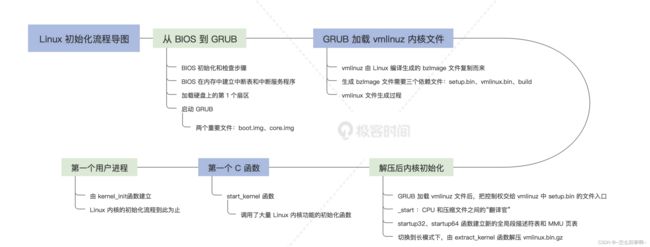
Linux 内核初始化过程
Linux上GRUB是怎样启动的
本节树立启动的整体流程,重点解读Linux上GRUB是怎样启动,以及内核里的“实权人物”-- vmlinuz内核文件是如何产生和运转的。
全局流程
在机器加电后,BIOS会进行自检,然后由BIOS加载引导设备中引导扇区。在安装有Linux操作系统的情况下,在引导扇区里,通常是安装的GRUB的一小段程序(和windows情况不同),最后,GRUB会加载Linux的内核映像vmlinux,如下图所示:
x86的全局启动流程示意图:

从BIOS到GRUB
CPU 被设计成只能运行内存中的程序,没有办法直接运行储存在硬盘或者 U 盘中的操作系统程序。必须先加载到内存(RAM)中才能运行,这是因为硬盘、U盘(外部存储器)并不和CPU直接相连,他们的访问机制和寻址方式与内存截然不同。
内存在断电后就没法保存数据了,那 BIOS 又是如何启动的呢?硬件工程师设计 CPU 时,硬性地规定在加电的瞬间,强制将 CS 寄存器的值设置为 0XF000,IP 寄存器的值设置为 0XFFF0。
(CS:IP 两个寄存器指示了 CPU 当前将要读取的指令的地址,其中 CS 为代码段寄存器,而 IP 为指令指针寄存器 。)
这样,CS:IP就指向了0XFFFF0这个物理地址,在这个物理地址上连接了主板上的一块小的ROM芯片,这种芯片的访问机制和寻址方式和内存一样,只是它在断电时不会丢失数据,在常规下也不能往里面写数据,它只是一种只读内存,BIOS程序就被固化在该ROM芯片中。
现在,CS:IP 指向了 0XFFFF0 这个位置,正是 BIOS 程序的入口地址。这意味着 BIOS 正式开始启动。
BIOS 一开始会初始化 CPU,接着检查并初始化内存,然后将自己的一部分复制到内存,最后跳转到内存中运行。BIOS 的下一步就是枚举本地设备进行初始化,并进行相关的检查,检查硬件是否损坏,这期间 BIOS 会调用其它设备上的固件程序,如显卡、网卡等设备上的固件程序。
当设备初始化和检查步骤完成之后,BIOS 会在内存中建立中断表和中断服务程序,这是启动 Linux 至关重要的工作,因为 Linux 会用到它们。
具体是怎么操作的呢?BIOS 会从内存地址(0x00000)开始用 1KB 的内存空间(0x00000~0x003FF)构建中断表,在紧接着中断表的位置,用 256KB 的内存空间构建 BIOS 数据区(0x00400~0x004FF),并在 0x0e05b 的地址加载了 8KB 大小的与中断表对应的中断服务程序。
中断表中有 256 个条目,每个条目占用 4 个字节,其中两个字节是 CS 寄存器的值,两个字节是 IP 寄存器的值。每个条目都指向一个具体的中断服务程序。
为了启动外部储存器中的程序,BIOS 会搜索可引导的设备,搜索的顺序是由 CMOS 中的设置信息决定的(这也是我们平时讲的,所谓的在 BIOS 中设置的启动设备顺序)。一个是软驱,一个是光驱,一个是硬盘上,还可以是网络上的设备甚至是一个 usb 接口的 U 盘,都可以作为一个启动设备。
Linux 通常是从硬盘中启动的。硬盘上的第 1 个扇区(每个扇区 512 字节空间),被称为** MBR(主启动记录)**,其中包含有基本的 GRUB 启动程序和分区表,安装 GRUB 时会自动写入到这个扇区,当 MBR 被 BIOS 装载到 0x7c00 地址开始的内存空间中后,BIOS 就会将控制权转交给了 MBR。在当前的情况下,其实是交给了 GRUB。
到这里,BIOS 到 GRUB 的过程结束。
GRUB是如何启动的
BIOS 只会加载硬盘上的第 1 个扇区。不过这个扇区仅有 512 字节,这 512 字节中还有 64 字节的分区表加 2 字节的启动标志,很显然,剩下 446 字节的空间,是装不下 GRUB 这种大型通用引导器的。
于是,GRUB 的加载分成了多个步骤,同时 GRUB 也分成了多个文件,其中有两个重要的文件 boot.img 和 core.img,如下所示:

其中,boot.img 被 GRUB 的安装程序写入到硬盘的 MBR 中,同时在 boot.img 文件中的一个位置写入 core.img 文件占用的第一个扇区的扇区号。
而 core.img 文件是由 GRUB 安装程序根据安装时环境信息,用其它 GRUB 的模块文件动态生成。如下图所示:

如果是从硬盘启动的话,core.img 中的第一个扇区的内容就是 diskboot.img 文件。diskboot.img 文件的作用是,读取 core.img 中剩余的部分到内存中。
由于这时 diskboot.img 文件还不识别文件系统,所以我们将 core.img 文件的全部位置,都用文件块列表的方式保存到 diskboot.img 文件中。这样就能确保 diskboot.img 文件找到 core.img 文件的剩余内容,最后将控制权交给 kernel.img 文件。
因为这时 core.img 文件中嵌入了足够多的功能模块,所以可以保证 GRUB 识别出硬盘分区上文件系统,能够访问 /boot/grub 目录,并且可以加载相关的配置文件和功能模块,来实现相关的功能,例如加载启动菜单、加载目标操作系统等。
正因为 GRUB2 大量使用了动态加载功能模块,这使得 core.img 文件的体积变得足够小。而 GRUB 的 core.img 文件一旦开始工作,就可以加载 Linux 系统的 vmlinuz 内核文件了。
详解vmlinuz文件结构
我们在 /boot 目录下会发现 vmlinuz 文件,这个文件是怎么来的呢?
其实它是由 Linux 编译生成的 bzImage 文件复制而来的,你自己可以下载最新的 Linux 代码.
我们一致把 Linux 源码解压到一个 linux 目录中,也就是说我们后面查找 Linux 源代码文件总是从 linux 目录开始的,切换到代码目录执行 make ARCH=x86_64,再执行 make install,就会产生 vmlinuz 文件,你可以参考后面的 makefile 代码。
#linux/arch/x86/boot/Makefile
install: sh $(srctree)/$(src)/install.sh $(KERNELRELEASE) $(obj)/bzImage \ System.map "$(INSTALL_PATH)"
install.sh 脚本文件只是完成复制的功能,所以我们只要搞懂了 bzImage 文件结构,就等同于理解了 vmlinuz 文件结构。
那么 bzImage 文件又是怎么来的呢?我们只要研究 bzImage 文件在 Makefile 中的生成规则,就会恍然大悟,代码如下 :
#linux/arch/x86/boot/Makefile
$(obj)/bzImage: $(obj)/setup.bin $(obj)/vmlinux.bin $(obj)/tools/build FORCE $(call if_changed,image) @$(kecho) 'Kernel: $@ is ready' ' (#'`cat .version`')'
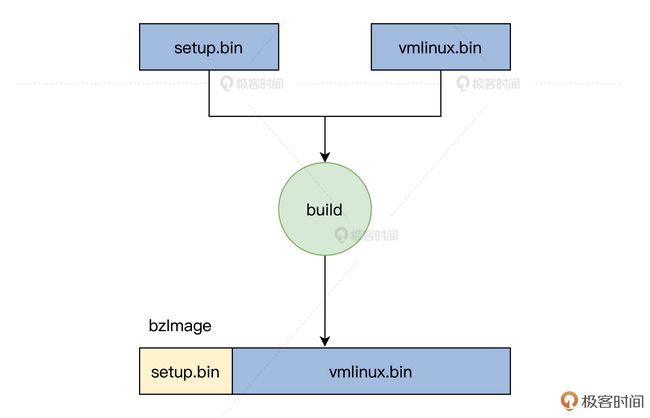
从前面的代码可以知道,生成 bzImage 文件需要三个依赖文件:setup.bin、vmlinux.bin,linux/arch/x86/boot/tools 目录下的 build。
其实,build 只是一个 HOSTOS(正在使用的 Linux)下的应用程序,它的作用就是将 setup.bin、vmlinux.bin 两个文件拼接成一个 bzImage 文件,如下图所示:
setup.elf 文件又怎么生成的呢?我们结合后面的代码来看看。
#这些目标文件正是由/arch/x86/boot/目录下对应的程序源代码文件编译产生
setup-y += a20.o bioscall.o cmdline.o copy.o cpu.o cpuflags.o cpucheck.o
setup-y += early_serial_console.o edd.o header.o main.o memory.o
setup-y += pm.o pmjump.o printf.o regs.o string.o tty.o video.o
setup-y += video-mode.o version.o
#……
SETUP_OBJS = $(addprefix $(obj)/,$(setup-y))
#……
