Azure机器学习模型搭建
Azure机器学习模型搭建
Azure Machine Learning(简称“AML”)是微软在其公有云Azure上推出的基于Web使用的一项机器学习服务,机器学习属人工智能的一个分支,它技术借助算法让电脑对大量流动数据集进行识别。这种方式能够通过历史数据来预测未来事件和行为,其实现方式明显优于传统的商业智能形式。
微软的目标是简化使用机器学习的过程,以便于开发人员、业务分析师和数据科学家进行广泛、便捷地应用。
这款服务的目的在于“将机器学习动力与云计算的简单性相结合”。
AML目前在微软的Global Azure云服务平台提供服务,用户可以通过站点:https://studio.azureml.net/ 申请免费试用。
实验步骤:
获取数据
UCI机器学习数据库的网址:****http://archive.ics.uci.edu/ml/****
该数据库是加州大学欧文分校(UniversityofCaliforniaIrvine)提出的用于机器学习的数据库,这个数据库目前共有187个数据集,其数目还在不断增加,UCI数据集是一个常用的标准测试数据集。数据库不断更新,是所有学习人工智能、机器学习等都需要用到的数据库,是看文章、写论文、测试算法的必备数据集。数据库种类涉及生活、工程、科学各个领域,记录数也是从少到多,最多达几十万条。
我们使用其中:美国人口普查数据集(****https://archive.ics.uci.edu/ml/datasets/census+income)****的数据,该数据从美国1994年人口普查数据库抽取而来,可以用来预测居民收入是否超过50K/year。该数据集类变量为年收入是否超过50k,属性变量包含年龄,工种,学历,职业,人种等重要信息,
值得一提的是,14个属性变量中有7个类别型变量,数据集各属性:其中序号0~13是属性, 14是类别
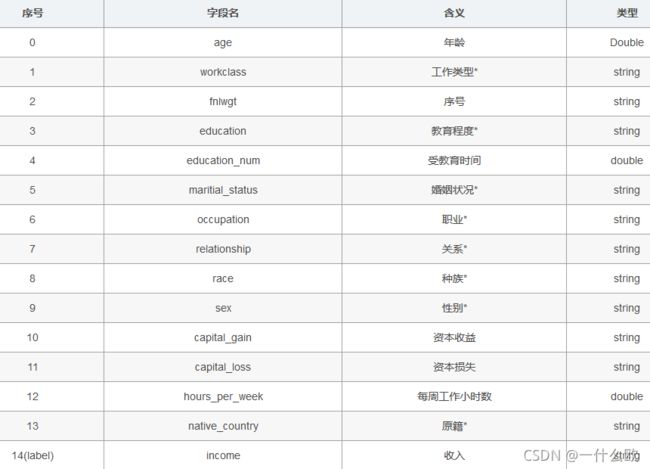
数据集局部图如下图所示:
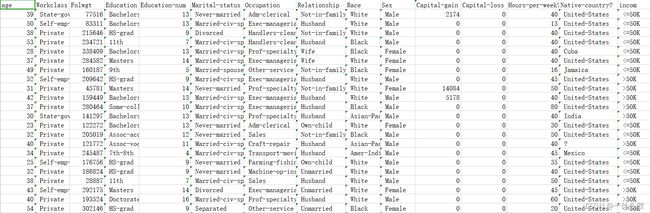
现在,用 Microsoft Excel 或任何其他电子表格工具中打开 adult.data 文件,并为其添加网站中属性列表的详细信息,这些信息如下列出。注意,其中的一部分属性值为连续的,因为它们以数值的形式表现,另一部分则为离散的。
- 观察数据集
****年龄(age)****,连续值
****工作种类(Workclass)****个人(Private), 无限责任公司(Self-emp-not-inc), 有限责任公司(Self-emp-inc), 联邦政府(Federal-gov), 地方政府( Local-gov), 州政府(State-gov), 无薪人员(Without-pay), 无工作经验人员(Never-worked)离散值
****序列号(********Fnlwgt********)****连续值
*教育情况(Education)* Bachelors, Some-college, 11th, HS-grad, Prof-school, Assoc-acdm, Assoc-voc, 9th, 7th-8th, 12th, Masters, 1st-4th, 10th, Doctorate, 5th-6th, Preschool )离散值
****受教育年限(Education-num)****,连续值
*婚姻状况(Marital-status)* 已婚(Married-civ-spouse),离婚(Divorced),未婚(Never-married),离异(Separated),丧偶(Widowed),已婚配偶缺席(Married-spouse-absent)、 再婚(Married-AF-spouse),离散值
****职业情况(Occupation)****技术支持(Tech-support),维修工艺(Craft-repair),服务行业(Other-service)、 销售(Sales)、 执行管理(Exec-managerial)、 专业教授(Prof-specialty),清洁工(Handlers-cleaners),机床操控人员(Machine-op-inspct)、 行政文员(Adm-clerical)、 养殖渔业(Farming-fishing)、 运输行业(Transport-moving),私人房屋服务(Priv-house-serv),保卫工作(Protective-serv), 武装部队(Armed-Forces)职业情况,离散值
****亲属情况(Relationship)****妻子(Wife),子女(Own-child),丈夫(Husband),外来人员(Not-in-family)、 其他亲戚(Other-relative)、 未婚(Unmarried),离散值
****种族肤色(Race)****白人(White),亚洲太平洋岛民(Asian-Pac-Islander),阿米尔-印度-爱斯基摩人(Amer-Indian-Eskimo)、 其他(Other),黑人(Black)离散值
****性别(Sex )****男性(Female),女性( Male),离散值
****资本盈利(Capital-gain )****连续值
*资本损失(Capital-loss)* ,连续值
