极客时间《数据分析实战45讲 - 基础篇》学习笔记
目录
图书资源
Numpy操作
Pandas操作
用户画像
数据采集
Python数据爬取
数据处理
可视化
其他
图书资源
思维:《思维简史:从丛林到宇宙》
商业相关: 《洛克菲勒留给儿子的38封信》 《商业冒险:华尔街的12个经典故事》 《从0到1:开启商业与未来的秘密》 《商业的本质》
数据处理:《数据挖掘:概念与技术》 《Pentaho Kettle解决方案》 《精益数据分析》 《Small Data》 《利用Python进行数据分析》《深入浅出数据分析》
问题:
- 1. C4.5、CART和其他决策树算法的区别?EM原理和实现?
- 矩阵和向量运作在数据挖掘中如何运用的?最优化方法的概念对迭代收敛的作用?
- 矩阵在PCA 方法、SVD 方法,以及 MF、NMF 方法中的应用?
- 隐式拷贝是什么?浅拷贝和深拷贝是什么意思?参考Python - 对象赋值、浅拷贝、深拷贝的区别 - 1024搜-程序员专属的搜索引擎但是没看懂
- 快速排序、合并排序、堆排序区别和实现?
- pandasql.sqldf中什么时候用globals()什么时候用locals()?
数据挖掘的过程可以分成以下 6 个步骤。
- 商业理解:数据挖掘不是我们的目的,我们的目的是更好地帮助业务,所以第一步我们要从商业的角度理解项目需求,在这个基础上,再对数据挖掘的目标进行定义。
- 数据理解:尝试收集部分数据,然后对数据进行探索,包括数据描述、数据质量验证等。这有助于你对收集的数据有个初步的认知。
- 数据准备:开始收集数据,并对数据进行清洗、数据集成等操作,完成数据挖掘前的准备工作。
- 模型建立:选择和应用各种数据挖掘模型,并进行优化,以便得到更好的分类结果。
- 模型评估:对模型进行评价,并检查构建模型的每个步骤,确认模型是否实现了预定的商业目标。
- 上线发布:模型的作用是从数据中找到金矿,也就是我们所说的“知识”,获得的知识需要转化成用户可以使用的方式,呈现的形式可以是一份报告,也可以是实现一个比较复杂的、可重复的数据挖掘过程。数据挖掘结果如果是日常运营的一部分,那么后续的监控和维护就会变得重要。
Python数据类型基本操作:
| 列表 | 增:list.append(), list.insert(index, value) 删:list.pop() |
| 元组 | 不能改 |
| 字典 | 增:dict['key'] = value 删:dict.pop('key') 查:‘key’ in dict, dict.get('key') |
| 集合 | 增:set.add(value) 删:set.remove(value) |
注释在 python 中使用 #,如果注释中有中文,一般会在代码前添加 # -- coding: utf-8 -。
import 引用可以是模块 module,或者包 package。针对 module,实际上是引用一个.py 文件。而针对 package,可以采用 from package_name import moudule_name的方式,这里实际上是从一个目录中引用模块,这时目录结构中必须带有一个 __init__.py 文件。
由于列表中的元素可以是任意的对象,所以列表中 list 保存的是对象的指针。虽然在 Python 编程中隐去了指针的概念,但是数组有指针,Python 的列表 list 其实就是数组。这样如果我要保存一个简单的数组[0,1,2],就需要有 3 个指针和 3 个整数的对象,这样对于 Python 来说是非常不经济的,浪费了内存和计算时间。
为什么要用 NumPy 数组结构而不是 Python 本身的列表 list?这是因为列表 list 的元素在系统内存中是分散存储的,而 NumPy 数组存储在一个均匀连续的内存块中。这样数组计算遍历所有的元素,不像列表 list 还需要对内存地址进行查找,从而节省了计算资源。另外在内存访问模式中,缓存会直接把字节块从 RAM 加载到 CPU 寄存器中。因为数据连续的存储在内存中,NumPy 直接利用现代 CPU 的矢量化指令计算,加载寄存器中的多个连续浮点数。另外 NumPy 中的矩阵计算可以采用多线程的方式,充分利用多核 CPU 计算资源,大大提升了计算效率。
除了使用 NumPy 外,还需要一些技巧来提升内存和提高计算资源的利用率。一个重要的规则就是:避免采用隐式拷贝,而是采用就地操作的方式。举个例子,如果我想让一个数值 x 是原来的两倍,可以直接写成 x*=2,而不要写成 y=x*2。
Numpy操作
问题:numpy.c_和numpy.r_的用法?
