elasticsearch简单使用和ELK的集成
准备
elasticsearch 介绍: 基于Lucene开发的搜索服务器,它提供了一个多用户的分布式搜索引擎,基于restful web 接口调用,并且是我们Java语言开发,安装简单,使用稳定,高效快随;即支持多语言的使用;市面上目前大部分的搜索功能都在使用它;
elasticsearch 安装
我这里的elasticsearch 7.6.1这个版本;由于es在启动的时候不能使用root的权限来启动所以在安装前我们必须要创建一个用户来启动es使用;不要想为什么官方就这么说的
#创建一个es的用户组
groupadd es
# 创建一个用户
useradd whj
passwd whj
#创建一个文件夹在/usr/local/es
mkdir ‐p /usr/local/es
# 把刚创建的用户添加到es用户组中
usermod -G es whj
# 设置权限
chown -R whj /usr/local/es
#添加用户权限
visudo # 打开文件在root ALL=(ALL) ALL 下面一行添加 whj ALL=(ALL) ALL
#保存后切换用户到whj
su whj
# 把准备好的elasticsearch-7.6.1压缩包放在/usr/local/ 目录下
# 进入local 目录下
tar -zxvf elasticsearch-7.6.1.tar.gz -C /usr/local/es
#解压完成后创建两个文档用来存放日志和数据
mkdir -p /usr/local/es/elasticsearch-7.6.1/log
mkdir -p /usr/local/es/elasticsearch-7.6.1/data
# 进入程序目录下
cd /usr/local/es/elasticsearch-7.6.1/config
# 删除原来的elasticsearh.yml配置文件
rm -rf elasticsearh.yml
#从新配置
vim elasticsearh.yml
cluster.name:whj‐es
node.name: node1
path.data: /usr/local/es/elasticsearch‐7.6.1/data
path.logs: /usr/local/es/elasticsearch‐7.6.1/log
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["服务器IP"]
cluster.initial_master_nodes: ["节点名"]
bootstrap.system_call_filter: false
bootstrap.memory_lock: false
http.cors.enabled: true
http.cors.allow‐origin: "*"
# 配置完后保存并退出
#在config 这个目录下jvm.options 这个是个运行时使用的内存配置自行根据服务器大小来修改
到这基本安装完成了,但是一般还会又有错,我这里列举我最常见的错误
错误信息描述:
max virtual memory areas vm.max_map_count [65530] likely too low,
increase to at least [262144]
调大系统的虚拟内存
原因:最大虚拟内存太小
vi /etc/sysctl.conf
#追加以下内容:vm.max_map_count=262144 保存后,执行:sysctl ‐p
启动es 服务
nohup /usr/local/es/elasticsearch‐7.6.1/bin/elasticsearch &
启动完成后使用http://ip:9200/?pretty来验证是否安装成功,看到如下就是成功

Kibana 安装
kibana 是什么?他是elasticsearch 图形化的方式,类似于mysql的Navicat Premium可视化工具,用来书写es的语句;在使用kibana客户端的时候需要注意他的版本要和elasticsearch保持一致
#把准备好的kibana-linux-7.6.1.tar.gz 放在/usr/local 下
# 进入文件夹
cd /usr/local
# 解压kibana
tar -zvxf kibana-linux-7.6.1.tar.gz -C /usr/local/es
# 解压完成后进入kibana 软件目录下
cd es/kibana/config
# 修改配置文件
vim kibana.yml
server.port: 5601
server.host: "服务器IP"
elasticsearch.hosts: ["http://IP:9200"]
# 保存并退出后进入bin目录下启动
nohup /usr/local/es/kibana-7.6.1/bin/kibana &
启动完成后在浏览器输入http://IP:5601 得到如下就是成功

IK分词器安装
我们后续也需要使用Elasticsearch来进行中文分词,所以需要单独给Elasticsearch
安装IK分词器插件。以下为具体安装步骤:
1.下载Elasticsearch IK分词器
https://github.com/medcl/elasticsearch-analysis-ik/releases
2 .并在es的安装目录下/plugins创建ik
mkdir ‐p /usr/local/es/elasticsearch‐7.6.1/plugins/ik
3 将下载的ik分词器上传并解压到该目录
cd /usr/local/es/elasticsearch‐7.6.1/plugins/ik
unzip elasticsearch‐analysis‐ik‐7.6.1.zip
4 重启Elasticsearch
Kibana 语句
如何创建一个文本
创建文本总体有两种,一种是动态映射(根据插入的数据自动分配映射),另一种就是静态映射(提前设置文本映射);
第一种创建一个动态映射的文本
//创建一个test的文本
PUT /test
在创建静态映射之前先了解下映射的数据类型; 字符类型:text,keyword(这个类型不会分词); 数字类型:integer,long,byte,short,double,float; 日期类型:date ;布尔型:boolean
创建一个静态映射单个字段指定分词器
//创建一个users的文本并且指定映射,并且给skill和address 指定分词器,如果不指定就是用默认分词器;
//修改默认分词器为ik
PUT /users
{
"mappings": {
"properties": {
"id":{"index": true,"type": "long"},
"name":{"type": "keyword"},
"age":{"type": "integer"},
"sex":{"type": "keyword"},
"birthday":{"type": "date"},
"skill":{"type": "text","analyzer": "ik_max_word"},
"address":{"type": "text","analyzer": "ik_smart"},
"pay":{"type": "double"}
}
},
"settings": {
"analysis": {
"analyzer": {
"default":{
"type":"ik_smart"
}
}
}
}
}
在查询的时候指定分词类型
根据上面创建的文档映射修改指定根据某个字段查询时候的分词器;
// 指定当使用skill或address 检索文档的时候我们会使用我们指定分词器来搜索;这个我后面会详细的讲下
PUT /users
{
"mappings": {
"properties": {
"id":{"index": true,"type": "long"},
"name":{"type": "keyword"},
