从零使用SVM(支持向量积)进行模糊数字分类
目录
- 数据集
- 分别读入训练数据和测试数据
- 绘制部分训练集图像
- 建模训练并预测
- 寻找预测错误的数据
- 绘制部分预测错误的数据与预测值
- 全部代码
数据集
下载数据点击这里!!!
这里下载这俩即可

分别读入训练数据和测试数据
# 加载训练集数据以及测试集数据
print('Load Training File Start...')
# data = pd.read_csv('optdigits.tra', header=None)
# x, y = data[list(range(64))], data[64]
# x, y = x.values, y.values
data = np.loadtxt('optdigits.tra', dtype=np.float, delimiter=',')
x, y = np.split(data, (-1,), axis=1)
images = x.reshape(-1, 8, 8)
print('images.shape = ', images.shape)
y = y.ravel().astype(np.int)
print('Load Test Data Start...')
data = np.loadtxt('optdigits.tes', dtype=np.float, delimiter=',')
x_test, y_test = np.split(data, (-1,), axis=1)
print(y_test.shape)
images_test = x_test.reshape(-1, 8, 8)
y_test = y_test.ravel().astype(np.int)
print('Load Data OK...')
绘制部分训练集图像
# 画出部分训练集图像
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(15, 9), facecolor='w')
for index, image in enumerate(images[:16]):
plt.subplot(4, 8, index + 1)
plt.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
plt.title('训练图片: %i' % y[index])
for index, image in enumerate(images_test[:16]):
plt.subplot(4, 8, index + 17)
plt.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
# save_image(image.copy(), index)
plt.title('测试图片: %i' % y_test[index])
plt.tight_layout()
plt.show()
如下图

建模训练并预测
# 建模训练并做预测
model = svm.SVC(C=1, kernel='rbf', gamma=0.001)
print('Start Learning...')
t0 = time()
model.fit(x, y)
t1 = time()
t = t1 - t0
print('训练+CV耗时:%d分钟%.3f秒' % (int(t / 60), t - 60 * int(t / 60)))
# print '最优参数:\t', model.best_params_
# clf.fit(x, y)
print('Learning is OK...')
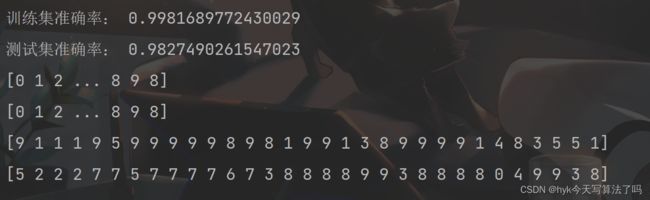
print('训练集准确率:', accuracy_score(y, model.predict(x)))
y_hat = model.predict(x_test)
print('测试集准确率:', accuracy_score(y_test, model.predict(x_test)))
print(y_hat)
print(y_test)
输出
寻找预测错误的数据
# 寻找预测错误数据
err_images = images_test[y_test != y_hat]
err_y_hat = y_hat[y_test != y_hat]
err_y = y_test[y_test != y_hat]
print(err_y_hat)
print(err_y)
绘制部分预测错误的数据与预测值
# 画出部分预测错误数据
plt.figure(figsize=(10, 8), facecolor='w')
for index, image in enumerate(err_images):
if index >= 12:
break
plt.subplot(3, 4, index + 1)
plt.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
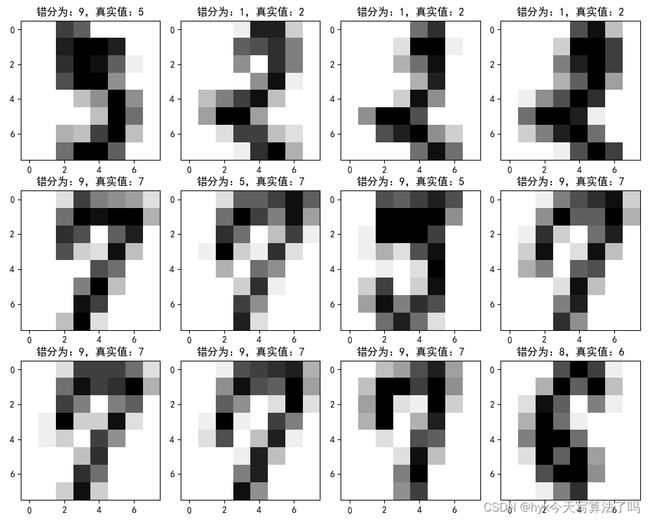
plt.title('错分为:%i,真实值:%i' % (err_y_hat[index], err_y[index]))
plt.tight_layout()
plt.show()
如下图
全部代码
if __name__ == "__main__":
# 加载训练集数据以及测试集数据
print('Load Training File Start...')
# data = pd.read_csv('optdigits.tra', header=None)
# x, y = data[list(range(64))], data[64]
# x, y = x.values, y.values
data = np.loadtxt('optdigits.tra', dtype=np.float, delimiter=',')
x, y = np.split(data, (-1,), axis=1)
images = x.reshape(-1, 8, 8)
print('images.shape = ', images.shape)
y = y.ravel().astype(np.int)
print('Load Test Data Start...')
data = np.loadtxt('optdigits.tes', dtype=np.float, delimiter=',')
x_test, y_test = np.split(data, (-1,), axis=1)
print(y_test.shape)
images_test = x_test.reshape(-1, 8, 8)
y_test = y_test.ravel().astype(np.int)
print('Load Data OK...')
# x, x_test, y, y_test = train_test_split(x, y, test_size=0.4, random_state=1)
# images = x.reshape(-1, 8, 8)
# images_test = x_test.reshape(-1, 8, 8)
# 画出部分训练集图像
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(15, 9), facecolor='w')
for index, image in enumerate(images[:16]):
plt.subplot(4, 8, index + 1)
plt.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
plt.title('训练图片: %i' % y[index])
for index, image in enumerate(images_test[:16]):
plt.subplot(4, 8, index + 17)
plt.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
# save_image(image.copy(), index)
plt.title('测试图片: %i' % y_test[index])
plt.tight_layout()
plt.show()
# params = {'C':np.logspace(0, 3, 7), 'gamma':np.logspace(-5, 0, 11)}
# model = GridSearchCV(svm.SVC(kernel='rbf'), param_grid=params, cv=3)
# 建模训练并做预测
model = svm.SVC(C=1, kernel='rbf', gamma=0.001)
print('Start Learning...')
t0 = time()
model.fit(x, y)
t1 = time()
t = t1 - t0
print('训练+CV耗时:%d分钟%.3f秒' % (int(t / 60), t - 60 * int(t / 60)))
# print '最优参数:\t', model.best_params_
# clf.fit(x, y)
print('Learning is OK...')
print('训练集准确率:', accuracy_score(y, model.predict(x)))
y_hat = model.predict(x_test)
print('测试集准确率:', accuracy_score(y_test, model.predict(x_test)))
print(y_hat)
print(y_test)
# 寻找预测错误数据
err_images = images_test[y_test != y_hat]
err_y_hat = y_hat[y_test != y_hat]
err_y = y_test[y_test != y_hat]
print(err_y_hat)
print(err_y)
# 画出部分预测错误数据
plt.figure(figsize=(10, 8), facecolor='w')
for index, image in enumerate(err_images):
if index >= 12:
break
plt.subplot(3, 4, index + 1)
plt.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
plt.title('错分为:%i,真实值:%i' % (err_y_hat[index], err_y[index]))
plt.tight_layout()
plt.show()