NumPy 中数据结构围绕 ndarray 展开
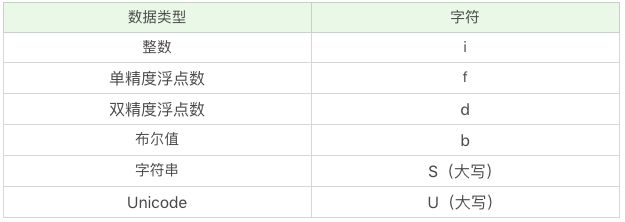
如果数据中使用了中文,可以把类型设置为 U32
# 定义数组结构类型
persontype = np.dtype({
'names':['name', 'age', 'chinese', 'math', 'english'],
'formats':['S32','i', 'i', 'i', 'f']})
peoples = np.array([("ZhangFei",32,75,100, 90),("GuanYu",24,85,96,88.5),
("ZhaoYun",28,85,92,96.5),("HuangZhong",29,65,85,100)],
dtype=persontype)
persontype2 = np.dtype({
'names':['name', 'age', 'english'],
'formats':['U32','i', 'f']})
peoples2 = np.array([("张飞",32,90),("关羽",24,88.5), ("赵云",28,96.5),("黄忠",29,100)], dtype=persontype2)
ages = peoples[:]['age']
chineses = peoples[:]['chinese']
# 创建连续数组:以下两种方式结果一样
x1 = np.arange(1,11,2)
x2 = np.linspace(1,9,5)
# Range of values (maximum - minimum) along an axis.
np.ptp(a, axis=None, out=None, keepdims=)
# 求均值
np.mean() # 求平均数
np.average() # 可以用过设置weights参数求加权平均值
# 求众数
## 法一:只能用在非负数据集
counts = np.bincount(nums)
np.argmax(counts)
## 法二:
from scipy import stats
stats.mode(nums)[0][0]
## 法三:
age_maxf = train_features['Age'].value_counts().index[0]
# 排序
np.sort(array, axis=-1, kind=‘quicksort’, order=None)
# kind里指定quicksort快速排序、mergesort合并排序、heapsort堆排序。
# axis默认是-1,即沿着数组的最后一个轴进行排序,也可以取不同的axis轴,axis=None代表采用扁平化的方式作为一个向量进行排序。
# order字段,对于结构化的数组可以指定按照某个字段进行排序。
Pandas操作
Pandas 中数据结构围绕一维序列 Series 和二维表 DataFrame 展开
# Pandas中的统计函数
temp = pd.Series([i for i in range(1, 20, 2)])
temp.index = [f'row {i}' for i in range(1, 20, 2)]
temp.min() # 1
temp.argmin() # 0
temp.idxmin() # 'row 1'
# 用SQL方式打开Pandas
from pandasql import sqldf
df1 = pd.DataFrame({'name':['ZhangFei', 'GuanYu', 'a', 'b', 'c'], 'data1':range(5)})
pysqldf = lambda sql: sqldf(sql, globals())
sql = "select * from df1 where name = 'ZhangFei'"用户画像
标签维度:
- 用户标签:它包括了性别、年龄、地域、收入、学历、职业、通过何种渠道进行的注册等。这些包括了用户的基础属性。
- 消费标签:消费习惯、购买意向、是否对促销敏感。这些统计分析用户的消费习惯。
- 行为标签:时间段、频次、时长、访问路径。这些是通过分析用户行为,来得到他们使用 App 的习惯。
- 内容分析:对用户平时浏览的内容,尤其是停留时间长、浏览次数多的内容进行分析,分析出用户对哪些内容感兴趣,比如,金融、娱乐、教育、体育、时尚、科技等。
标签类型:
- 数据层指的是用户消费行为里的标签。我们可以打上“事实标签”,作为数据客观的记录。
- 算法层指的是透过这些行为算出的用户建模。我们可以打上“模型标签”,作为用户画像的分类标识。
- 业务层指的是获客、粘客、留客的手段。我们可以打上“预测标签”,作为业务关联的结果。
