【Sharding-JDBC】(一) 整合mybatis-plus 水平分表
ps:
概念:水平分表是在同一个数据库内,把同一个表的数据按一定规则拆到多个表中
一、准备环境:
1.单数据库下,分表:
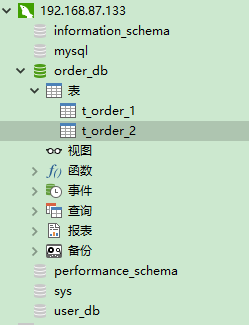
2.数据库脚本:
#创建订单库order_db
CREATE DATABASE `order_db` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
#在order_db中创建t_order_1、t_order_2表
DROP TABLE IF EXISTS `t_order_1`;
CREATE TABLE `t_order_1` (
`order_id` bigint(20) NOT NULL COMMENT '订单id',
`price` decimal(10, 2) NOT NULL COMMENT '订单价格',
`user_id` bigint(20) NOT NULL COMMENT '下单用户id',
`status` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '订单状态',
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
DROP TABLE IF EXISTS `t_order_2`;
CREATE TABLE `t_order_2` (
`order_id` bigint(20) NOT NULL COMMENT '订单id',
`price` decimal(10, 2) NOT NULL COMMENT '订单价格',
`user_id` bigint(20) NOT NULL COMMENT '下单用户id',
`status` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '订单状态',
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;二、pom.xml:(导入相应jar包)
ps:
这里用的springboot版本是2.2.2.RELEASE;
这里sharding-jdbc-spring-boot-starter我用4.0.0-RC2整合,控制台会报错:
Failed to configure a DataSource: 'url' attribute is not specified and no embedded datasource could be configured.
Reason: Failed to determine a suitable driver class
org.springframework.boot
spring-boot-starter
org.springframework.boot
spring-boot-starter-test
org.mybatis.spring.boot
mybatis-spring-boot-starter
2.1.1
com.alibaba
druid-spring-boot-starter
1.1.20
mysql
mysql-connector-java
5.1.47
org.apache.shardingsphere
sharding-jdbc-spring-boot-starter
4.0.0-RC1
com.baomidou
mybatis-plus-boot-starter
3.2.0
org.projectlombok
lombok
org.springframework.boot
spring-boot-starter-web
三、 application.yml:(重要)
#服务端口
server:
port: 56081
#服务名
spring:
application:
name: sharding-jdbc-examples
http:
encoding:
enabled: true
charset: utf-8
force: true
main:
allow-bean-definition-overriding: true
#shardingsphere相关配置
shardingsphere:
datasource:
names: m1 #配置库的名字,随意
m1: #配置目前m1库的数据源信息
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.87.133:3306/order_db?useUnicode=true
username: root
password: 123456
sharding:
tables:
t_order: # 指定t_order表的数据分布情况,配置数据节点
actualDataNodes: m1.t_order_$->{1..2}
tableStrategy:
inline: # 指定t_order表的分片策略,分片策略包括分片键和分片算法
shardingColumn: order_id
algorithmExpression: t_order_$->{order_id % 2 + 1}
keyGenerator: # 指定t_order表的主键生成策略为SNOWFLAKE
type: SNOWFLAKE #主键生成策略为SNOWFLAKE
column: order_id #指定主键
props:
sql:
show: true
#日志打印
logging:
level:
root: info
org.springframework.web: info
com.lucifer.sharding.dao: debug
druid.sql: debugt_order:在这里是逻辑表名,并非真实表名。真实表名是t_order_1,t_order_2;
actualDataNodes:m1.t_order_$->{1..2} 这里的m1就是库名(上面已经设置了),相当于就是 库名.逻辑表名_1,库名.逻辑表名_2======》对应的就是两个真实的表名。
shardingColumn:分片键,
algorithmExpression: t_order_$->{order_id % 2 + 1} :分片规则。t_order_$->{order_id % 2 + 1}分两半来看:
(1)--》t_order_逻辑表名_值,至于这个值是1还是2,是由
(2)---》order_id % 2 + 1来的,order_id的值除以2取模再加1.
也就是order_id为偶数的数据落在t_order_1,为奇数的落在t_order_2。
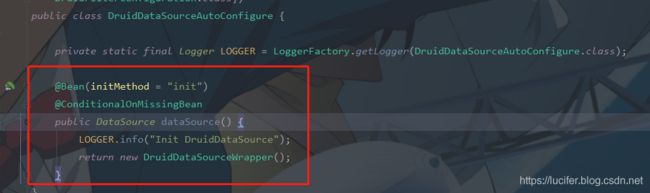
spring.main.allow-bean-definition-overriding: true :必须设置,否者会报错;
The bean 'dataSource', defined in class path resource [org/apache/shardingsphere/shardingjdbc/spring/boot/SpringBootConfiguration.class], could not be registered. A bean with that name has already been defined in class path resource [com/alibaba/druid/spring/boot/autoconfigure/DruidDataSourceAutoConfigure.class] and overriding is disabled.
