二十、泛型(2)
本章概要
- 泛型接口
- 泛型方法
- 变长参数和泛型方法
- 一个泛型的 Supplier
- 简化元组的使用
- 一个 Set 工具
泛型接口
泛型也可以应用于接口。例如 生成器,这是一种专门负责创建对象的类。实际上,这是 工厂方法 设计模式的一种应用。不过,当使用生成器创建新的对象时,它不需要任何参数,而工厂方法一般需要参数。生成器无需额外的信息就知道如何创建新对象。
一般而言,一个生成器只定义一个方法,用于创建对象。例如 java.util.function 类库中的 Supplier 就是一个生成器,调用其 get() 获取对象。get() 是泛型方法,返回值为类型参数 T。
为了演示 Supplier,我们需要定义几个类。下面是个咖啡相关的继承体系:
Coffee.java
public class Coffee {
private static long counter = 0;
private final long id = counter++;
@Override
public String toString() {
return getClass().getSimpleName() + " " + id;
}
}
Latte.java
public class Latte extends Coffee {
}
Mocha.java
public class Mocha extends Coffee {
}
Cappuccino.java
public class Cappuccino extends Coffee {
}
Americano.java
public class Americano extends Coffee {
}
Breve.java
public class Breve extends Coffee {
}
现在,我们可以编写一个类,实现 Supplier 接口,它能够随机生成不同类型的 Coffee 对象:
import java.util.*;
import java.util.function.*;
import java.util.stream.*;
public class CoffeeSupplier
implements Supplier<Coffee>, Iterable<Coffee> {
private Class<?>[] types = {Latte.class, Mocha.class,
Cappuccino.class, Americano.class, Breve.class};
private static Random rand = new Random(47);
public CoffeeSupplier() {
}
// For iteration:
private int size = 0;
public CoffeeSupplier(int sz) {
size = sz;
}
@Override
public Coffee get() {
try {
return (Coffee) types[rand.nextInt(types.length)].newInstance();
} catch (InstantiationException | IllegalAccessException e) {
throw new RuntimeException(e);
}
}
class CoffeeIterator implements Iterator<Coffee> {
int count = size;
@Override
public boolean hasNext() {
return count > 0;
}
@Override
public Coffee next() {
count--;
return CoffeeSupplier.this.get();
}
@Override
public void remove() {
throw new UnsupportedOperationException();
}
}
@Override
public Iterator<Coffee> iterator() {
return new CoffeeIterator();
}
public static void main(String[] args) {
Stream.generate(new CoffeeSupplier())
.limit(5)
.forEach(System.out::println);
for (Coffee c : new CoffeeSupplier(5)) {
System.out.println(c);
}
}
}
输出结果:

参数化的 Supplier 接口确保 get() 返回值是参数的类型。CoffeeSupplier 同时还实现了 Iterable 接口,所以能用于 for-in 语句。不过,它还需要知道何时终止循环,这正是第二个构造函数的作用。
下面是另一个实现 Supplier 接口的例子,它负责生成 Fibonacci 数列:
import java.util.function.*;
import java.util.stream.*;
public class Fibonacci implements Supplier<Integer> {
private int count = 0;
@Override
public Integer get() {
return fib(count++);
}
private int fib(int n) {
if (n < 2) {
return 1;
}
return fib(n - 2) + fib(n - 1);
}
public static void main(String[] args) {
Stream.generate(new Fibonacci())
.limit(18)
.map(n -> n + " ")
.forEach(System.out::print);
}
}
输出结果:

虽然我们在 Fibonacci 类的里里外外使用的都是 int 类型,但是其参数类型却是 Integer。这个例子引出了 Java 泛型的一个局限性:基本类型无法作为类型参数。不过 Java 5 具备自动装箱和拆箱的功能,可以很方便地在基本类型和相应的包装类之间进行转换。通过这个例子中 Fibonacci 类对 int 的使用,我们已经看到了这种效果。
如果还想更进一步,编写一个实现了 Iterable 的 Fibnoacci 生成器。我们的一个选择是重写这个类,令其实现 Iterable 接口。不过,你并不是总能拥有源代码的控制权,并且,除非必须这么做,否则,我们也不愿意重写一个类。而且我们还有另一种选择,就是创建一个 适配器 (Adapter) 来实现所需的接口,我们在前面介绍过这个设计模式。
有多种方法可以实现适配器。例如,可以通过继承来创建适配器类:
import java.util.*;
public class IterableFibonacci
extends Fibonacci implements Iterable<Integer> {
private int n;
public IterableFibonacci(int count) {
n = count;
}
@Override
public Iterator<Integer> iterator() {
return new Iterator<Integer>() {
@Override
public boolean hasNext() {
return n > 0;
}
@Override
public Integer next() {
n--;
return IterableFibonacci.this.get();
}
@Override
public void remove() { // Not implemented
throw new UnsupportedOperationException();
}
};
}
public static void main(String[] args) {
for (int i : new IterableFibonacci(18)) {
System.out.print(i + " ");
}
}
}
输出结果:

在 for-in 语句中使用 IterableFibonacci,必须在构造函数中提供一个边界值,这样 hasNext() 才知道何时返回 false,结束循环。
泛型方法
到目前为止,我们已经研究了参数化整个类。其实还可以参数化类中的方法。类本身可能是泛型的,也可能不是,不过这与它的方法是否是泛型的并没有什么关系。
泛型方法独立于类而改变方法。作为准则,请“尽可能”使用泛型方法。通常将单个方法泛型化要比将整个类泛型化更清晰易懂。
如果方法是 static 的,则无法访问该类的泛型类型参数,因此,如果使用了泛型类型参数,则它必须是泛型方法。
要定义泛型方法,请将泛型参数列表放置在返回值之前,如下所示:
public class GenericMethods {
public <T> void f(T x) {
System.out.println(x.getClass().getName());
}
public static void main(String[] args) {
GenericMethods gm = new GenericMethods();
gm.f("");
gm.f(1);
gm.f(1.0);
gm.f(1.0F);
gm.f('c');
gm.f(gm);
}
}
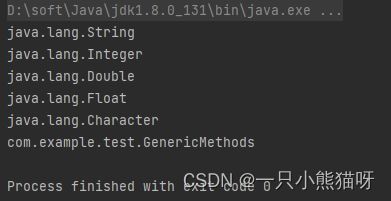
尽管可以同时对类及其方法进行参数化,但这里未将 GenericMethods 类参数化。只有方法 f() 具有类型参数,该参数由方法返回类型之前的参数列表指示。
对于泛型类,必须在实例化该类时指定类型参数。使用泛型方法时,通常不需要指定参数类型,因为编译器会找出这些类型。 这称为 类型参数推断。因此,对 f() 的调用看起来像普通的方法调用,并且 f() 看起来像被重载了无数次一样。它甚至会接受 GenericMethods 类型的参数。
如果使用基本类型调用 f() ,自动装箱就开始起作用,自动将基本类型包装在它们对应的包装类型中。
变长参数和泛型方法
泛型方法和变长参数列表可以很好地共存:
import java.util.ArrayList;
import java.util.List;
public class GenericVarargs {
@SafeVarargs
public static <T> List<T> makeList(T... args) {
List<T> result = new ArrayList<>();
for (T item : args)
result.add(item);
return result;
}
public static void main(String[] args) {
List<String> ls = makeList("A");
System.out.println(ls);
ls = makeList("A", "B", "C");
System.out.println(ls);
ls = makeList(
"ABCDEFFHIJKLMNOPQRSTUVWXYZ".split(""));
System.out.println(ls);
}
}

此处显示的 makeList() 方法产生的功能与标准库的 java.util.Arrays.asList() 方法相同。
@SafeVarargs 注解保证我们不会对变长参数列表进行任何修改,这是正确的,因为我们只从中读取。如果没有此注解,编译器将无法知道这些并会发出警告。
一个泛型的 Supplier
这是一个为任意具有无参构造方法的类生成 Supplier 的类。为了减少键入,它还包括一个用于生成 BasicSupplier 的泛型方法:
import java.util.function.Supplier;
public class BasicSupplier<T> implements Supplier<T> {
