【论文笔记】Point Cloud Forecasting as a Proxy for 4D Occupancy Forecasting
原文链接:https://arxiv.org/abs/2302.13130
1. 引言
运动规划需要预测其余物体的运动,但相应的感知模块如建图、目标检测、跟踪和轨迹预测通常都需要大量人力标注HD地图、语义标签、边界框或物体的轨迹,难以扩展到大型无标签数据集上。3D点云预测是一种自监督方法,但其算法隐式地捕捉传感器的外参(自车运动)、内参(激光雷达的采样模式)和其余物体的形状与运动。但自动驾驶系统需要预测的是环境而非传感器本身,因为自车能够获取未来运动规划(外参)和校准的传感器参数(内参)。
3D点云预测即输入过去时刻的点云,预测未来时刻的点云。通常输入与输出点云均表达在传感器坐标系下。
本文将点云预测任务修改为时空(4D)占用预测,以排除传感器内外参。这能够解耦并简化点云预测的形式。由于获取4D占用标注很困难,本文根据给定的内外参,从4D占用预测中“渲染”点云(因此本文也可以视为一种新视图合成方法)。实验表明,本文的方法能大幅超过SotA的点云预测方法,且能进行零样本跨传感器泛化。
3. 方法
自动驾驶汽车会记录大量的无标注激光雷达点云序列 X − T : T X_{-T:T} X−T:T,也可同时估计各帧的传感器相对位置 o − T : T o_{-T:T} o−T:T。假设将序列分为过去部分( − T : 0 -T:0 −T:0)和未来部分( 0 : T 0:T 0:T)。
标准的点云预测方法(记为函数 g g g)将历史序列 X − T : 0 X_{-T:0} X−T:0作为输入,预测未来的点云序列 X ^ 1 : T \hat{X}_{1:T} X^1:T:
X ^ 1 : T = g ( X − T : 0 ) \hat{X}_{1:T}=g(X_{-T:0}) X^1:T=g(X−T:0)
设 x ∈ X t x\in X_t x∈Xt为第 t t t帧点云中的一个点,其射线原点为 o t o_t ot,射线方向为 d d d,距离为 λ \lambda λ,则:
x = o t + λ d , x ∈ X t x=o_t+\lambda d,x\in X_t x=ot+λd,x∈Xt
本文的方法(记为函数 f f f)输入未来 t t t时刻的一条射线(由原点与方向 ( o t , d ) (o_t,d) (ot,d)表达),基于过去的点云序列 X − T : 0 X_{-T:0} X−T:0和传感器位置 o − T : 0 o_{-T:0} o−T:0预测射线传播的距离 λ ^ \hat{\lambda} λ^:
λ ^ = f ( o t , d ; X − T : 0 , o − T : 0 ) \hat{\lambda}=f(o_t,d;X_{-T:0},o_{-T:0}) λ^=f(ot,d;X−T:0,o−T:0)
这一公式与NeRF类似,只是预测的为深度而非辐射。
时空(4D)占用:本文将时空占用定义为特定时间下某3D位置处的占用状态。设 z z z为真实的时空占用状态(可能因为遮挡而无法直接观测), V \mathcal{V} V为有界时空体,被离散化为时空体素 v v v。则可以使用
z ( v ) ∈ { 0 , 1 } , v = ( x , y , z , t ) ∈ V z(v)\in\{0,1\},v=(x,y,z,t)\in\mathcal{V} z(v)∈{0,1},v=(x,y,z,t)∈V
来表达体素 v v v的占用情况,其中1表示被占用,0表示未被占用(空)。
实际中,可以使用占用预测网络 h h h(参数为 w w w),根据历史的点云与传感器位置序列,预测离散时空4D占用:
z ^ = h ( X − T : 0 , o − T : 0 ; w ) \hat{z}=h(X_{-T:0},o_{-T:0};w) z^=h(X−T:0,o−T:0;w)
其中 z ^ [ v ] ∈ R [ 0 , 1 ] \hat{z}[v]\in\mathbb{R}_{[0,1]} z^[v]∈R[0,1]表示体素 v ∈ V v\in\mathcal{V} v∈V的预测占用状态。网络结构见附录。