Action:
Consider renaming one of the beans or enabling overriding by setting spring.main.allow-bean-definition-overriding=true意思很明确,有两个同样名字的bean。
查看SpringBoot和druid源码,可以看到有相同名字的bean。

四、代码段
ps:代码很简单,主要是配置,所以这里就不多说了。
controller:
package com.lucifer.sharding.controller;
import com.lucifer.sharding.service.OrderService;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
/**
* @author Lucifer
*/
@RestController
public class OrderController {
@Resource
private OrderService orderService;
@GetMapping(value = "/add")
public void addOrder() {
orderService.addOrder();
}
@GetMapping(value = "/find")
public void findOrder() {
orderService.findOrder();
}
}service接口:
package com.lucifer.sharding.service;
/**
* @author Lucifer
*/
public interface OrderService {
/**
* 新增订单
*
*/
void addOrder();
/**
* 查询
*/
void findOrder();
}
service实现类:
package com.lucifer.sharding.service.impl;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.lucifer.sharding.dao.OrderDao;
import com.lucifer.sharding.pojo.Order;
import com.lucifer.sharding.service.OrderService;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import java.math.BigDecimal;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
/**
* @author Lucifer
*/
@Service
public class OrderServiceImpl implements OrderService {
@Resource
OrderDao orderDao;
@Override
public void addOrder() {
for (int i = 0; i < 10; i++) {
Order order = new Order();
order.setPrice(new BigDecimal(Math.random()));
order.setUserId(new Random().nextLong());
order.setStatus("0");
orderDao.insert(order);
}
}
//执行新增后,将两库的数据各取一条,来测试
@Override
public void findOrder() {
List list=new ArrayList<>();
list.add(418415166183440384L);
list.add(418417197166100481L);
QueryWrapper queryWrapper=new QueryWrapper<>();
queryWrapper.in("order_id", list);
orderDao.selectList(queryWrapper);
}
}
dao层接口:
package com.lucifer.sharding.dao;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.lucifer.sharding.pojo.Order;
/**
* @author Lucifer
*/
public interface OrderDao extends BaseMapper {
}
实体类:
package com.lucifer.sharding.pojo;
import java.io.Serializable;
import java.math.BigDecimal;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
/**
* @author Lucifer
*/
@TableName(value = "t_order")
@Data
public class Order implements Serializable {
/**
* 订单id
*/
private Long orderId;
/**
* 订单价格
*/
private BigDecimal price;
/**
* 下单用户id
*/
private Long userId;
/**
* 订单状态
*/
private String status;
private static final long serialVersionUID = 1L;
}ps:
需要说的是这个mybatis-plus的注解@TableName(value = "t_order")指定表名,这里指定逻辑表名。
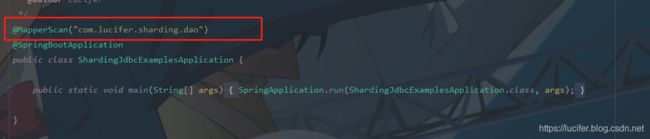
SpringBoot启动类上添加@MapperScan注解。
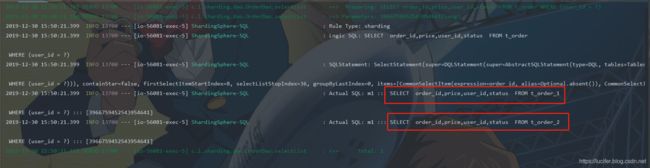
五、测试
控制台打印:
数据库:

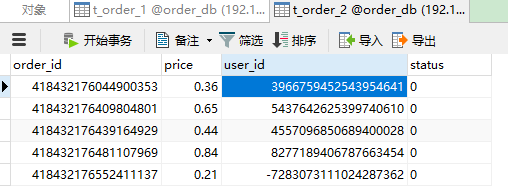
其实大概的逻辑就是ShardingSphere给你用雪花算法生成了一个主键order_id的值,而根据这个值在配置文件中所配置的规则来决定插入到哪个表中,至于查询也是,根据你的order_id来决定来查哪张表(测试截图忽略)。
也就是如果查询字段不是分片键,那么会查两个表;如图: