【分布式事务】初步探索分布式事务的概率和理论,初识分布式事的解决方案 Seata,TC 服务的部署以及微服务集成 Seata
文章目录
- 一、分布式服务案例
-
- 1.1 分布式服务 demo
- 1.2 演示分布式事务问题
- 二、分布式事务的概念和理论
-
- 2.1 什么是分布式事务
- 2.2 CAP 定理
- 2.3 BASE 理论
- 2.4 分布式事务模型
- 三、分布式事务解决方案 —— Seata
-
- 3.1 什么是 Seata
- 3.2 Seata 的架构
- 3.3 Seata 的四种分布式事务解决方案
- 四、Seata 服务的部署和集成
-
- 4.1 部署 Seata 的 TC 服务
- 4.2 微服务集成 Seata
一、分布式服务案例
在了解分布式事务之前,让我们通过一个微服务的案例来演示一下分布式事务存在的问题。
1.1 分布式服务 demo
首先,我准备了一个微服务的 demo 项目,这个项目的结构如下:
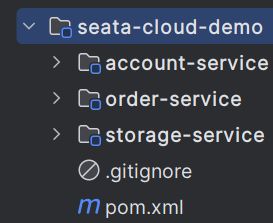
在这个Spring Cloud 项目中一共有三个服务:account-service 账户服务,order-service 订单服务和 storage-service 库存服务。其中order-service 负责下单业务,在下单时会调用订单服务,创建订单并写入数据库。然后订单服务调用账户服务和库存服务:
- 账户服务负责扣减用户余额;
- 库存服务负责扣减商品库存。
这个调用的流程图如下:

目前这三个服务涉及到了三种数据库表,它们的结构如下:
-
首先是订单表:

-
然后是账户表:

-
最后是库存表:

这三个服务的核心业务代码如下:
-
首先是
order-service:@Override @Transactional public Long create(Order order) { // 创建订单 orderMapper.insert(order); try { // 扣用户余额 accountClient.deduct(order.getUserId(), order.getMoney()); // 扣库存 storageClient.deduct(order.getCommodityCode(), order.getCount()); } catch (FeignException e) { log.error("下单失败,原因:{}", e.contentUTF8(), e); throw new RuntimeException(e.contentUTF8(), e); } return order.getId(); } -
然后是
account-service:@Override @Transactional public void deduct(String userId, int money) { log.info("开始扣款"); try { accountMapper.deduct(userId, money); } catch (Exception e) { throw new RuntimeException("扣款失败,可能是余额不足!", e); } log.info("扣款成功"); } -
最后是
storage-service:@Transactional @Override public void deduct(String commodityCode, int count) { log.info("开始扣减库存"); try { storageMapper.deduct(commodityCode, count); } catch (Exception e) { throw new RuntimeException("扣减库存失败,可能是库存不足!", e); } log.info("扣减库存成功"); }
可以发现,这三个核心的业务代码都加上了 @Transactional 注解来开启事务,下面就通过 Postman 来演示一下这个过程。
1.2 演示分布式事务问题
在演示之前,先看看数据库中的数据:
-
order_tbl:

-
account_tbl:

-
storage_tbl:
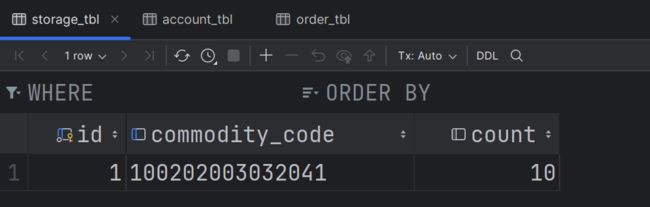
首先是正常状态,即余额和库存都充足的情况:
通过 Postman 发送如下请求,此时指定商品的数量为 2,库存充足:

