Seurat 单细胞转录组测序数据分析教程(二)——python(scanpy)
Seurat 单细胞转录组测序数据分析教程(二)——python(scanpy)
文章参考至scanpy官网,做了一个更详细的解读。
数据由来自健康捐赠者的 3k PBMC组成,可从 10x Genomics 免费获得。在 unix 系统上,您可以取消注释并运行以下命令来下载和解压数据。最后一行创建一个用于写入已处理数据的目录。
# !mkdir data
# !wget http://cf.10xgenomics.com/samples/cell-exp/1.1.0/pbmc3k/pbmc3k_filtered_gene_bc_matrices.tar.gz -O data/pbmc3k_filtered_gene_bc_matrices.tar.gz
# !cd data; tar -xzf pbmc3k_filtered_gene_bc_matrices.tar.gz
# !mkdir write
导入数据
import numpy as np
import pandas as pd
import scanpy as sc
sc.settings.verbosity = 3 # verbosity: errors (0), warnings (1), info (2), hints (3)
sc.logging.print_header()
sc.settings.set_figure_params(dpi=80, facecolor='white')
将计数矩阵读入AnnData对象,该对象包含许多用于注释和不同数据表示的插槽。它还带有自己的基于 HDF5 的文件格式。
adata = sc.read_10x_mtx(
'data/filtered_gene_bc_matrices/hg19/', # the directory with the `.mtx` file
var_names='gene_symbols', # use gene symbols for the variable names (variables-axis index)
cache=True) # wr
adata.var_names_make_unique() # this is unnecessary if using `var_names='gene_ids'` in `sc.read_10x_mtx`
预处理
显示在所有细胞中每个细胞中产生最高计数分数的那些基因。
sc.pl.highest_expr_genes(adata, n_top=20, )

基本过滤:
sc.pp.filter_cells(adata, min_genes=200)
sc.pp.filter_genes(adata, min_cells=3)
让我们收集一些关于线粒体基因的信息,这对质量控制很重要。
引用自“Simple Single Cell”工作流程(Lun、McCarthy & Marioni,2017):
高比例表明细胞质量差(Islam 等人,2014 年;Ilicic 等人,2016 年),可能是因为穿孔细胞的细胞质 RNA 丢失。原因是线粒体比单个转录物分子大,不太可能通过细胞膜的撕裂逃逸。
有了pp.calculate_qc_metrics,我们可以非常有效地计算许多指标。
adata.var['mt'] = adata.var_names.str.startswith('MT-') # annotate the group of mitochondrial genes as 'mt'
sc.pp.calculate_qc_metrics(adata, qc_vars=['mt'], percent_top=None, log1p=False, inplace=True)
一些计算出的质量度量的小提琴图:
- 计数矩阵中表达的基因数量
- 每个细胞的总计数
- 线粒体基因计数的百分比
sc.pl.violin(adata, ['n_genes_by_counts', 'total_counts', 'pct_counts_mt'],
jitter=0.4, multi_panel=True)

去除线粒体基因表达过多或总计数过多的细胞:
sc.pl.scatter(adata, x='total_counts', y='pct_counts_mt')
sc.pl.scatter(adata, x='total_counts', y='n_genes_by_counts')
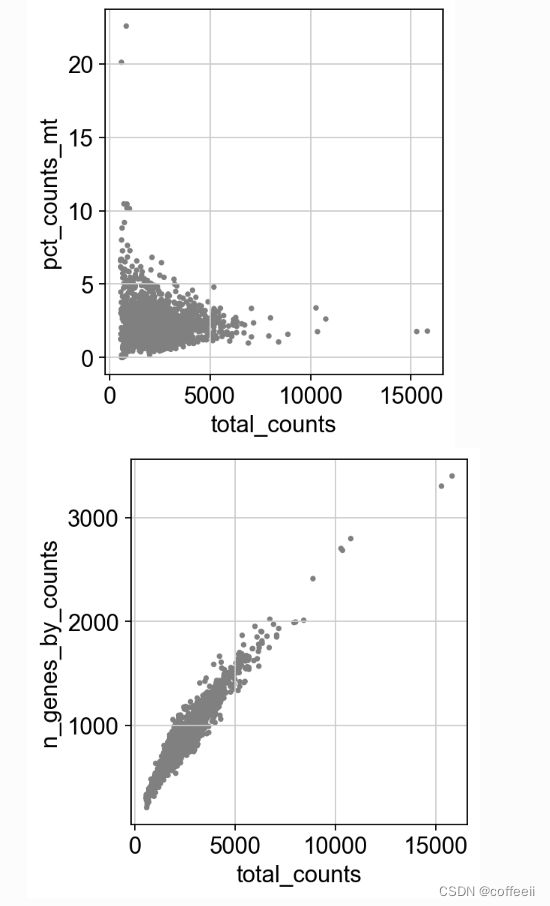
实际上通过切片对象来进行过滤AnnData。
adata = adata[adata.obs.n_genes_by_counts < 2500, :]
adata = adata[adata.obs.pct_counts_mt < 5, :]
总计数归一化(库大小正确)数据矩阵X
每个细胞 10,000 次读取,以便细胞之间的计数具有可比性。
sc.pp.normalize_total(adata, target_sum=1e4)
对数据进行对数化:
sc.pp.log1p(adata)
识别高变异基因。
sc.pp.highly_variable_genes(adata, min_mean=0.0125, max_mean=3, min_disp=0.5)
sc.pl.highly_variable_genes(adata)

