BP神经网络的数据分类——语音特征信号分类
大家好,我是带我去滑雪!
BP神经网络,也称为反向传播神经网络,是一种常用于分类和回归任务的人工神经网络(ANN)类型。它是一种前馈神经网络,通常包括输入层、一个或多个隐藏层和输出层。BP神经网络的分类任务涉及将输入数据分为不同的类别,其中每个类别由网络输出的一个节点表示。
目录
(1)BP神经网络的训练步骤
(2)语音特征识别分类
(3)模型建立
(4)数据选择与归一化
(5)BP神经网络结构初始化
(6)模型训练
(7)模型分类
(8)结果分析
(1)BP神经网络的训练步骤
BP神经网络的训练过程包括以下几个步骤:
- 输入层:输入层接收原始数据,将其传递给神经网络。每个输入节点对应于数据的一个特征或属性。
- 隐藏层:BP神经网络可以包含一个或多个隐藏层。隐藏层的目的是学习数据中的复杂模式和特征。每个隐藏层包含多个神经元,这些神经元通过权重和激活函数进行连接。
- 输出层:输出层产生网络的最终输出,通常对应于分类的不同类别。每个输出节点表示一个类别,并输出的值通常被解释为某个样本属于该类别的概率。
- 权重:在BP神经网络中,每个连接都有一个相关联的权重。这些权重是网络的参数,通过训练来学习。它们用于控制信号在网络中的传递和变换。
- 激活函数:每个神经元都包含一个激活函数,用于将神经元的输入转换为输出。常见的激活函数包括Sigmoid、ReLU(Rectified Linear Unit)和Softmax函数。
- 前向传播:前向传播是指从输入层到输出层的信息传递过程。每个神经元将其输入与相关的权重相乘,并将结果传递给激活函数。这一过程逐层进行,直到得到输出。
- 反向传播:反向传播是BP神经网络的关键部分。它使用损失函数来度量网络输出与实际目标之间的误差。然后,通过链式法则,误差被反向传播回网络,以调整权重,减小误差。这是通过梯度下降算法实现的,以最小化损失函数。
- 训练:训练是指通过提供大量已知的输入和目标输出数据来调整网络的权重,以使网络能够对新数据进行分类。训练通常涉及多次迭代的前向传播和反向传播过程。
- 预测:一旦网络经过训练,它可以用来对未知数据进行分类。输入数据传递到网络中,然后网络输出表示每个类别的概率或类别标签。
(2)语音特征识别分类
语音特征信号识别是一种技术,它涉及分析和识别从声音信号中提取出的语音特征。这些特征是声音信号中的可量化属性,有助于理解和识别说话者的身份、语言、情感、语速、音调和其他相关信息。语音特征信号识别在语音处理、语音识别、情感分析、说话者识别等领域中具有广泛的应用。
语音识别的运算过程为:首先,将待识别语音转化为电信号后输入识别系统,经过预处理后用数学方法提取语音特征信号,提取出的语音特征信号可以看成该段语音的模式;然后,将该段语音模型同已知参考模式相比较,获得最佳匹配的参考模式为该段语音的识别结果。
选取民歌、古筝、摇滚、流行四类不同音乐,用BP神经网络实现对这四类音乐的有效分类。每段音乐都用倒谱系数法(倒谱系数法的核心思想是将信号的频谱信息转化为倒谱域,以便更好地分析和处理信号的特征)提取500组24维语音特征信号,提出的语音特征信号。
(3)模型建立
由于语音特征输入信号有24维,待分类的语音信号有4类,所以将BP神经网络的结构设置为24-25-4,即输入层有24个节点,隐含层有25个节点,输出层有4个节点。BP神经网络训练用训练数据训练BP神经网络,由于一共有2000组的语音特征信号,从中随机选择1500组作为训练数据训练神经网络,500组数据作为测试数据测试网络分类能力。BP神经网络再用训练好的神经网络对测试数据所属语音类别进行分类。
(4)数据选择与归一化
首先根据倒谱系数法提取四类音乐特征信号,不同的语音信号分别用1、2、3、4标识,提取的信号分别存储于data1.mat、data2.mat、data3.mat、data4.mat数据库文件中,每组数据为25维,第一维为类别标识,后24维为语音特征信号。对汇总后的数据进行归一化处理。根据语音类别标识设定每组语音信号的期望输出值,如标识类为1,期望输出向量为[1,0,0,0]。
%% 清空环境变量
clc
clear
%% 训练数据预测数据提取及归一化
%下载四类语音信号
load data1 c1
load data2 c2
load data3 c3
load data4 c4
%四个特征信号矩阵合成一个矩阵
data(1:500,:)=c1(1:500,:);
data(501:1000,:)=c2(1:500,:);
data(1001:1500,:)=c3(1:500,:);
data(1501:2000,:)=c4(1:500,:);
%从1到2000间随机排序
k=rand(1,2000);
[m,n]=sort(k);
%输入输出数据
input=data(:,2:25);
output1 =data(:,1);
%把输出从1维变成4维
output=zeros(2000,4);
for i=1:2000
switch output1(i)
case 1
output(i,:)=[1 0 0 0];
case 2
output(i,:)=[0 1 0 0];
case 3
output(i,:)=[0 0 1 0];
case 4
output(i,:)=[0 0 0 1];
end
end
%随机提取1500个样本为训练样本,500个样本为预测样本
input_train=input(n(1:1500),:)';
output_train=output(n(1:1500),:)';
input_test=input(n(1501:2000),:)';
output_test=output(n(1501:2000),:)';
%输入数据归一化
[inputn,inputps]=mapminmax(input_train);
(5)BP神经网络结构初始化
根据语音特征信号的特点确定BP神经网络的结构为24-25-4,随机初始化BP神经网络权值和阈值。
innum=24;
midnum=25;
outnum=4;
%权值初始化
w1=rands(midnum,innum);
b1=rands(midnum,1);
w2=rands(midnum,outnum);
b2=rands(outnum,1);
w2_1=w2;w2_2=w2_1;
w1_1=w1;w1_2=w1_1;
b1_1=b1;b1_2=b1_1;
b2_1=b2;b2_2=b2_1;
%学习率
xite=0.1;
alfa=0.01;
loopNumber=10;
I=zeros(1,midnum);
Iout=zeros(1,midnum);
FI=zeros(1,midnum);
dw1=zeros(innum,midnum);
db1=zeros(1,midnum);(6)模型训练
使用训练数据训练模型,在训练过程中根据网络预测误差调整网络的权值和阈值。
E=zeros(1,loopNumber);
for ii=1:10
E(ii)=0;
for i=1:1:1500
%% 网络预测输出
x=inputn(:,i);
% 隐含层输出
for j=1:1:midnum
I(j)=inputn(:,i)'*w1(j,:)'+b1(j);
Iout(j)=1/(1+exp(-I(j)));
end
% 输出层输出
yn=w2'*Iout'+b2;
%% 权值阀值修正
%计算误差
e=output_train(:,i)-yn;
E(ii)=E(ii)+sum(abs(e));
%计算权值变化率
dw2=e*Iout;
db2=e';
for j=1:1:midnum
S=1/(1+exp(-I(j)));
FI(j)=S*(1-S);
end
for k=1:1:innum
for j=1:1:midnum
dw1(k,j)=FI(j)*x(k)*(e(1)*w2(j,1)+e(2)*w2(j,2)+e(3)*w2(j,3)+e(4)*w2(j,4));
db1(j)=FI(j)*(e(1)*w2(j,1)+e(2)*w2(j,2)+e(3)*w2(j,3)+e(4)*w2(j,4));
end
end
w1=w1_1+xite*dw1'+alfa*(w1_1-w1_2);
b1=b1_1+xite*db1'+alfa*(b1_1-b1_2);
w2=w2_1+xite*dw2'+alfa*(w2_1-w2_2);
b2=b2_1+xite*db2'+alfa*(b2_1-b2_2);
w1_2=w1_1;w1_1=w1;
w2_2=w2_1;w2_1=w2;
b1_2=b1_1;b1_1=b1;
b2_2=b2_1;b2_1=b2;
end
end(7)模型分类
使用已经训练后的BP神经网络模型分类语音特征信号,根据分类结果分析BP神经网络的分类能力。
output_fore=zeros(1,500);
for i=1:500
output_fore(i)=find(fore(:,i)==max(fore(:,i)));
end
%BP网络预测误差
error=output_fore-output1(n(1501:2000))';
%画出预测语音种类和实际语音种类的分类图
figure(1)
plot(output_fore,'r')
hold on
plot(output1(n(1501:2000))','b')
legend('预测语音类别','实际语音类别')
%画出误差图
figure(2)
plot(error)
title('BP网络分类误差','fontsize',12)
xlabel('语音信号','fontsize',12)
ylabel('分类误差','fontsize',12)
%print -dtiff -r600 1-4
k=zeros(1,4);
%找出判断错误的分类属于哪一类
for i=1:500
if error(i)~=0
[b,c]=max(output_test(:,i));
switch c
case 1
k(1)=k(1)+1;
case 2
k(2)=k(2)+1;
case 3
k(3)=k(3)+1;
case 4
k(4)=k(4)+1;
end
end
end
%找出每类的个体和
kk=zeros(1,4);
for i=1:500
[b,c]=max(output_test(:,i));
switch c
case 1
kk(1)=kk(1)+1;
case 2
kk(2)=kk(2)+1;
case 3
kk(3)=kk(3)+1;
case 4
kk(4)=kk(4)+1;
end
end
%正确率
rightridio=(kk-k)./kk;(8)结果分析
BP神经网络分类误差如下图所示。
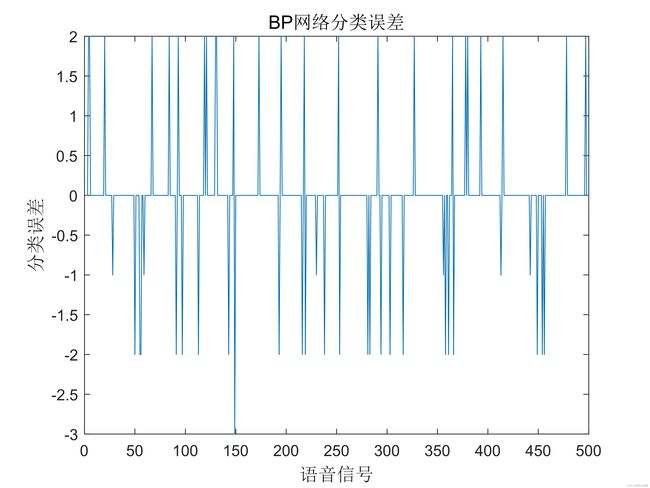
BP神经网络的分类正确率为:
| 语音信号识别 | 第一类 | 第二类 | 第三类 | 第四类 |
| 正确率 | 0.8049 | 1 | 0.8702 | 0.8984 |
通过分类结果的准确率可以发现,基于BP神经网络的语音信号分类算法具有较高的准确性,能够准确识别出语音信号所属类别。
更多优质内容持续发布中,请移步主页查看。
点赞+关注,下次不迷路!