"age":{"type": "integer"},
"sex":{"type": "keyword"},
"birthday":{"type": "date"},
"skill":{"type": "text","analyzer": "ik_max_word","search_analyzer": "ik_max_word"},
"address":{"type": "text","analyzer": "ik_smart","search_analyzer": "ik_smart"},
"pay":{"type": "double"}
}
},
"settings": {
"analysis": {
"analyzer": {
"default":{
"type":"ik_smart"
}
}
}
}
}
那么当我不想要这个文档的时候可以使用以下语句删除
// 删除users 这个文档
DELETE /users
当我创建好一个静态映射文档我们怎么去修改它,如果没有数据一般我们直接删除从建;当我们有数据那么就需要如下:
就以上面的为例:我先创建了一个users 并且有数据,现在要给它加上字段搜索时的分词
1).首先创建一个文档(userss)
2).将需要修改的文档(users)数据迁移到刚创建的文档中(userss)
3).删除原文档(users)
4).给迁移好的文档重新改个别名为原文档名(users )
//创建这里就省略了从第二步开始
//迁移数据从users 迁移到userss
POST _reindex
{
"source": {
"index": "users"
},
"dest": {
"index": "userss"
}
}
//删除原文档
DELETE /users
//修改userss 文档别名为users 修改后即可根据userss检索也可以根据users 检索
PUT /userss/_alias/users
这样就可以完成一个文档的修改;
RESTFUL 方式操作语句和简单得添加
1.添加数据
POST /userss/_doc/2
{
"id": 2,
"name": "段誉",
"age": 21,
"sex": "男",
"birthday": "2021-03-01",
"skill": "凌波微步,六脉圣剑,无相功",
"address": "云南大理北京路199号",
"pay": 50000
}
2.删除文档某条数据
DELETE /users/_doc/2
3.查询数据
//查询所有默认查询十条
GET /users/_search
//根据id查询
GET /users/_doc/1
//条件查询根据name
GET /users/_search?q=name:"段誉"
// 区间查询age[21,22]
GET /users/_search?q=age:[21 TO 22]
//age大于21的数据
GET /users/_search?q=age:>21
//分页查询
GET /users/_search?from=1&size=1
//指定显示的文本数据的字段
GET /users/_search?_source=id,name
//根据id排序降序
GET /users/_search?sort=id:desc
批量操作
批量插入数据
请求方式:post
请求地址: _bulk
//插入数据当文本中存在同样id数据的时候插入数据就会报错
POST _bulk
{"create":{"_index":"users","_id":1}}
{"id":1,"name":"乔峰","age":22,"sex":"男","birthday":"2020-01-01","skill":"打狗棍,降龙十八掌,狮吼功","address":"苏州市吴江区恭喜路100号","pay":20000}
{"create":{"_index":"users","_id":2}}
{"id": 2,"name": "段誉","age": 21,"sex": "男","birthday": "2021-03-01","skill": "凌波微步,六脉圣剑,无相功","address": "云南大理北京路199号","pay": 50000}
//插入数据当文本中存在同样id数据的时候就会全文本替换当前id的数据
POST _bulk
{"index":{"_index":"users","_id":1}}
{"id":1,"name":"乔峰","age":22,"sex":"男","birthday":"2020-01-01","skill":"打狗棍,降龙十八掌,狮吼功","address":"苏州市吴江区恭喜路100号","pay":20000}
{"index":{"_index":"users","_id":2}}
{"id": 2,"name": "段誉","age": 21,"sex": "男","birthday": "2021-03-01","skill": "凌波微步,六脉圣剑,无相功","address": "云南大理北京路199号","pay": 50000}
//批量修改数据
POST _bulk
{"update":{"_index":"users","_id":1}}
{"doc":{"age":24}}
{"update":{"_index":"users","_id":2}}
{"doc":{"pay":60000}}
//批量删除
POST _bulk
{"delete":{"_index":"users","_id":1}}
{"delete":{"_index":"users","_id":2}}
批量查询文档
1.请求方式:GET
请求地址:_mget
请求参数: docs 参数数组
_index,_source,_id
//
GET _mget
{
"docs":[
{
"_index":"users",
"_id":1,
"_source":["id","name","address"]
},
{
"_index":"account_index",
"_id":1
}
]
}
2.请求方式: GET
请求地址:/users/_mget (由于指定了文档名所以不能多文档查询)
请求参数: docs 数组参数
_id,_source
GET /users/_mget
{
"docs":[
{
"_id":1,
"_source":["name","age"]
}
]
}
批量查询组合我这里就介绍两种
DSL 查询语句
基础查询
1.无条件查询
GET /users/_search
{
"query": {"match_all": {}}
}
2.有条件查询 且只能是单一条件
1). match 模糊查询。条件会被分词
//这个模糊查询跟我们想的有些不一样通常我们的mysql模糊查询是根据我们查询值"%大狗架%",但是我们的es会先分词可能会出现"%大狗%","%架%"等只要有一个分词匹配就会被检索;
GET /userss/_search
{
"query": {
"match": {
"skill": "打狗架"
}
}
}
// 两个词语查询 如果使用的是and 则是都需要满足,如果or 则只需要满足一个
GET /users/_search
{
"query": {
"match": {
"skill": {
"query": "打狗 凌波",
"operator": "or" //and
}
}
}
//还有种百分比的但是这种不准确
GET /users/_search
{
"query": {
"match": {
"skill": {
"query": "大狗 凌波",
"minimum_should_match": "68%"
}
}
}
}
2).前缀搜索 ——prefix
//查询前缀为打的数据
GET /users/_search
{
"query": {
"prefix": {
"skill": {
"value": "打"
}
}
}
}
3).正则表达式查询——这个用的少,我没怎么用过自行去查
4).精确查询(使用的查询不被分词作为整体查询数据)——trem
GET /users/_search
{
"query": {
"term": {
"name": {
"value": "乔峰"
}
}
}
}
5).trems 查询
//同一字段包含多个值
GET /users/_search
{
"query": {
"terms": {
"skill": [
"打狗棍",
"降龙十八掌"
]
}
}
}
6).查询包某个字段的所有数据 exists
//查询包含字段name的数据
GET /users/_search
{
"query": {
"exists": {
"field": "name"
}
}
}
7).区间查询 range
//查询年纪区间在[10,20]
GET /users/_search
{
"query": {
"range": {
"age": {
"gte": 10,
"lte": 20
}
}
}
}
8).根据id查询 ids
// 根据id集合查询
GET /users/_search
{
"query": {
"ids": {
"values": [1,2]
}
}
}
组合查询(多条)
组合查询的叶子节点就是上面的基础查询的语句
bool节点下:must,should,must_not,filter
1).must 下面的叶子节点都需要满足
//当名字为段誉性别为男的数据会被检索出来
GET /users/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "段誉"
}
},{
"term": {
"sex": {
"value": "男"
}
}
}
]
}
}
}
2).should 下面的叶子节点不需要都满足,只要满足一条就会被检索
// 这个查询就是name可以是"段誉" 或者"乔峰"
GET /users/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"name": "段誉"
}
},
{
"match": {
"name": "乔峰"
}
}
]
}
}
}
**3).filter 过滤器查询,他查询的结果不会被评分 **
GET /users/_search
{
"query": {
"bool": {
"filter": {
"term": {
"name": "乔峰"
}
}
}
}
}
4).must_not 不包含条件的数据
// 被检索的数据name 值不能为"乔峰"且age 值不能为 21
GET /users/_search
{
"query": {
"bool": {
"must_not": [
{"match": {
"name": "乔峰"
}},
{
"match": {
"age": 21
}
}
]
}
}
}
总结: 使用组合查询bool节点下的各个子节点的叶子节点都有我们的基础查询节点组成,而且我们bool 节点下子节点可以是多个不同子节点组成;组合查询的must 和should 子节点的效率要比 fliter 和 must_not 低那是因为他们在查询的时候不对结果进行分数计算,还有如果使用这两个关键字查询的数据出现的次数多,会对数据缓存那么效率就更高了;
在查询语句中使用filter和must_not 就会被称为filter DSL 语句,使用must和should 则是queryDSL ;上面也提到了filter DSL 的语句比较高效;
检索的案例
1.指定匹配度来检索数据;
// 百分比命中—— 这个命中不是绝对的百分比
GET /users/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"skill": {
"query": "凌波微步2",
"minimum_should_match": "100%"
}
}
}
]
}
}
}
// 指定命中数
GET /users/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"skill": {
"query": "凌波微步",
"minimum_should_match": 3
}
}
}
]
}
}
}
从上述的语句当中可以看到关键词minimum_should_match参数可以是百分比或者是正整数;当是百分比的时候就是query的值分词后和元数据得分词命中在query 字段中占得百分比(根据上述得语句查询分词会把上面分成,“凌波”,“微”,“步”,“2”;当我们设置100%时则是全部命中,但设置为75%是正好相乘为整数则是命中3个分词,那么设置为75%到100%之间不包括百分之百都是命中3个分词);还有一种就是设置正整数那么就简单了设置几就是命中几个;
2.使用 bool+should 来指定检索的精准度
// 查询当中命中4个
GET /users/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"skill": "凌波"
}
},
{
"match": {
"skill": "微"
}
},{
"match": {
"skill": "步"
}
},{
"match": {
"skill": "我"
}
},{
"match": {
"skill": "ni"
}
}
],
"minimum_should_match": 4
}
}
}
从上述我们可以看到这两种方式都可以完成我们精准指定但是一般使用第二种方式效率高;
3.权重检索(满足权重优先排序)
// 查询name包含段誉或者skill包含打狗棍
GET /users/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"name":{
"query": "段誉",
"boost": 1
}
}
},
{
"match": {
"skill": {
"query": "打狗棍",
"boost": 3
}
}
}
]
}
}
}
查询同时包含这两个的数据优先显示然后是包含打狗棍的数据在是只包含 段誉的数据;权重计算:检索es会自动检查关联度算出一个分数_source 然后在乘以设置的权重数;得到一个新的分数,再根据分数排名所以一般情况下权重越大那么就越有可能被先检索;
4.dis_max 搜索使用的是best fields 策略
best fields 策略:检索文档的一个filed时,尽可能的匹配搜索条件;与之相反的就是most fields 策略当我们使用bool+should 或者must+should 都是使用的most fields 策略检索;most fields 搜索条件尽可能的匹配多个filed;
most fields优点:通过精确检索的数据会尽可能的排序在前面,我们通过minimum_should_match 的设置来去掉长尾的数据对检索排序的影响
most fields缺点: 排序不均匀,为什么会出现排序不均呢?检索的时候出现多条件检索,但是我们想使用其中某条条件进行分数排序,但是由于我们不能控制每条数据条件的分数所以可能排在前面的不是准确的数据 ,但是我们可以根据dis_max的搜索排序
// 检索满足address 或者 skill 字段,当两个条件都满足的时候根据最大的分数排序,而不会将二者分数相加
GET /users/_search
{
"query": {
"dis_max": {
"queries": [
{
"match": {
"address": "云南大理"
}
},
{
"match": {
"skill": "凌波微步"
}
}
]
}
}
}
//上面的搜索是只根据最大的分数列排序,下面是根据最大的分数列加上其他列分数的70%相加后排序
GET /users/_search
{
"query": {
"dis_max": {
"tie_breaker": 0.7,
"queries": [
{
"match": {
"address": "云南大理"
}
}
,
{
"match": {
"skill": "凌波微步"
}
}
]
}
}
}
总结: 上述两种查询方式第一种方式如果两个条件都满足,只根据评分最高的条件排序,忽略其他的条件;第二种方式如果两个条件都满足最高的分数加上其他条件分数的百分之70% 在进行排序;
上面通过这个dis_max 检索讲了两种检索策略;其实还有一种策略叫做cross fields 策略;但是在介绍这个策略之前先了解下 multi_match 检索;
5.multi_match检索
// 检索使用best_fields策略条件为"河南打狗棍法"被分词后 只要address 和 skill列的原始值分词命中一个词就会被检索出来且address 权重为3
GET /users/_search
{
"query": {
"multi_match": {
"query": "河南打狗棍法",
"fields": ["address^3","skill"],
"type": "best_fields",
"minimum_should_match": 1
}
}
}
cross fields 检索策略
这种搜索策略是跟我们most fields 的检索方式一样尽可能的匹配多字段,而计算分数排序的方式有何best fields 一致;使用这种搜索的缺点就是没有办法去掉长尾数据;所以一般商业上使用best fields 检索策略
// 下面就是是用来cross fields
GET /users/_search
{
"query": {
"multi_match": {
"query": "苏州市",
"fields": ["address","skill"],
"type": "cross_fields",
"operator": "and"
}
}
}
总结: 上面总结了三种检索的策略都有各自的问题most fields 排序不均,best fields 尽可能的匹配单个字段,而cross fields 没办法去掉长尾数据;那有有什么办法解决这种问题? 其实有的在数据建模的时候会讲一个关键字 “copy_to” 这个可以解决问题,但是原则还是best fields策略
6. match_phrase 短语搜索
固定的短语不可拆分类似于trem关键字的检索
//文档里的原数据是"江苏省苏州市姑苏区馆前路001号",但是由于条件是"江苏省姑苏区"这个不会被检索
GET /users/_search
{
"query": {
"match_phrase": {
"address": {
"query": "江苏省姑苏区"
}
}
}
}
总结通过上面的查询方式我们的江苏省姑苏区是不可以被拆分的;也就是当我们的分词器对这个词进行分词的时候他们的数据下标是紧挨的如下:
从上面的图看到position这个字段这个就是被分词后的下标也表示短语中的词所在的位置;当使用短语检索的时,会根据分词后的结果检索到数据在根据下标来判断短语的位置,如果位置相邻就是匹配成功,位置不相邻就不会被检索注意:这里的相邻并不是指下标一样,只是指在这个分词里下标连续,在原数据里下标也连续;且分词匹配的数据
那么当的原数据分词不连续但是数据里包含了,条件短语怎么办?可以使用slop如下:
//文档里的原数据是"江苏省苏州市姑苏区馆前路001号",但是由于条件是"江苏省姑苏区"上面的方式不会被检索下面则会被检索
GET /users/_search
{
"query": {
"match_phrase": {
"address": {
"query": "江苏省姑苏区",
"slop": 5
}
}
}
}
总结: 为啥会被检索到?原数据通过默认分词器假设如下
| 江 | 苏 | 省 | 苏 | 州 | 市 | 姑 | 苏 | 区 | 馆 | 前 | 路 | 001 | 号 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 那么怎么匹配它通过移动达到"江苏省姑苏区" 那么姑会向前移动3个单位苏也移动3个单位没有超过设置的5 则就会匹配上面的数据 | |||||||||||||
| 推荐搜索——这个百度框的搜索当输入值的时候会有提示的搜索 |
GET /users/_search
{
"query": {
"match_phrase_prefix": {
"address": {
"query": "江苏省苏",
"slop": 5,
"max_expansions": 10
}
}
}
}
其原理和match phrase类似,是先使用match匹配term数据(江苏省),然后在指定的slop移动次数范围内,前缀匹配(苏),max_expansions是用于指定prefix 最多匹配多少个term(单词),超过这个数量就不再匹配了。这种语法的限制是,只有最后一个term会执行前缀搜索。执行性能很差,毕竟最后一个term是需要扫描所有符合slop要求的倒排索引的term。因为效率较低,如果必须使用,则一定要使用参数max_expansions。
7.fuzzy模糊搜技术
这种技术在英文的搜索中很有效果但是在中文中基本没有效果,其实也能想的出来,在计算机中不可能写错字,只可能是别字所以没有效果;而这种技术最好的使用方式就是hello写成了hallo也会检索出hello。看如下
//name 为字段 fuzziness 的值表示可以错几个,或者减少几个
GET /users/_search
{
"query": {
"fuzzy": {
"name": {
"query":"hallo",
"fuzziness": 2
}
}
}
}
8.高亮查询检索
我们有些业务场景需要把检索的条件,在检索后的数据中用其他的颜色体现出来;这时候就需要使用检索高亮来对原数据中的数据进行标签,以便于前端高亮
//对"江苏省"高亮 highlight 里fields 对应数据列 默认使用标识
GET /users/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"address": "江苏省"
}
}
]
}
},
"highlight": {
"fields": {
"address": {}
}
}
}
检索后如下:

高亮自定义标签,最高的显示数和高亮词组数
// 指定高亮的标签的前半部分“pre_tags” 后半部分“post_tags” 指定高亮的字段的数据显示数“fragment_size” ,指定需要高亮几个片段“number_of_fragments”
GET /users/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"address": "江苏省"
}
}
]
}
},
"highlight": {
"pre_tags": [""],
"post_tags": [""],
"fields": {
"address": {
"fragment_size": 100,
"number_of_fragments": 1
}
}
}
}
还有一种如果只要知道就行如果遇到了自行百度下就是设置高亮的检索方式;一般默认的就够用了,但是由于可能某个字段非常的大所以可能需要在数据建模的时候考虑到设置高亮的属性这个我会在数据建模中说到
9. 聚合检索
聚合检索当我们需要有统计,分组的数据检索的时候使用;
1).准备聚合搜索的数据如下:
// 创建一个文档 不了解怎么创建文档请看上面
PUT /phone
{
"mappings": {
"properties": {
"phone_name":{"type": "text"},
"brand":{"type": "keyword"},
"price":{"type": "double"},
"sales":{"type": "integer"},
"size":{"type": "text"},
"timedate":{"type": "date"}
}
}
}
//向文本库中添加数据
POST _bulk
{"index":{"_index":"phone","_id":1}}
{"phone_name":"华为p10","brand":"华为","price":999.00,"sales":20000,"timedate":"2015-01-01"}
{"index":{"_index":"phone","_id":2}}
{"phone_name":"华为p20","brand":"华为","price":8999.00,"sales":200000,"timedate":"2019-10-01"}
{"index":{"_index":"phone","_id":3}}
{"phone_name":"荣耀","brand":"华为","price":1999.00,"sales":15000,"timedate":"2018-10-01"}
{"index":{"_index":"phone","_id":4}}
{"phone_name":"小米6","brand":"小米","price":1999.00,"sales":10009,"timedate":"2016-05-20"}
{"index":{"_index":"phone","_id":5}}
{"phone_name":"小米8","brand":"小米","price":1999.00,"sales":99999,"timedate":"2018-09-10"}
{"index":{"_index":"phone","_id":6}}
{"phone_name":"iphone 11","brand":"苹果","price":5999.00,"sales":9888,"timedate":"2019-08-11"}
{"index":{"_index":"phone","_id":7}}
{"phone_name":"iphone 12","brand":"苹果","price":6299.00,"sales":300000,"timedate":"2020-10-01"}
{"index":{"_index":"phone","_id":8}}
{"phone_name":"iPhone 13","brand":"苹果","price":7499.00,"sales":100000,"timedate":"2021-06-24"}
{"index":{"_index":"phone","_id":9}}
{"phone_name":"5230","brand":"诺基亚","price":1699.00,"sales":9999,"timedate":"2010-04-24"}
{"index":{"_index":"phone","_id":10}}
{"phone_name":"N95","brand":"诺基亚","price":3999.00,"sales":1000,"timedate":"2011-08-24"}
{"index":{"_index":"phone","_id":11}}
{"phone_name":"坚果R2","brand":"坚果","price":1299.00,"sales":99,"timedate":"2014-03-10"}
1).根据品牌统计销售的数量
// 根据brand 这个字段进行分组后计算price 的和;
GET /phone/_search
{
"aggs": {
"group_by_brand": {
"terms": {
"field": "brand"
},
"aggs": {
"sum_by_brand": {
"sum": {
"field": "price"
}
}
}
}
}
}
总结: group_by_brand ,sum_by_brand 字段是自定义字段;trems 所分组的字段必须是keword 或者是设置一个属性(自行查阅官方我一般直接keyword);aggs 里还可以嵌套aggs如上;
2).在1的基础上加上分组后的平均价格,最大值,最小值,不显示文档数据只返回聚合数据
// 根据brand进行分组然后根据price 计算分组中price 的和,最大值,平均值,最小值等
GET /phone/_search
{
"aggs": {
"group_by_brand": {
"terms": {
"field": "brand",
"size": 0
},
"aggs": {
"sum_by_brand": {
"sum": {
"field": "price"
}
},
"avg_by_brand":{
"avg": {
"field": "price"
}
},
"max_by_price":{
"max": {
"field": "price"
}
},
"min_by_price":{
"min": {
"field": "price"
}
}
}
}
}
}
总结: 上语句中 group_by_brand, sum_by_brand, avg_by_brand, max_by_price, min_by_price;这个五个字段都是自定义字段,相当于聚合名;size 显示聚合分组数据条数,terms 根据字段分组, max 算出某个字段的最大值,min 计算莫格字段的最小值 …一下雷同
3). 分组后的数据进行排序
//根据brand 分组,对分组后的数据根据price 字段升序,分组每个分组最多显示十个数据
GET /phone/_search
{
"size": 0,
"aggs": {
"group_by_brand": {
"terms": {
"field": "brand"
},
"aggs":{
"top_phone":{
"top_hits": {
"size": 10,
"sort": [
{"price": {
"order": "desc"
}}
]
}
}
}
}
}
}
总结: group_by_brand,to_phone 为聚合名,group_by_brand 分组聚合,分组下top_phone 重排序 top 里的size 为聚合后显示数,最外面的size 为检索的原数据条数;
然后还有 query+aggs 组合使用 filter +aggs 组合使用等;还可以在聚合aggs 下使用filter 如下
//filter 放在aggs 外使用是对所有的数据进行过滤,放在里面则是对query的结果进行的过滤
GET /phone/_search
{ "query": {
"match": {
"brand": "华为"
}
},
"aggs": {
"name": {
"filter": {
"range": {
"price": {
"gte": 1999,
"lte": 19999
}
}
}
}
}
}
10.分页检索
分页检索分为两种一种是from size 如下
//从第一个数据开始每页显示两个数据
GET /phone/_search
{
"from": 0,
"size": 2
}
上面的这种方式检索就是每次去筛选,当筛选到合适的时候就返回,但是这种筛选随着数据的增加性能就会出现问题,当数据超过10000的时候就能感受出来,所以默认的es from和size的分页方式是不可以查询10000条以后的数据,可以通过设置来改变,设置如
PUT _settings
{
"index": {
"max_result_window": "10000000"
}
}
第二种就是通过scroll来检索当
//使用scroll请求第一次只需要指定过期时间和条数
GET /phone/_search?scroll=2m
{
"size": 2
}
//第二次检索的时候只需要指定scroll_id 并指定好过期时间 即可如下
GET /_search/scroll?scroll=2m
{
"scroll_id":"DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAMNbUWNTVXQ05rTktSSEswTEpTbVh3cVVwdw=="
}