LDFLAGS_setup.elf := -m elf_i386 -T$(obj)/setup.elf: $(src)/setup.ld $(SETUP_OBJS) FORCE $(call if_changed,ld)
#……
OBJCOPYFLAGS_setup.bin := -O binary$(obj)/setup.bin: $(obj)/setup.elf FORCE $(call if_changed,objcopy)
不难发现 setup.bin 文件正是由 /arch/x86/boot/ 目录下一系列对应的程序源代码文件编译链接产生,其中的 head.S 文件和 main.c文件格外重要,
vmlinux.bin 是怎么产生的,构建 vmlinux.bin 的规则依然在 linux/arch/x86/boot/ 目录下的 Makefile 文件中,如下所示:
#linux/arch/x86/boot/Makefile
OBJCOPYFLAGS_vmlinux.bin := -O binary -R .note -R .comment -S$(obj)/vmlinux.bin: $(obj)/compressed/vmlinux FORCE $(call if_changed,objcopy)
vmlinux.bin 文件依赖于 linux/arch/x86/boot/compressed/ 目录下的 vmlinux 目标,下面让我们切换到 linux/arch/x86/boot/compressed/ 目录下继续追踪。打开该目录下的 Makefile,会看到如下代码。
#linux/arch/x86/boot/compressed/Makefile
#……
#这些目标文件正是由/arch/x86/boot/compressed/目录下对应的程序源代码文件编译产生$(BITS)取值32或者64
vmlinux-objs-y := $(obj)/vmlinux.lds $(obj)/kernel_info.o $(obj)/head_$(BITS).o \ $(obj)/misc.o $(obj)/string.o $(obj)/cmdline.o $(obj)/error.o \ $(obj)/piggy.o $(obj)/cpuflags.o
vmlinux-objs-$(CONFIG_EARLY_PRINTK) += $(obj)/early_serial_console.o
vmlinux-objs-$(CONFIG_RANDOMIZE_BASE) += $(obj)/kaslr.o
ifdef CONFIG_X86_64
vmlinux-objs-y += $(obj)/ident_map_64.o
vmlinux-objs-y += $(obj)/idt_64.o $(obj)/idt_handlers_64.o vmlinux-objs-y += $(obj)/mem_encrypt.o
vmlinux-objs-y += $(obj)/pgtable_64.o
vmlinux-objs-$(CONFIG_AMD_MEM_ENCRYPT) += $(obj)/sev-es.o
endif
#……
$(obj)/vmlinux: $(vmlinux-objs-y) $(efi-obj-y) FORCE
$(call if_changed,ld)
结合这段代码我们发现,linux/arch/x86/boot/compressed 目录下的 vmlinux 是由该目录下的 head_32.o 或者 head_64.o、cpuflags.o、error.o、kernel.o、misc.o、string.o 、cmdline.o 、early_serial_console.o 等文件以及 piggy.o 链接而成的。
其中,vmlinux.lds 是链接脚本文件。在没做任何编译动作前,前面依赖列表中任何一个目标文件的源文件(除了 piggy.o 源码),我们几乎都可以在 Linux 内核源码里找到
比如说,head_64.o 对应源文件 head_64.S、string.o 对应源文件 string.c、misc.o 对应源文件 misc.c 等。
那么问题来了,为啥找不到 piggy.o 对应的源文件,比如 piggy.c、piggy.S 或其他文件呢?你需要在 Makefile 文件仔细观察一下,才能发现有个创建文件 piggy.S 的规则,代码如下所示:
#linux/arch/x86/boot/compressed/Makefile
