Kafka关键点总结-主题和分区
1.主题和分区(都是逻辑上的概念)
主题可以分为1个或者多个分区,分区划分的好处是:提供了可伸缩性、水平扩展的功能,通过多副本机制为Kafka提供数据冗余以提高数据可靠性,他可以看做是对消息的二次归类。
分区和主题都是逻辑概念,没有物理的存在,分区的每个副本(或者更确切的说是日志,日志与副本一一对应)才真正的对应了一个名为
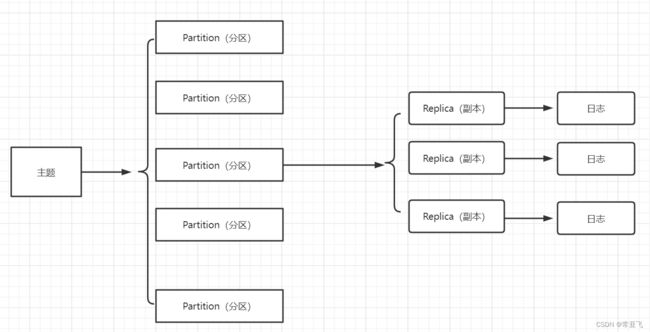
主题和分区都是提供给上层用户的抽象,而在副本层或者说是Log层面才是实际物理的存在,同一个分区中的多个副本必须分布在不同的broker中,这样才能提供有效的数据冗余。
查看分区副本的分配细节的命令:
bin/kafka-topics.sh --zookeeper localhost:2181/kafka --describe --topic topic--create(我们创建的时候起的名字)
2.查看问题分区
bin/kafka-topics.sh --zookeeper localhost:2181/kafka --describe --topic topic--create --under-replicated-partitions
这个命令是查看所有的副本,包含失效的
也可以使用来查看主题中没有leader副本的分区,这些分区已经处于离线状态,对于外界生产者和消费者来说处于不可用的状态
bin/kafka-topics.sh --zookeeper localhost:2181/kafka --describe --topic topic--create --unavailable-partitions
3.修改主题
bin/kafka-topics.sh --zookeeper localhost:2181/kafka --alter--topic topic--create --under-replicated-partitions
我们可以用这个命令修改分区个数或者其他配置
注意:目前Kafka只支持增加分区而不支持减少分区数,比如我们将主题个数减少,就会报出InvalidPartitionException异常
4.优先副本
分区使用多副本机制来提升可靠性,但是只有leader副本对外提供读写服务,而follower副本只负责在内部进行消息的同步。
针对同一个分区而言,同一个broker中不可能出现他的多个副本,即Kafka集群的一个broker中最多能有他的一个副本,我们将leader副本所在的broker叫做分区的leader节点,而follower副本所在的broker节点叫做分区的follower节点。
为了能够有效的治理负载失衡的问题,Kafka引入了优先副本(preferred replica)的概念。
所谓优先副本就是指在AR集合列表上的第一个副本,例如主题topic-partitions中分区0的AR集合列表为[1,2,0],那么分区0的有限副本就是1。理想情况下,优先副本就是该分区的leader副本,所以也称为preferred leader。Kafka要确保所有的主题的优先副本在Kafka中的均匀分布,这样就保证了所有分区的leader的均衡分布。
优先副本的选举是指通过一定的方式促使优先副本选举为leader副本,以此来促进集群的负载均衡,这一行为也称为“分区平衡”
但是分区平衡并不能保证负载均衡,每个分区的leader副本的负载是各不相同的,有些leader副本负载很高,例如要承载30000的负荷,有的leader却只需要承担个位数的负载,也就是说集群中的本区分配均衡、leader分配均衡,也并不能确保整个集群的负载就是均衡的,还需要其他的一些影星的指标来做进一步的衡量,
参加选举的条件:在ISR中保持心跳同步的副本才能参与选举。
选举算法:类似于微软的PacificA算法
老的Kafka是使用ZK进行leader节点的选举
新的Kafka中是所有broker先竞争一个Controller来负责leader副本的选举,所有的broker都会尝试在ZK中创建一个临时节点,谁先创建成功,谁就是Controller,如果Controller挂掉或者网络断掉的情况下临时节点就会消失,其他的Broker就会通过watch机制监测到Controller下线的通知,然后继续按照之前的谁先创建成功谁就是Controller的原则再次竞争Controller
Controller的作用:(1)监听Broker变化(2)监听Topic变化(3)监听Partition变化(4)获取和管理Broker、Topic、Partition的信息(5)管理Partition的主从信息
选举过程:controller感知到分区leader所在的broker挂了(controller监听了很多zk节点可以感知到broker存活),controller会从ISR列表(参数unclean.leader.election.enable=false的前提下)里挑第一个broker作为leader(第一个broker最先放进ISR列表,可能是同步数据最多的副本),如果参数unclean.leader.election.enable为true,代表在ISR列表里所有副本都挂了的时候可以在ISR列表以外的副本中选leader,这种设置,可以提高可用性,但是选出的新leader有可能数据少很多。
副本进入ISR列表有两个条件:
副本节点不能产生分区,必须能与zookeeper保持会话以及跟leader副本网络连通
副本能复制leader上的所有写操作,并且不能落后太多。(与leader副本同步滞后的副本,是由
replica.lag.time.max.ms 配置决定的,超过这个时间都没有跟leader同步过的一次的副本会被移出ISR列表)
如果ISR中broker都挂了,但是Replicas中还存在另一个broker副本,此时会等待ISR中的某个broker恢复后重新选举,这个过程中Kafka无法提供写请求。
还要一种情况是不想等待ISR中的broker恢复,就要将Replicas中剩下的一个broker选举为leader,但是此时可能这个broker中的数据并不是完整的,这样就会造成数据丢失(这种情况应该是unclean.leader.election.enable为true的时候才有效)!
