软件测试/测试开发丨学习笔记之用户端Web自动化测试
本文为霍格沃兹测试开发学社学员学习笔记分享
原文链接:https://ceshiren.com/t/topic/24862
一、Web自动化测试复用浏览器
1、复用浏览器简介


2、为什么要复用浏览器的
1)自动化测试过程中,存在人为介入场景
2)提高调试UI自动化测试脚本效率
3、复用已有浏览器-配置步骤
1)需要退出当前所有的谷歌浏览器(特别注意)
2)输入启动命令,通过命令启动谷歌浏览器
①找到 chrome 的启动路径
②配置环境变量
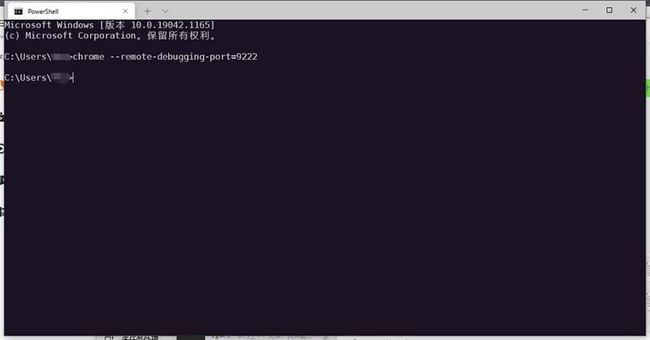
3)验证是否启动成功
windows:chrome --remote-debugging-port=9222
mac:Google Chrome --remote-debugging-port=9222
(执行后,打开浏览器,输入localhost:9222)验证是否启动成功
4、windows 环境变量配置
1)获取启动路径
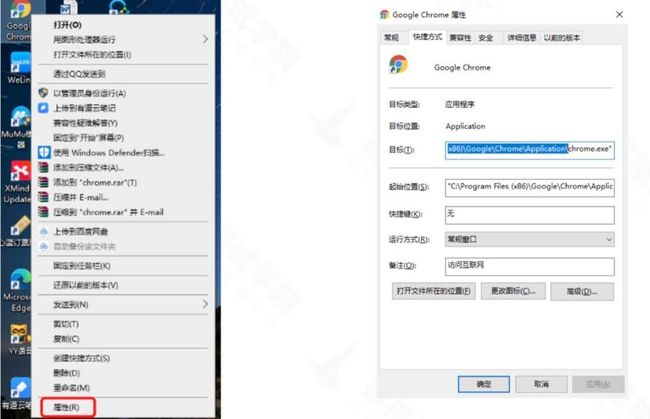
2)配置环境变量

3)重启命令行
4)windows关闭谷歌浏览器进程(打开任务管理器)

5、Mac 环境变量配置
1)获取启动路径(注意:使用 tab 键,不要手动输入)
2)将启动路径配置到环境变量中
举例:
export PATH=$PATH:/Applications/Google\ Chrome.app/Contents/MacOS
6、复用已有浏览器-代码设置(Python)
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
# 定义配置的实例对象option
option = Options()
# 修改实例属性为 debug 模式启动的 ip + 窗口
option.debugger_address = "localhost:9222"
# 实例化 driver的时候,添加option配置
driver = webdriver.Chrome(options=option)
# driver.get("https://work.weixin.qq.com/wework_admin/frame") # ①
# 扫码登录之后,点击添加学员操作
# driver.find_element(By.XPATH, "//*[text()='添加成员']").click() # ②
driver.find_element(By.ID, "username").send_keys("username001") # 输入姓名
driver.find_element(By.ID, "memberAdd_english_name").send_keys("othername") # 输入别名
二、Web自动化测试之Cookie登录
1、cookie 是什么
1)Cookie 是一些认证数据信息,存储在电脑的浏览器上
2)当 web 服务器向浏览器发送 web 页面时,在连接关闭后,服务端不会记录用户的信息
2、为什么要使用Cookie自动化登录
1)复用浏览器仍然在每次用例开始都需要人为介入
2)若用例需要经常执行,复用浏览器则不是一个好的选择
3)大部分cookie的时效性都很长,扫一次可以使用多次

3、常见问题,企业微信为例:
1)企业微信cookie有互踢机制。在获取cookie成功之后。不需要再进行扫码操作
2)获取cookie的时候,即执行代码获取cookie时,一定要确保已经登录
3)植入cookie之后需要进入登录页面,刷新验证是否自动登录成功。
4、python语言
获取 cookie driver.get_cookies()
添加 cookie driver.add_cookie(cookie)
import time
import yaml
from selenium import webdriver
class TestCookieLogin:
def setup_class(self):
self.driver = webdriver.Chrome()
# 获取cookie
def test_get_cookies(self):
# 登录企业微信页面,先登录再获取cookie
self.driver.get("https://work.weixin.qq.com/wework_admin/frame#contacts")
time.sleep(20) # 等待20秒,人工扫码登录
