肝了几万字,送给看了《算法图解》却是主攻Java的你和我(上篇)
地图
- 楔子
- 第1章 算法简介
-
- 1.2 二分查找
- 第2章 选择排序
-
- 2.3 选择排序
- 第3章 递归
- 第4章 快速排序
-
- 4.1 分而治之
- 4.2 快速排序
- 第5章 散列表
-
- 5.1 散列函数
- 5.2 应用案例
-
- 5.2.1 将散列表用于查找
- 5.2.2 防止重复
- 5.2.3 将散列表用作缓存
- 5.2.4 小结
- 第6章 广度优先搜索
-
- 6.4 实现图
- 6.5 实现算法
楔子
最近看了下《算法图解》这本书,写的确实通俗易懂、生动有趣,很适合算法入门(作者快打钱 !!!)。如果有需要的话,本博主也贴心的准备了这本书的电子版,通过下图下方的百度网盘链接就可下载哦!

链接:https://pan.baidu.com/s/1ubClKcrgOTqqfS7BXJrB8Q
提取码:sywh
但可惜书中示例都是用Python代码实现的,虽然狠狠的感受了一把Python的简洁和优雅之处,但是对于主攻Java语言的程序员包括我有点不太友好。为此,我特意将书中的Python代码翻译成了Java代码,希望对大家能有帮助。
因此本篇博客结合《算法图解》一书食用更佳!当然,本博主并不是简单粗暴的直接翻译,而是辅以必要的讲解,所以没有看过《算法图解》一书也可放心食用。
第1章 算法简介
1.2 二分查找
二分查找很像我们之前酒桌喝酒玩的猜数字的游戏。当时我们为了增加游戏的激烈程度,往往猜的数字都是直接对半砍。
方法binary_search用于接收一个有序数组和一个元素。如果指定的元素包含在数组中,这个方法将返回其位置。你将跟踪要在其中查找的数组部分——开始时为整个数组。
int low = 0;
int high = array.length - 1;
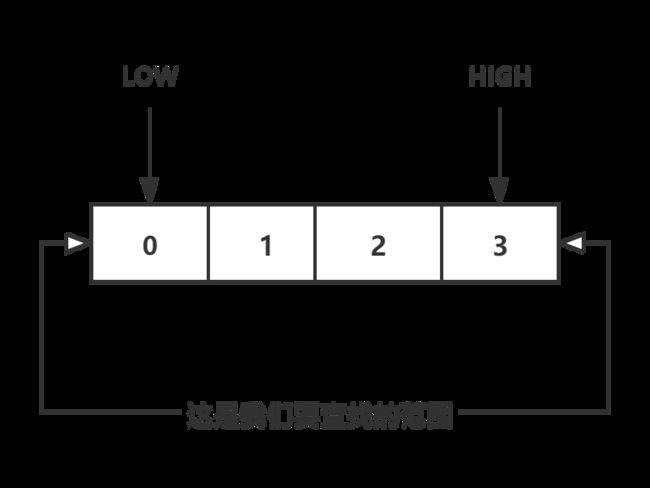
你每次都检查中间的元素:
// 整数除法,如果(low + high)不是偶数,Java自动将mid向下取整
int mid = (low + high) /2; // (0+3)/2 = 1(1.5向下取整)
int guess = array[mid];
如果猜的数字小了,就相应的修改low值:
if (guess < item)
low = mid + 1;
如果猜的数字大了,就相应的修改high值:
if (guess > item)
high = mid - 1;

完整的代码示例如下:
/**
* 用二分查找判断一个数是否存在一个数组里
* @param array 数组
* @param item 需要判断数组中是否存在的一个指定元素
* @return
*/
private static int binary_search(int[] array, int item) {
//需要查找的最小范围 - 数组索引从0开始
int low = 0 ;
// 需要查找的最大范围 - 数组长度-1
int high = array.length - 1;
while (low <= high) { // 只要范围没有缩小到只包含一个元素,就继续查找
// 整数除法,如果(low + high)不是偶数,Java自动将mid向下取整
int mid = (low + high) /2; // 如 (0+3)/2 = 1(1.5向下取整)
int guess = array[mid]; // 检查中间的元素
if (item == guess) // 如果找到了这个元素,则返回这个元素的索引即位置
return mid;
if (guess > item) // 猜的数字大了
high = mid - 1; // 不要使用 middle--
else // 猜的数字小了
low = mid + 1; // 不要使用 middle++
}
return -1; // 返回-1表示没有指定的元素
}
先写一个方便显示二分查找结果的方法:
/**
* 根据二分查找的结果打印出相应的内容
* @param array 用于查找的数组
* @param index 二分查找返回的索引
* @param item 查找的元素
*/
private static void printResult(int[] array, int index, int item) {
if (index == -1)
System.out.println("很抱歉,数组 "+ Arrays.toString(array) +" 中没有 " + item + " 这个元素");
else
System.out.println("数组 "+ Arrays.toString(array) +" 中存在 " + item + " 这个元素,它的索引为:" + index);
}
来测试一下吧:
public static void main(String[] args) {
// 声明一个数组
int[] array = {1, 3, 5, 7, 9};
System.out.println("=================================================");
// 需要查找的元素
int item = 7;
// 进行二分查找并返回相应的结果
int index = binary_search(array, item);
// 根据二分查找的结果打印出相应的内容
printResult(array, index, item);
// 需要查找的元素
int item1 = -1;
// 进行二分查找并返回相应的结果
int index1 = binary_search(array, item1);
// 根据二分查找的结果打印出相应的内容
printResult(array, index1, item1);
System.out.println("=================================================");
}
运行main方法:

完美!!!
第2章 选择排序
2.3 选择排序
选择排序的速度虽然没有快速排序这么快,但也是一种很灵巧的算法。如以下代码可通过选择排序实现:将数组元素按从小到大的顺序排列。 我们先编写一个用于找出数组中最小元素的方法:
/**
* 找出一个数组中最小的元素,并返回它的索引
* @param arr
* @return
*/
private static int findSmallest(int[] arr) {
// 最小元素的值,默认第一个元素为最小的元素
int smallest = arr[0];
// 最小元素的索引,默认第一个元素为最小的元素
int smallestIndex = 0;
// 遍历数组 - 因为默认第一个元素为最小元素,所以从1开始
for (int i = 1; i < arr.length; i++) {
if (arr[i] < smallest) {
smallest = arr[i];
smallestIndex = i;
}
}
return smallestIndex;
}
现在可以使用这个方法来编写选择排序了:
/**
* 选择排序,返回一个排序后的数组 -> 由小到大
* @param arr
* @return
*/
private static int[] selectionSort(int[] arr) {
int[] newArr = new int[arr.length];
//遍历需要排序的数组
for (int i = 0; i < arr.length; i++) {
// 找出数组中最小的元素的索引
int smallestIndex = findSmallest(arr);
// 得到这个最小的元素
int smallest = arr[smallestIndex];
// 将目前数组中最小的元素添加到新的数组中
newArr[i] = smallest;
// 将这个最小的元素从旧的数组中弹出,以便下次循环
arr.pop(smallestIndex);
}
return newArr;
}
再来测试一下:
public static void main(String[] args) {
// 定义需要排序的数组
int[] arr = {5, 3, 6, 2, 10};
// 用选择排序对数组进行排序,并返回一个排序好的数组
int[] newArr = selectionSort(arr);
// 输出排序好的数组
System.out.println(Arrays.toString(newArr));
}
逻辑好像很完美,那么能得到我们想要的结果吗?答案是不能,因为以上代码编译都通过不了!!!
那么,为什么代码编译通过不了呢?
因为Java中没有pop这个方法,即Java不能通过数组的索引直接弹出数组中对应的元素!!!
// 将这个最小的元素从旧的数组中弹出,以便下次循环
arr.pop(smallestIndex);
这个时候有些学习Java语言的小伙伴就开始慌了,那难道Java语言就实现不了选择排序吗?不会吧!!!

不要慌,问题不大!本博主就是为了解决此类问题而来。
用Java来实现选择排序的话,同样的我们需要找到数组中的最小元素,但是我们并不需要一个新的数组来一个一个装值!!! 不过,我们可以将需要排序的数组看成两个数组,左边的数组是已经排好序的数组,右边的数组是乱序的数组。当左边的排好序的数组越来越长,最后吞噬掉右边乱序的数组的时候,这个数组就排好序了。这样讲可能会有点让人云里雾里。
不过没关系,下面直接上步骤,上面文字的个中滋味你就能体会到了。
首先,我们假定数组的第一位为最小元素:

然后,我们从假定最小元素的位置向后遍历数组进行比较:

这样我们就可以求出目前数组中最小的值,也就是图中位于索引4处的0元素:
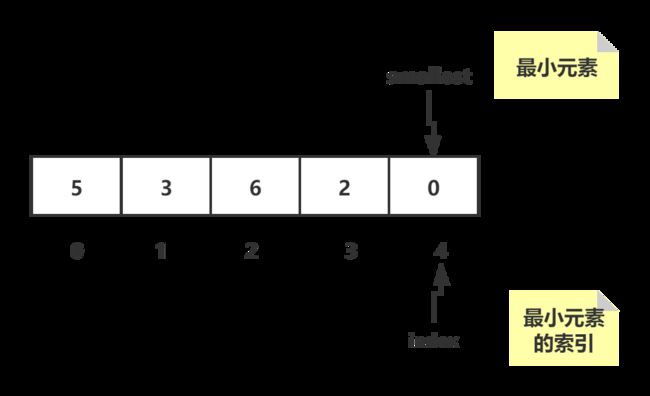
然后我们再把现在求出的最小元素和之前假定的最小元素互换位置:

我们把元素的位置互换之后,再假定数组的第二个位置也就是之前假定位置的下一位为最小元素:
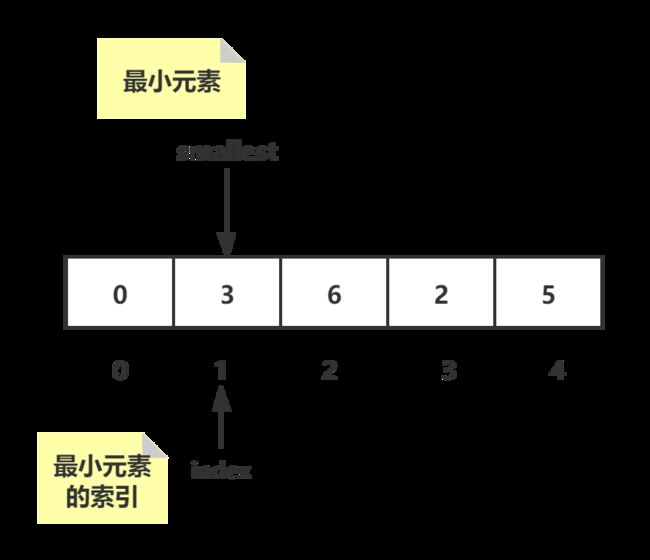
然后再重复类似于之前的操作:
- 向后遍历数组,得出从假定最小元素位置后开始数组的最小值。
- 数组中假定的最小元素和求出的最小元素互换位置。
- 再假定之前假定位置的下一位为最小元素,继续向后遍历比较,互换位置。
这样我们就可以发现似乎左边有一个有序的数组,右边有一个乱序的数组,而右边乱序的数组一直在抛出最小元素给左边有序的数组吞噬。当右边的数组被左边的数组吞噬完了,左边的数组就成功的进化成了完整版的有序数组。这样我们的排序就完成了。听起来好像有点血腥暴力
好,原理解释完了,直接上代码!!
/**
* 以最小元素为标志位 -> 选择排序(升序)
* @param arr 需要排序的数组
* @return
*/
private static int[] selectionSort(int[] arr) {
// 默认最小值为第一个元素值
int smallest = arr[0];
// 最小值的索引
int index = 0;
// 外层循环控制需要比较的次数
for (int i = 0; i < arr.length - 1; i++) {
// 遍历数组,开始比较 {5, 3, 6, 2, 0}
for (int j = i + 1; j < arr.length; j++) {
// 判断当前遍历的元素是否比最小的元素小,直至求出当前乱序(右边)数组中的最小值
if (arr[j] < smallest) {
smallest = arr[j];
index = j;
}
}
// 之前假定的最小元素和求出的最小元素互换位置
int temp = arr[i];
arr[i] = smallest;
arr[index] = temp;
// 假定的最小元素向后移动一位,以便下次比较
smallest = arr[i+1];
index = i+1;
}
return arr;
}
来测试一下吧:
public static void main(String[] args) {
// 需要排序的数组
int[] arr = {5, 3, 6, 2, 0};
// 进行选择排序,并返回一个已经排序好的数组
selectionSort(arr);
// 输出已经排序好的数组
System.out.println(Arrays.toString(arr));
}
运行main方法:
![]()
排序成功,大功告成!!!
第3章 递归
个人一直认为,编程是一门艺术。而递归则是这门艺术中的优雅之王!
没错,说的就是本帝龟了!!!

