联邦图机器学习(综述阅读)
目录
一、联邦图机器学习的介绍
二、联邦图机器学习的类型
三、具有结构化数据的联邦学习(FL With Structured Data)
3.1 跨客户端信息重构
3.2 重叠实例对齐
3.3 非独立同分布数据适配
3.3.3 基于单一全局模型的方法
3.3.2 基于个性化模型的方法
四、结构化联邦学习(Structured FL)
4.1 集中式聚合
4.2 全分散传输
一、联邦图机器学习的介绍
图数据通常分布在多个数据所有者中,由于隐私问题,无法在不同的地方收集图数据。联邦学习是一种分布式学习方案,它使参与者在不共享私人数据隐私的情况下联邦训练一个全局模型。因此将联邦学习与图学习相结合成为解决上述问题的一个很有前途的方案。
根据节点类型和边类型的数量,图可以分为同构图(只包含一种类型的节点和一种类型的边)和异构图(其节点属于一种以上的节点或边)。
二、联邦图机器学习的类型
1、具有结构化数据的联邦学习:客户端基于其图数据协同训练机器学习模型,同时将图数据保存在本地。每个客户端可以具有一个(子)图或多个图。当客户端拥有多个图时,客户端为图级任务训练图机器学习模型;当客户端拥有一个图或整个图的子图时,图机器学习模型用于节点级任务。
2、结构化联邦学习:客户端之间存在结构信息,。将每个客户端作为一个节点时,结构化联邦学习的所有客户端形成一个图(客户端级图)。可以利用客户端图来设计更有效的联邦优化方法。值得注意的是,客户端上的数据集不一定是结构化数据。
挑战:
1、跨客户端信息缺失:具有结构化数据的联邦学习的常见场景中,每个客户端都拥有全局图的一个子图,并且一些节点可能具有属于其他客户端的邻居。由于隐私问题,节点只能聚合其客户端内的邻居特征,这导致了节点表示不足。
2、图结构的隐私泄露:具有结构化数据的联邦学习中,应额外考虑结构信息的隐私。结构隐私会通过共享邻接矩阵或传输节点嵌入空间而暴露。
3、跨客户端的数据异构性:不同于传统联邦学习中来自Non-IID数据样本的异构性,图数据包含丰富的结构信息。同时客户端之间不同的图结构也会影响图机器学习的性能。
4、参数利用策略:在结构化联邦学习中,客户端图使客户端能够从其邻居客户端获得信息。在结构化联邦学习中,应设计好充分利用由中央服务器协调或以完全分散的方式安排的邻居信息的有效策略。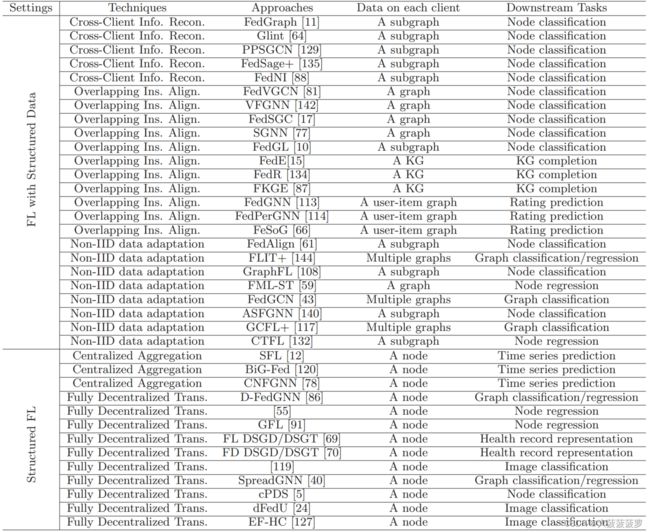
三、具有结构化数据的联邦学习(FL With Structured Data)
3.1 跨客户端信息重构
当一个图被拆分为多个子图,每个客户端拥有一个子图时,每个节点只能对来自其邻居子集(子图中的邻居)的信息进行GNN聚合。丢失的跨客户端信息导致每个客户端上的节点嵌入有偏差。
中间结果传输(中央服务器知道原始图结构):从客户端收集图机器学习模型的中间结果,并根据跨客户端邻居的完整邻居列表计算节点嵌入。
为了避免暴露原始节点特征,每个客户端在处理第一个GCN层时在其本地子图中执行GNN聚合。然后,每个客户端对节点执行GNN聚合,包括来自其他客户端的其邻居的嵌入。
Question:需要原始图的结构信息来计算节点嵌入,在现实世界中是不切实际的。此外,对于每个本地更新,中间结果被传输多次,这也带来了显著的通信成本。
缺失邻居生成(中央服务器不知道原始图结构):设计一个缺失邻居生成器,在其他客户端上重建节点的交叉子图邻居的特征。首先每个客户端在其局部子图![]() 中隐藏节点和相关边的子集,以形成受损子图
中隐藏节点和相关边的子集,以形成受损子图![]() 。然后每个客户端训练一个由
。然后每个客户端训练一个由![]() 参数化的预测器和一个由
参数化的预测器和一个由![]() 参数化的编码器(例如GCN),前者用于预测
参数化的编码器(例如GCN),前者用于预测![]() 中每个节点的隐藏邻居数量
中每个节点的隐藏邻居数量![]() ,后者用于通过最小化损失来预测隐藏邻居的特征。
,后者用于通过最小化损失来预测隐藏邻居的特征。
![]()
其中![]() 和
和![]() 分别是隐藏邻居的预测数量及其预测特征的损失函数。
分别是隐藏邻居的预测数量及其预测特征的损失函数。
3.2 重叠实例对齐
在应用程序中,一个实例可以属于多个客户端。来自不同客户端的重叠实例的嵌入可能来自协作训练期间的不同嵌入空间。重叠实例对齐的关键思想是通过在客户端本地实例嵌入的基础上学习全局嵌入。
基于齐次图的对齐:现有工作主要是在纵向联邦学习下进行的。一种情况是,一组节点位于所有客户端上,但他们的特征和关系在客户端之间不同。中央服务器可以从客户端收集本地节点嵌入并对齐重叠的节点嵌入。另外一种情况是,一个客户端只包含图数据的结构信息,而其他客户端只包含节点特征。可以通过在联邦优化过程中同时保护结构信息和原始节点特征来处理这个问题。
基于KG的对齐:每个客户端拥有一个KG,并且每个KG可能具有也存在于其他客户端上的重叠实体。在每一轮通信之后,服务器从每个客户端收集每个局部嵌入矩阵以更新全局嵌入矩阵。然后,服务器将全局嵌入分发给相应的客户端,用于随后的本地训练。
基于用户项目图的对齐
3.3 非独立同分布数据适配
每个客户端上的数据分布可能在节点特征和图结构方面存在很大差异。这种数据异构型会导致严重的模型差异,从而减低全局模型的性能。现有技术分为基于全局模型的单一方法和基于个性化模型的方法。
3.3.3 基于单一全局模型的方法
基于单一全局模型的方法的目标是在来自客户端的图数据上训练全局图机器学习模型。
设计损失函数:1、为局部损失函数添加正则化项。2、实例重加权(最小化局部模型和全局模型之间的损失差异)
联邦学习模型聚合重新加权:在联邦学习的聚合过程中重新加权局部模型,例如在模型聚合阶段为每个客户端的模型参数分配自适应权重。
模型插值:客户端的局部模型是由其上一轮的局部模型和当前轮次全局模型组合得到的。
3.3.2 基于个性化模型的方法
与训练单个全局图机器学习模型不同,该方法旨在为每个客户端训练一个个性化的、量身定制的图机器学习模型。
客户端聚类:将具有相似数据分布的客户端放在一个组中,组中的客户端共享相同的模型参数。
四、结构化联邦学习(Structured FL)
在现实世界中,客户端可能与其他人有连接,例如,存在于交通传感器之间的道路路径。这些连接通常包含客户端之间的丰富信息(例如,数据分布的相似性)。考虑到这些连接,客户端可以形成一个客户端图。结构化联邦学习考虑客户端图,并使客户端能够从其邻居获得信息。
4.1 集中式聚合
中央服务器类似于标准联邦学习中,从客户端收集参数。然后通过基于客户端图![]() 的图机器学习模型更新每个客户端的参数。最后将更新后的参数发送回客户端。
的图机器学习模型更新每个客户端的参数。最后将更新后的参数发送回客户端。
传输模型参数:将本地模型参数作为图机器学习模型的输入传输到中央服务器。
传输嵌入:服务器收集每个客户端的本地嵌入,并通过图机器学习模型计算全局嵌入。
4.2 全分散传输
以完全去中心化的方式训练模型,以减少高额的通信成本。每个客户端从其邻居接收模型参数后,执行GNN聚合以更新其本地模型参数,让每个客户端直接汇总来自其相邻客户端的模型参数。然而这种方法会导致丢失每个客户端的本地信息,因为更新后的模型完全由相邻信息决定。可以通过在聚合过程中涉及本地信息的方式来缓解,例如在聚合过程中直接添加局部梯度。
参考文献:[1] Fu X, Zhang B, Dong Y, et al. Federated graph machine learning: A survey of concepts, techniques, and applications[J]. ACM SIGKDD Explorations Newsletter, 2022, 24(2): 32-47.