最终成功执行,然后让我们看一看数据库中的数据变化
-
order_tbl中新增了一条订单数据:
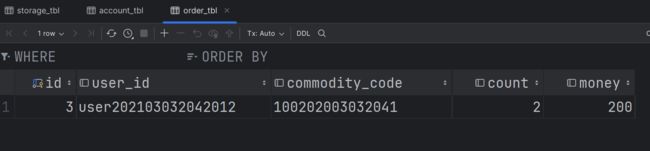
-
account_tbl表中该用户的余额成功扣减 200:
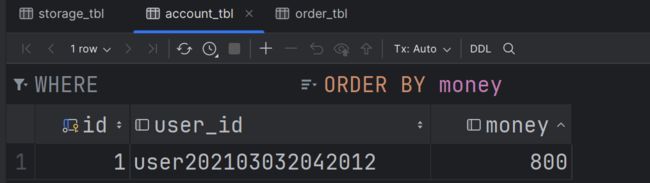
-
storage_tbl表中该商品的库存数量也成功扣减 2 个:

然后让我们来演示一下当库存不足的情况下,是否会存在问题:
现在设置要扣减的库存为 10,而此时的库存数量为 8,则整个过程应该执行失败:
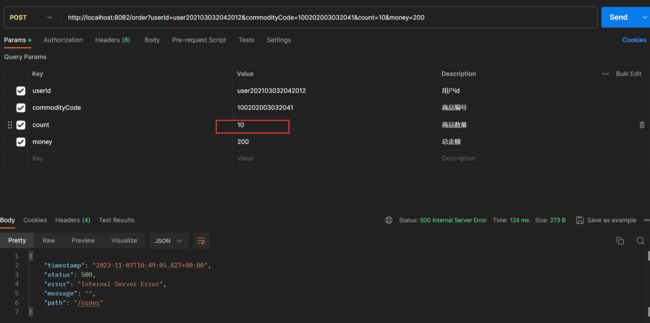
然后再让我们来看一看数据库中的数据变化:
-
order_tbl表中没有新增订单:
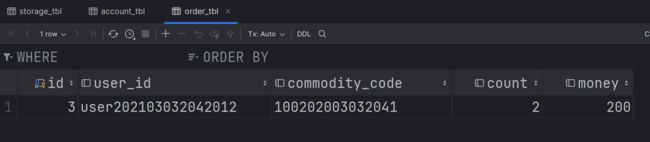
-
account_tbl表中却扣减了 200 金额:

-
storage_tbl表中没有扣减库存:
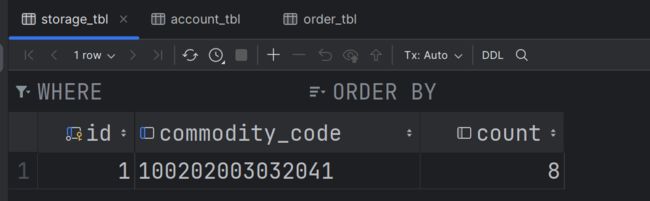
在上面的微服务中,一个业务跨越多个服务或数据源,每个服务都是一个分支事务,要保证所有分支事务最终状态一致,这样的事务就是分布式事务。
但是,上面的微服务上没有实现分布式事务,而只有分支事务,站在分支事务的角度上来看:

- 订单服务虽然下单成功,但是因为调用库存服务,库存服务因为库存不足调用失败回滚了,因此订单服务作为外部事务也会回滚。
- 账户服务在执行的时候没有问题,因此执行成功了。
- 库存服务因为库存不足,业务失败因此回滚了。
因此,要想保证整个业务的流程都能够正常执行,那么就需要采用分布式事务,即要么所有的分支事务都执行成功,要么都执行失败。
二、分布式事务的概念和理论
2.1 什么是分布式事务
分布式事务是指在分布式系统中,多个独立的事务操作需要协同工作以维护数据的一致性和完整性。在传统的单机事务中,ACID(原子性、一致性、隔离性、持久性)属性可以轻松满足,但在分布式系统中,由于涉及多个数据存储节点,实现分布式事务变得更加复杂。
关键问题包括如何协调各个参与者的事务、如何处理网络分区和节点故障、如何保证全局数据一致性等。因此,分布式事务需要特殊的技术和协议来管理和维护数据一致性,以确保分布式系统的正确运行。
2.2 CAP 定理
CAP 定理是分布式系统理论中的一个重要概念,由计算机科学家 Eric Brewer 提出。CAP 定理指出,一个分布式系统的设计不能同时满足以下三个属性:
-
一致性(Consistency):所有节点看到的数据是一致的,即在任何时刻,系统中的所有节点都能看到相同的数据。
-
可用性(Availability):系统在任何时刻都能处理读写请求,即系统保持可用状态,不会出现服务不可用的情况。
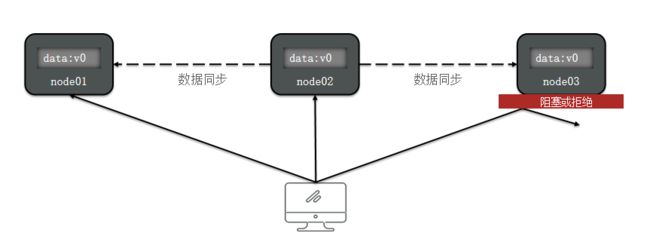
-
分区容忍性(Partition Tolerance):系统能够在网络分区或节点故障的情况下继续工作,即系统能够容忍部分节点无法通信或故障。
CAP 定理指出,在分布式系统中,最多只能满足其中的两个属性,而必须牺牲其中一个。这意味着在面对网络分区或故障时,要么保证一致性和可用性,但失去了分区容忍性;要么保证一致性和分区容忍性,但失去了可用性。这对分布式系统的设计和架构提出了重要挑战。
例如:ES 集群出现分区时,故障节点会被剔除集群,数据分片会重新分配到其它节点,保证数据一致。因此是低可用性,高一致性,属于CP 模式。
2.3 BASE 理论
BASE 理论是对 CAP 定理的一种思考和解决方案,它的名称是对以下三个核心概念的缩写:
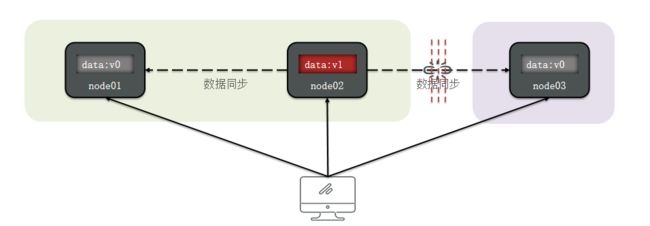
1. Basically Available(基本可用性): 这意味着分布式系统在出现故障时仍然能够保持基本的可用性。即使部分组件故障或数据出现不一致,系统仍然可以提供有限的服务,不会变得完全不可用。这允许系统在面临问题时继续对外提供核心功能,确保用户体验。
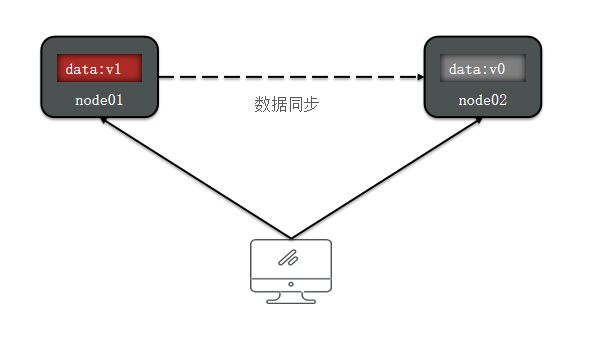
2. Soft State(软状态): BASE 理论承认在一定时间内,分布式系统的数据可以处于不一致的中间状态。这是因为各个节点在进行数据同步或处理时可能存在延迟、不同步的情况,导致数据不完全一致。允许出现软状态意味着系统可以容忍一段时间内的数据不一致,但要求最终达到一致状态。
3. Eventually Consistent(最终一致性): 最终一致性是 BASE 理论的核心概念,它强调虽然分布式系统不能保证强一致性,但最终所有节点的数据将达到一致状态。系统会采取一系列措施来保证数据最终一致,例如定期数据同步、修复数据不一致等。这种方法可以在面临一致性挑战的同时,保持分布式系统的可用性和性能。
BASE 理论的思想在分布式系统中得到了广泛应用,特别是对于大规模、高可用性的系统。它提供了一种权衡可用性和一致性的方法,允许根据具体需求和应用场景来选择适当的数据一致性模型(如最终一致性),以满足不同业务的要求。这使得分布式系统更具弹性、可伸缩性和容错性,同时在最终实现数据一致性。