这种方式可以处理大数据量的分页;我猜测的原理是这样的检索的第一次其实就把所有的值检索出来,并在size 的标识下设置一个标志位当第二次检索的时候会根据第一次设置的每页的显示大小向下进行标志位;如果一页一页的看这样消耗应该不会很大但如果跳跃式随机向页数查看那么就会在后台代码端进行循环,但是像循环上一页或者多页通过es 是没有办法的,对scroll_id的管理cpu的消耗也不会太小,所以看你的项要求,选择合适的scroll;个人认为在app 中使用scroll 翻滚没有跳页同时上一页的数据也是拼接但是网页端的分页我还是建议使用from+size;
检索数据的分数计算原理
通过上面的检索可以知道所有的检索除了使用filter 或者must_not 的方式检索出来的数据不包括score;其他的检索都有score 这个就是检索的相关度分数;
分数计算:ES 根据 TF /IDF 两种算法计算被检索的文档相关度
TF算法: 检索的词条在filed 中出现的越频繁那么说明相关度越高;例如
检索的词条: 你好
doc1: 你好! …; doc2: 你好… 你好…
那么根据TF 就算就是doc2相关度分数高
IDF :检索的词条在filed 中出现的越频繁就越不相关;假设词条 :你好啊 ;根据词条检索或进行分词成"你好",“啊”;
当文档中数据你好 啊这两个词条中间的数据间隔比较大,间隔越大越不相关;或者当这两个次出现的你好1000次而啊出现了10次那么越多也会越不相关;
计算分数还会根据向量来计算:假设检索的词条:“你好”;"你"这个词条假设评分是2,"好"评分为4;假设同时又三个文档数据满足一个只包含 你 那么分数就是(2,0);一个包含 好 同理分数就是(0,4)而包含 你好的就是 (2,4)由着这个就可以画成一个图那么弧度越高的说明相关度就越高;但是如果出现多个词条那么我们图就不能完成这时候就会使用线性代数方式去计算;
这个原理知道就好
数据建模
1.案例:一个用户文档里有一个地址数组
//创建一个文档
PUT /account_index
{
"mappings": {
"properties": {
"login_name":{"type": "keyword"},
"pass":{"type": "keyword"},
"address":{
"properties": {
"province":{"type":"keyword"},
"city":{"type":"keyword"},
"area":{"type":"keyword"}
}
}
}
}
}
//向文档中添加数据
POST _bulk
{"create":{"_index":"account_index","_id":1}}
{"login_name":"whj","pass":"123456","address":[{"province":"北京市","city":"北京市","area":"西城区"},{"province":"天津市","city":"天津市","area":"西城区"},{"province":"安徽省","city":"芜湖市","area":"鸠江区"}]}
{"create":{"_index":"account_index","_id":2}}
{"login_name":"henopu","pass":"3219227","address":[{"province":"江苏省","city":"苏州市","area":"工业园区"},{"province":"天津市","city":"天津市","area":"西城区"},{"province":"安徽省","city":"芜湖市","area":"鸠江区"}]}
{"create":{"_index":"account_index","_id":3}}
{"login_name":"1550990980","pass":"5771438","address":[{"province":"江苏省","city":"常州市","area":"园区"},{"province":"天津市","city":"天津市","area":"西城区"}]}
//查询方式如下:查询一个省市市北京,城市市天津的数据 这种查询方式后面又详细解释
GET /account_index/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"address.province": "北京市"
}
}, {
"match": {
"address.province": "天津市"
}
}
]
}
}
}
上面是最简单的一对多方式;但是上面的查询也暴露了一个问题就是当我们省市为北京,城市为天津实际应该是没有数据的但是由于查询的不准且性和因为address 为数组则导致这个可以查询出来,所以我们得使用另一种方式如下:
2. nested object 同一案例
//创建一个新的文档如下
PUT /new_account_index
{
"mappings": {
"properties": {
"login_name":{"type": "keyword"},
"pass":{"type": "keyword"},
"address":{
"type": "nested",
"properties": {
"province":{"type":"keyword"},
"city":{"type":"keyword"},
"area":{"type":"keyword"}
}
}
}
}
}
// 添加数据略...... 数据添加跟上面得数据一样
//搜索语句 这种查询语句后面有详细解释
GET /new_account_index/_search
{
"query": {
"bool": {
"must": [
{
"nested": {
"path": "address",
"query": {
"bool": {
"must": [
{
"match": {
"address.province": "北京市"
}
},
{
"match": {
"address.city": "天津市"
}
}
]
}
}
}
}
]
}
}
}
按照这个上面得方式建立得文档,查询时这个数据不能被查询到;
那么为什么上面得数据可以被查询到而下面得数据不能被查询到;那是因为第一种方式会把我们数据进行扁平化处理成如下情况:
[
{
"login_name":"whj",
"pass":"123456",
"address.province":["北京市","天津市","安徽省","江苏省"],
"address.city":["北京市","天津市","芜湖市","苏州市","常州市"],
"address.area":["西城区","鸠江区","工业园区","园区"]
}
]
所以第一种方式查询得时候就会出现数据不准确而我们得nested 方式不会扁平化数据所以数据查询准确,但是他有缺点就是当我们每次更新数据需要更新整个文档,维护成本高;所以也有方式解决这个问题就是父子文档
3.父子数据建模
父子数据建模跟数据库建模有点出入;数据库要完成父子数据得建立是建立两个表,根据某个字段关联完成,通过sql关联检索;但是在es 中一般不会建立两个文档去完成父子数据关系;在文档中有个特定得文档关系,在数据存储得时候都是独立存在得,通过关系得映射来映射父子关系如下:

//创建父子类文档
PUT /my_posts
{
"mappings": {
"properties": {
"commots_join_posts":{
"type": "join",
"relations":{
"posts":"commots"
}
},
"title":{"type": "text"},
"main_body":{"type": "text"}
}
}
}
// 添加父文档得数据;在设定得映射名中指定映射得值父类指定父类值
POST /my_posts/_doc/posts1
{
"title":"你好",
"main_body":"你好,是一个汉语词语,拼音是nǐ hǎo,是汉语中打招呼的敬语常用词语。作为一般对话的开场白。这也是个最基本的汉语词语。主要用于打招呼请教别人问题前的时候,或者单纯表示礼貌的时候等。",
