Android性能优化系列篇(三):崩溃优化+卡顿优化
前言
汇总了一下众多大佬的性能优化文章,知识点,主要包含:
UI优化/启动优化/崩溃优化/卡顿优化/安全性优化/弱网优化/APP深度优化等等等~
本篇是第三篇:崩溃优化+卡顿优化 [非商业用途,如有侵权,请告知我,我会删除]
强调一下: 性能优化的开发文档跟之前的面试文档一样,需要的跟作者直接要。
三、崩溃优化
3.1 崩溃分析
崩溃率是衡量一个应用质量高低的基本指标:
- Android 崩溃分为 Java 崩溃和 Native 崩溃:
- Java 崩溃就是在 Java 代码中,出现了未捕获异常,导致程序异常退出;
- Native 崩溃又是怎么产生的呢?一般都是因为在 Native 代码中访问非法地址, 也可能是地址对齐出现了问题,或者发生了程序主动 abort,这些都会产生相应的 signal 信号,导致程序异常退出。
- Native崩溃的捕获流程
完整的 Native 崩溃从捕获到解析的流程:
- 编译端。编译 C/C++ 代码时,需要将带符号信息的文件保留下来
- 客户端。捕获到崩溃时候,将收集到尽可能多的有用信息写入日志文件,然后选择合适的时机上传到服务器。
- 服务端。读取客户端上报的日志文件,寻找适合的符号文件,生成可读的 C/C++ 调用栈。
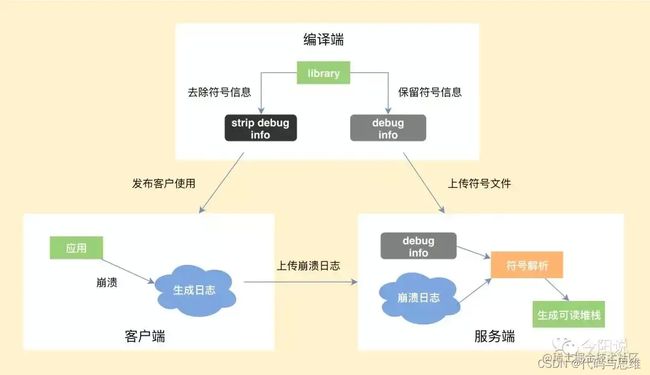
Native 崩溃捕获的难点
上面的三个流程中,最核心的是怎么样保证客户端在各种极端情况下依然可以生成崩溃日志。因为在崩溃时,程序会处于一个不安全的状态,如果处理不当,非常容易发生二次崩溃。那么,生成崩溃日志时会有哪些比较棘手的情况呢?
情况一: 文件句柄泄漏,导致创建日志文件失败,怎么办?应对方式:我们需要提前申请文件句柄 fd 预留,防止出现这种情况。
情况二: 因为栈溢出了,导致日志生成失败,怎么办?应对方式:为了防止栈溢出导致进程没有空间创建调用栈执行处理函数,我们通常会使用常见的 signalstack。在一些特殊情况,我们可能还需要直接替换当前栈,所以这里也需要在堆中预留部分空间。
情况三: 整个堆的内存都耗尽了,导致日志生成失败,怎么办?应对方式:这个时候我们无法安全地分配内存,也不敢使用 stl 或者 libc 的函数,因为它们内部实现会分配堆内存。这个时候如果继续分配内存,会导致出现堆破坏或者二次崩溃的情况。Breakpad 做的比较彻底,重新封装了Linux Syscall Support,来避免直接调用 libc。
情况四: 堆破坏或二次崩溃导致日志生成失败,怎么办?应对方式:Breakpad 会从原进程 fork 出子进程去收集崩溃现场,此外涉及与 Java 相关的,一般也会用子进程去操作。这样即使出现二次崩溃,只是这部分的信息丢失,我们的父进程后面还可以继续获取其他的信息。在一些特殊的情况,我们还可能需要从子进程 fork 出孙进程。
选择合适的崩溃服务
对于很多中小型公司来说,并不建议自己去实现一套如此复杂的系统,可以选择一些第三方的服务。目前各种平台也是百花齐放,包括腾讯的Bugly、阿里的啄木鸟平台、网易云捕、Google 的 Firebase 等等
3.2 崩溃现场应采集哪些信息
1. 崩溃信息:
- 进程名、线程名:
崩溃的进程是前台进程还是后台进程,崩溃是不是发生在 UI 线程。
- 崩溃堆栈和类型:
属于 Java 崩溃、Native 崩溃,还是 ANR
2. 系统信息
- Logcat: 这里包括应用、系统的运行日志
- 机型、系统、厂商、CPU、ABI、Linux 版本等
- 设备状态:是否root、是否是模拟器
3. 内存信息
OOM、ANR、虚拟内存耗尽等,很多崩溃都跟内存有直接关系
- 系统剩余内存:
当系统可用内存很小(低于 MemTotal 的 10%)时,OOM、大量 GC、系统频繁自杀拉起等问题都非常容易出现
- 应用使用内存:
包括 Java 内存、RSS(Resident Set Size)、PSS(Proportional Set Size),我们可以得出应用本身内存的占用大小和分布
- 虚拟内存:
可以通过 /proc/self/status 得到,通过 /proc/self/maps 文件可以得到具体的分布情况,有时候我们一般不太重视虚拟内存,但是很多类似 OOM、tgkill 等问题都是虚拟内存不足导致的
4. 资源信息
有的时候我们会发现应用堆内存和设备内存都非常充足,还是会出现内存分配失败的情况,这跟资源泄漏可能有比较大的关系
- 文件句柄 fd:
文件句柄的限制可以通过 /proc/self/limits 获得,一般单个进程允许打开的最大文件句柄个数为 1024。 但是如果文件句柄超过 800 个就比较危险,需要将所有的 fd 以及对应的文件名输出到日志中,进一步排查是否出现了有文件或者线程的泄漏
- 线程数:
当前线程数大小可以通过上面的 status 文件得到,一个线程可能就占 2MB 的虚拟内存,过多的线程会对虚拟内存和文件句柄带来压力。 根据我的经验来说,如果线程数超过 400 个就比较危险。需要将所有的线程 id 以及对应的线程名输出到日志中,进一步排查是否出现了线程相关的问题。
- JNI:
使用 JNI 时,如果不注意很容易出现引用失效、引用爆表等一些崩溃。我们可以通过 DumpReferenceTables 统计 JNI 的引用表,进一步分析是否出现了 JNI 泄漏等问题。
5. 应用信息
除了系统,其实我们的应用更懂自己,可以留下很多相关的信息
- 崩溃场景
崩溃发生在哪个 Activity 或 Fragment,发生在哪个业务中
- 关键操作路径
不同于开发过程详细的打点日志,我们可以记录关键的用户操作路径,这对我们复现崩溃会有比较大的帮助
- 其他自定义信息
不同的应用关心的重点可能不太一样,比如网易云音乐会关注当前播放的音乐,QQ 浏览器会关注当前打开的网址或视频。此外例如运行时间、是否加载了补丁、是否是全新安装或升级等信息也非常重要。
6. 其他信息
除了上面这些通用的信息外,针对特定的一些崩溃,我们可能还需要获取类似磁盘空间、电量、网络使用等特定信息。所以说一个好的崩溃捕获工具,会根据场景