#……
quiet_cmd_mkpiggy = MKPIGGY $@
cmd_mkpiggy = $(obj)/mkpiggy $< > $@
targets += piggy.S
$(obj)/piggy.S: $(obj)/vmlinux.bin.$(suffix-y) $(obj)/mkpiggy FORCE $(call if_changed,mkpiggy)
看到上面的规则,我们豁然开朗,原来 piggy.o 是由 piggy.S 汇编代码生成而来,而 piggy.S 是编译 Linux 内核时由 mkpiggy 工作(HOST OS 下的应用程序)动态创建的,这就是我们找不到它的原因。
piggy.S 的第一个依赖文件 vmlinux.bin.$(suffix-y) 中的 suffix-y,它表示内核压缩方式对应的后缀。
#linux/arch/x86/boot/compressed/Makefile
#……
vmlinux.bin.all-y := $(obj)/vmlinux.bin
vmlinux.bin.all-$(CONFIG_X86_NEED_RELOCS) += $(obj)/vmlinux.relocs
$(obj)/vmlinux.bin.gz: $(vmlinux.bin.all-y) FORCE
$(call if_changed,gzip)
$(obj)/vmlinux.bin.bz2: $(vmlinux.bin.all-y) FORCE
$(call if_changed,bzip2)
$(obj)/vmlinux.bin.lzma: $(vmlinux.bin.all-y) FORCE
$(call if_changed,lzma)
$(obj)/vmlinux.bin.xz: $(vmlinux.bin.all-y) FORCE
$(call if_changed,xzkern)
$(obj)/vmlinux.bin.lzo: $(vmlinux.bin.all-y) FORCE
$(call if_changed,lzo)
$(obj)/vmlinux.bin.lz4: $(vmlinux.bin.all-y) FORCE
$(call if_changed,lz4)
$(obj)/vmlinux.bin.zst: $(vmlinux.bin.all-y) FORCE
$(call if_changed,zstd22)
suffix-$(CONFIG_KERNEL_GZIP) := gz
suffix-$(CONFIG_KERNEL_BZIP2) := bz2
suffix-$(CONFIG_KERNEL_LZMA) := lzma
suffix-$(CONFIG_KERNEL_XZ) := xz
suffix-$(CONFIG_KERNEL_LZO) := lzo
suffix-$(CONFIG_KERNEL_LZ4) := lz4
suffix-$(CONFIG_KERNEL_ZSTD) := zst
由前面内容可以发现,Linux 内核可以被压缩成多种格式。虽然现在我们依然没有搞清楚 vmlinux.bin 文件是怎么来的,但是我们可以发现,linux/arch/x86/boot/compressed 目录下的 Makefile 文件中,有下面这样的代码。
#linux/arch/x86/boot/compressed/Makefile
#……
OBJCOPYFLAGS_vmlinux.bin := -R .comment -S
$(obj)/vmlinux.bin: vmlinux FORCE
$(call if_changed,objcopy)
也就是说,arch/x86/boot/compressed 目录下的 vmlinux.bin,它是由 objcopy 工具通过 vmlinux 目标生成。而 vmlinux 目标没有任何修饰前缀和依赖的目标,这说明它就是最顶层目录下的一个 vmlinux 文件。
我们继续深究一步就会发现,objcopy 工具在处理过程中只是删除了 vmlinux 文件中“.comment”段,以及符号表和重定位表(通过参数 -S 指定),而 vmlinux 文件的格式依然是 ELF 格式的,如果不需要使用 ELF 格式的内核,这里添加“-O binary”选项就可以了。
我们现在来梳理一下,vmlinux 文件是如何创建的。