# 登录成功后获取cookie
cookie = self.driver.get_cookies()
# 将cookie写入一个可持久存储的地方,如数据库、文件
# 打开文件时添加写权限
with open("cookie.yaml", "w") as f:
# 第一个参数是需要写入的数据
yaml.safe_dump(cookie, f)
# cookie植入
def test_add_cookies(self):
# 访问企业微信主页面
self.driver.get("https://work.weixin.qq.com/wework_admin/frame#contacts")
# 定义cookie,cookie信息从已经写入的cookie文件中获取
cookies = yaml.safe_load(open("cookie.yaml"))
# 植入cookie
for c in cookies:
self.driver.add_cookie(c)
time.sleep(3) # 强制等待
# 再次访问企业微信页面
self.driver.get("https://work.weixin.qq.com/wework_admin/frame#contacts")
三、pageobject设计模式
1、page object 模式简介
PO设计模式|selenium:
https://www.selenium.dev/zh-cn/documentation/test_practices/encouraged/page_object_models/
PageObject:https://martinfowler.com/bliki/PageObject.html
2、传统 UI 自动化的问题
1)无法适应 UI 频繁变化
2)无法清晰表达业务用例场景
3)大量的样板代码 driver/find/click
3、POM 模式的优势
1)降低 UI 变化导致的测试用例脆弱性问题
2)让用例清晰明朗,与具体实现无关
4、POM 建模原则
1)字段意义
①不要暴露页面内部的元素给外部
②不需要建模 UI 内的所有元素
2)方法意义
①用公共方法代表 UI 所提供的功能
②方法应该返回其他的 PageObject 或者返回用于断言的数据
③同样的行为不同的结果可以建模为不同的方法
④不要在方法内加断言
5、POM 使用方法
1)把元素信息和操作细节封装到 PageObject 类中
2)根据业务逻辑,在测试用例中链式调用
"""代码示例"""
# test_search.py
# 传统线性脚本,传统测试用例
from selenium import webdriver
from selenium.webdriver.common.by import By
class TestSearch:
def test_search(self):
# 初始化浏览器
self.driver = webdriver.Chrome()
self.driver.get("https://xueqiu.com/")
self.driver.implicitly_wait(3)
# 输入搜索关键词
self.driver.find_element(By.NAME, "q").send_keys("阿里巴巴-SW")
# 点击搜索按钮
self.driver.find_element(By.CSS_SELECTOR, "i.search").click()
# 获取搜索结果
name = self.driver.find_element(By.XPATH, "//table//strong").text
# 断言
assert name == "阿里巴巴-SW"
# 脚本优化——>POM 脚本search_page.py
from selenium import webdriver
from selenium.webdriver.common.by import By
class SearchPage:
__INPUT_SEARCH = (By.NAME, "q")
__BUTTON_SEARCH = (By.CSS_SELECTOR, "i.search")
__SPAN_STOCK = (By.XPATH, "//table//strong")
def __init__(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
self.driver.get("https://xueqiu.com/")
def search_stock(self, stock_name: str):
self.driver.find_element(*self.__INPUT_SEARCH).send_keys(stock_name)
self.driver.find_element(*self.__BUTTON_SEARCH).click()
name = self.driver.find_element(By.XPATH, "//table//strong").text
return name
# PO 模式测试用例 test_search_pom.py
from webui.pageobject.search_page import SearchPage
class TestSearchPom:
def test_search_pom(self):
text = SearchPage().search_stock("阿里巴巴-SW")
# 断言
assert "阿里巴巴-SW" == text
四、异常自动截图
1、异常截图的目的(使用场景)
1)增加自动化测试代码的可测性
2)丰富报告
2、异常截图实现原理
1)装饰器
2)自动化关键数据记录:截图、日志、page_source
import time
import allure
from selenium import webdriver
from selenium.webdriver.common.by import By
"""问题:异常捕获处理代码和业务代码无关,不能耦合,如有多条用例就要写多个异常捕获
解决:使用装饰器装饰用例或者相关方法,就不会体现在源码中了
"""
# 装饰器的外函数需要一个形参代表函数对象
# 问题:需要通过driver实例截图和打印page_source,装饰器需要先去获取driver实例对象
# 解决:
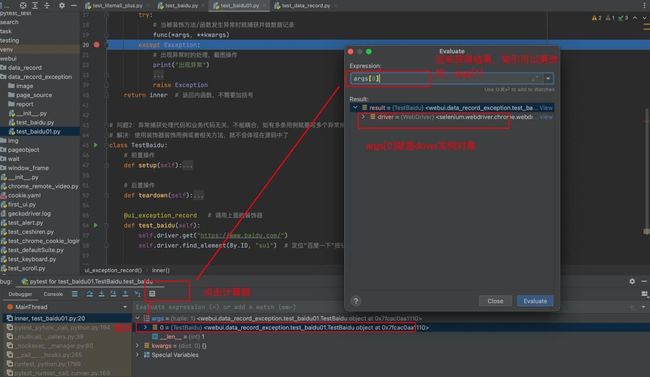
def ui_exception_record(func):
def inner(*args, **kwargs): # 内函数
# 获取被装饰方法的self,如def test_baidu(self)方法中的self,即实例对象
# 通过self就可以拿到声明的实例变量
# 前提条件,被装饰的方法是一个实例方法,实例需要有实例变量self.driver
# 注意:要保证使用装饰器时,driver已经声明,在用例类里面的前置操作对self.driver声明,也可以将driver = args[0].driver放在except Exception里面的第一行
# driver = args[0].driver
try:
# 当被装饰方法/函数发生异常时就捕获并做数据记录
return func(*args, **kwargs) # 这里会执行被装饰函数
except Exception:
driver = args[0].driver
# 出现异常时的处理,截图操作
timestamp = int(time.time()) # 获取当前时间的时间戳
# 提前创建好image和pagesource路径
image_path = f"./image/image_{timestamp}.PNG"
page_source_path = f"./page_source/page_source_{timestamp}.html "
# 截图
driver.save_screenshot(image_path)
# 记录page_source,将获取的page_source写入到record.html
with open(page_source_path, "w", encoding="utf-8") as f:
f.write( driver.page_source)
# 将截图放到报告中
allure.attach.file(image_path, name="picture", attachment_type=allure.attachment_type.PNG)
# 将pagesource记录放到报告中
# 想要html的源码可以将attachment_type=allure.attachment_type.TEXT
allure.attach.file(page_source_path, name="pagesource", attachment_type=allure.attachment_type.TEXT)
# 问题1:异常处理会影响用例本身的结果,如本来就是有异常的用例,却通过了
# 解决:在exception之后再把异常抛出
raise Exception
return inner # 返回内函数,不需要加括号
# 问题2:异常捕获处理代码和业务代码无关,不能耦合,如有多条用例就要写多个异常捕获
# 解决:使用装饰器装饰用例或者相关方法,就不会体现在源码中了
class TestBaidu:
# 前置操作
def setup(self):
self.driver = webdriver.Chrome() # driver声明
# 后置操作
def teardown(self):
self.driver.quit()
# 如果装饰器中的try没有return,被装饰方法有返回值时,会丢失返回值,其他方法调用就没有返回值
# @ui_exception_record
# def find(self):
# return self.driver.find_element(By.ID, "su") # 返回find_element对象
@ui_exception_record # 调用上面的装饰器
def test_baidu(self):
self.driver.get("https://www.baidu.com/")
# self.find().click() # 调用find()方法的返回对象,并点击
self.driver.find_element(By.ID, "su").click() # 定位"百度一下"按钮


五、测试用例流程设计
1、自动化测试用例流程
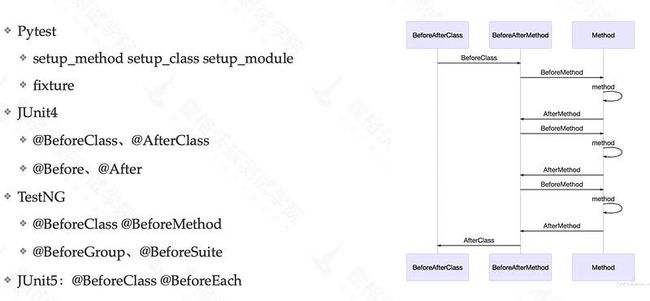
2、web自动化测试-用例设计
【类型:框架对应:作用】
前置:
setup_class/BeforeAll:准备测试数据、实例的初始化
setup/BeforeEach:恢复用例初始状态、数据清理(也可以在用例级别完成)
后置:
teardown_class/AfterAll:driver进程退出
teardown/AfterEach:恢复用例初始状态、数据清理(也可以在用例级别完成)
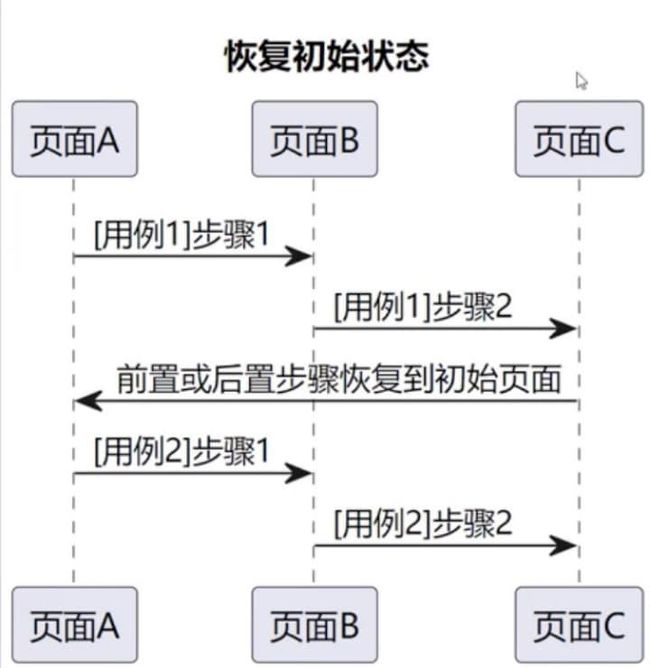
3、恢复用例初始状态
1)场景:单条用例执行完成之后如果不恢复下一条用例的开始状态(回复用例初始页面),则会影响下一条用例的执行。
2)解决方案:
①每条用例执行完成都quit()(影响执行效率)
②封装一个方法,用例执行完成之后回到首页
例子:
1)用例1 执行过程经过A->B->C 三个页面
2)用例2 执行过程经过A->B->C 三个页面
3)用例1 执行完成之后执行用例2
"""title 不恢复初始状态"""
participant 页面A as p1
participant 页面B as p2
participant 页面C as p3
p1 -> p2: [用例1]步骤1
p2 -> p3: [用例1]步骤2
p3 x-> p2: [用例2]步骤1

"""title 恢复初始状态"""
participant 页面A as p1
participant 页面B as p2
participant 页面C as p3
p1 -> p2: [用例1]步骤1
p2 -> p3: [用例1]步骤2
p3 -> p1: 前置或后置步骤恢复到初始页面
p1 -> p2: [用例2]步骤1
p2 -> p3: [用例2]步骤2
4、数据清理
1)清理策略
①在前置处理中执行
②在后置处理中执行
2)清理方式
①调用业务接口
②通过UI自动化方式操作
③连接数据库执行SQL(不推荐)
六、selenium多浏览器处理
1、多浏览器测试概述
1)是跨不同浏览器组合验证网站或 web 应用程序功能的过程
2)是兼容性测试的一个分支,用于保持功能和质量的一致性
3)适用于面向客户的网站和组织内部使用的站点
2、多浏览器的实现方案
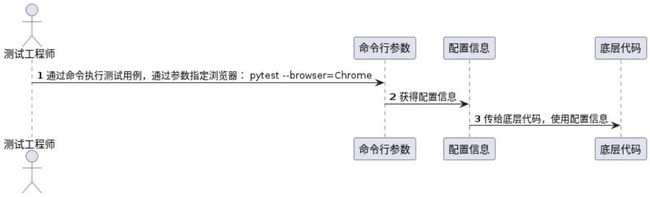
3、pytest hook 函数
1)pytest_addoption 添加命令行参数组/命令行参数
2)pytest_configure 解析命令行选项,每个插件都会用到这个hook函数
4、pytest_addoption 与 pytest_configure
(1)pytest_addoption:
1)parser.getgroup 创建/获取组名
2)addoption 添加一个命令行选项
(2)pytest_configure:
1)通过config 对象的getoption()方法获取命令行参数
2)将命令行获取到的内容赋值给变量
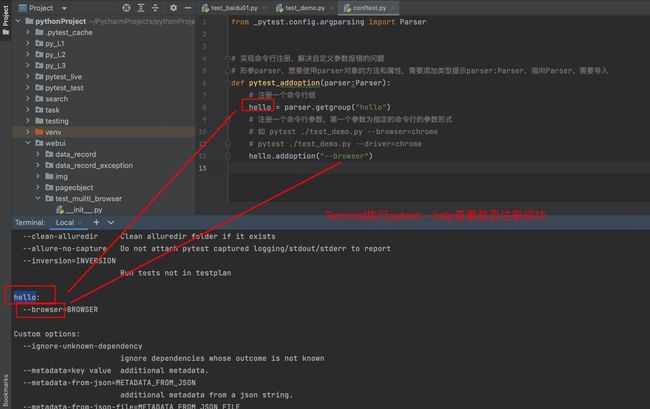
conftest.py文件代码
from _pytest.config import Config
from _pytest.config.argparsing import Parser
web_env = {}
# 实现命令行注册,解决自定义参数报错的问题
# 形参parser,想要使用parser对象的方法和属性,需要添加类型提示parser:Parser,指向Parser,需要导入
def pytest_addoption(parser: Parser):
# 注册一个命令行组
hello = parser.getgroup("hello")
# 注册一个命令行参数,第一个参数为指定的命令行的参数形式
# 如 pytest ./test_demo.py --browser=chrome
# pytest ./test_demo.py --driver=chrome
# default默认的浏览器,dest重命名,将--browser更改为browser,help
hello.addoption("--browser", default="firefox", dest="browser", help="指定执行到浏览器")
def pytest_configure(config: Config): # config是一个对象
browser = config.getoption("browser") # 获取的是pytest_addoption方法中hello.addoption中的"--browser"
print(f"通过命令行获取到浏览器为{browser}")
web_env["browser"] = browser # 将命令行获取到的内容赋值给变量web_env
#测试用例文件test_browser.py
from selenium import webdriver
from webui.test_muliti_browser.conftest import web_env
class TestBrowser:
def setup_class(self):
#
self.browser = web_env.get("browser")
def test_browser(self):
print(f"获取到的浏览器信息为{self.browser}")
if self.browser == "firefox":
self.driver = webdriver.Firefox()
else:
self.driver = webdriver.Chrome()
self.driver.get("https://ceshiren.com/")
self.driver.quit()
5、命令行参数处理
1)通过 pytest_addoption hook 函数,配置命令行参数
2)通过 pytest_configure 函数,接收命令行参数信息
3)将参数保存到变量中
七、执行 javascript 脚本
1、JavaScript简介
1)JavaScript 是一种具有函数优先的轻量级,解释型或即时编译型的编程语言
2)可以嵌入到HTML页面对浏览器事件做出响应
3)也可以基于Node.js技术进行服务器端编程
2、自动化测试中使用JavaScript脚本
使用场景:部分场景使用selenium原生方法无法解决,如修改时间控件、滚动到某个元素、其他场景等
3、JavaScript调试方法
1)进入 console 调试
2)js 脚本如果有返回值则会在浏览器返回
4、JS 脚本-元素操作
1)通过 css 查找元素
①点击元素(对应click)
②input标签对应的值(对应send_keys)
③元素的类属性
④元素的文本属性
获取属性的值.value,如获取百度输入框的值,元素获取采用css表达式
document.querySelector("#kw").value
修改属性的值,如修改输入框内的值为"python语言",修改的值必须是input标签对应的值
document.querySelector("#kw").value="python语言"
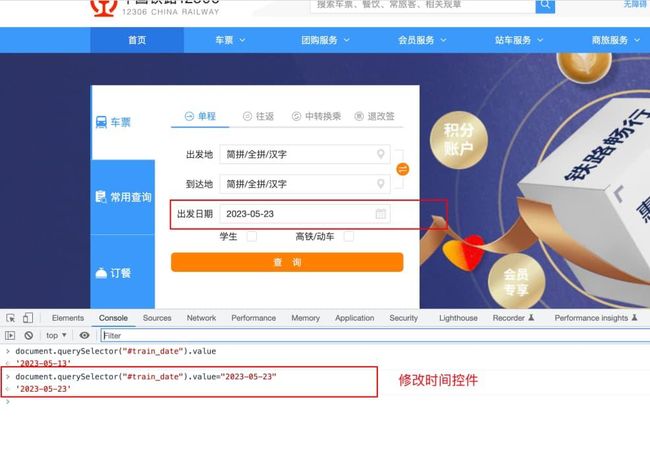
# 修改时间控件的值
document.querySelector("#train_date").value="2023-05-23"
点击按钮
document.querySelector("#su").click()
输入内容并点击搜索按钮,两个表达式使用分号隔开
document.querySelector("#kw").value="go语言";document.querySelector("#su").click()
定位“我的淘宝”元素
document.querySelector("#J_SiteNavMytaobao")
获取“我的淘宝”下拉框的悬停类属性值
document.querySelector("#J_SiteNavMytaobao").className
修改类属性的值,达到悬停效果
document.querySelector("#J_SiteNavMytaobao").className="site-nav-menu site-nav-mytaobao site-nav-multi-menu J_MultiMenu site-nav-menu-hover"
获取元素内的文本信息
document.querySelector("#ember90").innerText



5、JS脚本滚动操作
1)页面滚动到底部
document.documentElement.scrollTop="10000"
2)指定到滚动的位置
document.querySelector('[data-topic-id="22037"]').scrollIntoView()
6、Selenium执行js
1)Selenium执行js
①调用执行js方法
②在 js 语句中添加 return:代码可以获取js的执行结果
③结合 find_element 方法
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
"""案例一:通过属性修改展示下拉框
打开淘宝首页https://www.taobao.com/
修改下拉框属性
点击悬浮框内的选项"""
def test_taobao_js():
driver = webdriver.Chrome()
# 打开淘宝地址
driver.get("https://www.taobao.com/")
driver.implicitly_wait(3) # 隐式等待
# 修改类属性值,使得"我的淘宝"下拉框悬停
driver.execute_script('document.querySelector("#J_SiteNavMytaobao").className="site-nav-menu site-nav-mytaobao site-nav-multi-menu J_MultiMenu site-nav-menu-hover"')
# 定位到下拉选项"已买到的宝贝",并点击
driver.find_element(By.XPATH, "//*[text()='已买到的宝贝']").click()
time.sleep(5)
driver.quit()
"""案例二:通过属性修改时间控件的值
打开12306网站
修改时间控件值
打印出发日期"""
def test_12306_js():
driver = webdriver.Chrome()
# 打开淘宝地址
driver.get("https://www.12306.cn/index/")
driver.implicitly_wait(3) # 隐式等待
# 修改时间控件的信息
driver.execute_script('document.querySelector("#train_date").value="2023-05-23"')
# 获取时间控件的信息并返回所选日期的值给到date_data
date_data = driver.execute_script('return document.querySelector("#train_date").value')
# 打印出发日期
print(f"获取的时间信息为{date_data}")
八、headless无头浏览器使用
1、Options概述
1)是一个配置浏览器启动的选项类,用于自定义和配置Driver会话
2)常见使用场景:
①设置无头模式:不会显示调用浏览器,避免人为干扰的问题。
②设置调试模式:调试自动化测试代码(浏览器复用)
2、添加启动配置(arguments)
1)无头模式: --headless
2)窗体最大化 start-maximized
3)指定浏览器分辨率 window-size=1920x3000
from selenium import webdriver
from selenium.webdriver.common.by import By
def test_options():
# 在实例化driver对象之前,需要先定义好配置信息
options = webdriver.ChromeOptions()
# 在浏览器启动之前,就配置完成,窗口最大化的配置
options.add_argument("start-maximized")
# 指定浏览器分辨率
options.add_argument("window-size=1920x3000")
# 无头模式,浏览器不会显示的启动在机器上
options.add_argument("--headless")
# 实例化一个driver对象,注意:配置对象option 要通过chrome_options参数添加
driver = webdriver.Chrome(chrome_options=options)
driver.get("https://ceshiren.com/")
# 获取登录按钮的文本信息
login_text = driver.find_element(By.CSS_SELECTOR, ".login-button").text
print(login_text)
driver.quit()
九、capability配置参数解析与分布式运行
1、capability概述
1)Capabilities是WebDriver支持的标准命令之外的扩展命令(配置信息)
2)配置web驱动的属性,如浏览器名称、浏览器平台等。
3)结合Selenium Grid完成分布式、兼容性等测试
4)官网地址: https://www.selenium.dev/zh-cn/documentation/webdriver/capabilities/shared/
from selenium import webdriver
from selenium.webdriver.common.by import By
def test_ceshiren():
# 本机是Mac,切换成 windows 就会报错
capabilities = {"browserName": "chrome", "platformName": "mac"}
# 通过 desired_capabilities 添加配置信息
driver = webdriver.Chrome(desired_capabilities=capabilities)
driver.implicitly_wait(5) # 隐式等待
driver.get("https://ceshiren.com/")
driver.quit()
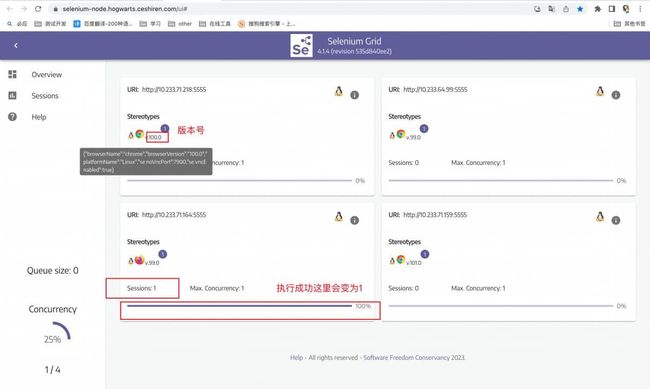
2、Selenium Grid
1)Selenium Grid 允许我们在多台机器上并行运行测试,并集中管理不同的浏览器版本和浏览器配置(而不是在每个单独的测试中)。
2)官网地址:https://www.selenium.dev/documentation/grid/

3)保证本地可以正常调通
4)实例化Remote()类并添加相应的配置:远程地址、设备配置
from selenium import webdriver
from selenium.webdriver.common.by import By
def test_ceshiren_grid():
# 1.本地可以调通
# 2.切换为webdriver.Remote
# driver = webdriver.Chrome()
# 主控hub的地址:域名+/wd/hub
executor_url = "https://selenium-node.hogwarts.ceshiren.com/wd/hub"
# capabilities = {"browserName": "chrome", "browserVersion": "100.0"}
capabilities = {"browserName": "firefox"} # 不需要版本
# 实例化Remote,获取可以远程控制的driver实例对象
# 通过 command_executor 配置selenium hub地址
# 通过 desired_capabilities 添加配置信息
driver = webdriver.Remote(command_executor=executor_url, desired_capabilities=capabilities)
driver.implicitly_wait(5) # 隐式等待
driver.get("https://ceshiren.com/")
login_text = driver.find_element(By.CSS_SELECTOR, ".login-button").text
print(login_text)