将 AnnData 对象的属性设置.raw为标准化和对数化的原始基因表达,以便稍后用于差异测试和基因表达的可视化。这只是冻结了 AnnData 对象的状态。
实际进行过滤
adata = adata[:, adata.var.highly_variable]
回归每个细胞的总计数和线粒体基因表达百分比的影响。将数据缩放到单位方差。
sc.pp.regress_out(adata, ['total_counts', 'pct_counts_mt'])
将每个基因缩放到单位方差。剪辑值超过标准偏差 10。
sc.pp.scale(adata, max_value=10)
主成分分析
通过运行主成分分析 (PCA) 来降低数据的维度,它揭示了变化的主轴并对数据进行了去噪。
sc.tl.pca(adata, svd_solver='arpack')
我们可以在 PCA 坐标中绘制散点图,但我们稍后不会使用它。
sc.pl.pca(adata, color='CST3')

让我们检查单个 PC 对数据总方差的贡献。这为我们提供了有关我们应该考虑多少个 PC 的信息,以便计算细胞的邻域关系,例如在聚类函数sc.tl.louvain()或 tSNE中使用sc.tl.tsne()。根据我们的经验,通常粗略估计 PC 的数量就可以了。
sc.pl.pca_variance_ratio(adata, log=True)

计算邻域图
让我们使用数据矩阵的 PCA 表示来计算单元格的邻域图。您可以在此处简单地使用默认值。为了重现修拉的结果,我们取以下值。
sc.pp.neighbors(adata, n_neighbors=10, n_pcs=40)
嵌入邻域图
我们建议使用 UMAP 在二维中嵌入图形(McInnes 等人,2018 年),见下文。它可能比 tSNE 更忠实于流形的全局连通性,即,它更好地保留轨迹。在某些情况下,您可能仍会观察到断开连接的集群和类似的连接违规。它们通常可以通过运行来补救:
sc.tl.paga(adata)
sc.pl.paga(adata, plot=False) # remove `plot=False` if you want to see the coarse-grained graph
sc.tl.umap(adata, init_pos='paga')
sc.tl.umap(adata)
sc.pl.umap(adata, color=['CST3', 'NKG7', 'PPBP'])

当我们设置.raw的属性adata时,前面的图显示了“原始”(归一化、对数化但未校正)基因表达。您还可以通过明确声明您不想使用 来绘制缩放和校正的基因表达.raw。
sc.pl.umap(adata, color=['CST3', 'NKG7', 'PPBP'], use_raw=False)

聚类邻域图
与 Seurat 和许多其他框架一样,我们推荐Traag 等人 (2018)的 Leiden 图聚类方法(基于优化模块化的社区检测) 。请注意,莱顿聚类直接对细胞的邻域图进行聚类,我们已经在上一节中计算过了。
sc.tl.leiden(adata)
绘制集群,这与 Seurat 的结果非常吻合。
sc.pl.umap(adata, color=['leiden', 'CST3', 'NKG7'])
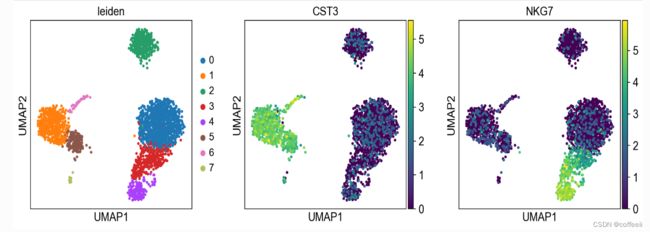
寻找标记基因
让我们计算每个簇中高度差异基因的排名。为此,默认情况下.raw使用 AnnData 的属性,以防它之前已被初始化。最简单和最快的方法是 t 检验。
sc.tl.rank_genes_groups(adata, 'leiden', method='t-test')
sc.pl.rank_genes_groups(adata, n_genes=25, sharey=False)

sc.settings.verbosity = 2 # reduce the verbosity
Wilcoxon 秩和 (Mann-Whitney-U)检验的结果非常相似。我们建议在出版物中使用后者,例如,参见Sonison & Robinson (2018)。您可能还会考虑功能更强大的差异测试包,例如 MAST、limma、DESeq2 以及针对 Python 的最新 diffxpy。
sc.tl.rank_genes_groups(adata, 'leiden', method='wilcoxon')
sc.pl.rank_genes_groups(adata, n_genes=25, sharey=False)

作为替代方案,让我们使用逻辑回归对基因进行排序。例如,Natranos 等人提出了这一点。(2018)。本质区别在于,在这里,我们使用多变量方法,而传统的差异测试是单变量的。克拉克等人。(2014)有更多详细信息。
sc.tl.rank_genes_groups(adata, 'leiden', method='logreg')
sc.pl.rank_genes_groups(adata, n_genes=25, sharey=False)

除了仅通过 t 检验发现的IL7R和仅通过其他两种方法发现的FCER1A外,所有标记基因均在所有方法中恢复。
让我们也定义一个标记基因列表供以后参考。
marker_genes = ['IL7R', 'CD79A', 'MS4A1', 'CD8A', 'CD8B', 'LYZ', 'CD14',
'LGALS3', 'S100A8', 'GNLY', 'NKG7', 'KLRB1',
'FCGR3A', 'MS4A7', 'FCER1A', 'CST3', 'PPBP']
实际上标记细胞类型。
new_cluster_names = [
'CD4 T', 'CD14 Monocytes',
'B', 'CD8 T',
'NK', 'FCGR3A Monocytes',
'Dendritic', 'Megakaryocytes']
adata.rename_categories('leiden', new_cluster_names)
sc.pl.umap(adata, color='leiden', legend_loc='on data', title='', frameon=False, save='.pdf')

现在我们已经注释了细胞类型,让我们可视化标记基因。
sc.pl.dotplot(adata, marker_genes, groupby='leiden');

还有一个非常紧凑的小提琴图
sc.pl.stacked_violin(adata, marker_genes, groupby='leiden', rotation=90);

在此分析过程中,AnnData 积累了以下注释

。