其实,vmlinux 文件就是编译整个 Linux 内核源代码文件生成的,Linux 的代码分布在各个代码目录下,这些目录之下又存在目录,Linux 的 kbuild(内核编译)系统,会递归进入到每个目录,由该目录下的 Makefile 决定要编译哪些文件。
在编译完具体文件之后,就会在该目录下,把已经编译了的文件链接成一个该目录下的 built-in.o 文件,这个 built-in.o 文件也会与上层目录的 built-in.o 文件链接在一起
再然后,层层目录返回到顶层目录,所有的 built-in.o 文件会链接生成一个 vmlinux 文件,这个 vmlinux 文件会通过前面的方法转换成 vmlinux.bin 文件。但是请注意,vmlinux.bin 文件它依然是 ELF 格式的文件。
最后,工具软件会压缩成 vmlinux.bin.gz 文件,这里我们以 gzip 方式压缩
让我们再次回到 mkpiggy 命令,其中 mkpiggy 是内核自带的一个工具程序,它把输出方式重定向到文件,从而产生 piggy.S 汇编文件,源码如下:
int main(int argc, char *argv[]){
uint32_t olen;
long ilen;
FILE *f = NULL;
int retval = 1;
f = fopen(argv[1], "r");
if (!f) {
perror(argv[1]);
goto bail;
}
//……为节约篇幅略去部分代码
printf(".section \".rodata..compressed\",\"a\",@progbits\n");
printf(".globl z_input_len\n");
printf("z_input_len = %lu\n", ilen);
printf(".globl z_output_len\n");
printf("z_output_len = %lu\n", (unsigned long)olen);
printf(".globl input_data, input_data_end\n");
printf("input_data:\n");
printf(".incbin \"%s\"\n", argv[1]);
printf("input_data_end:\n");
printf(".section \".rodata\",\"a\",@progbits\n");
printf(".globl input_len\n");
printf("input_len:\n\t.long %lu\n", ilen);
printf(".globl output_len\n");
printf("output_len:\n\t.long %lu\n", (unsigned long)olen);
retval = 0;
bail:
if (f)
fclose(f);
return retval;
}
//由上mkpiggy程序“写的”一个汇编程序piggy.S。
.section ".rodata..compressed","a",@progbits
.globl z_input_len
z_input_len = 1921557
.globl z_output_len
z_output_len = 3421472
.globl input_data,input_data_end
.incbin "arch/x86/boot/compressed/vmlinux.bin.gz"
input_data_end:
.section ".rodata","a",@progbits
.globl input_len
input_len:4421472
.globl output_len
output_len:4424772
根据上述代码不难发现,这个 piggy.S 非常简单,使用汇编指令 incbin 将压缩的 vmlinux.bin.gz 毫无修改地包含进来。
除了包含了压缩的 vmlinux.bin.gz 内核映像文件外,piggy.S 中还定义了解压 vmlinux.bin.gz 时需要的各种信息,包括压缩内核映像的长度、解压后的长度等信息。
这些信息和 vmlinux.bin.gz 文件,它们一起生成了 piggy.o 文件,然后 piggy.o 文件和(vmlinux−objs−y)(vmlinux−objs−y)(efi-obj-y) 中的目标文件一起链接生成,最终生成了 linux/arch/x86/boot/compressed 目录下的 vmlinux
解压后内核初始化
为何要从 _start 开始

......setup_header 结构
...... 
前面提到过,硬盘中 MBR 是由 GRUB 写入的 boot.img,因此这里的 linux/arch/x86/boot/head.S 中的 bootsector 对于硬盘启动是无用的。 GRUB 将 vmlinuz 的 setup.bin 部分读到内存地址 0x90000 处,然后跳转到 0x90200 开 始执行,恰好跳过了前面 512 字节的 bootsector,从 _start 开始。
16 位的 main 函数
我们通常用 C 编译器编译的代码,是 32 位保护模式下的或者是 64 位长模式的,却很少编 译成 16 位实模式下的,其实 setup.bin 大部分代码都是 16 位实模式下的。 从前面的代码里,我们能够看到在 linux/arch/x86/boot/head.S 中调用了 main 函数,该 函数在 linux/arch/x86/boot/main.c 文件中,代码如下


上面这些函数都在 linux/arch/x86/boot/ 目录对应的文件中,都是调用 BIOS 中断完成 的,具体细节,你可以自行查看。 我这里列出的代码只是帮助你理清流程,我们继续看看 go_to_protected_mode() 函数, 在 linux/arch/x86/boot/pm.c 中,代码如下。

protected_mode_jump 是个汇编函数,在 linux/arch/x86/boot/pmjump.S 文件中 即跳转到 boot_params.hdr.code32_start 中的地址。 这个地址在 linux/arch/x86/boot/head.S 文件中设为 0x100000,如下所示

需要注意的是,GRUB 会把 vmlinuz 中的 vmlinux.bin 部分,放在 1MB 开始的内存空 间中。通过这一跳转,正式进入 vmlinux.bin 中。
startup_32 函数
startup_32 中需要重新加载段描述符,之后计算 vmlinux.bin 文件的编译生成的地址和实 际加载地址的偏移,然后重新设置内核栈,检测 CPU 是否支持长模式,接着再次计算 vmlinux.bin 加载地址的偏移,来确定对其中 vmlinux.bin.gz 解压缩的地址。 如果 CPU 支持长模式的话,就要设置 64 位的全局描述表,开启 CPU 的 PAE 物理地址扩 展特性。再设置最初的 MMU 页表,最后开启分页并进入长模式,跳转到 startup_64,代 码如下。


startup_64 函数 现在,我们终于开启了 CPU 长模式,从 startup_64 开始真正进入了 64 位的时代,可喜 可贺。 startup_64 函数同样也是在 linux/arch/x86/boot/compressed/head64.S 文件中定义 的。 startup_64 函数中,初始化长模式下数据段寄存器,确定最终解压缩地址,然后拷贝压缩 vmlinux.bin 到该地址,跳转到 decompress_kernel 地址处,开始解压 vmlinux.bin.gz,


上述代码中最后到了 extract_kernel 函数,它就是解压内核的函数,下面我们就来研究 它。
extract_kernel 函数
从 startup_32 函数到 startup_64 函数,其间经过了保护模式、长模式,最终到达了 extract_kernel 函数,extract_kernel 函数根据 piggy.o 中的信息从 vmlinux.bin.gz 中解 压出 vmlinux。 根据前面的知识点,我们知道 vmlinux 正是编译出 Linux 内核 elf 格式的文件,只不过它 被去掉了符号信息。所以,extract_kernel 函数不仅仅是解压,还需要解析 elf 格式。 extract_kernel 函数是在 linux/arch/x86/boot/compressed/misc.c 文件中定义的

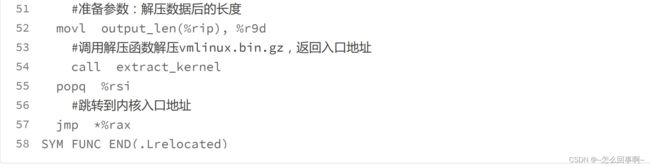
正如上面代码所示,extract_kernel 函数调用 __decompress 函数,对 vmlinux.bin.gz 使 用特定的解压算法进行解压。解压算法是编译内核的配置选项决定的。 但是,__decompress 函数解压出来的是 vmlinux 文件是 elf 格式的,所以还要调用 parse_elf 函数进一步解析 elf 格式,把 vmlinux 中的指令段、数据段、BSS 段,根据 elf 中信息和要求放入特定的内存空间,返回指令段的入口地址。
请你注意,在 Lrelocated 函数的最后一条指令:jmp *rax,其中的 rax 中就是保存的 extract_kernel 函数返回的入口点,就是从这里开始进入了 Linux 内核
Linux 内核的 startup_64
这里我提醒你留意,此时的 startup_64 函数并不是之前的 startup_64 函数,也不参与 前面的链接工作。 这个 startup_64 函数定义在 linux/arch/x86/kernel/head_64.S 文件中,它是内核的入口 函数,如下所示。

