致就修改(同时修改版本号),否则就失败,或者改用传统的互斥同步方式。
5.2 忙等待问题
上面的getAndAddInt方法就是一个很好的例子,getAndAddInt方法执行时,如果CAS失败,会一直尝试。如果CAS长时间一直不成功,可能会给CPU带来很大的开销。
5.3 只能保证一个共享变量的原子操作
当对一个共享变量操作时,我们可以用CAS的方式来保证原子操作,但是对于多个共享变量操作时,循环CAS就无法保证操作的原子性,这个时候我们可能就会用锁来保证原子性。
六、LongAdder
在5.2中提到的忙等待问题会给CPU带来很大的开销,从而会使性能下降。当然在大部分场景下使用Atomic原子操作类还是绰绰有余的,但在多线程竞争比较激烈,也就是并发冲突比较大的情况下,就得考虑其它方案了,比如LongAddr。
6.1 什么是LongAddr
LongAddr是Java 8中推出的一个新的类,主要是为了解决Atomic原子操作类在多线程竞争激烈的情况下性能并不高的问题,它主要是采用分段+CAS的方式来提升原子操作的性能。
但是性能高就意味着要有牺牲,而LongAddr就是典型的以空间换时间的实现方式,所以它需要用到更大的空间,而且LongAddr还可能存在结果不准确的问题,Atomic原子操作类并不会。
将AtomicInteger的例子改造一下:
public class LongAddrDemo {
public static LongAdder i=new LongAdder();
public static void increase(){
i.increment();
}
public static void main(String[] args) throws InterruptedException {
//启动10个线程,每个线程累加1000次
for (int j = 0; j < 10; j++) {
new Thread(() -> {
for (int k = 0; k < 10000; k++) {
increase();
}
}, String.valueOf(j)).start();
}
while (Thread.activeCount() > 2) {
Thread.yield();
}
System.out.println(i.sum());//100000
}
}6.2 LongAddr实现原理(源码解析)
Java 8中的LongAddr类继承自抽象类Striped64(也是atomic包下的),这个类也是Java 8新增的,主要的作用就是给并发场景下提供计数支持。
Striped64的设计思路与ConcurrentHashMap类似,都是通过分散竞争的方式来提升并发性能,其中主要依赖了两个字段:

解释:
- cells数组:当检测到有base变量被线程占有时,就会尝试暂存在cells数组中。
- base变量:当没有线程竞争时,首先会改变base的值。
最终的结果:base变量+cells数组中value。
通过查看LongAddr中的add方法的代码,我们就能更好地理解:

解释:
外层if:判断是否需要通过base进行累加
如果cells数组!=null,说明已经存在分段累加器(cells数组),则不需要base进行累加。
如果cells数组==null,即不存在分段累加器,那么就尝试使用cas进行base累加,失败则进入if进行更细粒度的累加。
内层if:进一步判断是否需要进行细粒度的累加操作
再一次判断cells数组是否为空,为空则表示没有分段的累加器。不为空进入下一步。
cells数组长度m是否小于0。不小于0进入下一步。
getProbe()&m通过探针索引获取cells数组中的某个位置的cell对象a,看是否有初始化。不为空进入下一步。
将Cell对象a的value与v+x进行CAS操作。
满足以上四个判断之一,则调用longAccumulate方法进行细粒度的累加操作。
总结一下,首先尝试通过CAS更新base的值,如果再竞争不激烈的情况下,是可以CAS成功的,如果成功,那么就和Atomic原子操作类一样了。如果失败,那么就代表竞争激烈,那么就会尝试通过cells数组来分散计数。Striped64根据线程来计算哈希,然后将不同的线程分散到不同Cell数组的index上,然后这个线程的计数内容就会保存在该Cell的位置上面,最后总计数则是base加上cells数组中的计数内容。
这跟ConcurrentHashMap的分段锁很像吧。最后再来看看它是怎么统计的:

很简单,就是将base和cells数组中的值都加起来得到最终的结果。
6.3 LongAddr计算不准确的问题
还是那句话,没有十全十美的技术,那么LongAddr为什么会存在计算不准确的情况呢?
通过查看LongAddr的代码很容易可以发现一个问题,那就是LongAddr的累加结果可能是不准确的,而且sum这个方法的注释上也明确点处了这个问题:
Returns the current sum. The returned value is NOT an atomic snapshot; invocation in the absence of concurrent updates returns an accurate result, but concurrent updates that occur while the sum is being calculated might not be incorporated.
翻译过来就是:返回值不是原子快照;在没有并发更新的情况下调用会返回准确的结果,但是在计算总和时发生并发更新可能不会被纳入计算。举个极端的例子:在并发高的情况下,如果刚好返回sum的时候有其它原子操作进行了累加操作,那么这时候返回的sum就会不准。
总体来说,LongAddr在高并发情况下提供了更好的性能,但牺牲了计算的准确性,所以它更适合应用于并发竞争激烈,但对数据准确度要求并不是百分之百准确的场景,比如微博点赞、文章阅读量的统计等场景。
End:希望对大家有所帮助,如果有纰漏或者更好的想法,请您一定不要吝啬你的赐教。