因此分布式事务最大的问题是各个子事务的一致性问题,因此可以借鉴 CAP 定理和 BASE 理论:
-
AP模式:各子事务分别执行和提交,允许出现结果不一致,然后采用弥补措施恢复数据即可,实现最终一致。
-
CP模式:各个子事务执行后互相等待,同时提交,同时回滚,达成强一致。但事务等待过程中,处于弱可用状态。
2.4 分布式事务模型
要解决分布式事务的问题,各个子系统之间必须能够感知彼此的事务状态,以确保状态一致性。为实现这一目标,通常需要引入一个事务协调者,它的职责是协调每个事务的参与者(子系统内的事务)。这些子系统内的事务通常被称为分支事务,而涉及多个分支事务的全局事务需要协调者来确保一致性。
以上述微服务为例,引入一个事务协调者后的架构如下:
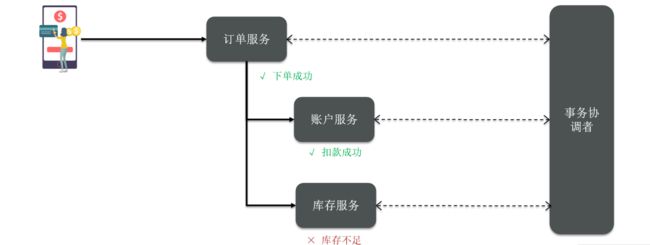
在这种架构中,事务协调者负责协调每个分支事务的执行。当某一分支事务(例如库存服务)由于库存不足而导致业务失败时,事务协调者可以通知所有分支事务进行回滚,以确保所有事务状态的一致性。
分布式事务模型的关键点包括:
-
事务协调者(Coordinator): 负责协调全局事务的执行和状态管理。它监控每个分支事务的执行情况,并根据需要发出提交或回滚命令。
-
分支事务(Branch Transaction): 每个子系统内部的事务,负责执行具体的业务操作。分支事务会根据协调者的指示执行提交或回滚操作。
-
全局事务(Global Transaction): 涉及多个子系统内的一组分支事务,全局事务由协调者协调管理,以确保所有分支事务的状态一致性。
引入事务协调者后,分布式系统可以更好地处理各个子系统之间的事务一致性问题,保证全局事务的正确执行。这种模型有助于应对网络故障、部分事务失败等情况,以确保分布式系统的数据一致性和完整性。
三、分布式事务解决方案 —— Seata
3.1 什么是 Seata
Seata(前身为Fescar)是一个分布式事务解决方案,最早由蚂蚁金服和阿里巴巴共同开源于2019年1月。Seata 的目标是提供高性能、简单易用的分布式事务服务,旨在为用户提供一站式的分布式解决方案。
Seata的主要功能和特点包括:
-
分布式事务协调: Seata充当分布式事务的协调者,负责管理和协调多个分支事务,以确保它们的一致性和完整性。
-
高性能: Seata通过优化事务日志存储和协调算法,提供高性能的分布式事务处理能力。
-
简单易用: Seata提供了简单的API和配置方式,使开发人员能够轻松地集成和使用分布式事务功能。
-
支持多种存储后端: Seata支持多种存储后端,包括MySQL、Oracle、PostgreSQL等,以满足不同环境的需求。
-
分布式事务模式: Seata支持两阶段提交(2PC)和补偿模式,可以根据业务需求选择合适的事务模式。
-
跨框架和跨语言: Seata可以与各种编程语言和框架集成,包括Java、Spring Cloud、Dubbo等,以及Node.js、Python等非Java语言。
Seata 的官方网站(http://seata.io/)提供了详细的文档、博客和源码分析,为用户提供了丰富的资源和支持,帮助开发人员更好地理解和使用分布式事务解决方案。Seata 的开源性质使得它成为解决分布式事务挑战的重要工具之一,广泛应用于云原生和微服务架构中。
3.2 Seata 的架构
Seata 的架构涉及三个重要的角色,它们分别是:
-
TC (Transaction Coordinator) - 事务协调者: TC 是 Seata 中的核心组件,负责维护全局事务和分支事务的状态,协调全局事务的提交或回滚。TC通过全局事务的唯一标识来管理多个分支事务,确保它们的状态一致性,并根据协调结果决定是提交还是回滚全局事务。