*每周工作时间(Hours-per-week* ),连续值
****国籍(Native-country )****美国(United-States)、 柬埔寨(Cambodia)、 英国(England),波多黎各(Puerto-Rico),加拿大(Canada),德国(Germany),美国周边地区(关岛-美属维尔京群岛等)(Outlying-US(Guam-USVI-etc)),印度(India)、 日本(Japan)、 希腊(Greece)、 美国南部(South)、 中国(China)、 古巴(Cuba)、 伊朗(Iran)、 洪都拉斯(Honduras),菲律宾(Philippines)、 意大利(Italy)、 波兰(Poland)、 牙买加(Jamaica)、 越南(Vietnam)、 墨西哥(Mexico)、 葡萄牙(Portugal)、 爱尔兰(Ireland)、 法国(France)、多米尼加共和国(Dominican-Republic)、 老挝(Laos)、 厄瓜多尔(Ecuador)、 台湾(Taiwan)、 海地(Haiti)、 哥伦比亚(Columbia)、 匈牙利(Hungary)、 危地马拉(Guatemala)、 尼加拉瓜(Nicaragua)、苏格兰(Scotland)、 泰国(Thailand)、 南斯拉夫(Yugoslavia),萨尔瓦多(El-Salvador)、 特立尼达和多巴哥(Trinadad&Tobago)、 秘鲁(Peru),香港(Hong),荷兰(Holland-Netherlands)离散值
*收入 (incom)* >50K, <=50K ,离散值
-
总括一下数据集的数据特征:
1,十四个与结果相关的唯一属性
2,数据集的实例数为 48,842
3,预测任务是确定用户是否一年收入超过$50,000美元。
实验准备
-
进入官网,点击Sign In
-
登陆注册
-
点击左下角的new 选择DATASET,点击从本地文件选择即"FROM LOCAL FILE",上传本地的数据文件
-
等待数据加载,完成信息的输入并点击签入按钮后,您的数据集将异步加载至您的第一个Azure机器学习实验的工作区中:
-
创建新的Azure机器学习实验,创建新的实验的方法是点击屏幕左下角的"+NEW"按钮,选择"实验"(EXPERIMENT)>“空白实验”(Blank Experiment):
开始实验
- 获取数据
选择Saved Datasets选项下的My Datasets > adult.data.csv,拖拽到Experiment中
- 数据基本处理
分割训练集,选择Sample and Split > Split Data,拖拽到Experiment中,将adult.data.csv与Split Data链接,并点击Split Data,将Fraction of rows in firs… 设置为0.8(0.8为训练集,0.2为测试集,我们后面将用到)
-
特征工程(略)
-
确认目标值
选择训练模型,选项Train选项中的Train Model,拖拽到Experiment中,同时将Train Model与Split Data链接,点击Train Model>Launch column selector>输入incom(目标值)
-
训练模型
由于我们训练的模型是有特征值有目标值的监督学习,我们展开"Machine Learning"即机器学习模块下的"Initialize Model"即初始化模型,展开"Classfication"即分类子模块。在此实验中,我们使用"Two-Class Boosted Decision Tree"即双类提升的决策树算法。并与Train Model链接
模型评分
-
选择Score>Score Model,拖拽到Experiment中,同时将Score Model分别与Split Data、Split Data链接。
-
点击菜单页下方的RUN,开始训练
-
等待模块中时钟图标消失,右击Score Model>Scored dataset>Visualize查看图形可视化
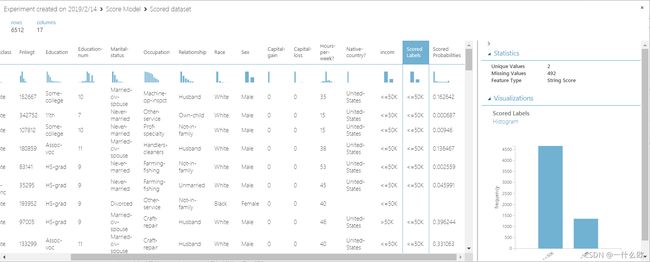
-
incom为实际值,Scired Labels为预测值,Scored Probabilities为预测得分
-
选择Machine Learning>Evaluate>Evaluate Model与Score Model链接,右击Evaluate Model选择RUN,同样Visualize查看图形可视化,我们可以看到ROC曲线以及其参数
