5W字穿透 ELK(史上最全):elasticsearch +logstash+kibana
本文 5w 字,帮忙大家 绞杀式、穿透式 掌握 elk 的原理和实操
文章很长,建议收藏起来慢慢读! 总目录 博客园版 为您奉上更多の珍贵的学习资源
有关本文的 脚本 和 代码,可以来 尼恩 发起的Java 高并发 疯狂创客圈 社群 交流和获取。
ELK的高并发场景的问题
elk能支撑50W到100W级qps场景的 大流量日志监控吗?
具体的架构如下:
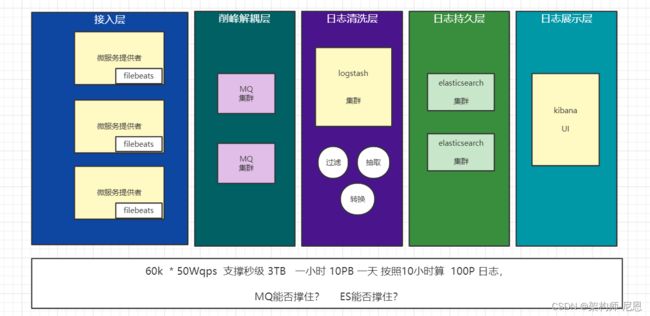
答案,当然没法撑住。
解决方案,稍后介绍。 但是,但是,咱们先得把ELK 的原理搞清楚,知己才能知彼
所以,接下来,给大家介绍 《ELK日志平台(elasticsearch +logstash+kibana)原理和实操》
关于 本文的代码,和技术问题, 请来尼恩 发起的Java 高并发 疯狂创客圈 社群交流 ,
ELK日志平台(elasticsearch +logstash+kibana)原理和实操
ELK指的是Elastic公司下面Elasticsearch、Logstash、Kibana三大开源框架首字母大写简称。
Elasticsearch、Logstash、Kibana三大开源框架首字母大写简称。
ELK的关系
在ELK架构中,Elasticsearch、Logstash和Kibana三款软件作用如下:
1、Elasticsearch
Elasticsearch是一个高度可扩展的全文搜索和分析引擎,基于Apache Lucence(事实上,Lucence也是百度所采用的搜索引擎)构建,能够对大容量的数据进行接近实时的存储、搜索和分析操作。
2、Logstash
Logstash是一个数据收集引擎,它可以动态的从各种数据源搜集数据,并对数据进行过滤、分析和统一格式等操作,并将输出结果存储到指定位置上。Logstash支持普通的日志文件和自定义Json格式的日志解析。
3、Kibana
Kibana是一个数据分析和可视化平台,通常与Elasticsearch配合使用,用于对其中的数据进行搜索、分析,并且以统计图标的形式展示。
ELK的架构如下所示:
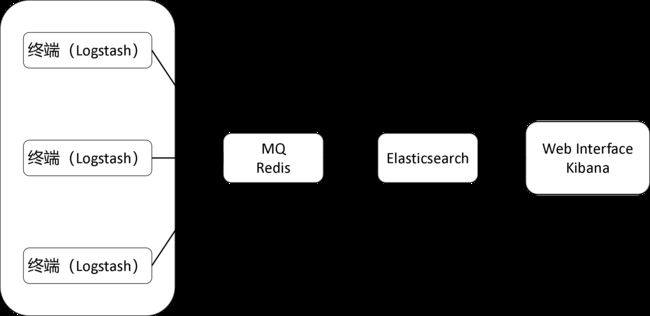
如上图所示,Logstash安装在各个设备上,用于收集日志信息,收集到的日志信息统一汇总到Elasticsearch上,然后由Kibana负责web端的展示。
其中,如果终端设备过多,会导致Elasticsearch过载的现象,此时,我们可以采用一台Redis设备作为消息队列,以暂时缓存数据,避免Elasticsearch压力突发。
关于 本文的代码,和技术问题, 请来尼恩 发起的Java 高并发 疯狂创客圈 社群交流 ,
ELK优点
ELK架构优点如下:
1、处理方式灵活。 Elasticsearch是全文索引,具有强大的搜索能力。
2、配置相对简单。 Kibana的配置非常简单,Elasticsearch则全部使用Json接口,配置也不复杂,Logstash的配置使用模块的方式,配置也相对简单。
3、检索性能高。 ELK架构通常可以达到百亿级数据的查询秒级响应。
4、集群线性扩展。 Elasticsearch本身没有单点的概念,自动默认集群模式,Elasticsearch和Logstash都可以灵活扩展。
5、页面美观。 Kibana的前端设计美观,且操作简单。
Logstash:从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储到 ES。
Elasticsearch:对大容量的数据进行接近实时的存储、搜索和分析操作。
Kibana:数据分析和可视化平台。与 Elasticsearch 配合使用,对数据进行搜索、分析和以统计图表的方式展示。
关于 本文的代码,和技术问题, 请来尼恩 发起的Java 高并发 疯狂创客圈 社群交流 ,
简单的ELK日志平台
刚来公司的时候,我们公司的日志收集系统ELK经常会出现查询不了最新的日志的情况,后面去查发现 ES的节点经常也是yellow或者red的情况。
有时候会收到开发的投诉。架构图解如下:

其中ElasticSearch 是三台服务器构成的集群,其中:
-
ElasticSearch做倒排索引,
-
Logstash跑在每个服务器上,各种日志通过Logstash搜集,Grok,Geoip等插件进行处理然后统一送到ElasticSearch的集群。
-
Kibana做图形化的展示。
这种elk架构比较简单,也存在一些问题:
1、Logstash依赖Java虚拟机占用系统的内存和CPU都比较大,
2、Logstash在数据量较大的时候容易导致其他业务应用程序崩溃,影响业务正常使用
3、随着时间的积累,es空间不能满足现状
4、Kibana没有安全管控机制,没有权限审核,安全性较差。
5、ElasticSearch 主节点也是数据节点,导致有时候查询较慢
关于 本文的代码,和技术问题, 请来尼恩 发起的Java 高并发 疯狂创客圈 社群交流 ,
ELK改进之引入Filebeat
ElasticSearch的版本,我们还是选择原来的 6.2.x的版本,然后重新搭建了一套ELK的日志系统。
ElasticSearch 6.x 的版本如果要做用于鉴权的话,必须依赖X-Pack,但是X-pack是付费的产品,所以,引入x-pack,虽然能实现 Index 级别的权限管控,确保数据安全,但是涉及到费用的问题。
于是,ElasticSearch的版本采用ElasticSearch 7.x的版本,用户鉴权采用其免费的 basic 认证实现(因为7.x的新版本在性能上优化,查询和写入速度会更快)
架构图解如下:

整个架构的具体的改进方法如下:
1、客户端选用更轻量化的Filebeat,Filebeat 采用 Golang 语言进行编写的,优点是暂用系统资源小,收集效率高。
2、Filebeat 数据收集之后统一送到多个 Logstatsh进行统一的过滤,然后将过滤后的数据写入ElasticSearch集群。
3、将原有的3个es节点增加至6个节点,其中3个ES节点是master节点,其余的节点是数据节点,如果磁盘不够用可以横向扩展数据节点。
6、ElasticSearch集群的硬盘采用 SSD的硬盘
7、ElasticSearch 做冷热数据分离
8、60天之前的索引数据进行关闭,有需要用的时候手工打开
9、ElasticSearch的版本采用ElasticSearch 7.x的版本,用户鉴权采用其免费的 basic 认证实现(因为7.x的新版本在性能上优化,查询和写入速度会更快)
到此,我们的日志系统算暂时是正常并且能满足日志查日志的需求了,也很少出现卡顿的现象了,并且服务器的资源使用率直接下降了一半。
ELK的应用场景
- 异常分析
通过将应用的日志内容通过Logstash输入到Elasticsearch中来实现对程序异常的分析排查
- 业务分析
将消息的通讯结果通过Logstash输入到Elasticsearch中来实现对业务效果的整理
- 系统分析
将处理内容的延迟作为数据输入到Elasticsearch 中来实现对应用性能的调优
但是,ELK 不适宜与超大规模(PB级别以上)日志场景
关于 本文的代码,和技术问题, 请来尼恩 发起的Java 高并发 疯狂创客圈 社群交流 ,
ELK的不足
es的资源占用
一般使用 ES 时,必须要事先评估好节点配置和集群规模,可以从以下几个方面进行评估:
-
存储容量:要考虑索引副本数量、数据膨胀、ES 内部任务额外占用的磁盘空间(比如 segment merge )以及操作系统占用的磁盘空间等因素,如果再需要预留 50% 的空闲磁盘空间,那么集群总的存储容量大约为源数据量的 4 倍;
-
计算资源:主要考虑写入,2 核 8GB 的节点可以支持 5000 qps 的写入,随着节点数量和节点规格的提升,写入能力基本呈线性增长;
-
索引和分片数量评估:一般一个 shard 的数据量在 30-50 GB为宜,可以以此确定索引的分片数量以及确定按天还是按月建索引。需要控制单节点总的分片数量,1GB 堆内存支持 20-30 个分片为宜。另外需要控制集群整体的分片数量,集群总体的分片数量一般不要超过 3w 。
算下来 3W * 50G = 1500 T = 1.5P
那么,elk 如何支持 一天100PB,一个月上千PB规模的日志量呢?