"commots_join_posts":{
"name":"posts"
}
}
POST /my_posts/_doc/posts2
{
"title":"hello world",
"main_bod":"Hello World 中文意思是“你好,世界”。因为 The C Programming Language中使用它做为第一个演示程序,后来的程序员在学习编程或进行设备调试时延续了这一习惯。",
"commots_join_posts":{
"name":"posts"
}
}
//添加子类文档,相对添加父类文档添加,子类则需要考虑少量的条件;第一指定子类文档要与父类文档的分片一致且指定父类文档名;比如根据上述数据posts1 来指定子类文档如下: routing 指定父类文档id,name: 指定设置好的子类文档名,parent:指定父类文档ID
POST /my_posts/_doc/commots1?routing=posts1
{
"user_name":"whj",
"comment":"你好啊!",
"commots_join_posts":{
"name":"commots",
"parent":"posts1"
}
}
//指定posts2的子类文档
POST /my_posts/_doc/commots2?routing=posts2
{
"user_name":"hh",
"comment":"你好世界",
"commots_join_posts":{
"name":"commots",
"parent":"posts2"
}
}
总结: 创建文档可以包含父子数据中所有的字段,当父类使用一部分,子类使用一部分;我有在定义父子类关系的时候我上面的这种方式;当往文本库中插入数据的时候,父类在映射部分指定设置的父类文档映射名即可;而子类必须指定父类的映射id 和路由的父类id
父子建模的数据检索
1).检索子类
//根据父文档ID检索其对应的子类
GET /my_posts/_search
{
"query": {
"parent_id":{
"type":"commots",
"id":"posts2"
}
}
}
//根据父类查询子类
GET /my_posts/_search
{
"query": {
"has_parent": {
"parent_type": "posts",
"query": {
"match": {
"title": "hello world"
}
}
}
}
}
//根据子数据查询父文本数据
GET /my_posts/_search
{
"query": {
"has_child": {
"type": "commots",
"query": {
"match": {
"user_name": "hh"
}
}
}
}
}
// 根据父文档id查询子文档
GET /my_posts/_search
{
"query": {
"parent_id":{
"type":"commots",
"id":"posts2"
}
}
}
总结: 从es 的层面由上述三种方式完成父子类的数据模型第一种方式这里不总结弊端问题太明显了;一般我们都会去选择nested 和父子建模去完成,一对多的关系;不要问多对多的关系你自己想一下如果多对多会用什么为什么? nested 与 父子建模的对比,nested 结构简单容易学,数据存储一起读取性能高;但是父子建模可以单独更新文档;而nested每次更新文档的时候都需要整体更新,则需要个对立内存块更新;综上优缺点一般在以查为主情况下选择nested 反之则使用父子模式; 有人会有疑问那我使用Java代码单独处理这些问题可不可以速度会不会比这个快?肯定可以,但是速度未必比上述两种快;在开发中尽量的使用原子性不必要
分词器的使用
es 中为什么可以做到模糊检索都是大部分都是分词器的功劳,当输入一个条件的时,则会将条件进行分词,并与要进行检索的数据分词后进行对比,只要有命中就会返回;而这些条件和数据的分词使用的就是分词器;一般情况下使用两种,一种是用来处理英文并且是es内置的分词器,还有一种就是处理中文的分词器简称IK(安装教程上面有);
分词器分词对比
使用内置分词器standard
GET _analyze
{
"text": "hello world"
}
GET _analyze
{
"text": "你好世界"
}
通过上面的字段分词如下
| hello | world |
|---|
| 你 | 好 | 世 | 界 |
|---|---|---|---|
| 根据这个分词大概了解英文根据空格来分词,但是中文按照一个个生词分割;实际中可能需要生词;所以这时候默认的就完成不了,从而选择IK分词 | |||
| IK分词器 | |||
| ik有两种模式第一种ik_smart粗粒度的拆分,第二种ik_max_word细粒度拆分; |
自定义分词器
有的时候分词可能会有长句,但是想省略形容词连接词可能就需要自定义分词器;
默认使用standard 自定义
//自定义分词器
PUT /my_analyze
{
"settings": {
"analysis": {
"char_filter": {
"&_to_and":{
"type":"mapping",
"mappings":["&=> and","||=> or"]
}
},
"filter": {
"my_stopword":{
"type":"stop",
"stopword":["the","a"]
}
},
"analyzer": {
"my_analyzer":{
"type":"custom",
"char_filter":["&_to_and"],
"tokenizer":"standard",
"filter":["my_stopword"]
}
}
}
}
}
总结: char_filter 替换关键字或者是字符替换,filter:设置停用词;analyzer 组合定制自己的分词器;组合的种类太多只能告诉你有这么个东西在使用的时候可以去参照官方
IK 分词器的定制:首先找到配置文件目录在es的plugins目录下的 /ik/config下如图

配置文件extra 开头的文件可以先不用管按照顺序介绍下面的文档
1).IKAnalyzer.cfg.xml 这个文件是一个ik 的配置文件类似于上面自定义分词器的配置文件内容如下:
DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置comment>
<entry key="ext_dict">entry>
<entry key="ext_stopwords">entry>
properties>
2).main.dic: 原生的词库只要出现词库中的单词就不会被拆分
3).quantifier.dic: 单位相关的词库
4).stoppword.dic: 停用词词库,拆分的时候不会出现,直接省略
5).suffix.dic: 都是写地址比如省市县乡
6).surname.dic: 姓氏词库
ik分词器的热加载
IK 自定义词库创建一个词库比如最近的网络词汇yyds 等等 创建完的词库放在原生词库同目录下在xml文件中配置自定义的文件 按照逗号隔开然后重启es 即可每次添加都需要重启;
实际开发中不需要重启的我们可以使用远程的方式来解决这个问题,远程的方法还有个好处就是在集时只需要添加一次就可以完成;也是通过上面xml的配置完成
Beats
Beats:一个数据收发的组件库,它包括了AuditBeat(审计数据),FileBeat(日志文件),PacketBeat(网络流量数据)等,它们可以安装在服务器中,通过这些组件收到的日志数据并发送到Elasticsearch 或者LogStash 中,但在中小企业中最常用的就是FileBeat,所以我这里介绍FileBeat;
FileBeat 简介
FileBeat专门用于转发和收集日志数据的轻量级采集工具。它可以为作为代理安装在服务器上,FileBeat监视指定路径的日志文件,收集日志数据,并将收集到的日志转发到Elasticsearch或者Logstash。