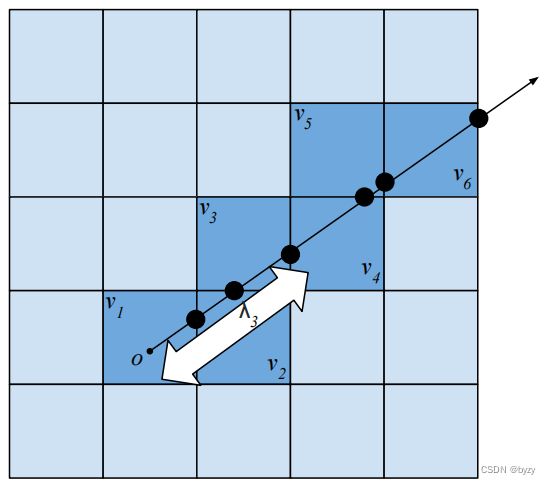
从占用进行深度渲染:给定射线查询 x = o + λ d x=o+\lambda d x=o+λd,首先通过体素遍历计算其与占用网格如何相交,如上图所示。假设相交的体素列表为 { v 1 , ⋯ , v n } \{v_1,\cdots,v_n\} {v1,⋯,vn},首先将射线离散化为其与体素边界的交点(假定射线仅能落在体素边界或无穷远处),然后假设 v i v_i vi的占用为射线离开 v i − 1 v_{i-1} vi−1在 v i v_i vi处终止的条件概率,则从原点出发的射线停止在 v i v_i vi的概率为:
p i = ∏ j = 1 i − 1 ( 1 − z ^ [ v j ] ) z ^ [ v i ] p_i=\prod_{j=1}^{i-1}(1-\hat{z}[v_j])\hat{z}[v_i] pi=j=1∏i−1(1−z^[vj])z^[vi]
然后可计算射线的期望距离:
λ ^ = f ( o , d ) = ∑ i = 1 n p i λ ^ i \hat{\lambda}=f(o,d)=\sum_{i=1}^np_i\hat{\lambda}_i λ^=f(o,d)=i=1∑npiλ^i
其中 λ ^ i \hat{\lambda}_i λ^i为射线在 v i v_i vi处终止时的距离。
训练时,允许虚拟终止点落在真实网格外,即:
λ ^ = f ( o , d ) = ∑ i = 1 n p i λ ^ i + ∑ i = 1 n ( 1 − p i ) λ ^ n + 1 \hat{\lambda}=f(o,d)=\sum_{i=1}^np_i\hat{\lambda}_i+\sum_{i=1}^n(1-p_i)\hat{\lambda}_{n+1} λ^=f(o,d)=i=1∑npiλ^i+i=1∑n(1−pi)λ^n+1
其中 λ ^ n + 1 = λ \hat{\lambda}_{n+1}=\lambda λ^n+1=λ为真实距离。
损失函数:在渲染距离与真实距离之间使用L1损失:
L ( w ) = ∑ ( o , λ , d ) ∈ ( X 1 : T , o 1 : T ) ∣ λ − f ( o , d ; X − T : 0 , o − T : 0 , w ) ∣ L(w)=\sum_{(o,\lambda,d)\in(X_{1:T},o_{1:T})}|\lambda-f(o,d;X_{-T:0},o_{-T:0},w)| L(w)=(o,λ,d)∈(X1:T,o1:T)∑∣λ−f(o,d;X−T:0,o−T:0,w)∣
4. 评估
最佳的评估方案是将预测占用与真实占用比较,但真实占用的获取十分困难。因此,本文利用传感器内外参,使用预测的4D占用“渲染”点云,评估渲染点云的质量来代表4D占用预测的质量。
对每一个真实射线 O Q → = o + λ d \overrightarrow{OQ}=o+\lambda d OQ=o+λd,得到预测 O P → = o + λ ^ d \overrightarrow{OP}=o+\hat{\lambda}d OP=o+λ^d,定义误差 ϵ = ∣ O Q → − O P → ∣ = ∣ P Q → ∣ = ∣ λ − λ ^ ∣ \epsilon=|\overrightarrow{OQ}-\overrightarrow{OP}|=|\overrightarrow{PQ}|=|\lambda-\hat{\lambda}| ϵ=∣OQ−OP∣=∣PQ∣=∣λ−λ^∣。
近场误差:由于实际上预测的占用只与观测到的区域相关,本文提出射线截断,将给定的射线 X Y → \overrightarrow{XY} XY截断在 V \mathcal{V} V中,记为 ϕ V : X Y → → X ′ Y ′ → \phi_{\mathcal{V}}:\overrightarrow{XY}\rightarrow\overrightarrow{X'Y'} ϕV:XY→X′Y′,如下图所示。

则近场预测误差 ϵ V \epsilon_\mathcal{V} ϵV定义为:
ϵ V = ∣ ϕ V ( O Q → ) − ϕ V ( O P → ) ∣ = ∣ O ′ Q ′ → − O ′ P ′ → ∣ = ∣ P ′ Q ′ → ∣ \epsilon_\mathcal{V}=|\phi_\mathcal{V}(\overrightarrow{OQ})-\phi_\mathcal{V}(\overrightarrow{OP})|=|\overrightarrow{O'Q'}-\overrightarrow{O'P'}|=|\overrightarrow{P'Q'}| ϵV=∣ϕV(OQ)−ϕV(OP)∣=∣O′Q′−O′P′∣=∣P′Q′∣
注意 O Q → \overrightarrow{OQ} OQ与 O P → \overrightarrow{OP} OP共线,被 V \mathcal{V} V截断后的射线起点也相同。
为了考虑预测错误的严重程度(即近距离处的误差比远距离处的相同误差有更大的影响),提出相对近场预测误差 ϵ V r e l \epsilon^{rel}_\mathcal{V} ϵVrel:
ϵ V r e l = ∣ ϕ V ( O Q → ) − ϕ V ( O P → ) ∣ ∣ O Q → ∣ = ∣ P ′ Q ′ → ∣ ∣ O Q → ∣ \epsilon^{rel}_\mathcal{V}=\frac{|\phi_\mathcal{V}(\overrightarrow{OQ})-\phi_\mathcal{V}(\overrightarrow{OP})|}{|\overrightarrow{OQ}|}=\frac{|\overrightarrow{P'Q'}|}{|\overrightarrow{OQ}|} ϵVrel=∣OQ∣∣ϕV(OQ)−ϕV(OP)∣=∣OQ∣∣P′Q′∣
由于其余点云预测任务产生的点数不一定和真实射线数一致,且预测点与真实点没有一对一的对应关系,因此本文对预测点云进行表面拟合,然后计算真实射线与拟合表面的交点,输出对应的射线(截断)距离。
此外,还考虑chamfer距离 d d d,和近场chamfer距离 d V d_\mathcal{V} dV:
d = 1 2 N ∑ x ∈ X min x ^ ∈ X ^ ∥ x − x ^ ∥ 2 2 + 1 2 M ∑ x ^ ∈ X ^ min x ∈ X ∥ x − x ^ ∥ 2 2 d=\frac{1}{2N}\sum_{x\in X}\min_{\hat{x}\in\hat{X}}\|x-\hat{x}\|_2^2+\frac{1}{2M}\sum_{\hat{x}\in\hat{X}}\min_{x\in X}\|x-\hat{x}\|_2^2 d=2N1x∈X∑x^∈X^min∥x−x^∥22+2M1x^∈X^∑x∈Xmin∥x−x^∥22 d V = 1 2 N ′ ∑ x ∈ X V min x ^ ∈ X ^ V ∥ x − x ^ ∥ 2 2 + 1 2 M ′ ∑ x ^ ∈ X V ^ min x ∈ X V ∥ x − x ^ ∥ 2 2 d_\mathcal{V}=\frac{1}{2N'}\sum_{x\in X_\mathcal{V}}\min_{\hat{x}\in\hat{X}_\mathcal{V}}\|x-\hat{x}\|_2^2+\frac{1}{2M'}\sum_{\hat{x}\in\hat{X_\mathcal{V}}}\min_{x\in X_\mathcal{V}}\|x-\hat{x}\|_2^2 dV=2N′1x∈XV∑x^∈X^Vmin∥x−x^∥22+2M′1x^∈XV^∑x∈XVmin∥x−x^∥22
其中 X , X ^ X,\hat{X} X,X^为真实点云和预测点云, N , M N,M N,M为真实点云与预测点云的点数; X V , X ^ V X_\mathcal{V},\hat{X}_\mathcal{V} XV,X^V为 V \mathcal{V} V内的真实点云和预测点云, N ′ , M ′ N',M' N′,M′为 V \mathcal{V} V内真实点云与预测点云的点数。
5. 实验
基准方案:(1)使用过去帧与当前帧点云建立二值占用,然后查询真实射线得到点云。(2)其余点云预测的SotA方案。
5.1 对SotA的重新评估