从吞吐量上来说,虽然mq进行扩展,能支撑100w 级别qps的吞吐量
但是, 后端的logstash 吞吐峰值15000 qps ,es的单节点写入 是 5000 qps 左右,
30K * 100Wqps 的日志吞吐量,如果不希望发生太大的日志延迟, 消息积压,
需要 100+个 logstash 节点, 300+个ES节点
这个需要庞大的资源成本,庞大的运维成本
如果又要兼顾吞吐量,又要 降低硬件成本和运维成本,必须要
-
缩短 日志传输和处理链路,
-
并采用更高性能,更大压缩比例的存储组件,如clickhouse,
架构如下:
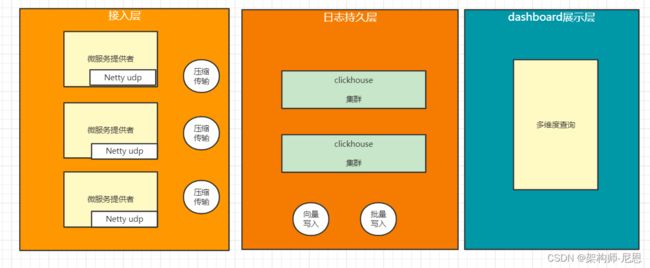
clickhouse 的数据压缩比例,请参考另外一篇博客:
clickhouse 超底层原理 + 高可用实操 (史上最全)
最终,压缩后的数据,只剩下 原始数据的 20%-30% , 单数据库这块,减少了50% 的硬盘容量,
使用elk方案,数据有多个副本,包括MQ(主副本2 份),数据库(1 份),现在减少到 数据库(1 份),这里至少减少50% ,
这种高并发、大数据量场景下的 日志方案,请参见23章视频:《100Wqps 超高并发日志平台》实操
所以,接下来,正式给大家介绍 《ELK日志平台(elasticsearch +logstash+kibana)原理和实操》
咱们先得把ELK 的原理搞清楚,
知己才能知彼,才能知道怎么去优化和改进
关于 本文的代码,和技术问题, 请来尼恩 发起的Java 高并发 疯狂创客圈 社群交流 ,
Elasticsearch概述
Elasticsearch 是一个分布式的开源搜索和分析引擎,在 Apache Lucene 的基础上开发而成。
Lucene 是开源的搜索引擎工具包,Elasticsearch 充分利用Lucene,并对其进行了扩展,使存储、索引、搜索都变得更快、更容易, 而最重要的是, 正如名字中的“ elastic ”所示, 一切都是灵活、有弹性的。而且,应用代码也不是必须用Java 书写才可以和Elasticsearc兼容,完全可以通过JSON 格式的HTTP 请求来进行索引、搜索和管理Elasticsearch 集群。
如果你已经听说过Lucene ,那么可能你也听说了Solr,
Solr也是开源的基于Lucene 的分布式搜索引擎,跟Elasticsearch有很多相似之处。
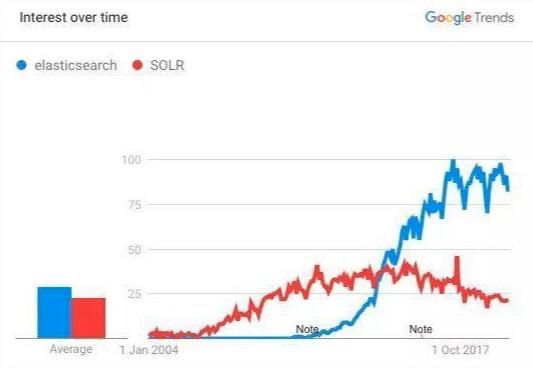
但是Solr 诞生于2004 年,而Elasticsearch诞生于2010,Elasticsearch凭借后发优势和更活跃的社区、更完备的生态系统,迅速反超Solr,成为搜索市场的第二代霸主。
Elasticsearch具有以下优势:
- Elasticsearch 很快。 由于 Elasticsearch 是在 Lucene 基础上构建而成的,所以在全文本搜索方面表现十分出色。Elasticsearch 同时还是一个近实时的搜索平台,这意味着从文档索引操作到文档变为可搜索状态之间的延时很短,一般只有一秒。因此,Elasticsearch 非常适用于对时间有严苛要求的用例,例如安全分析和基础设施监测。
- Elasticsearch 具有分布式的本质特征。 Elasticsearch 中存储的文档分布在不同的容器中,这些容器称为分片,可以进行复制以提供数据冗余副本,以防发生硬件故障。Elasticsearch 的分布式特性使得它可以扩展至数百台(甚至数千台)服务器,并处理 PB 量级的数据。
- Elasticsearch 包含一系列广泛的功能。 除了速度、可扩展性和弹性等优势以外,Elasticsearch 还有大量强大的内置功能(例如数据汇总和索引生命周期管理),可以方便用户更加高效地存储和搜索数据。
- Elastic Stack 简化了数据采集、可视化和报告过程。 人们通常将 Elastic Stack 称为 ELK Stack(代指Elasticsearch、Logstash 和 Kibana),目前 Elastic Stack 包括一系列丰富的轻量型数据采集代理,这些代理统称为 Beats,可用来向 Elasticsearch 发送数据。通过与 Beats 和 Logstash 进行集成,用户能够在向 Elasticsearch 中索引数据之前轻松地处理数据。同时,Kibana 不仅可针对 Elasticsearch 数据提供实时可视化,同时还提供 UI 以便用户快速访问应用程序性能监测 (APM)、日志和基础设施指标等数据。
logstash概述
简单来说logstash就是一根具备实时数据传输能力的管道,负责将数据信息从管道的输入端传输到管道的输出端;与此同时这根管道还可以让你根据自己的需求在中间加上滤网,Logstash提供里很多功能强大的滤网以满足你的各种应用场景。
logstash常用于日志系统中做日志采集设备,最常用于ELK中作为日志收集器使用
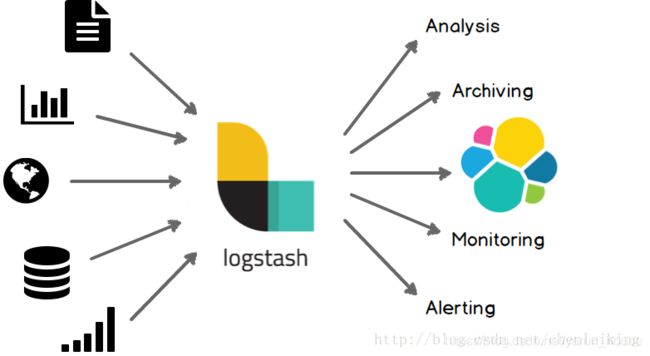
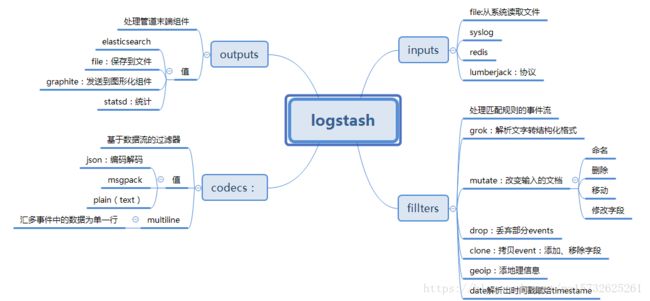
logstash作用:
集中、转换和存储你的数据,是一个开源的服务器端数据处理管道,可以同时从多个数据源获取数据,并对其进行转换,然后将其发送到你最喜欢的“存储
logstash的架构:
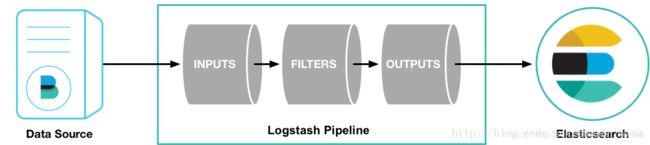
logstash的基本流程架构:input | filter | output 如需对数据进行额外处理,filter可省略。
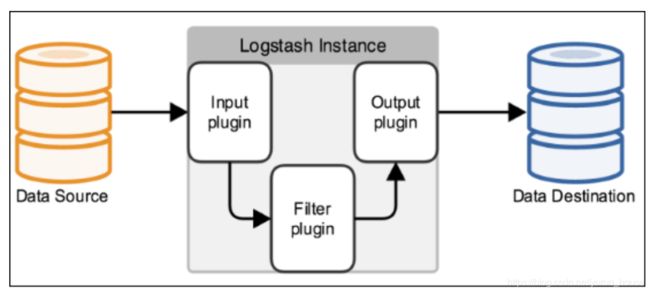
Input(输入):
采集各种样式,大小和相关来源数据,从各个服务器中收集数据。
数据往往以各种各样的形式,或分散或集中地存在于很多系统中。
Logstash 支持各种输入选择 ,可以在同一时间从众多常用来源捕捉事件。
能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。
inpust:必须,负责产生事件(Inputs generate events),
常用:File、syslog、redis、beats(如:Filebeats)
Filter(过滤器)
用于在将event通过output发出之前,对其实现某些处理功能。
filters:可选,负责数据处理与转换(filters modify them),
常用:grok、mutate、drop、clone、geoip
grok:用于分析结构化文本数据。
Output(输出):
将我们过滤出的数据保存到那些数据库和相关存储中。
outputs:必须,负责数据输出(outputs ship them elsewhere),
常用:elasticsearch、file、graphite、statsd
关于 本文的代码,和技术问题, 请来尼恩 发起的Java 高并发 疯狂创客圈 社群交流 ,
Logstash的角色与不足
早期的ELK架构中使用Logstash收集、解析日志,
但是:Logstash对内存、cpu、io等资源消耗比较高。
相比Logstash,Beats所占系统的CPU和内存几乎可以忽略不计。
所以,在收集这块,一般使用filebeat 代替 Logstash
filebeat介绍
当你要面对成百上千、甚至成千上万的服务器、虚拟机和容器生成的日志时,Filebeat 将为你提供一种轻量型方法,用于转发和汇总日志与文件,让简单的事情不再繁杂。
关于Filebeat,记住两点:
- 轻量级日志采集器
- 输送至 Elasticsearch 或 Logstash,在 Kibana 中实现可视化
filebeat和beats的关系
filebeat是Beats中的一员。
Beats在是一个轻量级日志采集器,其实Beats家族有6个成员,目前Beats包含六种工具:
- Packetbeat:网络数据(收集网络流量数据)
- Metricbeat:指标(收集系统、进程和文件系统级别的CPU和内存使用情况等数据)
- Filebeat:日志文件(收集文件数据)
- Winlogbeat:windows事件日志(收集Windows事件日志数据)
- Auditbeat:审计数据(收集审计日志)
- Heartbeat:运行时间监控(收集系统运行时的数据)
Filebeat是如何工作的
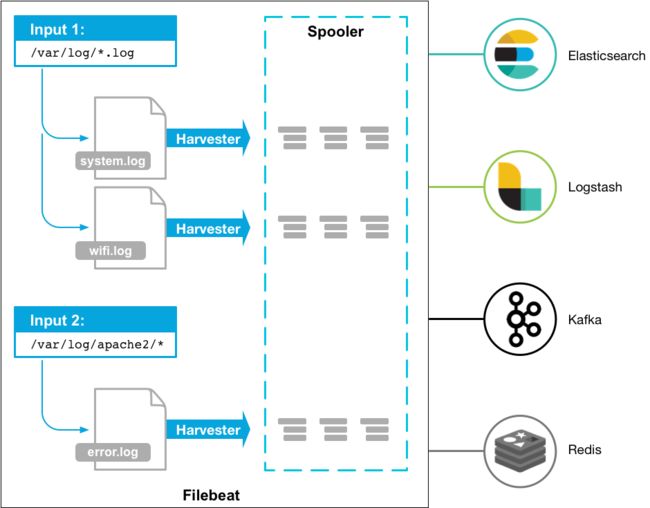
Filebeat由两个主要组件组成:inputs 和 harvesters (直译:收割机,采集器)。
这些组件一起工作以跟踪文件,并将事件数据发送到你指定的输出。
Filebeat的工作方式如下:
启动Filebeat时,它将启动一个或多个输入,这些输入将在为日志数据指定的位置中查找。
对于Filebeat所找到的每个日志,Filebeat都会启动收割机。
每个收割机都读取一个日志以获取新内容,并将新日志数据发送到libbeat,libbeat会汇总事件并将汇总的数据发送到您为Filebeat配置的输出。
关于 本文的代码,和技术问题, 请来尼恩 发起的Java 高并发 疯狂创客圈 社群交流 ,
Filebeat是一个轻量级日志传输Agent,可以将指定日志转发到Logstash、Elasticsearch、Kafka、Redis等中。
Filebeat占用资源少,而且安装配置也比较简单,支持目前各类主流OS及Docker平台。
Filebeat是用于转发和集中日志数据的轻量级传送程序。
作为服务器上的代理安装,Filebeat监视您指定的日志文件或位置,收集日志事件,并将它们转发到Elasticsearch或Logstash进行索引。
harvester是什么
一个harvester负责读取一个单个文件的内容。
harvester逐行读取每个文件(一行一行地读取每个文件),并把这些内容发送到输出。
每个文件启动一个harvester。
harvester负责打开和关闭这个文件,这就意味着在harvester运行时文件描述符保持打开状态。
在harvester正在读取文件内容的时候,文件被删除或者重命名了,那么Filebeat会续读这个文件。
这就有一个问题了,就是只要负责这个文件的harvester没用关闭,那么磁盘空间就不会释放。
默认情况下,Filebeat保存文件打开直到close_inactive到达。
input是什么
一个input负责管理harvesters,并找到所有要读取的源。
如果input类型是log,则input查找驱动器上与已定义的glob路径匹配的所有文件,并为每个文件启动一个harvester。
每个input都在自己的Go例程中运行。
下面的例子配置Filebeat从所有匹配指定的glob模式的文件中读取行:
filebeat.inputs:
- type: log
paths:
- /var/log/*.log
- /var/path2/*.log
Filebeat如何保持文件状态
Filebeat保存每个文件的状态,并经常刷新状态到磁盘上的注册文件(registry)。
状态用于记住harvester读取的最后一个偏移量,并确保所有日志行被发送(到输出)。
如果输出,比如Elasticsearch 或者 Logstash等,无法访问,那么Filebeat会跟踪已经发送的最后一行,并只要输出再次变得可用时继续读取文件。
当Filebeat运行时,会将每个文件的状态新保存在内存中。
当Filebeat重新启动时,将使用注册文件中的数据重新构建状态,Filebeat将在最后一个已知位置继续每个harvester。
对于每个输入,Filebeat保存它找到的每个文件的状态。
因为文件可以重命名或移动,所以文件名和路径不足以标识文件。对于每个文件,Filebeat存储惟一标识符,以检测文件是否以前读取过。
如果你的情况涉及每天创建大量的新文件,你可能会发现注册表文件变得太大了。
(画外音:Filebeat 保存每个文件的状态,并将状态保存到registry_file中的磁盘。当重新启动Filebeat时,文件状态用于在以前的位置继续读取文件。如果每天生成大量新文件,注册表文件可能会变得太大。为了减小注册表文件的大小,有两个配置选项可用:clean_remove 和 clean_inactive。对于你不再访问且被忽略的旧文件,建议您使用clean_inactive。如果想从磁盘上删除旧文件,那么使用clean_remove选项。)
Filebeat如何确保至少投递一次(at-least-once)?
