传输层——UDP协议
文章目录
-
- 传输层
-
- 再谈端口号
- 端口号划分
- 认识及查看知名端口号
- linux下网络命令
-
- **netstat(查看当前主机的连接情况,高频重要)**
- pidof(查看服务器的进程id)
- UDP协议
-
- UDP协议端格式
- UDP的特点
- 面向数据报
- UDP的缓冲区
- UDP使用注意事项
- 基于UDP的应用层协议
- 底层实现的结构
传输层
这部分由网络基础(一)可以知道是由操作系统实现的内核级协议
再谈端口号
端口号(Port)标识了一个主机上进行通信的不同的应用程序。
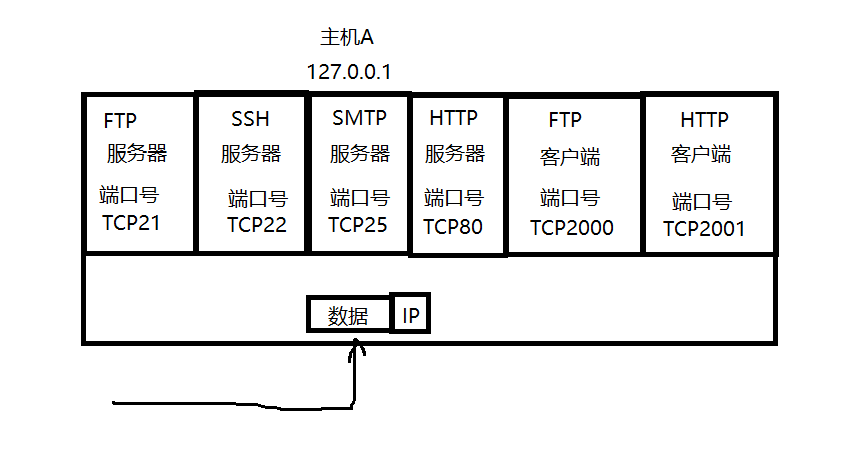
向上交付的时候根据TCP/UDP首都中的端口号进行分用。那么端口号是怎么找到进程的?内核里用的哈希算法。根据端口号直接哈希,在哈希表里找PCB。端口号作key,进程号PID作为value进行哈希挂接到哈希表里,分用的时候用端口号直接在哈希表里找。
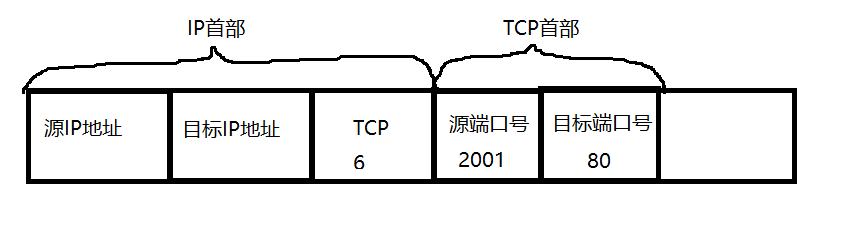
在TCP/IP协议中, 用"源IP",“源端口号”,“目的IP”,“目的端口号”,"协议号"这样一个五元组来标识一个通信(可以通过netstat -n查看); “源IP+源端口”叫套接字。“目的IP+目的端口号”叫套接字。前四元组可以称作一对进程。
同一个浏览器进程打开两个百度页面的过程如下图:

一个进程是否可以bind多个端口号?
可以
一个端口号是否可以被多个进程bind?
不可以
端口号划分
0-1023:知名端口号,HTTP,FTP,SSH等这些广为使用的应用层协议,他们的端口号都是固定的。我们无法绑定。
1024-65535:操作系统动态分配的端口号,客户端程序的端口号,就是由操作系统从这个范围分配的。
认识及查看知名端口号
有些服务器是非常常用的,为了使用方便,人们约定一些常用的服务器,都是用以下这些固定的端口号:
- ssh服务器,使用22端口
- ftp服务器,使用21端口
- telnet服务器,使用23端口
- http服务器,使用80端口
- https服务器,使用443端口
我们的Xshell本质是一个ssh客户端。使用的原因是有GUI方便访问。windows的cmd也可以直接以ssh user@IP进行访问服务器。默认使用了服务器上ssh程序的22端口号,因此连接可以不用写端口号。
浏览器访问网页的时候一般也不用指定端口,只要指定协议名称后默认就会加上端口。
cat /etc/services可以查看服务与端口对应的关系。