private Class<T> type;
public BasicSupplier(Class<T> type) {
this.type = type;
}
@Override
public T get() {
try {
// Assumes type is a public class:
return type.newInstance();
} catch (InstantiationException |
IllegalAccessException e) {
throw new RuntimeException(e);
}
}
// Produce a default Supplier from a type token:
public static <T> Supplier<T> create(Class<T> type) {
return new BasicSupplier<>(type);
}
}
此类提供了产生以下对象的基本实现:
- 是 public 的。 因为 BasicSupplier 在单独的包中,所以相关的类必须具有 public 权限,而不仅仅是包级访问权限。
- 具有无参构造方法。要创建一个这样的 BasicSupplier 对象,请调用
create()方法,并将要生成类型的类型令牌传递给它。通用的create()方法提供了BasicSupplier.create(MyType.class)这种较简洁的语法来代替较笨拙的new BasicSupplier。(MyType.class)
例如,这是一个具有无参构造方法的简单类:
public class CountedObject {
private static long counter = 0;
private final long id = counter++;
public long id() {
return id;
}
@Override
public String toString() {
return "CountedObject " + id;
}
}
CountedObject 类可以跟踪自身创建了多少个实例,并通过 toString() 报告这些实例的数量。 BasicSupplier 可以轻松地为 CountedObject 创建 Supplier:
import java.util.stream.Stream;
public class BasicSupplierDemo {
public static void main(String[] args) {
Stream.generate(
BasicSupplier.create(CountedObject.class))
.limit(5)
.forEach(System.out::println);
}
}
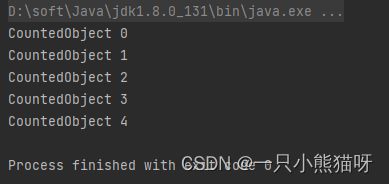
泛型方法减少了产生 Supplier 对象所需的代码量。 Java 泛型强制传递 Class 对象,以便在 create() 方法中将其用于类型推断。
简化元组的使用
使用类型参数推断和静态导入,我们将把早期的元组重写为更通用的库。在这里,我们使用重载的静态方法创建元组:
Tuple.java
public class Tuple {
public static <A, B> Tuple2<A, B> tuple(A a, B b) {
return new Tuple2<>(a, b);
}
public static <A, B, C> Tuple3<A, B, C>
tuple(A a, B b, C c) {
return new Tuple3<>(a, b, c);
}
public static <A, B, C, D> Tuple4<A, B, C, D>
tuple(A a, B b, C c, D d) {
return new Tuple4<>(a, b, c, d);
}
public static <A, B, C, D, E>
Tuple5<A, B, C, D, E> tuple(A a, B b, C c, D d, E e) {
return new Tuple5<>(a, b, c, d, e);
}
}
Tuple2.java
public class Tuple2<A, B> {
public final A a1;
public final B a2;
public Tuple2(A a, B b) {
a1 = a;
a2 = b;
}
public String rep() {
return a1 + ", " + a2;
}
@Override
public String toString() {
return "(" + rep() + ")";
}
}
Tuple3.java
public class Tuple3<A, B, C> extends Tuple2<A, B> {
public final C a3;
public Tuple3(A a, B b, C c) {
super(a, b);
a3 = c;
}
@Override
public String rep() {
return super.rep() + ", " + a3;
}
}
Tuple4.java
public class Tuple4<A, B, C, D>
extends Tuple3<A, B, C> {
public final D a4;
public Tuple4(A a, B b, C c, D d) {
super(a, b, c);
a4 = d;
}
@Override
public String rep() {
return super.rep() + ", " + a4;
}
}
Tuple5.java
public class Tuple5<A, B, C, D, E>
extends Tuple4<A, B, C, D> {
public final E a5;
public Tuple5(A a, B b, C c, D d, E e) {