Filebeat保证事件将被投递到配置的输出中至少一次,并且不会丢失数据。
Filebeat能够实现这种行为,因为它将每个事件的投递状态存储在注册表文件中。
在定义的输出被阻塞且没有确认所有事件的情况下,Filebeat将继续尝试发送事件,直到输出确认收到事件为止。
如果Filebeat在发送事件的过程中关闭了,则在关闭之前它不会等待输出确认所有事件。当Filebeat重新启动时,发送到输出(但在Filebeat关闭前未确认)的任何事件将再次发送。
这确保每个事件至少被发送一次,但是你最终可能会将重复的事件发送到输出。你可以通过设置shutdown_timeout选项,将Filebeat配置为在关闭之前等待特定的时间。
Filebeat下载页面
https://www.elastic.co/cn/downloads/past-releases#filebeat
Filebeat文件夹结构
| 描述 | |
|---|---|
| filebeat | 用于启动filebeat的二进制文件 |
| data | 持久化数据文件的位置 |
| logs | Filebeat创建的日志的位置 |
| modules.d | 简化filebeat配置的模板文件夹,如nginx/kafka等日志收集模板 |
| filebeat.yml | filebeat配置文件 |
Filebeat启动命令
./filebeat -e -c filebeat 配置文件
关于 本文的代码,和技术问题, 请来尼恩 发起的Java 高并发 疯狂创客圈 社群交流 ,
配置inputs
为了手动配置Filebeat(代替用模块),你可以在filebeat.yml中的filebeat.inputs区域下指定一个inputs列表。
列表时一个YMAL数组,并且你可以指定多个inputs,相同input类型也可以指定多个。例如:
filebeat.inputs:
- type: log
paths:
- /var/log/system.log
- /var/log/wifi.log
- type: log
paths:
- "/var/log/apache2/*"
fields:
apache: true
fields_under_root: true
Log input
从日志文件读取行
为了配置这种input,需要指定一个paths列表,列表中的每一项必须能够定位并抓取到日志行。例如:
filebeat.inputs:
- type: log
paths:
- /var/log/messages
- /var/log/*.log
你还可以应用设置其它额外的配置项(比如,fields, include_lines, exclude_lines, multiline等等)来从这些文件中读取行
你设置的这些配置对所有这种类型的input在获取日志行的时候都生效。
为了对不同的文件应用不同的配置,你需要定义多个input区域:
filebeat.inputs:
- type: log # 从system.log和wifi.log中读取日志行
paths:
- /var/log/system.log
- /var/log/wifi.log
- type: log # 从apache2目录下的每一个文件中读取日志行,并且在输出的时候会加上额外的字段apache
paths:
- "/var/log/apache2/*"
fields:
apache: true
fields_under_root: true
配置项
paths
例如:/var/log//.log 将会抓取/var/log子目录目录下所有.log文件。
它不会从/var/log本身目录下的日志文件。如果你应用recursive_glob设置的话,它将递归地抓取所有子目录下的所有.log文件。
recursive_glob.enabled
允许将扩展为递归glob模式。
启用这个特性后,每个路径中最右边的被扩展为固定数量的glob模式。
例如:/foo/**扩展到/foo, /foo/*, /foo/**,等等。
如果启用,它将单个**扩展为8级深度*模式。
这个特性默认是启用的,设置recursive_glob.enabled为false可以禁用它。
encoding
读取的文件的编码
下面是一些W3C推荐的简单的编码:
- plain, latin1, utf-8, utf-16be-bom, utf-16be, utf-16le, big5, gb18030, gbk, hz-gb-2312
- euc-kr, euc-jp, iso-2022-jp, shift-jis, 等等
plain编码是特殊的,因为它不校验或者转换任何输入。
exclude_lines
一组正则表达式,用于匹配你想要排除的行。Filebeat会删除(PS:我觉得用“丢弃”更合适)这组正则表达式匹配的行。默认情况下,没有行被删除。空行被忽略。
如果指定了multiline,那么在用exclude_lines过滤之前会将每个多行消息合并成一个单行。(PS:也就是说,多行合并成单行后再支持排除行的过滤)
下面的例子配置Filebeat删除以DBG开头的行:
filebeat.inputs:
- type: log
...
exclude_lines: ['^DBG']
include_lines
一组正则表达式,用于匹配你想要包含的行。Filebeat只会导出那些匹配这组正则表达式的行。默认情况下,所有的行都会被导出。空行被忽略。
如果指定了multipline设置,每个多行消息先被合并成单行以后再执行include_lines过滤。
下面是一个例子,配置Filebeat导出以ERR或者WARN开头的行:
filebeat.inputs:
- type: log
...
include_lines: ['^ERR', '^WARN']
(画外音:如果 include_lines 和 exclude_lines 都被定义了,那么Filebeat先执行 include_lines 后执行 exclude_lines,而与这两个选项被定义的顺序没有关系。include_lines 总是在 exclude_lines选项前面执行,即使在配置文件中 exclude_lines 出现在 include_lines的前面。)
下面的例子导出那些除了以DGB开头的所有包含sometext的行:
filebeat.inputs:
- type: log
...
include_lines: ['sometext']
exclude_lines: ['^DBG']
harvester_buffer_size
当抓取一个文件时每个harvester使用的buffer的字节数。默认是16384。
max_bytes
单个日志消息允许的最大字节数。超过max_bytes的字节将被丢弃且不会被发送。对于多行日志消息来说这个设置是很有用的,因为它们往往很大。默认是10MB(10485760)。
json
这些选项使得Filebeat将日志作为JSON消息来解析。例如:
json.keys_under_root: true
json.add_error_key: true
json.message_key: log
为了启用JSON解析模式,你必须至少指定下列设置项中的一个:
keys_under_root
默认情况下,解码后的JSON被放置在一个以"json"为key的输出文档中。如果你启用这个设置,那么这个key在文档中被复制为顶级。默认是false。
overwrite_keys
如果keys_under_root被启用,那么在key冲突的情况下,解码后的JSON对象将覆盖Filebeat正常的字段
add_error_key
如果启用,则当JSON反编排出现错误的时候Filebeat添加 “error.message” 和 "error.type: json"两个key,或者当没有使用message_key的时候。
message_key
一个可选的配置,用于在应用行过滤和多行设置的时候指定一个JSON key。指定的这个key必须在JSON对象中是顶级的,而且其关联的值必须是一个字符串,否则没有过滤或者多行聚集发送。
ignore_decoding_error
一个可选的配置,用于指定是否JSON解码错误应该被记录到日志中。如果设为true,错误将被记录。默认是false。
multiline
用于控制Filebeat如何扩多行处理日志消息
exclude_files
一组正则表达式,用于匹配你想要忽略的文件。默认没有文件被排除。
下面是一个例子,忽略.gz的文件
filebeat.inputs:
- type: log
...
exclude_files: ['\.gz$']
ignore_older
如果启用,那么Filebeat会忽略在指定的时间跨度之前被修改的文件。如果你想要保留日志文件一个较长的时间,那么配置ignore_older是很有用的。例如,如果你想要开始Filebeat,但是你只想发送最近一周最新的文件,这个情况下你可以配置这个选项。
你可以用时间字符串,比如2h(2小时),5m(5分钟)。默认是0,意思是禁用这个设置。
你必须设置ignore_older比close_inactive更大。
close_*
close_*配置项用于在一个确定的条件或者时间点之后关闭harvester。关闭harvester意味着关闭文件处理器。如果在harvester关闭以后文件被更新,那么在scan_frequency结束后改文件将再次被拾起。然而,当harvester关闭的时候如果文件被删除或者被移动,那么Filebeat将不会被再次拾起,并且这个harvester还没有读取的数据将会丢失。
close_inactive
当启用此选项时,如果文件在指定的持续时间内未被获取,则Filebeat将关闭文件句柄。当harvester读取最后一行日志时,指定周期的计数器就开始工作了。它不基于文件的修改时间。如果关闭的文件再次更改,则会启动一个新的harvester,并且在scan_frequency结束后,将获得最新的更改。
推荐给close_inactive设置一个比你的日志文件更新的频率更大一点儿的值。例如,如果你的日志文件每隔几秒就会更新,你可以设置close_inactive为1m。如果日志文件的更新速率不固定,那么可以用多个配置。
将close_inactive设置为更低的值意味着文件句柄可以更早关闭。然而,这样做的副作用是,如果harvester关闭了,新的日志行不会实时发送。
关闭文件的时间戳不依赖于文件的修改时间。代替的,Filebeat用一个内部时间戳来反映最后一次读取文件的时间。例如,如果close_inactive被设置为5分钟,那么在harvester读取文件的最后一行以后,这个5分钟的倒计时就开始了。
你可以用时间字符串,比如2h(2小时),5m(5分钟)。默认是5m。
close_renamed
当启用此选项时,Filebeat会在重命名文件时关闭文件处理器。默认情况下,harvester保持打开状态并继续读取文件,因为文件处理器不依赖于文件名。如果启用了close_rename选项,并且重命名或者移动的文件不再匹配文件模式的话,那么文件将不会再次被选中。Filebeat将无法完成文件的读取。
close_removed
当启用此选项时,Filebeat会在删除文件时关闭harvester。通常,一个文件只有在它在由close_inactive指定的期间内不活跃的情况下才会被删除。但是,如果一个文件被提前删除,并且你不启用close_removed,则Filebeat将保持文件打开,以确保harvester已经完成。如果由于文件过早地从磁盘中删除而导致文件不能完全读取,请禁用此选项。
close_timeout
当启用此选项是,Filebeat会给每个harvester一个预定义的生命时间。无论读到文件的什么位置,只要close_timeout周期到了以后就会停止读取。当你想要在文件上只花费预定义的时间时,这个选项对旧的日志文件很有用。尽管在close_timeout时间以后文件就关闭了,但如果文件仍然在更新,则Filebeat将根据已定义的scan_frequency再次启动一个新的harvester。这个harvester的close_timeout将再次启动,为超时倒计时。
scan_frequency
Filebeat多久检查一次指定路径下的新文件(PS:检查的频率)。例如,如果你指定的路径是 /var/log/* ,那么会以指定的scan_frequency频率去扫描目录下的文件(PS:周期性扫描)。指定1秒钟扫描一次目录,这还不是很频繁。不建议设置为小于1秒。
如果你需要近实时的发送日志行的话,不要设置scan_frequency为一个很低的值,而应该调整close_inactive以至于文件处理器保持打开状态,并不断地轮询你的文件。
默认是10秒。
scan.sort
如果你指定了一个非空的值,那么你可以决定用scan.order的升序或者降序。可能的值是 modtime 和 filename。为了按文件修改时间排序,用modtime,否则用 filename。默认此选项是禁用的。
scan.order
可能的值是 asc 或者 desc。默认是asc。
更多配置请查看 https://www.elastic.co/guide/en/beats/filebeat/current/configuration-filebeat-options.html
这里再重点说一下 ignore_older , close_inactive , scan_frequency 这三个配置项
- ignore_older: 它是设置一个时间范围(跨度),不在这个跨度范围之内的文件更新都不管
- scan_frequency: 它设置的是扫描文件的频率,看看文件是否更新
- close_inactive:它设置的是文件如果多久没更新的话就关闭文件句柄,它是有一个倒计时,如果在倒计时期间,文件没有任何变化,则当倒计时结束的时候关闭文件句柄。不建议设置为小于1秒。
如果文件句柄关了以后,文件又被更新,那么在下一个扫描周期结束的时候变化发现这个改变,于是会再次打开这个文件读取日志行,前面我们也提到过,每个文件上一次读到什么位置(偏移量)都记录在registry文件中。
管理多行消息
Filebeat获取的文件可能包含跨多行文本的消息。例如,多行消息在包含Java堆栈跟踪的文件中很常见。为了正确处理这些多行事件,你需要在filebeat.yml中配置multiline以指定哪一行是单个事件的一部分。
你可以在filebeat.yml的filebeat.inputs区域指定怎样处理跨多行的消息。例如:
multiline.pattern: '^\['
multiline.negate: true
multiline.match: after
上面的例子中,Filebeat将所有不以 [ 开始的行与之前的行进行合并。
multiline.pattern
指定用于匹配多行的正则表达式
multiline.negate
定义模式是否被否定。默认false。
multiline.match
指定Filebeat如何把多行合并成一个事件。可选的值是 after 或者 before。
这种行为还收到negate的影响:
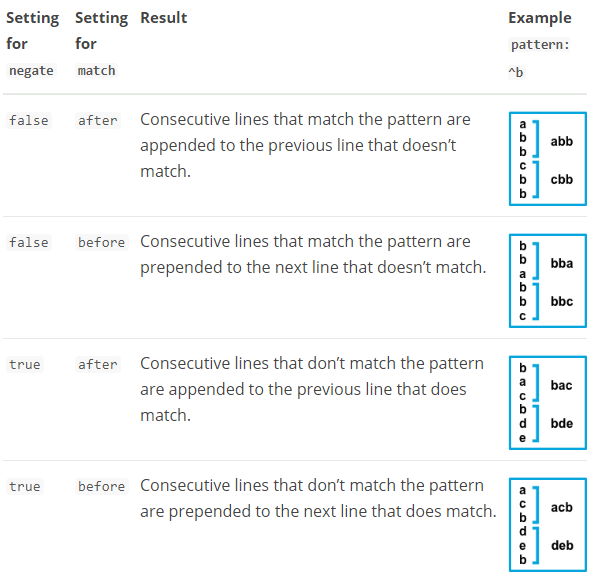
multiline.flush_pattern
指定一个正则表达式,多行将从内存刷新到磁盘。
multiline.max_lines
可以合并成一个事件的最大行数。如果一个多行消息包含的行数超过max_lines,则超过的行被丢弃。默认是500。
配置Logstash output
output.logstash:
hosts: ["127.0.0.1:5044"]
上面是配置Filebeat输出到Logstash,那么Logstash本身也有配置,例如:
input {
beats {
port => 5044
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
}
}
负载均衡
为了启用负载均衡,当你配置输出的时候你需要指定 loadbalance: true
output.logstash:
hosts: ["localhost:5044", "localhost:5045"]
loadbalance: true
一键安装 es+logstash+ kibana
实操过程,请参见23章视频:《100Wqps 超高并发日志平台》实操
对应的镜像版本
elasticsearch:7.14.0
kibana:7.14.0
logstash:7.14.0
filebeat:7.14.0
docker编码文件
version: "3.5"
services:
elasticsearch:
image: andylsr/elasticsearch-with-ik-icu:7.14.0
container_name: elasticsearch
hostname: elasticsearch
restart: always
ports:
- 9200:9200
volumes:
- ./elasticsearch7/logs:/usr/share/elasticsearch/logs
- ./elasticsearch7/data:/usr/share/elasticsearch/data
- ./elasticsearch7/config/single-node.yml:/usr/share/elasticsearch/config/elasticsearch.yml
- ./elasticsearch7/config/jvm.options:/usr/share/elasticsearch/config/jvm.options
- ./elasticsearch7/config/log4j2.properties:/usr/share/elasticsearch/config/log4j2.properties
environment:
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- "TZ=Asia/Shanghai"
- "TAKE_FILE_OWNERSHIP=true" #volumes 挂载权限 如果不想要挂载es文件改配置可以删除
ulimits:
memlock:
soft: -1
hard: -1
networks:
base-env-network:
aliases:
- elasticsearch
kibana:
image: docker.elastic.co/kibana/kibana:7.14.0
container_name: kibana
volumes:
- ./elasticsearch7/config/kibana.yml:/usr/share/kibana/config/kibana.yml
ports:
- 15601:5601
ulimits:
nproc: 65535
memlock: -1
depends_on:
- elasticsearch
networks:
base-env-network:
aliases:
- kibana
logstash:
image: logstash:7.14.0
container_name: logstash
hostname: logstash
restart: always
ports:
- 19600:9600
- 15044:5044
volumes:
- ./logstash/logstash.conf:/usr/share/logstash/pipeline/logstash.conf:rw
- ./logstash/logstash.yml:/usr/share/logstash/config/logstash.yml
- ./logstash/data:/home/logstash/data
networks:
base-env-network:
aliases:
- logstash
# docker network create base-env-network
networks:
base-env-network:
external:
name: "base-env-network"
访问kibana
http://cdh1:15601
SkyWalking
http://cdh2:13800/
kibana
以上的实操过程,请参见23章视频:《100Wqps 超高并发日志平台》实操
读取filebeat-输出到es集群
在分布式系统中,一台主机可能有多个应用,应用将日志输出到主机的指定目录,这时由logstash来搬运日志并解析日志,然后输出到elasticsearch上。
由于于logstash是java应用,解析日志是非的消耗cpu和内存,logstash安装在应用部署的机器上显得非常的笨重。
最常见的做法是用filebeat部署在应用的机器上,logstash单独部署,然后由filebeat将日志输出给logstash解析,解析完由logstash再传给elasticsearch。
在上面的配置中,输入数据源为filebeat,输出源为elasticsearch。
修改logstash的安装目录的config目录下的logstash.conf文件,配置如下:
input {
beats {
port => "5044"
}
}
filter {
if "message-dispatcher" in [tags]{
grok {
match => ["message", "%{TIMESTAMP_ISO8601:time}\s* \s*%{NOTSPACE:thread-id}\s* \s*%{LOGLEVEL:level}\s* \s*%{JAVACLASS:class}\s* \- \s*%{JAVALOGMESSAGE:logmessage}\s*"]
}
}
if "ExampleApplication" in [tags]{
grok {
match => ["message", "%{TIMESTAMP_ISO8601:time}\s* \s*%{NOTSPACE:thread-id}\s* \s*%{LOGLEVEL:level}\s* \s*%{JAVACLASS:class}\s* \- \s*%{JAVALOGMESSAGE:logmessage}\s*"]
}
}
mutate {
remove_field => "log"
remove_field => "beat"
remove_field => "meta"
remove_field => "prospector"
remove_field => "[host][os]"
}
}
output {
stdout { codec => rubydebug }
if "message-dispatcher" in [tags]{
elasticsearch {
hosts => [ "elasticsearch:9200" ]
index => "message-dispatcher-%{+yyyy.MM.dd}"
}
}
if "ExampleApplication" in [tags]{
elasticsearch {
hosts => [ "elasticsearch:9200" ]
index => "ExampleApplication-%{+yyyy.MM.dd}"
}
}
}
更多的输入和输出源的配置见官网
https://www.elastic.co/guide/en/logstash/current/advanced-pipeline.html
在kibana显示的效果
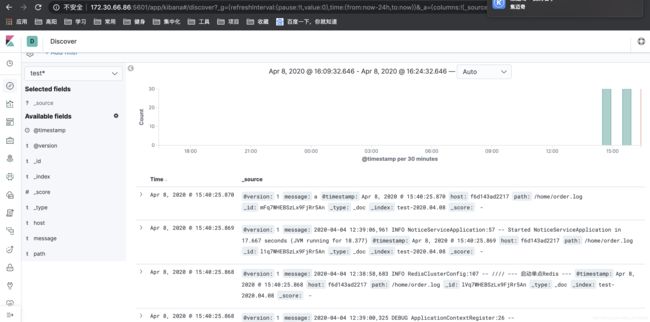
在kibana组件上查看,可以看到创建了一个filebeat开头的数据索引,如下图:
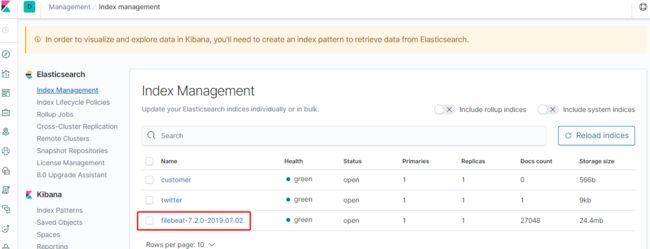
在日志搜索界面,可以看到service-hi应用输出的日志,如图所示:
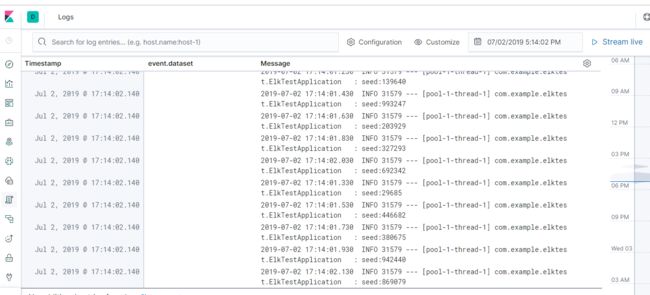
使用filebeat发送日志
制作filebeat镜像
官方文档
https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-getting-started.html
下载filebeat,下载命令如下:
https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.14.0-linux-x86_64.tar.gz
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.2.0-linux-x86_64.tar.gz
tar -zxvf filebeat-7.2.0-linux-x86_64.tar.gz
mv filebeat-7.2.0-linux-x86_64 /usr/share/
cd /usr/share/filebeat-7.2.0-linux-x86_64/
制作基础的unbantu镜像
why unbantu? not alpine? not centos?
Alpine 只有仅仅 5 MB 大小,并且拥有很友好的包管理机制。
Docker 官方推荐使用 Alpine 替代 Ubuntu 做为容器的基础镜像。
曾经尝试使用alpine:3.7作为底层镜像, 按照zookeeper,但是一直启动不来,换成了centos的镜像,排查过程反复实验,耗时很久。
网上小伙伴构建filebeat镜像,基于alpine:3.7, 构建后的镜像运行时报“standard_init_linux.go:190: exec user process caused “no such file or directory””,故最后还是选择ubuntu。
这里选择ubuntu的原因,是其作为底层打包出来的镜像比centos要小很多。
# 基础镜像 生成的镜像作为基础镜像
FROM ubuntu:18.04
# 指定维护者的信息
MAINTAINER 尼恩@疯狂创客圈
# RUN apt-get update && apt-get -y install openjdk-8-jdk
#install wget,sudo,python,vim,ping and ssh command
RUN sed -i s@/archive.ubuntu.com/@/mirrors.aliyun.com/@g /etc/apt/sources.list && apt-get clean && \
apt-get update && apt-get -y install wget && apt-get -y install sudo && \
apt-get -y install iputils-ping && \
apt-get -y install net-tools && \
apt install -y tzdata && \
rm -rf /etc/localtime && ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && dpkg-reconfigure -f noninteractive tzdata && \
apt-get clean
# echo "Asia/Shanghai" > /etc/timezone && dpkg-reconfigure -f noninteractive tzdata && \
# RUN dpkg-reconfigure -f noninteractive tzdata
# RUN apt-get clean
#apt-get -y install python && \
# apt-get -y install vim && \
# apt-get -y install openssh-server && \
# apt-get -y install python-pip && \
# 复制并解压
ADD jdk-8u121-linux-x64.tar.gz /usr/local/
ENV work_path /usr/local
WORKDIR $work_path
# java
ENV JAVA_HOME /usr/local/jdk1.8.0_121
ENV JRE_HOME /usr/local/jdk1.8.0_121/jre
ENV CLASSPATH .:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
ENV PATH ${PATH}:${JAVA_HOME}/bin
dockfile add命令:
ADD指令的功能是将主机构建环境(上下文)目录中的文件和目录、以及一个URL标记的文件 拷贝到镜像中。
其格式是: ADD 源路径 目标路径
注意事项:
1、如果源路径是个文件,且目标路径是以 / 结尾, 则docker会把目标路径当作一个目录,会把源文件拷贝到该目录下。
如果目标路径不存在,则会自动创建目标路径。
2、如果源路径是个文件,且目标路径是不是以 / 结尾,则docker会把目标路径当作一个文件。
如果目标路径不存在,会以目标路径为名创建一个文件,内容同源文件;
如果目标文件是个存在的文件,会用源文件覆盖它,当然只是内容覆盖,文件名还是目标文件名。
如果目标文件实际是个存在的目录,则会源文件拷贝到该目录下。 注意,这种情况下,最好显示的以 / 结尾,以避免混淆。
3、如果源路径是个目录,且目标路径不存在,则docker会自动以目标路径创建一个目录,把源路径目录下的文件拷贝进来。
如果目标路径是个已经存在的目录,则docker会把源路径目录下的文件拷贝到该目录下。
4、如果源文件是个归档文件(压缩文件,比如 .tar文件),则docker会自动帮解压。
推送镜像到dockerhub
这个镜像解决了jdk问题,时区问题
推送到了dockerhub,大家可以直接作为基础镜像使用
docker login
docker tag 8d0abdffe76f nien/ubuntu:18.04
docker push nien/ubuntu:18.04
制作filebeat镜像
官方文档
https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-getting-started.html
下载filebeat,下载命令如下:
https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.14.0-linux-x86_64.tar.gz
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.2.0-linux-x86_64.tar.gz
tar -zxvf filebeat-7.2.0-linux-x86_64.tar.gz
mv filebeat-7.2.0-linux-x86_64 /usr/share/
cd /usr/share/filebeat-7.2.0-linux-x86_64/
dockerfile
# 基础镜像 生成的镜像作为基础镜像
FROM nien/ubuntu:18.04
# 指定维护者的信息
MAINTAINER 尼恩@疯狂创客圈
# 复制并解压
ADD filebeat-7.14.0-linux-x86_64.tar.gz /usr/local/
构建镜像
docker build -t filebeat:7.14.0 .
