主从复制Slave_IO_Running: NO Slave_SQL_Running: NO ,Slave failed to initialize relay log info struct解决办法
1. 解决问题的思路:
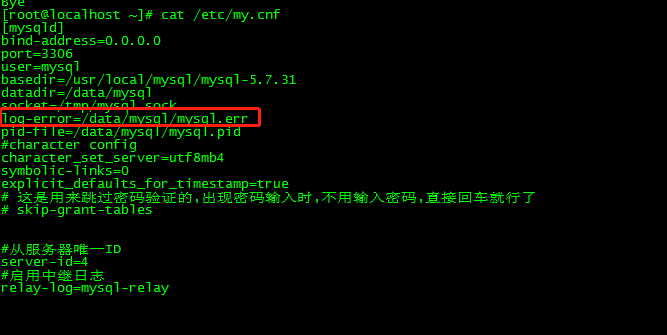
- 找到mysql配置的这个文件/etc/my.cnf
- 在文件中找到mysql错误异常日志文件的路径,我配置的是log-error=/data/mysql.err
- 编辑/var/log/mysqld.log文件
- 查看具体异常信息
2. 异常信息
[ERROR] Slave I/O for channel ‘’: Fatal error: The slave I/O thread stops because master and slave have equal MySQL server UUIDs; these UUIDs must be different for replication to work. Error_code: 1593

3. 问题定位
由于uuid相同,而导致触发此异常。
首先我只安装了一台linux 又克隆了两台,一主三从 , 关键点就在于我是克隆的,才导致了报Slave_IO_Running: NO
原因: mysql 有个uuid , 然而uuid 是唯一标识的,所以我克隆过来的uuid是一样的,只需要修改一下uuid 就ok了,找到auto.cnf 文件修改uuid
4. 解决方案
查询命令找此auto.cnf修改uuid即可:
find -name auto.cnf
其实这个文件就在mysql的data目录中/data/mysql,这是我的文件位置
重启mysql服务器,再查看mysql从节点的状态,恢复正常
重启mysql
service mysql restart
5. 登录MYSQL,重启SLAVE,再次验证
#停止链路
stop slave;
#启动链路
start slave;
#查看链路
show slave status \G