nuScences上的定性结果:可视化表明,本文的方法与基准方案(1)能产生比SotA更能表现场景几何的点云。此外,本文的方法能够假想或补全动态物体的运动与静态物体的遮挡区域。
nuScenes上使用新指标评估的结果:与基准方案相比,本文的方法预测的点云有更低的距离误差;基准方案(1)的性能也高于点云预测的SotA方案。
nuScenes上使用旧指标评估的结果:本文的方法在近场chamfer距离上有更高的性能,因为本文的方法是对近场占用进行优化的。对于普通的chamfer距离,由于本文不能估计预定义体素网格外的射线终点,因此低于部分SotA方案。
在KITTI-Odometry上的结果:若能在KITTI-Odometry数据集上重新训练模型,本文的方法能超过SotA;当不能获取KITTI-Odometry的数据样本时,本文在ArgoVerse2.0数据集上的预训练模型能在KITTI-Odometry上超过基准方案。若能够获取KITTI-Odometry的小部分数据,则预训练模型在这些数据上进行微调后,性能能超过在KITTI-Odometry上训练的基准方案。本文的方法是第一个能进行传感器转移/泛化的方法,说明了从场景运动中分离传感器内外参的好处。
ArgoVerse2.0数据集和KITTI-Odometry的激光雷达线数相同且采集频率相同,且前者比后者更大且场景更丰富。
5.2 结构消融
考虑两种结构:静态结构(对所有的未来帧预测同样的体素占用)和残差结构(对不同的未来帧预测带残差体素的静态体素占用)。
实验表明,静态结构在短期预测上的能力很强大(超过基准方案),这是因为场景的大部分区域均为静态的。而动态结构(为每一帧预测不同的体素占用)在长期预测上的能力很强大。残差结构希望从场景的静态区域中分离动态元素,但实践中因为没有足够的正则化强制进行运动补偿而失败。
5.3 应用
跨传感器泛化:本文的方法可以进行零样本跨传感器泛化或多数据集学习。
新视图合成:使用本文预测的占用,可以生成未来新视图的密集深度图,从而可以密集化稀疏的激光雷达点云。
附录
A. 网络细节
结构实施:本文基于神经运动预测模型的编码器-解码器结构(文章:End-to-end interpretable neural motion planner),延伸为BEV占用预测(文章:Differentiable raycasting for self-supervised occupancy forecasting)。注意本文将 X × Y × Z × T X\times Y\times Z\times T X×Y×Z×T的4D体素reshape为 X × Y × Z T X\times Y\times ZT X×Y×ZT的3D体素,将 Z Z Z(高度)维度与通道维度整合,从而能使用2D卷积处理。这表明每一个通道均代表在高度和时间维度上的一段场景。
可微渲染器:以自车位置为起点、激光雷达点为终点定义射线。4D体素网格首先根据激光雷达返回初始化为3种状态:空、被占用和未知。使用快速体素遍历算法。当射线不在体素空间内终止时,将概率集中在体素空间边界上,从而产生体素空间边界处的点。
B. 额外结果
B.1 nuScenes
评估时获取真实自车姿态:现实中,可能无法获取未来时刻的自车姿态。本文使用基于线性运动建立运动规划器,以规划结果的自车姿态用于评估结果。实验表明,这样做对于本文的方法以及基准方案(1)而言仅会导致性能略微下降,这表明本文的方法优于SotA的原因不是使用了未来时刻的真实自车姿态。
C. 前景v.s.背景查询射线
为评估本文方法结构的变体,本文利用nuScenes-LiDARSeg的标签,将射线分为前景和背景。
前景物体的差性能:相比于背景,所有变体均在前景物体(包含静态前景物体)上有较差的性能。这是因为场景中的大部分体素属于背景,训练中前景对象的权重被降低了。
每种变体的强项:静态变体在短期预测中性能最优;长期预测中,动态变体在基于射线的背景评价指标上有更高的性能,残差变体在基于射线的前景评价指标上更优(可能是前景背景的分解更好)。
与基准方案(1)比较:长期预测中,本文的方法在所有前景物体类别和背景物体上的性能均更优;短期预测中,基准方案(1)与本文方法相当,在某些时候甚至优于本文方法(对于多数动态物体),是一种无需学习的强大基准方案。