构建之后,进入容器,可以看到 /usr/local 目录下的filebeat-7.14.0-linux-x86_64
[root@cdh2 filebeat]# docker run -it filebeat:7.14.0 /bin/bash
root@7ba04f21f26e:/usr/local# ll
total 48
drwxr-xr-x 1 root root 4096 Apr 2 09:26 ./
drwxr-xr-x 1 root root 4096 Mar 16 03:27 ../
drwxr-xr-x 2 root root 4096 Mar 16 03:27 bin/
drwxr-xr-x 2 root root 4096 Mar 16 03:27 etc/
drwxr-xr-x 5 root root 4096 Apr 2 09:26 filebeat-7.14.0-linux-x86_64/
drwxr-xr-x 2 root root 4096 Mar 16 03:27 games/
drwxr-xr-x 2 root root 4096 Mar 16 03:27 include/
drwxr-xr-x 8 uucp 143 4096 Dec 13 2016 jdk1.8.0_121/
drwxr-xr-x 2 root root 4096 Mar 16 03:27 lib/
lrwxrwxrwx 1 root root 9 Mar 16 03:27 man -> share/man/
drwxr-xr-x 2 root root 4096 Mar 16 03:27 sbin/
drwxr-xr-x 1 root root 4096 Apr 2 00:44 share/
drwxr-xr-x 2 root root 4096 Mar 16 03:27 src/
推送镜像到dockerhub
这个镜像解决了jdk问题,时区问题
推送到了dockerhub,大家可以直接作为基础镜像使用
[root@cdh2 filebeat]# docker tag fb44037ab5f9 nien/filebeat:7.14.0
[root@cdh2 filebeat]# docker push nien/filebeat:7.14.0
The push refers to repository [docker.io/nien/filebeat]
069c957c7a4e: Pushing [=======> ] 19.99MB/140MB
b17e3cbc28a1: Mounted from nien/ubuntu
5695cc8dd56c: Mounted from nien/ubuntu
9d6787a516e7: Mounted from nien/ubuntu
如果要收集日志,就可以用这个基础镜像加点配置就ok啦
关于 本文的代码,和技术问题, 请来尼恩 发起的Java 高并发 疯狂创客圈 社群交流 ,
example-application微服务的filebeat配置:
实操过程,请参见23章视频:《100Wqps 超高并发日志平台》实操
关于 本文的代码,和技术问题, 请来尼恩 发起的Java 高并发 疯狂创客圈 社群交流 ,
filebeat.yml的参考配置:
# ============================== Filebeat inputs ===============================
filebeat.config.inputs:
enable: true
path: /work/filebeat/input.yml
reload.enabled: true
reload.period: 2s
# ============================== Filebeat modules ==============================
filebeat.config.modules:
# Glob pattern for configuration loading
path: ${path.config}/modules.d/*.yml
# Set to true to enable config reloading
reload.enabled: true
# Period on which files under path should be checked for changes
#reload.period: 10s
#----------------------------- Logstash output --------------------------------
output.logstash:
# The Logstash hosts
hosts: ["cdh1:15044"]
# Optional SSL. By default is off.
# List of root certificates for HTTPS server verifications
#ssl.certificate_authorities: ["/etc/pki/root/ca.pem"]
# Certificate for SSL client authentication
#ssl.certificate: "/etc/pki/client/cert.pem"
# Client Certificate Key
#ssl.key: "/etc/pki/client/cert.key"
输出到logstsh的地址为logstash,这里用的是容器的名称, logstash和 这个微服务,需要在同一个网络。
如果不是,可以使用虚拟机的名称,然后把 5044,映射到15044
input.yml配置:
主要配置的是日志的搜集目录为/work/logs/output.log,这个目录是应用message-dispatcher输出日志的文件。
由于其他的微服务也是固定在这个 文件,

所以这个路径,基本可以固定。
#filebeat.input:
- type: log
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /work/logs/info/*.log
- /work/logs/error/*.log
#
# - /work/logs/output.log
multiline:
pattern: '^\s*(\d{4}|\d{2})\-(\d{2}|[a-zA-Z]{3})\-(\d{2}|\d{4})' # 指定匹配的表达式(匹配以 2017-11-15 08:04:23:889 时间格式开头的字符串)
negate: true # 是否匹配到
match: after # 合并到上一行的末尾, 为了error日志
max_lines: 1000 # 最大的行数
timeout: 30s # 如果在规定的时候没有新的日志事件就不等待后面的日志
tags: ["example-application"] #用于logstash过滤
#fields:
#source: ExampleApplication
#tags: ["GUID"]
#- /var/log/*.log
#- c:\programdata\elasticsearch\logs\*
#include_l ines: ['^ERROR']
启动filebeat,执行一下命令:
nohup /user/local/filebeat-7.14.0-linux-x86_64/filebeat -c /work/filebeat/filebeat.yaml >> /work/filebeat/out.log 2>&1 &
修改dockerfile
FROM nien/filebeat:7.14.0
# 指定维护者的信息
MAINTAINER 尼恩@疯狂创客圈
ADD dispatcher-provider-1.0-SNAPSHOT.jar /app/message-dispatcher.jar
ADD deploy-sit.sh /app/run.sh
RUN chmod +x /app/run.sh
# WORKDIR /app/
ENTRYPOINT /bin/bash -c "/app/run.sh start"
# ENTRYPOINT /bin/bash
一键发布
使用shell脚本一键发布,这里的脚本,请参见视频
具体的演示,请参见视频
启动之后
spatcher | ----------------------------------------------------------
message-dispatcher | UAA 推送中台 push-provider is running! Access URLs:
message-dispatcher | Local: http://127.0.0.1:7703/message-dispatcher-provider/
message-dispatcher | swagger-ui: http://127.0.0.1:7703/message-dispatcher-provider/swagger-ui.html
message-dispatcher | actuator: http://127.0.0.1:7703/message-dispatcher-provider/actuator/info
message-dispatcher | ----------------------------------------------------------
message-di
http://cdh2:7703/message-dispatcher-provider/swagger-ui.html
message-dispatcher微服务的日志
在SpringBoot应用message-dispatcher微服务的日志,输出日志如下:
[root@cdh2 filebeat]# cd /home/docker-compose/sit-ware/message-dispatcher/work/logs/
[root@cdh2 logs]# cat output.log
2022-04-02 09:03:30.103 [background-preinit] DEBUG o.h.v.m.ResourceBundleMessageInterpolator:89 - Loaded expression factory via original TCCL
2022-04-02 09:03:59.633 [main] INFO o.s.c.s.PostProcessorRegistrationDelegate$BeanPostProcessorChecker:330 - Bean 'org.springframework.cloud.autoconfigure.ConfigurationPropertiesRebinderAutoConfiguration' of type [org.springframework.cloud.autoconfigure.ConfigurationPropertiesRebinderAutoConfiguration$$EnhancerBySpringCGLIB$$e81692de] is not eligible for getting processed by all BeanPostProcessors (for example: not eligible for auto-proxying)
2022-04-02 09:04:05.331 [main] INFO c.a.n.client.config.impl.LocalConfigInfoProcessor:195 - LOCAL_SNAPSHOT_PATH:/root/nacos/config
2022-04-02 09:04:06.034 [main] INFO com.alibaba.nacos.client.config.impl.Limiter:53 - limitTime:5.0
2022-04-02 09:04:06.899 [main] INFO com.alibaba.nacos.client.config.utils.JVMUtil:47 - isMultiInstance:false
2022-04-02 09:04:07.068 [main] WARN c.a.cloud.nacos.client.NacosPropertySourceBuilder:87 - Ignore the empty nacos configuration and get it based on dataId[message-dispatcher-provider] & group[DEFAULT_GROUP]
2022-04-02 09:04:07.100 [main] WARN c.a.cloud.nacos.client.NacosPropertySourceBuilder:87 - Ignore the empty nacos configuration and get it based on dataId[message-dispatcher-provider.yml] & group[DEFAULT_GROUP]
2022-04-02 09:04:07.191 [main] INFO o.s.c.b.c.PropertySourceBootstrapConfiguration:101 - Located property source: CompositePropertySource {name='NACOS', propertySources=[NacosPropertySource {name='message-dispatcher-provider-sit.yml,DEFAULT_GROUP'}, NacosPropertySource {name='message-dispatcher-provider.yml,DEFAULT_GROUP'}, NacosPropertySource {name='message-dispatcher-provider,DEFAULT_GROUP'}, NacosPropertySource {name='sharding-db-dev.yml,DEFAULT_GROUP'}]}
2022-04-02 09:04:07.304 [main] INFO c.c.s.message.start.MessageDispatchApplication:652 - The following profiles are active: sit
2022-04-02 09:04:28.417 [main] INFO o.s.d.r.config.RepositoryConfigurationDelegate:247 - Multiple Spring Data modules found, entering strict repository configuration mode!
2022-04-02 09:04:28.418 [main] INFO o.s.d.r.config.RepositoryConfigurationDelegate:127 - Bootstrapping Spring Data JPA repositories in DEFAULT mode.
2022-04-02 09:04:34.251 [main] INFO o.s.d.r.config.RepositoryConfigurationDelegate:185 - Finished Spring Data repository scanning in 5673ms. Found 3 JPA repository interfaces.
2022-04-02 09:04:37.630 [main] WARN o.springframework.boot.actuate.endpoint.EndpointId:131 - Endpoint ID 'nacos-config' contains invalid characters, please migrate to a valid format.
2022-04-02 09:07:17.969 [main] ERROR org.springframework.boot.SpringApplication:823 - Application run failed
org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'messageController': Injection of resource dependencies failed; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'messagePushServiceImpl': Injection of resource dependencies failed; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'rocketmqMessageService' defined in URL [jar:file:/app/message-dispatcher.jar!/BOOT-INF/classes!/com/crazymaker/springcloud/message/service/impl/RocketmqMessageService.class]: Initialization of bean failed; nested exception is java.lang.IllegalStateException: org.apache.rocketmq.remoting.exception.RemotingTimeoutException: wait response on the channel timeout, 3000(ms)
at org.springframework.context.annotation.CommonAnnotationBeanPostProcessor.postProcessProperties(CommonAnnotationBeanPostProcessor.java:325)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.populateBean(AbstractAutowireCapableBeanFactory.java:1404)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.doCreateBean(AbstractAutowireCapableBeanFactory.java:592)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBean(AbstractAutowireCapableBeanFactory.java:515)
然后在部署了filebeat的机器上部署该应用,应用的输出文件为/var/log/service-hi.log,应用启动命令如下:
1 nohup java -jar elk-test-0.0.1-SNAPSHOT.jar > /var/log/service-hi.log 2>&1 &
应用启动成功后日志输出如下:
1 2019-07-02 17:13:13.530 INFO 31579 --- [pool-1-thread-1] com.example.elktest.ElkTestApplication : seed:562779
2 2019-07-02 17:13:13.630 INFO 31579 --- [pool-1-thread-1] com.example.elktest.ElkTestApplication : seed:963836
3 2019-07-02 17:13:13.730 INFO 31579 --- [pool-1-thread-1] com.example.elktest.ElkTestApplication : seed:825694
4 2019-07-02 17:13:13.830 INFO 31579 --- [pool-1-thread-1] com.example.elktest.ElkTestApplication : seed:33228
5 2019-07-02 17:13:13.930 INFO 31579 --- [pool-1-thread-1] com.example.elktest.ElkTestApplication : seed:685589
这时的日志数据的传输路径如下图:
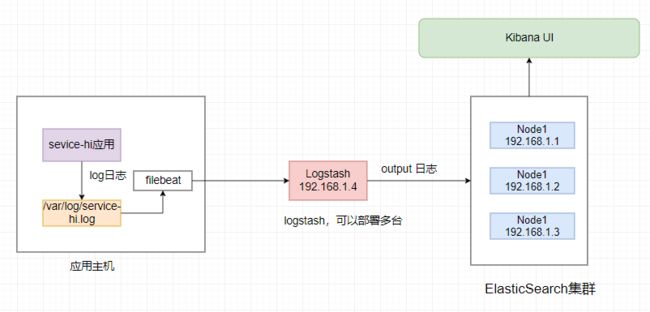
关于 本文的代码,和技术问题, 请来尼恩 发起的Java 高并发 疯狂创客圈 社群交流 ,
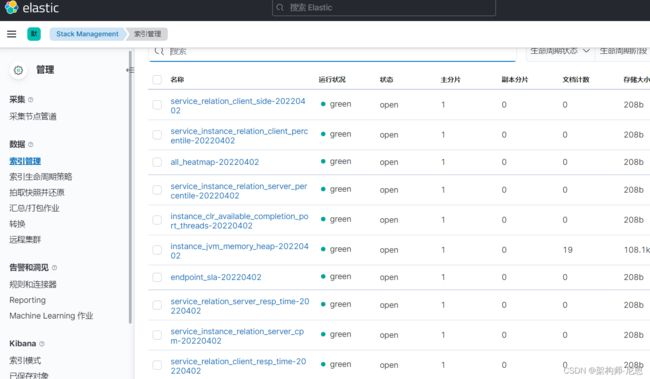
查看日志索引
docker run --name filebeat -d \
-v /home/qw/elk/filebeat/filebeat.yml:/usr/share/filebeat/filebeat.yml \
-v /home/qw/elk/testlog/:/home/ \
elastic/filebeat:7.2.0
效果
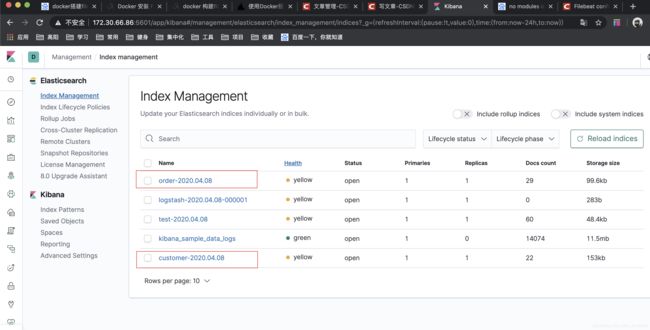
可以看到 在kibana中多了两个索引
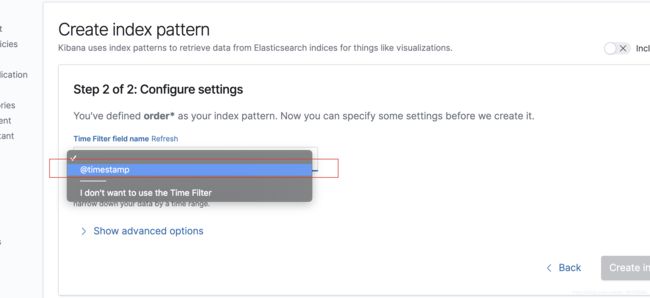
需要配置
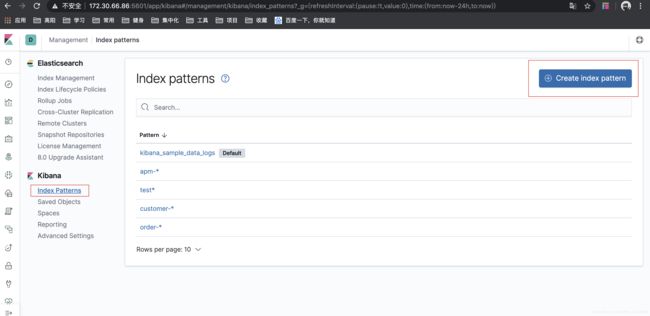
创建一个
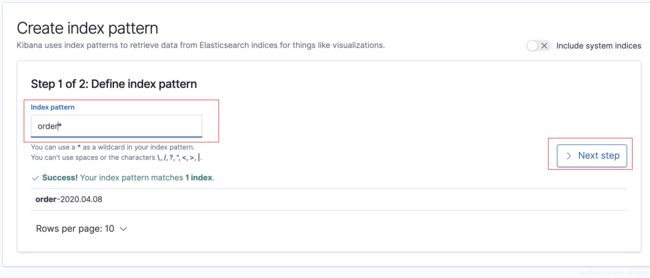
选择
最终展示
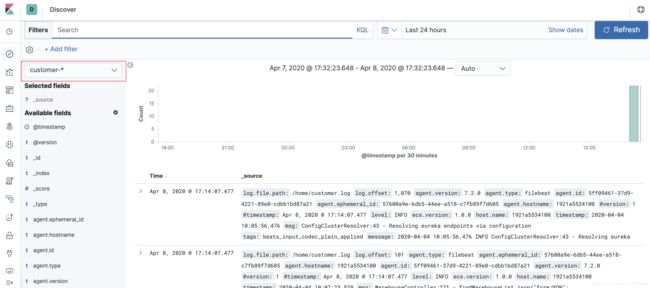
到这里简单收集日志就完成了,需要更多复杂业务配置,需要大家根据需求自己配置详细信息.