标签应用:
- 获客:如何进行拉新,通过更精准的营销获取客户。
- 活客:个性化推荐,搜索排序,场景运营等。
- 留客:流失率预测,分析关键节点降低流失率。
数据采集

开放数据源:单位维度,比如政府、企业、高校;行业维度,比如交通、金融、能源等领域。
爬虫抓取:常用工具有火车采集器、八爪鱼、搜集客
日志采集:统计用户的操作。我们可以在前端进行埋点,在后端进行脚本收集、统计,来分析网站的访问情况,以及使用瓶颈等。
Python数据爬取
爬虫的过程包括三个阶段:打开网页、提取数据和保存数据。在“打开网页”这一步骤中,可以使用 Requests 访问页面,得到服务器返回给我们的数据,这里包括 HTML 页面以及 JSON 数据。在“提取数据”这一步骤中,针对 HTML 页面,可以使用 XPath 进行元素定位,提取数据;针对 JSON 数据,可以使用 JSON 进行解析。在最后一步“保存数据”中,我们可以使用 Pandas 保存数据,最后导出 CSV 文件。
Requests访问页面:
Requests 是 Python HTTP 的客户端库,它有两种访问方式:Get 和 Post。Get 把参数包含在 url 中,而 Post 通过 request body 来传递参数。
访问豆瓣,用 Get 从服务器上获取数据:
'''
proxies = { "http": None, "https": None}
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36'
}
'''
r = requests.get('http://www.douban.com') # , proxies=proxies, headers = headers使用 Post 进行表单传递,向服务器传递数据:(自己尝试尚未得到满意结果)
r = requests.post('http://xxx.com', data = {'key':'value'})代理问题:requests 代理设置问题解决方案_简单随风的博客-CSDN博客
状态码有误:利用 r = requests.get('https://www.douban.com') 爬取豆瓣数据返回 r.status_code = 418,参考网络爬虫之Requests爬取豆瓣电影中“三.Requests请求服务器”。
比较:r.text is the content of the response in Unicode, and r.content is the content of the response in bytes. Presumably r.text would be preferred for textual responses, such as an HTML or XML document, and r.content would be preferred for "binary" filetypes, such as an image or PDF file.
XPath定位
使用 XPath 定位,可以用解析库 lxml。XPath 是 XML 的路径语言,通过元素和属性导航定位位置。常用路径表达方式如下:

例:
- xpath(‘node’) 选取了 node 节点的所有子节点;
- xpath(’/div’) 从根节点上选取 div 节点;
- xpath(’//div’) 选取所有的 div 节点;
- xpath(’./div’) 选取当前节点下的 div 节点;
- xpath(’…’) 回到上一个节点;
- xpath(’//@id’) 选取所有的 id 属性;
- xpath(’//book[@id]’) 选取所有拥有属性 id 的 book 元素;
- xpath(’//book[@id=“abc”]’) 选取所有 book 元素,且这些 book 元素拥有 id= "abc"的属性;
- xpath(’//book/title | //book/price’) 选取 book 元素的所有 title 和 price 元素。
想要定位 HTML 中的所有列表项目,可以采用下面这段代码:
from lxml import etree
html = etree.HTML(html)
result = html.xpath('//li')JSON对象
数据爬取(JSON下载和XPath下载两种)
问题:
Python + Selenium + 第三方浏览器可以让我们处理多种复杂场景,包括网页动态加载、JS 响应、Post 表单等。因为 Selenium 模拟的就是一个真实的用户的操作行为,就不用担心 cookie 追踪和隐藏字段的干扰了。
这部分内容中各个技术细节的具体含义?