super(a, b, c, d);
a5 = e;
}
@Override
public String rep() {
return super.rep() + ", " + a5;
}
}
我们修改 TupleTest.java 来测试 Tuple.java :
import static com.example.test.Tuple.tuple;
public class TupleTest2 {
static Tuple2<String, Integer> f() {
return tuple("hi", 47);
}
static Tuple2 f2() {
return tuple("hi", 47);
}
static Tuple3<Amphibian, String, Integer> g() {
return tuple(new Amphibian(), "hi", 47);
}
static Tuple4<Vehicle, Amphibian, String, Integer> h() {
return tuple(
new Vehicle(), new Amphibian(), "hi", 47);
}
static Tuple5<Vehicle, Amphibian,
String, Integer, Double> k() {
return tuple(new Vehicle(), new Amphibian(),
"hi", 47, 11.1);
}
public static void main(String[] args) {
Tuple2<String, Integer> ttsi = f();
System.out.println(ttsi);
System.out.println(f2());
System.out.println(g());
System.out.println(h());
System.out.println(k());
}
}
Americano.java
public class Americano extends Coffee {
}
Vehicle.java
public class Vehicle {
}
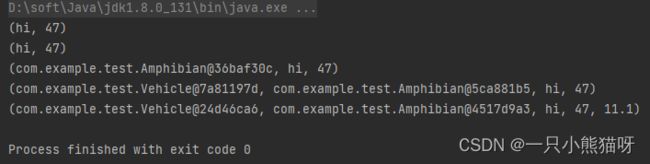
请注意,f() 返回一个参数化的 Tuple2 对象,而 f2() 返回一个未参数化的 Tuple2 对象。编译器不会在这里警告 f2() ,因为返回值未以参数化方式使用。从某种意义上说,它被“向上转型”为一个未参数化的 Tuple2 。 但是,如果尝试将 f2() 的结果放入到参数化的 Tuple2 中,则编译器将发出警告。
一个 Set 工具
对于泛型方法的另一个示例,请考虑由 Set 表示的数学关系。这些被方便地定义为可用于所有不同类型的泛型方法:
import java.util.HashSet;
import java.util.Set;
public class Sets {
public static <T> Set<T> union(Set<T> a, Set<T> b) {
Set<T> result = new HashSet<>(a);
result.addAll(b);
return result;
}
public static <T>
Set<T> intersection(Set<T> a, Set<T> b) {
Set<T> result = new HashSet<>(a);
result.retainAll(b);
return result;
}
// Subtract subset from superset:
public static <T> Set<T>
difference(Set<T> superset, Set<T> subset) {
Set<T> result = new HashSet<>(superset);
result.removeAll(subset);
return result;
}
// Reflexive--everything not in the intersection:
public static <T> Set<T> complement(Set<T> a, Set<T> b) {
return difference(union(a, b), intersection(a, b));
}
}
前三个方法通过将第一个参数的引用复制到新的 HashSet 对象中来复制第一个参数,因此不会直接修改参数集合。因此,返回值是一个新的 Set 对象。
这四种方法代表数学集合操作: union() 返回一个包含两个参数并集的 Set , intersection() 返回一个包含两个参数集合交集的 Set , difference() 从 superset 中减去 subset 的元素 ,而 complement() 返回所有不在交集中的元素的 Set。作为显示这些方法效果的简单示例的一部分,下面是一个包含不同水彩名称的 enum :
public enum Watercolors {
ZINC, LEMON_YELLOW, MEDIUM_YELLOW, DEEP_YELLOW,
ORANGE, BRILLIANT_RED, CRIMSON, MAGENTA,
ROSE_MADDER, VIOLET, CERULEAN_BLUE_HUE,
PHTHALO_BLUE, ULTRAMARINE, COBALT_BLUE_HUE,
PERMANENT_GREEN, VIRIDIAN_HUE, SAP_GREEN,
YELLOW_OCHRE, BURNT_SIENNA, RAW_UMBER,
BURNT_UMBER, PAYNES_GRAY, IVORY_BLACK
}
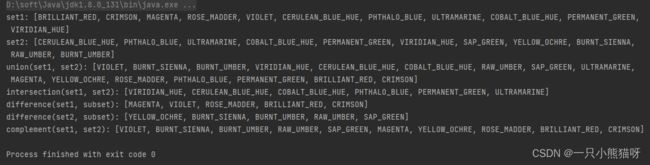
为了方便起见(不必全限定所有名称),将其静态导入到以下示例中。本示例使用 EnumSet 轻松从 enum 中创建 Set 。在这里,静态方法 EnumSet.range() 要求提供所要在结果 Set 中创建的元素范围的第一个和最后一个元素:
import java.util.EnumSet;
import java.util.Set;
import static com.example.test.Sets.*;
import static com.example.test.Watercolors.*;
public class WatercolorSets {
public static void main(String[] args) {
Set<Watercolors> set1 =
EnumSet.range(BRILLIANT_RED, VIRIDIAN_HUE);
Set<Watercolors> set2 =
EnumSet.range(CERULEAN_BLUE_HUE, BURNT_UMBER);
System.out.println("set1: " + set1);
System.out.println("set2: " + set2);
System.out.println(
"union(set1, set2): " + union(set1, set2));
Set<Watercolors> subset = intersection(set1, set2);
System.out.println(
"intersection(set1, set2): " + subset);
System.out.println("difference(set1, subset): " +
difference(set1, subset));
System.out.println("difference(set2, subset): " +
difference(set2, subset));
System.out.println("complement(set1, set2): " +
complement(set1, set2));
}
}
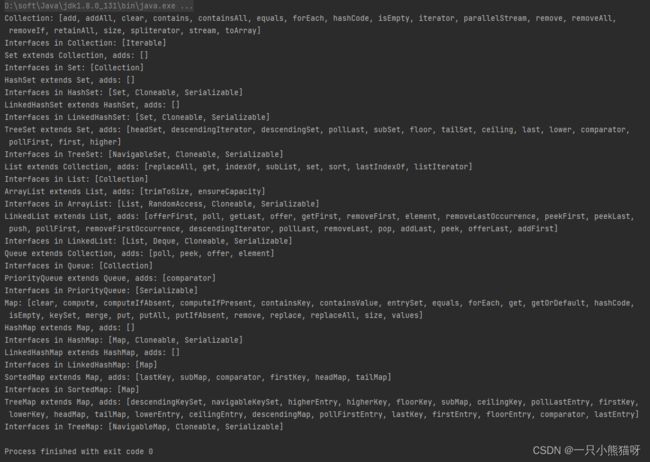
接下来的例子使用 Sets.difference() 方法来展示 java.util 包中各种 Collection 和 Map 类之间的方法差异:
import java.lang.reflect.Method;
import java.util.*;
import java.util.stream.Collectors;
public class CollectionMethodDifferences {
static Set<String> methodSet(Class<?> type) {
return Arrays.stream(type.getMethods())
.map(Method::getName)
.collect(Collectors.toCollection(TreeSet::new));
}
static void interfaces(Class<?> type) {
System.out.print("Interfaces in " +
type.getSimpleName() + ": ");
System.out.println(
Arrays.stream(type.getInterfaces())
.map(Class::getSimpleName)
.collect(Collectors.toList()));
}
static Set<String> object = methodSet(Object.class);
static {
object.add("clone");
}
static void
difference(Class<?> superset, Class<?> subset) {
System.out.print(superset.getSimpleName() +
" extends " + subset.getSimpleName() +
", adds: ");
Set<String> comp = Sets.difference(
methodSet(superset), methodSet(subset));
comp.removeAll(object); // Ignore 'Object' methods
System.out.println(comp);
interfaces(superset);
}
public static void main(String[] args) {
System.out.println("Collection: " +
methodSet(Collection.class));
interfaces(Collection.class);
difference(Set.class, Collection.class);
difference(HashSet.class, Set.class);
difference(LinkedHashSet.class, HashSet.class);
difference(TreeSet.class, Set.class);
difference(List.class, Collection.class);
difference(ArrayList.class, List.class);
difference(LinkedList.class, List.class);
difference(Queue.class, Collection.class);
difference(PriorityQueue.class, Queue.class);
System.out.println("Map: " + methodSet(Map.class));
difference(HashMap.class, Map.class);
difference(LinkedHashMap.class, HashMap.class);
difference(SortedMap.class, Map.class);
difference(TreeMap.class, Map.class);
}
}