上述代码中省略了和流程无关的代码,对于 SMP 系统加电之后,总线仲裁机制会选出多个 CPU 中的一个 CPU,称为 BSP,也叫第一个 CPU。它负责让 BSP CPU 先启动,其它 CPU 则等待 BSP CPU 的唤醒。
这里我来分情况给你说说。对于第一个启动的 CPU,会跳转 secondary_startup_64 函数 中 1 标号处,对于其它被唤醒的 CPU 则会直接执行 secondary_startup_64 函数。 接下来,我给你快速过一遍 secondary_startup_64 函数,后面的代码我省略了这个函数 对更多 CPU 特性(设置 GDT、IDT,处理了 MMU 页表等)的检查,因为这些工作我们 早已很熟悉了,代码如下所示。

在 secondary_startup_64 函数一切准备就绪之后,最后就会调用 x86_64_start_kernel 函 数,看它的名字好像是内核的开始函数,但真的是这样吗,我们一起看看才知道
Linux 内核的第一个 C 函数
若不是经历了前面的分析讲解。要是我问你 Linux 内核的第一个 C 函数是什么,你可能无 从说起,就算一通百度之后,仍然无法确定.
但是,只要我们跟着代码的执行流程,就会发现在 secondary_startup_64 函数的最后, 调用的 x86_64_start_kernel 函数是用 C 语言写的,那么它一定就是 Linux 内核的第一 个 C 函数。它在 linux/arch/x86/kernel/head64.c 文件中被定义,这个文件名你甚至都能 猜出来,如下所示。

x86_64_start_kernel 函数中又一次处理了页表,处理页表就是处理 Linux 内核虚拟地址空 间,Linux 虚拟地址空间是一步步完善的。 然后,x86_64_start_kernel 函数复制了引导信息,即 struct boot_params 结构体。最后 调用了 x86_64_start_reservations 函数,其中处理了平台固件相关的东西,就是调用了大 名鼎鼎的 start_kernel 函数。
有名的 start_kernel 函数
start_kernel 函数之所以有名,这是因为在互联网上,在各大 Linux 名著之中,都会大量 宣传它 Linux 内核中的地位和作用,正如其名字表达的含意,这是内核的开始。 但是问题来了。我们一路走来,发现 start_kernel 函数之前有大量的代码执行,那这些代 码算不算内核的开始呢?当然也可以说那就是内核的开始,也可以说是前期工作。
其实,start_kernel 函数中调用了大量 Linux 内核功能的初始化函数,它定义在 /linux/init/main.c 文件中。
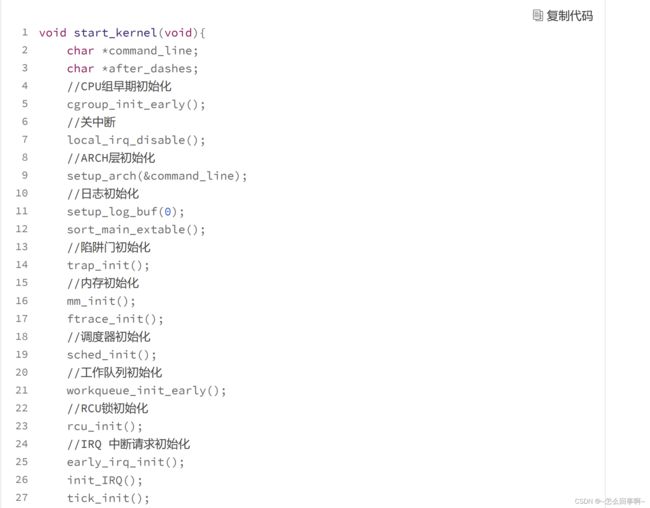


start_kernel 函数我如果不做精简,会有 200 多行,全部都是初始化函数,我只留下几个 主要的初始化函数,这些函数的实现细节我们无需关心。 可以看到,Linux 内核所有功能的初始化函数都是在 start_kernel 函数中调用的,这也是 它如此出名,如此重要的原因。 一旦 start_kernel 函数执行完成,Linux 内核就具备了向应用程序提供一系列功能服务的 能力。这里对我们而言,我们只关注一个 arch_call_rest_init 函数。下面我们就来研究 它。 如下所示。

rest_init 函数的重要功能就是建立了两个 Linux 内核线程,我们看看精简后的 rest_init 函数:

Linux 内核线程可以执行一个内核函数, 只不过这个函数有独立的线程上下文,可以被 Linux 的进程调度器调度,对于 kernel_init 线程来说,执行的就是 kernel_init 函数
Linux 的第一个用户进程
当我们可以建立第一个用户进程的时候,就代表 Linux 内核的初始流程已经基本完成。 经历了“长途跋涉”,我们也终于走到了这里。Linux 内核的第一个用户态进程是在 kernel_init 线程建立的,而 kernel_init 线程执行的就是 kernel_init 函数。那 kernel_init 函数到底做了什么呢?
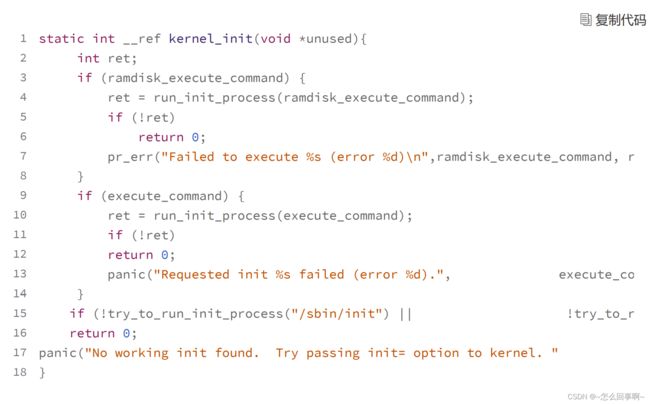
结合上述代码,可以发现 ramdisk_execute_command 和 execute_command 都是内核 启动时传递的参数,它们可以在 GRUB 启动选项中设置。 比方说,通常引导内核时向 command line 传递的参数都是 init=xxx ,而对于 initrd 则 是传递 rdinit=xxx 。
但是,通常我们不会传递参数,所以这个函数会执行到上述代码的 15 行,依次尝试以 /sbin/init、/etc/init、/bin/init、/bin/sh 这些文件为可执行文件建立进程,但是只要其中 之一成功就行了 。
try_to_run_init_process 和 run_init_process 函数的核心都是调用 sys_fork 函数建立进 程的,这里我们不用关注它的实现细节。 到这里,Linux 内核已经建立了第一个进程,Linux 内核的初始化流程也到此为止。
重点回顾
又到了课程尾声,Linux 初始化流程的学习我们就告一段落了,我来给你做个总结。
今天我们讲得内容有点多,我们从 _start 开始到 startup32、startup64 函数 ,到 extract_kernel 函数解压出真正的 Linux 内核文件 vmlinux 开始,然后从 Linux 内核的入 口函数 startup_64 到 Linux 内核第一个 C 函数,最后接着从 Linux 内核 start_kernel 函 数的建立 ,说到了第一个用户进程。
一起来回顾一下这节课的重点:
1.GRUB 加载 vmlinuz 文件之后,会把控制权交给 vmlinuz 文件的 setup.bin 的部分中 _start,它会设置好栈,清空 bss,设置好 setup_header 结构,调用 16 位 main 切换到 保护模式,最后跳转到 1MB 处的 vmlinux.bin 文件中。
2. 从 vmlinux.bin 文件中 startup32、startup64 函数开始建立新的全局段描述符表和 MMU 页表,切换到长模式下解压 vmlinux.bin.gz。释放出 vmlinux 文件之后,由解析 elf 格式的函数进行解析,释放 vmlinux 中的代码段和数据段到指定的内存。然后调用其中 的 startup_64 函数,在这个函数的最后调用 Linux 内核的第一个 C 函数。
3.Linux 内核第一个 C 函数重新设置 MMU 页表,随后便调用了最有名的 start_kernel 函 数, start_kernel 函数中调用了大多数 Linux 内核功能性初始化函数,在最后调用 rest_init 函数建立了两个内核线程,在其中的 kernel_init 线程建立了第一个用户态进程。