-
TM (Transaction Manager) - 事务管理器: TM 定义了全局事务的范围,它负责启动全局事务、提交或回滚全局事务。TM 与 TC 进行通信,以协调全局事务的状态和最终结果。TM可以是应用程序的一部分,用于启动和管理分布式事务。
-
RM (Resource Manager) - 资源管理器: RM 管理分支事务处理的资源,包括数据库、消息队列、缓存等。RM 与 TC 进行通信以注册分支事务、报告分支事务的状态,并根据 TC 的指示来驱动分支事务的提交或回滚。RM 负责协调资源的一致性,以确保全局事务的一致性。
这三个角色的架构图如下:
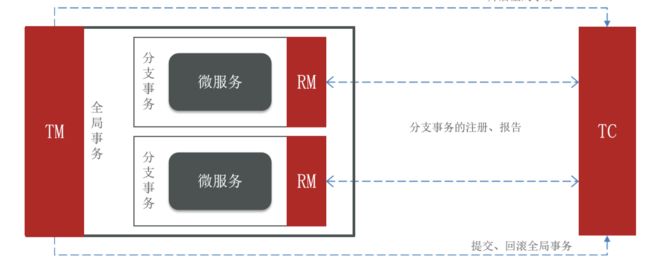 这三个角色共同协作,构成了 Seata 的分布式事务管理架构。TC 作为协调者负责全局事务的管理,TM 负责事务的启动和控制,RM 负责资源的管理和一致性保障。通过这种分布式事务管理架构,Seata能够有效地管理分布式事务的状态和保证一致性,为分布式系统提供可靠的事务支持。
这三个角色共同协作,构成了 Seata 的分布式事务管理架构。TC 作为协调者负责全局事务的管理,TM 负责事务的启动和控制,RM 负责资源的管理和一致性保障。通过这种分布式事务管理架构,Seata能够有效地管理分布式事务的状态和保证一致性,为分布式系统提供可靠的事务支持。
3.3 Seata 的四种分布式事务解决方案
Seata 提供了四种不同的分布式事务解决方案,以满足不同业务场景的需求。这些解决方案分别是:
-
XA 模式(eXtended Architecture): XA模式是一种强一致性分阶段事务模式,它允许分布式事务在多个资源管理器(例如数据库)之间进行协调。在XA模式中,事务协调者(TC)协调多个RM(Resource Manager)来确保事务的一致性。虽然XA模式提供了强一致性,但通常会牺牲一定的可用性,并且需要支持XA协议的资源管理器。XA模式不需要业务侵入。
-
TCC 模式(Try-Confirm-Cancel): TCC模式是一种最终一致性的分阶段事务模式,它要求业务代码显式地定义“尝试”、“确认”和“取消”三个阶段的操作。TCC模式通过在每个参与者(分支事务)上执行这些操作来实现最终一致性。虽然TCC模式具有一定的业务侵入,但它提供了更灵活的事务控制和适应性。
-
AT 模式(Automatic Transaction): AT模式是一种最终一致性的分阶段事务模式,它无需业务代码显式地定义阶段操作,而是通过自动代理来管理分支事务。AT模式是Seata的默认模式,它提供了最终一致性的分布式事务解决方案,并且无需业务侵入。AT模式适用于大多数业务场景。
-
SAGA 模式: SAGA模式是一种长事务模式,它将分布式事务分解成多个连续的步骤,每个步骤都是一个本地事务。SAGA模式适用于需要跨多个微服务的长时间事务。虽然SAGA模式具有业务侵入,但它提供了更高级别的事务控制和业务流程管理。
这四种分布式事务解决方案使 Seata 能够适应不同的应用场景,从强一致性到最终一致性,从无业务侵入到有业务侵入,满足了多样化的分布式事务需求。根据具体的业务要求和架构设计,开发人员可以选择适当的 Seata 模式来实现分布式事务管理。
四、Seata 服务的部署和集成
4.1 部署 Seata 的 TC 服务
-
首先我们要下载 seata-server (TC 服务)压缩包,下载地址:http://seata.io/zh-cn/blog/download.html。这里我选择的版本是
1.4.2:

-
将这个压缩包解压到非中文目录下,其目录结构如下:

-
修改
conf目录下的registry.conf文件,这里我们选择将seata-server服务注册到 Nacos 中:registry { # 注册中心类型:file 、nacos 、eureka、redis、zk、consul、etcd3、sofa type = "nacos" nacos { application = "seata-tc-server" serverAddr = "127.0.0.1:8848" group = "DEFAULT_GROUP" namespace = "" cluster = "CD" username = "nacos" password = "nacos" } } config { # file、nacos 、apollo、zk、consul、etcd3 type = "nacos" nacos { serverAddr = "127.0.0.1:8848" namespace = "" group = "SEATA_GROUP" username = "nacos" password = "nacos" dataId = "seataServer.properties" } } -
在 Nacos 中添加
seataServer.properties配置文件。为了让 TC 服务的集群可以共享配置,所以选择了 Nacos 作为统一配置中心。因此服务端配置文件seataServer.properties文件需要添加到 Nacos 中。文件内容如下:# 数据存储方式,db代表数据库 store.mode=db store.db.datasource=druid store.db.dbType=mysql store.db.driverClassName=com.mysql.jdbc.Driver store.db.url=jdbc:mysql://127.0.0.1:3306/seata?useUnicode=true&rewriteBatchedStatements=true store.db.user=root store.db.password=passwd store.db.minConn=5 store.db.maxConn=30 store.db.globalTable=global_table store.db.branchTable=branch_table store.db.queryLimit=100 store.db.lockTable=lock_table store.db.maxWait=5000 # 事务、日志等配置 server.recovery.committingRetryPeriod=1000 server.recovery.asynCommittingRetryPeriod=1000 server.recovery.rollbackingRetryPeriod=1000 server.recovery.timeoutRetryPeriod=1000 server.maxCommitRetryTimeout=-1 server.maxRollbackRetryTimeout=-1 server.rollbackRetryTimeoutUnlockEnable=false server.undo.logSaveDays=7 server.undo.logDeletePeriod=86400000 # 客户端与服务端传输方式 transport.serialization=seata transport.compressor=none # 关闭metrics功能,提高性能 metrics.enabled=false metrics.registryType=compact metrics.exporterList=prometheus metrics.exporterPrometheusPort=9898 -
创建数据库表
TC 服务在管理分布式事务时,需要记录事务相关数据到数据库中,需要提前创建好这些表。因此新建一个名为seata的数据库,然后创建一张分支事务表和一张全局事务表。这些表主要记录全局事务、分支事务、全局锁信息:SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS = 0; -- ---------------------------- -- 分支事务表 -- ---------------------------- DROP TABLE IF EXISTS `branch_table`; CREATE TABLE `branch_table` ( `branch_id` bigint(20) NOT NULL, `xid` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `transaction_id` bigint(20) NULL DEFAULT NULL, `resource_group_id` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `resource_id` varchar(256) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `branch_type` varchar(8) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `status` tinyint(4) NULL DEFAULT NULL, `client_id` varchar(64) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `application_data` varchar(2000) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `gmt_create` datetime(6) NULL DEFAULT NULL, `gmt_modified` datetime(6) NULL DEFAULT NULL, PRIMARY KEY (`branch_id`) USING BTREE, INDEX `idx_xid`(`xid`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact; -- ---------------------------- -- 全局事务表 -- ---------------------------- DROP TABLE IF EXISTS `global_table`; CREATE TABLE `global_table` ( `xid` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `transaction_id` bigint(20) NULL DEFAULT NULL, `status` tinyint(4) NOT NULL, `application_id` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `transaction_service_group` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `transaction_name` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `timeout` int(11) NULL DEFAULT NULL, `begin_time` bigint(20) NULL DEFAULT NULL, `application_data` varchar(2000) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `gmt_create` datetime NULL DEFAULT NULL, `gmt_modified` datetime NULL DEFAULT NULL, PRIMARY KEY (`xid`) USING BTREE, INDEX `idx_gmt_modified_status`(`gmt_modified`, `status`) USING BTREE, INDEX `idx_transaction_id`(`transaction_id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact; SET FOREIGN_KEY_CHECKS = 1; -
启动 TC 服务,进入
seata-server的bin目录,运行其中的seata-server.bat即可:
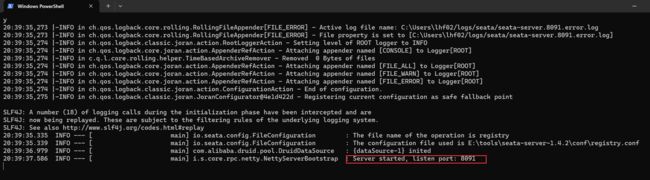
启动成功后,可以发现seata-server默认的端口号是 8091, 并且此时也应该注册到 Nacos 注册中心了。打开浏览器,访问nacos的控制台,然后进入服务列表页面,可以看到seata-tc-server的信息:

4.2 微服务集成 Seata
-
首先,我们需要在微服务中引入 seata 依赖:
<dependency> <groupId>com.alibaba.cloudgroupId> <artifactId>spring-cloud-starter-alibaba-seataartifactId> dependency> <dependency> <groupId>io.seatagroupId> <artifactId>seata-spring-boot-starterartifactId> <version>1.4.2version> dependency>注意,引入的依赖版本要和
seata-server版本匹配。 -
修改配置文件,需要修改所有微服务的
application.yml文件,添加下面的配置:seata: registry: # TC 服务注册中心的配置,微服务根据这些信息去注册中心获取 tc 服务地址 # 参考 tc 服务的 registry.conf 中的配置 type: nacos nacos: # tc server-addr: 127.0.0.1:8848 namespace: "" group: DEFAULT_GROUP application: seata-tc-server # tc服务在nacos中的服务名称 tx-service-group: seata-demo # 事务组,根据这个获取 tc 服务的cluster名称 service: vgroup-mapping: # 事务组与TC服务cluster的映射关系 seata-demo: CD注意,Seata 客户端获取 TC 服务的集群名称 cluster 是通过
tx-service-group和vgroup-mapping的映射来获取的,即以tx-service-group为 key ,以vgroup-mapping为 value:

-
完成了上面的所有配置之后,重启这三个微服务,就可以在
seata-server的控制台中看到如下的日志:
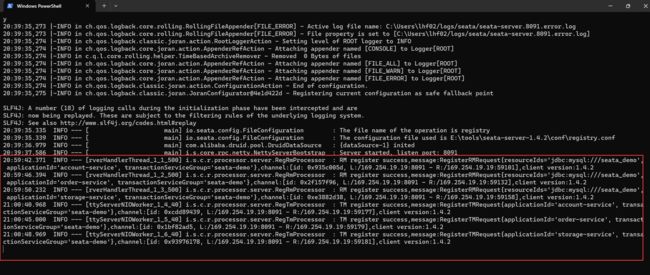
通过这些日志可以发现,seata-server 成功为微服务注册了资源管理器和事务管理器了。