动态网页与静态网页:静态页面与动态页面的区别_易优CMS
自己尝试的例子:
- 谷歌浏览器右键点击检查,选中Network板块;
- 豆瓣打开网页;
- 输入关键词“王祖贤”,搜索结果中“相关豆瓣内容”中选择“显示更多”,依次出现游园惊梦、阿婴、倩女幽魂等;
- 找到Type为xhr的数据,复制链接为 https://www.douban.com/j/search?q=%E7%8E%8B%E7%A5%96%E8%B4%A4&start=2&subtype=item
- 打开该链接可以看到格式大致为
能看到王祖贤的相关豆瓣内容一共100条,其中一次只返回了 20 条,还有更多的数据可以请求。数据被放到了一个数组结构的 items 对象里,每个数组元素包含一些影片的相关信息。{'items': [...影片信息,如title='倩女幽魂'..., ...影片信息...], 'total': 100, 'limit': 20, 'more': True} - 观察网址本身 https://www.douban.com/j/search?q=王祖贤&start=2&subtype=item,发现有三个参数q、start和subtype。start是请求的起始 ID,此处对图片的顺序标识是从 0 开始计算的。start=2 是因为初始时便显示2条。如果想从第 21 个图片下载,可以设置 start = 20。
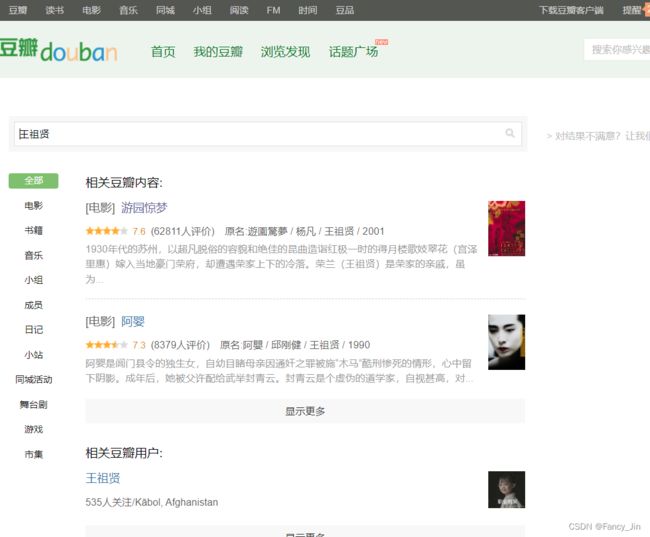
- 对 https://www.douban.com/j/search?q=王祖贤&start=2&subtype=item 中需要的内容利用XPath进行解析,再用根据该链接变动规律,利用 for 循环完成对列表中所有数据的爬取。代码如下
import requests import json import pandas as pd from lxml import etree query = '王祖贤' proxies = { "http": None, "https": None} # 在挂有代理服务器的时候需要设置 headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \ AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.67 Safari/537.36' } # 根据实际情况会有不同,具体获取方法见“状态码有误”部分 df = pd.DataFrame() '''解析信息''' def parse_html(text): html = etree.HTML(text) return html.xpath('//a[@class="nbg"]/@title | //span[@class="rating_nums"]/text() | \ //a[@class="nbg"]/@onclick | //a[@class="nbg"]/@href') ''' for 循环 请求全部的 url ''' for i in range(0, 100, 20): url = 'https://www.douban.com/j/search?q='+query+'&start='+str(i)+'&subtype=item' r = requests.get(url, proxies=proxies, headers=headers) response = json.loads(r.text)['items'] # print(list(map(parse_html, response))) df = pd.concat([df, pd.DataFrame(map(parse_html, response))]) df = df.reset_index(drop=True) df.columns = ['href_link', 'onclick_info', 'title', 'rating'] df.to_excel('E:/your_path/极客时间/crawler_test.xlsx', index=False)
如果是需要用户登陆后才能爬取的数据,可以使用python+selenium的方式完成账户的自动登录,因为selenium是个自动化测试框架,使用selenium的webdriver可以模拟浏览器的行为。找到输入用户名密码的地方,输入相应的值,然后模拟点击即可完成登录(没有验证码的情况下)。另外也可以使用cookie来登录网站:登录网站时,先保存网站的cookie,下次访问时,加载之前保存的cookie,放到request headers中,则不需要再登录网站。
数据处理
问题:
- 为什么MinMaxScaler().fit_transform()对于一个多维数组会以列为维度进行规范化,而不是整个数组或者以行为维度?如果想实现后面两种应该怎么做?z-score规范化的scale()同理。
- 非线性z分原理?没太看懂