replicas 表示某个partition在哪几个broker上存在备份。不管这个几点是不是”leader“,甚至这个节点挂了,也会列出。
isr 是replicas的一个子集,它只列出当前还存活着的,并且已同步备份了该partition的节点。
5.分区重分配(分区再平衡)
当某个节点上的分区都已经处于功能失效的状态的时候,Kafka并不会将这些失效的分区副本自动地迁移到集群中剩余的可用的broker节点上,如果放任不管,则不仅会影响整个集群的负载均衡,还会影响整体服务的可用性和可靠性。
需要做分区重分配的场景:
(1)需要对集群中的一个节点进行有计划的下线的时候,为了保证分区及副本的合理分配,我们也希望通过某种方式能够将该节点上的分区副本迁移到其他的可用节点上
(2)集群中新增broker节点时,这个时候只有新创建的主题分区才会有可能被分配到这个节点上,而之前的主题分区并不会自动的分配到新加入的节点上,因为他们被创建时还没有这个新节点,这样新节点的负载和原先节点的负载之间就会严重不均衡
为了解决这些问题而进行的让分区副本再次进行合理的分配就是所谓的分区重分配。Kafka提供了kafka-reassign-partitions.sh脚本来执行分区重分配的工作,它可以在集群扩容、borker节点失效的场景下对分区进行迁移。
使用这个脚本分为三个步骤:
(1)首先创建需要一个包含主题清单的json文件
(2)根据主题清单和broker节点清单生成一份重分配的方案
bin/kafka-reassign-partitions.sh --zookeeper localhost:2181/kafka --generate --topic--to --move-json-file reassign.json -- broker-list 0,2
这里的reassign.json时第一步我们创建的,0,2时目前可以用的broker节点,这一步的话只是取生成候选方案
除了用脚本生成候选方案,用户也可以自定义重分配方案,这样就不需要执行第一步和第二步的操作了。
(3)根据这份方案执行具体的重分配动作。
执行具体的重分配操作:bin/kafka-reassign-partitions.sh --zookeeper localhost:2181/kafka --execute --reassignment-json-file project.json(上一步给出的重分配的候选方案我们保存在这个文件里)
如果这一步发现leader副本不均衡,比如3个在broker 0上,1个在broker 2上,我们可以借助kafka-preferred-replica-election.sh脚本来执行一次优先副本的选举动作
bin/kafka-topics.sh --zookeeper localhost:2181/kafka --describe --topic topic-reassign(我们创建的topic的名字)
6.分区重分配的基本原理
通过控制器为每个分区添加新副本(增加副本因子),新的副本将从分区的leader副本那里复制所有的数据,根据数据的大小不同,复制的过程可能花费一些时间,因为数据是通过网络复制到新的副本上。在复制完成之后,控制器将旧副本从副本清单里移除(恢复为原来的副本因子数),重分配的过程中要确保有足够的空间。
如果是要将某个broker下线,那么执行分区重分配之前最好先关闭或者重启broker。这样broker就不再是任何分区的leader节点了,他的分区就可以被分配给集群中的其他的broker。这样可以减少broker间的流量复制,提升重分配的性能,较少对集群的影响。
7. Topic、Partition和broker的对应关系
- 每个topic都可以被划分成一个或者多个分区(至少有一个分区),它是topic物理上的分组,在创建topic的时候指定
- 一个Partition只对应一个Broker,一个Broker可以管理多个Partition。
- 在一个分区内消息是顺序的,在不同的分区之间,kafka并不保证消息的顺序
- 同一个主题下,不同分区所包含的内容是不同的,每个消息被添加到分区当中时,会被分配一个偏移量(offset),它是消息在分区当中的唯一编号,kafka是通过offset来确保一个分区内的消息顺序的,offset的顺序并不跨越分区。
- 在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1