独家 | 流媒体服务中的诈骗检测

文:Soheil Esmaeilzadeh, Negin Salajegheh, Amir Ziai, Jeff Boote
翻译:陈超
校对:赵茹萱
本文约4500字,建议阅读12分钟
本文基于预期用户的流媒体行为及其与设备交互来定义流媒体特征,对非预期流媒体行为进行系统性概述,并用一套基于模型和数据驱动的异常检测策略来识别它们。
引言
流媒体服务覆盖了全世界上百万的用户。这些服务使用户可以在较广的设备范围(包括智能手机、笔记本电脑和电视)上收看或下载内容。然而,该服务也存在一定限制,例如活跃设备数、信息流数量以及下载条目数。大量的平台用户也构成了一个包括内容诈骗、账户盗用以及服务条款滥用在内的庞大特殊受攻击面。大规模和实时检测欺诈和滥用行为仍非常具有挑战性。
数据分析和机器学习技术能够很好地用于保障大规模流媒体平台安全。即使这些技术可以将安全方案与服务规模相协调,但仍有一些挑战需要克服,例如要求标签化的数据样本,定义有效特征以及发现合适的算法。在本文中,通过流媒体安全专家的知识和经验,我们基于预期用户的流媒体行为和他们与设备交互来定义特征。我们对非预期流媒体行为进行了系统性概述,并用一套基于模型和数据驱动的异常检测策略来识别它们。
一、异常检测背景
异常(也称为异常值)被定义为数据样本中不满足特定环境中人们一致认可的正常行为的特定模式(或事件)。
有两种主要的异常检测方法,即(1)基于规则;(2)基于模型。基于规则的异常检测方法是用领域专家的知识和经验建立的一系列规则。领域专家将给定情境下异常事件的特征进行界定,并开发一套基于规则的功能识别异常事件。由于这种依赖,这种部署和基于规则的异常检测方法的使用会随着规模而变得非常昂贵和耗时。此外,基于规则的异常检测方法需要专家们持续的监督,以保持基本规则集的更新,识别新的威胁。但对专家的依赖也会使基于规则的方法在范围和效力上产生偏见或受到限制。
另一方面,基于模型的异常检测方法中,模型在一种自动化的行为中建立并用于检测异常事件。虽然基于模型的异常检测方法更能够量化并且适用于实时分析,它们也高度依赖于内容特定(通常标签化的)数据的可用性。基于模型的异常检测方法,一般来说,有三种类别,(1)有监督的(2)半监督的以及(3)无监督的。给定标签化数据集,有监督的异常检测模型可以识别异常和正常事件。在半监督异常检测模型中,仅有正常案例需要训练。这些模型学习正常样本的分布,并利用这些知识在推断时识别异常样本。无监督异常检测模型不需要任何标签化数据样本。但是,想要可靠地评估它们的功效并不容易。
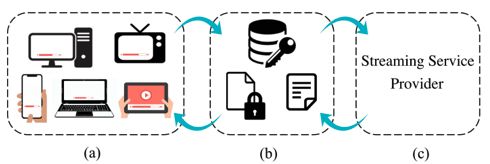
图 1. 流媒体平台图示:(a)说明可用于流媒体的设备类型(b)指定一组身份验证和授权系统,如许可证和清单服务器,用于提供加密内容以及解密密钥和清单,以及(c)显示流媒体服务提供者(作为数字内容提供者的代理实体),与其他两个组件交互。
二、流媒体平台
图1中的商业流媒体平台主要依赖于数字版权管理(DRM)系统。DRM是用于保护电影和音乐等数字媒体版权的访问控制技术的集合。DRM帮助数字产品拥有者阻挡非法访问,修改,以及他们版权工作的分布。DRM系统提供持续的内容保护,防止对数字内容进行未经授权的操作,并将其限制为流媒体和实时消费。DRM的核心是使用数字许可证,它为数字内容指定一组使用权限,并包含通过请求式流媒体服务来从所有者处获取流媒体内容的权限。