logstash 详解
Logstash 是一款强大的数据处理工具,它可以实现数据传输,格式处理,格式化输出,
logstash 还有强大的插件功能,常用于日志处理.
logstash我们只让它进行日志处理,处理完之后将其输出到elasticsearch。
官方文档
https://www.elastic.co/guide/en/logstash/7.17/index.html
关于 本文的代码,和技术问题, 请来尼恩 发起的Java 高并发 疯狂创客圈 社群交流 ,
stash第一个事件
Logstash管道有两个必需元素,输入和输出,以及一个可选元素filter。
输入插件使用来自源的数据,过滤器插件在您指定时修改数据,输出插件将数据写入目标。
如下图
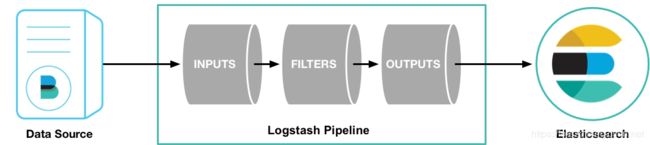
根据官方文档Logstash对数据的处理主要流程是
- 首先数据传入logstash,在其内部对数据进行过滤和处理
- logstash将处理过的数据传递给Elasticsearch
- Elasticsearch对数据进行存储、创建索引等内容
- kibana对数据提供可视化的支持
Logstash的核心流程的三个环节
Logstash核心分三个环节:
- 数据输入
- 数据处理
- 数据输出
其数据输入、处理、输出主要在配置中间中下面部分进行配置
input {}
filter {}
output {}
logstash数值类型
- 数组
match =>[“datetime”, “UNIX”, “ISO8601”]
- 布尔
必须是一个true或false
ssl_enable => true
- 字节
一个字段是字节字符串字段表示有效字节的单元。它是一种方便的方式在特定尺寸的插件选项。
支持SI (k M G T P E Z Y)和Binary (TiKimigipiziyiei)单位。
二进制单元在基座单元和Si-1024在基底1000。
这个字段是大小写敏感的。如果未指定单位,则整数表示的字符串的字节数。
my_bytes => "1113" # 1113 bytes
my_bytes => "10MiB" # 10485760 bytes
my_bytes => "100kib" # 102400bytes
my_bytes => "180 mb"# 180000000 bytes
- 编解码器
codec => “json”
- 哈希
哈希是一个键值对的集合中指定的格式,多个键值对的条目以空格分隔而不是逗号。
match => { “field1” => “value1” “field2” =>“value2” … }
- 数字
数字必须有效的数字值(浮点或整数)。
port => 33
- 密码
密码是一个字符串的单个值,则不对其进行记录或打印。
my_password => “password”
- uri
my_uri =>“http://foo:[email protected]”
- 路径
一个路径是一个字符串,表示系统运行的有效路径。
my_path =>“/tmp/logstash”
- 转义序列
默认地,转义字符没有被启用。如果你希望使用转义字符串序列,您需要在你的logstash.yml中设置config.support_escapes: true
| Text | Result |
|---|---|
| \r | carriage return (ASCII 13) |
| \n | new line (ASCII 10) |
| \t | tab (ASCII 9) |
| \ | backslash (ASCII 92) |
| " | double quote (ASCII 34) |
| ’ | single quote (ASCII 39) |
logstash 条件判断
有时您只想在特定条件下过滤或输出事件。为此,您可以使用条件。
Logstash中的条件查看和行为与编程语言中的条件相同。条件语句支持if,else if以及else报表和可以被嵌套。
条件语法
if EXPRESSION{ … } else if EXPRESSION { … } else { … }
logstash 比较运算符
等于: ==, !=, <, >, <=, >=
正则: =~, !~ (checks a pattern on the right against a string value on the left)
包含关系: in, not in
支持的布尔运算符:and, or, nand, xor
支持的一元运算符: !
| 作用 | 符号 |
|---|---|
| 等于 | == |
| 不等于 | != |
| 小于 | < |
| 大于 | > |
| 小于等于 | <= |
| 大于等于 | >= |
| 匹配正则 | =~ |
| 不匹配正则 | !~ |
| 包含 | in |
| 不包含 | not in |
| 与 | and |
| 或 | or |
| 非与 | nand |
| 非或 | xor |
| 复合表达式 | () |
| 取反符合 | !() |
关于 本文的代码,和技术问题, 请来尼恩 发起的Java 高并发 疯狂创客圈 社群交流 ,
数据输入环节
input配置定义了数据的来源。其主要支持下面方式
事件源可以是从stdin屏幕输入读取,可以从file指定的文件,也可以从es,filebeat,kafka,redis等读取
stdin
监控控制台输入。
要测试Logstash安装成功,运行最基本的Logstash管道。 执行以下的命令
bin/logstash -e 'input { stdin { } } output { stdout {} }'
-e 标志使您可以直接从命令行指定配置。
通过在命令行指定配置,可以快速测试配置,而无需在迭代之间编辑文件。
示例中的管道从标准输入stdin获取输入,并以结构化格式将输入移动到标准输出stdout。
启动Logstash后,等到看到“Pipeline main started”,然后在命令提示符下输入hello world,显示的如下:
hello world
{
"host" => "VM_0_13_centos",
"message" => "hello world",
"@version" => "1",
"@timestamp" => 2019-07-02T06:26:28.684Z
}
file
监控文件内容
file{
path => ['/var/log/nginx/access.log'] #要输入的文件路径
type => 'nginx_access_log'
start_position => "beginning"
}
-
path 可以用/var/log/.log,/var/log/**/.log,
-
type 通用选项. 用于激活过滤器
-
start_position 选择logstash开始读取文件的位置,begining或者end。
还有一些常用的例如:discover_interval,exclude,sincedb_path,sincedb_write_interval等可以参考官网
syslogs
从syslogs读取数据
syslog{
port =>"514"
type => "syslog"
}
# port 指定监听端口(同时建立TCP/UDP的514端口的监听)
#从syslogs读取需要实现配置rsyslog:
# cat /etc/rsyslog.conf 加入一行
*.* @172.17.128.200:514 #指定日志输入到这个端口,然后logstash监听这个端口,如果有新日志输入则读取
# service rsyslog restart #重启日志服务
beats
从Elastic beats接收数据
beats {
port => 5044 #要监听的端口
}
# 还有host等选项
# 从beat读取需要先配置beat端,从beat输出到logstash。
# vim /etc/filebeat/filebeat.yml
..........