![]()
我们自己写一个程序使用端口号时,要避开这些知名端口号。
linux下网络命令
至此见过的工具包括:ssh,telnet,fldder,netstat,ifconfig
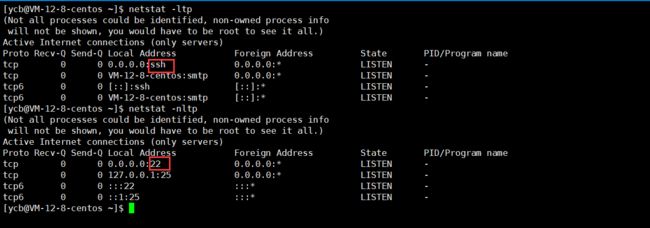
netstat(查看当前主机的连接情况,高频重要)
语法:netstat [选项]
功能:查看网络状态
常用选项:
- n 拒绝显示别名,能显示数字的全部转化成数字
- l 仅列出有在 Listen (监听) 的服务状态
- p 显示建立相关链接的程序名
- t (tcp)仅显示tcp相关选项
- u (udp)仅显示udp相关选项
- a (all)显示所有选项。
同理,查看io情况,使用iostat。(Tips:这些命令在sysstat包里,安装既可: yum install sysstat)
比如free查看空闲内存信息。cat /proc/meminfo查看内存信息。cat /proc/cpuinfo查看cpu信息。
pidof(查看服务器的进程id)
语法:pidof [进程名]
功能:通过进程名, 查看进程id
老做法是ps aux | grep httpServer。
现在的做法是pidof httpServer。
如何杀掉服务器进程?老做法是找到pid然后kill -9 pid。
另一种做法是pidof httpServer | xargs kill -9,其中xargs是将管道的输出转化成下个进程的命令行参数而不是原来的stdin。其中xargs在最开始的笔记中常见指令的最后一个。
UDP协议
UDP协议端格式
udp本身不保证可靠性,内部有一个校验和,但是udp校验不通过没有通知机制默认没收到。
不保证可靠性决定了udp协议的本身比较简单。日常生活中很多场景不需要保证可靠性,比如直播,DNS应用层协议。
只要当前协议上还有协议,要做到两件工作:将报头和有效载荷进行分离;进行向上交付。
分离过程:对于前者来说,UDP的报头是定长报头,直接就可以分离(前8个字节直接拿走,剩下的有效载荷读取长度为16位UDP长度-8字节的内容)。
交付过程:向上交付和tcp一样通过端口进行分用,交给应用层所绑定的某一个进程,查找<端口号,进程PID>哈希表。
这里可以联系网络编程套接字中对端可以通过reve from中的sockaddr_in获得对端的ip和port。ip在下一层。

- 16位UDP长度,表示整个数据报(UDP首部+UDP数据)的最大长度;
- 如果校验和出错,就会直接丢弃;
UDP的特点
UDP传输的过程类似于寄信。要么不读取,要读取拿出来的一定是一个完整的报文。
- 无连接:知道对端的IP和端口号就直接进行传输,不需要建立连接;
- 不可靠:没有确认机制,没有重传机制;如果因为网络故障该段无法发到对方,UDP协议层也不会给应用层返回任何错误信息;
- 面向数据报:不能够灵活的控制读写数据的次数和数量;比如发了10个报文,必须读10次。而tcp字节流一次想读几个字节就几个字节。
面向数据报
应用层交给UDP多长的报文,UDP原样发送,既不会拆分,也不会合并; 只进行了加报头。
用UDP传输100个字节的数据: 如果发送端调用一次sendto,发送100个字节,那么接收端也必须调用对应的一次recvfrom,接收100个字节;而不能循环调用10次recvfrom,每次接收10个字节。
UDP的缓冲区
可以联系语言级别的刷新策略,当不使用换行或者强制fflush(stdout)的时候,输出到显示器上基本是进程结束的时候输出。原因在于IO是比较慢的,所以引入了缓冲区。将输出先输出到内存中,之后再放到外设上。而网卡也是外设,会有缓冲区。
- UDP没有真正意义上的发送缓冲区,调用sendto会直接交给内核, 由内核将数据传给网络层协议进行后续的传输动作;
- UDP具有接收缓冲区。但是这个接收缓冲区不能保证收到的UDP报的顺序和发送UDP报的顺序一致;如果缓冲区满了,再到达的UDP数据就会被丢弃;
UDP的socket既能读, 也能写, 这个概念叫做全双工。
如果一个线程只通过udp套接字进行读,一个线程通过udp套接字进行写。这两个线程之间对接一个缓冲区,一个不断放,一个不断写,利用生产者消费者模型进行群聊。
UDP使用注意事项
我们注意到,UDP协议首部中有一个16位的最大长度。也就是说一个UDP能传输的数据最大长度是64K(包含UDP首部)。然而64K在当今的互联网环境下,是一个非常小的数字。如果我们需要传输的数据超过64K,就需要在应用层手动的分包,多次发送,并在接收端手动拼装。
如果想要提升UDP的可靠性可以山寨一部分TCP的功能来实现。
基于UDP的应用层协议
- NFS: 网络文件系统
- TFTP: 简单文件传输协议
- DHCP: 动态主机配置协议,路由器在内置局域网中选择一个没被使用的IP发送给我们,主机在局域网中使用该IP地址。
- BOOTP: 启动协议(用于无盘设备启动)
- DNS: 域名解析协议
当然, 也包括自己写UDP程序时自定义的应用层协议;
应用场景有直播用udp,早期QQ用udp,服务器压力小。
底层实现的结构
过程:使用udphdr创建对象,填充对应字段,把数据和变量拷贝起来(memcpy)形成报文往下交付。
#define __be16 u_int16_t
#define __be32 u_int32_t
#define __be64 u_int_64_t
struct udphdr
{
__be16 source;
__be16 dest;
__be16 len;
__sum check;
};