在《算法图解》第三章《递归》中,作者把人分为三种:
- 恨它的。
- 爱它的。
- 恨了几年后又爱上它的。
作者坦言承认自己属于第三种,而本博主则是第一眼就爱上了递归,并且与递归结下了不解之缘。以下有博客为证!
- 递归和循环之间不得不说的故事
- 递归实战篇:查询商品分类的实现
- 今天我们来聊聊递归喝汽水问题
可以不为夸张的说,我一半以上博客访问量都是靠的递归。而《算法图解》中对于算法和循环的观点跟我之前的博客中总结的观点不谋而合。在此引用Leight Caldwell在Stack Overflow上说的一句话:
如果使用循环,程序的性能可能会更高;如果使用递归,程序可能更容易理解。
而如果想深入理解这句话的话,可以点击上面的链接去看看我的递归系列博客。包括关于递归的终止条件也就是本书中的基线条件,以及栈的概念在我的递归系列博客中已经讲的很清楚了,此处就不再多加赘述。
第4章 快速排序
4.1 分而治之
给定一个数字数组:

使用循环将这些数字相加,并返回结果:
/**
* @author guqueyue
* @Date 2020/7/24
* for循环求出数组各元素之和
**/
public class ForArraySum {
public static void main(String[] args) {
// 声明一个数组并赋值
int[] arr = {2, 4, 6};
// 求数组各元素之和并返回这个和的值
int total = sum(arr);
// 输出结果
System.out.println(Arrays.toString(arr) + "中各元素之和为:" + total);
}
/**
* 使用for循环将数组中的数字相加并返回结果
* @param arr
* @return
*/
private static int sum(int[] arr) {
int total = 0;
// 遍历数组
for (int x : arr) {
total += x;
}
return total;
}
}
运行得:
![]()
使用递归求上述数字数组的和:
/**
* @author guqueyue
* @Date 2020/7/8
* 递归计算数组的和
* index - 1 和 index--
**/
public class RecursionArraySum {
public static void main(String[] args) {
int[] arr = {2, 4, 6};
// 用递归求数组之和
int sum = recursion(arr, 0);
System.out.println(Arrays.toString(arr) + "中各数字之和为:" + sum);
}
/**
* 用递归求数组之和,从第一个数加起
* @param arr 数组
* @param index 第一个元素的索引
* @return
*/
private static int recursion(int[] arr, int index) {
if (index == (arr.length - 1)) {
return arr[index];
}else {
return arr[index] + recursion(arr, index+1);
}
}
}
运行得:
![]()
4.2 快速排序
快速排序是一种很常见的排序算法,最近我在工作中也用到了这种排序算法那。在排序速度方面,它比我们之前介绍的选择排序要快得多。
在《算法图解》一书中,作者已经把快速排序中蕴含的分而治之的思想策略说的很清楚了。在此,我就不多加赘述。毕竟这篇也不是专门介绍某种算法的博客,而是类似于《算法图解》的学习笔记。当然,我以后也会出关于各种算法介绍的博客。有感兴趣的小伙伴可以关注我哦!加关注,不迷路!!!
当然,看到这里但是却没有看过这本书的小伙伴可以去到本篇博客开始的地方找到百度网盘的链接下载即可(不过,我猜是没有人能看到这里的 )
如果我们仿造书中作者用Python的代码示例中的逻辑,写出来的Java代码应该是这样的:
/**
* @author guqueyue
* @Date 2020/7/27
* 模仿Python代码示例的快速排序
**/
public class QuickSortFromPython {
public static void main(String[] args) {
// 声明一个数组
int[] array = {10, 5, 2, 3, 10};
// 获得排序成功的数组
int[] newArray = quickSort(array);
// 打印排好序的数组
System.out.println(Arrays.toString(newArray));
}
/**
* 快速排序
* @param array 需要排序的数组
* @return
*/
private static int[] quickSort(int[] array) {
if (array.length < 2) { // 基线条件:为空或只包含一个元素的数组是“有序”的
return array;
} else { // 递归条件
// 取数组第一个元素为基准值
int pivot = array[0];
// 由所有小于等于基准值的元素组成的子数组(去除基准值)
int[] less = getSmallArray(array, pivot);
// 由所有大于基准值的元素组成的子数组(去除基准值)
int[] greater = getBigArray(array, pivot);
return getSortArray(quickSort(less), pivot, quickSort(greater));
}
}
/**
* 根据传入的小于基准值的数组、基准值以及大于基准值的数组
* 拼接成一个数组
* @param less 小于基准值的数组
* @param pivot 基准值
* @param greater 大于基准值的数组
* @return
*/
private static int[] getSortArray(int[] less, int pivot, int[] greater) {
// 声明一个新数组
int[] newArray = new int[less.length + 1 + greater.length];
// 遍历小于基准值的数组, 赋值给新数组
for (int i = 0; i < less.length; i++) {
newArray[i] = less[i];