output.logstash:
hosts: ["localhost:5044"]
kafka
从kafka topic中读取数据
kafka{
bootstrap_servers=> "kafka01:9092,kafka02:9092,kafka03:9092"
topics => ["access_log"]
group_id => "logstash-file"
codec => "json"
}
kafka{
bootstrap_servers=> "kafka01:9092,kafka02:9092,kafka03:9092"
topics => ["weixin_log","user_log"]
codec => "json"
}
# bootstrap_servers 用于建立群集初始连接的Kafka实例的URL列表。
# topics 要订阅的主题列表,kafka topics
# group_id 消费者所属组的标识符,默认为logstash。kafka中一个主题的消息将通过相同的方式分发到Logstash的group_id
# codec 通用选项,用于输入数据的编解码器。
关于 本文的代码,和技术问题, 请来尼恩 发起的Java 高并发 疯狂创客圈 社群交流 ,
数据处理环节
filter plugin 过滤器插件,主要是对数据进行处理。
grok解析文本并构造
Grok 是一个十分强大的 Logstash Filter 插件,它可以通过正则解析任意文本,将非结构化日志数据格式转换为结构化的、方便查询的结构。
它是目前 Logstash 中解析非结构化日志数据最好的方式。
Grok 的语法规则是:
这里的 “语法” 指的是匹配模式,例如,使用 NUMBER 模式可以匹配出数字,IP 模式则会匹配出 127.0.0.1 这样的 IP 地址。比如按以下格式输入内容:
172.16.213.132 [16/Jun/2020:16:24:19 +0800] "GET / HTTP/1.1" 403 5039
那么,
• %{IP:clientip} 匹配模式将获得的结果为:clientip: 172.16.213.132
• %{HTTPDATE:timestamp} 匹配模式将获得的结果为:timestamp: 16/Jun/2020:16:24:19 +0800
• %{QS:referrer} 匹配模式将获得的结果为:referrer: “GET / HTTP/1.1”
到这里为止,我们已经获取了上面输入中前三个部分的内容,分别是 clientip、timestamp 和 referrer 三个字段。
如果要获取剩余部分的信息,方法类似。
要在线调试 Grok,可以点击在线调试,可点击这里进行在线调试,非常方便。
下面是一个组合匹配模式,它可以获取上面输入的所有内容:
%{IP:clientip}\ \[%{HTTPDATE:timestamp}\]\ %{QS:referrer}\ %{NUMBER:response}\ %{NUMBER:bytes}
正则匹配是非常严格的匹配,在这个组合匹配模式中,使用了转义字符 \,这是因为输入的内容中有空格和中括号。
通过上面这个组合匹配模式,我们将输入的内容分成了 5 个部分,即 5 个字段。
将输入内容分割为不同的数据字段,这对于日后解析和查询日志数据非常有用,这正是我们使用 grok 的目的。
Logstash 默认提供了近 200 个匹配模式(其实就是定义好的正则表达式)让我们来使用,可以在 Logstash 安装目录下找到。
例如,我这里的路径为:
/usr/local/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patterns
此目录下有定义好的各种匹配模式,基本匹配定义在 grok-patterns 文件中。
从这些定义好的匹配模式中,可以查到上面使用的四个匹配模式对应的定义规则。
除此之外,还有很多默认定义好的匹配模式文件,比如 httpd、java、linux-syslog、redis、mongodb、nagios 等,这些已经定义好的匹配模式,可以直接在 Grok 过滤器中进行引用。
当然也可以定义自己需要的匹配模式。
在了解完 Grok 的匹配规则之后,下面通过一个配置实例深入介绍下 Logstash 是如何将非结构化日志数据转换成结构化数据的。
首先看下面的一个事件配置文件:
input{
stdin{}
}
filter{
grok{
match => ["message", "%{IP:clientip}\ \[%{HTTPDATE:timestamp}\]\ %{QS:referrer}\ % {NUMBER:response}\ %{NUMBER:bytes}"]
}
}
output{
stdout{
codec => "rubydebug"
}
}
在这个配置文件中,输入配置成了 stdin,在 filter 中添加了 grok 过滤插件,并通过 match 来执行正则表达式解析,
grok 中括号中的正则表达式就是上面提到的组合匹配模式,然后通过 rubydebug 编码格式输出信息。
这样的组合有助于调试和分析输出结果。
通过此配置启动 Logstash 进程后,我们仍然输入之前给出的那段内容:
172.16.213.132 [16/Jun/2020:16:24:19 +0800] "GET / HTTP/1.1" 403 5039
然后,查看 rubydebug 格式的日志输出,内容如下:
{
"timestamp" => "16/Jun/2020:16:24:19 +0800",
"response" => "403",
"bytes" => "5039",
"@version" => "1",
"clientip" => "172.16.213.132",
"host" => "nnmaster.cloud",
"referrer" => "\"GET / HTTP/1.1\"",
"message" => "172.16.213.132 [16/Jun/2020:16:24:19 +0800] \"GET / HTTP/1.1\" 403 5039",
"@timestamp" => 2020-06-16T07:46:53.120Z
}
从这个输出可知,通过 Grok 定义好的 5 个字段都获取到了内容,并正常输出了。
date日期解析
解析字段中的日期,然后转存到@timestamp
[2018-07-04 17:43:35,503]
grok{
match => {"message"=>"%{DATA:raw_datetime}"}
}
date{
match => ["raw_datetime","YYYY-MM-dd HH:mm:ss,SSS"]
remove_field =>["raw_datetime"]
}
#将raw_datetime存到@timestamp 然后删除raw_datetime
#24/Jul/2018:18:15:05 +0800
date {
match => ["timestamp","dd/MMM/YYYY:HH:mm:ss Z]
}
mutate字段转换
mutate字段转换, 对字段做处理 重命名、删除、替换和修改字段。
Mutate过滤器的配置选项
| 选项 | 类型 | 是否必须 | 简述 |
|---|---|---|---|
| convert | hash | No | 转化命令,是对字段类型做转化,例如:String转为integer |
| copy | hash | No | 将一个已经存在的字段复制给另一个字段。 |
| gsub | array | No | 通过正则表达式匹配字段的值,然后替换为指定的字符串。 |
| join | hash | No | 使用分隔符连接数组。 |
| lowercase | array | No | 将string类型的字段值转化为小写的形式。 |
| merge | hash | No | 合并两个数组或者Hash类型的字段。string类型的字段会自动的合并为一个数组。 |
| coerce | hash | No | 为存在但是不为空的字段设置默认值 |
| rename | hash | No | 字段重命名 |
| replace | hash | No | 将一个字段的值替换为一个新的值。 |
| split | hash | No | 将一个字段按照指定符号切割为数组。 |
| strip | array | No | 去除字段中的空格。 |
| update | hash | No | 更新字段为一个新值。 |
| uppercase | array | No | 将字符串字段转化为大写形式。 |
| capitalize | array | No | 将字符串字段转化为首字母大写的形式。 |
| tag_on_failure | string | No | 错误发生时的配置 |
covert类型转换
covert:类型转换。类型包括:integer,float,integer_eu,float_eu,string和boolean
- 字段类型为 hash
- 没有默认值
将字段转化为不同的类型,例如:string 转 integer。
如果被转化的字段类型是数组,数组的所有成员都将被转化。如果对象是hash 就不会进行转化。
实例:
filter {
mutate {
convert => {
"fieldname" => "integer"
"booleanfield" => "boolean"
}
}
}
split
split:使用分隔符把字符串分割成数组
eg:
mutate{
split => {"message"=>","}
}
aaa,bbb
{
"@timestamp" => 2018-06-26T02:40:19.678Z,
"@version" => "1",
"host" => "localhost",
"message" => [
[0] "aaa",
[1] "bbb"
]}
192,128,1,100
{
"host" => "localhost",
"message" => [
[0] "192",
[1] "128",
[2] "1",
[3] "100"
],
"@timestamp" => 2018-06-26T02:45:17.877Z,
"@version" => "1"
}
mutate{
split => {"message"=>","}
}
merge
merge:合并字段 。数组和字符串 ,字符串和字符串
eg:
filter{
mutate{
add_field => {"field1"=>"value1"}
}
mutate{
split => {"message"=>"."} #把message字段按照.分割
}
mutate{
merge => {"message"=>"field1"} #将filed1字段加入到message字段
}
}
输入:abc
{
"message" => [
[0] "abc,"
[1] "value1"
],
"@timestamp" => 2018-06-26T03:38:57.114Z,
"field1" => "value1",
"@version" => "1",
"host" => "localhost"
}
输入:abc,.123
{
"message" => [
[0] "abc,",
[1] "123",
[2] "value1"
],
"@timestamp" => 2018-06-26T03:38:57.114Z,
"field1" => "value1",
"@version" => "1",
"host" => "localhost"
}
rename
rename:对字段重命名
filter{
mutate{
rename => {"message"=>"info"}
}
}
123
{
"@timestamp" => 2018-06-26T02:56:00.189Z,
"info" => "123",
"@version" => "1",
"host" => "localhost"
}
remove_field:移除字段
mutate {
remove_field => ["message","datetime"]
}
join
join:用分隔符连接数组,如果不是数组则不做处理
mutate{
split => {"message"=>":"}
}
mutate{
join => {"message"=>","}
}
abc:123
{
"@timestamp" => 2018-06-26T03:55:41.426Z,
"message" => "abc,123",
"host" => "localhost",
"@version" => "1"
}
aa:cc
{
"@timestamp" => 2018-06-26T03:55:47.501Z,
"message" => "aa,cc",
"host" => "localhost",
"@version" => "1"
}
gsub:用正则或者字符串替换字段值。仅对字符串有效
mutate{
gsub => ["message","/","_"] #用_替换/
}
------>
a/b/c/
{
"@version" => "1",
"message" => "a_b_c_",
"host" => "localhost",
"@timestamp" => 2018-06-26T06:20:10.811Z
}
update:更新字段。如果字段不存在,则不做处理
mutate{
add_field => {"field1"=>"value1"}
}
mutate{
update => {"field1"=>"v1"}
update => {"field2"=>"v2"} #field2不存在 不做处理
}
---------------->
{
"@timestamp" => 2018-06-26T06:26:28.870Z,
"field1" => "v1",
"host" => "localhost",
"@version" => "1",
"message" => "a"
}
replace:更新字段。如果字段不存在,则创建
mutate{
add_field => {"field1"=>"value1"}
}
mutate{
replace => {"field1"=>"v1"}
replace => {"field2"=>"v2"}
}
---------------------->
{
"message" => "1",
"host" => "localhost",
"@timestamp" => 2018-06-26T06:28:09.915Z,
"field2" => "v2", #field2不存在,则新建
"@version" => "1",
"field1" => "v1"
}
geoip
根据来自Maxmind GeoLite2数据库的数据添加有关IP地址的地理位置的信息
geoip {
source => "clientip"
database =>"/tmp/GeoLiteCity.dat"
}
ruby
ruby插件可以执行任意Ruby代码
filter{
urldecode{
field => "message"
}
ruby {
init => "@kname = ['url_path','url_arg']"
code => "
new_event = LogStash::Event.new(Hash[@kname.zip(event.get('message').split('?'))])
event.append(new_event)"
}
if [url_arg]{
kv{
source => "url_arg"
field_split => "&"
target => "url_args"
remove_field => ["url_arg","message"]
}
}
}
# ruby插件
# 以?为分隔符,将request字段分成url_path和url_arg
-------------------->
www.test.com?test
{
"url_arg" => "test",
"host" => "localhost",
"url_path" => "www.test.com",
"message" => "www.test.com?test",
"@version" => "1",
"@timestamp" => 2018-06-26T07:31:04.887Z
}
www.test.com?title=elk&content=学习elk
{
"url_args" => {
"title" => "elk",
"content" => "学习elk"
},
"host" => "localhost",
"url_path" => "www.test.com",
"@version" => "1",
"@timestamp" => 2018-06-26T07:33:54.507Z
}
urldecode
用于解码被编码的字段,可以解决URL中 中文乱码的问题
urldecode{
field => "message"
}
# field :指定urldecode过滤器要转码的字段,默认值是"message"
# charset(缺省): 指定过滤器使用的编码.默认UTF-8
kv
通过指定分隔符将字符串分割成key/value
kv{
prefix => "url_" #给分割后的key加前缀
target => "url_ags" #将分割后的key-value放入指定字段
source => "message" #要分割的字段
field_split => "&" #指定分隔符
remove_field => "message"
}
-------------------------->
a=1&b=2&c=3
{
"host" => "localhost",
"url_ags" => {
"url_c" => "3",
"url_a" => "1",
"url_b" => "2"