在客户端,请求发送给流媒体服务获取受保护的加密数字内容。为了将数字内容流媒体化,用户要从验证用户资格证书的清除库处获取许可证。一旦许可证分配给用户,使用内容解密模块(CDM),受保护的内容获得解码并准备好根据许可证强制的使用权限预览。使用许可证生成解密密钥,这是特定的电影标题,只能由给定设备上的特定帐户使用,有有限的生命周期,并强制限制允许的并发流媒体的数量。
流媒体经验中涉及的另一个相关组件是清单的概念。清单是视频、音频和字幕等的集合,以一些统一资源定位器(url)的形式出现,客户使用它们来获取电影流。客户请求清单并在许可证请求之前传递给播放器,并列出可用的流媒体。
三、数据
1. 数据标签
在流媒体平台中的异常检测任务,我们既没有已经训练好的模型也没有任何标签化的珊瑚橘样本,我们使用结构化的先验领域特异性基于规则的假设用于数据标签化。相应地,我们定义了一套基于规则的启发法用于识别客户的异常流媒体行为并将其标记为异常或正常。在本文中我们将诈骗种类分为(i)内容诈骗(ii)服务诈骗(iii)账户诈骗。在安全专家的帮助下,我们设计并开发了启发法功能为了发现一系列可疑的行为。我们之后使用这样的启发法功能用于给数据样本自动打标签。为了标记一组正常(非异常)帐户,使用了一组经过审查的用户,这些用户很可靠,没有任何形式的欺诈。
接下来,我们将分享三个例子,作为我们用来标记异常账户的内部启发式的子集:
(i)快速许可获取:启发法基于这样一个事实,正常的用户通常一次观看一个内容,他们需要一段时间才能转移到另一个内容,因此许可获取率相对较低。基于这个推理,我们将所有快速获得许可证的帐户标记为异常帐户。
(ii)太多失败的流媒体尝试:启发法依赖于大多数设备的流媒体没有错误,而在试错模式下的设备,为了找到“正确的”参数,会留下一长串错误。异常高的错误水平是欺诈尝试的一个指标。
(iii)设备类型和DRM的不寻常组合:一种基于设备类型(如浏览器)通常与特定DRM系统(如Widevine)相匹配的启发式方法。不寻常的组合可能是试图绕过安全措施的设备被破坏的迹象。
应该注意的是,启发式,即使作为嵌入安全专家的知识标记异常帐户的一个很好的代理,也可能不是完全准确的,它们可能错误地将帐户标记为异常(即假阳性事件),例如在有bug的客户端或设备的情况下。这取决于机器学习模型来发现和避免这种假阳性事件。
2.数据特征化
表1列出了本文中使用特征的完整列表。这些特征主要分为两类。一个类负责记录一天内特定参数/活动/使用的不同出现次数。例如,dist_title_cnt特性描述了一个帐户流传输的不同电影题目的数量。另一方面,第二类功能捕获特定参数/活动/使用在一天中的百分比。
由于保密原因,我们对特征进行了部分模糊,例如,dev_type_a_pct、drm_type_a_pct和end_frmt_a_pct是有意模糊的,我们没有明显地提到设备、DRM类型和编码格式。
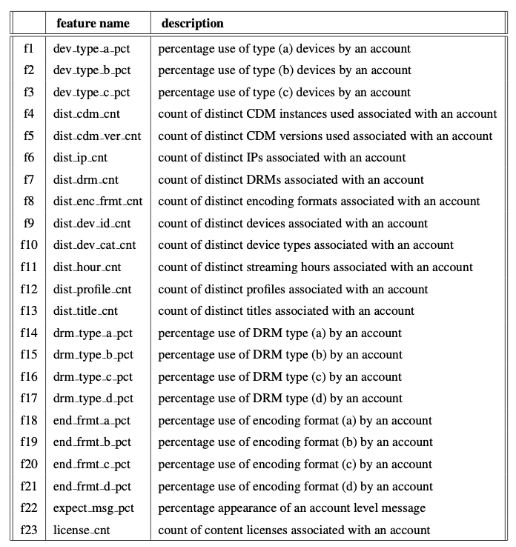
表 1. 流媒体相关特征列表,后缀pct和cnt分别表示百分比和计数
3.数据统计
在这一部分中,我们给出表1中所示特征的统计数据。在过去30天里,我们收集了1030005个正常账户和28045个异常账户。使用启发式感知方法识别(标记)异常帐户。图2(a)显示了异常样本的数量作为欺诈类别的函数,其中8,741个(31%)、13,299个(47%)、6,005个(21%)数据样本分别被标记为内容欺诈、服务欺诈和账户欺诈。图2(b)显示,在被启发式函数标记为异常的28045个数据样本中,23838个(85%)、3365个(12%)和842个(3%)分别被认为是一类、二类和三类欺诈事件。