}
// 添加基准值
newArray[less.length] = pivot;
// 遍历大于基准值的数组,赋值给新数组
for (int i = 0; i < greater.length; i++) {
newArray[i + less.length + 1] = greater[i];
}
return newArray;
}
/**
* 根据传入的数组和基准值,返回小于等于这个基准值的数组
* @param array 数组
* @param pivot 基准值
* @return
*/
private static int[] getSmallArray(int[] array, int pivot) {
// 声明一个集合用来装值
List<Integer> list = new ArrayList<Integer>();
// 遍历数组
for (int i = 1; i < array.length; i++) {
if (array[i] <= pivot) {
list.add(array[i]);
}
}
// 将集合转换成数组
int[] smallArray = new int[list.size()];
for (int i = 0; i < smallArray.length; i++) {
smallArray[i] = list.get(i);
}
return smallArray;
}
/**
* 根据传入的数组和基准值,返回大于这个基准值的数组
* @param array 数组
* @param pivot 基准值
* @return
*/
private static int[] getBigArray(int[] array, int pivot) {
// 声明一个集合用来装值
List<Integer> list = new ArrayList<Integer>();
// 遍历数组
for (int i = 1; i < array.length; i++) {
if (array[i] > pivot) {
list.add(array[i]);
}
}
// 将集合转换成数组
int[] bigArray = new int[list.size()];
for (int i = 0; i < bigArray.length; i++) {
bigArray[i] = list.get(i);
}
return bigArray;
}
}
运行main方法:
![]()
排序成功!可是真的完美吗?书中用Python代码十几行实现的代码,仿照它的逻辑用Java写却用了一百多行!!!
那么,我又要发出灵魂的拷问了:Java有这么弱吗?
当然没有!!!Java和Python作为两种不同的编程语言。两者由于语法的不同,自然会有不同的实现方式。同选择排序有些类似的是,Java实现快速排序也并不需要得到什么新的数组,直接在一个数组内进行排序操作即可:
/**
* @author guqueyue
* @Date 2020/7/8
* 快速排序
**/
public class QuickSort {
static int[] arr = {8, 2, 17, 5, 8, 12};
/**
* 快速排序 -> 升序排序
* @param array
* @param begin
* @param end
*/
private static void quickSort(int[] array, int begin, int end) {
int i, j, flag, temp;
if (begin > end) {
return;
}
i = begin;
j = end;
//基准值
flag = array[begin];
while (i < j) {
// 从右往左找, 直到找到一个比基准值小的元素
for (; array[j] >= flag && i < j; j--);
// 从左往右找, 直到找到一个比基准值大的元素
for (; array[i] <= flag && i < j; i++);
// 如果满足条件就交换位置
if (i < j) {
temp = array[j];
array[j] = array[i];
array[i] = temp;
}
}
// 最后将基准值与 i和j相等位置即最后i、j相遇位置的数字交换
// flag = array[begin]; -> 之前的代码
array[begin] = array[j];
array[j] = flag;
// 递归调用左半数组
quickSort(array, begin, j-1);
// 递归调用右半数组
quickSort(array, j+1, end);
}
public static void main(String[] args) {
quickSort(arr, 0, arr.length-1);
System.out.println(Arrays.toString(arr));
}
}
运行main方法,得:
![]()
完美!虽然代码量还是比python多,但也没多多少。况且Java优势在于企业级开发,也不是算法这方面,所以也不用纠结这个问题了。
以上代码关于两个数互换问题如果不懂的,可以看我的这篇博客:
实现两个数互换的八种方法
至于关于用Java实现快速排序的具体步骤讲解。
以后本博主会出算法系列的博客进行详细详解的,欢迎大家关注我哦!
第5章 散列表
5.1 散列函数
用Java语言来创建散列表:
/**
* @author guqueyue
* @Date 2020/7/28
* 散列表
**/
public class HashTable {
public static void main(String[] args) {
// 创建散列表book
HashMap<String, Double> book = new HashMap<String, Double>();
// 创建散列表book之后,在其中添加一些商品的价格
book.put("apple", 0.67); // 一个苹果的价格为67美分
book.put("milk", 1.49); // 牛奶的价格为1.49美元
book.put("avocado", 1.49);
// 输出book
System.out.println(book);
// 得到鳄梨的价格
System.out.println("鳄梨的价格为:" + book.get("avocado") + "美元");
}
}
运行应用程序,得:

5.2 应用案例
5.2.1 将散列表用于查找
用Java语言来创建电话薄:
/**
* @author guqueyue
* @Date 2020/7/28
* 电话薄
**/
public class PhoneBook {
public static void main(String[] args) {
// 创建一个散列表
HashMap<String, String> phoneBook = new HashMap<String, String>();
// 添加一些联系人的电话号码
phoneBook.put("jenny", "8675309");
phoneBook.put("emergency", "911");
// 查找jenny的电话号码
String name = "jenny";
System.out.println(name + "的号码电话为:" + phoneBook.get(name));
}
}
运行应用程序,控制台输出如下:
![]()
查找成功!!!
5.2.2 防止重复
避免重复投票:
/**
* @author guqueyue
* @Date 2020/7/9
* 不要把map放在方法里循环new
**/
public class CheckVoter {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
// 用来存储已经投过票姓名的散列表
HashMap<String, Boolean> nameMap = new HashMap<String, Boolean>();
while (true) {
System.out.print("请输入姓名:");
String name = scanner.next();
checkVoter(name, nameMap);
}
}
/**
* 根据是否已经投过票来输出结果
* @param name 已经投过票者的姓名
* @param nameMap 用来存储已经投过票姓名的散列表
*/
private static void checkVoter(String name, HashMap<String, Boolean> nameMap) {
if (nameMap.containsKey(name)) { // 判断是否已经投过票
System.out.println("kick them out!");
}else {
nameMap.put(name, true); // 投过票的把他存起来
System.out.println("let them vote!");
}
}
}
运行应用程序:

完美!!!
5.2.3 将散列表用作缓存
说到缓存,可能广大的程序员朋友们对这个词语并不陌生。往往代码的逻辑明明并没有错,已经检查了千百遍,却就是出不了想要的效果,结果发现是缓存的锅,气的直想砸电脑。

又或者,发现别人写的代码有问题,明明已经对环境进行了各种检查,清了千百遍缓存。然后去问别人的时候,别人张口就来一句:你缓存清了没有?然后就没理你了。

但是作为一个程序员,从设计的角度来讲,不得不承认,缓存是个好东西。缓存就是让网站将数据记住,而不再重新计算,这极大的减轻了服务器的压力,特别是在高并发的情况下。
当然了,其实散列表用作缓存的逻辑跟之前防止重复例子的逻辑差不多:
/**
* @author guqueyue
* @Date 2020/7/28
* 缓存模拟
**/
public class Cache {
public static void main(String[] args) {
Scanner input = new Scanner(System.in);
Map<String, String> cache = new HashMap<String, String>();
while (true) {
System.out.print("请输入网址:");
String url = input.next();
// 根据网址返回页面
String page = getPage(url, cache);
// 模拟返回的页面,并打印出来
System.out.println("服务器返回了:" + page);
}
}
/**
* 根据url得到页面
* @param url
* @param cache
* @return
*/
private static String getPage(String url, Map<String, String> cache) {
if (cache.containsKey(url)) { // 判断缓存中是否有这个网址对应的页面
// 如果有,直接从缓存中返回页面
return cache.get(url);
}else {
// 如果缓存中没有有这个网址对应的页面,则去向服务器请求数据再生成这个页面
String dataPage = getDataFromServer(url);
// 再将生成这个页面所需的数据也就是这个页面放入缓存中
cache.put(url, dataPage);
return dataPage;
}
}
/**
* 模拟服务器根据url返回相应的数据以便生成页面
* @param url
* @return
*/
private static String getDataFromServer(String url) {
System.out.println("服务器接收到了url请求...");
// 模拟生成的页面
String dataPage = "一个" + url + "的页面";
// 返回这个页面
return dataPage;
}
}
运行应用程序:
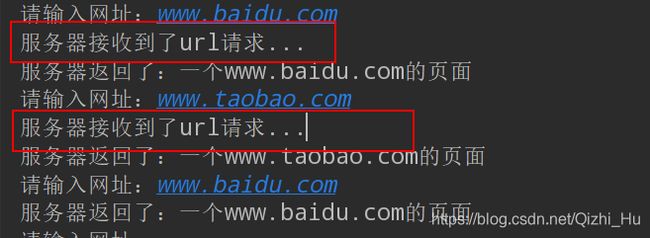
我们可以很清晰的看到:当我们第一次发出百度和淘宝的请求时,服务器都接收到了url请求,也就是说从服务器返回了用于生成页面的数据。但是当我们第二次发出百度的请求时,浏览器并没有接收到请求,也就是说这个时候百度主页面是直接在缓存里面取的。
5.2.4 小结
所以,通过以上分析,我们可以得出散列表的三个作用:
- 模拟映射关系,就像之前的电话薄以及水果店价格表。
- 防止重复, 好比之前的防止重复投票。
- 缓存/记住数据,以免服务器再次通过处理来生成它们。
第6章 广度优先搜索
广度优先搜索(breadth-first search, BFS)是为了解决最短路径问题所产生的算法,如计算出前往朋友家的最短路径,又或者求出象棋中把对方将死的最少步数。广度优先搜索作为一种用于图的查找算法,可帮助回答两类问题:
- 从一个节点出发,有前往另一个节点的路径吗?
- 从一个节点出发,前往另一节点的哪条路径更短?
6.4 实现图
接下来使用散列表来实现图,图又由多个节点组成,如下图:

上图我们可以运用以下Java代码来建立映射关系:
Map<String, String[]> graph = new HashMap<String, String[]>();
graph.put("you", new String[]{"alice", "bob", "claire"});
其实图只不过是一系列的节点和边,哪怕如下图一样复杂的图,我们也能用代码表示。

上图用Java代码表示如下:
Map<String, String[]> graph = new HashMap<String, String[]>();
graph.put("you", new String[]{"alice", "bob", "claire"});
graph.put("bob", new String[]{"anuj", "peggy"});
graph.put("alice", new String[]{"peggy"});
graph.put("claire", new String[]{"thom", "jonny"});
graph.put("anuj", null);
graph.put("peggy", null);
graph.put("thom", null);
graph.put("jonny", null);
6.5 实现算法
关于算法的实现原理请翻书哦!另外关于队列的概念书中也讲的清楚了,此处我也就不加赘述。
这里我们就像书中一样通过Java代码来实现查找你的人际关系圈中是否有芒果商(这里我们默认名字最后一个字母为m的为芒果商):
/**
* @author guqueyue
* @Date 2020/7/30
* 查找你的朋友是否有芒果商
**/
public class MangoSeller {
public static void main(String[] args) {
// 创建一张用来表示你人际关系的图
Map<String, String[]> graph = new HashMap<String, String[]>();
createGraph(graph);
// 创建一个队列
List<String> searchQueue = new ArrayList<String>();
// 将你的邻居都加入到这个搜索队列中
addSearchQueue(searchQueue, graph.get("you"));
// 检查你的人脉关系中是否有芒果商
boolean flag = searchQueue(searchQueue, graph);
// 如果返回false,则表明你的人脉圈中没有芒果商人
if (!flag) System.out.println("不好意思,你的朋友中没有芒果商人!!!");
}
/**
* 检查你的人脉关系中是否有芒果商
* @param searchQueue 队列
* @param graph 人际关系图
* @return
*/
private static boolean searchQueue(List<String> searchQueue, Map<String, String[]> graph) {
// 只要队列不为空,就一直遍历查找
while (searchQueue.size() != 0) {
// 取出其中的第一个人, 并移除
String person = searchQueue.get(0);
searchQueue.remove(0);
// 检查这个人是否是芒果商
if (personIsSeller(person)) { // 是芒果商
System.out.println(person + " is a mango seller!");
return true;
}else {
// 不是芒果商,将这个人的朋友都加入到搜索队列中
addSearchQueue(searchQueue, graph.get(person));
}
}
// 如果最终返回了false,则说明你的人际关系圈中并没有芒果商
return false;
}
/**
* 通过姓名检查这个人是不是芒果商
* @param person
* @return
*/
private static boolean personIsSeller(String person) {
// 判断姓名字符串最后一个字符是不是以m结尾
return person.substring(person.length() - 1).equals("m");
}
/**
* 往搜索队列中添加邻居
* @param searchQueue
* @param you
*/
private static void addSearchQueue(List<String> searchQueue, String[] you) {
// 如果邻居不为空,则添加
if (you != null) {
for (String person : you) {
searchQueue.add(person);
}
}
}
/**
* 人际关系图
* @param graph
*/
private static void createGraph(Map<String, String[]> graph) {
graph.put("you", new String[]{"alice", "bob", "claire"});
graph.put("bob", new String[]{"anuj", "peggy"});
graph.put("alice", new String[]{"peggy"});
graph.put("claire", new String[]{"thom", "jonny"});
graph.put("anuj", null);
graph.put("peggy", null);
graph.put("thom", null);
graph.put("jonny", null);
}
}
跑一下代码,得出:
![]()
结果好像很完美,那么有没有什么问题呢?
我们试着来打印一下程序检查的人员以及顺序:
System.out.println("正在检查:" + person);
运行程序:
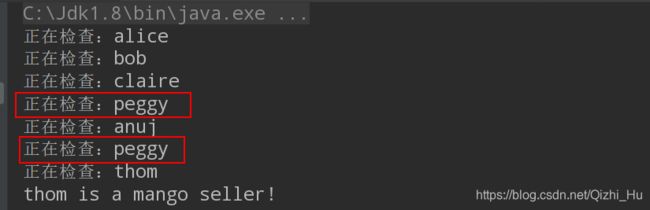
这个时候我们就可以很轻易的发现peggy这个人竟然被检查了两次。也就是说,我们做了重复检查的事情,做了无用功,影响了程序的效率。
这是为什么呢?我们通过之前的人际关系图可以发现原来peggy不但是bob的邻居,他还是alice的邻居,所以他被重复检查了两次:

我猜这个时候可能就有人会说了:只是影响了一点效率而已,没关系的!
真的没关系吗???
如果这个时候人际关系图是这样的:

对应的代码:
graph.put("you", new String[]{"peggy"});
graph.put("peggy", new String[]{"you"});
我们试着运行一下程序:

我们会发现系统陷入了疯狂的死循环中!!!不断的检查你和peggy是否是芒果商。原因很简单,当检查你是否是芒果商的时候,会将peggy加入到搜索队列中;而当检查peggy是否是芒果商时,又会将你加入到搜索队列中。如此周而复始,往复循环!
所以,我们需要在检查的方法中给已经检查过的人做标记,之后不再检查他
代码如下:
/**
* 检查你的人脉关系中是否有芒果商
* @param searchQueue 队列
* @param graph 人际关系图
* @return
*/
private static boolean searchQueue(List<String> searchQueue, Map<String, String[]> graph) {
// 用于记录检查过的人
List<String> searched = new ArrayList<String>();
// 只要队列不为空,就一直遍历查找
while (searchQueue.size() != 0) {
// 取出其中的第一个人, 并移除
String person = searchQueue.get(0);
searchQueue.remove(0);
// 只有当这个人没有被检查过才能被检查
if (!searched.contains(person)) {
// 检查这个人是否是芒果商
if (personIsSeller(person)) { // 是芒果商
System.out.println(person + " is a mango seller!");
return true;
}else {
// 不是芒果商,将这个人的朋友都加入到搜索队列中
addSearchQueue(searchQueue, graph.get(person));
// 将这个人标记为检查过
searched.add(person);
}
}
}
// 如果最终返回了false,则说明你的人际关系圈中并没有芒果商
return false;
}
运行程序:

完美!!!没有死循环了!
下面的作者的自我吐槽
现在已经是凌晨的2点14分了,不知不觉这篇博客也已经写了2万多字。其实明明知道写这么长的博客不会有很多人看的,明明知道把这篇博客拆分成很多篇访问量会多好多,但是我就是不想这么做。如果有人能够看到这里的话,谢谢你!时候不早了,晚安!

emmmm,本来初计划是一篇博客写完《算法图解》的Java形式讲解,但是文章太长了,还是分个上下两篇吧。
第一次写博客周期这么长,还没写完。喜欢就点个赞吧!
下篇链接:肝了几万字,送给看了《算法图解》却是主攻Java的你和我(下篇)