},
"@version" => "1",
"@timestamp" => 2018-06-26T07:07:24.557Z
useragent
添加有关用户代理(如系列,操作系统,版本和设备)的信息
if [agent] != "-" {
useragent {
source => "agent"
target => "ua"
remove_field => "agent"
}
}
# if语句,只有在agent字段不为空时才会使用该插件
#source 为必填设置,目标字段
#target 将useragent信息配置到ua字段中。如果不指定将存储在根目录中
数据输出
output配置定义了数据输出目标
stdout
将数据输出到屏幕上
input{
file{
path=>"/home/order.log"
discover_interval => 10
start_position => "beginning"
}
}
output{
stdout { codec => rubydebug }
}
file
将数据写入文件
读取指定文件-输出到文件
input{
file{
path=>"/home/order.log"
discover_interval => 10
start_position => "beginning"
}
}
output{
file{
path=>"/home/aaa.log"
}
}
ps: 需要注意的是 这里的输出文件必须要求 w的权限 看看是否报错
如果报错需要进入容器赋权
kafka
数据发送到kafka
kafka{
bootstrap_servers => "localhost:9092"
topic_id => "test_topic" #必需的设置。生成消息的主题
}
elasticseach
数据存储到elasticseach中
读取指定文件-输出到es
input{
file{
path=>"/home/order.log"
discover_interval => 10
start_position => "beginning"
}
}
output{
elasticsearch{
hosts=>["172.30.66.86:9200"]
index => "test-%{+YYYY.MM.dd}"
}
}
Kibana查看应用日志
实操过程,请参见23章视频:《100Wqps 超高并发日志平台》实操
关于 本文的代码,和技术问题, 请来尼恩 发起的Java 高并发 疯狂创客圈 社群交流 ,
1 查看应用日志
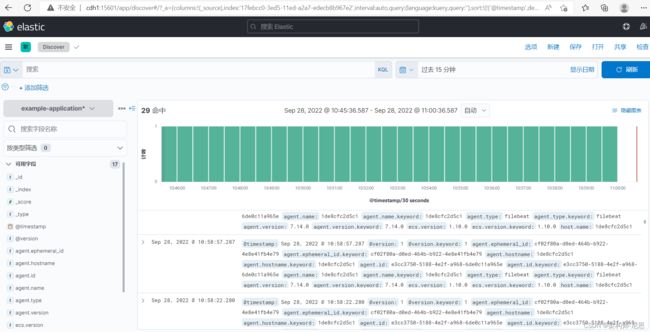
2 如何搜索日志
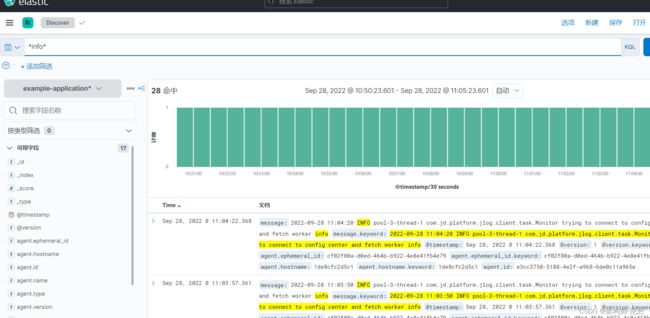
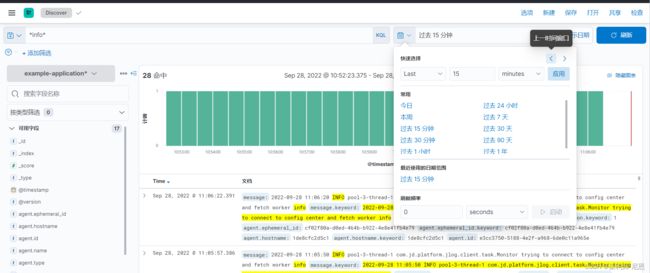
3 如何查看指定时间的应用日志
- ->右上角选择时间
4 如何定位错误日志
- Search框输入error -> Refresh
(有自己的语法规则,要搜索一下)
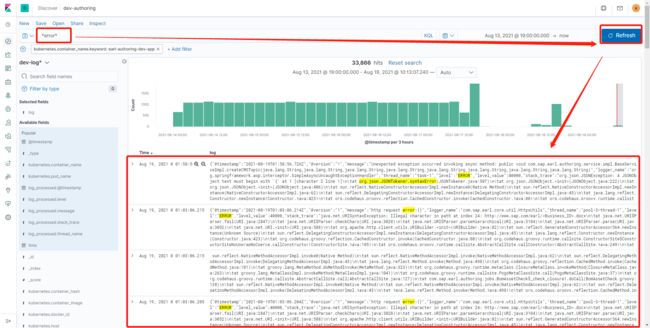
5 如何展开显示日志
- 连续点开两个箭头
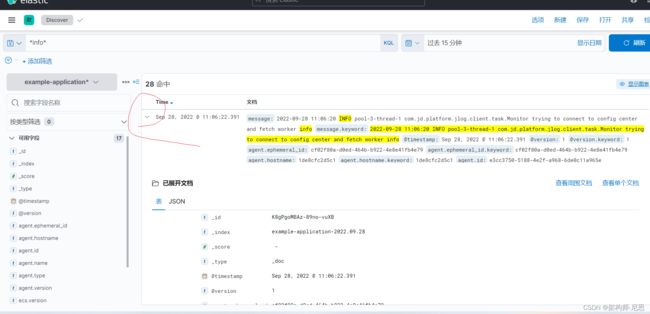
关于 本文的代码,和技术问题, 请来尼恩 发起的Java 高并发 疯狂创客圈 社群交流 ,
es的安全认证
通常搭建的elk默认是不需要身份认证,这样就会把数据暴露在外网,因此会显得非常危险。
下面我们介绍如何为es加入身份认证
es身份认证参考链接
切记,这里 修改es 配置文件和 启动es的二进制文件的时候 一定要用es系统用户不要用ubuntu或root用户操作。不然会报错。
配置了 安全认证后 logstash + filebeat +es +kibfana 都需要在配置文件中 加入 访问的账号密码来认证。
logstash 配置文件
elasticsearch {
hosts => ["ip:9200"]
user => elastic --加入es用户
password => xxxx --加入es密码
index => "test-%{+YYYY-MM-dd}"
timeout => 300
}
kibfana 配置文件
配置 Kibana 以使用内置 kibana 用户和您创建的密码
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://localhost:9200"]
kibana.index: ".kibana"
i18n.locale: "zh-CN" --配置 kibana 显示中文
elasticsearch.username: "kibana" --加入kibana 账户
elasticsearch.password: "123456" --加入kibana 账户的密码
配置 elk的ElastAlert 预警插件
我们都知道 elk架构 是收集与分析 集群的日志 方便开发排错
但是 预警功能是缺一不可的,如果开发人员不能及时查看线上错误日式,这个时候 就需要我们的预警插件来实现实时推送告警。
ElastAlert : 是python开发一个插件因此需要配合python运行环境和python-pip 包管理工具,以及相关依赖包
1.安装相关依赖包
yum -y install openssl openssl-devel gcc gcc-c++ --centos系统安装方式
--ubuntu 安装方式
sudo apt-get install openssl --openssl依赖包
sudo apt-get install libssl-dev --openssl-devel 依赖包
sudo apt-get install build-essential --gcc 依赖包 注意:gcc和g++版本必须一致
sudo apt-get install g++ 7.4 --g++ 依赖包
g++ --version --查看版本
gcc --version
wget https://www.python.org/ftp/python/3.6.9/Python-3.6.9.tgz --下载二进制python源码
2.安装python运行环境
tar xf Python-3.6.9.tgz
cd Python-3.6.9./configure --prefix=/usr/local/python --with-openssl
make && make install --编译源码
配置
mv /usr/bin/python /usr/bin/python_old //把ubuntu自带的python2.7环境移出到另外一个文件夹
ln -s /usr/local/python/bin/python3 /usr/bin/python //建立python软链接
ln -s /usr/local/python/bin/pip3 /usr/bin/pip //建立pip软链接
pip install --upgrade pip //此处没有安装pip的需要去安装pip
sudo apt install python3-pip //安装pip3.0版本 对应了python 3.6.9版本
//此处我没有动ubuntu自带的python2.7版本的 因此我们使用新的python使用3.6.9时,按以下方式使用:
python3.6 --version
python2.7 --version
pip3 --version
//使用python和pip命令时 都改为 python3.6与pip3
到此python环境配置完成
3.安装elastalert
下载源码
git clone https://github.com/Yelp/elastalert.git //下载 源码
cd elastalert
pip3 install "elasticsearch<8,>7"
//因为我们的es是7.4.0,所以这里选用的版本是这个
pip3 install -r requirements.txt 用pip安装依赖
安装成功时候 /usr/local/python/bin/目录下会有四个文件
ls /usr/local/python/bin/elastalert* 或者这个目录下
ls /usr/local/bin/elastalert*

ln -s /usr/local/python/bin/elastalert* /usr/bin //建立软链接把这四个命令链接到bin目录下
4. 配置ElastAlert
配置config.yaml 文件 (创建)
cp config.yaml.example config.yaml
sudo vi config.yaml
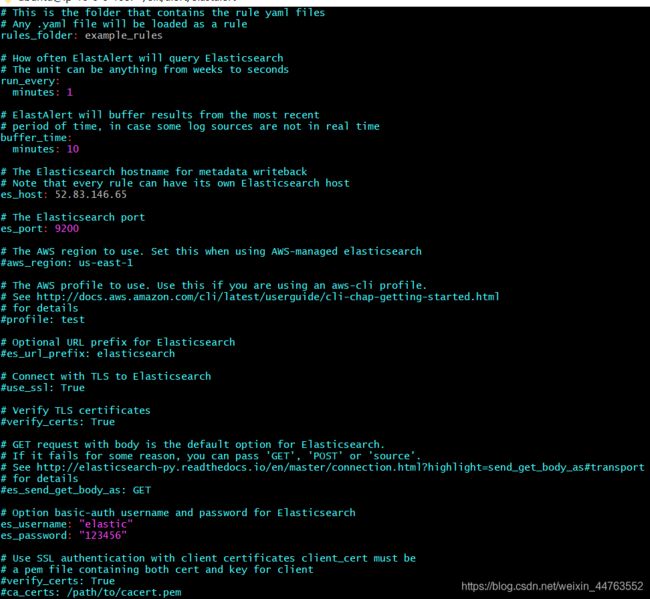
rules_folder:ElastAlert从中加载规则配置文件的位置。它将尝试加载文件夹中的每个.yaml文件。
没有任何有效规则,ElastAlert将无法启动。
run_every: ElastAlert多久查询一次Elasticsearch的时间。
buffer_time:查询窗口的大小,从运行每个查询的时间开始向后延伸。对于其中use_count_query或use_terms_query设置为true的规则,将忽略此值。
es_host:是Elasticsearch群集的地址,ElastAlert将在其中存储有关其状态,查询运行,警报和错误的数据。
es_port:es对应的端口。es_username: 可选的; 用于连接的basic-auth用户名es_host。
es_password: 可选的; 用于连接的basic-auth密码es_host。
es_send_get_body_as: 可选的; 方法查询Elasticsearch - GET,POST或source。
默认是GET writeback_index:ElastAlert将在其中存储数据的索引的名称。我们稍后将创建此索引。
alert_time_limit: 失败警报的重试窗口。
创建elastalert-create-index索引 告警索引
$ elastalert-create-index
New index name (Default elastalert_status)
Name of existing index to copy (Default None)
New index elastalert_status created
Done!
5.配置Rule 告警规则配置
所有的告警规则,通过在example_rules目下创建配置文件进行定义,这里简单创建一个来作为演示
name: Nginx_err //规则名称
use_strftine_index: true
index: 10.0.0.153-system_cro-2020.11.18 //监听查询es的索引
type: any //告警规则类型 有很多种 这种是 只要匹配到就触发告警
aggregation:
seconds: 1 //告警频率
filter:
- query:
query_string:
query: "status:500 or status:404" //触发报警的匹配条件 这里可以用kibana的语法去匹配
num_events: 1 //事件触发次数 的贬值
timeframe:
minutes: 1 //一分钟内超过 num_envents触发的次数 就触发告警
alert:
- "email" //告警类型 此处是email 例如钉钉 企业微信
email_format: html //email 正文格式
alert_subject: "正式环境Error告警" //告警正文标题
alert_text_type: alert_text_only //正文类型
alert_text: "
告警详情
@timestamp: {} @version: {} _id: {} _index: {} ip: {} request: {} status: {} method: {} bytes: {} source: {} client_ip: {} httpversion: {}
" //正文内容
alert_text_args:
- "@timestamp" //使用的是python的format格式动态填充数据
- "@version" //这些是属性值 按顺序对饮正文内容里面的 {}
- _id
- _index
- host.name
- request
- status
- method
- bytes
- message
- remote_ip
- httpversion
email:
- "[email protected]" //收件人 多个请依次往下填写
- "[email protected]"
- "[email protected]"
smtp_host: smtp.mxhichina.com //邮件服务器
smtp_port: 25 //邮件端口
smtp_auth_file: /home/ubuntu/elk/alert/elastalert/smtp_auth_file.yaml //此处新建了一个文件是 发件人的认证文件 存放发件人账户和密码或授权码
from_addr: haoyacong@gimmake.com //发件人
email_reply_to: haoyacong@gimmake.com //收件人标头
运行ElastAlert
cd ElastAlert //ElastAlert 的安装目录
python3.6 -m elastalert.elastalert --verbose --config config.yaml --rule ./example_rules/nginx_404.yaml //指定告警规则文件
nohup python3.6 -m elastalert.elastalert --verbose --config config.yaml --rule ./example_rules/nginx_404.yaml & //在后台运行
//如果运行多个告警规则执行多个上面的命令 如果执行example_rules下的全部规则文件 使用以下命令:
nohup python3.6 -m elastalert.elastalert --verbose --config config.yaml &
参考文献
- 疯狂创客圈 JAVA 高并发 总目录
https://www.cnblogs.com/crazymakercircle/p/9904544.html
ThreadLocal(史上最全)
https://www.cnblogs.com/crazymakercircle/p/14491965.html - 3000页《尼恩 Java 面试宝典 》的 35个面试专题 :
https://www.cnblogs.com/crazymakercircle/p/13917138.html - 价值10W的架构师知识图谱
https://www.processon.com/view/link/60fb9421637689719d246739
4、架构师哲学
https://www.processon.com/view/link/616f801963768961e9d9aec8
5、尼恩 3高架构知识宇宙
https://www.processon.com/view/link/635097d2e0b34d40be778ab4
https://gitee.com/bison-fork/loki/blob/v2.2.1/production/docker-compose.yaml
SkyWalking官网 http://skywalking.apache.org/zh/
SkyWalking的docker github地址 https://github.com/apache/sky…
elasticsearch https://www.elastic.co/guide/…
skywalking中文文档 https://skyapm.github.io/docu…
agent config https://github.com/apache/sky…
skywalking和其它agent一起使用的处理
https://zhuanlan.zhihu.com/p/163809795
https://www.cnblogs.com/you-men/p/14900249.html
https://cloud.tencent.com/developer/article/1684909
https://www.cnblogs.com/javaadu/p/11742605.html
https://www.jianshu.com/p/2fa99bd1997e
https://blog.csdn.net/weixin_42073629/article/details/106775584
https://www.cnblogs.com/kebibuluan/p/14466285.html
https://blog.csdn.net/weixin_42073629/article/details/106775584
https://blog.csdn.net/Jerry_wo/article/details/107937902
https://www.cnblogs.com/wzxmt/p/11031110.html
https://blog.csdn.net/zhangshng/article/details/104558016
https://blog.csdn.net/yurun_house/article/details/109025588
https://blog.csdn.net/weixin_40228200/article/details/123930498
https://blog.csdn.net/lanxing_huangyao/article/details/119795303
https://www.codenong.com/pzlong372468585/