可能原因一:MySQL的uuid是唯一的,查看主从机器的uuid是否唯一。
查看文件:/var/lib/mysql/auto.cnf
查看结果:主从机器的uuid不一样,此可能性被排除。
可能原因二:确认server-id是否唯一。
查看文件:/etc/mysql/my.cnf
查看结果:主从机器的server-id唯一,此可能性被排除。
可能性三:因为从库MySQL重启导致二进制文件位置从库和主库不一致。
1、查看:
主库:show master status\G
从库:show slave status\G
2、主库从库二进制文件是不一致的,开心,可能就是这个原因了。
3、根据网上方法修改:在从库中依次执行如下操作
mysql> stop slave;
Query OK, 0 rows affected (0.00 sec)
mysql> CHANGE MASTER TO MASTER_LOG_FILE='master-bin.000004', MASTER_LOG_POS=154;
Query OK, 0 rows affected (0.00 sec)
mysql> start slave;
4、再次查看从库信息:sad。。并没有解决 。
5、失望中,试着依次重启了主机、从机的MySQL。
排查方式
1. 首先我们先通过 performance_schema 查看一下造成报错的原因
select * from performance_schema.replication_applier_status_by_worker;
问题描述:发现主库操作数据从库没有变动问题,可能原因是从库重启导致的无法同步问题。
排查思路:
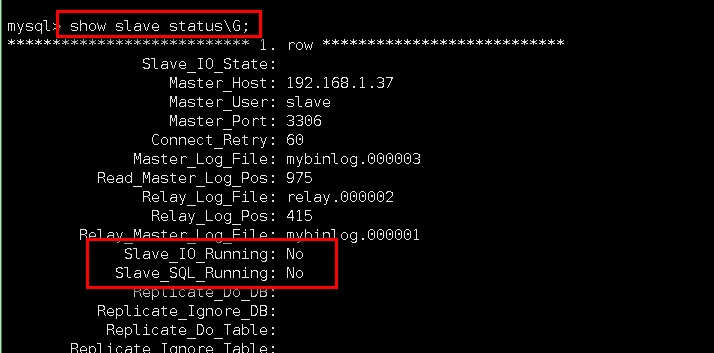
1、查看主从复制状态
发现从库的IO和SQL进程都是no(正常状态应该是yes)
注意:mysql replication中slave机器上有两个关键进程,死一个都不行,一个是slave_sql_running,一个是slave_io_running,一个负责与主机的IO通信,一个负责自己的slave mysql进程。
2、解决办法如下:
>stop slave; ##停止同步
> SET GLOBAL SQL_SLAVE_SKIP_COUNTER=1; START SLAVE; ##设置counter为1,启动同步
>show slave status\G; ##查看同步状态
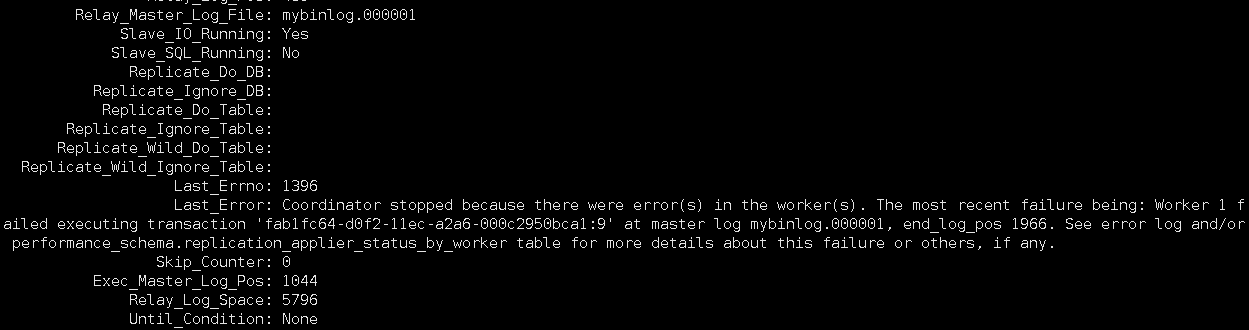
3、发现SQL进程还是No
提示信息显示如下:
Last_Errno: 1396
Last_Error: Coordinator stopped because there were error(s) in the worker(s). The most recent failure being: Worker 1 failed executing transaction 'fab1fc64-d0f2-11ec-a2a6-000c2950bca1:9' at master log mybinlog.000001, end_log_pos 1966. See error log and/or performance_schema.replication_applier_status_by_worker table for more details about this failure or others, if any.

4、根据上面的提示,查询到的异常数据出现在opp_starck表中
#select * from performance_schema.replication_applier_status_by_worker\G; 确定事务发生在表opp_strack上,定位在表上,再去排查是哪张表

可以参考:mysql主从同步报错,提示Last_Error: Coordinator stopped because there were error(s) in the worker(s). The most_mysql 报错 last_谁还不是小白鼠的博客-CSDN博客
5、主从数据恢复一致后需要在slave上跳过报错的事务,在从库中执行
使用GTID跳过错误的方法:找到错误的GTID跳过(通过exec_master_log_pos去binlog里找GTID,或者则通过监控表replication_applier_status_by_worker找到GTID,也可以通过excured_gtid_set算GTID),这里使用监控来找到错误的GTID。找到GTID之后,跳过错误的步骤:
>stop slave; #停止同步
>set @@session.gtid_next='fab1fc64-d0f2-11ec-a2a6-000c2950bca1:9'; #跳过错误的GTID
>begin; #提交一个空事务,因为设置gtid_next后,gtid的生命周期就开始了,必须通过显性的提交一个事务来结束,否则报错:ERROR
>commit
>set @@session.gtid_next=automatic; #设置回自动模式
>start slave; #启动同步
>show slave status\G; #再次确认状态

6、如下图主从复制恢复正常

GTID:是对于一个已提交事务的唯一编号,并且是一个全局(主从复制)唯一的编号。
GTID核心参数
重要参数:
gtid-mode=on --启用gtid类型,否则就是普通的复制架构
enforce-gtid-consistency=true --强制GTID的一致性
log-slave-updates=1 --slave更新是否记入日志
注:
Slave_IO_State # 从库的当前状态
Slave_IO_Running # 读取主服务器二进制日志的I/O线程是否正在运行
Slave_SQL_Running # 执行读取主服务器中二进制日志事件的SQL线程是否正在运行
Seconds_Behind_Master # 是否为0,为0就是已经同步了
如果Slave_IO_Running或Slave_SQL_Running不同时为YES,请尝试执行
mysql> stop slave;
mysql> reset slave;
mysql> start slave;