图3给出了表1中描述的23个数据特征在清洁和异常数据样本中的相关矩阵。正如我们在图3中看到的,与设备签名相对应的特征之间,如dist_cdm_cnt和dist_dev_id_cnt,以及引用标题获取活动的特征之间,如dist_title_cnt和license_cnt,存在正相关关系。
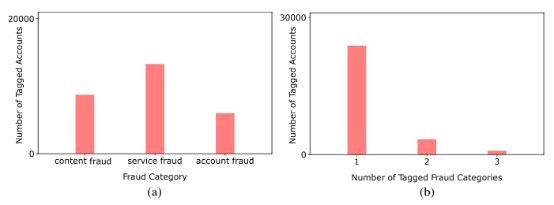
图2。异常样本数量作为(a)欺诈类别和(b)标记类别数量的函数。
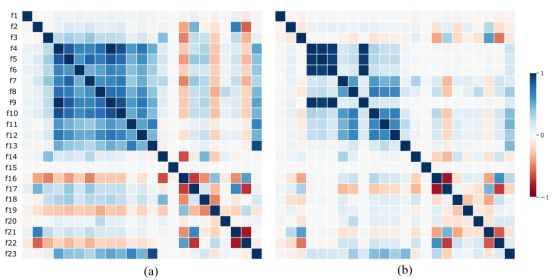
图3。(a)干净数据样本和(b)异常数据样本的特征相关矩阵如表1所示。
4.标签不平衡解决方案
众所周知,类别不平衡会影响分类模型的准确性和鲁棒性。因此在本研究中,我们使用合成少数群体过采样技术(SMOTE)通过创建一组合成样本来对少数群体进行过采样。
图4显示了合成少数过采样技术(SMOTE)的高层示意图,其中绿色和红色分别表示两个类,其中红色类的样本数量较少,即为少数类,并进行了综合上采样。
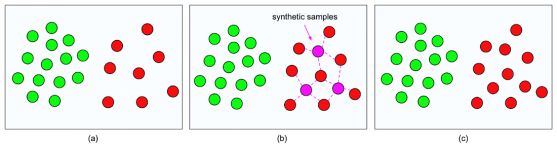
图4。合成少数过采样技术
5.评价指标
为了评估异常检测模型的性能,我们考虑了一组评估指标并报告了它们的值。对于单类和二元异常检测任务,这些指标是精度、精度、召回率、f0.5、f1和f2得分,以及接收者工作特征曲线下的面积(ROC AUC)。对于多类多标签任务,我们考虑精度、精度、召回率、f0.5、f1和f2得分,以及一组附加指标,即精确匹配比(EMR)得分、汉明损失和汉明得分。
6.基于模型的异常检测
在本节中,我们将简要描述在此工作中用于异常检测的建模方法。我们考虑两种基于模型的异常检测方法,即(i)半监督和(ii)如图5所示的监督。

图5。基于模型的异常检测方法:(a)半监督和(b)监督。
7.半监督异常检测
半监督模型的关键在于,在训练阶段,模型应该学习正常数据样本的分布,以便在推理时能够区分正常样本(已被训练)和异常样本(未被观察)。然后在推断阶段,异常样本将只是那些脱离正常样本分布的样本。当处理复杂和高维数据集时,单类方法的性能可能会变得次优。然而,有文献支持深度神经自编码器在复杂高维异常检测任务中的表现优于单类方法。
作为单类异常检测方法,除了深度自编码器外,我们还使用单类支持向量机、隔离林、椭圆包络和局部离群因子方法。
8.有监督异常检测
二分类:在使用二元分类的异常检测任务中,我们只考虑了两类样本,即正常样本和异常样本,而不区分异常样本的类型,即三种欺诈类别。对于二元分类任务,我们使用多种监督分类方法,即: (i)支持向量分类(SVC), (ii) k最近邻分类,(iii)决策树分类,(iv)随机森林分类,(v)梯度增强,(vi) AdaBoost 算法,(vii)最近质心分类(viii)二次判别分析(QDA)分类(ix)高斯朴素贝叶斯分类(x)高斯过程分类器(xi)标签传播分类(xii) 提升算法(XGBoost)。最后,在进行分层k-fold交叉验证之后,我们执行一个高效的网格搜索来优化上述每种模型中的超参数,以实现二元分类任务,并仅报告优化后的超参数的性能指标。
9.多类多标签分类
在使用多类多标签分类的异常检测任务中,我们将三种欺诈类别视为可能的异常类(即多类),并使用前面提出的启发式感知数据标记策略为每个数据样本分配一个或多个欺诈类别作为其标签集(即多标签)。对于多类多标签分类任务,我们使用多种监督分类技术,即(i) k -最近邻(K-Nearest Neighbors)、(ii)决策树(Decision Tree)、(iii)额外树(Extra Trees)、(iv)随机森林和(v)提升算法(XGBoost)。
三、结果与讨论
表2给出了半监督异常检测方法的评价指标值。从表2可以看出,在半监督异常检测方法中,深度自编码器模型表现最好,准确率约为96%,f1评分为94%。图6(a)显示了异常和正常样本在推断阶段的均方误差(MSE)值的分布。

表2。一组半监督异常检测模型的评价指标的取值。
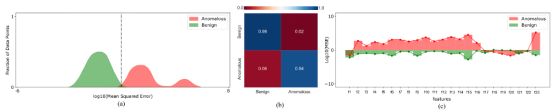
图6。对于深度自编码器模型:(a)在推断阶段异常和正常样本的均方误差(MSE)值的分布——(b)正常和异常样本的混淆矩阵——(c) 23个特征中每个异常和正常样本的均方误差(MSE)值的平均值。
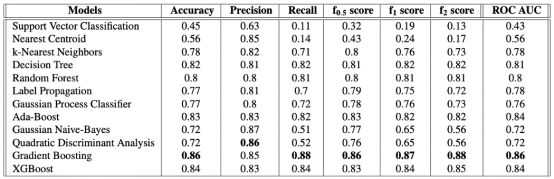
表3。一组有监督的二元异常检测分类器的评价指标的值。

表4。研究了一组有监督的多类多标签异常检测方法的评价指标的取值。括号中的值表示在原始(未上采样)数据集上训练的模型的性能。
表3给出了一组有监督的二元异常检测模型的评价指标值。表4给出了一组有监督的多类多标签异常检测模型的评价指标值。
在图7(a)中,对于内容欺诈类别,三个最重要的特征是不同编码格式的计数(dist_enc_frmt_cnt)、不同设备的计数(dist_dev_id_cnt)和不同DRMs的计数(dist_drm_cnt)。这意味着,对于内容欺诈,使用多种设备以及编码格式从其他功能中脱颖而出。对于图7(b)中的服务欺诈类别,我们可以看到三个最重要的特性:与帐户(license_cnt)关联的内容许可计数、不同设备的计数(dist_dev_id_cnt)和帐户(dev_type_a_pct)使用类型(a)设备的百分比。这表明,在服务欺诈类别中,(a)类型的内容许可证和不同设备的数量从其他特征中脱颖而出。最后,对于图7(c)中的帐户欺诈类别,我们看到不同设备(dist_dev_id_cnt)的计数主要突出于其他特性。
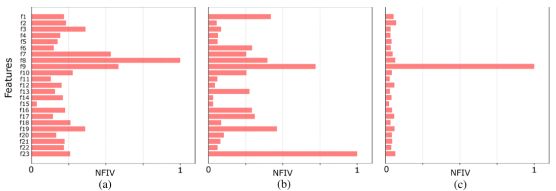
图7。表4中使用XGBoost方法的多类多标签异常检测任务的标准化特征重要性值(NFIV)跨三个异常类,即(a)内容欺诈、(b)服务欺诈和(c)账户欺诈。
您可以在我们的论文中找到更多技术细节。
您对解决机器学习(https://jobs.netflix.com/search?q=%22machine%20learning%22)和安全(https://jobs.netflix.com/search?q=security)交叉领域的挑战性问题感兴趣吗?我们一直在寻找优秀的人才加入我们。
原文标题:
Machine Learning for Fraud Detection in Streaming Services
原文链接:
https://netflixtechblog.medium.com/machine-learning-for-fraud-detection-in-streaming-services-b0b4ef3be3f6
编辑:于腾凯
校对:林亦霖
译者简介

陈超,北京大学应用心理硕士,数据分析爱好者。本科曾混迹于计算机专业,后又在心理学的道路上不懈求索。在学习过程中越来越发现数据分析的应用范围之广,希望通过所学输出一些有意义的工作,很开心加入数据派大家庭,保持谦逊,保持渴望。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。

点击“阅读原文”拥抱组织