# 删除非 ASCII 字符
df['first_name'].replace({r'[^\x00-\x7F]+':''}, regex=True, inplace=True)
# 切分名字
df[['first_name','last_name']] = df['name'].str.split(expand=True)\xnn 匹配ASCII代码中十六进制代码为nn的字符,[x00-x7f] 匹配ASCII值从0-127的字符
0-127表示单字节字符,即数字、英文字符、半角符号及某些控制字符。无法匹配中文。
规范化方法:
min-max规范化:将原始数据变换到[0,1]的空间中。公式为:新数值 =(原数值 - 极小值)/(极大值 - 极小值)。
Z-Score规范化:假设A与B的考试成绩都为80分,A的考卷满分是 100 分(及格60分),B的考卷满分是500分(及格300分)且 A 和 B 的考试成绩都是成正态分布。那么如何用相同的标准来比较A与B的成绩呢?Z-Score可以解决这一问题。定义:新数值 =(原数值 - 均值)/ 标准差。假设A所在班级平均分为80,标准差为 10;B所在班级平均分为400,标准差为100。那么A的新数值=(80-80)/10=0,B的新数值=(80-400)/100=-3.2。则在Z-Score标准下,A的成绩比B好。Z-Score的优点是算法简单,不受数据量级影响,结果易于比较。不足在于,它需要数据整体的平均值和方差,且结果没有实际意义,仅用于比较。
“Z-Score”的非线性计算方式:
- 先按公式计算出百分等级。百分等级(年级)=100-(100x 年级名次 -50)/ 有效参加考试人数。这里百分等级是每个学生在该批学生中的相对位置,其中百分等级是按照正态分布图的所占面积比例求得的;
- 按照百分等级数去标准正态分布表中查询得出 Z-Score 值,这样最终得出的 Z 分便是标准的正态分布,能够将偏态转化成标准正态。
因为在很多情况下,数值如果不是正态分布,而是偏态分布,直接使用 Z-Score 的线性计算方式无法将分数转化成正态分布。采用以上的方法可以解决这一个问题,大家可以了解下。
小数定标规范化:通过移动小数点位置进行规范化。小数点移动位数取决于属性取值中的最大绝对值。比如属性A的取值范围是-999到88,最大绝对值为 999,小数点就会移动 3 位,即新数值 = 原数值/1000。故A的取值范围被规范化为-0.999到0.088。
from sklearn import preprocessing
import numpy as np
x = np.array([[ 0., -3., 1.],
[ 3., 1., 2.],
[ 0., 1., -1.]])
# min-max规范化
min_max_scaler = preprocessing.MinMaxScaler()
minmax_x = min_max_scaler.fit_transform(x)
# 结果:
# [[0. 0. 0.66666667]
# [1. 1. 1. ]
# [0. 1. 0. ]]
# z-score规范化
scaled_x = preprocessing.scale(x)
# 结果:
# [[-0.70710678 -1.41421356 0.26726124]
# [ 1.41421356 0.70710678 1.06904497]
# [-0.70710678 0.70710678 -1.33630621]]
# 小数定标规范化
j = np.ceil(np.log10(np.max(abs(x)))) # np.ceil()向上取整
scaled_x = x/(10**j)
# 结果:
# [[ 0. -0.3 0.1]
# [ 0.3 0.1 0.2]
# [ 0. 0.1 -0.1]]需要规范化的算法:
在数据挖掘算法中,一般情况下是需要进行数据规范化的,尤其是针对距离相关的运算,比如 K-Means、KNN 以及聚类算法中,有对距离的定义,所以在用这些算法前,需要进行数据规范化。
另外一些算法用到了梯度下降作为优化器,这是为了提高迭代收敛的效率,也就是提升找到目标函数最优解的效率。我们也需要进行数据规范化,比如逻辑回归、SVM 和神经网络算法。在这些算法中都有目标函数,需要对目标函数进行求解。梯度下降的目标是寻找到目标函数的最优解,而梯度的方法则指明了最优解的方向。
但不是所有的算法都需要进行数据规范化。如构造决策树时,我们不关心特征值的大小维度,也没有使用到梯度下降来做优化,所以数据规范化对决策树构造结果和构造效率影响不大。除此之外,还是建议在做数据挖掘算法前进行数据规范化。
规范化方法选择:数据比较零散时可以使用Min-Max规范化;如果数据符合高斯分布,可以使用Z-Score规范化。 有些分类方法对归一化比较敏感,比如GaussianNB,效果就不一定好。
可视化
问题:
- 商业智能分析(Tableau & PowerBI)和可视化大屏(DataV)和前端可视化组件的区别?
- 典型的 Web 渲染技术:Canvas、SVG 和 WebGL。简单来说,Canvas 和 SVG 是 HTML5 中主要的 2D 图形技术,WebGL 是 3D 框架。Canvas 适用于位图,也就是给了你一张白板,需要你自己来画点。Canvas 技术可以绘制比较复杂的动画。不过它是 HTML5 自带的,所以低版本浏览器不支持 Canvas。ECharts 这个可视化组件就是基于 Canvas 实现的。SVG 的中文是可缩放矢量图形,它是使用 XML 格式来定义图形的。相当于用点和线来描绘了图形,相比于位图来说文件比较小,而且任意缩放都不会失真。SVG 经常用于图标和图表上。它最大的特点就是支持大部分浏览器,动态交互性实现起来也很方便,比如在 SVG 中插入动画元素等。WebGL 是一种 3D 绘图协议,能在网页浏览器中呈现 3D 画面技术,并且可以和用户进行交互。你在网页上看到的很多酷炫的 3D 效果,基本上都是用 WebGL 来渲染的。下面介绍的 Three.js 就是基于 WebGL 框架的。在了解这些 Web 渲染协议之后,我再来带你看下这些常用的可视化组件: Echarts、D3、Three.js 和 AntV。ECharts 是基于 H5 canvas 的 Javascript 图表库,是百度的开源项目,一直都有更新,使用的人也比较多。它作为一个组件,可以和 DataV、Python 进行组合使用。你可以在 DataV 企业版中接入 ECharts 图表组件。也可以使用 Python 的 Web 框架(比如 Django、Flask)+ECharts 的解决方案。这样可以让你的项目更加灵活地使用到 ECharts 的图表库,不论你是用 Python 语言,还是用 DataV 的工具,都可以享受到 ECharts 丰富的图表库样式。D3 的全称是 Data-Driven Documents,简单来说,是一个 JavaScript 的函数库,因为文件的后缀名通常为“.js”,所以 D3 也常使用 D3.js 来称呼。它提供了各种简单易用的函数,大大简化了 JavaScript 操作数据的难度。你只需要输入几个简单的数据,就能够转换为各种绚丽的图形。由于它本质上是 JavaScript,所以用 JavaScript 也是可以实现所有功能的。Three.js,顾名思义,就是 Three+JS 的意思。“Three”表示 3D 的意思,“Three.js”就是使用 JavaScript 来实现 3D 效果。Three.js 是一款 WebGL 框架,封装了大量 WebGL 接口,因为直接用 WebGL API 写 3D 程序太麻烦了。AntV 是蚂蚁金服出品的一套数据可视化组件,包括了 G2、G6、F2 和 L7 一共 4 个组件。其中 G2 应该是最知名的,它的意思是 The grammar Of Graphics,也就是一套图形语法。它集成了大量的统计工具,而且可以让用户通过简单的语法搭建出多种图表。G6 是一套流程图和关系分析的图表库。F2 适用于移动端的可视化方案。L7 提供了地理空间的数据可视化框架。 这一部分中提到的具体技术内容?
- 核函数和核密度估计?核密度图?
- 蜘蛛图中为什么# plt.xticks(angles[:-1], labels, color='grey', size=8, FontProperties=font)
# ax.set_thetagrids(angles[:-1] * 180/np.pi, labels, FontProperties=font)这两种都是可以实现?通过plt和ax作图的区别在哪里?
散点图:
Matplotlib 默认情况下呈现的是长方形。而 Seaborn 呈现的是正方形,而且不仅显示出了散点图,还给了这两个变量的分布情况。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
N = 1000
x = np.random.randn(N)
y = np.random.randn(N)
df = pd.DataFrame({'x':x, 'y':y})
plt.scatter(x, y, marker='x')
sns.jointplot(x='x', y='y', data=df, kind='scatter')折线图:
在Matplotlib中,可以直接使用 plt.plot() 函数,但需要将x轴的按大小进行排序,否则画出来的折线图将无法按照 x 轴递增的顺序展示。
利用以下代码进行Matplotlib和Seaborn画图,结果一样,只是在Seaborn中标记了x和y轴含义。
x = [2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019]
y = [5, 3, 6, 20, 17, 16, 19, 30, 32, 35]
df = pd.DataFrame({'x_data':x, 'y_data':y})
plt.plot(x, y)
sns.lineplot(x='x_data', y='y_data', data=df)直方图:
可以看到变量的数值分布。
a = np.random.randn(100)
plt.hist(a, bins=10)
sns.distplot(a, bins=10, kde=False)
sns.histplot(a, bins=10, kde=True)
sns.displot(a, bins=10, kde=True)
条形图:
帮助查看类别的特征。
x = ['Cat1', 'Cat2', 'Cat3', 'Cat4', 'Cat5']
y = [5, 4, 8, 12, 7]
df = pd.DataFrame({'x':x, 'y':y})
plt.bar(x, y)
sns.barplot(x='x', y='y', data=df)箱线图:
分析数据的差异性、离散程度和异常值等。
data = np.random.normal(size=(10, 4))
labels = ['A','B','C','D']
df = pd.DataFrame(data, columns=labels)
plt.boxplot(data, labels=labels)
sns.boxplot(data=df)饼图:
nums = [25, 37, 33, 37, 6]
labels = ['High-school','Bachelor','Master','Ph.d', 'Others']
plt.pie(nums, labels=labels)热力图:
flights = sns.load_dataset("flights")
data=flights.pivot('year','month','passengers')
sns.heatmap(data)蜘蛛图:
原理类似于在极坐标系中绘制折线图,并根据需要在其中填充颜色
# 原代码和该代码有区别
from matplotlib.font_manager import FontProperties
labels = np.array([u"推进","KDA",u"生存",u"团战",u"发育",u"输出"])
stats = [83, 61, 95, 67, 76, 88]
angles = np.linspace(0, 2*np.pi, len(labels), endpoint=False)
# endpoint=True时为[0., 1.25663706, 2.51327412, 3.76991118, 5.02654825, 6.28318531]
stats = np.concatenate((stats, [stats[0]]))
angles = np.concatenate((angles, [angles[0]])) # 让曲线闭合故加一位
ax = plt.subplot(111, polar=True)
ax.plot(angles, stats, 'o-', linewidth=2)
ax.fill(angles, stats, alpha=0.25)
font= FontProperties(fname=r"C:\Windows\Fonts\simhei.ttf", size=14)
ax.set_thetagrids(angles[:-1] * 180/np.pi, labels, FontProperties=font)二元变量分布:散点图、核密度图、Hexbin图
Hexbin图代表直方图的二维模拟
sns.jointplot(x='total_bill', y='tip', data=tips, kind='scatter')
sns.jointplot(x='total_bill', y='tip', data=tips, kind='kde')
sns.jointplot(x='total_bill', y='tip', data=tips, kind='hex')成对关系:
sns.pairplot() 会同时展示 DataFrame 中每对变量的关系;在对角线上,能看到每个变量自身作为单变量的分布情况。
iris = sns.load_dataset('iris')
sns.pairplot(iris)其他
问题:
- 规范化后的数值都会在同一个数量的级别上,这样方便后续进行运算。另外还有一些算法用到了梯度下降作为优化器,这是为了提高迭代收敛的效率,也就是提升找到目标函数最优解的效率。规范化如何在这两点上起作用?
- 用 Chrome 浏览器的开发者工具,可以监测出来网页中是否有 json 数据的传输。怎么看?
- 有个答疑二和答疑三涉及加餐还没看