FileBeat 原理
FileBeat 启动会启动一个或者多Input,每一个Input对应一个文件集合的监控地址,每一个文件都对应启动一个Harvester(收割机),Harvester 会监听每个文件的偏移量当文件发生改变的时候都会将数据发送到libbeat 中进行整合,整合后发送到Output 中,通过Output 发送到配置关联的第三方插件(Elasticsearch,LogStash或者MQ中)

安装FileBeat
FileBeat 下载一个压缩包,注意的时下载的版本需要和Elasticsearch的版本一致;由于本文档上办部分安装的版本都是7.6.1这里FileBeat 也安装7.6.1;压缩包下载地址https://www.elastic.co/cn/downloads/past-releases/filebeat-7-6-1
1.下载完成后将压缩包放入/usr/local/es 中并解压(这个目录是在安装es的时候创建的)
tar -zxvf /usr/local/es/filebeat-7.6.1-linux-x86_64.tar.gz -C /usr/local/es
2.解压完成后进入filebeat 查看下文件如下:

3.配置FileBeat
配置FileBeat分两个部分:Inputs,output; Inputs采集日志数据,Output输出日志数据;配置文件可以参考filebeat.reference.yml文件这里包含所有类的采集交互的配置
Inputs配置
filebeat.inputs:
‐ type: log
enabled: true
paths:
‐ /var/log/*.log
#‐ c:\programdata\elasticsearch\logs\*

output配置
#将日志文件发送到elasticsearch上
output.elasticsearch:
hosts: ["Ip1:9200","Ip2:9200","Ip3:9200"]
#将日志发送到logstash 上
output.logstash:
enable: true
hosts: ["ip:5044"]
接下来创建配置文件这里只配置发送到es上
# 进入filebeat文件夹下
cd filebeat-7.6.1-linux-x86_64
#创建一个配置文件
touch filebeat_log.yml
# 接下来就是配置,把上面的Inputs 和output 中es 配置放在创建的配置文件中
启动FileBeat
在启动之前首先要确保发送到的中间件已启
#启动FileBeat 并指定配置文件
./filebeat ‐c filebeat_log.yml ‐e
启动完成后,当监听的文档路劲中文档发生变化就会向es中添加数据
FileBeat 日志收集工具还可以去收集mysql 的错误日志,慢查询日志指定这种出了问题的日志,这样有助于我们分析和优化,这些FileBeat 都是可以操作的
LogStash
logstash: 数据采集工具;它和Beats 是不同的它可以通过设置表达式来筛选各种日志文件,而Beats只能通过设置对一种来进行采集,比如我们项目中使用log 日志 beats 只能将他们全部采集下来但是我们需要的是出问题或者特定的log 进行分析那么FileBeat他是做不到的,但是FileBeat 可以去筛选特定的日志比如mysql的这种就是特定的日志他不会发生变化的;而且FileBeat 是只能采取日志文件,但是Logstash是可以采取mq,mysql,nosql 的数据的;所以综上logstash 的功能要比Beats强大,很少直接使用logstash;
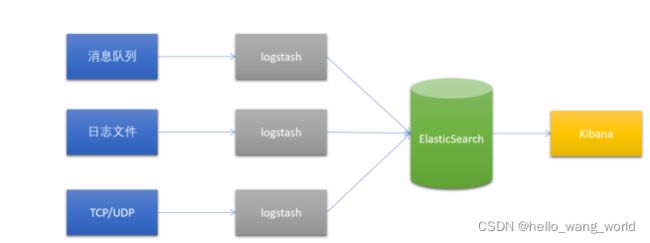
FileBeat 和Logstash区别:
Logstash 运行在jvm中,消耗的资源大。
FileBeat 基于Golang语言开发的;所以在处理并发能力,资源消耗小。
共同点:都可以进行日志的采集;
不同点:logstash 可以对日志进行过滤,而且可以收集如消息队列里的数据
一般使用logstash 就可以通过它们的不同点完成一个背压机制;当我们有多个日志文件需要采集的时候可以通过FileBeat 进行日志的收集并且发送到redis,或者MQ 等中间件中,在通过LogStash 对读取出中间件的数据进行过滤后输送到Elasticsearch 这样就不会去启动多个logstash

安装logstash
下载安装包: https://www.elastic.co/cn/downloads/past‐releases/logstash‐7‐6‐1
将下载完成的安装包放在/usr/local/es 下;进入目录下解压文件
# 将文件解压到指定的路径下
unzip logstash-7.6.1.zip -d /usr/local/es
# 解压后进入logstash的config 配置文件夹
cd /usr/local/es/logstash-7.6.1/config
# 创建一个文件配置
touch file.conf
# 编写配置如下
vim file.conf
input {
file {
path => "/usr/local/server.log"
type => "log"
start_position => "beginning"
}
}
output {
elasticsearch { hosts => ["ip1:9200","ip2:9200","ip3:9200"] }
stdout {}
}
上面的配置就是监听/usr/local/的server.log 日志文件再将日志输入es;
将上面的配置写入到
启动logstash
#进入目录
cd /usr/local/es/logstash‐7.6.1/
#启动并指定配置文件
bin/logstash -f /config/file.conf
启动成功后会es中创建一个索引库并把数据传入es中

其实如果logstash 只是作为日志来使用的话我根本不建议使用它来监听日志,通常只用它来过滤日志,其实时间开发中我们也未必需要他来过滤日志,对于中间件filebeat的module功能比如mysql 就可以定义之采集error和慢sql的日志等;而我们自己写的软件有很多的方式将日志输出到指定的位置;有人可能觉得这样回损耗系统的性能,通常不是特别重要的我们也不需要记录,大部分都是在记录错误,那么你有大量的bug也不可能,所以在某种情况下logstash 失去了过滤的意义;当然我没接触过大数据可能他在大数据的领域功能很好。还有就是logstash 可以作mysql和elasticsearh 之间的同步;
一般mysql 和elasticsearch 同步只有两种方式: 第一种就是通过工具使用logstash 等;第二种就是es client的API;我这里告诉你不用纠结直接API;首先说如果你选择了工具同步解决不了父子类在es中的同步,还有同步不是实时中间可能会出现logstash的断链,还有数据的实时性没有API高,等于又在自己的系统上再加一层中间件的架构那么这种同步在我看来就有点没那么好用;在说API,首先他不会出现父子类不好同步,第二有人说他也有可能出现刚写入数据库这时候挂了怎么同步es呢?那再代码中解决这种方式太简单了,事务;,方法一是通过第三方的定时监听同步可能你的数据放好在这次监听结束 的同时插入成功那么es和mysql同步需要登上一个完整的周期;
有人可能还有疑问这个数据一致的实时性不好但是我的数据经常修改,那么你自己就要坐权衡取舍了,其实很多的项目中用到的es存储的数据都是一次上传很少修改的不要跟我讲销量库存这种数据;如果你的项目中有库存和销量你记着在es中就是大概,真正运算的时候不可能从es中取进行计算,都是从reids或者其他的地方取到就算后修改es; 所以对于你es中需要存取常修改的数据那么只能是个近似值或者不常修改的值;当然如果你的es直接当作DB使用那么不谈